
Abstract
Speech Emotion Recognition (SER) is the operation or series of steps used for the identification of human emotions from verbal expressions. SER is a challenging task, and extensive reliance has been placed on models which use audio features in developing well-performing classifiers. Practitioners rely more on the power of the deep learning models, but even lighter and more interpretable ML models can achieve performance that was achieved by DL-based models with close values of accuracy, f-score, precision, and recall. Lighter machine learning-based models trained over a few handcrafted features, such as pitch, harmonics, speech energy, and pause, are able to achieve a performance comparable to the current deep learning-based state-of-the-art method for emotion recognition. To increase the accuracy of the models, we also used the features such as MFCC in the feature extraction process. In this paper, we implement the lightweight interpretable machine learning models namely, Random Forest, Gradient Boosting, Support Vector Machines, Naive Bayes, and Logistic Regression, for speech emotion detection. The ensembling of these models is done to find out the best combination for better accuracy. We developed an application for improving the customer-care services by classifying and prioritizing the feedback based on the emotions of the voice data.
Similar content being viewed by others


Keywords
- Speech emotion recognition
- Random forest
- Gradient boosting
- Support vector machines
- Naive Bayes
- And logistic regression
1 Introduction
Speech Emotion Recognition (SER) technology is making invaluable contributions to business organizations. Businesses that provide customer services benefit from this to improve self-service in a way that enriches customer experience. Emotion recognition is the capability of identifying human emotions from verbal expressions.
The planned model is an AI-based framework for human speech recognition (audio). The framework utilizes handcreated highlights like pitch, music, sound energy, and so on to distinguish the emotion of the speech signal. Then the extracted features are used to train five machine learning classifiers. An ensemble of the best performing models is then used to determine the emotion of the speech. The designed system focuses on recognizing emotions from speech, where the use of the comparatively lightweight machine learning models. This model makes use of handcrafted features namely signal mean, signal standard deviation, sound energy, silence, pitch and harmonics along with MFCC to improve the accuracy for the models used to train ML classifiers. The designed system focuses on recognizing emotions from speech, where the comparatively lightweight machine learning models are used. This model makes use of handcrafted features namely signal mean, signal standard deviation, sound energy, silence, pitch, and harmonics along with MFCC to improve the accuracy for the models used to train ML classifiers.
The system mainly consists of the following phases:
-
1.
Feature extraction—Forming feature vectors of the features extracted from the audio file.
-
2.
ML classifiers—ML classifiers are trained on the extracted features and an ensemble of the best performing models is taken to determine the emotion of the speech.
The aim of this work is to:
-
1.
Experiment with Random Forest, Gradient Boosting, Support Vector Machine, Naive Bayes, and Logistic Regression methods for classifying speech emotions.
-
2.
Experiment with ensemble of methods.
-
3.
Compare the performance with the accuracy of each method.
-
4.
Classify the emotions as angry, happy, sad, neutral, frustrated, excited, fearful, surprised, and disgusted.
-
5.
Evaluate the method on the iemocap dataset
-
6.
Apply the handcrafted features with state-of-the-art features.
-
7.
Compare model performance applying MFCC and handcrafted features.
2 Related Work
Research on the recognition of the human voice has been conducted since the fifties. The applications of speech emotion sentiment analysis in the real-world market do not seem to be as fast as the study. Speech Emotion Recognition is one of the ways of extracting the semantics from the speech that adds more information to the analysis and thus improving the performance of speech recognition systems.
Consider the example of an English word “OKAY” which can be interpreted differently with respect to how it is used in a conversation. It can mean sanction, disbelief, consent, endorsement, indorsement, warrant, admiration, disinterest, or assertion. Understanding of the word when spoken out loud by a human to human can be interpreted very flawlessly; on the contrary, in a human to computer conversation, it can be misinterpreted, or the computer cannot comprehend with the utmost perfection. Therefore, just processing the text itself is not enough to understand the semantics of the actual spoken statement or speech. The processing of non-linguistics information such as emotion is crucial. The non-linguistics in various cases can be observed through Facial expressions in videos, Expression of emotions in speech, and Punctuation in text. SER research has been progressing with human-centered computing. Mimicking the human perception mechanism is the main objective of an SER. In an SER, when human–machine interaction is taken under consideration, the challenge is of detection of emotion in the speech; for detecting these features, the identification of acceptable features which characterize the distinct emotions, along with the features, right models also need to be identified to extract information specific to the emotions from the extracted speech features [7].
