
Abstract
We propose MetaFM, a novel ML-style module system that enables users to decompose multi-stage programs (i.e., programs written in a typed multi-stage programming language) into loosely coupled components in a manner natural with respect to type abstraction. The distinctive aspect of MetaFM is that it allows values at different stages to be bound in a single structure (i.e., \( \textbf{struct} \ \cdots \ \textbf{end} \)). This feature is crucial, for example, for defining a function and a macro that use one abstract type in common, without revealing the implementation detail of that type. MetaFM also accommodates functors, higher-kinded types, the \(\textbf{with} \ \textbf{type} \)-construct, etc. with staging features. For defining semantics and proving type safety, we employ an elaboration technique, i.e., type-directed translation to a target language, inspired by the formalization of F-ing Modules. Specifically, we give a set of elaboration rules for converting MetaFM programs into System F\(\omega ^{\langle \rangle }\), a multi-stage extension of System F\(\omega \), and prove that the elaboration preserves typing. Additionally, our language supports cross-stage persistence (CSP), a feature for code reuse spanning more than one stage, without breaking type safety.
You have full access to this open access chapter, Download conference paper PDF
Keywords
1 Introduction
1.1 Multi-stage Programming
Program generation is a technique useful for several purposes such as improving performance or enhancing maintainability of programs; it can be used for optimizing programs by exploiting information available only at runtime, and also works as a basis for macros for eliminating so-called boilerplate code. Various studies and implementations provide features for code generation, and their formalizations differ from one another. Among these, a considerable amount of studies have been done for proposing multi-stage programming (MSP) languages [5, 6, 12, 13, 16, 26, 31,32,33,34,35, 38]. They enable users to write code-generating programs in a less error-prone manner with the aid of their type systems.
For a brief introduction to MSP, we use a simple setting similar to MetaML [32, 33] or \(\lambda ^\bigcirc \) [5, 6] here. In addition to ordinary constructs for typed functional languages, two special constructs, bracket
 and escape
and escape
 , are provided:
, are provided:
 . Brackets and escapes correspond to (hygienic) quasi-quotes and unquotes in Lisp, respectively. Owing to brackets and escapes, every subpart of expressions has its stage; a subexpression inside a bracket has one higher stage than outside, and conversely, a subexpression inside an escape has one lower stage. The lowermost stage is called stage \(0\), and seen from stage \(n\), subexpressions at stage \((n + 1)\) intuitively represent code fragments used for building the resulting code. One can intuitively understand the notion of stages in a graphical manner like (a) and (b) below, considering that expressions are bumpy; brackets are convex, and escapes are concave.
. Brackets and escapes correspond to (hygienic) quasi-quotes and unquotes in Lisp, respectively. Owing to brackets and escapes, every subpart of expressions has its stage; a subexpression inside a bracket has one higher stage than outside, and conversely, a subexpression inside an escape has one lower stage. The lowermost stage is called stage \(0\), and seen from stage \(n\), subexpressions at stage \((n + 1)\) intuitively represent code fragments used for building the resulting code. One can intuitively understand the notion of stages in a graphical manner like (a) and (b) below, considering that expressions are bumpy; brackets are convex, and escapes are concave.

The essentials of the evaluation rules are the following: (i) The ordinary (call-by-value) \(\beta \)-reduction is performed only at stage \(0\); expressions inside brackets are not evaluated in a usual sense except for ones inside escapes, since they represent code fragments. (ii) Escape cancels bracket; an expression of the form
 is evaluated to \(e\) when \(e\) is a “completed” code fragment, i.e., does not contain further escapes. Such code fragments are dubbed as code values henceforth. An example evaluation step is shown in (c) above.
is evaluated to \(e\) when \(e\) is a “completed” code fragment, i.e., does not contain further escapes. Such code fragments are dubbed as code values henceforth. An example evaluation step is shown in (c) above.
After repeated reduction, a program at stage 0 hopefully reaches a code value
 , which intuitively corresponds to the end of macro expansion. Then the bracketed expression \(e\) is “put down” to stage 0, and the evaluation of the expression starts in turn. Especially when the number of stages is \(2\), stage \(0\) is for code generation, and the generated program at stage \(1\) is for ordinary evaluation.
, which intuitively corresponds to the end of macro expansion. Then the bracketed expression \(e\) is “put down” to stage 0, and the evaluation of the expression starts in turn. Especially when the number of stages is \(2\), stage \(0\) is for code generation, and the generated program at stage \(1\) is for ordinary evaluation.
As an example multi-stage program, let us consider \( \texttt{ genpower } \), a function that takes a natural number \(n\) and produces code for the \(n\)-th power function. This function can be implemented like the following:

The application \( \texttt{genpower } \ \texttt{2 } \) is, for instance, evaluated as follows (which does not precisely conform to the operational semantics but describes overall steps):

A minimal type system for asserting the safety of staged computation is actually quite concise; it basically suffices to equip types of the form
 , which is the type for code fragments that will be expressions of type \(\tau \) at the next stage. For example, \( \texttt{ genpower } \) is assigned type
, which is the type for code fragments that will be expressions of type \(\tau \) at the next stage. For example, \( \texttt{ genpower } \) is assigned type
 since it takes an integer and returns a code value bracketing an expression of type \( \texttt{ int } \rightarrow \texttt{ int } \) at stage \(1\). Thanks to such typing, we can assert that programs do not get stuck during code generation and neither does the evaluation of produced code, once code-generating programs are successfully type-checked.
since it takes an integer and returns a code value bracketing an expression of type \( \texttt{ int } \rightarrow \texttt{ int } \) at stage \(1\). Thanks to such typing, we can assert that programs do not get stuck during code generation and neither does the evaluation of produced code, once code-generating programs are successfully type-checked.
1.2 Point at Issue: Modularity
Although possibly used as an intermediate language to handle the results of some transformations such as those guided by binding-time analysis [30], MSP languages are intended to be written by hand as well. As long as written and read directly by users, multi-stage programs are desirably composed of loosely coupled smaller components for code maintainability. To this end, as widely known, ML-family languages such as Standard ML or OCaml conventionally have an encapsulation mechanism called a module system [7,8,9, 14, 19, 21, 23, 24]. One can naturally expect that such a module system is also useful for MSP.
In this paper, we propose a new module system for the purpose above. Our contributions can be summarized as follows: (1) Language design: We design a module system named MetaFM that enables us to decompose multi-stage programs in a manner natural with respect to type abstraction. Unlike some existing module systems equipped with staging features [16, 26, 35], our module system does not assign stages to modules; instead, it allows values at different stages to be bound in the same structure (i.e., \( \textbf{struct} \ \cdots \ \textbf{end} \)). We observe that this language design is crucial for the natural decomposition of multi-stage programs into loosely coupled components, as exemplified in Sects. 2–3. (2) Reconciliation of staging with full-fledged ML-style modules: Based on the language design above, we accommodate staging with some advanced features for modules such as higher-order functors, sealing, the \(\textbf{with}\ \textbf{type}\)-construct, or higher-kinded types. Our module system also supports cross-stage persistence (CSP) [33, 38], an important staging feature that enables the reuse of one common value at more than one stage. We give semantics to our language through an elaboration, i.e., a type-directed translation to a target language, and show that the elaboration is sound, i.e., that any target terms produced by the elaboration are well-typed. (3) Target type safety: As a target language, we define System F\(\omega ^{\langle \rangle }\), a multi-stage extension of System F\(\omega \) [11, 22], and prove its type safety. The language has its own stage polymorphism to provide CSP for MetaFM.
On the other hand, our method has the following limitations so far: (a) It does not support the \( \textbf{run} \)-primitive [13, 26, 32, 34, 35], which executes code like \( ( \textbf{run} \ ( \texttt{genpower } \ \texttt{3 } ) ) \ \texttt{5 } \longrightarrow ^*\texttt{ 125 } \). This is not a severe limitation because \( \textbf{run} \) is not necessary if one wants to do only compile-time code generation, and may well be covered by some techniques orthogonal to ours, such as \(\lambda ^{\triangleright }\) [34]. (b) It cannot handle first-class modules [20, 24, 25]. This is perhaps difficult to overcome within our language design because unpacking them can be done only at runtime while modules in our formalization are not staged and considered stage-\( 0 \). (c) It cannot straightforwardly extend with features that have side effects such as mutable references due to a lack of sophistication in the semantics. We have a promising solution to this issue nonetheless, and discuss it as part of our future work.
The rest of the paper is organized as follows: First, Sect. 2 displays examples that motivate our language design. Section 3 compares related work and ours, and discusses the necessity of the design. Section 4 formalizes the source language, omitting CSP for clarity for the moment. After Sect. 5 defines the target language and proves its type safety, Sect. 6 explains the elaboration rules and proves their soundness. Section 7 extends our language with CSP without breaking the previously proved properties. Finally, Sect. 8 mentions future work and its provisional implementation, and Sect. 9 concludes the paper. Many definitions and proofs are in Appendix due to space limitations.

Example definition of modules in MetaFM
2 Motivating Examples
To showcase our motivation, consider a module \( \texttt{ Timestamp } \) that handles absolute timestamps as data of abstract type \( \texttt{Timestamp } . \texttt{t } \), under the two-stage setting, i.e., where we only have stages \( 0 \) and \( 1 \), which are for compile-time macro expansion and runtime, respectively. The module has, for instance, a predicate \( \texttt{ precedes } \) of type \( \texttt{ t } \rightarrow \texttt{ t } \rightarrow \texttt{ bool } \) that takes two timestamps and judges which is earlier. It would be useful if the module provides a macro \( \texttt{ gen } \) that transforms datetime texts into the corresponding timestamps beforehand like the following:

In our language, one can implement such \( \texttt{ Timestamp } \) as shown in Fig. 1(a)Footnote 1. Timestamps are represented by Unix time integers, and functions are implemented as simple arithmetics. The macro \( \texttt{ gen } \) is implemented by using an auxiliary function \( \texttt{ parseDatetime } \) of type \( \texttt{ string } \rightarrow \texttt{ option } \ \texttt{ int } \) at stage \(0\); Although its definition is omitted, \( \texttt{ parseDatetime } \) parses a text and returns \( \texttt{Some } \ \texttt{ts } \) if the given text is a valid datetime, where \( \texttt{ ts } \) is the corresponding Unix timestamp, or returns \( \texttt{ None } \) otherwise. Most importantly, \( \texttt{ gen } \) does not expose the internal representation of \( \texttt{Timestamp } . \texttt{t } \)-typed values, as the ordinary functions do not.
As a side note, two additional constructs excluded from the formalization are used in the example above. One is \( \textbf{fail} \), which simply aborts the program when evaluated. Note that allowing the use of \( \textbf{fail} \) at stage \(0\) is much less harmful than that at stage \(1\); such an abort occurs before runtime. The other is \( \textbf{lift} \ e \), which evaluates \(e\) to a value \(v\), and “lifts” it to
 for the next stage. We should note here that lifting and CSP are different despite their apparent resemblance, and that one cannot lift arbitrary values; lifting functions, for example, makes variable occurrences in the function body inconsistent as to their stage. It is thus desirable to rule out such lifting, but that topic is out of the scope of this paper.
for the next stage. We should note here that lifting and CSP are different despite their apparent resemblance, and that one cannot lift arbitrary values; lifting functions, for example, makes variable occurrences in the function body inconsistent as to their stage. It is thus desirable to rule out such lifting, but that topic is out of the scope of this paper.
Another example is shown in Fig. 1(b). We here implement a functor \( \texttt{ MakeMap } \) for handling (finite) maps, which is equivalent to OCaml’s Map.Make; it takes a module \( \texttt{ Key } \) of signature \( \texttt{ Ord } \), which requires \( \texttt{ Key } \) to have a type \( \texttt{Key } . \texttt{t } \) of mapping keys and a comparison function \( \texttt{Key } . \texttt{compare } \) of type \( \texttt{Key } . \texttt{t } \rightarrow \texttt{Key } . \texttt{t } \rightarrow \texttt{int } \) used for efficient access to values, and produces a module that provides a type \( \texttt{ t } \ \alpha \) for maps whose keys and values are of type \( \texttt{Key } . \texttt{t } \) and \(\alpha \), respectively. We add to the resulting module a macro \( \texttt{ gen } \) that produces a map from a list of key–value pairs beforehand. Since module expressions are not staged, we do not have any additional difficulty in the reconciliation of functors and staging features. One can use this macro as follows, for instance:

