
Abstract
Process discovery methods automatically infer process models from event logs. Often, event logs contain so-called noise, e.g., infrequent outliers or recording errors, which obscure the main behavior of the process. Existing methods filter this noise based on the frequency of event labels: infrequent paths and activities are excluded. However, infrequent behavior may reveal important insights into the process. Thus, not all infrequent behavior should be considered as noise. This paper proposes the Data-aware Heuristic Miner (DHM), a process discovery method that uses the data attributes to distinguish infrequent paths from random noise by using classification techniques. Data- and control-flow of the process are discovered together. We show that the DHM is, to some degree, robust against random noise and reveals data-driven decisions, which are filtered by other discovery methods. The DHM has been successfully tested on several real-life event logs, two of which we present in this paper.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
Process models are used by organizations to document, specify, and analyze their processes [1]. A process model describes the expected behavior of a process in terms of its activities (i.e., units of work) and their ordering. Most contemporary processes are supported by information systems. Often, those systems record information about the execution of processes in databases. With the abundance of such data, there is a growing interest in process discovery [2], i.e., revealing the actual execution of processes from events. Process discovery methods automatically infer process models from event logs.
One important challenge for process discovery methods is to handle event logs with noise [2, 3]. In practice, event logs often contain noise, e.g., out-of-order events, exceptional behavior, or recording errors [4]. Including all such infrequent events in the process discovery often leads to unusable, complex models. Therefore, noise filtering methods that distinguish noise from the regular behavior of the process may be useful.
Some of the early techniques for process discovery assumed noise-free event logs (e.g., the Alpha algorithm [5] and the region based approaches [6]). These techniques are of limited use in real-life settings. Most of the more recent and more sophisticated process discovery methods support noise filtering [3]. Existing noise-filtering methods are based on frequencies [7,8,9,10], machine-learning techniques [11, 12], genetic algorithms [13], or probabilistic models [14, 15]. All of those methods focus on the control-flow perspective (i.e., the event labels) when filtering noise. Dedicated noise filtering methods [16, 17] are also based on frequencies.
However, processes are often governed by rules. Decision are taken on the basis of available data, available resources, and the process context. Some paths may be executed infrequently because the corresponding conditions are rarely fulfilled. Existing methods based solely on the control-flow perspective would disregard such infrequent behavior as noise. However, some infrequent behavior may be characterized by very deterministic rules, and, thus, be of great interest to process analysts (e.g., in the context of risks and fraud). For example, shortcuts in a process might only be taken by a specific resource, undesired behavior might be subject to conditions, and infrequently actions might be legitimate only for special types of cases. These kind of events should not be set aside as noise. Methods exist to discover such decision rules [18,19,20] but all rely on a previously discovered process model of the process. Hence, existing methods do not leverage the full potential of the data perspective. Data- and control-flow need to be discovered together. Recent work on declarative process discovery [21] considers the data perspective. However, similar to association rule mining, sets of rules rather than full process models are returned.
In this work, we propose the Data-aware Heuristic Miner (DHM), which takes the data perspective into account when discovering the control flow of a process. The DHM uses classification techniques to reveal data dependencies between activities, and uses these data dependencies to distinguish noise from infrequent conditional behavior. It returns process models that yield a better insight into the data perspective of processes by revealing hidden data dependencies while filtering random noise. The evaluation on real-life cases shows that the DHM reveals additional insights not returned by state-of-the-art process discovery methods. We confirmed the discovered conditions with a domain expert for one of the real-life event logs. The experiment on the synthetic data shows that the DHM is resilient to a certain degree of randomly injected noise, which is not characterized by data conditions. It rediscovers the original model, whereas earlier techniques either show too much, or too little behavior. The contribution of this paper is a process discovery method that is able to distill important information from infrequent behavior instead of dismissing it as noise.
The remainder of this paper is structured as follows. We start by introducing the problem with an example in Sect. 2. Then, required preliminaries are introduced in Sect. 3. Section 4 presents our novel process discovery method. We evaluate our method using both synthetic and real-life data in Sect. 5. Finally, Sect. 6 concludes the paper.
2 Problem Description
Figure 1 shows a simplified process from the health care domain. We use this example in the paper to motivate the relevance of the data perspective for noise filtering. When patients arrive at the hospital they are assigned a triage priority, registered and assigned to a responsible nurse. Only in exceptional cases, patients are assigned the white triage priority. Those patients typically, leave the emergency ward directly after registration since their injuries do not require the attendance of a doctor  . All other patients are admitted to the emergency ward. While patients are in the emergency ward a nurse periodically checks their condition. In parallel to this, for the group of patients under consideration, an X-ray is taken and a doctor visits the patient. There are two different work practices regarding these two activities. Normally, the doctor visits the patients after which the X-Ray is taken. One particular nurse (Alice) re-sequences these activities in the reversed order to improve the process: first the X-ray is taken and, only thereafter, the doctor visits the patient
. All other patients are admitted to the emergency ward. While patients are in the emergency ward a nurse periodically checks their condition. In parallel to this, for the group of patients under consideration, an X-ray is taken and a doctor visits the patient. There are two different work practices regarding these two activities. Normally, the doctor visits the patients after which the X-Ray is taken. One particular nurse (Alice) re-sequences these activities in the reversed order to improve the process: first the X-ray is taken and, only thereafter, the doctor visits the patient  . As this work practice is only followed by one nurse, it is observed less frequently. Afterwards, the doctor visits the patient one more time and decides on the type of dismissal. Then, the patient is prepared for a possible transfer. For patients with the out dismissal type an ambulance needs to be organized
. As this work practice is only followed by one nurse, it is observed less frequently. Afterwards, the doctor visits the patient one more time and decides on the type of dismissal. Then, the patient is prepared for a possible transfer. For patients with the out dismissal type an ambulance needs to be organized  . This process contains three examples of infrequent, data-dependent behavior:
. This process contains three examples of infrequent, data-dependent behavior:  a data-dependent path,
a data-dependent path,  data-dependent re-sequencing, and
data-dependent re-sequencing, and  a data-dependent activity. The goal of our work is to rediscover such behavior, while ignoring random noise.
a data-dependent activity. The goal of our work is to rediscover such behavior, while ignoring random noise.

