
Abstract
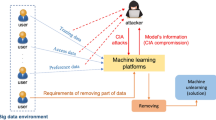
Machine learning models are considered as the model owners’ intellectual property (IP). An attacker may steal and abuse others’ machine learning models such that it does not need to train its own model, which requires a large amount of resources. Therefore, it becomes an urgent problem how to distinguish such compromise of IP. Watermarking has been widely adopted as a solution in the literature. However, watermarking requires modification of the training process, which leads to utility loss and is not applicable to legacy models. In this chapter, we introduce another path toward protecting IP of machine learning models via fingerprinting the classification boundary. This is based on the observation that a machine learning model can be uniquely represented by its classification boundary. For instance, the model owner extracts some data points near the classification boundary of its model, which are used to fingerprint the model. Another model is likely to be a pirated version of the owner’s model if they have the same predictions for most fingerprinting data points. The key difference between fingerprinting and watermarking is that fingerprinting extracts fingerprint that characterizes the classification boundary of the model, while watermarking embeds watermarks into the model via modifying the training or fine-tuning process. In this chapter, we illustrate that we can robustly protect the model owners’ IP with the fingerprint of the model’s classification boundary.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Adi, Y., Baum, C., Cisse, M., Pinkas, B., Keshet, J.: Turning your weakness into a strength: watermarking deep neural networks by backdooring. In: 27th {USENIX} Security Symposium ({USENIX} Security 18), pp. 1615–1631 (2018)
Alzantot, M., Sharma, Y., Elgohary, A., Ho, B.-J., Srivastava, M., Chang, K.-W.: Generating natural language adversarial examples. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (2018)
Athalye, A., Engstrom, L., Ilyas, A., Kwok, K.: Synthesizing robust adversarial examples. In: International Conference on Machine Learning, pp. 284–293. PMLR (2018)
Bradley, A.P.: The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recogn. 30(7), 1145–1159 (1997)
Cao, X., Jia, J., Gong, N.Z.: IPGuard: protecting intellectual property of deep neural networks via fingerprinting the classification boundary. In: Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security, pp. 14–25 (2021)
Carlini, N., Wagner, D.: Adversarial examples are not easily detected: bypassing ten detection methods. In: Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, pp. 3–14 (2017)
Carlini, N., Wagner, D.: Towards evaluating the robustness of neural networks. In: 2017 IEEE Symposium on Security and Privacy (SP), pp. 39–57. IEEE (2017)
Carrara, F., Becarelli, R., Caldelli, R., Falchi, F., Amato, G.: Adversarial examples detection in features distance spaces. In: Proceedings of the European Conference on Computer Vision (ECCV) Workshops (2018)
Chandrasekaran, V., Chaudhuri, K., Giacomelli, I., Jha, S., Yan, S.: Exploring connections between active learning and model extraction. In: 29th USENIX Security Symposium (USENIX Security 20), pp. 1309–1326 (2020)
Chen, H., Rohani, B.D., Koushanfar, F.: DeepMarks: a digital fingerprinting framework for deep neural networks (2018). arXiv preprint arXiv:1804.03648
Chen, K., Guo, S., Zhang, T., Li, S., Liu, Y.: Temporal watermarks for deep reinforcement learning models. In: Proceedings of the 20th International Conference on Autonomous Agents and Multiagent Systems, pp. 314–322 (2021)
Chollet, F., et al.: Keras (2015). https://keras.io
Darvish Rouhani, B., Chen, H., Koushanfar, F.: DeepSigns: an end-to-end watermarking framework for ownership protection of deep neural networks. In: Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, pp. 485–497. ACM (2019)
Li, B., Fan, L., Gu, H., Li, J., Yang, Q.: FedIPR: ownership verification for federated deep neural network models. In: FTL-IJCAI (2021)