One important thing here is that \( \texttt{Key } . \texttt{compare } \) should be available both at stage \( 0 \) and \( 1 \) so that both \( \texttt{ gen } \) and ordinary functions can use it at compile-time and runtime, respectively. Such capability is called cross-stage persistence or CSP for short [33, 38] and is known as one of the vital staging features for practical use. We support it by bindings of the form \( \textbf{val} ^{\ge n } \ X = E \ \), which defines a value \(X\) for any stage \(n'\) such that \(n' \ge n\). Based on this language design, \( \texttt{ Ord } \) will be \( ( \textbf{sig} \ \textbf{type} \ \texttt{t } \, {::} \, *; \textbf{val} ^{\ge 0 }\ \texttt{compare } : \texttt{t } \rightarrow \texttt{t } \rightarrow \texttt{int } \ \textbf{end} ) \), for example.
3 Related Work and Our Approach
There are some existing studies that mix staging features with module systems, though their goals differ from ours: Inoue et al. [16] indicated that by staging modules we can eliminate abstraction overheads due to the use of functors, and then Watanabe et al. [35] and Sato et al. [26] followed the approach and proposed the formalization of such type systems. Despite the difference in the purpose, it is apparently worth considering that we can possibly utilize them for our goal. However, such reuse seems somewhat unsatisfactory; to implement modules equivalent to \( \texttt{ Timestamp } \) (or \( \texttt{ MakeMap } \)) in such languages where only entire modules are staged, one could do one of the following: (1) separate the module into two, i.e., \( \texttt{ Timestamp } \) at stage \( 1 \) for ordinary functions, and \( \texttt{ GenTimestamp } \) at stage \( 0 \) for defining macros; (2) do basically the same as (1), but define the type for representing timestamps internally in a separate module \( \texttt{ TimestampImpl } \), and both \( \texttt{ Timestamp } \) and \( \texttt{ GenTimestamp } \) include it; or (3) define \( \texttt{ Timestamp } \) at stage \( 0 \), and ordinary functions are bound as code values. Each option has a kind of drawback, unfortunately. First, consider implementing the macro \( \texttt{ gen } \) in \( \texttt{ GenTimestamp } \) based on (1). To assign type
 to the macro, we must provide a “backdoor” function \( \lambda x .\ x \) as \( \texttt{Timestamp } . \texttt{make } \) of type \( \texttt{int } \rightarrow \texttt{Timestamp } . \texttt{t } \) and leave its application in code fragments produced by \( \texttt{ gen } \). Things get worse when considering the \( \texttt{ MakeMap } \) example; we cannot even provide such a backdoor so that \( \texttt{ GenMakeMap } \) can use it (at least when functors are generative, not applicative). Option (2) seems better in that it does not require a backdoor, but it is a kind of expediency; it reveals \( \texttt{ TimestampImpl } \) (or \( \texttt{ MapImpl } \)) to outside and thus requires another mechanism than modules that conceals the implementation. Option (3) is good in terms of modularity, but it makes every occurrence of ordinary values at stage \( 1 \) be like
to the macro, we must provide a “backdoor” function \( \lambda x .\ x \) as \( \texttt{Timestamp } . \texttt{make } \) of type \( \texttt{int } \rightarrow \texttt{Timestamp } . \texttt{t } \) and leave its application in code fragments produced by \( \texttt{ gen } \). Things get worse when considering the \( \texttt{ MakeMap } \) example; we cannot even provide such a backdoor so that \( \texttt{ GenMakeMap } \) can use it (at least when functors are generative, not applicative). Option (2) seems better in that it does not require a backdoor, but it is a kind of expediency; it reveals \( \texttt{ TimestampImpl } \) (or \( \texttt{ MapImpl } \)) to outside and thus requires another mechanism than modules that conceals the implementation. Option (3) is good in terms of modularity, but it makes every occurrence of ordinary values at stage \( 1 \) be like
 .
.
Perhaps some of the most similar existing work would be Modular Macros [37] and MacoCaml [36]; the former informally suggests a language design similar to ours by giving some examples, and the latter gives a formalization that supports a subset of that language design. MacoCaml offers structures (i.e., \( \textbf{struct} \ \cdots \ \textbf{end} \)) in which both values and macros can be bound, and supports CSP by level-shifting imports \(\textbf{import}^{\downarrow }\) inspired by Flatt [10]. Major differences between ours and MacoCaml are that the number of stages in a structure is not limited to two, that the type abstraction by signatures is taken into account, and that functors can be handled. Aside from how semantics is precisely defined, ours can perhaps be seen as an extension of MacoCaml (without mutable references) with functors, higher-kinded types, sealing, the \(\textbf{with}\ \textbf{type}\)-construct, etc.
A technical challenge lies in giving semantics to our language and, at the same time, proving that our language is type-safe and does not break type abstraction. Indeed, defining semantics conforming to full-fledged ML-style module systems has long been an issue by itself [4, 7, 14, 15, 23, 27]. Among the line of studies, F-ing Modules [23, 24] elegantly formalizes such semantics through an elaboration (i.e., a type-directed translation) to System F\(\omega \) [11, 22]. This approach seems better than giving semantics directly on module expressions in that it does not suffer at all from the avoidance problem [4, 7, 14] caused by locally defined types under the combination of sealing (\( X \mathrel {:>} S \)) and projection (\( M . X \)).
To define semantics for our language, we follow the elaboration approach taken by F-ing Modules. Specifically, we translate the source language MetaFM into System F\(\omega ^{\langle \rangle }\), a multi-stage extension of System F\(\omega \). This is in contrast to MacoCaml, which gives semantics directly to module expressions and might well induce the avoidance problem when extending with features of full-fledged ML-style modules such as sealing and projection. Although the elaboration intensively utilizes the existential quantification offered by System F\(\omega ^{\langle \rangle }\) to demonstrate that type abstraction is properly done, its operational essence is rather simple; in a sense, our elaboration performs the option (3) above internally.
4 Source Language
The following defines the entire syntax for our source language MetaFM, where meta-level notations \([\mu ]^{*}\) and \([\mu \mapsto \nu ]\) range over the (possibly empty) finite sequences of \(\mu \) and the finite maps from \(\mu \) to \(\nu \), respectively:

The metavariables \(M\), \(S\), \(B\), and \(D\) stand for modules, signatures, bindings, and declarations, respectively. For brevity, we use the same metavariable \(X\) in common for names of values, types, and modules bound as members of structures. The module language is quite similar to that of F-ing Modules [23, 24]; modules consist of identifiers \(X\), projections \( M . X \), structures \( \textbf{struct} \ \boldsymbol{B} \ \textbf{end} \), functor abstractions \( \textbf{fun} ( X : S ) \rightarrow M \), functor applications \( \ X_{{\textrm{1}}} \ X_{{\textrm{2}}} \), and sealing \( X \mathrel {:>} S \). The sole essential difference is that value bindings \( \textbf{val} ^{ n }\ X = E \) and declarations \( \textbf{val} ^{ n }\ X : T \) have an annotation \(n\) that specifies for which stage the value \(X\) is defined. The binding forms
 and \( \textbf{val} \ X = E \ \) used in Sect. 1 were actually syntax sugars of \( \textbf{val} ^{ 0 }\ X = E \) and \( \textbf{val} ^{ 1 }\ X = E \), respectively. We do not specify the core language in detail, but both expressions \(E\) and types \(T\) are equipped with paths \(P\) to items in structures (e.g. \( \texttt{Timestamp } . \texttt{precedes } \)). We only formalize generative functors (i.e., ones that produce fresh abstract types each time even if applied to the same module); we can perhaps handle applicative ones as well in an F-ing Modules-like manner, but omit them for simplicity.
and \( \textbf{val} \ X = E \ \) used in Sect. 1 were actually syntax sugars of \( \textbf{val} ^{ 0 }\ X = E \) and \( \textbf{val} ^{ 1 }\ X = E \), respectively. We do not specify the core language in detail, but both expressions \(E\) and types \(T\) are equipped with paths \(P\) to items in structures (e.g. \( \texttt{Timestamp } . \texttt{precedes } \)). We only formalize generative functors (i.e., ones that produce fresh abstract types each time even if applied to the same module); we can perhaps handle applicative ones as well in an F-ing Modules-like manner, but omit them for simplicity.
For defining elaboration rules, we employ semantic signatures \( \varSigma \) and \(\xi \) [23, 24], as internal representations, and make type environments \( \varGamma \) track them:

where \(n\) ranges over the set of stage numbers (i.e. the set of natural numbers). Although \(s\) ranges over exactly the same set as \(n\) for the moment, it will be extended for CSP in Sect. 7. Basically,
 and
and
 correspond to value and type items in structures, respectively, and \( \mathopen {\{\!|} R \mathclose {|\!\} } \) and \( \forall \boldsymbol{b} .\ \varSigma \rightarrow \xi \) work respectively as structure and functor signatures. Existentially quantified type variables intuitively correspond to abstract types. For simplicity, we assume that source variables \(X\) can be injectively embedded into the set of labels as \( l_{ X } \).
correspond to value and type items in structures, respectively, and \( \mathopen {\{\!|} R \mathclose {|\!\} } \) and \( \forall \boldsymbol{b} .\ \varSigma \rightarrow \xi \) work respectively as structure and functor signatures. Existentially quantified type variables intuitively correspond to abstract types. For simplicity, we assume that source variables \(X\) can be injectively embedded into the set of labels as \( l_{ X } \).

Signature elaboration rules (selective; see Fig. 11 for omitted ones)
Figure 2 displays the elaboration rules for the judgment \( \varGamma \vdash S \rightsquigarrow \xi \), which converts syntactic signature \(S\) into semantic signature \(\xi \). Among the rules, only D-Val is essentially new, compared to those of F-ing Modules [23, 24]; it handles declarations of value items of type \(\tau \) at stage \(n\) by signatures
 .
.
The set of typing rules for modules and bindings is displayed in Fig. 3. The judgment \( \varGamma \vdash M : \xi \rightsquigarrow e \) intuitively states that \(M\) is assigned signature \(\xi \) under type environment \( \varGamma \), aside from the elaboration part \(\rightsquigarrow e\) for the moment; indeed, one can read the rules just ignoring the portions with a gray background. We explain how the elaboration works later in Sect. 5. While most of the rules are essentially the same as those of F-ing Modules, only B-Val is new; it type-checks the left-hand side \(E\) of a binding \( \textbf{val} ^{ n }\ X = E \) as an expression at stage \(n\), and assigns signature
 to the value item \(X\), where \(\tau \) is the resulting type.
to the value item \(X\), where \(\tau \) is the resulting type.

Module elaboration rules (selective; see Fig. 10 for omitted ones)
Although we do not fix the core language, Fig. 4 displays foundational or basic rules for judgments such as \( \varGamma \vdash ^{ s } E : \tau \rightsquigarrow e \). Among the rules, E-Path essentially uses signatures
 for value items; it limits the occurrence of paths by stage number \(n\) as well as by types so that value items are used only at the stage for which they are bound. The rules for staging, i.e., E-Brkt and E-Esc, are fairly standard as an MSP language; an expression of the form
for value items; it limits the occurrence of paths by stage number \(n\) as well as by types so that value items are used only at the stage for which they are bound. The rules for staging, i.e., E-Brkt and E-Esc, are fairly standard as an MSP language; an expression of the form
 has a code type
has a code type
 if the subexpression \(E\) is assigned the type \(\tau \) at the next stage, and a subexpression \(E\) of
if the subexpression \(E\) is assigned the type \(\tau \) at the next stage, and a subexpression \(E\) of
 is expected to be of type
is expected to be of type
 at the previous stage.
at the previous stage.
As is usual with module systems, the rules M-App and M-Seal depend on signature matching \( \varGamma \vdash \varSigma \leqslant \exists \boldsymbol{b} .\ \varSigma ' \uparrow \boldsymbol{\tau } \rightsquigarrow e \), where \(\boldsymbol{\tau }\) ranges over the set of finite sequences of types. This judgment intuitively asserts that \( \varSigma \) can be a subtype of \( \exists \boldsymbol{b} .\ \varSigma ' \) when the type variables in \(\boldsymbol{b}\) (i.e., abstract types) are respectively instantiated by the types listed in \(\boldsymbol{\tau }\). Selected rules for signature matching are shown in Fig. 5. Again, only U-Val is essentially new; the others are exactly the same as the corresponding rules of F-ing Modules.
What we should note lastly is decidability. While most of the rules are syntax-directed, U-Val requires type equivalence \( \tau \equiv \tau ' \), and U-Match depends on the guess at each \(\tau _{ i }\), which makes the decidability of the whole type-checking non-trivial. The former is easy: we can prove that the evident type-level reduction relation on well-kinded types is confluent and strongly normalizing, and can thus check type equivalence by comparing normal forms. The latter requires a more complicated technique, but we can indeed infer each \(\tau _{ i }\) as discussed in [24].
In the forthcoming two sections, we define a target language, see how the elaboration part \(\rightsquigarrow e\) works, and show that \(e\) is well-typed in the target language.
5 Target Language and Its Type Safety
This section introduces System F\(\omega ^{\langle \rangle }\), a multi-stage extension of System F\(\omega \) [11, 22] used as a target language. The following defines the syntax:

Expressions \(e\) have bracket
 and escape
and escape
 for staging in addition to the standard constructs for typed lambda calculi, record construction \( \{ l_{{\textrm{1}}} = e_{{\textrm{1}}} , \ldots , l_{ m } = e_{ m } \} \) (where the labels are assumed to be pairwise distinct), record projection \( e \# l \), type variable abstraction \( \mathrm {\Lambda } \alpha \mathrel {::} \kappa .\ e \), type application \( e \ \tau \), and pack/unpack expressions for existential quantification. Higher-kinded types \(\tau \) consist of type variables \(\alpha \), function types \( \tau \rightarrow \tau \), record types \( \{ r \} \), type-level abstractions \( \mathrm {\Lambda } \alpha \mathrel {::} \kappa .\ \tau \), type-level applications \( \tau \ \tau \), existential (resp. universal) quantification \( \exists \alpha \mathrel {::} \kappa .\ \tau \) (resp. \( \forall \alpha \mathrel {::} \kappa .\ \tau \)), and code types
for staging in addition to the standard constructs for typed lambda calculi, record construction \( \{ l_{{\textrm{1}}} = e_{{\textrm{1}}} , \ldots , l_{ m } = e_{ m } \} \) (where the labels are assumed to be pairwise distinct), record projection \( e \# l \), type variable abstraction \( \mathrm {\Lambda } \alpha \mathrel {::} \kappa .\ e \), type application \( e \ \tau \), and pack/unpack expressions for existential quantification. Higher-kinded types \(\tau \) consist of type variables \(\alpha \), function types \( \tau \rightarrow \tau \), record types \( \{ r \} \), type-level abstractions \( \mathrm {\Lambda } \alpha \mathrel {::} \kappa .\ \tau \), type-level applications \( \tau \ \tau \), existential (resp. universal) quantification \( \exists \alpha \mathrel {::} \kappa .\ \tau \) (resp. \( \forall \alpha \mathrel {::} \kappa .\ \tau \)), and code types
 .
.
Figure 6 shows the typing rules for \( \gamma \vdash ^{ s } e : \tau \), which states that \(e\) is assigned type \(\tau \) at stage \(s\) under the type environment \(\gamma \). The judgments \( \vdash \gamma \) and \( \gamma \vdash \tau \mathrel {::} \kappa \), which are defined in Appendix, assert that \(\gamma \) is well-formed and that \(\tau \) is assigned the kind \(\kappa \) under \(\gamma \), respectively. The set of rules is basically a natural integration of System F\(\omega \) with staging features, but pack/unpack-expressions are allowed only at stage \( 0 \). This is just because it suffices for our purpose; we could possibly allow them at arbitrary stages, but we don’t have to.