A simplified process in BPMN notation from the emergency ward of a hospital, which is used as motivating example throughout this paper.

Models discovered by IM and HM on an event log generated from the example process.
Assume an event log of the process in Fig. 1 obtained from the information systems of the hospital. As motivated in the introduction, it is likely that this event log contains noise. We applied both the Heuristic Miner (HM) [8] and the Inductive Miner (IM) [9] as representatives of discovery methods supporting noise filtering on such an event log with a controlled degree of noiseFootnote 1. Figure 2 shows the resulting process models in BPMN notation. Clearly, both methods are unaware of the data perspective. Therefore, they fail to distinguish between random noise and the infrequent data-dependent behavior  ,
,  , and
, and  . It might be possible to tweak the parameters of the algorithms such that more behavior is revealed (e.g., through grid search). Still, finding the correct parameter setting that does not include unrelated noise requires deep knowledge about the underlying process. Therefore, this is often not feasible. Moreover, it is not possible to reveal the infrequent data-dependent behavior by using decision mining techniques. Those techniques can only reveal decision rules for paths that are reflected in the process model, thus low-frequent but deterministic behavior remains undetected.
. It might be possible to tweak the parameters of the algorithms such that more behavior is revealed (e.g., through grid search). Still, finding the correct parameter setting that does not include unrelated noise requires deep knowledge about the underlying process. Therefore, this is often not feasible. Moreover, it is not possible to reveal the infrequent data-dependent behavior by using decision mining techniques. Those techniques can only reveal decision rules for paths that are reflected in the process model, thus low-frequent but deterministic behavior remains undetected.
In the remainder of this paper, we describe the DHM, which extends the ideas of the HM with the use of classification techniques to reveal data dependencies. Our method, indeed, rediscovers the behavior of the process as shown in Fig. 1.
3 Preliminaries
An event log stores information about activities that were recorded by information systems supporting the execution of a process [2]. Each execution of a process instance results in a sequence of events. Each events corresponds to the execution of one activity. Given universes of attributes A and values U, an event log \(L = (E,\varSigma ,\#,\mathscr {L})\) consists of:
-
E a finite set of unique event identifiers;
-
\(\varSigma \subseteq U\) a finite set of activities;
-
\(\#: E \rightarrow (A \not \rightarrow U)\) obtains the attribute values recorded for an event;
-
\(\mathscr {L}\subseteq E^*\) the set of traces over E. A trace \(\sigma \in \mathscr {L}\) records the sequence of events for one process instance. Each event occurs only in a single trace.
Given an event \(e \in E\), we write \(\#_a(e) \in U\) to obtain the value \(u \in U\) recorded for attribute \(a \in A\). We require events to record at least the activity attribute: \(\#_{act}(e) \in \varSigma \) is the name of the activity that caused the event. Given a trace \(\langle e_1, \ldots , e_n \rangle \in \mathscr {L}\), we define \( val : E \rightarrow (A \not \rightarrow U)\) to collect the latest attribute values recorded before an event occurred, i.e., \( val (e_i) = val (e_{i-1}) \oplus \#(e_{i-1})\) with special case \( val (e_1) = f_{\varnothing }\).Footnote 2 We denote the predecessor event in the trace by \({}^\bullet (e_i) = e_{i-1}\) with special case \({}^\bullet (e_1) = \bot \). Finally, in the remainder of this paper, we assume that a particular event log \(L = (E,\varSigma ,\#,\mathscr {L})\) exists to avoid unnecessary notation.
Example 1
Table 1 shows three traces \(\sigma _1,\sigma _2,\sigma _3 \in \mathscr {L}\) based on the process shown in Fig. 1. Each event has a unique identifier. We can identify the activity of event \(e_{11}\) as \(\#_{act}(e_{11})=Triage\). Moreover, event \(e_{11}\) writes the attribute value \(\#_{ Priority }(e_{11})=\text {Red}\). We obtain the latest attribute values recorded before \(e_{18}\) occurred as \( val (e_{18})= f\), with \(f( Priority ) = \text {Red}\) and \(f( Nurse ) = \text {Joe}\).
Our method uses Causal nets (C-nets) to represent the discovered process model [8, 22]. A C-net is a tuple \((\varSigma ,s_i,s_o,D,I,O)\) where:
-
\(\varSigma \) is a finite set of activities;
-
\(s_i \in \varSigma \) is the unique start activity;
-
\(s_o \in \varSigma \) is the unique end activity;
-
\(D \subseteq \varSigma \times \varSigma \) is the dependency relation;
-
\(B = \{ X \subseteq \mathscr {P}(\varSigma ) \mid X = \{ \varnothing \} \vee \varnothing \notin X\}\) are possible bindings;Footnote 3
-
\(I \in \varSigma \rightarrow B\) is the set of input bindings per activity;
-
\(O \in \varSigma \rightarrow B\) is the set of output bindings per activity,
such that the dependency relations match the input and output bindings, i.e., \(D = \{(s_1,s_2) \in \varSigma \times \varSigma \mid s_1 \in \bigcup _{\beta \in I(s_2)}\beta \wedge s_2 \in \bigcup _{\beta \in O(s_1)}\beta \}\). We require C-nets to have a unique start and end activity, i.e., \(\{s_i\} = \{ s \in \varSigma \mid I(s) = \{\varnothing \}\}\) \(\{s_o\} = \{ s \in \varSigma \mid O(s) = \{\varnothing \}\}\). The input and output binding functions of a C-net define its language. We describe the C-net semantics by example, the full semantics are described in [22].

