
Abstract
Hyperproperties are properties of sets of computation traces. In this paper, we study quantitative hyperproperties, which we define as hyperproperties that express a bound on the number of traces that may appear in a certain relation. For example, quantitative non-interference limits the amount of information about certain secret inputs that is leaked through the observable outputs of a system. Quantitative non-interference thus bounds the number of traces that have the same observable input but different observable output. We study quantitative hyperproperties in the setting of HyperLTL, a temporal logic for hyperproperties. We show that, while quantitative hyperproperties can be expressed in HyperLTL, the running time of the HyperLTL model checking algorithm is, depending on the type of property, exponential or even doubly exponential in the quantitative bound. We improve this complexity with a new model checking algorithm based on model-counting. The new algorithm needs only logarithmic space in the bound and therefore improves, depending on the property, exponentially or even doubly exponentially over the model checking algorithm of HyperLTL. In the worst case, the new algorithm needs polynomial space in the size of the system. Our Max#Sat-based prototype implementation demonstrates, however, that the counting approach is viable on systems with nontrivial quantitative information flow requirements such as a passcode checker.
This work was partly supported by the ERC Grant 683300 (OSARES) and by the German Research Foundation (DFG) in the Collaborative Research Center 1223.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others




1 Introduction
Model checking algorithms [17] are the cornerstone of computer-aided verification. As their input consists of both the system under verification and a logical formula that describes the property to be verified, they uniformly solve a wide range of verification problems, such as all verification problems expressible in linear-time temporal logic (LTL), computation-tree logic (CTL), or the modal \(\mu \)-calculus. Recently, there has been a lot of interest in extending model checking from standard trace and tree properties to information flow policies like observational determinism or quantitative information flow. Such policies are called hyperproperties [21] and can be expressed in HyperLTL [18], an extension of LTL with trace quantifiers and trace variables. For example, observational determinism [47], the requirement that any pair of traces that have the same observable input also have the same observable output, can be expressed as the following HyperLTL formula:  For many information flow policies of interest, including observational determinism, there is no longer a need for property-specific algorithms: it has been shown that the standard HyperLTL model checking algorithm [26] performs just as well as a specialized algorithm for the respective property.
For many information flow policies of interest, including observational determinism, there is no longer a need for property-specific algorithms: it has been shown that the standard HyperLTL model checking algorithm [26] performs just as well as a specialized algorithm for the respective property.
The class of hyperproperties studied in this paper is one where, by contrast, the standard model checking algorithm performes badly. We are interested in quantitative hyperproperties, i.e., hyperproperties that express a bound on the number of traces that may appear in a certain relation. A prominent example of this class of properties is quantitative non-interference [43, 45], where we allow some flow of information but, at the same time, limit the amount of information that may be leaked. Such properties are used, for example, to describe the correct behavior of a password check, where some information flow is unavoidable (“the password was incorrect”), and perhaps some extra information flow is acceptable (“the password must contain a special character”), but the information should not suffice to guess the actual password. In HyperLTL, quantitative non-interference can be expressed [18] as the formula  The formula states that there do not exist \(2^c+1\) traces (corresponding to more than c bits of information) with the same observable input but different observable output. The bad performance of the standard model checking algorithm is a consequence of the fact that the \(2^{c}+1\) traces are tracked simultaneously. For this purpose, the model checking algorithm builds and analyzes a \((2^c+1)\)-fold self-composition of the system.
The formula states that there do not exist \(2^c+1\) traces (corresponding to more than c bits of information) with the same observable input but different observable output. The bad performance of the standard model checking algorithm is a consequence of the fact that the \(2^{c}+1\) traces are tracked simultaneously. For this purpose, the model checking algorithm builds and analyzes a \((2^c+1)\)-fold self-composition of the system.
We present a new model checking algorithm for quantitative hyperproperties that avoids the construction of the huge self-composition. The key idea of our approach is to use counting rather than checking as the basic operation. Instead of building the self-composition and then checking the satisfaction of the formula, we add new atomic propositions and then count the number of sequences of evaluations of the new atomic propositions that satisfy the specification. Quantitative hyperproperties are expressions of the following form:
where \(\triangleleft \in \{\le ,<,\ge ,>,=\}\). The universal quantifiers introduce a set of reference traces against which other traces can be compared. The formulas \(\varphi \) and \(\psi \) are HyperLTL formulas. The counting quantifier \(\# \sigma :X.\, \psi \) counts the number of paths \(\sigma \) with different valuations of the atomic propositions X that satisfy \(\psi \). The requirement that no more than c bits of information are leaked is the following quantitative hyperproperty:

As we show in the paper, such expressions do not change the expressiveness of the logic; however, they allow us to express quantitative hyperproperties in exponentially more concise form. The counting-based model checking algorithm then maintains this advantage with a logarithmic counter, resulting in exponentially better performance in both time and space.
The viability of our counting-based model checking algorithm is demonstrated on a SAT-based prototype implementation. For quantitative hyperproperties of intrest, such as bounded leakage of a password checker, our algorithm shows promising results, as it significantly outperforms existing model checking approaches.
1.1 Related Work
Quantitative information-flow has been studied extensively in the literature. See, for example, the following selection of contributions on this topic: [1, 14, 19, 32, 34, 43]. Multiple verification methods for quantitative information-flow were proposed for sequential systems. For example, with static analysis techniques [15], approximation methods [35], equivalence relations [3, 22], and randomized methods [35]. Quantitative information-flow for multi-threaded programs was considered in [11].
The study of quantitative information-flow in a reactive setting gained a lot of attention recently after the introduction of hyperproperties [21] and the idea of verifying the self-composition of a reactive system [6] in order to relate traces to each other. There are several possibilities to measure the amount of leakage, such as Shannon entropy [15, 24, 37], guessing entropy [3, 34], and min-entropy [43]. A classification of quantitative information-flow policies as safety and liveness hyperproperties was given in [46]. While several verification techniques for hyperproperties exists [5, 31, 38, 42], the literature was missing general approaches to quantitative information-flow control. SecLTL [25] was introduced as first general approach to model check (quantitative) hyperproperties, before HyperLTL [18], and its corresponding model checker [26], was introduced as a temporal logic for hyperproperties, which subsumes the previous approaches.
Using counting to compute the number of solutions of a given formula is studied in the literature as well and includes many probabilistic inference problems, such as Bayesian net reasoning [36], and planning problems, such as computing robustness of plans in incomplete domains [40]. State-of-the-art tools for propositional model counting are Relsat [33] and c2d [23]. Algorithms for counting models of temporal logics and automata over infinite words have been introduced in [27, 28, 44]. The counting of projected models, i.e., when some parts of the models are irrelevant, was studied in [2], for which tools such as #CLASP [2] and DSharp_P [2, 41] exist. Our SAT-based prototype implementation is based on a reduction to a Max#SAT [29] instance, for which a corresponding tool exists.
Among the already existing tools for computing the amount of information leakage, for example, QUAIL [8], which analyzes programs written in a specific while-language and LeakWatch [12], which estimates the amount of leakage in Java programs, Moped-QLeak [9] is closest to our approach. However, their approach of computing a symbolic summary as an Algebraic Decision Diagram is, in contrast to our approach, solely based on model counting, not maximum model counting.
2 Preliminaries
2.1 HyperLTL
HyperLTL [18] extends linear-time temporal logic (LTL) with trace variables and trace quantifiers. Let \( AP \) be a set of atomic propositions. A trace t is an infinite sequence over subsets of the atomic propositions. We define the set of traces  . A subset \(T \subseteq TR \) is called a trace property and a subset \(H \subseteq 2^ TR \) is called a hyperproperty. We use the following notation to manipulate traces: let \(t \in TR \) be a trace and \(i \in \mathbb {N}\) be a natural number. t[i] denotes the i-th element of t. Therefore, t[0] represents the starting element of the trace. Let \(j \in \mathbb {N}\) and \(j \ge i\). t[i, j] denotes the sequence \(t[i]~t[i+1]\ldots t[j-1]~t[j]\). \(t[i, \infty ]\) denotes the infinite suffix of t starting at position i.
. A subset \(T \subseteq TR \) is called a trace property and a subset \(H \subseteq 2^ TR \) is called a hyperproperty. We use the following notation to manipulate traces: let \(t \in TR \) be a trace and \(i \in \mathbb {N}\) be a natural number. t[i] denotes the i-th element of t. Therefore, t[0] represents the starting element of the trace. Let \(j \in \mathbb {N}\) and \(j \ge i\). t[i, j] denotes the sequence \(t[i]~t[i+1]\ldots t[j-1]~t[j]\). \(t[i, \infty ]\) denotes the infinite suffix of t starting at position i.
HyperLTL Syntax. Let \(\mathcal {V}\) be an infinite supply of trace variables. The syntax of HyperLTL is given by the following grammar:

