
Abstract
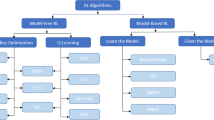
Our aim is to optimize the performance of ads for company products which are being deployed at user’s end to increase the revenue generated by getting more clicks and also spending less time and money in Research and Development. This is a specific application that we have chosen, but it can be applied in various fields as per the requirement of the problem. This is done by first analyzing the demands of various products by making use of various factors like product category and the time period of the year. Once it is found that the products have low sales, the ads are pushed to create interest among the users. Multiple ads which are created by the company are deployed and then optimized by analyzing the clicks that they generate over a period of time. Hit and trial way for exploring is one of the characteristic features of reinforced algorithms. For unique cases actions not only affect the present state but also the next state and the succeeding rewards. We have tried to find a way to solve the problem of multi-armed bandit (MAB) problem or N-armed bandit problem. Though several strategies have been suggested over the years, the two most prominent and commonly used are upper confidence limit (UCB) and Thompson sampling (TS). This paper explains why N-arm is preferable over A/B testing in such cases. Comparison of various approaches to solve the N-arm problem has been done. The strategies that we use for gathering of information and exploiting includes two methods, first option being arbitrary selection and the second one is that we are optimistic about uncertain machine initially and we collect the information of getting success in each round from selected machine. These actions having higher arbitrariness are favored because they provide more data advantage. We found out that Thompson sampling slightly outperforms UCB since it does a better job at manipulation.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Abbreviations
- MAB:
-
Multi-armed Bandit
- ML:
-
Machine Learning
- RL:
-
Reinforcement Learning
- TS:
-
Thompson sampling
- UCB:
-
Upper confidence bound
References
Bharat K, Henzinger M (2017) Improved algorithms for topic distillation in a hyperlinked environment. ACM SIGIR Forum 51(2):194–201
Barto AG (2013) Intrinsic motivation and reinforcement learning. In: Intrinsically motivated learning in natural and artificial systems. Springer, Berlin, pp 17–47
Kaelbling LP, Littman ML Moore AW (1996) Reinforcement learning: a survey. J Artif intell res 4:237–285
Whitehead S, Ballard D (1991) Learning to perceive and act by trial and error. Mach Learn 7(1):45–83
Rydén T (1997) On recursive estimation for hidden Markov models. Stoch Process Appl 66(1):79–96
Auer P (2002) Using confidence bounds for exploitation-exploration trade-offs. J Mach Learn Res 3:397–422
Hansen LV, Kiderlen M, Vedel Jensen EB (2011) Image-based empirical importance sampling: an efficient way of estimating intensities. Scand J Stat 38(3):393–408
Féraud R, Urvoy T (2013) Exploration and exploitation of scratch games. Mach Learn 92(2–3):377–401
Osband I, Van Roy B, Russo D, Wen Z (2017) Deep exploration via randomized value functions. arXiv:1703.07608
Audibert J, Munos R, Szepesvári C (2009) Exploration–exploitation tradeoff using variance estimates in multi-armed bandits. Theoret Comput Sci 410(19):1876–1902
Szepesvári C (2010) Algorithms for reinforcement learning. Synth Lect Artif Intell Mach Learn 4(1):1–103
Pelekis C, Ramon J (2017) Hoeffding’s inequality for sums of dependent arbritrary variables. Mediterr J Math 14(6)
Littman ML (2015) Reinforcement learning improves behaviour from evaluative feedback. Nature 521(7553):445
Luhmann C (2013) Discounting of delayed rewards is not hyperbolic. J Exp Psychol Learn Mem Cogn 39(4):1274–1279
Zoghi M, Whiteson S, Munos R, de Rijke M (2013). Relative upper confidence bound for the K-armed dueling bandit problem
Guttman I, Scollnik D (1994) An index sampling algorithm for analysis. Commun Stat Simul Comput 23(2):323–339
Vorobeychik Y, Kantarcioglu M (2018) Adversarial machine learning. Synth Lect Artif Intell Mach Learn 12(3):1–169
Shepard R (1964) Feigenbaum E, Feldman J (eds) Computers and thought. Behav Sci 9(1):57–65 (1963)
Lillicrap TP, Hunt JJ, Pritzel A, Heess N, Erez T, Tassa Y, Wierstra D (2015) Continuous control with deep reinforcement learning. arXiv:1509.02971
Riquelme C, Tucker G, Snoek J (2018) Deep bayesian bandits showdown: an empirical comparison of bayesian deep networks for Thompson sampling. arXiv:1802.09127
Mei Y (2006) Sequential change-point detection when unknown parameters are present in the pre-change distribution. Ann Stat 34(1):92–122
Barto A (1991) Learning and incremental dynamic programming. Behav Brain Sci 14(1):94–95
Russo D, Van Roy B, Kazerouni A, Osband I, Wen Z (2018) A tutorial on Thompson sampling. Found Trends Mach Learn 11(1):1–96
Chen W, Niu Z, Zhao X, Li Y (2012) A hybrid recommendation algorithm adapted in e-learning environments. World Wide Web 17(2):271–284
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Jain, R., Nagrath, P., Raina, S.T., Prakash, P., Thareja, A. (2021). ADS Optimization Using Reinforcement Learning. In: Abraham, A., Castillo, O., Virmani, D. (eds) Proceedings of 3rd International Conference on Computing Informatics and Networks. Lecture Notes in Networks and Systems, vol 167. Springer, Singapore. https://doi.org/10.1007/978-981-15-9712-1_6
Download citation
DOI: https://doi.org/10.1007/978-981-15-9712-1_6
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-9711-4
Online ISBN: 978-981-15-9712-1
eBook Packages: EngineeringEngineering (R0)