A causal net (C-net) of the example process. Activities are depicted with boxes, the dependency relations as edges, and the binding functions as black dots on the edges. The unique start and end activities are shown as black boxes. The dotted edges are explained in Sect. 5.
Example 2
Figure 3 shows how the example from Fig. 1 can be modeled as C-net. Activities are depicted with boxes and dependency relations as edges. There are unique start and end activities: \(s_i\) and \(s_o\). Output and input bindings are depicted by black dots on the edges in Fig. 3. Bindings indicate which combinations of activities can precede or follow a given activity. Connected dots show activities belonging to the same binding. We abbreviate activity names by using the first letter. For example, after activity \(s_i\), activities T and R follow in a sequence, i.e., \(O(s_i)=\{\{T\}\}\), \(I(T)=\{\{s_i\}\}\) and \(O(T)=\{\{R\}\}\), \(I(R)=\{\{T\}\}\). Then, there are multiple alternative choices. Three output bindings are defined for R: \(O(R) = \{ \{ s_o \}, \{C,X\}, \{C,V\} \}\). Each set of activities represents a possible choice of following activities (XOR gateway). Either only \(s_o\), or both C and X, or both C and V need to happen. Activities in the same set can be executed in parallel (AND gateway).
4 Data-Driven Process Discovery
The DHM builds on the insight that infrequent but data-dependent process behavior is of great interest to process analysts and, thus, should not be disregarded as noise. We extend the ideas of the HM [8] with a measure for conditional dependency.
4.1 Data-Aware Dependency Measure
To discover data-dependent behavior in the event log, we make use of classification techniques (e.g., decision trees). More specifically, we rely on binary classifiers predicting directly-follows relations based on attribute values recorded in the event log. We denote these classifiers as dependency conditions.
Definition 1
(Dependency conditions). Given universes of attributes A, values U, and activities \(\varSigma \subseteq U\), we define the dependency conditions \(C \in (\varSigma \times \varSigma ) \rightarrow ((A \not \rightarrow U) \rightarrow \{0,1\})\). A dependency condition \(C_{a,b}(x)=(C(a,b))(x)\) is a binary classifier that predicts whether an event of activity a is directly followed by an event of activity b for the attribute values \(x \in (A \not \rightarrow U)\), i.e., \(C_{a,b}(x) = 1\) when \(\mathbf {b}\) is predicted to directly follow \(\mathbf {a}\) and \(C_{a,b}(x) = 0\) when a different activity is predicted.
In the remainder of the paper, we denote with \(\mathbf {1}\) a special dependency condition function that returns classifiers predicting 1 regardless of the attribute values, i.e., \(\forall a,b \in \varSigma , \forall x \in (A \not \rightarrow U): \mathbf {1}_{a,b}(x)=1\). Given a dependency condition, we establish the frequency with which activities are observed to directly follow other activities in the event log when the condition holds. We denote this as: conditional directly follows.
Definition 2
(Conditional directly follows relation). Given activities \(a,b \in \varSigma \) and dependency conditions C, we write \(a >^{C,L}b\) if and only if an execution of activity a with the latest attribute values x is directly followed by an execution of activity b under dependency condition \(C_{a,b}(x)\). We denote the frequency of a conditional directly follows relation \(a >^{C,L}b\) in the event log as:
Now, we define a data-aware variant of the dependency measure proposed by the HM.
Definition 3
(Conditional dependency measure). Given activities \(a,b \in \varSigma \) and dependency conditions C. We define \(a \Rightarrow ^{C,L}b: \varSigma \times \varSigma \rightarrow [-1,1]\) as the strength of the causal dependency from a to b under condition \(C_{a,b}\) in the event log:
The intuition behind the data-aware variant of these measures is that a relation (a, b) should be included in the dependency relations of the discovered causal net when it is clearly characterized by a certain dependency condition \(C_{a,b}\).
Example 3
Consider an event log L with 50 traces like \(\sigma _1\), 50 traces like \(\sigma _2\) and 50 traces like \(\sigma _3\) as shown in Table 1. We determine the conditional dependency measure \(X \Rightarrow ^{C,L}V\) from activity X-Ray (X) to activity Visit (V). We assume that condition \(C_{X,V}(v)\) returns 1 only if attribute \( Nurse \) values takes on the value Alice. Then, we obtain the number of times X is directly followed by V under condition \(C_{X,V}\) as \(\left| X >^{C,L}V\right| =50\), and the number of times V is directly followed by X under conditions C as \(\left| V >^{C,L}X\right| =0\). Therefore, the conditional dependency measure under conditions C is \(X \Rightarrow ^{C,L}V = \frac{50-0}{50+0+1} \approx 0.98\). This indicates a strong dependency relation from activity X to activity V under condition \(C_{X,V}\). By contrast, if we consider the unconditional dependency measure \(X \Rightarrow ^{\mathbf {1},L}V\), then we obtain \(\frac{50-100}{50+100+1} \approx -0.33\). Thus, when disregarding the data perspective, both activities appear to be executed in parallel.
