
Abstract
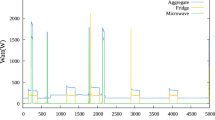
Dimensionality reduction is a machine learning based technique used to convert the data from higher dimensionality space to lower dimensionality space. This technique helps to build lighter version machine learning based predictive models. In this paper, a deep learning model i.e.. autoencoders is used to reduce the dimensionality of active power load data from higher dimensionality space consists 14 input features to lower dimensionality space consists 7 input features. Original active power load data is prepared based on data collected from 33/11KV substation located in Godishala village, Telangana State, India, from 01.01.2021 to 31.12.2021. Autoencoder model is trained and tested with python program using visual studio. From the simulation results, observed that autoencoder model reduces the dimensionality space of load data with almost same variance that original data exist.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Alimoussa M, Porebski A, Vandenbroucke N, El Fkihi S, Oulad Haj Thami R (2022) Compact hybrid multi-color space descriptor using clustering-based feature selection for texture classification. J Imaging 8(8). https://doi.org/10.3390/jimaging8080217. https://www.mdpi.com/2313-433X/8/8/217
Alomari ES, Nuiaa RR, Alyasseri ZAA, Mohammed HJ, Sani NS, Esa MI, Musawi BA (2023) Malware detection using deep learning and correlation-based feature selection. Symmetry 15(1). https://doi.org/10.3390/sym15010123. https://www.mdpi.com/2073-8994/15/1/123
Bacanin N, Stoean C, Zivkovic M, Rakic M, Strulak-Wójcikiewicz R, Stoean R (2023) On the benefits of using metaheuristics in the hyperparameter tuning of deep learning models for energy load forecasting. Energies 16(3). https://doi.org/10.3390/en16031434. https://www.mdpi.com/1996-1073/16/3/1434
Buatoom U, Jamil MU (2023) Improving classification performance with statistically weighted dimensions and dimensionality reduction. Appl Sci 13(3). https://doi.org/10.3390/app13032005. https://www.mdpi.com/2076-3417/13/3/2005
de Castro-Cros M, Velasco M, Angulo C (2023) Analysis of gas turbine compressor performance after a major maintenance operation using an autoencoder architecture. Sensors 23(3). https://doi.org/10.3390/s23031236. https://www.mdpi.com/1424-8220/23/3/1236
Chikkankod AV, Longo L (2022) On the dimensionality and utility of convolutional autoencoder & rsquo;s latent space trained with topology-preserving spectral EEG head-maps. Mach Learn Knowl Extract 4(4):1042–1064
Dessureault JS, Massicotte D (2022) Dpdrc, a novel machine learning method about the decision process for dimensionality reduction before clustering. AI 3(1):1–21. https://doi.org/10.3390/ai3010001. https://www.mdpi.com/2673-2688/3/1/1
Do JS, Kareem AB, Hur JW (2023) Lstm-autoencoder for vibration anomaly detection in vertical carousel storage and retrieval system (vcsrs). Sensors 23(2). https://doi.org/10.3390/s23021009. https://www.mdpi.com/1424-8220/23/2/1009
Fan L (2020) Dimensionality reduction of image feature based on geometric parameter adaptive lle algorithm. J Intell Fuzzy Syst 38(2):1569–1577. https://doi.org/10.3233/JIFS-179520
Ferner C, Wegenkittl S (2022) Benefits from variational regularization in language models. Mach Learn Knowl Extract 4(2):542–555
Fiorini S, Ciavotta M, Maurino A (2022) Listening to the city, attentively: A spatio-temporal attention-boosted autoencoder for the short-term flow prediction problem. Algorithms 15(10). https://doi.org/10.3390/a15100376. https://www.mdpi.com/1999-4893/15/10/376
Gisbrecht A, Hammer B (2015) Data visualization by nonlinear dimensionality reduction. Wiley Interdisc Rev Data Mining Knowl Discov 5(2):51–73. https://doi.org/10.1002/widm.1147
Grimaccia F, Mussetta M, Niccolai A, Veeramsetty V, Chandra DR (2022) Short-term load forecasting in dso substation networks with dimensionality reduction techniques. In: 2022 IEEE international conference on environment and electrical engineering and 2022 IEEE industrial and commercial power systems Europe (EEEIC/I &CPS Europe). IEEE, pp 1–6. https://doi.org/10.1109/EEEIC/ICPSEurope54979.2022.9854749
