
Abstract
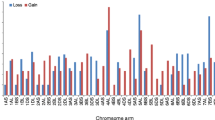
Complex Triticeae genomes pose a challenge to genome sequencing efforts due to their size and repetitive nature. Genome sequencing can reveal details of conservation and rearrangements between related genomes. We have applied Illumina second generation sequencing technology to sequence and assemble the low copy and unique regions of Triticum aestivum chromosome arm 7BS, followed by the construction of a syntenic build based on gene order in Brachypodium. We have delimited the position of a previously reported translocation between 7BS and 4AL with a resolution of one or a few genes and report approximately 13% genes from 7BS having been translocated to 4AL. An additional 13 genes are found on 7BS which appear to have originated from 4AL. The gene content of the 7DS and 7BS syntenic builds indicate a total of ~77,000 genes in wheat. Within wheat syntenic regions, 7BS and 7DS share 740 genes and a common gene conservation rate of ~39% of the genes from the corresponding regions in Brachypodium, as well as a common rate of colinearity with Brachypodium of ~60%. Comparison of wheat homoeologues revealed ~84% of genes previously identified in 7DS have a homoeologue on 7BS or 4AL. The conservation rates we have identified among wheat homoeologues and with Brachypodium provide a benchmark of homoeologous gene conservation levels for future comparative genomic analysis. The syntenic build of 7BS is publicly available at http://www.wheatgenome.info.




Similar content being viewed by others

References
Akhunov ED, Goodyear AW, Geng S, Qi LL, Echalier B, Gill BS, Miftahudin, Gustafson JP, Lazo G, Chao S, Anderson OD, Linkiewicz AM, Dubcovsky J, La Rota M, Sorrells ME, Zhang D, Nguyen HT, Kalavacharla V, Hossain K, Kianian SF, Peng J, Lapitan NL, Gonzalez-Hernandez JL, Anderson JA, Choi DW, Close TJ, Dilbirligi M, Gill KS, Walker-Simmons MK, Steber C, McGuire PE, Qualset CO, Dvorak J (2003) The organization and rate of evolution of wheat genomes are correlated with recombination rates along chromosome arms. Genome Res 13(5):753–763. doi:10.1101/gr.808603GR-8086R
Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ (1990) Basic local alignment search tool. J Mol Biol 215(3):403–410. doi:10.1006/jmbi.1990.9999S0022283680799990
Bennetzen JL, Coleman C, Liu R, Ma J, Ramakrishna W (2004) Consistent over-estimation of gene number in complex plant genomes. Curr Opin Plant Biol 7(6):732–736. doi:10.1016/j.pbi.2004.09.003
Berkman PJ, Skarshewski A, Lorenc M, Lai K, Duran C, Ling EYS, Stiller J, Smits L, Imelfort M, Manoli S, McKenzie M, Kubaláková M, Šimková H, Batley J, Fleury D, Doležel J, Edwards D (2011) Sequencing and assembly of low copy and genic regions of isolated Triticum aestivum chromosome arm 7DS. Plant Biotechnol J. 9(7):768–775. doi:10.1111/j.1467-7652.2010.00587.x
Buell CR, Last RL (2010) Twenty-First century plant biology: impacts of the Arabidopsis genome on plant biology and agriculture. Plant Physiol 154(2):497–500. doi:10.1104/pp.110.159541
