
Abstract
This paper presents a novel type of high-speed and area-efficient register-based transpose memory architecture enabled by reporting on both edges of the clock. The proposed new architecture, by using the double-edge triggered registers, doubles the throughput and increases the maximum frequency by avoiding some of the combinational circuit used in prior work. The proposed design is evaluated with both FPGA and ASIC flow in 28/32nm technology. The experimental results show that the proposed memory achieves almost 4X improvement in throughput while consuming 46 % less area with the FPGA implementations compared to prior work. For ASIC implementations, it achieves more than 60 % area reduction and at least 2X performance improvement while burning 60 % less power compared to other register-based designs implemented with the same flow. As an example, a proposed 8X8 transpose memory with 12-bit input/output resolution is able to achieve a throughput of 107.83Gbps at 647MHz by taking only 140 slices on a Virtex-7 Xilinx FPGA platform, and achieve a throughput of 88.2Gbps at 529MHz by taking 0.024mm 2 silicon area for ASIC. The proposed transpose memory is integrated in both 2D-DCT and 2D-IDCT blocks for signal processing applications on the same FPGA platform. The new architecture allows a 3.5X speed-up in performance for the 2D-DCT algorithm, compared to the previous work, while consuming 28 % less area, and 2D-IDCT achieves a 3X speed-up while consuming 20 % less area.
























Similar content being viewed by others

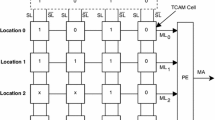

References
Ahmed, N, Natarajan, T, & Kamisetty, RR (1974). Discrete cosine transform. IEEE transactions on Computers, 100(1), 90–93.
Lay, DC (2005). Linear algebra and its applications.
Golub, GH, & Van Loan, CF. (2012). Matrix computations Vol. 3: JHU Press.
Dennis, G.R., Hope, J.J., & Johnsson, M.T. (2013). Xmds2: Fast, scalable simulation of coupled stochastic partial differential equations. Computer Physics Communications, 184(1), 201–208.
Boggs, P.T., & Tolle, J.W. (1995). Sequential quadratic programming.
Jain, R., & Panda, P.R. (2007). Memory architecture exploration for power-efficient 2d-discrete wavelet transform. In 20th International Conference on VLSI Design held jointly with 6th International Conference on Embedded Systems (VLSID’07) (pp. 813–818). IEEE.
Ma, Y (1999). An effective memory addressing scheme for fft processors. IEEE Transactions on Signal Processing, 47(3), 907–911.
Zhang, X, & Parhi, K.K. (2002). Implementation approaches for the advanced encryption standard algorithm. Circuits and Systems Magazine, IEEE, 2(4), 24–46.
Shang, Q., Fan, Y., Shen, W., Shen, S., & Zeng, X. (2014). Single-port SRAM-based transpose memory with diagonal data mapping for large size 2-D DCT/IDCT. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 22(11), 2422–2426.
Ahmed, A., Shahid, M.U., & et al. (2012). N point DCT VLSI architecture for emerging HEVC standard. VLSI Design, 2012, 6.
Madisetti, A, & Willson Jr, A.N. (1995). A 100 mhz 2-d 8 × 8 DCT/IDCT processor for HDTV applications. IEEE Transactions on Circuits and Systems for Video Technology, 5(2), 158–165.
Ruiz, GA, & Michell, JA (1998). Memory efficient programmable processor chip for inverse haar transform. IEEE transactions on signal processing, 46(1), 263–268.
Li, Y, He, Y, & Mei, S (2008). A highly parallel joint VLSI architecture for transforms in H.264/AVC. Signal Processing Systems, 50(1), 19–32.
Burg, A, Coskun, A, Guthaus, M, Katkoori, S, & Reis, R. VLSI-SoC: from algorithms to circuits and system-on-chip design.
Bruguera, J.D., & Osorio, R.R. (2006). A unified architecture for h.264 multiple block-size dct with fast and low cost quantization. In 9th EUROMICRO conference on digital system design: Architectures, methods and tools, 2006. DSD 2006 (pp. 407–414).
El-Hadedy, ME, Madian, AH, Saleh, HI, Ashour, MA, & Aboelsaud, MA (2007). Hardware implementation of the encoder modified mid-band exchange coefficient technique (mmbec) based on fpga. In 2007 internatonal conference on microelectronics (pp. 43–46). IEEE.
El-Hadedy, M, Purohit, S, Margala, M, & Knapskog, SJ (2010). Performance and area efficient transpose memory architecture for high throughput adaptive signal processing systems. In NASA/ESA conference on adaptive hardware and systems (AHS) (pp. 113–120). IEEE.