Huang X, Wu L, Ye Y (2019) A review on dimensionality reduction techniques. Int J Pattern Recogn Artif Intell 33(10):1950017. https://doi.org/10.1142/S0218001419500174
Ibrahim S, Nazir S, Velastin SA (2021) Feature selection using correlation analysis and principal component analysis for accurate breast cancer diagnosis. J Imaging 7(11). https://doi.org/10.3390/jimaging7110225. https://www.mdpi.com/2313-433X/7/11/225
Katsamenis I, Bakalos N, Karolou EE, Doulamis A, Doulamis N (2022) Fall detection using multi-property spatiotemporal autoencoders in maritime environments. Technologies 10(2). https://doi.org/10.3390/technologies10020047. https://www.mdpi.com/2227-7080/10/2/47
Kiarashinejad Y, Abdollahramezani S, Adibi A (2020) Deep learning approach based on dimensionality reduction for designing electromagnetic nanostructures. NPJ Comput Mater 6(1):1–12. https://doi.org/10.1038/s41524-020-0276-y
Kumar V, Minz S (2014) Feature selection: a literature review. SmartCR 4(3):211–229. https://doi.org/10.6029/smartcr.2014.03.007
Lee J, Ryu S, Chung W, Kim S, Kang YJ (2023) Estimates of internal forces in torsionally braced steel i-girder bridges using deep neural networks. Appl Sci 13(3). https://doi.org/10.3390/app13031499. https://www.mdpi.com/2076-3417/13/3/1499
Li D, Tang Z, Kang Q, Zhang X, Li Y (2023) Machine learning-based method for predicting compressive strength of concrete. Processes 11(2). https://doi.org/10.3390/pr11020390. https://www.mdpi.com/2227-9717/11/2/390
Li J, Zhang J, Bah MJ, Wang J, Zhu Y, Yang G, Li L, Zhang K (2022) An auto-encoder with genetic algorithm for high dimensional data: towards accurate and interpretable outlier detection. Algorithms 15(11). https://doi.org/10.3390/a15110429. https://www.mdpi.com/1999-4893/15/11/429
Li X, Zhang L, You J (2019) Locally weighted discriminant analysis for hyperspectral image classification. Remote Sens 11(2):109. https://doi.org/10.3390/rs11020109
Li Y, Yan Y (2023) Training autoencoders using relative entropy constraints. Appl Sci 13(1). https://doi.org/10.3390/app13010287. https://www.mdpi.com/2076-3417/13/1/287
Liang H, Sun X, Sun Y, Gao Y (2017) Text feature extraction based on deep learning: a review. EURASIP J Wireless Commun Netw 2017(1):1–12. https://doi.org/10.1186/s13638-017-0993-1
Ma H, Yang P, Wang F, Wang X, Yang D, Feng B (2023) Short-term heavy overload forecasting of public transformers based on combined lstm-xgboost model. Energies 16(3). https://doi.org/10.3390/en16031507. https://www.mdpi.com/1996-1073/16/3/1507
McClelland JL, Rumelhart DE, Group PR et al (1987) Parallel distributed processing: explorations in the microstructure of cognition: psychological and biological models, vol 2. MIT press. https://doi.org/10.7551/mitpress/5236.001.0001
Nayak SR, Nayak DR, Sinha U, Arora V, Pachori RB (2023) An efficient deep learning method for detection of covid-19 infection using chest x-ray images. Diagnostics 13(1). https://doi.org/10.3390/diagnostics13010131. https://www.mdpi.com/2075-4418/13/1/131
Oppel H, Munz M (2021) Analysis of feature dimension reduction techniques applied on the prediction of impact force in sports climbing based on IMU data. AI 2(4):662–683. https://doi.org/10.3390/ai2040040. https://www.mdpi.com/2673-2688/2/4/40
Peralta B, Soria R, Nicolis O, Ruggeri F, Caro L, Bronfman A (2023) Outlier vehicle trajectory detection using deep autoencoders in Santiago, Chile. Sensors 23(3). https://doi.org/10.3390/s23031440. https://www.mdpi.com/1424-8220/23/3/1440
Podder P, Das SR, Mondal MRH, Bharati S, Maliha A, Hasan MJ, Piltan F (2023) Lddnet: a deep learning framework for the diagnosis of infectious lung diseases. Sensors 23(1). https://doi.org/10.3390/s23010480. https://www.mdpi.com/1424-8220/23/1/480