The rough categorization of speech emotion features is as follows [1]:
-
1.
Acoustic features
-
2.
Linguistic features (words + discourse)
-
3.
Hybrid features (acoustic + linguistic)
-
4.
Context Information (e.g., subject and gender).
In the SER, the dependencies on the speech and lexical content are ignored and focus is given on the extraction of emotion features and characterizing them. The speech features are further categorized into four categories namely continuous features, qualitative features, spectral features, and TEO (Teager energy operator)-based features. The continuous features or sometimes known as the prosodic featuresf are ones that are largely used in the SER’s [7, 8]. The use of qualitative features is done as the emotional content of the speech is related to voice quality [6]. The selection of spectral features is often done as a short-time representation for speech signals [6, 9]. The MFCC, LPCC, and LFPC are some of the widely known system features [5, 7]. The fourth feature category is based on the experimental studies done by Teager [6]. According to Teager, the speech is produced by nonlinear airflow in the human vocal system. In stressful situations, the airflow affects the speech; thus, nonlinear speech features are necessary for detecting speech. The sub-categorization of these features is done by Continuous/Prosodic features which are pitch-related, formant, energy-related, timing, and articulation features. The next subcategory is the Qualitative features; these are divided into voice level (signal amplitude, energy, and duration), voice pitch, phrase, phoneme, word and features boundaries, and temporal structures. Spectral/Vocal tract features are the next subcategory which include the LPC (linear predictor coefficients), SMC (time coherence method), LFPC (Log-frequency power coefficients), OSALPCC (one-sided autocorrelation linear predictor coefficients), LPCC (linear prediction cepstral coefficients), and MFCC (Mel-frequency cepstral coefficients). The last subcategory is TEO-based (Teager energy operator) which has TEO decomposed FM variation (TEO-FM-Var), Normalized TEO autocorrelation envelope area (TEO-Auto-Env), and Critical band-based TEO autocorrelation envelope area (TEO-CB-Auto-Env).
Speech Processing can be done either prior or later to the feature extraction. The speech which is used can be from different environments; thus performing some form of energy normalization, so it is important to each expression which is to be used. Different ways of normalizing include pre-emphasis radiation filter, feature normalization [6]. In some cases, to reduce the ripples in the stream, multiplication by a hamming window is done. In some cases, post-processing, i.e., working on the extracted values before using them to train and test on the models. It is done in some cases as the extracted features can be of different units [5]. A typical SER contains a two-stage process of first being feature extraction from the available input data and the second one being classifier which decides the underlying emotion of the speech. The Hidden Markov Model is a classifier which is used most in emotion classification [6]. There are also some systems which make use of Multiple Classifier System (MCS). In this model, three approaches can be followed namely hierarchical, serial, and parallel. The most used techniques are HMM (Hidden Markov Model), GMM (Gaussian Mixture model), SVM (Support Vector Machine), ANN (Artificial Neural Network), k-NN classifier, Fuzzy classifiers, and Decision trees. Databases or the speech corpora are chosen based on the motive to be achieved in the SER. The database, its content and the language chosen, and its actual scope need to be the considered criteria while the preparation of the database. The use of low-quality databases gives rise to incorrect conclusions. The speech corpora, based on design, is classified as [7, 9] Actor-based emotional speech database, Elicited emotional database, and Natural emotional speech database. This classification is done based on how the preparation of the database is done. Actor-based database has trained professionals who enact a certain situation, elicited database is the artificial emotional situation which is nearly similar to the natural database. Natural databases as the name suggests are created from real-world data.
