
Abstract
In this research work, a detailed review has been conducted to provide the current research scenario of speech emotion recognition (SER). The key purpose is really to look into what is being done in this research as well as the areas where research is lacking. The investigation reveals that “speech emotion recognition” work is a significant field of research, with a large number of research papers published each year in articles and journals. To optimize the detection results of SER systems, the majority of research consists of three main components of SER: (i) datasets, (ii) speech attributes, and (iii) classifiers. After conducting an interrelation study of the essential components, the efficiency of the SER system is determined in terms of identification rate. We researchers established that even a mixture of datasets, speech signal attributes, as well as classification methods affects the recognition performance of the SER system. Based on our review, we also suggested SER features that could be considered in future work.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
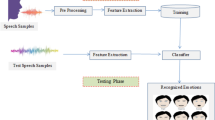


References
Liogienė, T., & Tamulevičius, G. (2015). SFS feature selection technique for multistage emotion recognition. In IEEE 3rd Workshop on Advances in Information, Electronic and Electrical Engineering (AIEEE). IEEE.
Abdel-Hamid, L. (2020). Egyptian Arabic speech emotion recognition using prosodic, spectral and wavelet features. Speech Communication, 122, 19–30.
Tahon, M., & Devillers, L. (2015). Towards a small set of robust acoustic features for emotion recognition: Challenges. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 24(1), 16–28.
Deb, S., & Dandapat, S. (2018). Multiscale amplitude feature and significance of enhanced vocal tract information for emotion classification. IEEE Transactions on Cybernetics, 49(3), 802–815.
Koduru, A., Valiveti, H. B., & Budati, A. K. (2020). Feature extraction algorithms to improve the speech emotion recognition rate. International Journal of Speech Technology, 23(1), 45–55.
Pravena, D., & Govind, D. (2017). Development of simulated emotion speech database for excitation source analysis. International Journal of Speech Technology, 20(2), 327–338.
Wang, W., Watters, P. A., Cao, X., Shen, L., & Li, B. (2020). Significance of phonological features in speech emotion recognition. International Journal of Speech Technology, 23(3), 633–642.
Wang, K., An, N., Li, B. N., Zhang, Y., & Li, L. (2015). Speech emotion recognition using Fourier parameters. IEEE Transactions on Affective Computing, 6(1), 69–75.
Kuchibhotla, S., Vankayalapati, H. D., Vaddi, R. S., & Anne, K. R. (2014). A comparative analysis of classifiers in emotion recognition through acoustic features. International Journal of Speech Technology, 17(4), 401–408.
Haque, A., & Sreenivasa Rao, K. (2015). Analysis and modification of spectral energy for neutral to sad emotion conversion. In 2015 Eighth International Conference on Contemporary Computing (IC3). IEEE.
Lingampeta, D., & Yalamanchili, B. (2020). Human emotion recognition using acoustic features with optimized feature selection and fusion techniques. In 2020 International Conference on Inventive Computation Technologies (ICICT). IEEE.
Christy, A., Vaithyasubramanian, S., Jesudoss, A., & Praveena, M. D. (2020). Multimodal speech emotion recognition and classification using convolutional neural network techniques. International Journal of Speech Technology, 23(2), 381–388.
Jermsittiparsert, K., Abdurrahman, A., Siriattakul, P., Sundeeva, L. A., Hashim, W., Rahim, R., & Maseleno, A. (2020). Pattern recognition and features selection for speech emotion recognition model using deep learning. International Journal of Speech Technology, 23(4), 799–806.
Singh, R., & Sharma, D. K. (2020). Fault-tolerant reversible gate based sequential QCA circuits: Design and contemplation. Journal of Nano-electronics and Optoelectronics, 15(4), 331–344. American Scientific Publications.
Sharma, R., Kumar, R., Sharma, D. K., Son, L. H., Priyadarshini, I., Pham, B. T., Bui, D. T., & Rai, S. (2019). Inferring air pollution from air quality index by different geographical areas: A case study in India. In Air quality, atmosphere and health. Springer Publication.
Sharma, D. K., Kaushik, B. K., & Sharma, R. K. (2014). Impact of driver size and interwire parasitics on crosstalk noise and delay. Journal of Engineering, Design and Technology, 12(4), 475–490. Emerald Pub., U.K.
Ancilin, J., & Milton, A. (2021). Improved speech emotion recognition with Mel frequency magnitude coefficient. Applied Acoustics, 179, 108046.
Jayachitra, S., & Prasanth, A. (2021). Multi-feature analysis for automated brain stroke classification using weighted Gaussian Naïve Bayes classifier. Journal of Circuits, Systems and Computers, 30(2150178), 1–22.
Issa, D., Fatih Demirci, M., & Yazici, A. (2020). Speech emotion recognition with deep convolutional neural networks. Biomedical Signal Processing and Control, 59, 101894.
Özseven, T. (2019). A novel feature selection method for speech emotion recognition. Applied Acoustics, 146, 320–326.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Subramanian, R., Aruchamy, P. (2023). A Survey of Human Emotion Recognition Using Speech Signals: Current Trends and Future Perspectives. In: Sharma, D.K., Peng, SL., Sharma, R., Jeon, G. (eds) Micro-Electronics and Telecommunication Engineering . Lecture Notes in Networks and Systems, vol 617. Springer, Singapore. https://doi.org/10.1007/978-981-19-9512-5_46
Download citation
DOI: https://doi.org/10.1007/978-981-19-9512-5_46
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-9511-8
Online ISBN: 978-981-19-9512-5
eBook Packages: EngineeringEngineering (R0)