Core language elaboration rules

Signature subtyping rules (selective; see Fig. 12 for omitted ones)

Typing rules for System F\(\omega ^{\langle \rangle }\) (selective; see Fig. 14 for omitted ones)

Operational semantics of System F\(\omega ^{\langle \rangle }\) (selective; see Fig. 15 for omitted ones)
The small-step call-by-value operational semantics of System F\(\omega ^{\langle \rangle }\) is shown in Fig. 7. The judgment \( e \, {\mathop {\longrightarrow }\limits ^{ n }}\, e' \) stands for the reduction of the expression \(e\) at stage \(n\). As is usual in multi-stage languages, essential reductions, such as ordinary \(\beta \)-reduction or access to record fields, are defined only at stage \(0\), and the cancellation of brackets by escapes happens only at stage \(1\). Here, values \( v ^{( 0 )} \) (resp. \( v ^{( n )} \)) at stage \( 0 \) (resp. at stage \(n \ge 1 \)) are defined by the following:

We have the following standard type safety properties of System F\(\omega ^{\langle \rangle }\). Here, we write \( \vdash ^{\ge n } \gamma \) if all entries in \(\gamma \) of the form \(x : \tau ^{ s } \) satisfy \(s \ge n\). Since the language has type equivalence, we have to take care of the so-called inversion lemma by using an argument similar to the one in Chapter 30 of [22].
Theorem 1
(Preservation). If \( \gamma \vdash ^{ n } e : \tau \) and \( e \,{\mathop {\longrightarrow }\limits ^{ n }} \, e' \), then \( \gamma \vdash ^{ n } e' : \tau \).
Theorem 2
(Progress). If \( \vdash ^{\ge 1 } \gamma \) and \( \gamma \vdash ^{ n } e : \tau \), then \(e\) is a value at stage \(n\), or there exists \(e'\) such that \( e \,{\mathop {\longrightarrow }\limits ^{ n }} \, e' \).
6 Elaboration and Its Soundness
This section explains the elaboration of MetaFM programs into System F\(\omega ^{\langle \rangle }\), i.e., discusses the \(\rightsquigarrow e\) part of the rules in Figs. 3, 4, and 5.
Taking the elaboration part into account, the judgment \( \varGamma \vdash ^{ s } E : \tau \rightsquigarrow e \) intuitively states that the core language expression \(E\) at stage \(s\) is translated to the term \(e\) at stage \(s\) in System F\(\omega ^{\langle \rangle }\), in addition to typing \(E\). Basically the same holds for the judgment \( \varGamma \vdash M : \xi \rightsquigarrow e \); it illustrates that the module \(M\) is converted to the term \(e\). What should be noted here is that the resulting terms \(e\) of the module elaboration are at stage \( 0 \) in System F\(\omega ^{\langle \rangle }\); through elaboration, we virtually deal with modules as if they were at stage \( 0 \). In this sense, particularly, functor applications are resolved by stage-\( 0 \) computation. Lastly, terms \(e\) produced by judgments for signature subtyping such as \( \varGamma \vdash \varSigma \leqslant \varSigma ' \rightsquigarrow e \) are intuitively “upcast functions” from the subtype to the supertype. This intuition is justified afterwards by Theorem 3. For simplicity, in Figs. 3, 4, and 5, we assume that source variables \(X\) can be injectively embedded into the target variables, which is ranged over by \(x\). The figures also use the following syntax sugars as well as let-expressions and pack/unpack-expressions generalized for sequences, the precise definitions of which are shown in Appendix:

We embed semantic signatures into System F\(\omega ^{\langle \rangle }\) types by the following \(\lfloor -\rfloor \), and use them for describing the rules and for proving type safety:

The intuition for the elaboration rules involved in staging is fairly easy; leaving types out of account, B-Val and E-Path convert bindings \( \textbf{val} ^{ n }\ X = E \) and variable occurrences \(X\) at stage \(n\) into
 and
and
 in essence, respectively. The rule U-Val does similar things for building upcast functions.
in essence, respectively. The rule U-Val does similar things for building upcast functions.
Example 1
The elaboration translates \( \texttt{ Timestamp } \) to the following in essence:

Although the translation above suffices for giving semantics that fulfills type safety as shown by the theorems below, we do not assert that resulting terms are evaluated in the same manner as programmers’ intuition on source programs. This is a common downside of the elaboration approach, which defines semantics only through translationFootnote 2. Indeed, our translation sometimes causes a counterintuitive evaluation order due to its naïveness; it does not bind identifiers to values but to code fragments in general. This might be fine for typical items defined by immediate values such as lambda abstractions, but some cases are essentially unsatisfactory. For example, one may expect that \( \textbf{val} ^{ 1 }\ \texttt{a } = \texttt{1 } + \texttt{2 } \) computes \( \texttt{1 } + \texttt{2 } \) once and replaces all the occurrences of \( \texttt{ a } \) with \( \texttt{ 3 } \) at runtime, but this is not the case; it replaces \( \texttt{ a } \) with the expression \( \texttt{1 } + \texttt{2 } \) at compile-time. In a sense, value items for stage \(\ge 1 \) are used in a CBN-like manner. For the same reason, the translation prevents the extension with features that have side effects, such as mutable referencesFootnote 3, in a straightforward manner. It may also enlarge the generated code and make it less performant since code fragments are copied to every occurrence. Section 8 discusses possible improvements in the elaboration.

Extension of System F\(\omega ^{\langle \rangle }\) with stage polymorphism
Nonetheless, we have the following theorems that prove that the elaboration is sound in the sense that every produced term is well-typed (under some moderate requirements for the core language; see Assumption 5 in Appendix).
Theorem 3
(Soundness of Signature Subtyping). If \( \varGamma \vdash \varSigma \leqslant \exists \boldsymbol{b} .\ \varSigma ' \uparrow ( \tau _{ i } ) _{i = 1}^{m} \rightsquigarrow e \) and \( \lfloor \varGamma \rfloor , \boldsymbol{b} \vdash \lfloor \varSigma ' \rfloor \mathrel {::} *\), then \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \varSigma \rfloor \rightarrow \lfloor [ \tau _{ i } / \alpha _{ i } ] _{i = 1}^{m} \varSigma ' \rfloor \) and \( \lfloor \varGamma \rfloor \vdash \tau _{ i } \mathrel {::} \kappa _{ i } \) for each \(i\), where \(\boldsymbol{b} = ( \alpha _{ i } {::} \kappa _{ i } ) _{i = 1}^{m} \).
Theorem 4
(Soundness of Elaboration).
-
1.
\( \varGamma \vdash T {::} \kappa \rightsquigarrow \tau \) implies \( \lfloor \varGamma \rfloor \vdash \tau \mathrel {::} \kappa \).
-
2.
\( \varGamma \vdash ^{ s } E : \tau \rightsquigarrow e \) implies \( \lfloor \varGamma \rfloor \vdash ^{ s } e : \tau \).
-
3.
\( \varGamma \vdash P : \varSigma \rightsquigarrow e \) implies \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \varSigma \rfloor \).
-
4.
\( \varGamma \vdash D \rightsquigarrow \exists \boldsymbol{b} .\ R \) (resp. \( \varGamma \vdash \boldsymbol{D} \rightsquigarrow \exists \boldsymbol{b} .\ R \)) implies \( \lfloor \varGamma \rfloor \vdash \lfloor \exists \boldsymbol{b} .\ \mathopen {\{\!|} R \mathclose {|\!\} } \rfloor \mathrel {::} *\).
-
5.
\( \varGamma \vdash B : \exists \boldsymbol{b} .\ R \rightsquigarrow e \) (resp. \( \varGamma \vdash \boldsymbol{B} : \exists \boldsymbol{b} .\ R \rightsquigarrow e \)) implies \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \exists \boldsymbol{b} .\ \mathopen {\{\!|} R \mathclose {|\!\} } \rfloor \).
-
6.
\( \varGamma \vdash S \rightsquigarrow \xi \) implies \( \lfloor \varGamma \rfloor \vdash \lfloor \xi \rfloor \mathrel {::} *\). 7. \( \varGamma \vdash M : \xi \rightsquigarrow e \) implies \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \xi \rfloor \).
7 Extension with Cross-Stage Persistence
As mentioned earlier in Sect. 1, we support cross-stage persistence (CSP) [13, 33, 38] by the following binding (resp. declaration) form, which binds (resp. declares) \(X\) as a value available at any stages \(n'\) such that \(n' \ge n\):

To achieve this, we first extend System F\(\omega ^{\langle \rangle }\) with stage variables \(\sigma \):

Intuitively, stage variables work for “stage polymorphism” and can be instantiated with an arbitrary natural number \(k\). Stages \(s\) can newly be of the form \( n \dotplus \sigma \), which stands for any stages greater than or equal to \(n\). Bracket
 with a stage variable expresses arbitrarily nested brackets and is instantiated to
with a stage variable expresses arbitrarily nested brackets and is instantiated to
 . We correspondingly have escape
. We correspondingly have escape
 , which can be instantiated to
, which can be instantiated to
 . Stage abstractions \( ( \mathrm {\Lambda } \sigma .\ e ) \) and stage applications \( e \mathbin {\uparrow } s \) perform generalization and instantiation of the stage variables, respectively. For typing, we use stage-polymorphic types \( \forall \sigma .\ \tau \) and persistent code types
. Stage abstractions \( ( \mathrm {\Lambda } \sigma .\ e ) \) and stage applications \( e \mathbin {\uparrow } s \) perform generalization and instantiation of the stage variables, respectively. For typing, we use stage-polymorphic types \( \forall \sigma .\ \tau \) and persistent code types
 . Figure 8 displays additional rules for extending System F\(\omega ^{\langle \rangle }\) with the stage polymorphism. The rule TT-BrktVar allows brackets with a stage variable \(\sigma \) to be used in “fixed” stages \(n\) (as long as \(\sigma \) is valid in that scope), and expressions inside them are regarded as being at “polymorphic” stages \( n \dotplus \sigma \). TT-EscVar does the converse by requiring persistent code types
. Figure 8 displays additional rules for extending System F\(\omega ^{\langle \rangle }\) with the stage polymorphism. The rule TT-BrktVar allows brackets with a stage variable \(\sigma \) to be used in “fixed” stages \(n\) (as long as \(\sigma \) is valid in that scope), and expressions inside them are regarded as being at “polymorphic” stages \( n \dotplus \sigma \). TT-EscVar does the converse by requiring persistent code types
 to expressions inside escapes with \(\sigma \). One may see that stage variables are a minimal version of transition variables [13, 34] or environment classifiers [31]. We can keep the stage polymorphism minimal here because we do not have to provide something like \(\sigma + \sigma '\) for the elaboration. Most importantly, adding these rules can be done without breaking the type safety of System F\(\omega ^{\langle \rangle }\), i.e., Theorems 1 and 2.
to expressions inside escapes with \(\sigma \). One may see that stage variables are a minimal version of transition variables [13, 34] or environment classifiers [31]. We can keep the stage polymorphism minimal here because we do not have to provide something like \(\sigma + \sigma '\) for the elaboration. Most importantly, adding these rules can be done without breaking the type safety of System F\(\omega ^{\langle \rangle }\), i.e., Theorems 1 and 2.

Extension of MetaFM with cross-stage persistence
Now that the target language supports stage polymorphism, we can utilize it to support CSP in MetaFM by extending rules as displayed in Fig. 9. Here, we add a new semantic signature
 for persistent value items that can be embedded into System F\(\omega ^{\langle \rangle }\) by using stage-polymorphic types, and \( \varGamma \) newly tracks stage variables for the soundness of the expression elaboration:
for persistent value items that can be embedded into System F\(\omega ^{\langle \rangle }\) by using stage-polymorphic types, and \( \varGamma \) newly tracks stage variables for the soundness of the expression elaboration:

