
Abstract
Since the rapid growth of big data technology and the continuous development of information technology in recent years, the significance of network security monitoring is increasing consistently. As one of the major tools to secure the system environment, organizations use various monitoring devices to govern the utilities of networks, hardware and applications. Meanwhile, massive and redundant data are produced by these devices constantly, which make a huge problem for analysts and scientists who are willing to extract useful information from them, and even impact the accuracy and efficiency of the monitoring systems. In this paper, we employ random forest algorithm and propose an ensemble learning model under certain scenarios with fixed data features. We use a preprocessing method to balance positive and negative samples, and then use 6 different intrusion detection systems as weak classifiers, which satisfy the rules of “partial sampling” and “partial features selection” of ensemble learning. Finally, we test three combination strategies, including relative majority voting, weighted voting and stacking, to combine the predictions. Experiments show that stacking has a better performance than the other two, with a score of 98.25% in recall, and achieves a 47.91% precision.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In recent years, network security monitoring has developed rapidly and played a significant role in network security. Network security monitoring is the prerequisite of a protected and functional network system. In the context of big data, network monitoring data are produced and altered endlessly. Network monitoring systems not only need to recognize the traditional risks such as spiders, port scanning, webshell, injection attack, advanced persistent threat, and phishing mail, but also have to discover the emerging risks such as privacy disclosure, information leakage, data theft, etc. In order to solve these problems, it is necessary to integrate the strengths of multiple security systems and platforms, which include internet probe, situation awareness system, internet management system, terminal detection system, database protection system, and so forth. However, these systems and platforms are mostly self-contained, which have fuzzy boundaries and duplicated functions. If their advantages can be combined and weaknesses can be complemented in one mechanism, it will reduce unneeded human labor and increase the overall efficiency.
Ensemble learning is the ideal method for solving the problem. Each intrusion detection system can be treated as a weak classifier to distinguish normal and intrusive data, through the integration of several weak classifiers, it will generate a strong classifier with more precise results and higher effectiveness.
In 2001, Giacinto et al. started to solve intrusion detection problems using ensemble learning method [1]. In 2008, Giacinto et al. proposed an ensemble learning method which could detect and discover unknown types of intrusion [2]. Random forest algorithm has been widely used and approved to be effective in intrusion detection ensembles. The common process is to extract the syntax features from PHP code through text analysis, and then build the webshell detection model [3, 4]. Because webshell contains both behavioral features and static text features, it is possible to build a stronger feature combination by merging behavioral features with text static features [5, 6]. Another method is combining random forest with deep learning to build a network intrusion detection model through deep random forest, which can handle more complex and huge datasets [7].
Researchers in intrusion detection often choose public datasets, such as NSL-KDD, ISC2012, ADFA13, DARPA98, or public repositories such as Github. Most of the public datasets are cleaned and balanced, with a proper balance rate of normal and intrusive data, which is suitable for algorithm research. But these datasets are outdated and are not able to reflect the newest trend in intrusion detection. According to certain scenarios, it is necessary to collect specific data and construct a specialized dataset [8].
In this paper, we use a dataset from recall sampling after desensitization of real data, which is deeply imbalanced. In order to adjust the ratio of different samples in an imbalanced dataset, the primary machine learning solutions are undersampling and oversampling. By adjusting model quality metrics for different categories, we can mitigate model failure caused by data imbalance [9, 10].
2 Network Security Monitoring and Random Forest
2.1 Network Security Monitoring
Network security monitoring is a technology that through collecting and analyzing attack alarms to enhance the responses to network intrusions. To conduct the network traffic analysis, people generally export network flow replica via a private network switch and execute the analytical procedures in a dedicated server. By using data presentation tools, data transmission tools, and data collection tools to analyze network traffic, flow information such as sessions, transactions, statistics, metadata, and alert data can be extracted. By analyzing various types of monitoring data, digital threats and intruders can be controlled to ensure network security.

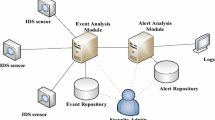
Network security monitoring process diagram
Figure 1 shows the process diagram of network security monitoring. Network monitoring analysis usually relies on analytical skills of the monitoring staff. Monitoring staff are in charge with extracting information from thousands of alarm data, analyzing and defining the misreporting rate, threaten level and hazard level of each alarm, and implement relevant responses appropriately. In addition to their analytical skill level, monitoring staff also need a thorough understanding of the network environment in specific field, including but not limited to business data patterns, asset locations, etc. They must identify and response to the intrusions timely from numerous alarm data in the complicate environments, and keep tracking the subsequent events and potential risks.