Carollo V, Matthews DE, Lazo GR, Blake TK, Hummel DD, Lui N, Hane DL, Anderson OD (2005) GrainGenes 2.0: an improved resource for the small-grains community. Plant Physiol 139(2):643–651. doi:10.1104/pp.105.064485
Chantret N, Salse J, Sabot F, Rahman S, Bellec A, Laubin B, Dubois I, Dossat C, Sourdille P, Joudrier P, Gautier MF, Cattolico L, Beckert M, Aubourg S, Weissenbach J, Caboche M, Bernard M, Leroy P, Chalhoub B (2005) Molecular basis of evolutionary events that shaped the hardness locus in diploid and polyploid wheat species (Triticum and Aegilops). Plant Cell 17(4):1033–1045. doi:10.1105/tpc.104.029181
Choulet F, Wicker T, Rustenholz C, Paux E, Salse J, Leroy P, Schlub S, Le Paslier MC, Magdelenat G, Gonthier C, Couloux A, Budak H, Breen J, Pumphrey M, Liu S, Kong X, Jia J, Gut M, Brunel D, Anderson JA, Gill BS, Appels R, Keller B, Feuillet C (2010) Megabase level sequencing reveals contrasted organization and evolution patterns of the wheat gene and transposable element spaces. Plant Cell 22(6):1686–1701
Conley EJ, Nduati V, Gonzalez-Hernandez JL, Mesfin A, Trudeau-Spanjers M, Chao S, Lazo GR, Hummel DD, Anderson OD, Qi LL, Gill BS, Echalier B, Linkiewicz AM, Dubcovsky J, Akhunov ED, Dvorak J, Peng JH, Lapitan NLV, Pathan MS, Nguyen HT, Ma X-F, Miftahudin, Gustafson JP, Greene RA, Sorrells ME, Hossain KG, Kalavacharla V, Kianian SF, Sidhu D, Dilbirligi M, Gill KS, Choi DW, Fenton RD, Close TJ, McGuire PE, Qualset CO, Anderson JA (2004) A 2600-Locus Chromosome Bin Map of Wheat Homoeologous Group 2 reveals interstitial gene-rich islands and colinearity with rice. Genetics 168(2):625–637. doi:10.1534/genetics.104.034801
Devos KM, Millan T, Gale MD (1993) Comparative RFLP maps of the homoeologous group-2 chromosomes of wheat, rye and barley. Theor and Appl Genet 85(6):784–792. doi:10.1007/bf00225020
Devos KM, Dubcovsky J, Dvorak J, Chinoy CN, Gale MD (1995) Structural Evolution of wheat chromosomes 4a, 5a, and 7b and its impact on recombination. Theor Appl Genet 91(2):282–288
Devos KM, Costa de Oliveira A, Xu X, Estill JC, Estep M, Jogi A, Morales M, Pinheiro J, San Miguel P, Bennetzen JL (2008) Structure and organization of the wheat genome—the number of genes in the hexaploid wheat genome. Paper presented at the 11th International Wheat Genetics Symposium, Brisbane, Australia, 24–29
Doležel J, Kubaláková M, Bartoš J, Macas J (2004) Flow cytogenetics and plant genome mapping. Chromosome Res 12(1):77–91
Duran C, Eales D, Marshall D, Imelfort M, Stiller J, Berkman PJ, Clark T, McKenzie M, Appleby N, Batley J, Basford K, Edwards D (2010) Future tools for association mapping in crop plants. Genome 53(11):1017–1023. doi:10.1139/g10-057
Eckardt NA (2001) A sense of self: the role of DNA sequence elimination in allopolyploidization. Plant Cell 13(8):1699–1704
Edwards D, Batley J (2010) Plant genome sequencing: applications for crop improvement. Plant Biotechnol J 8(1):2–9. doi:10.1111/j.1467-7652.2009.00459.x
Flavell RB, Rimpau J, Smith DB (1977) Repeated sequence DNA relationships in 4 cereal genomes. Chromosoma 63(3):205–222