An essential part of the extended rules lies in those for paths in expressions, i.e., E-Path, E-PersInNonpers, and E-PersInPers. These rules permit paths to persistent values to occur at any expressions but prevent definitions of persistent value items from depending on non-persistent ones in order for CSP to work correctly, i.e., we do not allow expressions \(E\) of \( \textbf{val} ^{\ge n } \ X = E \ \) to contain paths to non-persistent values. Again, owing to such typing, we successfully extend MetaFM with CSP without breaking the soundness shown by Theorems 3 and 4.
8 Future Work and Provisional Implementation
Though we have successfully given semantics to our language and proved its type safety, several aspects can be improved further. To remedy the issues pointed out in Sect. 6, we should desirably modify the translation about when to bind value items. Possible solutions would be the following: (1) use the genlet primitive [17, 26] for performing let-insertion during code generation; or (2) define conversion of programs into a flat list of bindings of the form \(\textbf{val} ^{n}\ x = e\) with functor applications resolved, by using static interpretation (which is dubbed as SI here) [1, 8, 9]. Because the former appears less suitable for proving type safety in that it complicates formal semantics, we have been intensively studying the latter. Our ongoing study is implying that mixing staging features with SI is fine, but the soundness of SI itself seems not so well-established. Elsman [8] first showed the soundness of SI for first-order functors, which is quite sufficient for typical use cases, but it did not support higher-order ones. The SI for Futhark [9] claims its support for higher-order ones, but it seems that its current mechanized proof only covers functors assigned a signature of the form \( \forall \varepsilon .\ \varSigma \rightarrow \exists \varepsilon .\ \varSigma ' \) in essence.
Although its type safety has not yet been proved, we implemented a two-stage versionFootnote 4 of MetaFM with an SI-based elaboration for
 [29].
[29].
 [28] is a statically-typed domain-specific language for typesetting documents where commands for the markup, which are equivalent to control sequences in
[28] is a statically-typed domain-specific language for typesetting documents where commands for the markup, which are equivalent to control sequences in
 like
like
 , can be implemented in an OCaml-like manner. Programs in this language are basically functional, but mutable references are exceptionally used for numbering sections, for example. Because the module system incorporated in
, can be implemented in an OCaml-like manner. Programs in this language are basically functional, but mutable references are exceptionally used for numbering sections, for example. Because the module system incorporated in
 appears working fine with mutable references so far, we believe that the SI approach is promising for solving the binding-time issue.
appears working fine with mutable references so far, we believe that the SI approach is promising for solving the binding-time issue.
9 Conclusion
We have proposed MetaFM, a module system for decomposing multi-stage programs into loosely coupled components without breaking type abstraction, by defining semantics and proving its type safety through an elaboration to System F\(\omega ^{\langle \rangle }\). It supports several important features such as sealing, functors, higher-kinded types, or CSP. Further improvements on the elaboration are nonetheless desirable for real-world use, which can probably be done by static interpretation.
Notes
- 1.
We here use a Haskell-like notation for kinds like \( \textbf{type} \ \texttt{t } \, {::} \, *\). We also write type constructors before type arguments in type-level applications.
- 2.
One exception is Crary’s work [3]. It defines a target language as a superset of the source language, and shows observational equivalence between source programs and their corresponding target terms for the first time.
- 3.
- 4.
This is not due to some kind of limitation; just because providing two stages suffices for most use cases. Indeed, very few realistic examples that use more than two stages are known in the literature of multi-stage programming.
References
Bochao, L., Ohori, A.: A flattening strategy for SML module compilation and its implementation. Inf. Media Technol. 5(1), 58–76 (2010)
Calcagno, C., Moggi, E., Sheard, T.: Closed types for a safe imperative MetaML. J. Funct. Program. 13(3), 545–571 (2003)
Crary, K.: Fully abstract module compilation. Proc. ACM Program. Lang. 3(POPL), 1–29 (2019)
Crary, K.: A focused solution to the avoidance problem. J. Funct. Program. 30, e24 (2020)
Davies, R.: A temporal-logic approach to binding-time analysis. In: Proceedings of the 11th Annual IEEE Symposium on Logic in Computer Science, LICS 1996, USA, p. 184. IEEE Computer Society (1996)
Davies, R.: A temporal logic approach to binding-time analysis. J. ACM 64(1), 1–45 (2017)
Dreyer, D., Crary, K., Harper, R.: A type system for higher-order modules. In: Proceedings of the 30th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 2003, pp. 236–249. Association for Computing Machinery, New York (2003)
Elsman, M.: Static interpretation of modules. In: Proceedings of the Fourth ACM SIGPLAN International Conference on Functional Programming, ICFP 1999, pp. 208–219. Association for Computing Machinery, New York (1999)
Elsman, M., Henriksen, T., Annenkov, D., Oancea, C.E.: Static interpretation of higher-order modules in Futhark: functional GPU programming in the large. Proc. ACM Program. Lang. 2(ICFP), 1–30 (2018)
Flatt, M.: Composable and compilable macros: you want it when? In: Proceedings of the Seventh ACM SIGPLAN International Conference on Functional Programming, ICFP 2002, pp. 72–83. Association for Computing Machinery, New York (2002)
Girard, J.Y.: Interprétation fonctionnelle et élimination des coupures de l’arithmétique d’ordre supérieur. Ph.D. thesis, Université Paris VII (1972)
Glück, R., Jørgensen, J.: Efficient multi-level generating extensions for program specialization. In: Hermenegildo, M., Swierstra, S.D. (eds.) PLILPS 1995. LNCS, vol. 982, pp. 259–278. Springer, Heidelberg (1995). https://doi.org/10.1007/BFb0026825
Hanada, Y., Igarashi, A.: On cross-stage persistence in multi-stage programming. In: Codish, M., Sumii, E. (eds.) FLOPS 2014. LNCS, vol. 8475, pp. 103–118. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-07151-0_7
Harper, R., Lillibridge, M.: A type-theoretic approach to higher-order modules with sharing. In: Proceedings of the 21st ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 1994, pp. 123–137. Association for Computing Machinery, New York (1994)
Harper, R., Stone, C.: A type-theoretic interpretation of standard ML, pp. 341–387. MIT Press, Cambridge (2000)
Inoue, J., Kiselyov, O., Kameyama, Y.: Staging beyond terms: prospects and challenges. In: Proceedings of the 2016 ACM SIGPLAN Workshop on Partial Evaluation and Program Manipulation, PEPM 2016, pp. 103–108. Association for Computing Machinery, New York (2016)
Kiselyov, O.: Let-insertion as a primitive (2017). https://okmij.org/ftp/ML/MetaOCaml.html#genlet. Accessed 10 Dec 2023
Kiselyov, O., Kameyama, Y., Sudo, Y.: Refined environment classifiers: type- and scope-safe code generation with mutable cells. In: Igarashi, A. (ed.) APLAS 2016. LNCS, vol. 10017, pp. 271–291. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-47958-3_15
Leroy, X.: Manifest types, modules, and separate compilation. In: Proceedings of the 21st ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 1994, pp. 109–122. Association for Computing Machinery, New York (1994)
Lillibridge, M.: Translucent sums: a foundation for higher-order module systems. Ph.D. thesis, Carnegie Mellon University (1997)
MacQueen, D.: Modules for standard ML. In: Proceedings of the 1984 ACM Symposium on LISP and Functional Programming, LFP 1984, pp. 198–207. Association for Computing Machinery, New York (1984)
Pierce, B.C.: Types and Programming Languages, 1st edn. The MIT Press, Cambridge (2002)
Rossberg, A., Russo, C., Dreyer, D.: F-ing modules. In: Proceedings of the 5th ACM SIGPLAN Workshop on Types in Language Design and Implementation, TLDI 2010, pp. 89–102. Association for Computing Machinery, New York (2010)
Rossberg, A., Russo, C., Dreyer, D.: F-ing modules. J. Funct. Program. 24(5), 529–607 (2014)
Russo, C.V.: First-class structures for standard ML. In: Smolka, G. (ed.) ESOP 2000. LNCS, vol. 1782, pp. 336–350. Springer, Heidelberg (2000). https://doi.org/10.1007/3-540-46425-5_22
Sato, Y., Kameyama, Y., Watanabe, T.: Module generation without regret. In: Proceedings of the 2020 ACM SIGPLAN Workshop on Partial Evaluation and Program Manipulation, PEPM 2020, pp. 1–13. Association for Computing Machinery, New York (2020)
Shao, Z.: Transparent modules with fully syntatic signatures. In: Proceedings of the Fourth ACM SIGPLAN International Conference on Functional Programming, ICFP 1999, pp. 220–232. Association for Computing Machinery, New York (1999)
Suwa, T.:
 (2017–2023). https://github.com/gfngfn/SATySFi. Accessed 10 Dec 2023
(2017–2023). https://github.com/gfngfn/SATySFi. Accessed 10 Dec 2023Suwa, T.: Develop
 0.1.0 (2021–2023). https://github.com/gfngfn/SATySFi/pull/294. Accessed 10 Dec 2023
0.1.0 (2021–2023). https://github.com/gfngfn/SATySFi/pull/294. Accessed 10 Dec 2023Taha, W.: Multi-Stage Programming: Its Theory and Applications. Oregon Graduate Institute of Science and Technology (1999)
Taha, W., Nielsen, M.F.: Environment classifiers. In: Proceedings of the 30th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 2003, pp. 26–37. Association for Computing Machinery, New York (2003)
Taha, W., Sheard, T.: Multi-stage programming with explicit annotations. SIGPLAN Not. 32(12), 203–217 (1997)
Taha, W., Sheard, T.: MetaML and multi-stage programming with explicit annotations. Theor. Comput. Sci. 248(1), 211–242 (2000)