Fidel, G., Bitton, R., Shabtai, A.: When explainability meets adversarial learning: detecting adversarial examples using SHAP signatures. In: 2020 International Joint Conference on Neural Networks (IJCNN), pp. 1–8. IEEE (2020)
Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples. In: ICLR (2015)
Grosse, K., Manoharan, P., Papernot, N., Backes, M., McDaniel, P.: On the (statistical) detection of adversarial examples (2017). arXiv preprint arXiv:1702.06280
Guo, J., Potkonjak, M.: Watermarking deep neural networks for embedded systems. In: 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), pp. 1–8. IEEE (2018)
Han, S., Pool, J., Tran, J., Dally, W.: Learning both weights and connections for efficient neural network. In: Advances in Neural Information Processing Systems, pp. 1135–1143 (2015)
Hartung, F., Kutter, M.: Multimedia watermarking techniques. Proc. IEEE 87(7), 1079–1107 (1999)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Identity mappings in deep residual networks. In: European conference on Computer Vision, pp. 630–645. Springer, Berlin (2016)
Hendrycks, D., Zhao, K., Basart, S., Steinhardt, J., Song, D.: Natural adversarial examples. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15262–15271 (2021)
Hu, X., Liang, L., Deng, L., Li, S., Xie, X., Ji, Y., Ding, Y., Liu, C., Sherwood, T., Xie, Y., Neural network model extraction attacks in edge devices by hearing architectural hints. In: ASPLOS (2020)
Hua, W., Zhang, Z., Suh, G.E.: Reverse engineering convolutional neural networks through side-channel information leaks. In: 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), pp. 1–6. IEEE (2018)
Jagielski, M., Carlini, N., Berthelot, D., Kurakin, A., Papernot, N.: High accuracy and high fidelity extraction of neural networks. In: 29th USENIX Security Symposium (USENIX Security 20), pp. 1345–1362 (2020)
Juuti, M., Szyller, S., Marchal, S., Asokan, N.: PRADA: protecting against DNN model stealing attacks (2018). arXiv preprint arXiv:1805.02628
Kesarwani, M., Mukhoty, B., Arya, V., Mehta, S.: Model extraction warning in MLAAS paradigm. In: Proceedings of the 34th Annual Computer Security Applications Conference, pp. 371–380 (2018)
Kurakin, A., Goodfellow, I.J., Bengio, S.: Adversarial examples in the physical world. In: ICLR (2017)
Kurakin, A., Goodfellow, I.J., Bengio, S.: Adversarial examples in the physical world. In: Artificial Intelligence Safety and Security, pp. 99–112. Chapman and Hall/CRC (2018)
Le Merrer, E., Perez, P., Trédan, G.: Adversarial frontier stitching for remote neural network watermarking. Neural Comput. Appl. 32(13), 9233–9244 (2020)
Li, F.-Q., Wang, S.-L., Liew, A.-W.-C.: Regulating ownership verification for deep neural networks: scenarios, protocols, and prospects. In: IJCAI Workshop on Toward IPR on Deep Learning as Services (2021)
Li, H., Kadav, A., Durdanovic, I., Samet, H., Graf, H.P.: Pruning filters for efficient ConvNets (2016). arXiv preprint arXiv:1608.08710
Li, X., Li, F.: Adversarial examples detection in deep networks with convolutional filter statistics. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 5764–5772 (2017)
Li, Y., Zhu, L., Jia, X., Jiang, Y., Xia, S.-T., Cao, X.: Defending against model stealing via verifying embedded external features. In: AAAI (2022)
Li, Z., Hu, C., Zhang, Y., Guo, S.: How to prove your model belongs to you: a blind-watermark based framework to protect intellectual property of DNN. In: Proceedings of the 35th Annual Computer Security Applications Conference, pp. 126–137 (2019)
Lim, J.H., Chan, C.S., Ng, K.W., Fan, L., Yang, Q.: Protect, show, attend and tell: empowering image captioning models with ownership protection. Pattern Recogn. 122, 108285 (2022)
Lu, J., Issaranon, T., Forsyth, D.: SafetyNet: detecting and rejecting adversarial examples robustly. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 446–454 (2017)