Time is the most important factor in safeguarding the network system. In one sense, misreporting can lead to serious failures because the monitoring staff are unable to deal with intrusions timely. On the other hand, underreporting can cause more risky situations which are hard to predict. Therefore, with the development of network security in recent years, monitoring systems become more and more comprehensive. With the arrival of the big data era and the improvement of computing power, the quantity and repeatability of security data are increased tremendously. New security risks, especially data security risks arise. These factors are challenges to the real-time monitoring.
Because each intrusion detection system has its own technical advantages, the combination of these systems are fairly complex. In practice, administrators must patrol all intrusion detection systems at the same time during a monitoring process. In addition to intrusion detection tools, monitoring staff should be able to operate other systems flexibly, including asset mapping system, log audit system, host scanning system, security disposal tools, security filing platform, external intelligence platform, tracking and recording platform, and so on. The complex environment and complicated functions also challenge the real-time monitoring.
From the perspective of alarm data itself, in the practical monitoring exercises, most of the alarm information belong to misreported data. Among the alarm data, most intrusions are crawlers, port scanning or vulnerability detection, which are highly repeated and lower threatened. The true threatening invasion are difficult to discover at first because they are hidden in a lot of worthless data.
To face these challenges, a common solution is building network security policies. But policies are always static and fixed, which can be slow to adapt to the network environment changes and cannot be simply applied to all the services and systems.
Based on above conditions, we propose a new solution to decrease the amount of data size and increase the efficiency of security system devices by further screening and classifying of the alarm data.
2.2 Random Forest
Machine learning (ML) has made great achievements in automated classification tasks in recent years, and one of the popular field in ML is ensemble learning. By training multiple weak classifiers and combine them into a strong classifier, ensemble learning can solve a classification problem jointly. Generally speaking, the classifier generated by ensemble learning is more precise than any of the weak classifiers. Sampling methods such as boosting and bagging are commonly used in ensemble learning. As combination strategies, except voting methods such as average method and relative majority voting method, stacking method is also used which integrating and combining models by constructing learners. Random forest is an important method widely used in ensemble learning.
Random forest is an integrated classifier based on bagging expansion, and consists of many decision trees. The predictive output of the classifier is combined after each decision tree is classified. Based on bagging, random feature selection is introduced into random forest. In another words, we need to make a random selection for a feature subset before classification, and then conduct the classification task on the subset.
From the perspective of machine learning, we can treat intrusion detection as a classification task. Intrusion detection systems can transform raw data into structured data tables using data representation tool, then classify data according to attack features and attack types after analyzing them. Each intrusion detection system can be treated as a weak classifier to execute classification. Because of the inaccuracy of the classification result of each weak classifier, we can generate an integrated classifiers using ensemble learning to improve the precision.
By further studies on the data features of intrusion detection in monitoring analysis, we found that each intrusion detection system can only identify part of the attack features because different intrusion detection systems come from different manufacturers with different application scenarios. On the other hand, the network traffic capture method can be consider as a special bagging in machine learning because each intrusion detection system is deployed at different positions of the network system, which captures incomprehensive and overlapping network traffic data. Therefore, when we use individual intrusion detection system as a classifier, it naturally satisfies the two properties of “partial sampling” and “partial feature selection”. Based on the ideology of random forest, we use ensemble learning method to conduct network monitoring analysis from multiple intrusion detection systems.
Compare with other analysis types in network security, monitoring analysis has higher requirements on timeliness. Analysis with large-scaled neural networks require expensive equipments to ensure the efficiency of computing process. Some algorithms such as K-NN and SVM are only applicable to analysis with small-scaled datasets. With random forest, the computation cost is at equivalent level as the cost of IDS. When considering timeliness, cost and efficiency, and datasets scale, random forest method is the best choice in practice of large-scale network monitoring analysis.
2.3 Imbalanced Learning and Cost-Sensitive Learning
From the perspective of machine learning, the characteristics of monitoring data are typical category imbalance and cost sensitive data. In the network traffic, the vast majority of traffic comes from normal network services, only a small part comes from intrusions.
In this paper, alarm data is regarded as positive class, normal traffic is regarded as negative class. Without any data processing, after sampling the network traffic, we found that the ratio of alarm data to service data reached a level of 1:106 at most. There is a serious imbalance between positive and negative data, which will lead to the natural bias of classification algorithm towards negative data.
Monitoring data is an important data related to network security. The consequences of incorrect classification of monitoring data are different, misreporting may not lead to direct consequences, but underreporting may lead to security vulnerabilities in actual monitoring. As shown in the Table 1, for the confusion matrix, the impact of underreporting is far greater than that of misreporting.
There are data level methods and algorithm level methods to solve the class imbalance. The data level methods mainly include oversampling, undersampling and composite sampling. Among them, the disadvantage of undersampling is that it may cause the loss of information, while the disadvantage of oversampling is that it causes over fitting. The algorithm level method is mainly to modify the existing algorithm to pay more attention to the minority class.