Tsukada, T., Igarashi, A.: A logical foundation for environment classifiers. In: Curien, P.L. (ed.) TLCA 2009. LNCS, vol. 5608, pp. 341–355. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-02273-9_25
Watanabe, T., Kameyama, Y.: Program generation for ML modules (short paper). In: Proceedings of the ACM SIGPLAN Workshop on Partial Evaluation and Program Manipulation, PEPM 2018, pp. 60–66. Association for Computing Machinery, New York (2017)
Xie, N., White, L., Nicole, O., Yallop, J.: MacoCaml: staging composable and compilable macros. Proc. ACM Program. Lang. 7(ICFP), 604–648 (2023)
Yallop, J., White, L.: Modular macros. In: OCaml Users and Developers Workshop, vol. 6 (2015)
Yuse, Y., Igarashi, A.: A modal type system for multi-level generating extensions with persistent code. In: Proceedings of the 8th ACM SIGPLAN International Conference on Principles and Practice of Declarative Programming, PPDP 2006, pp. 201–212. Association for Computing Machinery, New York (2006)
 (2017–2023).
(2017–2023).  0.1.0 (2021–2023).
0.1.0 (2021–2023). Acknowledgments
We thank the anonymous referees for a number of helpful suggestions. This work is supported in part by JSPS KAKENHI Grant Number JP20H00582.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendices
A An Example Elaboration Involving CSP
Example 2
Consider the following structure:
This will be translated to the following target term:


Module elaboration rules (other than the ones for CSP)

Signature elaboration rules (other than the ones for CSP)

Signature subtyping rules (other than the ones for CSP)

Syntax sugars for System F\(\omega ^{\langle \rangle }\) terms used in elaboration rules

Typing rules for System F\(\omega ^{\langle \rangle }\) (without CSP)

Operational semantics of System F\(\omega ^{\langle \rangle }\) (without CSP)

Well-formedness, kinding, and type equivalence in System F\(\omega ^{\langle \rangle }\)

Type-level parallel reduction relation for System F\(\omega ^{\langle \rangle }\) types

Miscellaneous definitions
B Complete Definitions
This section displays definitions including ones omitted from the text.
-
Figure 10: Module elaboration rules (other than the ones for CSP)
-
Figure 11: Signature elaboration rules (other than the ones for CSP)
-
Figure 12: Signature subtyping rules (other than the ones for CSP)
-
Figure 13: Syntax sugars for System F\(\omega ^{\langle \rangle }\) terms used in elaboration rules
-
Figure 14: Typing rules for System F\(\omega ^{\langle \rangle }\) (without CSP)
-
Figure 15: Operational semantics of System F\(\omega ^{\langle \rangle }\) (without CSP)
-
Figure 16: Well-formedness, kinding, and type equivalence in System F\(\omega ^{\langle \rangle }\)
-
Figure 17: Type-level parallel reduction relation for System F\(\omega ^{\langle \rangle }\) types
-
Figure 18: Miscellaneous definitions
C Proofs for Target Type Safety
Lemma 1
(Substitution of terms). If \( \gamma , x : ( \tau ' ) ^{ s' } , \gamma ' \vdash ^{ s } e : \tau \) and \( \gamma \vdash ^{ s' } e' : \tau ' \), then \( \gamma , \gamma ' \vdash ^{ s } [ e' / x ] e : \tau \).
Proof
By straightforward induction on the derivation of \( \gamma , x : ( \tau ' ) ^{ s' } , \gamma ' \vdash ^{ s } e : \tau \).
Lemma 2
(Substitution of types).
-
1.
If \( \gamma , \alpha \mathrel {::} \kappa ' , \gamma ' \vdash \tau \mathrel {::} \kappa \) and \( \gamma \vdash \tau ' \mathrel {::} \kappa ' \), then \( \gamma , [ \tau ' / \alpha ] \gamma ' \vdash [ \tau ' / \alpha ] \tau \mathrel {::} \kappa \).
-
2.
\( \tau _{{\textrm{1}}} \equiv \tau _{{\textrm{2}}} \) implies \( [ \tau ' / \alpha ] \tau _{{\textrm{1}}} \equiv [ \tau ' / \alpha ] \tau _{{\textrm{2}}} \).
-
3.
If \( \gamma , \alpha \mathrel {::} \kappa ' , \gamma ' \vdash ^{ s } e : \tau \) and \( \gamma \vdash \tau ' \mathrel {::} \kappa ' \), then \( \gamma , [ \tau ' / \alpha ] \gamma ' \vdash ^{ s } [ \tau ' / \alpha ] e : \tau \).
Proof
By straightforward induction on the derivation of \( \gamma , \alpha \mathrel {::} \kappa ' , \gamma ' \vdash \tau \mathrel {::} \kappa \), \( \tau _{{\textrm{1}}} \equiv \tau _{{\textrm{2}}} \), and \( \gamma , \alpha \mathrel {::} \kappa ' , \gamma ' \vdash ^{ s } e : \tau \), respectively.
Lemma 3
(Substitution of stages).
-
1.
If \( \gamma , \sigma , \gamma ' \vdash s \) and \( \gamma \vdash s' \), then \( \gamma , [ s' / \sigma ] \gamma ' \vdash [ s' / \sigma ] s \).
-
2.
\( \tau _{{\textrm{1}}} \equiv \tau _{{\textrm{2}}} \) implies \( [ s' / \sigma ] \tau _{{\textrm{1}}} \equiv [ s' / \sigma ] \tau _{{\textrm{2}}} \).
-
3.
If \( \gamma , \sigma , \gamma ' \vdash \tau \mathrel {::} \kappa \) and \( \gamma \vdash s' \), then \( \gamma , [ s' / \sigma ] \gamma ' \vdash [ s' / \sigma ] \tau \mathrel {::} \kappa \).
-
4.
If \( \gamma , \sigma , \gamma ' \vdash ^{ s } e : \tau \) and \( \gamma \vdash s' \), then \( \gamma , [ s' / \sigma ] \gamma ' \vdash ^{ [ s' / \sigma ] s } [ s' / \sigma ] e : [ s' / \sigma ] \tau \).
Proof
-
1.
By a case analysis on \(s\) and \(s'\).
-
Case \(s = n\): Trivially holds.
-
Case \(s = n \dotplus \sigma ' \) and \(\sigma ' \ne \sigma \): Easy.
-
Case \(s = n \dotplus \sigma \):
-
Case \(s' = n'\): We have \( [ s' / \sigma ] s = ( n + n' ) \), which makes the goal trivial.
-
Case \(s' = n' \dotplus \sigma ' \): By \( \gamma \vdash s' \), we have \( \sigma ' \in \gamma \). Since \( [ s' / \sigma ] s = ( n + n' ) \dotplus \sigma ' \), we clearly have \( \gamma , [ s' / \sigma ] \gamma ' \vdash [ s' / \sigma ] s \).
-
-
-
2.
By straightforward induction on the derivation of \( \tau _{{\textrm{1}}} \equiv \tau _{{\textrm{2}}} \).
-
3.
By induction on the derivation of \( \gamma , \sigma , \gamma ' \vdash \tau \mathrel {::} \kappa \).
-
Case
 : By IH, we first have \( \gamma , [ s' / \sigma ] ( \gamma ' , \sigma ' ) \vdash [ s' / \sigma ] \tau ' \mathrel {::} *\), namely \( \gamma , [ s' / \sigma ] \gamma ' , \sigma ' \vdash [ s' / \sigma ] \tau ' \mathrel {::} *\) by \(\sigma \ne \sigma '\). This derives
: By IH, we first have \( \gamma , [ s' / \sigma ] ( \gamma ' , \sigma ' ) \vdash [ s' / \sigma ] \tau ' \mathrel {::} *\), namely \( \gamma , [ s' / \sigma ] \gamma ' , \sigma ' \vdash [ s' / \sigma ] \tau ' \mathrel {::} *\) by \(\sigma \ne \sigma '\). This derives
 .
. -
Case
 : By IH for \( \gamma , \sigma , \gamma ' \vdash \tau ' \mathrel {::} *\), we have \( \gamma , [ s' / \sigma ] \gamma ' \vdash [ s' / \sigma ] \tau ' \mathrel {::} *\).
: By IH for \( \gamma , \sigma , \gamma ' \vdash \tau ' \mathrel {::} *\), we have \( \gamma , [ s' / \sigma ] \gamma ' \vdash [ s' / \sigma ] \tau ' \mathrel {::} *\).-
Case where \(\sigma ' \ne \sigma \): Since
 and either \(\gamma \) or \(\gamma '\) contains \(\sigma '\), we can derive:
and either \(\gamma \) or \(\gamma '\) contains \(\sigma '\), we can derive: 
-
Case where \(\sigma ' = \sigma \) and \(s' = n\): We have
 , and we can clearly derive
, and we can clearly derive
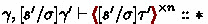 by repeatedly applying TK-Code.
by repeatedly applying TK-Code. -
Case where \(\sigma ' = \sigma \) and
 and can derive
and can derive
 in the same manner as the previous case. Since we have \( \sigma '' \in \gamma \) by \( \gamma \vdash s' \), we can derive:
in the same manner as the previous case. Since we have \( \sigma '' \in \gamma \) by \( \gamma \vdash s' \), we can derive: 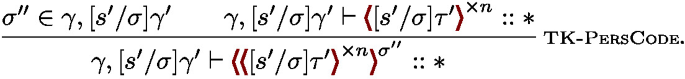
-
-
The other cases are straightforward.
-
-
4.
By induction on the derivation of \( \gamma , \sigma , \gamma ' \vdash ^{ s } e : \tau \).
-
Case
 : By IH, we first have \( \gamma , [ s' / \sigma ] ( \gamma ' , \sigma ' ) \vdash ^{ 0 } [ s' / \sigma ] e' : [ s' / \sigma ] \tau ' \), namely \( \gamma , [ s' / \sigma ] \gamma ' , \sigma ' \vdash ^{ 0 } [ s' / \sigma ] e' : [ s' / \sigma ] \tau ' \) by \(\sigma \ne \sigma '\). This enables us to derive:
: By IH, we first have \( \gamma , [ s' / \sigma ] ( \gamma ' , \sigma ' ) \vdash ^{ 0 } [ s' / \sigma ] e' : [ s' / \sigma ] \tau ' \), namely \( \gamma , [ s' / \sigma ] \gamma ' , \sigma ' \vdash ^{ 0 } [ s' / \sigma ] e' : [ s' / \sigma ] \tau ' \) by \(\sigma \ne \sigma '\). This enables us to derive: 
-
Case
 : By IH, we have \( \gamma , [ s' / \sigma ] \gamma ' \vdash ^{ 0 } [ s' / \sigma ] e_{{\textrm{1}}} : [ s' / \sigma ] ( \forall \sigma _{{\textrm{1}}} .\ \tau _{{\textrm{1}}} ) \). We can assume \(\sigma _{{\textrm{1}}} \ne \sigma \) w.l.o.g. here, and thus have \( [ s' / \sigma ] ( \forall \sigma _{{\textrm{1}}} .\ \tau _{{\textrm{1}}} ) = \forall \sigma _{{\textrm{1}}} .\ [ s' / \sigma ] \tau _{{\textrm{1}}} \). By 1, from \( \gamma , \sigma , \gamma ' \vdash s_{{\textrm{2}}} \), we have \( \gamma , [ s' / \sigma ] \gamma ' \vdash [ s' / \sigma ] s_{{\textrm{2}}} \). Therefore, we can derive:
: By IH, we have \( \gamma , [ s' / \sigma ] \gamma ' \vdash ^{ 0 } [ s' / \sigma ] e_{{\textrm{1}}} : [ s' / \sigma ] ( \forall \sigma _{{\textrm{1}}} .\ \tau _{{\textrm{1}}} ) \). We can assume \(\sigma _{{\textrm{1}}} \ne \sigma \) w.l.o.g. here, and thus have \( [ s' / \sigma ] ( \forall \sigma _{{\textrm{1}}} .\ \tau _{{\textrm{1}}} ) = \forall \sigma _{{\textrm{1}}} .\ [ s' / \sigma ] \tau _{{\textrm{1}}} \). By 1, from \( \gamma , \sigma , \gamma ' \vdash s_{{\textrm{2}}} \), we have \( \gamma , [ s' / \sigma ] \gamma ' \vdash [ s' / \sigma ] s_{{\textrm{2}}} \). Therefore, we can derive: 
i.e., we have \( \gamma , [ s' / \sigma ] \gamma ' \vdash ^{ 0 } [ s' / \sigma ] ( e_{{\textrm{1}}} \mathbin {\uparrow } s_{{\textrm{2}}} ) : [ s' / \sigma ] ( [ s_{{\textrm{2}}} / \sigma _{{\textrm{1}}} ] \tau _{{\textrm{1}}} ) \).
-
Case
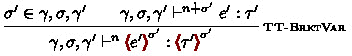 : By IH, we have \( \gamma , [ s' / \sigma ] \gamma ' \vdash ^{ [ s' / \sigma ] ( n \dotplus \sigma ' ) } [ s' / \sigma ] e' : [ s' / \sigma ] \tau ' \).
: By IH, we have \( \gamma , [ s' / \sigma ] \gamma ' \vdash ^{ [ s' / \sigma ] ( n \dotplus \sigma ' ) } [ s' / \sigma ] e' : [ s' / \sigma ] \tau ' \).-
Case \(\sigma ' \ne \sigma \): Since \( [ s' / \sigma ] ( n \dotplus \sigma ' ) = n \dotplus \sigma ' \) and either \(\gamma \) or \(\gamma '\) contains \(\sigma '\), we can derive:

i.e., we have
 .
. -
Case \(\sigma ' = \sigma \) and \(s' = n'\): We have \( [ s' / \sigma ] ( n \dotplus \sigma ' ) = ( n + n' ) \), and thus by repeatedly applying TT-Brkt, we can derive:

i.e., we have
 .
. -
Case \(\sigma ' = \sigma \) and \(s' = n' \dotplus \sigma '' \): We have \( [ s' / \sigma ] ( n \dotplus \sigma ' ) = ( n + n' ) \dotplus \sigma '' \), and we can derive
 in the same way as the previous case. Since \( \sigma '' \in \gamma \) holds by \( \gamma \vdash s' \), we can further derive:
in the same way as the previous case. Since \( \sigma '' \in \gamma \) holds by \( \gamma \vdash s' \), we can further derive: 
i.e., we have
 .
.
-
-
Case
 : By IH, we first have
: By IH, we first have
 .
.-
Case \(\sigma ' \ne \sigma \): Since
 , we can derive:
, we can derive: 
-
Case \(\sigma ' = \sigma \) and \(s' = n'\): We have
 , and this enables us to derive:
, and this enables us to derive: 
i.e., we have
 .
. -
Case \(\sigma ' = \sigma \) and \(s' = n' \dotplus \sigma '' \): We have
 . Since we have \( \sigma '' \in \gamma \) by \( \gamma \vdash s' \), we can derive:
. Since we have \( \sigma '' \in \gamma \) by \( \gamma \vdash s' \), we can derive: 
i.e., we have
 .
.
-
-
Case
 : By IH, we have \( \gamma , [ s' / \sigma ] \gamma ' \vdash ^{ [ s' / \sigma ] s } [ s' / \sigma ] e : [ s' / \sigma ] \tau ' \). By 2 and 3, we also have \( [ s' / \sigma ] \tau \equiv [ s' / \sigma ] \tau ' \) and \( \gamma , [ s' / \sigma ] \gamma ' \vdash [ s' / \sigma ] \tau \mathrel {::} *\), respectively. Therefore, we can derive:
: By IH, we have \( \gamma , [ s' / \sigma ] \gamma ' \vdash ^{ [ s' / \sigma ] s } [ s' / \sigma ] e : [ s' / \sigma ] \tau ' \). By 2 and 3, we also have \( [ s' / \sigma ] \tau \equiv [ s' / \sigma ] \tau ' \) and \( \gamma , [ s' / \sigma ] \gamma ' \vdash [ s' / \sigma ] \tau \mathrel {::} *\), respectively. Therefore, we can derive: 
-
The other cases are straightforward.
-
 : By IH, we first have
: By IH, we first have  .
. : By IH for
: By IH for  and either
and either 
 , and we can clearly derive
, and we can clearly derive
 by repeatedly applying
by repeatedly applying  and can derive
and can derive
 in the same manner as the previous case. Since we have
in the same manner as the previous case. Since we have 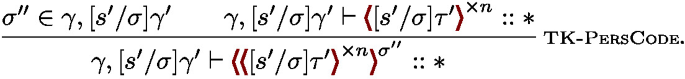
 : By IH, we first have
: By IH, we first have 
 : By IH, we have
: By IH, we have 
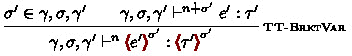 : By IH, we have
: By IH, we have 
 .
.
 .
. in the same way as the previous case. Since
in the same way as the previous case. Since 
 .
. : By IH, we first have
: By IH, we first have
 .
. , we can derive:
, we can derive: 
 , and this enables us to derive:
, and this enables us to derive: 
 .
. . Since we have
. Since we have 
 .
. : By IH, we have
: By IH, we have 
Lemma 4
(Equivalence of the two equivalences). \( \tau _{{\textrm{1}}} \equiv \tau _{{\textrm{2}}} \) iff
 .
.
Proof
Mostly the same as Lemma 30.3.5 of [22].
Lemma 5
\( \tau _{{\textrm{1}}} \Rrightarrow \tau '_{{\textrm{1}}} \) implies \( [ \tau _{{\textrm{1}}} / \alpha ] \tau \Rrightarrow [ \tau '_{{\textrm{1}}} / \alpha ] \tau \).
Proof
By induction on the structure of \(\tau \).
Lemma 6
If \( \tau _{{\textrm{1}}} \Rrightarrow \tau '_{{\textrm{1}}} \) and \( \tau _{{\textrm{2}}} \Rrightarrow \tau '_{{\textrm{2}}} \), then \( [ \tau _{{\textrm{1}}} / \alpha ] \tau _{{\textrm{2}}} \Rrightarrow [ \tau '_{{\textrm{1}}} / \alpha ] \tau '_{{\textrm{2}}} \).
Proof
Do the same thing as Lemma 30.3.7 of [22] by using Lemma 5.
Lemma 7
(One-step diamond property). If \( \tau \Rrightarrow \tau _{{\textrm{1}}} \) and \( \tau \Rrightarrow \tau _{{\textrm{2}}} \), then there exists \(\tau '\) such that \( \tau _{{\textrm{1}}} \Rrightarrow \tau ' \) and \( \tau _{{\textrm{2}}} \Rrightarrow \tau ' \).
Proof
By induction on the derivation of \( \tau \Rrightarrow \tau _{{\textrm{1}}} \).
-
Case
 : The last rule for deriving \( \tau \Rrightarrow \tau _{{\textrm{2}}} \) is one of the following:
: The last rule for deriving \( \tau \Rrightarrow \tau _{{\textrm{2}}} \) is one of the following:-
Case
 is trivial.
is trivial. -
Case
 : By IH, there exist \(\tau ''''_{{\textrm{1}}}\) and \(\tau ''''_{{\textrm{2}}}\) such that \( \tau ''_{{\textrm{1}}} \Rrightarrow \tau ''''_{{\textrm{1}}} \), \( \tau '''_{{\textrm{1}}} \Rrightarrow \tau ''''_{{\textrm{1}}} \), \( \tau ''_{{\textrm{2}}} \Rrightarrow \tau ''''_{{\textrm{2}}} \), and \( \tau '''_{{\textrm{2}}} \Rrightarrow \tau ''''_{{\textrm{2}}} \). Therefore, by Lemma 6, we have \( [ \tau ''_{{\textrm{2}}} / \alpha ] \tau ''_{{\textrm{1}}} \Rrightarrow [ \tau ''''_{{\textrm{2}}} / \alpha ] \tau ''''_{{\textrm{1}}} \) and \( [ \tau '''_{{\textrm{2}}} / \alpha ] \tau '''_{{\textrm{1}}} \Rrightarrow [ \tau ''''_{{\textrm{2}}} / \alpha ] \tau ''''_{{\textrm{1}}} \).
: By IH, there exist \(\tau ''''_{{\textrm{1}}}\) and \(\tau ''''_{{\textrm{2}}}\) such that \( \tau ''_{{\textrm{1}}} \Rrightarrow \tau ''''_{{\textrm{1}}} \), \( \tau '''_{{\textrm{1}}} \Rrightarrow \tau ''''_{{\textrm{1}}} \), \( \tau ''_{{\textrm{2}}} \Rrightarrow \tau ''''_{{\textrm{2}}} \), and \( \tau '''_{{\textrm{2}}} \Rrightarrow \tau ''''_{{\textrm{2}}} \). Therefore, by Lemma 6, we have \( [ \tau ''_{{\textrm{2}}} / \alpha ] \tau ''_{{\textrm{1}}} \Rrightarrow [ \tau ''''_{{\textrm{2}}} / \alpha ] \tau ''''_{{\textrm{1}}} \) and \( [ \tau '''_{{\textrm{2}}} / \alpha ] \tau '''_{{\textrm{1}}} \Rrightarrow [ \tau ''''_{{\textrm{2}}} / \alpha ] \tau ''''_{{\textrm{1}}} \). -
Case
 : By IH, from \( \tau '_{{\textrm{2}}} \Rrightarrow \tau ''_{{\textrm{2}}} \) and \( \tau '_{{\textrm{2}}} \Rrightarrow \tau '''_{{\textrm{2}}} \), there exists \(\tau ''''_{{\textrm{2}}}\) such that \( \tau ''_{{\textrm{2}}} \Rrightarrow \tau ''''_{{\textrm{2}}} \) and \( \tau '''_{{\textrm{2}}} \Rrightarrow \tau ''''_{{\textrm{2}}} \). The last rule for deriving \( ( \mathrm {\Lambda } \alpha \mathrel {::} \kappa .\ \tau '_{{\textrm{1}}} ) \Rrightarrow \tau _{{\textrm{0}}} \) is either of the following:
: By IH, from \( \tau '_{{\textrm{2}}} \Rrightarrow \tau ''_{{\textrm{2}}} \) and \( \tau '_{{\textrm{2}}} \Rrightarrow \tau '''_{{\textrm{2}}} \), there exists \(\tau ''''_{{\textrm{2}}}\) such that \( \tau ''_{{\textrm{2}}} \Rrightarrow \tau ''''_{{\textrm{2}}} \) and \( \tau '''_{{\textrm{2}}} \Rrightarrow \tau ''''_{{\textrm{2}}} \). The last rule for deriving \( ( \mathrm {\Lambda } \alpha \mathrel {::} \kappa .\ \tau '_{{\textrm{1}}} ) \Rrightarrow \tau _{{\textrm{0}}} \) is either of the following:-
* Case
 : Since \(\tau _{{\textrm{0}}} = \mathrm {\Lambda } \alpha \mathrel {::} \kappa .\ \tau '_{{\textrm{1}}} \), we can derive
: Since \(\tau _{{\textrm{0}}} = \mathrm {\Lambda } \alpha \mathrel {::} \kappa .\ \tau '_{{\textrm{1}}} \), we can derive
 and, at the same time, have \( [ \tau ''_{{\textrm{2}}} / \alpha ] \tau ''_{{\textrm{1}}} \Rrightarrow [ \tau ''''_{{\textrm{2}}} / \alpha ] \tau ''_{{\textrm{1}}} \) by Lemma 5 and \( \tau ''_{{\textrm{2}}} \Rrightarrow \tau ''''_{{\textrm{2}}} \).
and, at the same time, have \( [ \tau ''_{{\textrm{2}}} / \alpha ] \tau ''_{{\textrm{1}}} \Rrightarrow [ \tau ''''_{{\textrm{2}}} / \alpha ] \tau ''_{{\textrm{1}}} \) by Lemma 5 and \( \tau ''_{{\textrm{2}}} \Rrightarrow \tau ''''_{{\textrm{2}}} \). -
* Case
 : By IH, from \( \tau '_{{\textrm{1}}} \Rrightarrow \tau ''_{{\textrm{1}}} \) and \( \tau '_{{\textrm{1}}} \Rrightarrow \tau '''_{{\textrm{1}}} \), there exists \(\tau ''''_{{\textrm{1}}}\) such that \( \tau ''_{{\textrm{1}}} \Rrightarrow \tau ''''_{{\textrm{1}}} \) and \( \tau '''_{{\textrm{1}}} \Rrightarrow \tau ''''_{{\textrm{1}}} \). Since \(\tau _{{\textrm{0}}} = \mathrm {\Lambda } \alpha \mathrel {::} \kappa .\ \tau '''_{{\textrm{1}}} \), we can derive
: By IH, from \( \tau '_{{\textrm{1}}} \Rrightarrow \tau ''_{{\textrm{1}}} \) and \( \tau '_{{\textrm{1}}} \Rrightarrow \tau '''_{{\textrm{1}}} \), there exists \(\tau ''''_{{\textrm{1}}}\) such that \( \tau ''_{{\textrm{1}}} \Rrightarrow \tau ''''_{{\textrm{1}}} \) and \( \tau '''_{{\textrm{1}}} \Rrightarrow \tau ''''_{{\textrm{1}}} \). Since \(\tau _{{\textrm{0}}} = \mathrm {\Lambda } \alpha \mathrel {::} \kappa .\ \tau '''_{{\textrm{1}}} \), we can derive
 and, at the same time, have \( [ \tau '''_{{\textrm{2}}} / \alpha ] \tau '''_{{\textrm{1}}} \Rrightarrow [ \tau ''''_{{\textrm{2}}} / \alpha ] \tau ''''_{{\textrm{1}}} \) by Lemma 6, \( \tau '''_{{\textrm{1}}} \Rrightarrow \tau ''''_{{\textrm{1}}} \), and \( \tau '''_{{\textrm{2}}} \Rrightarrow \tau ''''_{{\textrm{2}}} \).
and, at the same time, have \( [ \tau '''_{{\textrm{2}}} / \alpha ] \tau '''_{{\textrm{1}}} \Rrightarrow [ \tau ''''_{{\textrm{2}}} / \alpha ] \tau ''''_{{\textrm{1}}} \) by Lemma 6, \( \tau '''_{{\textrm{1}}} \Rrightarrow \tau ''''_{{\textrm{1}}} \), and \( \tau '''_{{\textrm{2}}} \Rrightarrow \tau ''''_{{\textrm{2}}} \).
-
-
 : The last rule for deriving
: The last rule for deriving  is trivial.
is trivial. : By IH, there exist
: By IH, there exist  : By IH, from
: By IH, from  : Since
: Since  and, at the same time, have
and, at the same time, have  : By IH, from
: By IH, from  and, at the same time, have
and, at the same time, have The other cases are more straightforward.
Lemma 8
(Confluence). If \( \tau \Rrightarrow ^{*} \tau _{{\textrm{1}}} \) and \( \tau \Rrightarrow ^{*} \tau _{{\textrm{2}}} \), then there exists \(\tau '\) such that \( \tau _{{\textrm{1}}} \Rrightarrow ^{*} \tau ' \) and \( \tau _{{\textrm{2}}} \Rrightarrow ^{*} \tau ' \).
Proof
By repeated use of Lemma 7.
Lemma 9
If
 , then there exists \(\tau '\) such that
, then there exists \(\tau '\) such that
 and
and
 .
.
Proof
By induction on the “length” of
 .
.
-
Case \(\tau _{{\textrm{1}}} = \tau _{{\textrm{2}}}\) trivially holds by \(\tau ' := \tau _{{\textrm{1}}}\).
-
Case
 and
and
 (where
(where
 means the transposition of \(\Rrightarrow \)): By IH, there exists \(\tau ''\) such that
means the transposition of \(\Rrightarrow \)): By IH, there exists \(\tau ''\) such that
 and
and
 . By Lemma 8, from \( \tau _{{\textrm{0}}} \Rrightarrow \tau \) and
. By Lemma 8, from \( \tau _{{\textrm{0}}} \Rrightarrow \tau \) and
 , there exists \(\tau '\) such that
, there exists \(\tau '\) such that
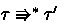 and
and
 . By transitivity, from
. By transitivity, from
 and
and
 , we have
, we have
 . Thus, both
. Thus, both
 and
and
 hold.
hold. -
Case \( \tau _{{\textrm{1}}} \Rrightarrow \tau _{{\textrm{0}}} \) and
 : Again, there exists \(\tau '\) such that
: Again, there exists \(\tau '\) such that
 by IH. Then, by transitivity, from \( \tau _{{\textrm{1}}} \Rrightarrow \tau _{{\textrm{0}}} \) and
by IH. Then, by transitivity, from \( \tau _{{\textrm{1}}} \Rrightarrow \tau _{{\textrm{0}}} \) and
 , we also have
, we also have
 .
.
 and
and
 (where
(where
 means the transposition of
means the transposition of  and
and
 . By Lemma
. By Lemma  , there exists
, there exists 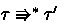 and
and
 . By transitivity, from
. By transitivity, from
 and
and
 , we have
, we have
 . Thus, both
. Thus, both
 and
and
 hold.
hold. : Again, there exists
: Again, there exists  by IH. Then, by transitivity, from
by IH. Then, by transitivity, from  , we also have
, we also have
 .
.Corollary 1
If \( \tau _{{\textrm{1}}} \equiv \tau _{{\textrm{2}}} \), then there exists \(\tau '\) such that
 and
and
 .
.
Proof
Immediate from Lemma 4 and Lemma 9.
Lemma 10
(Preservation of forms by reduction on types).
-
1.
If
 , then there exist \(\tau '_{{\textrm{1}}}\) and \(\tau '_{{\textrm{2}}}\) such that \(\tau ' = \tau '_{{\textrm{1}}} \rightarrow \tau '_{{\textrm{2}}} \),
, then there exist \(\tau '_{{\textrm{1}}}\) and \(\tau '_{{\textrm{2}}}\) such that \(\tau ' = \tau '_{{\textrm{1}}} \rightarrow \tau '_{{\textrm{2}}} \),
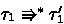 , and
, and
 .
. -
2.
If
 , then there exists \(\tau '_{{\textrm{1}}}\) such that \(\tau ' = \forall \alpha \mathrel {::} \kappa .\ \tau '_{{\textrm{1}}} \) and
, then there exists \(\tau '_{{\textrm{1}}}\) such that \(\tau ' = \forall \alpha \mathrel {::} \kappa .\ \tau '_{{\textrm{1}}} \) and
 .
. -
3.
If
 , then there exists \(\tau '_{{\textrm{1}}}\) such that \(\tau ' = \exists \alpha \mathrel {::} \kappa .\ \tau '_{{\textrm{1}}} \) and
, then there exists \(\tau '_{{\textrm{1}}}\) such that \(\tau ' = \exists \alpha \mathrel {::} \kappa .\ \tau '_{{\textrm{1}}} \) and
 .
. -
4.
If
 , then there exist \(\tau '_{{\textrm{1}}}, \ldots , \tau '_{ m }\) such that \(\tau ' = \{ l_{{\textrm{1}}} : \tau '_{{\textrm{1}}} , \ldots , l_{ m } : \tau '_{ m } \} \) and
, then there exist \(\tau '_{{\textrm{1}}}, \ldots , \tau '_{ m }\) such that \(\tau ' = \{ l_{{\textrm{1}}} : \tau '_{{\textrm{1}}} , \ldots , l_{ m } : \tau '_{ m } \} \) and
 for each \(i\).
for each \(i\). -
5.
If
 , then there exists \(\tau '_{{\textrm{1}}}\) such that
, then there exists \(\tau '_{{\textrm{1}}}\) such that