where \(a\in AP \) is an atomic proposition and \(\pi \in \mathcal V\) is a trace variable. Note that atomic propositions are indexed by trace variables. The quantification over traces makes it possible to express properties like “on all traces \(\psi \) must hold”, which is expressed by \(\forall \pi .~\psi \). Dually, one can express that “there exists a trace such that \(\psi \) holds”, which is denoted by \(\exists \pi .~\psi \). The derived operators  ,
,  , and \(\mathcal W\) are defined as for LTL. We abbreviate the formula \(\bigwedge _{x\in X} (x_\pi \leftrightarrow x_{\pi '})\), expressing that the traces \(\pi \) and \(\pi '\) are equal with respect to a set \(X \subseteq AP \) of atomic propositions, by \(\pi =_X \pi '\). Furthermore, we call a trace variable \(\pi \) free in a HyperLTL formula if there is no quantification over \(\pi \) and we call a HyperLTL formula \(\varphi \) closed if there exists no free trace variable in \(\varphi \).
, and \(\mathcal W\) are defined as for LTL. We abbreviate the formula \(\bigwedge _{x\in X} (x_\pi \leftrightarrow x_{\pi '})\), expressing that the traces \(\pi \) and \(\pi '\) are equal with respect to a set \(X \subseteq AP \) of atomic propositions, by \(\pi =_X \pi '\). Furthermore, we call a trace variable \(\pi \) free in a HyperLTL formula if there is no quantification over \(\pi \) and we call a HyperLTL formula \(\varphi \) closed if there exists no free trace variable in \(\varphi \).
HyperLTL Semantics. A HyperLTL formula defines a hyperproperty, i.e., a set of sets of traces. A set T of traces satisfies the hyperproperty if it is an element of this set of sets. Formally, the semantics of HyperLTL formulas is given with respect to a trace assignment \(\varPi \) from \(\mathcal {V}\) to \( TR \), i.e., a partial function mapping trace variables to actual traces. \(\varPi [\pi \mapsto t]\) denotes that \(\pi \) is mapped to t, with everything else mapped according to \(\varPi \). \(\varPi [i,\infty ]\) denotes the trace assignment that is equal to \(\varPi (\pi )[i,\infty ]\) for all \(\pi \).

