Collection
Special Issue: Seismomatics: Space-Time Analysis of Natural or Anthropogenic Catastrophes
Seismomatics is the fusion of mathematics, statistics, physics and data mining at the service of those scientific disciplines interested in the space–time analysis of natural or anthropogenic catastrophes. This special issue on seismomatics has been motivated by a conference of the same name, which took place in Valparaiso (Chile) from 5th to 9th of January 2015. The selection of papers comprises both new methodological proposals and a wide range of applications related to natural or anthropogenic catastrophes. We highlight statistical analysis of marine macroalgae, of annual minimum water levels of the Nile River, of massive data on chlorophyll, of temperature maxima recorded over a complex topography, and of airborne pollutants in relation to the spatial spread of human population across Europe.
The first conference on Seismomatics was held in January 2015 at the University Federico Santa Maria in Valparaiso (Chile), and was organised by E. Porcu, R. Vallejos (Department of Mathematics) and P. Catalan (Department of Civil Industry).
The main idea behind Seismomatics is to have a fusion of mathematics, statistics, physics and data mining at the service of those disciplines interested in the space–time analysis of natural or anthropogenic catastrophes. The fusion of mathematics with statistics implies that seismomatics works under the paradigm of space–time uncertainty.
The purpose of the first international conference on seismomatics was to merge contributions to the analysis and prediction of catastrophes, coming from fields as diverse as statistics, mathematics (in particular, PDE and numerical analysis), data mining and physics. All these fields have been very active, in the last 50 years, in the context of seismic data, ocean currents modelling, air pollution and many other branches of application, such as, for instance, tornadoes and air and water pollution.
Special attention has been paid to those phenomena that are of interest to the Chilean community, that is earthquakes, tsunamis, problems related to eco-balance in the Pacific Ocean, air pollution, climate change, floods, among others. The resulting papers are in two parallel special issues, one in Stochastic Environmental and Risk Assessment which is more devoted to earthquakes, and the one here focused on other natural phenomena.
As noted by Cobb and Watson (1980), statistical analysis of catastrophes seems a paradoxical term, because statistical models do not, as a rule, contain degenerate singularities, and catastrophe theory is generally perceived as a purely deterministic branch of differential topology. However, we do agree with the authors that a stochastic approach can well contribute to a better knowledge of catastrophic events. In particular, Cobb and Watson (1980) advocate the use of stochastic differential equations which should be built on the basis of certain physical laws (Christakos 1992; Christakos and Hristopoulos 1998 ). We instead advocate approaches based on random fields in order to build models for understanding catastrophic events defined over some spatial domain and evolving over time. This includes point process theory (Daley and Vere Jones 2002; Møller and Waagepetersen 2005) and geostatistics (Cressie 1993; Chilés and Delfiner 1999) among other approaches.
Thus, recent advances in this direction are related to the introduction of a stochastic approach into the mathematics of natural and anthropogenic catastrophes. The challenging book by Gordon Woo (1999) contains a memorable collection of potential mathematical and probabilistic approaches to several types of catastrophes, which certainly includes extreme values theory, albeit analysed under only the perspective of time series (not including space).
Forecasting catastrophes is a critical task and the word forecast needs to be interpreted with caution. Arguably it does not make much sense to talk about forecasts in the strict sense for earthquakes, as noted by Geller et al. (1997): citing recent results from the physics of non-linear systems “chaos theory”, they show that any small earthquake has some probability of developing into a large event, and this fact depends on unknown and unmeasurable details related to the conditions of the Earth’s interior. The case of tsunamis is different as they have a strict causal relationship with the occurrence of big seismic events.
Other catastrophes exhibit instead a more regular behaviour, and this is the case for airborne pollution (see the contribution by Fassò et al. 2016) or in the case of extreme temperatures observed over a complex topography (see Huser and Genton 2016). For those phenomena which are basically unpredictable, it might be more sensible to focus on warning mechanisms rather than having the obsession of prediction, as argued by Patricio Catalán (personal communication). In this sense, stochastic approaches can be certainly helpful in integrating the deterministic expert systems. This direction is also advocated by Woo (1999) on the basis of subjective probabilities.
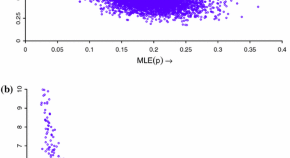
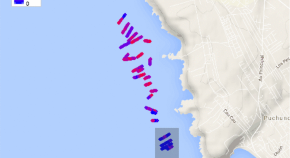
Acosta et al. (2016) provide a framework for estimating the effective sample size in a spatial regression model context when the data have been sampled using a line transect scheme, and there is an evident serial correlation due to the chronological order in which the observations were collected. The authors propose a recursive algorithm to separately estimate the linear and non-linear parameters involved in the covariance structure. The kriging equations are also presented. An application in the context of marine macroalgae, which is ultimately related to ocean-related catastrophes, is also presented.