Reddy GT, Reddy MPK, Lakshmanna K, Kaluri R, Rajput DS, Srivastava G, Baker T (2020) Analysis of dimensionality reduction techniques on big data. IEEE Access 8:54776–54788. https://doi.org/10.1109/ACCESS.2020.2980942
Sadek AH, Fahmy OM, Nasr M, Mostafa MK (2023) Predicting Cu(ii) adsorption from aqueous solutions onto nano zero-valent aluminum (nzval) by machine learning and artificial intelligence techniques. Sustainability 15(3). https://doi.org/10.3390/su15032081. https://www.mdpi.com/2071-1050/15/3/2081
Sahoo AK, Pradhan C, Barik RK, Dubey H (2019) Deepreco: Deep learning based health recommender system using collaborative filtering. Computation 7(2). https://doi.org/10.3390/computation7020025. https://www.mdpi.com/2079-3197/7/2/25
Salo F, Nassif AB, Essex A (2019) Dimensionality reduction with ig-pca and ensemble classifier for network intrusion detection. Comput Netw 148:164–175. https://doi.org/10.1016/j.comnet.2018.11.010
Tang J, Alelyani S, Liu H (2014) Feature selection for classification: a review. Data Classif Algorithms Appl 37. https://doi.org/10.1201/b17320
Vardhan BVS, Khedkar M, Srivastava I, Thakre P, Bokde ND (1996) A comparative analysis of hyperparameter tuned stochastic short term load forecasting for power system operator. Energies 16(3). https://doi.org/10.3390/en16031243. https://www.mdpi.com/1996-1073/16/3/1243
Veeramsetty V (2022) Electric power load dataset. https://data.mendeley.com/datasets/tj54nv46hj/1
Veeramsetty V, Chandra DR, Grimaccia F, Mussetta M (2022) Short term electric power load forecasting using principal component analysis and recurrent neural networks. Forecasting 4(1):149–164. https://doi.org/10.3390/forecast4010008
Veeramsetty V, Chandra DR, Salkuti SR (2021) Short-term electric power load forecasting using factor analysis and long short-term memory for smart cities. Int J Circ Theory Appl 49(6):1678–1703. https://doi.org/10.1002/cta.2928
Veeramsetty V, Deshmukh R (2020) Electric power load forecasting on a 33/11 kv substation using artificial neural networks. SN Appl Sci 2(5):855. https://doi.org/10.1007/s42452-020-2601-y
Veeramsetty V, Mohnot A, Singal G, Salkuti SR (2021) Short term active power load prediction on a 33/11 kv substation using regression models. Energies 14(11):2981. https://doi.org/10.3390/en14112981
Veeramsetty V, Rakesh Chandra D, Salkuti SR (2022) Short term active power load forecasting using machine learning with feature selection. In: Next generation smart grids: modeling, control and optimization. Springer, pp 103–124. https://doi.org/10.1007/978-981-16-7794-6_5
Veeramsetty V, Reddy KR, Santhosh M, Mohnot A, Singal G (2022) Short-term electric power load forecasting using random forest and gated recurrent unit. Electr Eng 104(1):307–329. https://doi.org/10.1007/s00202-021-01376-5
Veeramsetty V, Sai Pavan Kumar M, Salkuti SR (2022) Platform-independent web application for short-term electric power load forecasting on 33/11 kv substation using regression tree. Computers 11(8):119. https://doi.org/10.3390/computers11080119
Viale L, Daga AP, Fasana A, Garibaldi L (2023) Dimensionality reduction methods of a clustered dataset for the diagnosis of a scada-equipped complex machine. Machines 11(1). https://doi.org/10.3390/machines11010036. https://www.mdpi.com/2075-1702/11/1/36
Xing H, Chen B, Feng Y, Ni Y, Hou D, Wang X, Kong Y (2022) Mapping irrigated, rainfed and paddy croplands from time-series sentinel-2 images by integrating pixel-based classification and image segmentation on google earth engine. Geocarto Int 1–20. https://doi.org/10.1080/10106049.2022.2076923
You K, Qiu G, Gu Y (2022) Rolling bearing fault diagnosis using hybrid neural network with principal component analysis. Sensors 22(22). https://doi.org/10.3390/s22228906. https://www.mdpi.com/1424-8220/22/22/8906
Zhang Z, Huang R, Han F, Wang Z (2019) Image error concealment based on deep neural network. Algorithms 12(4). https://doi.org/10.3390/a12040082. https://www.mdpi.com/1999-4893/12/4/82
Acknowledgements
This research work was supported by “Woosong University’s Academic Research Funding—2023.”