In this paper, for the monitoring datasets, we mainly use the undersampling method. Specifically, we use two types of methods. First, we limit the recall channel and increase the proportion of positive samples as we keep the sampling comprehensiveness as much as possible. Second, based on the monitoring data itself, we screen data by several methods include filter white list data, remove data containing important business features, and remove normal network traffic in combination with external intelligence base. After undersampling, positive and negative classes form a data ratio within 1:100.
In order to balance the cost of underreporting, we adjusted the weight of underreporting in the learning process and increased the punishment.
3 Application of Random Forest Algorithm
3.1 Experiment Description
In this paper, the number of service data (TN) is far more than that of other classes, to avoid the disturbance of service data, we use precision, recall and F-score to evaluate classifier performance. Precision is defined as \(\frac{TP}{{TP + FP}}\), recall is defined as \(\frac{TP}{{TP + FN}}\).
From Table 1, FN stands for the number of underreporting, FP stands for the number of misreporting. Considering the importance of underreporting, we increase the weight of FN and define F-score as \(\frac{{\left( {a^{2} + 1} \right)PR}}{{a^{2} P + R}}\), in which \(a = 2\).
In this paper, we use three different combination strategies to combine classifiers, including relative majority voting, weighted voting and stacking.
For weak classifier \(h_{1} ,h_{2} ,...h_{6}\) and collection of category tags \(\left\{ {c_{1} ,c_{2} ,...c_{6} } \right\}\), we express the prediction output of \(h_{i}\) out of \(x\) as a 6-dimensional vector \(\left( {h_{i}^{1} \left( x \right),h_{i}^{2} \left( x \right),...h_{i}^{6} \left( x \right)} \right)\), let \(h_{i}^{j} \left( x \right)\) be the output of \(h_{i}\) on category tag \(c_{j}\).
Relative majority voting:
Weighted voting (\(w_{i}\) is the weight of \(h_{i}\)):
Stacking: A new dataset is generated from the training results of the initial dataset as a training sample, which is called a secondary training set, then we generate secondary learners for training by cross validation.
3.2 Data Sampling and Preprocessing
We select part of the network traffic through the recall channel for analysis. To ensure data comprehensiveness, we need to sample from the complete time period for forming a dataset. Table 2 shows the basic features of the dataset:
The dataset in Table 2 is generated and sampled from the full period in proportion based on the above features. In a complete period of one week, we observed that during working hours, the network traffic is large and mainly internal business data, while during night and holiday, the amount of network traffic data is relatively small, and the external network access data is the main data. After the dataset is formed, 30 data features are extracted from it combined with each intrusion detection device.
Before we preprocess the data, the ratio of the number of positive classes to the number of negative classes reaches 1:3322, which would cause bias that the results of the model tend to be negative class and cannot be classified correctly when we directly classify on the dataset of Table 2.
Therefore, we clean the dataset in Table 2 by filter the white list, clear the analyzed data in the security policy, remove the business characteristic data and analyze in combination with the external intelligence base. After above preprocess, Table 3 shows the features of the dataset:
After the above preprocess, the ratio of positive and negative classes in the dataset in Table 2 is reduced to nearly 1:69 in Table 3. The following is a further analysis based on the dataset formed in Table 3.
3.3 Classifier Analysis
Combined with intrusion detection equipment, six weak classifiers are extracted from the dataset. By manually analyzing the real situation of positive classification and manually labeling, the actual performance and classification ability of each weak classifier are obtained. Details are shown in the Table 4:
Further analysis based on the data in Table 4:
-
(1)
In Table 4, the first two classifiers correspond to Internet traffic, the last four classifiers mainly correspond to each intranet service and terminal detection equipment. Due to the partial overlap of functions, there is a large amount of duplicate data between different classifiers.
-
(2)
After removing the duplicate alarm classification, there are 4420 external network alarms, in which there are 2629 are correctly classified, the precision is relatively high, reaching 59.48%. The precision of each intranet service and terminal detection equipment is relatively low, there are 4138 alarms, in which there are 791 are correctly classified, the precision is 19.11%.
-
(3)
On the whole, belong 8558 alarms, there are 3420 are correctly classified, the precision is 39.96%. Belong them, the external IP intrusion classifier has high precision, which can identify most conventional intrusions, the most common intrusion includes port scanning, Weblogic attacks, deserialization attacks, and crawlers. The precision of Intranet service management and terminal alarm are relatively low, most of the false positives come from incorrect SQL injection identification, which is because different databases have different management strategies and release orders.
-
(4)
Through further analysis of the duplicate data, it is found that for some attack features, special devices are required to classify correctly, which makes it possible for us to correctly schedule the dominant classifiers for detection and recognition by combining strategies.