4.2 Discovering Data Conditions
We described the conditional directly-follows relation and the conditional dependency measure. We use the latter measure to determine which relations should be included in the C-net. Both concepts rely on discovered dependency conditions. Here, we describe how to train a classifier that can be used as dependency condition. We build a set of training instances for every combination of activities \((a,b) \in \varSigma \times \varSigma \).
In the remainder, \(\mathbb {B}(X)\) denotes the set of all multi-sets over a set X. We use \(X=[a^2,b]\) as a short-hand notation to denote the multi-set \(X= [ a,a,b ]\), and \(\biguplus \) to denote the sum of two multi-sets, i.e., \(X \biguplus [b,c] = [a^2,b^2,c]\).
Definition 4
(Training Instances). Given a source activity \(a \in \varSigma \), a candidate activity \(b \in \varSigma \), and a dependency threshold \(\theta _{ dep }\in [0,1]\). Let \(a^\bullet \subseteq \varSigma \) be the set of activities s that directly follow a in the event log with an unconditional dependency measure above the threshold \(\theta _{ dep }\), i.e., \(a^\bullet = \{ s \in \varSigma \mid a \Rightarrow ^{\mathbf {1},L}s \ge \theta _{ dep }\}\). We collect those events \(X_{L,a,b} \subseteq E\) that directly follow an execution of \(\mathbf {a}\) in the event log, and refer to activities in \(\mathbf {a}^\bullet \), or to the candidate activity \(\mathbf {b}\), i.e., \(X_{L,a,b} = \{ e \in E \mid {}^\bullet (e) = a \wedge \#_{act}(e) \in a^\bullet \cup \{ b \} \}\). Function \(T_{L,\theta _{ dep }} \in (\varSigma \times \varSigma ) \rightarrow \mathbb {B}((A \not \rightarrow U) \times \{ 1, 0 \})\) returns the multi-set of training instances:
Conceptually, our method is independent of the used classification algorithm. Concretely, we employ decision trees (C4.5) [23] as an efficient method that result in human interpretable conditions. We build the dependency conditions C by assembling a set of training instances \(T_{L,\theta _{ dep }}(a,b)\) and training a decision tree for each possible relation \((a,b) \in \varSigma \times \varSigma \). Only good dependency conditions with discriminative power are used later on. We use a score \(q(C_{a,b}) \in [0,1]\) to determine the quality of a particular condition \(C_{a,b}\). There are many possible performance measures for binary classification algorithm that can be used together with our method. None of the measures is universally accepted, the correct choice depends on the concrete application area.
We opted for Cohen’s kappa (\(\kappa \)) [24], which indicates whether the prediction was better than a prediction by chance (i.e., for \(\kappa >0\)). Kappa favors a good prediction performance on the minority class, which is a desirable property in our setting. Moreover, it has been recommended for nonparametric binary classifiers, such as C4.5, on data with imbalanced class priors [25]. However, we do not claim \(\kappa \) to be the best measure and, thus, foresee other measures to be plugged-in depending on the application area.
Example 4
Consider the dependency threshold \(\theta _{ dep }=0.9\) and an event log containing 150 traces, where 50 traces record the same values as \(\sigma _1\), 50 traces the same values as \(\sigma _2\) and 50 traces the same values as \(\sigma _3\). We train a classifier for the dependency condition \(C_{X,V}\), i.e., the dependency relation from X-Ray (X) to Visit (V) using the training instances \(T_{L,\theta _{ dep }}(X,V)\). The training instances are \(T_{L,\theta _{ dep }}(X,V) = [ (v_1, \text {Final Visit})^{50}, (v_2, \text {Visit})^{50} ]\) with attribute value functions \(v_1(P)=\text {Red}\), \(v_1(N)=\text {Joe}\) and \(v_2(P)=\text {Red}\), \(v_2(N)=\text {Alice}\). Please note that there is no instance with the activity Check (C) since the unconditional dependency measure \(X \Rightarrow ^{\mathbf {1},L}C\) is below the threshold of 0.9. Therefore, the instances based on trace \(\sigma _3\) are not included as we already know that activity C is in parallel to X. We train a C4.5 decision tree and obtain the dependency condition \(C_{X,V}\) with \(C_{X,V}(v_2) = 1\) and \(C_{X,V}(v_1) = 0\).
4.3 Data-Driven Discovery of Causal Nets
We describe the DHM method that builds C-nets based on conditional dependencies. The DHM supports four user-specified thresholds that can be used to tune the noise filtering capabilities to specific needs of the user. All thresholds range between 0 and 1:
-
\(\theta _{ obs }\), the observation threshold, which controls the relative frequency of relations;
-
\(\theta _{ dep }\), the dependency threshold, which controls the strength of causal dependencies;
-
\(\theta _{ bin }\), the binding threshold, which controls the number of bindings;
-
\(\theta _{ con }\), the condition threshold, which controls the quality of data-dependencies.
We discover a C-net \((\varSigma ,s_i,s_o,D,I,O)\) from event log \(L = (E,\varSigma ,\#,\mathscr {L})\) and thresholds \(\theta _{ obs },\theta _{ dep },\theta _{ bin },\theta _{ con }\) in the following steps.
-
1.
We want to ensure that the resulting C-net has a unique start and end activity.
Therefore, we add artificial start and end events to all traces, i.e., \(\forall _{\sigma \in \mathscr {L}} (\sigma = (e_i, e_1, \ldots , e_n, e_o) \wedge \#_{act}(e_i) = s_i \wedge \#_{act}(e_o) = s_o)\) and \(\varSigma = \varSigma \cup \{s_i,s_o\}\).
-
2.