Researchers have experimented with ensemble methods. In paper [14], the authors extracted features zero-crossing rate (ZCR), root mean square (RMS) energy, pitch frequency (normalized to 500 Hz), harmonics-to-noise ratio (HNR), and mel-frequency cepstral coefficients (MFCC) from the dataset FAU-Aibo corpus. The model was a classifier based on artificial neural networks with network topology using DL software tool Theano. The ensembling-learning method achieved the best unweighted average (UA) recall of 45%. Another study presented in [15] focused on prosodic and Spectral features and experimented on the RAVDESS and SAVEE datasets. The models Bagging and Boosting are the models used for the individual training. With experimental results, the author states that ensemble learning algorithms perform well and the random decision forest ensemble learning is efficient for SER. In paper [16], the authors have worked with IEMOCAP corpus to achieve a model that has shown greater accuracy of identification and higher ability to generalize. The models used are CNN and CRNN and LSTM. In the experimentation, the focus is given on the acoustic features. The weighted and unweighted accuracy of the ensemble model is 75%. In this study [17], the researchers have extracted prosodic features from a Natural Dataset, which is collected from a call-center and the ESMBS dataset. The ensemble model is a combination of Unweighted vote SVM with RBF kernel, random forest, K* instance-based learner, KNN with K = 5, and multi-layer perceptron. Experimental results show that StackingC, Vote, and SVM(RBF) have the highest accuracy of greater than 79% on the Natural Dataset using the forward selection and the StackingC classifier has the highest accuracy of 73.29% on the ESMBS using the genetic algorithm. The Researchers have extracted the MFCC and the Spectral Centroid features for the experiment purposes [18]. They have used multiple datasets; the Berlin EmoDB, RAVDESS, and IITKGP-SEHSC. The accuracy of 84.11% is achieved in the first ensemble model of Bagged ensemble of SVM’s. Comparatively, low accuracy of 77.19% is obtained for the AdaBoost ensemble of SVMs. In paper [19], the researchers have worked on multiple datasets Berlin emotional speech database (EmoDB), Surrey audio-visual expressed emotion database (SAVEE), and Aibo emotion corpus. The feature set used is the Spectral features, Mel-frequency cepstral coefficients (MFCC), linear predictor cepstral coefficients (LPCC), perceptual linear predictive (PLP), RASTA perceptual linear predictive (RASTA-PLP), and Prosodic Features. A Down sampling is applied to ensemble SoftMax regression model for speech emotion recognition (ESSER) which is the ESSER-SR. The EmoDB with speaker dependent ESSER has the WA of 88.68% and UA of 87.94%. For the SAVEE corpus with speaker dependent ESSER, the WA is 76.29% and UA is 73.42%. In the Aibo dataset ESSER-ER, the WA is 46.83% and UA is 45.58%.
The range of applications of SER is large, some are in the field of medical science, call center application, robotic engineering, in-car/self-driving cars, automation translation systems, aircraft cockpits, and mobile communications. It is found out that the SER is trained with stresses-speech to gain better performance than the ones which are trained in normal speech [6].
3 Experimental Setup
3.1 Dataset
In this work, we use the IEMOCAP released in 2008 by researchers at the University of Southern California (USC). It contains five recorded sessions of conversations from ten speakers and amounts to nearly 12 h of audio-visual information along with transcriptions. In the used dataset, the categorized emotions are angry, happy, sad, neutral, frustrated, excited, fearful, surprised, disgusted, and others. The use of session 5 is done for experimentation purposes and calculating the results.
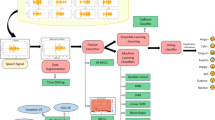
3.2 Architecture
Figure 1 shows the system architecture of such a speech sentiment analysis. The dataset is fed as the input to the system. Here, the dataset is the speech or voice data. This data is then pre-processed for removing any noise or unwanted features. The important features needed for analysis are retained and used to classify the input data into one of the predefined classes. The input voice signal data taken from training dataset is used to train the model over classification. All the blocks are explained in the following sections.

Speech emotion recognition architecture
3.3 Data Preprocessing
An initial frequency analysis revealed that the dataset is not balanced. For this purpose, the up-sampling of these emotions is done. So, the emotions such as “happy” and “excited” are merged into a single class “happy” along with “sad” and “frustrated” into a single class “sad”. This up-sampling is done as there was an under-representation of the emotion’s “fear” and “surprise”. The use of “others” is not done in the given experiments.