Hernandez P, Martis M, Dorado G, Pfeifer M, Gálvez S, Schaaf S, Jouve N, Simková H, Valárik M, Doležel J, Mayer KF (2011) Next generation sequencing and syntenic integration of flow-sorted arms of wheat chromosome 4A exposes the chromosome structure and gene content. Plant J. doi:10.1111/j.1365-313X.2011.04808.x (accepted)
Hossain KG, Kalavacharla V, Lazo GR, Hegstad J, Wentz MJ, Kianian PM, Simons K, Gehlhar S, Rust JL, Syamala RR, Obeori K, Bhamidimarri S, Karunadharma P, Chao S, Anderson OD, Qi LL, Echalier B, Gill BS, Linkiewicz AM, Ratnasiri A, Dubcovsky J, Akhunov ED, Dvorak J, Miftahudin, Ross K, Gustafson JP, Radhawa HS, Dilbirligi M, Gill KS, Peng JH, Lapitan NL, Greene RA, Bermudez-Kandianis CE, Sorrells ME, Feril O, Pathan MS, Nguyen HT, Gonzalez-Hernandez JL, Conley EJ, Anderson JA, Choi DW, Fenton D, Close TJ, McGuire PE, Qualset CO, Kianian SF (2004) A chromosome bin map of 2148 expressed sequence tag loci of wheat homoeologous group 7. Genetics 168(2):687–699. doi:10.1534/genetics.104.034850
Huang S, Sirikhachornkit A, Su X, Faris J, Gill B, Haselkorn R, Gornicki P (2002) Genes encoding plastid acetyl-CoA carboxylase and 3-phosphoglycerate kinase of the Triticum/Aegilops complex and the evolutionary history of polyploid wheat. Proc Natl Acad Sci USA 99(12):8133–8138. doi:10.1073/pnas.072223799
Imelfort M, Edwards D (2009) De novo sequencing of plant genomes using second-generation technologies. Brief Bioinform 10(6):609–618. doi:10.1093/bib/bbp039
Karlin S, Altschul SF (1993) Applications and statistics for multiple high-scoring segments in molecular sequences. Proceedings of the National Academy of Sci 90(12):5873–5877
Lander ES, Waterman MS (1988) Genomic mapping by fingerprinting random clones: a mathematical analysis. Genomics 2(3):231–239. doi:10.1016/0888-7543(88)90007-9. http://www.sciencedirect.com/science/article/pii/0888754388900079
Margulies M, Egholm M, Altman WE, Attiya S, Bader JS, Bemben LA, Berka J, Braverman MS, Chen YJ, Chen Z, Dewell SB, Du L, Fierro JM, Gomes XV, Godwin BC, He W, Helgesen S, Ho CH, Irzyk GP, Jando SC, Alenquer ML, Jarvie TP, Jirage KB, Kim JB, Knight JR, Lanza JR, Leamon JH, Lefkowitz SM, Lei M, Li J, Lohman KL, Lu H, Makhijani VB, McDade KE, McKenna MP, Myers EW, Nickerson E, Nobile JR, Plant R, Puc BP, Ronan MT, Roth GT, Sarkis GJ, Simons JF, Simpson JW, Srinivasan M, Tartaro KR, Tomasz A, Vogt KA, Volkmer GA, Wang SH, Wang Y, Weiner MP, Yu P, Begley RF, Rothberg JM (2005) Genome sequencing in microfabricated high-density picolitre reactors. Nature 437(7057):376–380. doi:10.1038/nature03959
Marshall DJ, Hayward A, Eales D, Imelfort M, Stiller J, Berkman PJ, Clark T, McKenzie M, Lai K, Duran C, Batley J, Edwards D (2010) Targeted identification of genomic regions using TAGdb. Plant Methods 6:19. doi:10.1186/1746-4811-6-19
Massa AN, Wanjugi H, Deal KR, O’Brien K, You FM, Maiti R, Chan AP, Gu YQ, Luo MC, Anderson OD, Rabinowicz PD, Dvorak J, Devos KM (2011) Gene space dynamics during the evolution of Aegilops tauschii, Brachypodium distachyon, Oryza sativa, and Sorghum bicolor Genomes. Mol Biol Evol 28(9):2537–2547
