
Abstract
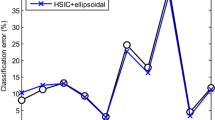
This paper proposes a new method of incorporating prior domain knowledge into a kernel based feature selection algorithm. The proposed feature selection algorithm combines the Fast Correlation-Based Filter (FCBF) and the kernel methods in order to uncover an optimal subset of features for the support vector regression. In the proposed algorithm, the Kernel Canonical Correlation Analysis (KCCA) is employed as a measurement of mutual information between feature candidates. Domain knowledge in forms of constraints is used to guide the tuning of the KCCA. In the second experiments, the audit quality research carried by Yang Li and Donald Stokes [1] provides the domain knowledge, and the result extends the original subset of features.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others
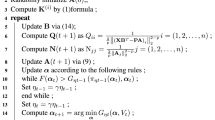

References
Li, Y., Stokes, D., Hamilton, J.: Listed company auditor self-selection bias and audit fee premiums (2005)
Cheeseman, P., Stutz, J.: Bayesian classification (autoclass): Theory and results. In: Advances in Knowledge Discovery and Data Mining, pp. 153–180 (1996)
Hall, M.A.: Correlation-based Feature Selection for Machine Learning. Phd thesis, Waikato University (1999)
Koller, D., Sahami, M.: Toward optimal feature selection. In: Thirteenth International Conference on Machine Learning, pp. 284–292. Morgan Kaufmann, San Francisco (1996)
John, G.H., Kohavi, R., Pfleger, K.: Irrelevant features and the subset selection problem. In: International Conference on Machine Learning, pp. 121–129 (1994)
Guyon, I., et al.: Gene selection for cancer classification using support vector machines. Machine Learning 46(1-3), 389–422 (2002)
Bach, F.R., Jordan, M.I.: Kernel independent component analysis. Journal of Machine Learning Research 3, 1–48 (2002)
Davidson, I., Ravi, S.S.: Hierarchical clustering with constraints: Theory and practice. In: 9th European Principles and Practice of KDD, PKDD (2005), http://www.cs.albany.edu/~davidson/
Yu, L., Liu, H.: Efficient feature selection via analysis of relevance and redundancy. Journal of Machine Learning Research 5, 1205–1224 (2004)
Breiman, L.: Heuristics of instability and stabilization in model selection. The Annals of Statistics 24(6), 2350–2383 (1996)
Soares, C., Brazdil, P.B., Kuba, P.: A meta-learning methods to select the kernel width in support vector regression. Machine Learning 54, 195–209 (2004)
Author information
Authors and Affiliations
Editor information
Rights and permissions
Copyright information
© 2007 Springer Berlin Heidelberg
About this paper
Cite this paper
Yu, T., Simoff, S.J., Stokes, D. (2007). Incorporating Prior Domain Knowledge into a Kernel Based Feature Selection Algorithm. In: Zhou, ZH., Li, H., Yang, Q. (eds) Advances in Knowledge Discovery and Data Mining. PAKDD 2007. Lecture Notes in Computer Science(), vol 4426. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-71701-0_120
Download citation
DOI: https://doi.org/10.1007/978-3-540-71701-0_120
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-71700-3
Online ISBN: 978-3-540-71701-0
eBook Packages: Computer ScienceComputer Science (R0)