We say a set of traces T satisfies a HyperLTL formula \(\varphi \) if \(\varPi \models _T \varphi \), where \(\varPi \) is the empty trace assignment.
2.2 System Model
A Kripke structure is a tuple \(K=(S,s_0,\delta , AP ,L)\) consisting of a set of states S, an initial state \(s_0 \in S\), a transition function \(\delta : S \rightarrow 2^S\), a set of atomic propositions \( AP \), and a labeling function \(L : S \rightarrow 2^ AP \), which labels every state with a set of atomic propositions. We assume that each state has a successor, i.e., \(\delta (s) \not = \emptyset \). This ensures that every run on a Kripke structure can always be extended to an infinite run. We define a path of a Kripke structure as an infinite sequence of states \(s_0s_1\dots \in S^\omega \) such that \(s_0\) is the initial state of K and \(s_{i+1} \in \delta (s_i)\) for every \(i \in \mathbb {N}\). We denote the set of all paths of K that start in a state s with \( Paths (K,s)\). Furthermore, \( Paths ^*(K,s)\) denotes the set of all path prefixes and \( Paths ^\omega (K,s)\) the set of all path suffixes. A trace of a Kripke structure is an infinite sequence of sets of atomic propositions \(L(s_0),L(s_1),\dots \in (2^ AP )^\omega \), such that \(s_0\) is the initial state of K and \(s_{i+1} \in \delta (s_i)\) for every \(i \in \mathbb {N}\). We denote the set of all traces of K that start in a state s with \( TR (K,s)\). We say that a Kripke structure K satisfies a HyperLTL formula \(\varphi \) if its set of traces satisfies \(\varphi \), i.e., if \(\varPi \models _{ TR (K,s_0)} \varphi \), where \(\varPi \) is the empty trace assignment.
2.3 Automata over Infinite Words
In our construction we use automata over infinite words. A Büchi automaton is a tuple \(\mathcal B = (Q,Q_0,\delta ,\varSigma ,F)\), where Q is a set of states, \(Q_0\) is a set of initial states, \(\delta : Q \times \varSigma \rightarrow 2^Q\) is a transition relation, and \(F\subset Q\) are the accepting states. A run of \(\mathcal B\) on an infinite word \(w = \alpha _1 \alpha _2 \dots \in \varSigma ^\omega \) is an infinite sequence \(r = q_0 q_1 \dots \in Q^\omega \) of states, where \(q_0 \in Q_0\) and for each \(i \ge 0\), \(q_{i+1} = \delta (q_i,\alpha _{i+1})\). We define \(\mathbf{Inf }(r)=\{q \in Q \mid \forall i \exists j>i.~r_j = q\}\). A run r is called accepting if \(\mathbf{Inf }(r) \cap F \not = \emptyset \). A word w is accepted by \(\mathcal B\) and called a model of \(\mathcal B\) if there is an accepting run of \(\mathcal B\) on w.
Furthermore, an alternating automaton, whose runs generalize from sequences to trees, is a tuple \(\mathcal A = (Q,Q_0,\delta ,\varSigma ,F)\). \(Q,Q_0, \varSigma \), and F are defined as above and \(\delta : Q \times \varSigma \rightarrow \mathbb {B}^+{Q}\) being a transition function, which maps a state and a symbol into a Boolean combination of states. Thus, a run(-tree) of an alternating Büchi automaton \(\mathcal A\) on an infinite word w is a Q-labeled tree. A word w is accepted by \(\mathcal {A}\) and called a model if there exists a run-tree T such that all paths p trough T are accepting, i.e., \(\mathbf{Inf }(p) \cap F \not = \emptyset \).
A strongly connected component (SCC) in \(\mathcal A\) is a maximal strongly connected component of the graph induced by the automaton. An SCC is called accepting if one of its states is an accepting state in \(\mathcal A\).
3 Quantitative Hyperproperties
Quantitative Hyperproperties are properties of sets of computation traces that express a bound on the number of traces that may appear in a certain relation. In the following, we study quantitative hyperproperties that are specified in terms of HyperLTL formulas. We consider expressions of the following general form:
Both the universally quantified variables \(\pi _1,\dots ,\pi _k\) and the variable \(\sigma \) after the counting operator \(\#\) are trace variables; \(\varphi \) is a HyperLTL formula over atomic propositions AP and free trace variables \(\pi _1 \ldots \pi _k\); \(A \subseteq AP\) is a set of atomic propositions; \(\psi \) is a HyperLTL formula over atomic propositions AP and free trace variables \(\pi _1 \ldots \pi _k\) and, additionally \(\sigma \). The operator \(\triangleleft \in \{<,\le ,=,>,\ge \}\) is a comparison operator; and \(n \in \mathbb {N}\) is a natural number.
For a given set of traces T and a valuation of the trace variables \(\pi _1,\dots ,\pi _k\), the term \(\# \sigma : A.\, \psi \) computes the number of traces \(\sigma \) in T that differ in their valuation of the atomic propositions in A and satisfy \(\psi \). The expression \(\# \sigma : A.\, \psi \triangleleft n\) is \( true \) iff the resulting number satisfies the comparison with n. Finally, the complete expression \(\forall \pi _1,\dots ,\pi _k.\,\varphi \rightarrow (\# \sigma : A.\, \psi \triangleleft n)\) is \( true \) iff for all combinations \(\pi _1,\dots ,\pi _k\) of traces in T that satisfy \(\varphi \), the comparison \(\# \sigma : A.\, \psi \triangleleft n\) is satisfied.
Example 1
(Quantitative non-interference). Quantitative information-flow policies [13, 20, 30, 34] allow the flow of a bounded amount of information. One way to measure leakage is with min-entropy [43], which quantifies the amount of information an attacker can gain given the answer to a single guess about the secret. The bounding problem [45] for min-entropy is to determine whether that amount is bounded from above by a constant \(2^c\), corresponding to c bits. We assume that the program whose leakage is being quantified is deterministic, and assume that the secret input to that program is uniformly distributed. The bounding problem then reduces to determining that there is no tuple of \(2^c+1\) distinguishable traces [43, 45]. Let \(O \subseteq AP\) be the set of observable outputs. A simple quantitative information flow policy is then the following quantitative hyperproperty, which bounds the number of distinguishable outputs to \(2^c\), corresponding to a bound of c bits of information:
A slightly more complicated information flow policy is quantitative non-interference. In quantitative non-interference, the bound must be satisfied for every individual input. Let \(I \subseteq AP\) be the observable inputs to the system. Quantitative non-interference is the following quantitative hyperpropertyFootnote 1:

For each trace \(\pi \) in the system, the property checks whether there are more than \(2^c\) traces \(\sigma \) that have the same observable input as \(\pi \) but different observable output.
Example 2
(Deniability). A program satisfies deniability (see, for example, [7, 10]) when there is no proof that a certain input occurred from simply observing the output, i.e., given an output of a program one cannot derive the input that lead to this output. A deterministic program satisfies deniability when each output can be mapped to at least two inputs. A quantitative variant of deniability is when we require that the number of corresponding inputs is larger than a given threshold. Quantitative deniability can be specified as the following quantitative Hyperproperty:

For all traces \(\pi \) of the system we count the number of sequences \(\sigma \) in the system with different input sequences and the same output sequence of \(\pi \), i.e., for the fixed output sequence given by \(\pi \) we count the number of input sequences that lead to this output.
4 Model Checking Quantitative Hyperproperties
We present a model checking algorithm for quantitative hyperproperties based on model counting. The advantage of the algorithm is that its runtime complexity is independent of the bound n and thus avoids the n-fold self-composition necessary for any encoding of the quantitative hyperproperty in HyperLTL.
Before introducing our novel counting-based algorithm, we start by a translation of quantitative hyperproperties into formulas in HyperLTL and establishing an exponential lower bound for its representation.
4.1 Standard Model Checking Algorithm: Encoding Quantitative Hyperproperties in HyperLTL
The idea of the reduction is to check a lower bound of n traces by existentially quantifying over n traces, and to check an upper bound of n traces by universally quantifying over \(n+1\) traces. The resulting HyperLTL formula can be verified using the standard model checking algorithm for HyperLTL [18].
Theorem 1
Every quantitative hyperproperty \( \forall \pi _1,\dots ,\pi _k.\ \psi _\iota \rightarrow (\# \sigma : A.\ \psi \triangleleft n) \) can be expressed as a HyperLTL formula. For \(\triangleleft \in \{\le \} (\{<\})\), the HyperLTL formula has \(n+k+1 (\text {resp. } n+k)\) universal trace quantifiers in addition to the quantifiers in \(\psi _\iota \) and \(\psi \). For \(\triangleleft \in \{\ge \} (\{>\})\), the HyperLTL formula has k universal trace quantifiers and n \((\text {resp. } n+1)\) existential trace quantifiers in addition to the quantifiers in \(\psi _\iota \) and \(\psi \). For \(\triangleleft \in \{=\}\), the HyperLTL formula has \(k+n+1\) universal trace quantifiers and n existential trace quantifiers in addition to the quantifiers in \(\psi _\iota \) and \(\psi \).
Proof
For \(\triangleleft \in \{\le \}\), we encode the quantitative hyperproperty \(\forall \pi _1,\dots ,\pi _k.\ \psi _\iota \rightarrow (\# \sigma : A.\ \psi \triangleleft n)\) as the following HyperLTL formula:

where \(\psi [\sigma \mapsto \pi '_i]\) is the HyperLTL formula \(\psi \) with all occurrences of \(\sigma \) replaced by \(\pi '_i\). The formula states that there is no tuple of \(n+1\) traces \(\pi '_1, \ldots , \pi '_{n+1}\) different in the evaluation of A, that satisfy \(\psi \). In other words, for every \(n+1\) tuple of traces \(\pi '_1, \ldots , \pi '_{n+1}\) that differ in the evaluation of A, one of the paths must violate \(\psi \). For \(\triangleleft \in \{ <\}\), we use the same formula, with \(\forall \pi '_1, \ldots , \pi '_{n}\) instead of \(\forall \pi '_1, \ldots , \pi '_{n+1}\).
For \(\triangleleft \in \{\ge \}\), we encode the quantitative hyperproperty analogously as the HyperLTL formula