Matthews DE, Carollo VL, Lazo GR, Anderson OD (2003) GrainGenes, the genome database for small-grain crops. Nucleic Acids Res 31(1):183–186
Mayer KF, Taudien S, Martis M, Šimková H, Suchánková P, Gundlach H, Wicker T, Petzold A, Felder M, Steuernagel B, Scholz U, Graner A, Platzer M, Doležel J, Stein N (2009) Gene content and virtual gene order of barley chromosome 1H. Plant Physiol. doi:10.1104/pp.109.142612
Naranjo T, Roca A, Goicoechea PG, Giraldez R (1987) Arm homoeology of wheat and rye chromosomes. Genome 29(6):873–882. doi:10.1139/g87-149
Paux E, Roger D, Badaeva E, Gay G, Bernard M, Sourdille P, Feuillet C (2006) Characterizing the composition and evolution of homoeologous genomes in hexaploid wheat through BAC-end sequencing on chromosome 3B. Plant J 48(3):463–474. doi:10.1111/j.1365-313X.2006.02891.x
Pop M (2009) Genome assembly reborn: recent computational challenges. Brief Bioinform 10(4):354–366. doi:10.1093/bib/bbp026
Qi LL, Echalier B, Chao S, Lazo GR, Butler GE, Anderson OD, Akhunov ED, Dvorak J, Linkiewicz AM, Ratnasiri A, Dubcovsky J, Bermudez-Kandianis CE, Greene RA, Kantety R, La Rota CM, Munkvold JD, Sorrells SF, Sorrells ME, Dilbirligi M, Sidhu D, Erayman M, Randhawa HS, Sandhu D, Bondareva SN, Gill KS, Mahmoud AA, Ma X-F, Miftahudin, Gustafson JP, Conley EJ, Nduati V, Gonzalez-Hernandez JL, Anderson JA, Peng JH, Lapitan NLV, Hossain KG, Kalavacharla V, Kianian SF, Pathan MS, Zhang DS, Nguyen HT, Choi D-W, Fenton RD, Close TJ, McGuire PE, Qualset CO, Gill BS (2004) A chromosome bin map of 16, 000 expressed sequence tag loci and distribution of genes among the three genomes of polyploid wheat. Genetics 168(2):701–712. doi:10.1534/genetics.104.034868
Rabinowicz PD, Citek R, Budiman MA, Nunberg A, Bedell JA, Lakey N, O’Shaughnessy AL, Nascimento LU, McCombie WR, Martienssen RA (2005) Differential methylation of genes and repeats in land plants. Genome Res 15(10):1431–1440. doi:10.1101/gr.4100405
Šafář J, Šimková H, Kubaláková M, Číhalíková J, Suchánková P, Bartoš J, Doležel J (2010) Development of chromosome-specific BAC resources for genomics of bread wheat. Cytogenet Genome Res 129(1–3):211–223. doi:10.1159/000313072
Šimková H, Svensson JT, Condamine P, Hřibová E, Suchánková P, Bhat PR, Bartoš J, Šafář J, Close TJ, Doležel J (2008) Coupling amplified DNA from flow-sorted chromosomes to high-density SNP mapping in barley. BMC Genomics 9:294. doi:10.1186/1471-2164-9-294
Vogel JP, Garvin DF, Mockler TC, Schmutz J, Rokhsar D, Bevan MW, Barry K, Lucas S, Harmon-Smith M, Lail K, Tice H, Schmutz Leader J, Grimwood J, McKenzie N, Huo N, Gu YQ, Lazo GR, Anderson OD, Vogel Leader JP, You FM, Luo MC, Dvorak J, Wright J, Febrer M, Idziak D, Hasterok R, Lindquist E, Wang M, Fox SE, Priest HD, Filichkin SA, Givan SA, Bryant DW, Chang JH, Mockler Leader TC, Wu H, Wu W, Hsia AP, Schnable PS, Kalyanaraman A, Barbazuk B, Michael TP, Hazen SP, Bragg JN, Laudencia-Chingcuanco D, Weng Y, Haberer G, Spannagl M, Mayer Leader K, Rattei T, Mitros T, Lee SJ, Rose JK, Mueller LA, York TL, Wicker Leader T, Buchmann JP, Tanskanen J, Schulman Leader AH, Gundlach H, Bevan