
Abstract
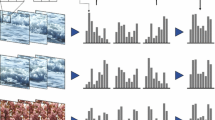
Real-world videos often contain dynamic backgrounds and evolving people activities, especially for those web videos generated by users in unconstrained scenarios. This paper proposes a new visual representation, namely scene aligned pooling, for the task of event recognition in complex videos. Based on the observation that a video clip is often composed with shots of different scenes, the key idea of scene aligned pooling is to decompose any video features into concurrent scene components, and to construct classification models adaptive to different scenes. The experiments on two large scale real-world datasets including the TRECVID Multimedia Event Detection 2011 and the Human Motion Recognition Databases (HMDB) show that our new visual representation can consistently improve various kinds of visual features such as different low-level color and texture features, or middle-level histogram of local descriptors such as SIFT, or space-time interest points, and high level semantic model features, by a significant margin. For example, we improve the-state-of-the-art accuracy on HMDB dataset by 20% in terms of accuracy.
Chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Schuldt, C., Laptev, I., Caputo, B.: Recognizing human actions: A local SVM approach. In: ICPR (2004)
Blank, M., Gorelick, L., Shechtman, E., Irani, M., Basri, R.: Actions as space-time shapes. In: ICCV (2005)
Liu, J., Luo, J., Shah, M.: Recognizing realistic actions from videos ”in the wild”. In: CVPR (2009)
Efros, A., Berg, A., Mori, G., Malik, J.: Recognizing action at a distance. In: ICCV, pp. 726–733 (2003)
Epstein, R., Kanwisher, N.: A cortical representation of the local visual environment. Nature 392, 598–601 (1998)
Friedman, A.: Framing pictures: The role of knowledge in automatized encoding and memory for gist. Journal of Experimental Psychology 108, 316–355 (1979)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proceedings of the IEEE 86, 2278–2324 (1998)
Niebles, J.C., Wang, H., Fei-Fei, L.: Unsupervised learning of human action categories using spatial-temporal words. IJCV 79, 299–318 (2008)
Dollár, P., Rabaud, V., Cottrell, G., Belongie, S.: Behavior recognition via sparse spatio-temporal features. In: IEEE International Workshop on VS-PETS (2005)
Laptev, I., Marszalek, M., Schmid, C., Rozenfeld, B.: Learning realistic human actions from movies. In: CVPR (2008)
Boureau, Y.L., Bach, F., LeCun, Y., Ponce, J.: Learning mid-level features for recognition. In: CVPR (2010)
Yang, J., Yu, K., Gong, Y., Huang, T.: Linear pyramid matching using sparse coding for image classification. In: CVPR (2009)
Jégou, H., Douze, M., Schmid, C., Pérez, P.: Aggregating local descriptors into a compact image representation. In: 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3304–3311. IEEE (2010)
Lazebnik, S., Schmid, C., Ponce, J.: Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In: CVPR, vol. 2, pp. 2169–2178 (2006)
Boureau, Y., Le Roux, N., Bach, F., Ponce, J., LeCun, Y.: Ask the locals: multi-way local pooling for image recognition. In: ICCV (2011)
Oliva, A., Torralba, A.: Modeling the shape of the scene: a holistic representation of the spatial envelope. IJCV 42 (2004)
Fei-Fei, L., Perona, P.: A bayesian hierarchy model for learning natural scene categories. In: CVPR (2005)
Russell, B., Torralba, A., Liu, C., Fergus, R., Freeman, W.T.: Object recognition by scene alignment. In: NIPS (2007)
Boutell, M., Luo, J., Brown, C.M.: Improved semantic region labeling based on scene context. In: ICME (2005)
Li, L.J., Fei-Fei, L.: What, where and who? classifying events by scene and object recognition. In: ICCV (2007)
Marszalek, M., Laptev, I., Schmid, C.: Actions in context. In: CVPR (2009)
Kimeldorf, G., Wahba, G.: Some results on tchebychefan spline functions. Journal of Mathematical Analysis and Applications 33, 82–95 (1971)
Yu, H., Hsieh, C., Chang, K., Lin, C.: Large linear classification when data cannot fit in memory. In: Proceedings of ACM SIGKDD, pp. 833–842. ACM (2010)
Xiao, J., Haysy, J., Ehinger, K.A., Oliva, A., Torralba, A.: Sun database: Large-scale scene recognition from abbey to zoo. In: CVPR (2010)
Zhang, B., Hsu, M., Dayal, U.: K-harmonic means-a data clustering algorithm. Hewlett-Packard Labs Technical Report HPL-1999-124 (1999)
Fan, R., Chang, K., Hsieh, C., Wang, X., Lin, C.: Liblinear: A library for large linear classification. The Journal of Machine Learning Research 9, 1871–1874 (2008)
Cao, L., Chang, S.F., Codella, N., Cotton, C., Ellis, D., Gong, L., Hill, M., Huang, G., Kender, J., Merler, M., Mu, Y., Natseve, A., Smith, J.R.: Ibm research and columbia university trecvid-2011 multimedia event detection (med) systems. In: NIST TRECVID Workshop (2011)
Natsev, A., Naphade, M.R., Smith, J.R.: Semantic representation, search and mining of multimedia content. In: ACM KDD, pp. 641–646 (2004)
Merler, M., Bert Huang, L.X., Hua, G., Natsev, A.: Semantic model vectors for complex video event recognition. IEEE Transactions on Multimedia (2011)
Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., Serre, T.: Hmdb: A large video database for human motion recognition. In: ICCV (2011)
Jhuang, H., Serre, T., Wolf, L., Poggio, T.: A biologically inspired system for action recognition. In: ICCV (2007)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2012 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Cao, L., Mu, Y., Natsev, A., Chang, SF., Hua, G., Smith, J.R. (2012). Scene Aligned Pooling for Complex Video Recognition. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds) Computer Vision – ECCV 2012. ECCV 2012. Lecture Notes in Computer Science, vol 7573. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-33709-3_49
Download citation
DOI: https://doi.org/10.1007/978-3-642-33709-3_49
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-33708-6
Online ISBN: 978-3-642-33709-3
eBook Packages: Computer ScienceComputer Science (R0)