3.4 Building Audio Vectors and Feature Extraction
In this phase, the conversion of the audio data into the floating-point values need not be in order to perform operations on the input audio files. This gives us control over the audio file which is converted into a numerical sequence. The use of handcrafted features along with MFCC is done. From the floating-point values, that is, the audio time series built, audio features such as signal mean, signal standard deviation, sound energy, pitch, harmonics, and MFCCs (Mel-frequency cepstral coefficients) are extracted. These features would be used for training the machine learning models. The use of MFCC along with the handcrafted features improves the accuracy of the models individually as well as in the ensembled models. The comparison of the scores calculated for the individual models and ensembled models is shown in the Result and Analysis section of the paper.
3.5 Classifiers
-
ML Models: The following models will be trained on the extracted features and labels.
-
Random Forest: Random Forest is a powerful classification prediction method as a mix of the tree classifier [13]. It is a supervised learning model which uses labeled data to learn how to classify unlabeled data. The major benefits are its precision is not less than AdaBoost, runs quicker, and does not generate over-fitting. The Random Forest Algorithm is used to solve regression and classification problems, making it a model that is widely used by engineers. Random forest is a supervised classification similar to decision trees.
-
Gradient Boosting: Gradient boosting is a kind of algorithm which is used over other regular algorithms (for example, Gradient boosting over decision trees algorithm) for improving the performance of the regular algorithm [12].
-
Support Vector Machine: Support Vector Machines (SVM) are a supervised algorithm that works for both classification and regression problems [12]. Support vectors are coordinate points in space, formed using the attributes of a data point. Briefly, for an N-dimensional dataset, each data point is plotted on an N-dimensional space using all its feature vector values as a coordinate point. Classification between the classes is performed by finding a hyperplane in space that clearly separates the distinct classes. SVM works best for high-dimensional data. The important aspect of implementing an SVM algorithm is finding the hyperplane.
-
Naive Bayes: Naïve Bayes classifier is based on the Bayes theorem, which determines the probability of an event based on a prior probability of events [12]. The Bayes theorem is used to compute prior probability values. This classifier algorithm assumes feature independence. No correlation between the features is considered. The algorithm is said to be Naïve because it treats all the features to independently contribute to deciding the target class.
-
Logistic Regression: Logistic Regression is a supervised classification algorithm which produces probability values of data belonging to different classes [12]. There are three types of Logistic Regression algorithms, namely Binary class, Multi-class, and Ordinal class logistic algorithms depending on the type of target class. The Wikipedia definition states that Logistic regression computes the relationship between the target (dependent) variable and one or more independent variables using the estimated probability values through a “logistic function”. The logistic function, also known as a sigmoid function, maps predicted values to probability values.
-
Ensembling: An ensemble of the models would be used for better performance. Ensembling is the process of combining two or more models for improved results. Ensembling of the ML models gives a higher accuracy as compared to each respective model.
4 Score Calculation
The performance of the models would be evaluated based on the following scores: accuracy, precision, recall, and f-score. Based on the respective model’s scores, the ensemble is done.
-
1.
Accuracy: This refers to the percentage of test samples that are classified correctly.
-
2.
Precision: This measure tells us out of all predictions, how many are actually present in the ground truth also known as labels.
-
3.
Recall: This measure tells us how many correct labels are present in the predicted output.
-
4.
F-score: It is defined as the harmonic mean of precision and recall. This measure was included as accuracy is not a complete measure of a model’s predictive power but F-score is since it is more normalized.
5 Implementation Details
The experiments were performed on the Intel i5 processor with 8GB ram. The use of librosa which is a Python library is done to process the audio files and extract features from these respective files. The scikit-learn and XGBoost Python libraries were used for the implementation of the ML models.
6 Results
In this experiment, 80–20% of data is used for training and testing resp, which is split randomly. Five ML classifiers are implemented and the data is trained over these five ML classifiers separately, also ensemble model, and tested on the same. After that, based on the evaluation criteria, decided a single ensemble model to continue. The Accuracy, F-Score, Precision, and Recall are represented in the graphs for the respective trained models with the variation of including MFCC with continuous speech features. The use of continuous features is done most of the time in SER. The addition of MFCC is a spectral type of feature, which improves the accuracy of the models.
In Fig. 2, without MFCC, the graph shows the accuracy, F-score, Precision, and Recall for all 5 ML classifiers with a total of 8 features which are signal mean, signal standard deviation, sound energy, silence, pitch, harmonics, etc. The accuracy for XGBoost, Random Forest, and SVM is 55.9%, 54.2%, and 43.7%, respectively.