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix
Appendix
1.1 Autoencoder
This section presents step by step procedure for training of autoencoder and also explains how trained encoder is used to reconstruct the data from original dataset. The sample architecture of autoencoder that used in this section to explain the training and data reconstruction procedure is shown in Fig. 5.

Sample autoencoder architecture
The initial weight and bias matrices are shown in equations (12–15). The data samples that are used to train the autoencoder is shown in Table 9.
1.2 Auto Encoder Training
In this section, update of weights and bias parameters of autoencoder based on given training data for one iteration is explained.
-
Iteration 01
-
Sample 01 = [ 0.1 0.2 0.3]
-
Calculate net input to hidden layer/latent space using Eq. (4) and the result for the first sample is shown below
Calculate the output of hidden layer/latent space using Eq. (5) and the result for the first sample is shown below
Calculate the input of output layer using Eq. (6) and the result for the first sample is shown below
As linear activation function is used in the output layer, the output and input for output layer remains same and that is
Calculate the change in weights connected to each neuron in the output layer using Eq. (20). Where n is a neuron in output layer.
Finally, change in weights between latent space and output layer is given by
Now update the weights between latent space and output layer using equation (25).
Calculate the change in bias connected to each neuron in the output layer using Eq. (27) and update bias parameters using Eq. (29)
Calculate the change in weights connected to each neuron in the latent space using Eq. (31). Where n is a neuron in output layer and j is neuron in latent space.
Finally, change in weights between latent space and input layer is given by
Now update the weights between latent space and input layer using Eq. (37).
Calculate the change in bias connected to each neuron “j” in the latent space using Eq. (39) and update bias parameters using equation (??).
Finally, change in bias parameter for the neurons in latent space are given by
-
Iteration 01
-
Sample 02 = [ 0.3 0.2 0.1]
-
Calculate net input to hidden layer/latent space using Eq. (4) and the result for the second sample is shown below
Calculate the output of hidden layer/latent space using Eq. (5) and the result for the first sample is shown below
Calculate the input of output layer using Eq. (6) and the result for the first sample is shown below
As linear activation function is used in the output layer, the output and input for output layer remains same and that is
Calculate the change in weights connected to each neuron in the output layer using Eq. (20).
Finally, change in weights between latent space and output layer is given by
Now update the weights between latent space and output layer using Eq. (25).
Calculate the change in bias connected to each neuron in the output layer using Eq. (27) and update bias parameters using Eq. (29)
Calculate the change in weights connected to each neuron in the latent space using Eq. (31). Where n is a neuron in output layer and j is neuron in latent space.
Finally, change in weights between latent space and input layer is given by
Now update the weights between latent space and input layer using Eq. (37).
Calculate the change in bias connected to each neuron “j” in the latent space using Eq. (39) and update bias parameters using Eq. (29).
Finally, change in bias parameter for the neurons in latent space are given by
Calculate the output of hidden layerlatent space using Eq. (5) and the result for the first sample is shown below
1.3 Reconstruction of Data Using Trained Autoencoder
Encoder part of trained autoencoder which is shown in Fig. 6 is used to reconstruct the data. Weight and bias matrices of encoder part are shown below.

Encoder part of sample autoencoder architecture
A sample data [0.2,0.3,0.4] is reconstructed into a data sample consists only two features as shown below
The output of hidden layer/latent space is reconstructed data.
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this chapter

Cite this chapter
Veeramsetty, V. et al. (2023). Active Power Load Data Dimensionality Reduction Using Autoencoder. In: Salkuti, S.R., Ray, P., Singh, A.R. (eds) Power Quality in Microgrids: Issues, Challenges and Mitigation Techniques. Lecture Notes in Electrical Engineering, vol 1039. Springer, Singapore. https://doi.org/10.1007/978-981-99-2066-2_22
Download citation
DOI: https://doi.org/10.1007/978-981-99-2066-2_22
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-2065-5
Online ISBN: 978-981-99-2066-2
eBook Packages: EnergyEnergy (R0)