M, Costa de Oliveira A, da CML, Belknap W, Jiang N, Lai J, Zhu L, Ma J, Sun C, Pritham E, Salse Leader J, Murat F, Abrouk M, Mayer K, Bruggmann R, Messing J, Fahlgren N, Sullivan CM, Carrington JC, Chapman EJ, May GD, Zhai J, Ganssmann M, Guna Ranjan Gurazada S, German M, Meyers BC, Green Leader PJ, Tyler L, Wu J, Thomson J, Chen S, Scheller HV, Harholt J, Ulvskov P, Kimbrel JA, Bartley LE, Cao P, Jung KH, Sharma MK, Vega-Sanchez M, Ronald P, Dardick CD, De Bodt S, Verelst W, Inze D, Heese M, Schnittger A, Yang X, Kalluri UC, Tuskan GA, Hua Z, Vierstra RD, Cui Y, Ouyang S, Sun Q, Liu Z, Yilmaz A, Grotewold E, Sibout R, Hematy K, Mouille G, Hofte H, Michael T, Pelloux J, O’Connor D, Schnable J, Rowe S, Harmon F, Cass CL, Sedbrook JC, Byrne ME, Walsh S, Higgins J, Li P, Brutnell T, Unver T, Budak H, Belcram H, Charles M, Chalhoub B, Baxter I (2010) Genome sequencing and analysis of the model grass Brachypodium distachyon. Nature 463(7282):763–768. doi:10.1038/nature08747
Vrána J, Kubaláková M, Šimková H, Číhalíková J, Lysák MA, Doležel J (2000) Flow sorting of mitotic chromosomes in common wheat (Triticum aestivum L.). Genetics 156(4):2033–2041
Wanjugi H, Coleman-Derr D, Huo N, Kianian SF, Luo M-C, Wu J, Anderson O, Gu YQ (2009) Rapid development of PCR-based genome-specific repetitive DNA junction markers in wheat. Genome 52(6):576–587
Wicker T, Buchmann JP, Keller B (2010) Patching gaps in plant genomes results in gene movement and erosion of colinearity. Genome Res. doi:10.1101/gr.107284.110
Zerbino DR, Birney E (2008) Velvet: algorithms for de novo short read assembly using de Bruijn graphs. Genome Res 18(5):821–829. doi:10.1101/gr.074492.107
Zhang Z, Schwartz S, Wagner L, Miller W (2000) A greedy algorithm for aligning DNA sequences. J Comput Biol 7(1–2):203–214. doi:10.1089/10665270050081478
Acknowledgments
The authors would like to acknowledge funding support from the Australian Research Council (Projects LP0882095, LP0883462 and DP0985953), the Czech Republic Ministry of Education, Youth and Sports (grant no. LC06004), the European Regional Development Fund (Operational Programme Research and Development for Innovations No. CZ.1.05/2.1.00/01.0007) and the Spanish Ministry of Science and Innovation (MICINN grants BIO2009-07443 and AGL2010-17316). We thank Dr. Jarmila Číhalíková, Romana Nováková, Bc. and Ms. Zdeňka Dubská for their assistance with chromosome sorting. Support from the Australian Genome Research Facility (AGRF), the Queensland Cyber Infrastructure Foundation (QCIF), the Australian Partnership for Advanced Computing (APAC) and Queensland Facility for Advanced Bioinformatics (QFAB) is gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by T. Close.
Rights and permissions
About this article
Cite this article
Berkman, P.J., Skarshewski, A., Manoli, S. et al. Sequencing wheat chromosome arm 7BS delimits the 7BS/4AL translocation and reveals homoeologous gene conservation. Theor Appl Genet 124, 423–432 (2012). https://doi.org/10.1007/s00122-011-1717-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00122-011-1717-2