Self-similar processes have been widely used in modelling real-world phenomena occurring in environmetrics, network traffic, image processing and stock pricing, to name but a few. The estimation of the degree of self-similarity has been studied extensively, while statistical tests for self-similarity are scarce and limited to processes indexed in one dimension. Lee et al. (2016) propose a statistical hypothesis test procedure for self-similarity of a stochastic process indexed in one dimension, and multi-self-similarity for a random field indexed in higher dimensions. If self-similarity is not rejected, their test provides a set of estimated self-similarity indexes. The key is to test stationarity of the inverse Lamperti transformations of the process. The inverse Lamperti transformation of a self-similar process is a strongly stationary process, revealing a theoretical connection between the two processes. The authors apply the self-similarity test to real data of annual minimum water levels of the Nile River, to network traffic records and to surface heights of food wrappings.
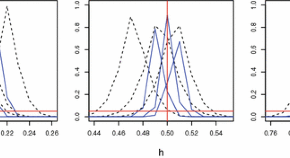
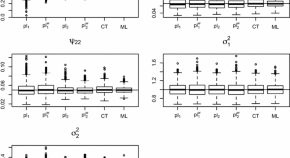
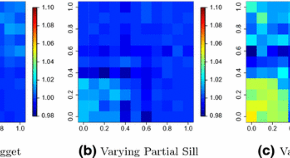
In the recent years, there has been a growing interest in proposing covariance models for multivariate Gaussian random fields. Some of these covariance models are very flexible and can capture both the marginal and the cross-spatial dependence of the components of the associated multivariate Gaussian random field. However, effective estimation methods for these models are somehow unexplored. Maximum likelihood is certainly a useful tool but it is impractical in all the circumstances where the number of observations is very large. Bevilacqua et al. (2016) consider two possible approaches based on composite likelihood for multivariate covariance model estimation. Asymptotic properties of the proposed estimators are assessed under increasing domain asymptotics. The authors apply the method for the analysis of a bivariate dataset on chlorophyll.
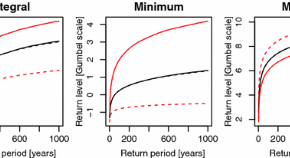
Max-stable processes are natural models for spatial extremes because they provide suitable asymptotic approximations to the distribution of maxima of random fields. In the recent past, several parametric families of stationary max-stable models have been developed, and fitted to various types of data. However, a recurrent problem is the modelling of non-stationarity. Huser and Genton (2016) develop non-stationary max-stable dependence structures in which covariates can be easily incorporated. Inference is performed using pairwise likelihoods, and its performance is assessed by an extensive simulation study based on a non-stationary locally isotropic extremal t-model. The methodology is used to analyse temperature maxima recorded over a complex topography.
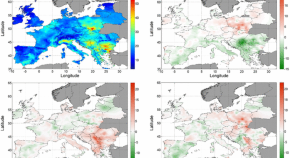
Fassò et al. (2016) seek to estimate the distribution of population by exposure to multiple airborne pollutants, taking into account the spatio-temporal variability of air quality and the spatial spread of human population across Europe. In order to optimise the spatial information content and to allow the computation of daily multi-pollutant exposure distributions across space and time, the authors introduce a multivariate spatio-temporal model which is estimated using the EM algorithm. A novel semi-parametric bootstrap technique is introduced and it is used to assess the exposure distribution uncertainty.
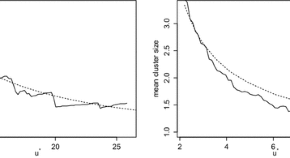
Risk assessment is naturally involved in problems related to natural or anthropogenic catastrophes, which need the fusion of mathematical and statistical methods able to handle space–time uncertainty. These real-life catastrophes are intimately related to the occurrence of extremal events, usually defined by exceedances over critical thresholds. The inherent uncertainty in this context is treated through continuous random field models underlying the phenomenon of interest. Particular (but common) effects of natural catastrophes induce transformations (of the space or the state) that affect in a direct way the definition of extremal events and the associated risk measures. Motivated by these natural phenomena, the definition of different indicators in spatial and spatio-temporal risk analysis depends on the analysis of structural characteristics of random field threshold exceedance sets. Structural characteristics of threshold exceedance sets, intrinsically related to the properties of the underlying random field model, are affected by space and/or state transformations such as deformation and blurring. Structural characteristics of random field threshold exceedance sets (e.g. size, connectivity, boundary regularity) are used in practice for definition of different indicators in spatial and spatio-temporal risk analysis. Angulo et al. (2016) study structural changes in threshold exceedance point patterns derived from random field deformation and blurring transformations. Specifically, based on simulation from a flexible random field model class, features such as aggregation/ inhibition, as well as local anisotropy in the distribution patterns, are investigated in relation to the local contraction/dilation effects of deformation and the smoothing properties of blurring.

Articles (12 in this collection)
-
-

-
European Population Exposure to Airborne Pollutants Based on a Multivariate Spatio-Temporal Model
Authors
-
-
Composite Likelihood Inference for Multivariate Gaussian Random Fields
Authors (first, second and last of 4)
-
-
-
-
-
Effective Sample Size for Line Transect Sampling Models with an Application to Marine Macroalgae
Authors
-
A Varying Coefficients Model For Estimating Finite Population Totals: A Hierarchical Bayesian Approach
Authors (first, second and last of 4)
-