 and
and
 .
.
 , then there exist
, then there exist 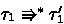 , and
, and
 .
. , then there exists
, then there exists  .
. , then there exists
, then there exists  .
. , then there exist
, then there exist  for each
for each  , then there exists
, then there exists  and
and
 .
.Proof
By straightforward induction on the “length” of reduction sequences.
Lemma 11
(Inversion).
-
1.
If \( \gamma \vdash ^{ s } ( \lambda x : \tau _{{\textrm{1}}} .\ e ) : \tau \), \( \tau \equiv \tau '_{{\textrm{1}}} \rightarrow \tau '_{{\textrm{2}}} \), and
 , then we have \( \tau _{{\textrm{1}}} \equiv \tau '_{{\textrm{1}}} \), \( \gamma , x : \tau _{{\textrm{1}}} ^{ s } \vdash ^{ s } e : \tau '_{{\textrm{2}}} \), and
, then we have \( \tau _{{\textrm{1}}} \equiv \tau '_{{\textrm{1}}} \), \( \gamma , x : \tau _{{\textrm{1}}} ^{ s } \vdash ^{ s } e : \tau '_{{\textrm{2}}} \), and
 .
. -
2.
If \( \gamma \vdash ^{ s } ( \mathrm {\Lambda } \alpha \mathrel {::} \kappa .\ e ) : \tau \), \( \tau \equiv \forall \alpha \mathrel {::} \kappa ' .\ \tau ' \), and
 , then we have \(\kappa = \kappa '\) and \( \gamma , \alpha \mathrel {::} \kappa \vdash ^{ s } e : \tau ' \).
, then we have \(\kappa = \kappa '\) and \( \gamma , \alpha \mathrel {::} \kappa \vdash ^{ s } e : \tau ' \). -
3.
If \( \gamma \vdash ^{ 0 } ( \textbf{pack} \ ( \tau _{{\textrm{1}}} , e )\ \textbf{as} \ \tau _{{\textrm{2}}} ) : \tau \), \( \tau \equiv \exists \alpha \mathrel {::} \kappa .\ \tau '_{{\textrm{1}}} \), and
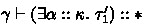 , then we have
, then we have
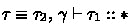 , and \( \gamma \vdash ^{ 0 } e : [ \tau _{{\textrm{1}}} / \alpha ] \tau '_{{\textrm{1}}} \).
, and \( \gamma \vdash ^{ 0 } e : [ \tau _{{\textrm{1}}} / \alpha ] \tau '_{{\textrm{1}}} \). -
4.
If \( \gamma \vdash ^{ s } \{ l_{{\textrm{1}}} = e_{{\textrm{1}}} , \ldots , l_{ m } = e_{ m } \} : \tau \), \( \tau \equiv \{ l_{{\textrm{1}}} : \tau '_{{\textrm{1}}} , \ldots , l_{ m } : \tau '_{ m } \} \), and
 , then, for each \(i \in \{1, \ldots , m\}\), we have \( \gamma \vdash ^{ s } e_{ i } : \tau '_{ i } \).
, then, for each \(i \in \{1, \ldots , m\}\), we have \( \gamma \vdash ^{ s } e_{ i } : \tau '_{ i } \). -
5.
If
 ,
,
 , and
, and
 , then we have \( \gamma \vdash ^{ s + 1 } e : \tau '_{{\textrm{1}}} \).
, then we have \( \gamma \vdash ^{ s + 1 } e : \tau '_{{\textrm{1}}} \). -
6.
If \( \gamma \vdash ^{ 0 } ( \mathrm {\Lambda } \sigma .\ e ) : \tau \), \( \tau \equiv \forall \sigma .\ \tau ' \), and
 , then we have \( \gamma , \sigma \vdash ^{ 0 } e : \tau ' \).
, then we have \( \gamma , \sigma \vdash ^{ 0 } e : \tau ' \).
 , then we have
, then we have  .
. , then we have
, then we have 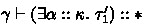 , then we have
, then we have
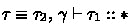 , and
, and  , then, for each
, then, for each  ,
,
 , and
, and
 , then we have
, then we have  , then we have
, then we have Proof
By induction on the derivation. We only show 1; the others can be proved in a similar manner. The last rule for deriving \( \gamma \vdash ^{ s } ( \lambda x : \tau _{{\textrm{1}}} .\ e ) : \tau \) is either TT-TEq or TT-Abs.
-
Case
 : Since we can derive
: Since we can derive
 , we have \( \tau _{{\textrm{1}}} \equiv \tau '_{{\textrm{1}}} \), \( \gamma , x : \tau _{{\textrm{1}}} ^{ s } \vdash ^{ s } e : \tau '_{{\textrm{2}}} \), and
, we have \( \tau _{{\textrm{1}}} \equiv \tau '_{{\textrm{1}}} \), \( \gamma , x : \tau _{{\textrm{1}}} ^{ s } \vdash ^{ s } e : \tau '_{{\textrm{2}}} \), and
 by IH.
by IH. -
Case
 : By Collorary 1 and \( \tau _{{\textrm{1}}} \rightarrow \tau _{{\textrm{2}}} \equiv \tau '_{{\textrm{1}}} \rightarrow \tau '_{{\textrm{2}}} \), there exists \(\tau ''\) such that
: By Collorary 1 and \( \tau _{{\textrm{1}}} \rightarrow \tau _{{\textrm{2}}} \equiv \tau '_{{\textrm{1}}} \rightarrow \tau '_{{\textrm{2}}} \), there exists \(\tau ''\) such that
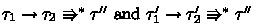 . Then, by Lemma 10, there exist \(\tau ''_{{\textrm{1}}}\) and \(\tau ''_{{\textrm{2}}}\) such that \(\tau '' = \tau ''_{{\textrm{1}}} \rightarrow \tau ''_{{\textrm{2}}} \),
. Then, by Lemma 10, there exist \(\tau ''_{{\textrm{1}}}\) and \(\tau ''_{{\textrm{2}}}\) such that \(\tau '' = \tau ''_{{\textrm{1}}} \rightarrow \tau ''_{{\textrm{2}}} \),
 ,
,
 ,
,
 , and
, and
 . Thus, by Lemma 4, we have \( \tau _{{\textrm{2}}} \equiv \tau ''_{{\textrm{2}}} \) and \( \tau ''_{{\textrm{2}}} \equiv \tau '_{{\textrm{2}}} \). Since
. Thus, by Lemma 4, we have \( \tau _{{\textrm{2}}} \equiv \tau ''_{{\textrm{2}}} \) and \( \tau ''_{{\textrm{2}}} \equiv \tau '_{{\textrm{2}}} \). Since
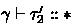 holds by tracing back the derivation of the assumption
holds by tracing back the derivation of the assumption
 , we can derive:
, we can derive: 
 : Since we can derive
: Since we can derive
 , we have
, we have  by IH.
by IH. : By Collorary
: By Collorary 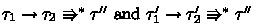 . Then, by Lemma
. Then, by Lemma  ,
,
 ,
,
 , and
, and
 . Thus, by Lemma
. Thus, by Lemma 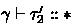 holds by tracing back the derivation of the assumption
holds by tracing back the derivation of the assumption
 , we can derive:
, we can derive: 
Lemma 12
\( \gamma \vdash ^{ s } e : \tau \) implies \( \vdash \gamma \) and
 .
.
Proof
By straightforward induction on the derivation of \( \gamma \vdash ^{ s } e : \tau \).
Theorem 1
(Preservation). If \( \gamma \vdash ^{ n } e : \tau \) and \( e \, {\mathop {\longrightarrow }\limits ^{ n }} \, e' \), then \( \gamma \vdash ^{ n } e' : \tau \).
Proof
By induction on the derivation of \( \gamma \vdash ^{ n } e : \tau \). We implicitly use Lemma 12 in the proof below.
-
Case
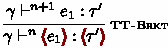 : The last rule for deriving
: The last rule for deriving
 is TE-Brkt, and thus we have \( e_{{\textrm{1}}} {\mathop {\longrightarrow }\limits ^{ n + 1 }} e'_{{\textrm{1}}} \) and
is TE-Brkt, and thus we have \( e_{{\textrm{1}}} {\mathop {\longrightarrow }\limits ^{ n + 1 }} e'_{{\textrm{1}}} \) and
 . By IH, we have \( \gamma \vdash ^{ n + 1 } e'_{{\textrm{1}}} : \tau ' \), and can thereby derive
. By IH, we have \( \gamma \vdash ^{ n + 1 } e'_{{\textrm{1}}} : \tau ' \), and can thereby derive
 .
. -
Case
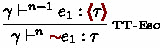 : The last rule for deriving
: The last rule for deriving
 is either TE-Esc1 or TE-Esc2.
is either TE-Esc1 or TE-Esc2.-
Case TE-Esc1 is straightforward by IH.
-
Case TE-Esc2: We have
 , and \(e' = v ^{( 1 )} \). By Lemma 11, we have \( \gamma \vdash ^{ 1 } v ^{( 1 )} : \tau \).
, and \(e' = v ^{( 1 )} \). By Lemma 11, we have \( \gamma \vdash ^{ 1 } v ^{( 1 )} : \tau \).
-
-
Case
 : The last rule for deriving \( ( \textbf{unpack} \ ( \alpha , x ) = e_{{\textrm{1}}} \ \textbf{in} \ e_{{\textrm{2}}} ) \, {\mathop {\longrightarrow }\limits ^{ n }} \, e' \) is either TE-Unpack1 or TE-Unpack2.
: The last rule for deriving \( ( \textbf{unpack} \ ( \alpha , x ) = e_{{\textrm{1}}} \ \textbf{in} \ e_{{\textrm{2}}} ) \, {\mathop {\longrightarrow }\limits ^{ n }} \, e' \) is either TE-Unpack1 or TE-Unpack2.-
Case TE-Unpack1 is straightforward from IH.
-
Case TE-Unpack2: We have \(n = 0 \), \(e_{{\textrm{1}}} = ( \textbf{pack} \ ( \tau '_{{\textrm{1}}} , v ^{( 0 )} )\ \textbf{as} \ \tau ' ) \), and \(e' = [ v ^{( 0 )} / x ] [ \tau '_{{\textrm{1}}} / \alpha ] e_{{\textrm{2}}} \). By Lemma 11, we have \( \exists \alpha \mathrel {::} \kappa .\ \tau _{{\textrm{1}}} \equiv \tau ' \),
 , and \( \gamma \vdash ^{ 0 } v ^{( 0 )} : [ \tau '_{{\textrm{1}}} / \alpha ] \tau _{{\textrm{1}}} \). Then, by Lemma 2, from \( \gamma , \alpha \mathrel {::} \kappa , x : \tau _{{\textrm{1}}} ^{ 0 } \vdash ^{ 0 } e_{{\textrm{2}}} : \tau \) and
, and \( \gamma \vdash ^{ 0 } v ^{( 0 )} : [ \tau '_{{\textrm{1}}} / \alpha ] \tau _{{\textrm{1}}} \). Then, by Lemma 2, from \( \gamma , \alpha \mathrel {::} \kappa , x : \tau _{{\textrm{1}}} ^{ 0 } \vdash ^{ 0 } e_{{\textrm{2}}} : \tau \) and
 , we have \( \gamma , x : [ \tau '_{{\textrm{1}}} / \alpha ] \tau _{{\textrm{1}}} ^{ 0 } \vdash ^{ 0 } [ \tau '_{{\textrm{1}}} / \alpha ] e_{{\textrm{2}}} : [ \tau '_{{\textrm{1}}} / \alpha ] \tau \). Since \(\alpha \not \in \mathop {\textrm{ftv}}(\tau )\) holds by
, we have \( \gamma , x : [ \tau '_{{\textrm{1}}} / \alpha ] \tau _{{\textrm{1}}} ^{ 0 } \vdash ^{ 0 } [ \tau '_{{\textrm{1}}} / \alpha ] e_{{\textrm{2}}} : [ \tau '_{{\textrm{1}}} / \alpha ] \tau \). Since \(\alpha \not \in \mathop {\textrm{ftv}}(\tau )\) holds by
 , we have \( [ \tau '_{{\textrm{1}}} / \alpha ] \tau = \tau \). Therefore, by Lemma 1, we have \( \gamma \vdash ^{ 0 } [ v ^{( 0 )} / x ] [ \tau '_{{\textrm{1}}} / \alpha ] e_{{\textrm{2}}} : \tau \).
, we have \( [ \tau '_{{\textrm{1}}} / \alpha ] \tau = \tau \). Therefore, by Lemma 1, we have \( \gamma \vdash ^{ 0 } [ v ^{( 0 )} / x ] [ \tau '_{{\textrm{1}}} / \alpha ] e_{{\textrm{2}}} : \tau \).
-
-
Case
 : The last rule for deriving \( ( e_{{\textrm{1}}} \mathbin {\uparrow } s_{{\textrm{2}}} ) \, {\mathop {\longrightarrow }\limits ^{ n }} \, e' \) is either TE-StgApp or TE-StgBeta.
: The last rule for deriving \( ( e_{{\textrm{1}}} \mathbin {\uparrow } s_{{\textrm{2}}} ) \, {\mathop {\longrightarrow }\limits ^{ n }} \, e' \) is either TE-StgApp or TE-StgBeta.-
Case TE-StgApp is straightforward by IH.
-
Case TE-StgBeta: We have \(n = 0 \), \(s_{{\textrm{2}}} = n'\), \(e = \mathrm {\Lambda } \sigma .\ e_{{\textrm{11}}} \), and \(e' = [ n' / \sigma ] e_{{\textrm{11}}} \). By Lemma 11, we have \( \gamma , \sigma \vdash ^{ 0 } e_{{\textrm{11}}} : \tau ' \). Therefore, by Lemma 3, we have \( \gamma \vdash ^{ 0 } [ n' / \sigma ] e_{{\textrm{11}}} : [ n' / \sigma ] \tau ' \).
-
-
Cases TT-StgAbs, TT-BrktVar, and TT-EscVar contradict the assumption \( e \, {\mathop {\longrightarrow }\limits ^{ n }} \, e' \).
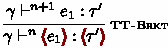 : The last rule for deriving
: The last rule for deriving
 is
is  . By IH, we have
. By IH, we have  .
.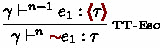 : The last rule for deriving
: The last rule for deriving
 is either
is either  , and
, and  : The last rule for deriving
: The last rule for deriving  , and
, and  , we have
, we have  , we have
, we have  : The last rule for deriving
: The last rule for deriving The other cases can be shown in similar ways by using IH and Lemma 11.
Lemma 13
Suppose \( \vdash ^{\ge 1 } \gamma \) and \(\gamma \) does not contain stage variables.
-
1.
If \( \gamma \vdash ^{ 0 } v ^{( 0 )} : \tau \rightarrow \tau ' \), then \( v ^{( 0 )} \) is of the form \( ( \lambda x : \tau _{{\textrm{1}}} .\ e ) \).
-
2.
If \( \gamma \vdash ^{ 0 } v ^{( 0 )} : \forall \alpha \mathrel {::} \kappa .\ \tau \), then \( v ^{( 0 )} \) is of the form \( ( \mathrm {\Lambda } \alpha \mathrel {::} \kappa .\ e ) \).
-
3.
If \( \gamma \vdash ^{ 0 } v ^{( 0 )} : \exists \alpha \mathrel {::} \kappa .\ \tau \), then \( v ^{( 0 )} \) is of the form \( \textbf{pack} \ ( \tau _{{\textrm{1}}} , e )\ \textbf{as} \ \tau _{{\textrm{2}}} \).
-
4.
If \( \gamma \vdash ^{ 0 } v ^{( 0 )} : \{ l_{{\textrm{1}}} : \tau _{{\textrm{1}}} , \ldots , l_{ m } : \tau _{ m } \} \), then \( v ^{( 0 )} \) is of the form \( \{ l_{{\textrm{1}}} = v_{{\textrm{1}}} ^{( 0 )} , \ldots , l_{ m } = v_{ m } ^{( 0 )} \} \).
-
5.
If
 , then \( v ^{( 0 )} \) is of the form
, then \( v ^{( 0 )} \) is of the form
 .
. -
6.
If \( \gamma \vdash ^{ 0 } v ^{( 0 )} : \forall \sigma .\ \tau \), then \( v ^{( 0 )} \) is of the form \( ( \mathrm {\Lambda } \sigma .\ e ) \).
 , then
, then  .
.Proof
Almost the same as Lemma 30.1.15 of [22]; by contradiction about the form of \( v ^{( 0 )} \) using Lemmata 1 and 10.
Theorem 2
(Progress). If \( \vdash ^{\ge 1 } \gamma \), \( \gamma \vdash ^{ n } e : \tau \), and \(\gamma \) does not contain stage variables, then \(e\) is a value at stage \(n\), or there exists \(e'\) such that \( e \,{\mathop {\longrightarrow }\limits ^{ n }} \, e' \).
Proof
By induction on the derivation of \( \gamma \vdash ^{ n } e : \tau \).
-
Case
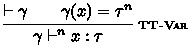 : By the assumption \( \vdash ^{\ge 1 } \gamma \), we have \(n \ge 1 \). Thus, \(x\) is a value at stage \(n \ge 1 \).
: By the assumption \( \vdash ^{\ge 1 } \gamma \), we have \(n \ge 1 \). Thus, \(x\) is a value at stage \(n \ge 1 \). -
Case
 :
:-
Case \(n = 0 \): \( \lambda x : \tau _{{\textrm{1}}} .\ e_{{\textrm{2}}} \) is a value at stage \( 0 \).
-
Case \(n \ge 1 \): Since \( \vdash ^{\ge 1 } \gamma , x : \tau _{{\textrm{1}}} ^{ n } \) holds, we have either of the following by IH:
-
* Case where \(e_{{\textrm{2}}}\) is a value \( v_{{\textrm{2}}} ^{( n )} \): \( \lambda x : \tau _{{\textrm{1}}} .\ v_{{\textrm{2}}} ^{( n )} \) is a value at stage \(n\).
-
* Case where \( e_{{\textrm{2}}} \, {\mathop {\longrightarrow }\limits ^{ n }}\, e'_{{\textrm{2}}} \) for some \(e'_{{\textrm{2}}}\): We can derive:

-
-
-
Case
 :
:-
Case where \( e_{{\textrm{1}}} \,{\mathop {\longrightarrow }\limits ^{ n }} \, e'_{{\textrm{1}}} \) for some \(e'_{{\textrm{1}}}\): We can derive
 .
. -
Case where \(e_{{\textrm{1}}}\) is a value \( v_{{\textrm{1}}} ^{( n )} \) and \( e_{{\textrm{2}}} \, {\mathop {\longrightarrow }\limits ^{ n }} \, e'_{{\textrm{2}}} \) for some \(e'_{{\textrm{2}}}\): We can derive
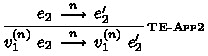 .
. -
Case where both \(e_{{\textrm{1}}}\) and \(e_{{\textrm{2}}}\) are values \( v_{{\textrm{1}}} ^{( n )} \) and \( v_{{\textrm{2}}} ^{( n )} \), respectively:
-
* Case \(n \ge 1 \): \( ( v_{{\textrm{1}}} ^{( n )} \ v_{{\textrm{2}}} ^{( n )} ) \) is a value at stage \(n \ge 1 \).
-
* Case \(n = 0 \): By Lemma 13, \( v_{{\textrm{1}}} ^{( 0 )} \) is of the form \( ( \lambda x : \tau _{{\textrm{11}}} .\ e_{{\textrm{12}}} ) \). Thus, we can derive
 .
.
-
-
-
 : We have \(n \ge 1 \). By IH, one of the following holds:
: We have \(n \ge 1 \). By IH, one of the following holds:-
Case where \( e_{{\textrm{1}}} {\mathop {\longrightarrow }\limits ^{ n - 1 }} e'_{{\textrm{1}}} \) for some \(e'_{{\textrm{1}}}\): We can derive
 .
. -
Case where \(e_{{\textrm{1}}}\) is a value \( v_{{\textrm{1}}} ^{( n - 1 )} \):
-
* Case \(n \ge 2 \):
 is a value at stage \(n\).
is a value at stage \(n\). -
* Case \(n = 1 \): By Lemma 13, \( v_{{\textrm{1}}} ^{( 0 )} \) is of the form
 . Therefore, we can derive
. Therefore, we can derive
 .
.
-
-
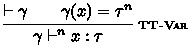 : By the assumption
: By the assumption  :
:
 :
: .
.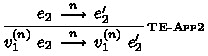 .
. .
. : We have
: We have  .
. is a value at stage
is a value at stage  . Therefore, we can derive
. Therefore, we can derive
 .
.The other cases are similar.
D Proofs for Soundness of Elaboration
Assumption 5
-
1.
If \( \varGamma \vdash \tau \leqslant \tau ' \rightsquigarrow e \), then \(\mathop {\textrm{fsv}}(\tau ) = \mathop {\textrm{fsv}}(\tau ') = \varnothing \) (i.e., neither \(\tau \) nor \(\tau '\) contains free stage variables), \(\mathop {\textrm{fv}}(e) = \varnothing \) (i.e., \(e\) is a closed term),
 ,
,
 , and, for any stage \(s\), we have \( \lfloor \varGamma \rfloor \vdash ^{ s } e : \tau \rightarrow \tau ' \).
, and, for any stage \(s\), we have \( \lfloor \varGamma \rfloor \vdash ^{ s } e : \tau \rightarrow \tau ' \). -
2.
The constructs for source types \(T\) other than
 do not violate the property that \( \varGamma \vdash T {::} \kappa \rightsquigarrow \tau \) implies \( \lfloor \varGamma \rfloor \vdash \tau \mathrel {::} \kappa \).
do not violate the property that \( \varGamma \vdash T {::} \kappa \rightsquigarrow \tau \) implies \( \lfloor \varGamma \rfloor \vdash \tau \mathrel {::} \kappa \). -
3.
The constructs for source expressions \(E\) other than \(x\), \( ( \lambda x : T .\ E ) \), \( ( E \ E ) \), \(P\),
 , or
, or
 do not violate the property that \( \varGamma \vdash ^{ s } E : \tau \rightsquigarrow e \) implies \( \lfloor \varGamma \rfloor \vdash ^{ s } e : \tau \) and \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \).
do not violate the property that \( \varGamma \vdash ^{ s } E : \tau \rightsquigarrow e \) implies \( \lfloor \varGamma \rfloor \vdash ^{ s } e : \tau \) and \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \).
 ,
,
 , and, for any stage
, and, for any stage  do not violate the property that
do not violate the property that  , or
, or
 do not violate the property that
do not violate the property that Theorem 3
(Soundness of Signature Subtyping).
-
1.
If \( \varGamma \vdash \varSigma \leqslant \exists \boldsymbol{b} .\ \varSigma ' \uparrow ( \tau _{ i } ) _{i = 1}^{m} \rightsquigarrow e \) and
 , then \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \varSigma \rfloor \rightarrow \lfloor [ \tau _{ i } / \alpha _{ i } ] _{i = 1}^{m} \varSigma ' \rfloor \), \(\mathop {\textrm{fsv}}( \varSigma ) = \mathop {\textrm{fsv}}( \varSigma ') = \varnothing \), and \( \lfloor \varGamma \rfloor \vdash \tau _{ i } \mathrel {::} \kappa _{ i } \) for each \(i\), where \(\boldsymbol{b} = ( \alpha _{ i } \,{::}\, \kappa _{ i } ) _{i = 1}^{m} \).
, then \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \varSigma \rfloor \rightarrow \lfloor [ \tau _{ i } / \alpha _{ i } ] _{i = 1}^{m} \varSigma ' \rfloor \), \(\mathop {\textrm{fsv}}( \varSigma ) = \mathop {\textrm{fsv}}( \varSigma ') = \varnothing \), and \( \lfloor \varGamma \rfloor \vdash \tau _{ i } \mathrel {::} \kappa _{ i } \) for each \(i\), where \(\boldsymbol{b} = ( \alpha _{ i } \,{::}\, \kappa _{ i } ) _{i = 1}^{m} \). -
2.
\( \varGamma \vdash \varSigma \leqslant \varSigma ' \rightsquigarrow e \) implies
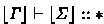 ,
,
 , \(\mathop {\textrm{fsv}}( \varSigma ) = \mathop {\textrm{fsv}}( \varSigma ') = \varnothing \), and \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \varSigma \rfloor \rightarrow \lfloor \varSigma ' \rfloor \).
, \(\mathop {\textrm{fsv}}( \varSigma ) = \mathop {\textrm{fsv}}( \varSigma ') = \varnothing \), and \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \varSigma \rfloor \rightarrow \lfloor \varSigma ' \rfloor \). -
3.
\( \varGamma \vdash \xi \leqslant \xi ' \rightsquigarrow e \) implies
 ,
,
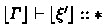 , \(\mathop {\textrm{fsv}}(\xi ) = \mathop {\textrm{fsv}}(\xi ') = \varnothing \), and \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \xi \rfloor \rightarrow \lfloor \xi ' \rfloor \).
, \(\mathop {\textrm{fsv}}(\xi ) = \mathop {\textrm{fsv}}(\xi ') = \varnothing \), and \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \xi \rfloor \rightarrow \lfloor \xi ' \rfloor \).
 , then
, then 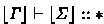 ,
,
 ,
,  ,
,
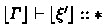 ,
, Proof
By mutual induction on the derivation. We only show the cases of U-Val, U-PersAsPers, and U-PersAsNonPers for 2; the others are almost the same as the corresponding proofs for F-ing Modules [24].
-
Case
 : By \( \varGamma \vdash \tau \leqslant \tau ' \rightsquigarrow e' \) and Assumption 5, we have \( \lfloor \varGamma \rfloor \vdash ^{ n } e' : \tau \rightarrow \tau ' \), \( \lfloor \varGamma \rfloor \vdash \tau \mathrel {::} *\),
: By \( \varGamma \vdash \tau \leqslant \tau ' \rightsquigarrow e' \) and Assumption 5, we have \( \lfloor \varGamma \rfloor \vdash ^{ n } e' : \tau \rightarrow \tau ' \), \( \lfloor \varGamma \rfloor \vdash \tau \mathrel {::} *\),
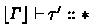 , \(\mathop {\textrm{fsv}}(\tau ) = \mathop {\textrm{fsv}}(\tau ') = \varnothing \), and \(\mathop {\textrm{fv}}(e') = \varnothing \). Since \( \gamma \vdash ^{ n } e' : \tau \rightarrow \tau ' \) holds by the evident weakening, we can derive the following, where
, \(\mathop {\textrm{fsv}}(\tau ) = \mathop {\textrm{fsv}}(\tau ') = \varnothing \), and \(\mathop {\textrm{fv}}(e') = \varnothing \). Since \( \gamma \vdash ^{ n } e' : \tau \rightarrow \tau ' \) holds by the evident weakening, we can derive the following, where
 :
: 
We also have
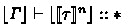 ,
,
 , and
, and
 .
. -
Case
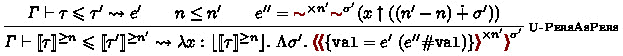 : Let
: Let
 . Similarly to the previous case, we have \( \gamma \vdash ^{ n' \dotplus \sigma ' } e' : \tau \rightarrow \tau ' \), \(\mathop {\textrm{fsv}}(\tau ) = \mathop {\textrm{fsv}}(\tau ') = \varnothing \), and \(\mathop {\textrm{fv}}(e') = \varnothing \). Since \( [ ( n' - n ) \dotplus \sigma ' / \sigma ] \tau = \tau \), we can derive:
. Similarly to the previous case, we have \( \gamma \vdash ^{ n' \dotplus \sigma ' } e' : \tau \rightarrow \tau ' \), \(\mathop {\textrm{fsv}}(\tau ) = \mathop {\textrm{fsv}}(\tau ') = \varnothing \), and \(\mathop {\textrm{fv}}(e') = \varnothing \). Since \( [ ( n' - n ) \dotplus \sigma ' / \sigma ] \tau = \tau \), we can derive: 
-
Case
 : We can derive the following in a manner similar to the previous case, where
: We can derive the following in a manner similar to the previous case, where
 :
: 
 : By
: By 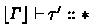 ,
,  :
: 
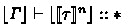 ,
,
 , and
, and
 .
.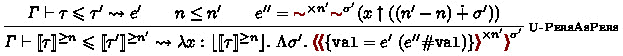 : Let
: Let
 . Similarly to the previous case, we have
. Similarly to the previous case, we have 
 : We can derive the following in a manner similar to the previous case, where
: We can derive the following in a manner similar to the previous case, where
 :
: 
Theorem 4
(Soundness of Elaboration).
-
1.
\( \varGamma \vdash T {::} \kappa \rightsquigarrow \tau \) implies \( \lfloor \varGamma \rfloor \vdash \tau \mathrel {::} \kappa \) and \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \).
-
2.
\( \varGamma \vdash ^{ s } E : \tau \rightsquigarrow e \) implies \( \lfloor \varGamma \rfloor \vdash ^{ s } e : \tau \) and \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \).
-
3.
\( \varGamma \vdash P : \varSigma \rightsquigarrow e \) implies \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \varSigma \rfloor \) and \(\mathop {\textrm{fsv}}( \varSigma ) = \varnothing \).
-
4.
\( \varGamma \vdash D \rightsquigarrow \exists \boldsymbol{b} .\ R \) (resp. \( \varGamma \vdash \boldsymbol{D} \rightsquigarrow \exists \boldsymbol{b} .\ R \)) implies
 and \(\mathop {\textrm{fsv}}( \exists \boldsymbol{b} .\ \mathopen {\{\!|} R \mathclose {|\!\} } ) = \varnothing \).
and \(\mathop {\textrm{fsv}}( \exists \boldsymbol{b} .\ \mathopen {\{\!|} R \mathclose {|\!\} } ) = \varnothing \). -
5.
\( \varGamma \vdash B : \exists \boldsymbol{b} .\ R \rightsquigarrow e \) (resp. \( \varGamma \vdash \boldsymbol{B} : \exists \boldsymbol{b} .\ R \rightsquigarrow e \)) implies \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \exists \boldsymbol{b} .\ \mathopen {\{\!|} R \mathclose {|\!\} } \rfloor \) and \(\mathop {\textrm{fsv}}( \exists \boldsymbol{b} .\ \mathopen {\{\!|} R \mathclose {|\!\} } ) = \varnothing \).
-
6.
\( \varGamma \vdash S \rightsquigarrow \xi \) implies
 and \(\mathop {\textrm{fsv}}(\xi ) = \varnothing \).
and \(\mathop {\textrm{fsv}}(\xi ) = \varnothing \). -
7.
\( \varGamma \vdash M : \xi \rightsquigarrow e \) implies \( \lfloor \varGamma \rfloor \vdash ^{ 0 } e : \lfloor \xi \rfloor \) and \(\mathop {\textrm{fsv}}(\xi ) = \varnothing \).
 and
and  and
and Proof
By mutual induction on the derivation. We only show the proofs about E-Path, E-PersInPers, E-PersInNonPers, B-Val, and B-ValPers for 2 and 5; the rest of the proofs are quite straightforward or essentially the same as the corresponding ones for F-ing Modules [24].
-
2.
-
Case
 : We have
: We have
 and
and
 by IH. Thus, we can derive:
by IH. Thus, we can derive: 
We also have \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \) by
 .
. -
Case
 : By IH, we have
: By IH, we have
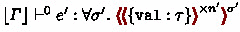 and
and
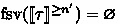 . Then, we have \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \) and thereby \( [ ( n - n' ) \dotplus \sigma / \sigma ' ] \tau = \tau \). This enables us to derive:
. Then, we have \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \) and thereby \( [ ( n - n' ) \dotplus \sigma / \sigma ' ] \tau = \tau \). This enables us to derive: 
-
Case
 : Similarly to the previous case, we have \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \) and can thereby derive:
: Similarly to the previous case, we have \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \) and can thereby derive: 
-
-
5.
-
Case
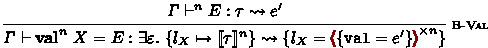 : By IH, we have \( \lfloor \varGamma \rfloor \vdash ^{ n } e' : \tau \) and \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \). Thus, we can derive:
: By IH, we have \( \lfloor \varGamma \rfloor \vdash ^{ n } e' : \tau \) and \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \). Thus, we can derive: 
and have \(\mathop {\textrm{fsv}}( \lfloor \exists \varepsilon .\ \mathopen {\{\!|} R \mathclose {|\!\} } \rfloor ) = \mathop {\textrm{fsv}}(\tau ) = \varnothing \).
-
Case
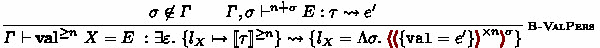 : By IH, we have \( \lfloor \varGamma , \sigma \rfloor \vdash ^{ n \dotplus \sigma } e' : \tau \) and \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \). Therefore, we can derive:
: By IH, we have \( \lfloor \varGamma , \sigma \rfloor \vdash ^{ n \dotplus \sigma } e' : \tau \) and \(\mathop {\textrm{fsv}}(\tau ) = \varnothing \). Therefore, we can derive: 
and have \(\mathop {\textrm{fsv}}( \lfloor \exists \varepsilon .\ \mathopen {\{\!|} R \mathclose {|\!\} } \rfloor ) = \mathop {\textrm{fsv}}(\tau ) = \varnothing \).
-
 : We have
: We have
 and
and
 by IH. Thus, we can derive:
by IH. Thus, we can derive: 
 .
. : By IH, we have
: By IH, we have
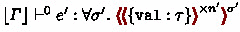 and
and
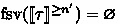 . Then, we have
. Then, we have 
 : Similarly to the previous case, we have
: Similarly to the previous case, we have 
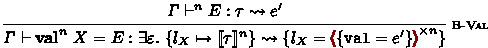 : By IH, we have
: By IH, we have 
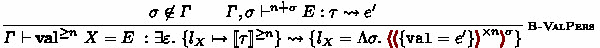 : By IH, we have
: By IH, we have 
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2024 The Author(s)
About this paper
Cite this paper
Suwa, T., Igarashi, A. (2024). An ML-Style Module System for Cross-Stage Type Abstraction in Multi-stage Programming. In: Gibbons, J., Miller, D. (eds) Functional and Logic Programming. FLOPS 2024. Lecture Notes in Computer Science, vol 14659. Springer, Singapore. https://doi.org/10.1007/978-981-97-2300-3_13
Download citation
DOI: https://doi.org/10.1007/978-981-97-2300-3_13
Publisher Name: Springer, Singapore
Print ISBN: 978-981-97-2299-0
Online ISBN: 978-981-97-2300-3
eBook Packages: Computer ScienceComputer Science (R0)