We build the set of standard dependency relations as follows:
$$\begin{aligned} D = \{ (a,b) \in \varSigma \times \varSigma \mid a \Rightarrow ^{\mathbf {1},L}b \ge \theta _{ dep }\wedge \frac{\left| a >^{\mathbf {1},L}b\right| }{\left| \mathscr {L}\right| } \ge \theta _{ obs }\}. \end{aligned}$$ -
3.
We discover the dependency conditions C by training classifiers for each pair \((a,b) \in \varSigma \times \varSigma \) using the training instances \(T_{L,\theta _{ dep }}(a,b)\).
-
4.
We add the conditional dependency relations to D. We use \(\theta _{ con }\) instead of \(\theta _{ obs }\) to obtain infrequent, high-quality data conditions:
$$\begin{aligned} D = D \cup \{ (a,b) \in \varSigma \times \varSigma \mid q(C_{a,b}) \ge \theta _{ con }\wedge a \Rightarrow ^{C,L}b \ge \theta _{ dep }\}. \end{aligned}$$ -
5.
Some activities \(s \in \varSigma \) might not have a predecessor or successor in the directed graph induced by D. Intuitively, each task in a process should have a cause (predecessor) and an effect (successor) [8], all tasks in the C-net should be connected. Therefore, we propose two alternative heuristics to enforce this:
-
all-task-connected heuristic proposed by the HM [8], or
-
the accepted-task-connected heuristic, a new heuristic.
Here, we describe the new accepted-task-connected heuristic. We repeatedly connect only those activities that are already part of the dependency graph using their best neighboring activities until all activities have a cause and an effect. Then, set \(\overline{D}\) of relations necessary to connect all activities accepted so far is:
$$\begin{aligned} \overline{D} = \{ (a,b) \in \varSigma \times \varSigma \mid&(\not \exists x \; (a,x) \in D \wedge \forall y \; (a \Rightarrow ^{\mathbf {1},L}b) \ge (a \Rightarrow ^{\mathbf {1},L}y)) \\ \vee&(\not \exists x \; (x,b) \in D \wedge \forall y \; (a \Rightarrow ^{\mathbf {1},L}b) \ge (y \Rightarrow ^{\mathbf {1},L}b) \}. \end{aligned}$$We extend the dependency relations with the new relations, i.e., \(D = D \cup \overline{D}\). There might be new, unconnected activities in D. Therefore, we repeat adding the best neighboring activities until set \(\overline{D}\) is empty.
-
-
6.
We discover the input and output binding functions of the C-net. For the output binding function O(a) of an activity \(a \in \varSigma \), we need to determine which executions of \(b \in \varSigma \) (with \((a,b) \in D\)) were caused by an execution of activity \(\mathbf {a}\). We use the heuristic proposed by the HM [8] and repeat it for completeness. The heuristic considers activity \(\mathbf {b}\) to be caused by activity \(\mathbf {a}\) only if it is the nearest activity that may have caused \(\mathbf {b}\). Any other activity \(\mathbf {s}\) executed in between \(\mathbf {a}\) and \(\mathbf {b}\) should not be a possible cause of \(\mathbf {b}\), i.e., \((s,b) \notin D\). Given a trace \(\sigma = \langle e_1, \ldots , e_i, \ldots , e_n \rangle \in \mathscr {L}\), the set of activities \(\overline{O}(e_i) \subseteq \varSigma \) that were caused by an event \(e_i\) is:
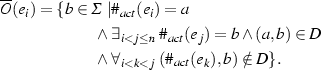
We determine the frequency \(\left| o\right| _{L,a} \in \mathbb {N}\) of an output binding \(o \subseteq \varSigma \) for activity \(a \in \varSigma \) in the event log L as:
$$ \left| o\right| _{L,a} = \left| \{ e \in E \mid \#_{act}(e) = a \wedge \overline{O}(e) = o \} \right| . $$Then, we build the complete multi-set of output bindings with the most frequent bindings. Those bindings that fulfill the user-specified binding threshold \(\theta _{ bin }\):
$$\begin{aligned} O(a) = \{ o \subseteq \varSigma \mid \frac{\left| o\right| _{L,a}}{max_{\overline{o} \subseteq \varSigma }(\left| \overline{o}\right| _{L,a})} \ge \theta _{ bin }\}. \end{aligned}$$The input binding function I is obtained by reversing the same approach.
Within the scope of this paper, we do not elaborate on the other heuristics of the HM [8], such as long-distance, length-two loops, and the relative-to-best. Those heuristics and improvements to the HM described by the Fodina miner [26] can be used together with the DHM. The choice which heuristics to apply highly depends on the process at hand. For example, the all-task-connected heuristic results in a process model with all observed activities regardless of the chosen observation frequency threshold \(\theta _{ obs }\). Even activities that are only observed once are added. This might not be desirable as very infrequent activities might be considered as noise. Therefore, we introduced the new accepted-task-connected heuristic.
5 Evaluation
We implemented the DHM in the open-source framework ProMFootnote 4. The package Data-AwareCNetMiner provides a highly interactive tool, which allows to quickly discover C-nets for different parameter settings and to explore the discovered data dependencies. C-nets can be converted to Petri nets or BPMN models. Therefore, existing tools can be used on the results. We applied our method to both synthetic and real-life event logs.