The formula states that there exist paths \(\pi '_1, \ldots , \pi '_{n}\) that differ in the evaluation of A and that all satisfy \(\psi \). For \(\triangleleft \in \{ >\}\), we use the same formula, with \(\exists \pi '_1, \ldots , \pi '_{n+1}\) instead of \(\forall \pi '_1, \ldots , \pi '_{n}\). Lastly, for \(\triangleleft \in \{ = \}\), we encode the quantitative hyperproperty as a conjunction of the encodings for \(\le \) and for \(\ge \).
Example 3
(Quantitative non-interference in HyperLTL). As discussed in Example 1, quantitative non-interference is the quantitative hyperproperty

where we measure the amount of leakage with min-entropy [43]. The bounding problem for min-entropy asks whether the amount of information leaked by a system is bounded by a constant \(2^c\) where c is the number of bits. This is encoded in HyperLTL as the requirement that there are no \(2^{c}+1\) traces distinguishable in their output:

This formula is equivalent to the formalization of quantitative non-interference given in [26].
Model checking quantitative hyperproperties via the reduction to HyperLTL is very expensive. In the best case, when \(\triangleleft \in \{\le , < \}\), \(\psi _\iota \) does not contain existential quantifiers, and \(\psi \) does not contain universal quantifiers, we obtain an HyperLTL formula without quantifier alternations, where the number of quantifiers grows linearly with the bound n. For m quantifiers, the HyperLTL model checking algorithm [26] constructs and analyzes the m-fold self-composition of the Kripke structure. The running time of the model checking algorithm is thus exponential in the bound. If \(\triangleleft \in \{\ge , >, = \}\), the encoding additionally introduces a quantifier alternation. The model checking algorithm checks quantifier alternations via a complementation of Büchi automata, which adds another exponent, resulting in an overall doubly exponential running time.
The model checking algorithm we introduce in the next section avoids the n-fold self-composition needed in the model checking algorithm of HyperLTL and its complexity is independent of the bound n.
4.2 Counting-Based Model Checking Algorithm
A Kripke structure \(K= (S,s_0, \tau , \textit{AP}, L)\) violates a quantitative hyperproperty
if there is a k-tuple \(t=(\pi _1,\dots ,\pi _k)\) of traces \(\pi _i \in \textit{TR}(K)\) that satisfies the formula
where \(\overline{\triangleleft }\) is the negation of the comparison operator \(\triangleleft \). The tuple t then satisfies the property \(\psi _\iota \) and the number of \((k+1)\)-tuples \(t'=(\pi _1,\dots , \pi _k, \sigma )\) for \(\sigma \in \textit{TR}(K)\) that satisfy \(\psi \) and differ pairwise in the A-projection of \(\sigma \) satisfies the comparison \(\overline{\triangleleft }~n\) (The A-projection of a sequence \(\sigma \) is defined as the sequence \(\sigma _A \in (2^A)^\omega \), such that for every position i and every \(a \in A\) it holds that \(a \in \sigma _A[i]\) if and only if \(a \in \sigma [i]\)). The tuples \(t'\) can be captured by the automaton composed of the product of an automaton \(A_{\psi _\iota \wedge \psi }\) that accepts all \(k+1\) of traces that satisfy both \(\psi _\iota \) and \(\psi \) and a \(k+1\)-self composition of K. Each accepting run of the product automaton presents \(k+1\) traces of K that satisfy \(\psi _\iota \wedge \psi \). On top of the product automaton, we apply a special counting algorithm which we explain in detail in Sect. 4.4 and check if the result satisfies the comparison \(\overline{\triangleleft }~n\).
Algorithm 1 gives a general picture of our model checking algorithm. The algorithm has two parts. The first part applies if the relation \(\overline{\triangleleft }\) is one of \(\{\ge , >\}\). In this case, the algorithm checks whether a sequence over \(\textit{AP}_\psi \) (propositions in \(\psi \)) corresponds to infinitely many sequences over A. This is done by checking whether the product automaton B has a so-called doubly pumped lasso(DPL), a subgraph with two connected lassos, with a unique sequence over \(\textit{AP}_\psi \) and different sequences over A. Such a doubly pumped lasso matches the same sequence over \(\textit{AP}_\psi \) with infinitely many sequences over A (more in Sect. 4.4). If no doubly pumped lasso is found, a projected model counting algorithm is applied in the second part of the algorithm in order to compute either the maximum or the minimum value, corresponding to the comparison operator \(\overline{\triangleleft }\). In the next subsections, we explain the individual parts of the algorithm in detail.

4.3 Büchi Automata for Quantitative Hyperproperties
For a quantitative hyperproperty \(\varphi = \forall \pi _1 \dots \pi _k.~ \psi _\iota \rightarrow (\#\sigma : A. \psi \triangleleft n )\) and a Kripke structure \(K=(S,s_0, \tau , \textit{AP}, L)\), we first construct an alternating automaton \(A_{\psi _{\iota } \wedge \psi }\) for the HyperLTL property \(\psi _{\iota } \wedge \psi \). Let \(A_{\psi _1} = (Q_1,q_{0,1}, \varSigma _2, \delta _1, F_1)\) and \(A_{\psi _2} = (Q_2,q_{0,2}, \varSigma _2, \delta _2, F_2)\) be alternating automata for subformulas \(\psi _1\) and \(\psi _2\). Let \(\varSigma = 2^{\textit{AP}_\varphi }\) where \(AP_\varphi \) are all indexed atomic propositions that appear in \(\varphi \). \(A_{\psi _{\iota } \wedge \psi }\) is constructed using following rulesFootnote 2:

For a quantified formula \(\varphi = \exists \pi . \psi _1\), we construct the product automaton of the Kripke structure K and the Büchi automaton of \(\psi _1\). Here we reduce the alphabet of the automaton by projecting all atomic proposition in \(\textit{AP}_\pi \) away:

Given the Büchi automaton for the hyperproperty \(\psi _\iota \wedge \psi \) it remains to construct the product with the \(k+1\)-self composition of K. The transitions of the automaton are defined over labels from \(\varSigma = 2^{\textit{AP}^*}\) where \(AP^* ={\textit{AP}_\sigma \cup \bigcup _i \textit{AP}_{\pi _i}}\). \(A_{\psi _{\iota } \wedge \psi }\). This is necessary to identify which transition was taken in each copy of K, thus, mirroring a tuple of traces in K. For each of the variables \(\pi _1,\dots \pi _k\) and \(\sigma \) we use following rule:

Finally, we transform the resulting alternating automaton to an equivalent Büchi automaton following the construction of Miyano and Hayashi [39].
4.4 Counting Models of \(\omega \)-Automata
Computing the number of words accepted by a Büchi automaton can be done by examining its accepting lassos. Consider, for example, the Büchi automata over the alphabet \(2^{\{a\}}\) in Fig. 1. The automaton on the left has one accepting lasso \((q_0)^\omega \) and thus has only one model, namely \(\{a\}^\omega \). The automaton on the right has infinitely many accepting lassos \((q_0\{\})^i\{a\}(q_1(\{\} \vee \{a\}))^\omega \) that accept infinitely many different words all of the from \(\{\}^*\{a\}(\{\}\vee \{a\})^\omega \). Computing the models of a Büchi automaton is insufficient for model checking quantitative hyperproperties as we are not interested in the total number of models. We rather maximize, respectively minimize, over sequences of subsets of atomic propositions the number of projected models of the Büchi automaton. For instance, consider the automaton given in Fig. 2. The automaton has infinitely many models. However, the maximum number of sequences \(\sigma _b \in 2^{\{b\}}\) that correspond to accepting lassos in the automaton with a unique sequence \(\sigma _a \in 2^{\{a\}}\) is two: For example, let n be a natural number. For any model of the automaton and for each sequence \(\sigma _a := \{\}^n\{a\}(\{\})^\omega \) the automaton accepts the following two sequences: \(\{b\}^n\{\}\{b\}^\omega \) and \(\{b\}^\omega \). Formally, given a Büchi automaton \(\mathcal {B}\) over \( AP \) and a set A, such that \(A \subseteq AP \), an A-projected model (or projected model over A) is defined as a sequence \(\sigma _A \in (2^ A )^\omega \) that results in the A-projection of an accepting sequence \(\sigma \in (2^ AP )^\omega \).

Büchi automata with one model (left) and infinitely many models (right).

A two-state Büchi automaton, such that there exist exactly two \(\{b\}\)-projected models for each \(\{a\}\)-projected sequence.
In the following, we define the maximum model counting problem over automata and give an algorithm for solving the problem. We show how to use the algorithm for model checking quantitative hyperproperties.
Definition 1
(Maximum Model Counting over Automata (MMCA)). Given a Büchi automaton B over an alphabet \(2^\textit{AP}\) for some set of atomic propositions \(\textit{AP}\) and sets \(X,Y,Z \subseteq \textit{AP}\) the maximum model counting problem is to compute
where \(\sigma \cup \sigma '\) is the point-wise union of \(\sigma \) and \(\sigma '\).
As a first step in our algorithm, we show how to check whether the maximum model count is equal to infinity.
Definition 2
(Doubly Pumped Lasso). For a graph G, a doubly pumped lasso in G is a subgraph that entails a cycles \(C_1\) and another different cycle \(C_2\) that is reachable from \(C_1\).

Forms of doubly pumped lassos.
In general, we distinguish between two types of doubly pumped lassos as shown in Fig. 3. We call the lassos with periods \(C_1\) and \(C_2\) the lassos of the doubly pumped lasso. A doubly pumped lasso of a Büchi automaton B is one in the graph structure of B. The doubly pumped lasso is called accepting when \(C_2\) has an accepting state. A more generalized formalization of this idea is given in the following theorem.
Theorem 2
Let \(B=(Q,q_0,\delta , 2^\textit{AP}, F)\) be a Büchi automaton for some set of atomic propositions \(\textit{AP}= X \cup Y \cup Z\) and let \(\sigma ' \in ( 2^{Y})^\omega \). The automaton B has infinitely many \(X \cup Y\)-projected models \(\sigma \) with \(\sigma =_{Y} \sigma '\) if and only if B has an accepting doubly pumped lasso with lassos \(\rho \) and \(\rho '\) such that: (1) \(\rho \) is an accepting lasso (2) \(\textit{tr}(\rho )=_{Y} \textit{tr}(\rho ')=_{Y}\sigma '\) (3) The period of \(\rho '\) shares at least one state with \(\rho \) and (4) \(\textit{tr}(\rho )\not =_X\textit{tr}(\rho ')\).
To check whether there is a sequence \(\sigma ' \in (2^Y)^\omega \) such that the number of \(X\cup Y\)-projected models \(\sigma \) of B with \(\sigma =_Y \sigma '\) is infinite, we search for a doubly pumped lasso satisfying the constraints given in Theorem 2. This can be done by applying the following procedure:
Given a Büchi automaton \(B=(Q,q_0,2^\textit{AP},\delta ,F)\) and sets \(X,Y,Z \subseteq ~\textit{AP}\), we construct the following product automaton \(B_\times =(Q_\times ,q_{\times ,0},2^\textit{AP}\times 2^\textit{AP}, \delta _\times , F_\times )\) where: \(Q_\times = Q \times Q\), \(q_{\times ,0} = (q_0,q_0)\), \(\delta _\times = \{(s_1,s_2) \xrightarrow {(\alpha ,\alpha ')} (s'_1,s_2') \mid s_1 \xrightarrow {\alpha } s_2, s'_1 \xrightarrow {\alpha '} s'_2, \alpha =_{Y} \alpha '\}\) and \(F_\times = Q\times F\). The automaton B has infinitely many models \(\sigma '\) if there is an accepting lasso \(\rho = (q_0,q_0)(\alpha _1,\alpha '_1) \dots ((q_j,q_j')(\alpha _{j+1},\alpha '_{j+1})\) \(\dots (q_k,q'_k) (\alpha _{k+1},\alpha '_{k+1}))\) in \(B_\times \) such that: \(\exists h\le j.~ q'_h = q_j\), i.e., B has lassos \(\rho _1\) and \(\rho _2\) that share a state in the period of \(\rho _1\) and \(\exists h>j.~ \alpha _h \not =_X \alpha '_h\), i.e., the lassos differ in the evaluation of X in a position after the shared state and thus allows infinitely many different sequence over X for the a sequence over Y. The lasso \(\rho \) simulates a doubly pumped lasso in B satisfying the constraints of Theorem 2.
Theorem 3
Given an alternating Büchi automaton \(A=(Q,q_0,\delta , 2^\textit{AP}, F)\) for a set of atomic propositions \(\textit{AP}= X\cup Y\cup Z\), the problem of checking whether there is a sequence \(\sigma ' \in ( 2^{Y})^\omega \) such that A has infinitely many \(X\cup Y\)-projected models \(\sigma \) with \(\sigma =_Y \sigma '\) is Pspace-complete.
The lower and upper bound for the problem can be given by a reduction from and to the satisfiability problem of LTL [4]. Due to the finite structure of Büchi automata, if the number of models of the automaton exceed the exponential bound \(2^{|Q|}\), where Q is the set of states, then the automaton has infinitely many models.
Lemma 1
For any Büchi automaton B, the number of models of B is less or equal to \(2^{|Q|}\) otherwise it is \(\infty \).
Proof
Assume the number of models is larger than \(2^{|Q|}\) then there are more than \(2^{|Q|}\) accepting lassos in B. By the pigeonhole principle, two of them share the same \(2^{|Q|}\)-prefix. Thus, either they are equal or we found doubly pumped lasso in B.
Corollary 1
Let a Büchi automaton B over a set of atomic propositions \(\textit{AP}\) and sets \(X,Y \subseteq \textit{AP}\). For each sequence \(\sigma _Y \in (2^{Y})^\omega \) the number of \(X\cup Y\)-projected models \(\sigma \) with \(\sigma =_Y \sigma _Y \) is less or equal than \(2^{|Q|}\) otherwise it is \(\infty \).
From Corollary 1, we know that if no sequence \(\sigma _Y \in (2^Y)^\omega \) matches to infinitely many \(X \cup Y\)-projected models then the number of such models is bound by \(2^{|Q|}\). Each of these models has a run in B which ends in an accepting strongly connected component. Also from Corollary 1, we know that every model has a lasso run of length |Q|. For each finite sequence \(w_Y\) of length \(|w_Y|= |Q|\) that reaches an accepting strongly connected component, we count the number \(X \cup Y\)-projected words w of length |Q| with \(w =_Y w_Y\) and that end in an accepting strongly connected component. This number is equal to the maximum model counting number.

