
Abstract
Deep convolutional neural networks are widely used in image recognition, but the black box property is always perplexing. In this paper, a method is proposed using visual annotation to interpret the internal structure of CNN from the semantic perspective. First, filters are screened in the high layers of the CNN. For a certain category, the important filters are selected by their activation values, frequencies and classification contribution. Then, deconvolution is used to visualize the filters, and semantic interpretations of the filters are labelled by referring to the visualized activation region in the original image. Thus, the CNN model is interpreted and analyzed through these filters. Finally, the visualization results of some important filters are shown, and the semantic accuracy of filters are verified with reference to the expert feature image sets. In addition, the results verify the semantic consistency of the same important filters under similar categories, which indicates the stability of semantic annotation of these filters.
C. Qi, Y. Zhao and Y. Wang—Contributed equally to this paper. This work is supported by: National Defense Science and Tech-nology Innovation Special Zone Project (No. 18-163-11-ZT-002-045-04); Engineering Research Center of State Financial Security, Ministry of Education, Central University of Finance and Economics, Beijing, 102206, China; Program for Innovation Research in Central University of Finance and Economics; National College Students’ Innovation and Entrepreneurship Training Program “Research on classification and interpretability of popular goods based on Neural Network”.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
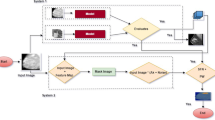


Notes
- 1.
This type of deconvolution for visualization is also called transpose convolution.
- 2.
When we annotate a filter, for each image in the set, we can get n regions through deconvolution based on the top n activation values, then give them semantic labels.
- 3.
We select each filter of the 13st layer for experiment.
References
Lipton, Z.C.: The Mythos of Model Interpretability. Commun. ACM 61(10), 1–27 (2018)
Springenberg, J.T., Dosovitskiy, A., Brox, T., Riedmiller, M.: Striving for simplicity: the all convolutional net. In: IEEE International Conference on Learning Representations (ICLR), pp. 1–14 (2015)
Zhou, B., Khosla, A., Lapedriza, A., et al.: Learning deep features for discriminative localization. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2921–2929 (2016)
Selvaraju, R.R., Cogswell, M., Das, A., et al.: Grad-CAM: visual explanations from deep networks via gradient-based localization. In: IEEE International Conference on Computer Vision (CVPR), pp. 618–626 (2017)
Simonyan, K., Vedaldi, A., Zisserman, A.: Deep inside convolutional networks: visualising image classification models and saliency maps. arXiv:1312.6034 (2013)
Wang, H., et al.: Score-CAM: score-weighted visual explanations for convolutional neural networks. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 111–119 (2020)
Smilkov, D., Thorat, N., Kim, B., Viegas, F., Wattenberg. M.: Smoothgrad: removing noise by adding noise. arXiv:1706.03825 (2017)
Zeiler, M D., Taylor, G W., Fergus, R.: Adaptive deconvolutional networks for mid and high level feature learning. In: International Conference on Computer Vision (ICCV), pp. 2018–2025 (2011)
Zeiler, M.D., Fergus, R.: Visualizing and understanding convolutional networks. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8689, pp. 818–833. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10590-1_53
Zhang, Q., Wu, Y.N., Zhu, S.C.: Interpretable convolutional neural networks. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8827–8836 (2018)
Zhang, Q., Yang, Y., Ma, H., Wu, Y.N.: Interpreting CNNs via decision trees. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6254–6263 (2019)
Zhang, Q., Cao, R., Wu, Y.N., Zhu, S.C.: Growing interpretable part graphs on ConvNets via multi-shot learning. In: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI 2017), pp. 2898–2906 (2017)
Dong, Y., Su, H., Zhu, J., Zhang, B.: Improving interpretability of deep neural networks with semantic information. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 975–983 (2017)
Deng, J., Dong, W., Socher, R., Li, L., Li, K., Li, F.-F.: ImageNet: a large-scale hierarchical image database. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 248–255 (2009)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556 (2014)
Zeiler, M.D., Krishnan, D., Taylor, G.W., Fergus, R.: Deconvolutional networks. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2528–2535 (2010)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Qi, C. et al. (2021). Analyzing Interpretability Semantically via CNN Visualization. In: Zeng, J., Qin, P., Jing, W., Song, X., Lu, Z. (eds) Data Science. ICPCSEE 2021. Communications in Computer and Information Science, vol 1452. Springer, Singapore. https://doi.org/10.1007/978-981-16-5943-0_8
Download citation
DOI: https://doi.org/10.1007/978-981-16-5943-0_8
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-5942-3
Online ISBN: 978-981-16-5943-0
eBook Packages: Computer ScienceComputer Science (R0)