5.1 Synthetic - Handling Noise
Event Log and Methods. We generated an event log with 100,000 traces and approximately 900,000 events by simulating the process model shown in Fig. 3. There are three data attributes: Priority (P), Nurse (N), and Type (T). We adjust the frequency distributions of these attributes such that paths A, B, and C in model Fig. 3 are recorded infrequently. Specifically, only 1.4% of the traces record \(P= white \), 19.1% of the traces record \(N= Alice \), and 4.3% of the traces record \(T= out \). We compared three methods: our proposed method (DHM), the heuristic miner with frequency filtering (HMF), and the heuristic miner without frequency filtering (HMA). All three methods, used thresholds \(\theta _{ obs }=0.06 \; (0.0 \text { for HMA}), \; \theta _{ dep }=0.9,\;\theta _{ bin }=0.1,\;\theta _{ con }=0.5\) together with the accepted-task-connected heuristic. We used C4.5 as classifier and estimated its performance using 10 times 10-fold cross validation.
Experimental Design. The experiment should evaluate the noise filtering capabilities of our method. Therefore, we injected noise into the event log by randomly adding one additional event to an increasing number of traces.Footnote 5 Then, we compared the discovered dependency relations with those of the reference model (Fig. 3) in terms of graph edit distance (GED) [27]. We did not use fitness, precision, or behavioral comparison measures as those would not be applicable in this setting. Fitness and precision do not measure the performance wrt. the reference model (gold standard). Moreover, when the discovered models are not sound (e.g., having a deadlock), the behavior may be undefined even when the model is close to the original. Behavioral measures would also fail to distinguish the difference between the data-dependent re-sequencing of activities (pattern  in Fig. 3) and simple parallelism. For example, both in Fig. 3 and in Fig. 2(b) activities Visit and X-Ray are behaviorally in parallel.
in Fig. 3) and simple parallelism. For example, both in Fig. 3 and in Fig. 2(b) activities Visit and X-Ray are behaviorally in parallel.

Graph edit distances between the dependency relations discovered by the compared methods and the reference dependency relations for varying amounts of injected noise.
Results. All models could be discovered in about 3 s using 2 GB of memory. Our method was able to rediscover the conditional relations  ,
,  and
and  , i.e., the red edges in Fig. 3. The original rules \(P= white \) and \(T= out \) were discovered for relations
, i.e., the red edges in Fig. 3. The original rules \(P= white \) and \(T= out \) were discovered for relations  and
and  . For path
. For path  , two rules were discovered: \(N= Alice \) for the edge from X-Ray to Visit and \(N\ne Alice \) for the edge from Visit to X-Ray. Our method discovered the data-dependent re-sequencing of activities Visit to X-Ray, whereas the standard HM (cf. BPMN model in Fig. 2(b)) considered both activities as parallel. Figure 4 shows the result of the GED measurement for noise levels ranging from 0% to 40%. Our method (DHM) handles the added noise well until 25% of the traces were modified. The HM with frequency-based noise filtering (method HMF) is also unaffected by the injected noise. However, it fails to discover the reference model even without noise, as shown in Fig. 2(b). The GED of the method HMF improves after injecting noise in 20% of the traces because the frequency of relation
, two rules were discovered: \(N= Alice \) for the edge from X-Ray to Visit and \(N\ne Alice \) for the edge from Visit to X-Ray. Our method discovered the data-dependent re-sequencing of activities Visit to X-Ray, whereas the standard HM (cf. BPMN model in Fig. 2(b)) considered both activities as parallel. Figure 4 shows the result of the GED measurement for noise levels ranging from 0% to 40%. Our method (DHM) handles the added noise well until 25% of the traces were modified. The HM with frequency-based noise filtering (method HMF) is also unaffected by the injected noise. However, it fails to discover the reference model even without noise, as shown in Fig. 2(b). The GED of the method HMF improves after injecting noise in 20% of the traces because the frequency of relation  increases by chance. When lowering the observation frequency threshold (method HMA), the injected noise quickly affects the discovery and undesirable dependencies appear. We did not include the IM in Fig. 4, as it returns models with a different structure. However, the models returned by the IM are already undesirable for an event log with 5% noise, c.f., Fig. 2(a).
increases by chance. When lowering the observation frequency threshold (method HMA), the injected noise quickly affects the discovery and undesirable dependencies appear. We did not include the IM in Fig. 4, as it returns models with a different structure. However, the models returned by the IM are already undesirable for an event log with 5% noise, c.f., Fig. 2(a).
5.2 Real-Life - Revealing Data Dependencies
We used two real-life event logs to show that our method can reveal infrequent behavior in a practical setting. Using the DHM important conditional dependencies can be found where existing methods abstract away such dependencies.
Data and Methods. The Road Fines (RF) event log was recorded by an information system that handles road-traffic fines by an Italian local police force [28, 29]. This event log contains about 150,000 cases, 500,000 events, and 9 data attributes. The Hospital Billing (HB) event log was obtained from the ERP system of a hospital. It contains 100,000 cases with 550,000 events and 38 data attributes related to the billing of medical services. We applied the proposed method (DHM), the HM with the same frequency filter settings (HMF) and the Inductive Miner (IM) to both event logs. Without a reference model and knowledge about expected noise levels, we could not compare the discovered models to a gold standard. Therefore, we compare the novel insights obtained by using our method with those from the other methods.