Maximum Model Counting Algorithm (left) and a Sketch of a step in this algorithm (right): Current elements of our working set are \(q_1,q_2 \in W\) and \(q_3 \in W'\). If \(i=0\), i.e., we are in the first step of the algorithm, then \(q_1\) and \(q_2\) are states of accepting SCCs.
Algorithm 2 describes the procedure. An algorithm for the minimum model counting problem is defined in similar way. The algorithm works in a backwards fashion starting with states of accepting strongly connected components. In each iteration i, the algorithm maps each state of the automaton with \(X \cup Y\)-projected words of length i that reach an accepting strongly connected component. After |Q| iterations, the algorithm determines from the mapping of initial state \(q_0\) a Y-projected word of length |Q| with the maximum number of matching \(X\cup Y\)-projected words (Fig. 4).
Theorem 4
The decisional version of the maximum model counting problem over automata (MMCA), i.e. the question whether the maximum is greater than a given natural number n, is in \( NP ^{\#P}\).
Proof
Let a Büchi automaton over an alphabet \(2^ AP \) for a set of atomic propositions \( AP \) and sets \(\textit{AP}_X,\textit{AP}_Y,\textit{AP}_Z \subseteq \textit{AP}\) and a natural number n be given. We construct a nondeterministic Turing Machine M with access to a \(\#P\)-oracle as follows: M guesses a sequence \(\sigma _Y \in 2^ AP_Y \). It then queries the oracle, to compute a number c, such that \(c = |\{\sigma _X \in (2^{\textit{AP}_X})^\omega \mid \exists \sigma _Z \in (2^{\textit{AP}_Z})^\omega .~ \sigma _X\cup \sigma _Y\cup \sigma _Z \in L(B)\}|\), which is a \(\#P\) problem [27]. It remains to check whether \(n>c\). If so, M accepts.
The following theorem summarizes the main findings of this section, which establish, depending on the property, an exponentially or even doubly exponentially better algorithm (in the quantitative bound) over the existing model checking algorithm for HyperLTL.
Theorem 5
Given a Kripke structure K and a quantitative hyperproperty \(\varphi \) with bound n, the problem whether \(K \models \varphi \) can be decided in logarithmic space in the quantitative bound n and in polynomial space in the size of K.
5 A Max#Sat-Based Approach
For existential HyperLTL formulas \(\psi _\iota \) and \(\psi \), we give a more practical model checking approach by encoding the automaton-based construction presented in Sect. 4 into a propositional formula.
Given a Kripke structure \(K=(S,s_0, \tau , \textit{AP}_K, L)\) and a quantitative hyperproperty \(\varphi =\forall \pi _1, \dots , \pi _k.~ \psi _\iota \rightarrow (\#\sigma :A.~ \psi ) \triangleleft n \) over a set of atomic propositions \(\textit{AP}_\varphi \subseteq \textit{AP}_K\) and bound \(\mu \), our algorithm constructs a propositional formula \(\phi \) such that, every satisfying assignment of \(\phi \) uniquely encodes a tuple of lassos \((\pi _1, \dots , \pi _k,\sigma )\) of length \(\mu \) in K, where \((\pi _1, \dots , \pi _k)\) satisfies \(\psi _\iota \) and \((\pi _1, \dots , \pi _k,\sigma )\) satisfies \(\psi \). To compute the values \(\max \limits _{(\pi _1,\dots ,\pi _k)}|\{\sigma _A \mid (\pi _1,\dots ,\pi _k,\sigma ) \models \psi _\iota \wedge \psi \}|\) (in case \(\triangleleft \in \{\le , <\}\)) or \(\min \limits _{(\pi _1,\dots ,\pi _k)}|\{\sigma _A \mid (\pi _1,\dots ,\pi _k,\sigma ) \models \psi _\iota \wedge \psi \}|\) (in case \(\triangleleft \in \{\ge , >\}\)), we pass \(\phi \) to a maximum model counter, respectively, to a minimum model counter with the appropriate sets of counting and maximization, respectively, minimization propositions. From Lemma 1 we know that it is enough to consider lasso of length exponential in the size of \(\varphi \). The size of \(\phi \) is thus exponential in the size of \(\varphi \) and polynomial in the size of K.
The construction resembles the encoding of the bounded model checking approach for LTL [16]. Let \(\psi _\iota = \exists \pi '_1 \dots \pi '_{k'}.~\psi '_{\iota }\) and \(\psi =\exists \pi ''_1 \dots \pi ''_{k''}.~\psi ''\) and let \(\textit{AP}_{\psi _\iota }\) and \(\textit{AP}_{\psi }\) be the sets of atomic propositions that appear in \(\psi _\iota \) and \(\psi \) respectively. The propositional formula \(\phi \) is given as a conjunction of the following propositional formulas: \(\phi = \bigwedge _{i\le k} \llbracket K \rrbracket _{\pi _i}^\mu \wedge \llbracket K \rrbracket _\sigma ^\mu \wedge \llbracket \psi _\iota \rrbracket _{\mu }^0 \wedge \llbracket \psi \rrbracket _{\mu }^0\) where:
-
\(\mu \) is length of considered lassos and is equal to \(\mu = 2^{|\psi '_\iota \wedge \psi ''|}*|S|^{k+k'+k''+1}+1\) which is one plus the size of the product automaton constructed from the \(k+k'+k''+1\) self-composition and the automaton for \(\psi _\iota \wedge \psi \). The “plus one” is to additionally check whether the number of models is infinite.
-
\(\llbracket K \rrbracket _\pi ^k\) is the encoding of the transition relation of the copy of K where atomic propositions are indexed with \(\pi \) and up to an unrolling of length k. Each state of K can be encoded as an evaluation of a vector of \(\log {|S|}\) unique propositional variables. The encoding is given by the propositional formula
 which encodes all paths of K of length k. The formula
which encodes all paths of K of length k. The formula  defines the assignment of the initial state. The formulas
defines the assignment of the initial state. The formulas  define valid transitions in K from the ith to the \((i+1)\)st state of a path.
define valid transitions in K from the ith to the \((i+1)\)st state of a path. -
\( \llbracket \psi _\iota \rrbracket _{k}^0\) and \(\llbracket \psi \rrbracket _{k}^0\) are constructed using the following rulesFootnote 3:
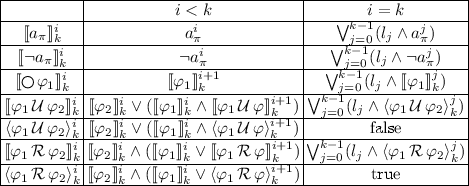
in case of an existential quantifier over a trace variable \(\pi \), we add a copy of the encoding of K with new variables distinguished by \(\pi \):

 which encodes all paths of K of length k. The formula
which encodes all paths of K of length k. The formula  defines the assignment of the initial state. The formulas
defines the assignment of the initial state. The formulas  define valid transitions in K from the ith to the
define valid transitions in K from the ith to the 