Tikekar, M, Huang, C-T, Juvekar, C, Sze, V, & Chandrakasan, AP (2014). A 249-mpixel/s HEVC video-decoder chip for 4k ultra-HD applications. IEEE Journal of Solid-State Circuits, 49(1), 61–72.
Heming, S U N, Dajiang, Z, & Peilinm, L (2014). A low-cost VLSI architecture of multiple-size IDCT for H. 265/HEVC. IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, 97(12), 2467–2476.
Guo, J-I, Ju, R-C, & Chen, J-W (2004). An efficient 2-D DCT/IDCT core design using cyclic convolution and adder-based realization. IEEE Transactions on Circuits and Systems for Video Technology, 14(4), 416–428.
Hsiao, S-F, Hu, YH, Juang, T-B, & Lee, C-H (2005). Efficient VLSI implementations of fast multiplier-less approximated DCT using parameterized hardware modules for silicon intellectual property design. IEEE Transactions on Circuits and Systems I: Regular Papers, 52(8), 1568–1579.
Wang, W, Bo, D, Zhang, C, Zhang, P, & Sun, N (2010). Accelerating 2d FFT with non-power-of-two problem size on FPGA. In 2010 International Conference on Reconfigurable Computing and FPGAs (ReConFig) (pp. 208–213).
Dillon, T (2004). An efficient architecture for ultra long FFTs in FPGAs and ASICs. Technical report DTIC Document.
Baozhao, T, Li, D, & Han, C (2004). Two-dimensional image processing without transpose. In Proceedings. ICSP,04. 2004 7th International Conference on Signal Processing, 2004 (pp. 523–526). IEEE.
Langemeyer, S, Pirsch, P, & Blume, H (2011). Using SDRAMs for two-dimensional accesses of long 2 n × 2 m-point FFTs and transposing. In 2011 International Conference on Embedded Computer Systems (SAMOS) (pp. 242–248). IEEE.
Shen, S, Shen, W, Fan, Y, & Zeng, X (2012). A unified 4/8/16/32-point integer IDCT architecture for multiple video coding standards. In 2012 IEEE International Conference on Multimedia and Expo (ICME) (pp. 788–793). IEEE.
Zhu, J, Liu, Z, & Wang, D (2013). Fully pipelined DCT/IDCT/Hadamard unified transform architecture for HEVC codec. In 2013 IEEE International Symposium on Circuits and Systems (ISCAS) (pp. 677–680). IEEE.
Agostini, LV, Silva, IS, & Bampi, S (2001). Pipelined fast 2d dct architecture for jpeg image compression. In 2001, 14th Symposium on Integrated Circuits and Systems Design (pp. 226–231). IEEE.
Kovac, M, & Ranganathan, N (1995). Jaguar: A fully pipelined vlsi architecture for jpeg image compression standard. Proceedings of the IEEE, 83(2), 247–258.
Choi, JR, Hur, WJ, Lee, KK, & Kim, AS (1997). A 400 mpixel/s IDCT for hdtv by multibit coding and group symmetry. In Solid-State Circuits Conference, 1997. Digest of Technical Papers. 43rd ISSCC., 1997 IEEE International (pp. 262–263). IEEE.
Wang, T-C, Huang, Y-W, Fang, H-C, & Chen, L-G (2003). Parallel 4 × 4 2d transform and inverse transform architecture for MPEG-4 AVC/H. 264. In Proceedings of the 2003 International Symposium on Circuits and Systems, 2003. ISCAS,03, (Vol. 2 pp. II–800). IEEE.
Chen, Y-H, & Liu, C-Y (2015). Area-efficient video transform for HEVC applications. Electronics Letters, 51(14), 1065–1067.
Swamy, R, Khorasani, M, Liu, Y, Elliott, D, & Bates S (2005). A fast, pipelined implementation of a two-dimensional inverse discrete cosine transform. In Canadian conference on electrical and computer engineering, 2005 (pp. 665–668).
Tumeo, A, Monchiero, M, Palermo, G, Ferrandi, F, & Sciuto, D (2007). A pipelined fast 2D-DCT accelerator for FPGA-based SoCs. In IEEE Computer Society Annual Symposium on VLSI, ISVLSI,07 (pp. 331–336). IEEE.
Sun, H, Zhou, D, Zhu, J, Kimura, S, & Goto, S (2014). An area-efficient 4/8/16/32-point inverse DCT architecture for UHDTV HEVC decoder. In Visual Communications and Image Processing Conference, 2014 IEEE (pp. 197–200). IEEE.
Park, J-S, Nam, W-J, Han, S-M, & Lee, S-S (2012). 2-D large inverse transform (16 × 16, 32 × 32) for HEVC (high efficiency video coding). JSTS. Journal of Semiconductor Technology and Science, 12(2), 203–211.