Road Fines. Figure 5 shows the C-net discovered by the DHM in about 4 s for the RF log. We used the all-task-connected heuristic of the original HM, since we know that each activity is of interest. We used eight of the attributes including a derived isPaid attribute since this process is about the payment of fines. We used C4.5 with 10-fold cross validation and only accepted classifications with \(\theta _{ con }\ge 0.5\). Most of the observed behavior (97.8%) can be replayed on the C-net using the alignment method presented in [22]. Our method reveals three additional relations (red edges), which are numbered in Fig. 5. Table 2 lists the conditional data-dependency measure, the frequency, as well as quality and used attributes of the obtained dependency condition for each relation. The first two relations target activity Add Penalty and both have a very good quality score. The decision rule for relation  mainly depends on the value of the dismissal attribute. Cases with values G do not receive a penalty, whereas cases with value NIL receive a penalty depending on the fine amount, the number of points, and the article. According to [29] this is to be expected as those cases are dismissed by the judge. Relation
mainly depends on the value of the dismissal attribute. Cases with values G do not receive a penalty, whereas cases with value NIL receive a penalty depending on the fine amount, the number of points, and the article. According to [29] this is to be expected as those cases are dismissed by the judge. Relation  is mainly based on the attribute isPaid. Unpaid fines that have with a small amount of less than 35 EUR receive a penalty. Relation
is mainly based on the attribute isPaid. Unpaid fines that have with a small amount of less than 35 EUR receive a penalty. Relation  was discovered for cases with a dismissal value of # or G. It is to be expected that the process finishes for cases with this code, since those cases are dismissed by the prefecture. Interestingly, this relation also occurs for cases with a dismissal value of NIL and high postal expenses. This should not happen, since those fines still need to be paid [29]. The DHM revealed three data dependencies that give more insights into the recorded behavior without obstructing the process model with infrequent noise. In the model obtained by IM none of the three relations are directly visible. Therefore, current decision mining techniques would not be able to discover the conditions.
was discovered for cases with a dismissal value of # or G. It is to be expected that the process finishes for cases with this code, since those cases are dismissed by the prefecture. Interestingly, this relation also occurs for cases with a dismissal value of NIL and high postal expenses. This should not happen, since those fines still need to be paid [29]. The DHM revealed three data dependencies that give more insights into the recorded behavior without obstructing the process model with infrequent noise. In the model obtained by IM none of the three relations are directly visible. Therefore, current decision mining techniques would not be able to discover the conditions.

Process model discovered for the RF log. The numbered edges were added by our method.
Hospital Billing. Figure 6 shows the C-net discovered by the DHM in about 3 s for the HB event log. The discovered model fits 97% of the observed behavior. We used the new accepted-task-connected heuristic since not all of the 21 activities may be of interest. We discovered the model using C4.5 on a subset of 13 attributes. Here, the quality threshold is set to  and the quality is, again, determined by 10-fold cross validation. Compared to the model returned by the HMF, our method revealed six additional dependencies. Again, we numbered these relations in Fig. 6, and list some key statistics in Table 3. For the purpose of this evaluation, we discussed the discovered conditional dependencies with a domain expert from the hospital who works in this process. Relation
and the quality is, again, determined by 10-fold cross validation. Compared to the model returned by the HMF, our method revealed six additional dependencies. Again, we numbered these relations in Fig. 6, and list some key statistics in Table 3. For the purpose of this evaluation, we discussed the discovered conditional dependencies with a domain expert from the hospital who works in this process. Relation  is based on a special closeCode that is used when nothing can be billed and, hence, the process ends. Relation
is based on a special closeCode that is used when nothing can be billed and, hence, the process ends. Relation  occurs mostly for two specific caseType values. According to the domain expert both case types correspond to exceptional cases: one is used for intensive care and the other for cases for which codes cannot be obtained (Code Nok). Relation
occurs mostly for two specific caseType values. According to the domain expert both case types correspond to exceptional cases: one is used for intensive care and the other for cases for which codes cannot be obtained (Code Nok). Relation  is, again, related to a specific caseType. This type is used for intensive-care activities as well and, often, does not require a code to be obtained. Relation
is, again, related to a specific caseType. This type is used for intensive-care activities as well and, often, does not require a code to be obtained. Relation  is also mainly related to the caseType and to some degree to the medical specialty. Both relation
is also mainly related to the caseType and to some degree to the medical specialty. Both relation  and relation
and relation  are conditional to the attribute closed, which indicates whether the invoice is closed or not. Clearly, deleted cases should not be in the closed status, whereas reopened cases with a change in diagnosis can be eventually closed in the future. The process model discovered by the DHM provides a balanced view on the interesting infrequent paths of the billing process together with the more frequent, regular behavior. Moreover, additional insight is provided by revealing the conditions with which infrequent paths occur. Again, the model returned by the IM did not include any of the six paths.
are conditional to the attribute closed, which indicates whether the invoice is closed or not. Clearly, deleted cases should not be in the closed status, whereas reopened cases with a change in diagnosis can be eventually closed in the future. The process model discovered by the DHM provides a balanced view on the interesting infrequent paths of the billing process together with the more frequent, regular behavior. Moreover, additional insight is provided by revealing the conditions with which infrequent paths occur. Again, the model returned by the IM did not include any of the six paths.

Process model discovered for the HB. The numbered edges are added by our method.
Limitations. We acknowledge that there are some limitations to our method. First, we only consider conditional directly-follows dependencies. Like most process mining approaches, our method requires sufficiently large event logs. Small event logs might, by chance, not contain all directly-follows relations. Moreover, more complex patterns of conditional infrequent behavior, e.g., longer sequences or sub-processes, cannot be discovered. Second, there is a risk that the returned C-nets are unsound [22] since our method is based on the HM. However, recent research shows that it is possible to structure the discovered model afterwards [30]. Third, as all data-driven method the DHM relies on data attributes and infrequent process paths being recorded. Last, we used only two real-life event logs in the evaluation. Therefore, only limited claims on the general applicability of the method can be made. We have also tested the DHM on other event logs. However, very few event logs with data attribute are publicly available.