We define sets \(X= \{a^i_\sigma \mid a \in A , i \le k\}\), \(Y= \{a^i \mid a \in \textit{AP}_\psi \setminus A, i\le k\}\) and \(Z = P\setminus X \cup Y\), where P is the set of all propositions in \(\phi \). The maximum model counting problem is then \(\textit{MMC}(\phi , X,Y,Z)\).
5.1 Experiments
We have implemented the Max#Sat-based model checking approach from the last section. We compare the Max#Sat-based approach to the expansion-based approach using HyperLTL [26]. Our implementation uses the MaxCount tool [29]. We use the option in MaxCount that enumerates, rather than approximates, the number of assignments for the counting variables. We furthermore instrumented the tool so that it terminates as soon as a sample is found that exceeds the given bound. If no sample is found after one hour, we report a timeout.
Table 1 shows the results on a parameterized benchmark obtained from the implementation of an 8bit passcode checker. The parameter of the benchmark is the bound on the number of bits that is leaked to an adversary, who might, for example, enter passcodes in a brute-force manner. In all instances, a violation is found. The results show that the Max#Sat-based approach scales significantly better than the expansion-based approach.
6 Conclusion
We have studied quantitative hyperproperties of the form \(\forall \pi _1,\dots ,\pi _k.\ \varphi \rightarrow (\# \sigma : A.\ \psi \triangleleft n)\), where \(\varphi \) and \(\psi \) are HyperLTL formulas, and \(\#\sigma :A. \varphi \triangleleft n\) compares the number of traces that differ in the atomic propositions A and satisfy \(\psi \) to a threshold n. Many quantitative information flow policies of practical interest, such as quantitative non-interference and deniability, belong to this class of properties. Our new counting-based model checking algorithm for quantitative hyperproperties performs at least exponentially better in both time and space in the bound n than a reduction to standard HyperLTL model checking. The new counting operator makes the specifications exponentially more concise in the bound, and our model checking algorithm solves the concise specifications efficiently.
We also showed that the model checking problem for quantitative hyperproperties can be solved with a practical Max#SAT-based algorithm. The SAT-based approach outperforms the expansion-based approach significantly for this class of properties. An additional advantage of the new approach is that it can handle properties like deniability, which cannot be checked by MCHyper because of the quantifier alternation.
Notes
- 1.
We write \(\pi =_A \pi '\) short for \(\pi _A = \pi '_A\) where \(\pi _A\) is the A-projection of \(\pi \).
- 2.
The construction follows the one presented in [26] with a slight modification on the labeling of transitions. Labeling over atomic proposition instead of the states of the Kripke structure suffices, as any nondeterminism in the Kripke structure is inherently resolved, because we quantify over trace not paths.
- 3.
We omitted the rules for boolean operators for the lack of space.
References
Alvim, M.S., Andrés, M.E., Palamidessi, C.: Quantitative information flow in interactive systems. J. Comput. Secur. 20(1), 3–50 (2012)
Aziz, R.A., Chu, G., Muise, C.J., Stuckey, P.J.: #\(\exists \)sat: projected model counting. In: Proceedings of the 18th International Conference on Theory and Applications of Satisfiability Testing - SAT 2015, Austin, TX, USA, 24–27 September 2015, pp. 121–137 (2015)
Backes, M., Köpf, B., Rybalchenko, A.: Automatic discovery and quantification of information leaks. In: 30th IEEE Symposium on Security and Privacy (S&P 2009), Oakland, California, USA, 17–20 May 2009, pp. 141–153 (2009)
Baier, C., Katoen, J.-P.: Principles of Model Checking (Representation and Mind Series). The MIT Press, Cambridge (2008)
Banerjee, A., Naumann, D.A.: Stack-based access control and secure information flow. J. Funct. Program. 15(2), 131–177 (2005)
Barthe, G., D’Argenio, P.R., Rezk, T.: Secure information flow by self-composition. Math. Struct. Comput. Sci. 21(6), 1207–1252 (2011)
Bindschaedler, V., Shokri, R., Gunter, C.A.: Plausible deniability for privacy-preserving data synthesis. PVLDB 10(5), 481–492 (2017)
Biondi, F., Legay, A., Traonouez, L.-M., Wąsowski, A.: QUAIL: a quantitative security analyzer for imperative code. In: Sharygina, N., Veith, H. (eds.) CAV 2013. LNCS, vol. 8044, pp. 702–707. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-39799-8_49
Chadha, R., Mathur, U., Schwoon, S.: Computing information flow using symbolic model-checking. In: 34th International Conference on Foundation of Software Technology and Theoretical Computer Science, FSTTCS 2014, New Delhi, India, 15–17 December 2014, pp. 505–516 (2014)
Chakraborti, A., Chen, C., Sion, R.: Datalair: efficient block storage with plausible deniability against multi-snapshot adversaries. PoPETs 2017(3), 179 (2017)
Chen, H., Malacaria, P.: Quantitative analysis of leakage for multi-threaded programs. In: Proceedings of the 2007 Workshop on Programming Languages and Analysis for Security, PLAS 2007, San Diego, California, USA, 14 June 2007, pp. 31–40 (2007)
Chothia, T., Kawamoto, Y., Novakovic, C.: LeakWatch: estimating information leakage from Java programs. In: Kutyłowski, M., Vaidya, J. (eds.) ESORICS 2014. LNCS, vol. 8713, pp. 219–236. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-11212-1_13
Clark, D., Hunt, S., Malacaria, P.: Quantified interference for a while language. Electr. Notes Theor. Comput. Sci. 112, 149–166 (2005)
Clark, D., Hunt, S., Malacaria, P.: Quantitative information flow, relations and polymorphic types. J. Log. Comput. 15(2), 181–199 (2005)
Clark, D., Hunt, S., Malacaria, P.: A static analysis for quantifying information flow in a simple imperative language. J. Comput. Secur. 15(3), 321–371 (2007)
Clarke, E., Biere, A., Raimi, R., Zhu, Y.: Bounded model checking using satisfiability solving. Form. Methods Syst. Des. 19(1), 7–34 (2001)
Clarke, E.M., Emerson, E.A.: Design and synthesis of synchronization skeletons using branching time temporal logic. In: Kozen, D. (ed.) Logic of Programs 1981. LNCS, vol. 131, pp. 52–71. Springer, Heidelberg (1982). https://doi.org/10.1007/BFb0025774
Clarkson, M.R., Finkbeiner, B., Koleini, M., Micinski, K.K., Rabe, M.N., Sánchez, C.: Temporal logics for hyperproperties. In: Abadi, M., Kremer, S. (eds.) POST 2014. LNCS, vol. 8414, pp. 265–284. Springer, Heidelberg (2014). https://doi.org/10.1007/978-3-642-54792-8_15