Lukas, N., Zhang, Y., Kerschbaum, F.: Deep neural network fingerprinting by conferrable adversarial examples. In: International Conference on Learning Representations (2021)
Ma, H., Chen, T., Hu, T.-K., You, C., Xie, X., Wang, Z.: Undistillable: making a nasty teacher that cannot teach students. In: International Conference on Learning Representations (2021)
Meng, D., Chen, H.: MagNet: a two-pronged defense against adversarial examples. In: Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, pp. 135–147 (2017)
Nagai, Y., Uchida, Y., Sakazawa, S., Satoh, S.I.: Digital watermarking for deep neural networks. Int. J. Multimedia Inform. Retrieval 7(1), 3–16 (2018)
Oh, S.J., Schiele, B., Fritz, M.: Towards reverse-engineering black-box neural networks. In: ICLR (2018)
Pang, T., Du, C., Dong, Y., Zhu, J.: Towards robust detection of adversarial examples. In: Advances in Neural Information Processing Systems, vol. 31 (2018)
Quan, Y., Teng, H., Chen, Y., Ji, H.: Watermarking deep neural networks in image processing. IEEE Trans. Neural Netw. Learn. Syst. 32(5), 1852–1865 (2020)
Roth, K., Kilcher, Y., Hofmann, T.: The odds are odd: a statistical test for detecting adversarial examples. In: International Conference on Machine Learning, pp. 5498–5507. PMLR (2019)
Song, Y., Kim, T., Nowozin, S., Ermon, S., Kushman, N.: PixelDefend: leveraging generative models to understand and defend against adversarial examples. In: International Conference on Learning Representations (2018)
Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., Fergus, R.: Intriguing properties of neural networks. In: ICLR (2014)
Tian, S., Yang, G., Cai, Y.: Detecting adversarial examples through image transformation. In: Thirty-Second AAAI Conference on Artificial Intelligence (2018)
Tramèr, F., Zhang, F., Juels, A., Reiter, M.K., Ristenpart, T.: Stealing machine learning models via prediction APIs. In: USENIX Security Symposium (2016)
Wang, B., Gong, N.Z.: Stealing hyperparameters in machine learning. In: IEEE S & P (2018)
Wang, S., Chang, C.-H.: Fingerprinting deep neural networks-a DeepFool approach. In: 2021 IEEE International Symposium on Circuits and Systems (ISCAS), pp. 1–5. IEEE (2021)
Xiao, C., Li, B., Zhu, J.-Y., He, W., Liu, M., Song, D.: Generating adversarial examples with adversarial networks. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence, pp. 3905–3911 (2018)
Xu, W., Evans, D., Qi, Y.: Feature squeezing: detecting adversarial examples in deep neural networks. In: Network and Distributed System Security Symposium (2018)
Yan, M., Fletcher, C.W., Torrellas, J.: Cache telepathy: leveraging shared resource attacks to learn DNN architectures (2018). arXiv preprint arXiv:1808.04761
Yang, P., Chen, J., Hsieh, C.-J., Wang, J.-L., Jordan, M.: ML-LOO: detecting adversarial examples with feature attribution. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 6639–6647 (2020)
Zhang, J., Gu, Z., Jang, J., Wu, H., Stoecklin, M.P., Huang, H., Molloy, I.: Protecting intellectual property of deep neural networks with watermarking. In: Proceedings of the 2018 on Asia Conference on Computer and Communications Security, pp. 159–172. ACM (2018)
Zhao, J., Hu, Q., Liu, G., Ma, X., Chen, F., Hassan, M.M.: AFA: adversarial fingerprinting authentication for deep neural networks. Comput. Commun. 150, 488–497 (2020)
Acknowledgements
This work was supported by National Science Foundation under grant No. 1937786 and 2112562.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this chapter

Cite this chapter
Cao, X., Jia, J., Gong, N.Z. (2023). Protecting Intellectual Property of Machine Learning Models via Fingerprinting the Classification Boundary. In: Fan, L., Chan, C.S., Yang, Q. (eds) Digital Watermarking for Machine Learning Model. Springer, Singapore. https://doi.org/10.1007/978-981-19-7554-7_5
Download citation
DOI: https://doi.org/10.1007/978-981-19-7554-7_5
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-7553-0
Online ISBN: 978-981-19-7554-7
eBook Packages: Computer ScienceComputer Science (R0)