Evaluation w/o MFCC features
In Fig. 3, with MFCC, the graph shows the accuracy, F-score, Precision, and Recall for all 5 ML classifiers with a total of 21 features which are signal mean, signal standard deviation, sound energy, silence, pitch, harmonics, and 13 MFCC features. The accuracy for XGBoost, Random forest, and SVM is 63.8%, 62.2%, and 63.4%, respectively.

Evaluation with MFCC features
In Fig. 4, the same is calculated but for Ensemble Models. The feature set does not include MFCC values. All models show similar results. The combination of Random forest + XGBoost + Multinomial Naive Bayes gives fairly high values of accuracy as well as recall and the values are 56.1% and 58.4%, respectively.

Evaluation of Ensemble Model w/o MFCC features
In Fig. 5, the same is calculated but for Ensemble Models. Here, the feature set includes MFCC values. However, the combination of Random forest + XGBoost + Multinomial Naive Bayes gives fairly high values of accuracy as well as precision and the values are 63.6% and 67.3%, respectively.

Evaluation of Ensemble Model with MFCC features
7 Discussion and Limitation
In this work, we tackle the task of speech emotion recognition and study the contribution of different audio features to identify the emotion from the voice. It is the collective study of feature sets and the models used for the speech emotion recognition. The use of classifiers and the feature sets makes the difference in the performance of models and thus the scores differences.
The audio features set used in this paper are signal mean, signal standard deviation, sound energy, pitch, harmonics, and MFCCs (Mel-frequency cepstral coefficients). A voting classifier is used to ensemble numerous models and predict an output (class) based on their highest probability of the chosen class as the output. Simple aggregation of the findings of each classifier is passed into the Voting Classifier and predicts the output class based on most of the voting. We compare the performance of two feature sets: one including MFCC and the other excluding MFCC. It was observed that all the models offer better results when MFCCs are included in the feature space. The maximum accuracy is shown by XGBoost followed by Random forest and SVM. The testing of each model was done separately for calculating the accuracy of the respective model with the motive of forming the ensemble models by combining the models with the most accuracy. Each model is provided with 80% of the total dataset for ML model training and 20% for ML model testing. We show that ensembling multiple ML models leads to considerable improvement in performance. All depending upon the performance of the above-mentioned individual models, an ensemble model was created. An ensemble of Random Forest, XGBoost, and Multinomial Naïve Bayes gave the maximum accuracy as well as precision of 63.6% and 67.3%, respectively, with the MFCC features included.
While training the Multinomial Naive Bayes model, some labels in testing data don’t appear in predicted values. Therefore, no F-score was calculated for such labels, and thus the F-score for such cases is considered to be 0.0. Since an average of the score was requested, a score of 0 was also included in the calculation. The accuracy of the ensemble models was expected to be greater than the individual models. Except all others, only the XGBoost classifier gives similar results to that of the ensemble model. The model predicts with an accuracy of 63%. Three out of every five emotions are predicted correctly. The ensemble model of ML has a higher performance than the LSTM and ARE, 43.6% and 56.2%, the deep learning methods [10]. This proves that the lightweight and less memory consuming ML models do perform better than the DL methods in this case.
The project does not work on the textual manuscript or the dataset available for certain audio. The combination of text along with the audio dataset can improve the accuracy of the model and provide more precise predictions.
8 Conclusion and Future Work
There are many fields that require information about the emotional state. Technological development puts more pressure on the greater accuracy and simplicity of communication between man and computer. Current applications use speech as an input–output interface, and this trend is broadening increasingly. This type of interaction can develop problems caused by the absence of information about the emotional state. The work involves the implementation of ML models for SER. It should be able to classify speech according to the emotions of the speaker. The classification should be near real-time.
The use of extra audio features can improve the feature library. Features such as chromogram and other time-domain features can be included as well. The performance based on the scaling of data can also be observed by comparing the outputs generated by the ML classifiers and the extra feature library.
References
Huang, Zhengwei, et al. (2014). Speech emotion recognition using CNN. Proceedings of the 22nd ACM international conference on Multimedia.