Clarkson, M.R., Myers, A.C., Schneider, F.B.: Belief in information flow. In: 18th IEEE Computer Security Foundations Workshop, (CSFW-18 2005), Aix-en-Provence, France, 20–22 June 2005, pp. 31–45 (2005)
Clarkson, M.R., Myers, A.C., Schneider, F.B.: Quantifying information flow with beliefs. J. Comput. Secur. 17(5), 655–701 (2009)
Clarkson, M.R., Schneider, F.B.: Hyperproperties. J. Comput. Secur. 18(6), 1157–1210 (2010)
Cohen, E.S.: Information transmission in sequential programs. In: Foundations of Secure Computation, pp. 297–335 (1978)
Darwiche, A.: New advances in compiling CNF into decomposable negation normal form. In: Proceedings of the 16th European Conference on Artificial Intelligence, ECAI 2004, including Prestigious Applicants of Intelligent Systems, PAIS 2004, Valencia, Spain, 22–27 August 2004, pp. 328–332 (2004)
Denning, D.E.: Cryptography and Data Security. Addison-Wesley, Boston (1982)
Dimitrova, R., Finkbeiner, B., Kovács, M., Rabe, M.N., Seidl, H.: Model checking information flow in reactive systems. In: Kuncak, V., Rybalchenko, A. (eds.) VMCAI 2012. LNCS, vol. 7148, pp. 169–185. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-27940-9_12
Finkbeiner, B., Rabe, M.N., Sánchez, C.: Algorithms for model checking HyperLTL and HyperCTL\(^*\). In: Kroening, D., Păsăreanu, C.S. (eds.) CAV 2015. LNCS, vol. 9206, pp. 30–48. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-21690-4_3
Finkbeiner, B., Torfah, H.: Counting models of linear-time temporal logic. In: Dediu, A.-H., Martín-Vide, C., Sierra-Rodríguez, J.-L., Truthe, B. (eds.) LATA 2014. LNCS, vol. 8370, pp. 360–371. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-04921-2_29
Finkbeiner, B., Torfah, H.: The density of linear-time properties. In: D’Souza, D., Narayan Kumar, K. (eds.) ATVA 2017. LNCS, vol. 10482, pp. 139–155. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-68167-2_10
Fremont, D.J., Rabe, M.N., Seshia, S.A.: Maximum model counting. In: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, California, USA, 4–9 February 2017, pp. 3885–3892 (2017)
Gray III, J.W.: Toward a mathematical foundation for information flow security. In: Proceedings of the IEEE Symposium on Security and Privacy, pp. 210–234, May 1991
Hammer, C., Snelting, G.: Flow-sensitive, context-sensitive, and object-sensitive information flow control based on program dependence graphs. Int. J. Inf. Secur. 8(6), 399–422 (2009)
Gray III, J.W.: Toward a mathematical foundation for information flow security. In: IEEE Symposium on Security and Privacy, pp. 21–35 (1991)
Bayardo Jr., R.J., Schrag, R.: Using CSP look-back techniques to solve real-world SAT instances. In: Proceedings of the Fourteenth National Conference on Artificial Intelligence and Ninth Innovative Applications of Artificial Intelligence Conference, AAAI 1997, Providence, Rhode Island, 27–31 July 1997, pp. 203–208 (1997)
Köpf, B., Basin, D.A.: An information-theoretic model for adaptive side-channel attacks. In: Proceedings of the 2007 ACM Conference on Computer and Communications Security, CCS 2007, Alexandria, Virginia, USA, 28–31 October 2007, pp. 286–296 (2007)
Köpf, B., Rybalchenko, A.: Approximation and randomization for quantitative information-flow analysis. In: Proceedings of the 23rd IEEE Computer Security Foundations Symposium, CSF 2010, Edinburgh, United Kingdom, 17–19 July 2010, pp. 3–14 (2010)
Littman, M.L., Majercik, S.M., Pitassi, T.: Stochastic boolean satisfiability. J. Autom. Reason. 27(3), 251–296 (2001)
Malacaria, P.: Assessing security threats of looping constructs. In: Proceedings of the 34th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 2007, Nice, France, 17–19 January 2007, pp. 225–235 (2007)
Milushev, D., Clarke, D.: Incremental hyperproperty model checking via games. In: Riis Nielson, H., Gollmann, D. (eds.) NordSec 2013. LNCS, vol. 8208, pp. 247–262. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-41488-6_17
Miyano, S., Hayashi, T.: Alternating finite automata on \(\omega \)-words. Theoret. Comput. Sci. 32(3), 321–330 (1984)
Morwood, D., Bryce, D.: Evaluating temporal plans in incomplete domains. In: Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, 22–26 July 2012, Toronto, Ontario, Canada (2012)
Muise, C.J., McIlraith, S.A., Beck, J.C., Hsu, E.I.: Dsharp: fast d-DNNF compilation with sharpSAT. In: Kosseim, L., Inkpen, D. (eds.) AI 2012. LNCS (LNAI), vol. 7310, pp. 356–361. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-30353-1_36
Myers, A.C.: JFlow: practical mostly-static information flow control. In: Proceedings of the 26th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 1999, San Antonio, TX, USA, 20–22 January 1999, pp. 228–241 (1999)
Smith, G.: On the foundations of quantitative information flow. In: de Alfaro, L. (ed.) FoSSaCS 2009. LNCS, vol. 5504, pp. 288–302. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-00596-1_21
Torfah, H., Zimmermann, M.: The complexity of counting models of linear-time temporal logic. Acta Informatica 55(3), 191–212 (2016)
Yasuoka, H., Terauchi, T.: On bounding problems of quantitative information flow. In: Gritzalis, D., Preneel, B., Theoharidou, M. (eds.) ESORICS 2010. LNCS, vol. 6345, pp. 357–372. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-15497-3_22
Yasuoka, H., Terauchi, T.: Quantitative information flow as safety and liveness hyperproperties. Theor. Comput. Sci. 538, 167–182 (2014)
Zdancewic, S., Myers, A.C.: Observational determinism for concurrent program security. In: Proceedings of CSF, p. 29. IEEE Computer Society (2003)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
<SimplePara><Emphasis Type="Bold">Open Access</Emphasis>This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License(http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.</SimplePara><SimplePara>The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.</SimplePara>
Copyright information
© 2018 The Author(s)
About this paper

Cite this paper
Finkbeiner, B., Hahn, C., Torfah, H. (2018). Model Checking Quantitative Hyperproperties. In: Chockler, H., Weissenbacher, G. (eds) Computer Aided Verification. CAV 2018. Lecture Notes in Computer Science(), vol 10981. Springer, Cham. https://doi.org/10.1007/978-3-319-96145-3_8
Download citation
DOI: https://doi.org/10.1007/978-3-319-96145-3_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-96144-6
Online ISBN: 978-3-319-96145-3
eBook Packages: Computer ScienceComputer Science (R0)