Chiang, P-T, & Chang, TS (2013). A reconfigurable inverse transform architecture design for HEVC decoder. In IEEE international symposium on circuits and systems (ISCAS) (p. 2013). IEEE.
Kalali, E, Ozcan, E, Yalcinkaya, O, & Hamzaoglu, I (2014). A low energy HEVC inverse transform hardware. IEEE Transactions on Consumer Electronics, 60(4), 754–761.
Huang, J, Parris, M, Lee, J, & Demara, RF (2009). Scalable FPGA-based architecture for DCT computation using dynamic partial reconfiguration. ACM Transactions on Embedded Computing Systems (TECS), 9(1), 9.
Huang, J, & Lee, J (2009). A self-reconfigurable platform for scalable DCT computation using compressed partial bitstreams and BlockRAM prefetching. IEEE Transactions on Circuits and Systems for Video Technology, 19 (11), 1623–1632.
Masaki, T, Morimoto, Y, Onoye, T, & Shirakawa, I (1995). VLSI implementation of inverse discrete cosine transformer and motion compensator for MPEG2 HDTV video decoding. IEEE Transactions on Circuits and Systems for Video Technology, 5(5), 387–395.
Lee, K-B, Hsu, H-C, & Jen, C-W (2004). A cost-effective MPEG-4 shape-adaptive DCT with auto-aligned transpose memory organization. In Proceedings of the 2004 International Symposium on Circuits and Systems, 2004. ISCAS,04, (Vol. 2 pp. II–777). IEEE.
Kinane, A, Muresan, V, & O’Connor, N (2005). An optimal adder-based hardware architecture for the DCT/SA-DCT. In Visual Communications and Image Processing 2005 (pp. 596045–596045). International Society for Optics and Photonics.
Rithe, R, Cheng, C-C, & Chandrakasan, AP (2012). Quad full-hd transform engine for dual-standard low-power video coding. IEEE Journal of Solid-State Circuits, 47(11), 2724–2736.
User Guide. 7 Series FPGAs configurable logic block. Xilinx, San Jose, CA, 1.7 edition, 11 2014.
Synopsys. 32/28nm generic library for teaching ic design.
Kodavalla, VK (2007). Ip gate count estimation methodology during micro-architecture phase. IP based Electronic System.
Bojnordi, MN, Sedaghati-Mokhtari, N, Fatemi, O, & Hashemi, MR (2006). An efficient self-transposing memory structure for 32-bit video processors. In IEEE Asia Pacific Conference on Circuits and Systems, 2006. APCCAS (pp. 1438–1441). IEEE.
Bukhari, K, Kuzmanov, G, & Vassiliadis, S (2002). DCT and IDCT implementations on different FPGA technologies. In Proceedings of ProRISC 2002 (pp. 232–235).
Ponomarenko, N, Egiazarian, K, Lukin, V, & Astola, J (2005). Additional lossless compression of jpeg images. In ISPA 2005, Proceedings of the 4th international symposium on image and signal processing and analysis, 2005 (pp. 117–120). IEEE.
Wikipedia. Discrete cosine transform, 2015. [Online; accessed 20 December 2015].
Sullivan, JG, & Baker, RL (1994). Efficient quadtree coding of images and video. IEEE Transactions on Image Processing, 3(3), 327–331.
Tumeo, A, Monchiero, M, Palermo, G, Ferrandi, F, & Sciuto, D (2007). A pipelined fast 2D-DCT accelerator for FPGA-based SoCs. In Proceedings of the IEEE Computer Society Annual Symposium on VLSI, ISVLSI ’07 (pp. 331–336). Washington: IEEE Computer Society.
Kusuma, ED, & Widodo, TS (2010). Fpga implementation of pipelined 2d-dct and quantization architecture for jpeg image compression. In 2010 International symposium on information technology, (Vol. 1 pp. 1–6). IEEE.
Kitsos, P, Voros, NS, Dagiuklas, T, & Skodras, AN (2013). A high speed fpga implementation of the 2d dct for ultra high definition video coding. In 2013 18th international conference on digital signal processing (DSP) (pp. 1–5). IEEE.
Acknowledgments
This work was supported in part by NSF grant no. CDI-1124931 and by the Center for Future Architectures Research (C-FAR), one of six centers of STARnet, a Semiconductor Research Corporation program sponsored by MARCO and DARPA.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
El-Hadedy, M., Guo, X., Margala, M. et al. Dual-Data Rate Transpose-Memory Architecture Improves the Performance, Power and Area of Signal-Processing Systems. J Sign Process Syst 88, 167–184 (2017). https://doi.org/10.1007/s11265-016-1199-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11265-016-1199-1