Yoon, Seunghyun, Seokhyun Byun, and Kyomin Jung. (2018). Multimodal speech emotion recognition using audio and text. 2018 IEEE Spoken Language Technology Workshop (SLT). IEEE.
Jia, Jia, et al. (2018). Inferring emotions from large-scale internet voice data. IEEE Transactions on Multimedia 21.7 (2018): 1853–1866.
Sanjay A Valaki and Prof. Harikrishna B. Jethva. (2016). A Survey on Feature Extraction and Classification Techniques for Speech Recognition. International Journal of Advance Research and Innovative Ideas in Education 2.6(2016): 830–837.
Chandrasekar, Purnima, Santosh Chapaneri, and Deepak Jayaswal. (2014). Automatic speech emotion recognition: A survey. 2014 international conference on circuits, systems, communication and information technology applications (CSCITA). IEEE.
El Ayadi, Moataz, Mohamed S. Kamel, and Fakhri Karray. “Survey on speech emotion recognition: Features, classification schemes, and databases.” Pattern recognition 44.3 (2011): 572–587.
Koolagudi, Shashidhar G., and K. Sreenivasa Rao. “Emotion recognition from speech: a review.” International journal of speech technology 15.2 (2012): 99–117.
Swain, Monorama, Routray, Aurobinda, & Kabisatpathy, Prithviraj. (2018). Databases, features and classifiers for speech emotion recognition: a review. International Journal of Speech Technology, 21(1), 93–120.
Basu, Saikat, et al. “A review on emotion recognition using speech.” 2017 International Conference on Inventive Communication and Computational Technologies (ICICCT). IEEE, 2017.
Sahu, Gaurav. “Multimodal speech emotion recognition and ambiguity resolution.” arXiv preprint arXiv:1904.06022 (2019).
Tarunika, K., R. B. Pradeeba, and P. Aruna. “Applying machine learning techniques for speech emotion recognition.” 2018 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT). IEEE, 2018.
Sundarprasad, Neethu. “Speech emotion detection using machine learning techniques.” (2018).
Liu, Yanli, Yourong Wang, and Jian Zhang. “New machine learning algorithm: Random forest.” International Conference on Information Computing and Applications. Springer, Berlin, Heidelberg, 2012.
Shih, Po-Yuan, Chia-Ping Chen, and Chung-Hsien Wu. “Speech emotion recognition with ensemble learning methods.” 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017.
Zvarevashe, Kudakwashe, & Olugbara, Oludayo. (2020). Ensemble learning of hybrid acoustic features for speech emotion recognition. Algorithms, 13(3), 70.
Zheng, Chunjun, Wang, Chunli, & Jia, Ning. (2020). An ensemble model for multi-level speech emotion recognition. Applied Sciences, 10(1), 205.
Morrison, Donn, Ruili Wang, and Liyanage C. De Silva. “Ensemble methods for spoken emotion recognition in call-centres.” Speech communication 49.2 (2007): 98–112.
Bhavan, Anjali, Pankaj Chauhan, and Rajiv Ratn Shah. “Bagged support vector machines for emotion recognition from speech.” Knowledge-Based Systems 184 (2019): 104886.
Sun, Yaxin, & Wen, Guihua. (2017). Ensemble softmax regression model for speech emotion recognition. Multimedia Tools and Applications, 76(6), 8305–8328.
Acknowledgements
This work was supported by the Pune Institute of Computer Technology (PICT), Pune. We thank the authorities of PICT for resources, support, and motivation. Dr. Dharmadhikari and Mrs. Chandak have been our reviewers throughout this project and have been guiding us on our numerous queries.
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Dhondge, S., Shewale, R., Satao, M., Jagdale, J. (2022). Impact of Lightweight Machine Learning Models for Speech Emotion Recognition. In: Khanna, A., Gupta, D., Bhattacharyya, S., Hassanien, A.E., Anand, S., Jaiswal, A. (eds) International Conference on Innovative Computing and Communications. Advances in Intelligent Systems and Computing, vol 1387. Springer, Singapore. https://doi.org/10.1007/978-981-16-2594-7_20
Download citation
DOI: https://doi.org/10.1007/978-981-16-2594-7_20
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-2593-0
Online ISBN: 978-981-16-2594-7
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)