3.4 Combination Strategy
We randomly divided the sample data into two subsets: a training dataset and a testing dataset. 70% of the total sample is used as training data to determine the optimal model parameters. The remaining 30% dataset is used as testing data to evaluate the predictive precision. In this paper, we use three different combination strategies for model training, including relative majority voting, weighted voting and stacking. Table 5 shows the classification results under different combination strategies.
The recall rate in Table 5 reflects the number of underreporting of the combination strategy. In the dataset of this paper, 1% recall rate represents about 40 underreports. Therefore, from Table 5 we can see that using relative majority voting or weighted voting for the classifier would cover part of the feature recognition ability, which has certain destructiveness to the model when the amount of weak classifiers are limited. Compared with the above two methods, stacking method has higher performance in classification recall rate. Based on specific scenarios, when data features are relatively fixed, stacking can find the correct classification when weak classifiers conflicted with each other.
4 Conclusion
-
(1)
In this paper, the safety monitoring dataset is generated by desensitizing the data from practical application and sampling in full cycle. After undersampling, we realize the relative balance of sample data. After data cleaning, the data proportion of the sample is reduced from 1:3322 to 1:69 without damage the features of dataset.
-
(2)
In practical security production, different intrusion detection devices have different feature recognition capabilities. After preprocessing, the overall classification precision was 39.96%. External IP intrusion is easier to be identified, and the classification precision is 59.48%, which can be correctly identified by most detection devices. For intranet service management and terminal security detection, the detection ability of the classifier is low, only 19.11%. In practical application, these kind of attacks are more necessary to rely on the corresponding equipment with the feature recognition ability to analyze and identify specific features.
-
(3)
Comparing with voting method, stacking has better performance to combine weak classifiers. After stacking, the precision of classification has increased to 47.91%. Limited by the feature recognition ability of the testing equipment, the precision of the model is limited in this dataset. It is necessary to introduce a new detection and recognition algorithm to greatly improve the precision of the model. Whether the classification precision can be further improved needs further research.
The data application detection in this paper is mainly used for off-line analysis. For the real-time detection of monitoring and analysis, how to conduct real-time analysis through the stream processing engine, and how the detection efficiency and effect are, still pending further study and improvement.
References
Giacinto, G., Roli, F.: Design of effective neural network ensembles for image classification purposes. Image Vis. Comput. 19(9/10), 699–707 (2001)
Giacinto, G., Perdisci, R., Rio, M.D., et al.: Intrusion detection in computer networks by a modular ensemble of one-class classifiers. Inf. Fusion 9(1), 69–82 (2008)
Pan, Z., Chen, Y., Chen, Y., et al.: Webshell detection based on executable data characteristics of PHP code. Wirel. Commun. Mob. Comput. 2021, 5533963 (2021)
Fang, Y., Qiu, Y., Liu, L., et al.: Detecting Webshell based on random forest with fasttext, pp. 52–56 (2018)
Farnaaz, N., Jabbar, M.A.: Random forest modeling for network intrusion detection system. Procedia Comput. Sci. 89, 213–217 (2016)
Zhou, A., Luktarhan, N., Ai, Z.: Research on WebShell detection method based on regularized neighborhood component analysis (RNCA). Symmetry 13(7), 1202 (2021)
Liu, Z., Su, N., Qin, Y., et al.: A deep random forest model on spark for network intrusion detection. Mob. Inf. Syst. 2020(1), 1–16 (2020)
Sharafaldin, I., Lashkari, A, H., Ghorbani, A, A.: Toward generating a new intrusion detection dataset and intrusion traffic characterization. In: International Conference on Information Systems Security and Privacy (2018)
Lovri, M., Malev, O., Klobuar, G., et al.: Predictive capability of QSAR models based on the CompTox Zebrafish Embryo Assays: an imbalanced classification problem. Molecules (Basel, Switzerland) 26(6), 1617 (2021)
Dong, J., Qian, Q.: A density-based random forest for imbalanced data classification. Future Internet 14, 90 (2022)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this paper

Cite this paper
Chen, Q., Zhang, X., Wang, Y., Zhai, Z., Yang, F. (2022). Applying a Random Forest Approach to Imbalanced Dataset on Network Monitoring Analysis. In: Lu, W., Zhang, Y., Wen, W., Yan, H., Li, C. (eds) Cyber Security. CNCERT 2022. Communications in Computer and Information Science, vol 1699. Springer, Singapore. https://doi.org/10.1007/978-981-19-8285-9_2
Download citation
DOI: https://doi.org/10.1007/978-981-19-8285-9_2
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-8284-2
Online ISBN: 978-981-19-8285-9
eBook Packages: Computer ScienceComputer Science (R0)