6 Conclusion
We presented the Data-aware Heuristic Miner (DHM), a process discovery method that reveals conditional infrequent behavior from event logs. The DHM distinguishes undesired noise from infrequent behavior that can be characterized by conditions over the data attributes of the event log. This is the first approach that uses both event labels and data attributes when discovering the control-flow. Dependency conditions are discovered using classification techniques, and, then, embedded in a complete process discovery algorithm built upon the Heuristic Miner. The returned process models are annotated with information on the discovered rules. We applied the DHM to a synthetic and two real-life events logs of considerable size and complexity. We showed that the DHM can efficiently handle large event logs and is robust against typical levels of random noise. The evaluation on two real-life cases shows that the DHM provides insights that could be easily missed when relying on state-of-the-art, frequency-based techniques. In our future work, we would like to extend the idea from directly-follows relations to more complex patterns of conditional behavior (e.g., long-term dependencies). The DHM successfully reveals data dependencies based on directly-follows relations, but dependencies that cannot be captured by directly-follows relations might be missed.
Notes
- 1.
Here, in 5% of the cases one additional event was randomly executed out of the original order.
- 2.
\(f \oplus g\) denotes the overriding union of f and g, and \(f_{\varnothing }: \varnothing \rightarrow U\) is the empty function.
- 3.
\(\mathscr {P}(\varSigma )\) denotes the powerset of set \(\varSigma \).
- 4.
The package DataAwareCNetMiner can be downloaded from http://promtools.org.
- 5.
The synthetic event logs can be downloaded from http://dx.doi.org/10.4121/uuid:32cad43f-8bb9-46af-8333-48aae2bea037.
References
Davies, I., Green, P., Rosemann, M., Indulska, M., Gallo, S.: How do practitioners use conceptual modeling in practice? Data Knowl. Eng. 58(3), 358–380 (2006)
van der Aalst, W.M.P.: Process Mining - Data Science in Action, 2nd edn. Springer, Heidelberg (2016)
Weerdt, J.D., Backer, M.D., Vanthienen, J., Baesens, B.: A multi-dimensional quality assessment of state-of-the-art process discovery algorithms using real-life event logs. Inf. Syst. 37(7), 654–676 (2012)
Suriadi, S., Andrews, R., ter Hofstede, A., Wynn, M.: Event log imperfection patterns for process mining: towards a systematic approach to cleaning event logs. Inf. Syst. 64, 132–150 (2017)
van der Aalst, W.M.P., Weijters, T., Maruster, L.: Workflow mining: discovering process models from event logs. IEEE Trans. Knowl. Data Eng. 16(9), 1128–1142 (2004)
Carmona, J., Cortadella, J., Kishinevsky, M.: A region-based algorithm for discovering petri nets from event logs. In: Dumas, M., Reichert, M., Shan, M.-C. (eds.) BPM 2008. LNCS, vol. 5240, pp. 358–373. Springer, Heidelberg (2008). doi:10.1007/978-3-540-85758-7_26
Günther, C.W., van der Aalst, W.M.P.: Fuzzy mining – adaptive process simplification based on multi-perspective metrics. In: Alonso, G., Dadam, P., Rosemann, M. (eds.) BPM 2007. LNCS, vol. 4714, pp. 328–343. Springer, Heidelberg (2007). doi:10.1007/978-3-540-75183-0_24
Weijters, A., Ribeiro, J.: Flexible heuristics miner (FHM). In: CIDM, pp. 310–317. IEEE (2011)
Leemans, S.J.J., Fahland, D., van der Aalst, W.M.P.: Discovering block-structured process models from event logs containing infrequent behaviour. In: Lohmann, N., Song, M., Wohed, P. (eds.) BPM 2013. LNBIP, vol. 171, pp. 66–78. Springer, Cham (2014). doi:10.1007/978-3-319-06257-0_6
Liesaputra, V., Yongchareon, S., Chaisiri, S.: Efficient process model discovery using maximal pattern mining. In: Motahari-Nezhad, H.R., Recker, J., Weidlich, M. (eds.) BPM 2015. LNCS, vol. 9253, pp. 441–456. Springer, Cham (2015). doi:10.1007/978-3-319-23063-4_29
Goedertier, S., Martens, D., Vanthienen, J., Baesens, B.: Robust process discovery with artificial negative events. J. Mach. Learn. Res. 10, 1305–1340 (2009)
Ponce-de-León, H., Carmona, J., vanden Broucke, S.K.L.M.: Incorporating negative information in process discovery. In: Motahari-Nezhad, H.R., Recker, J., Weidlich, M. (eds.) BPM 2015. LNCS, vol. 9253, pp. 126–143. Springer, Cham (2015). doi:10.1007/978-3-319-23063-4_8
Buijs, J., van Dongen, B.F., van der Aalst, W.M.P.: A genetic algorithm for discovering process trees. In: IEEE Congress on Evolutionary Computation, pp. 1–8. IEEE (2012)
Rembert, A.J., Omokpo, A., Mazzoleni, P., Goodwin, R.T.: Process discovery using prior knowledge. In: Basu, S., Pautasso, C., Zhang, L., Fu, X. (eds.) ICSOC 2013. LNCS, vol. 8274, pp. 328–342. Springer, Heidelberg (2013). doi:10.1007/978-3-642-45005-1_23
Bellodi, E., Riguzzi, F., Lamma, E.: Statistical relational learning for workflow mining. Intell. Data Anal. 20(3), 515–541 (2016)
Ghionna, L., Greco, G., Guzzo, A., Pontieri, L.: Outlier detection techniques for process mining applications. In: An, A., Matwin, S., Raś, Z.W., Ślęzak, D. (eds.) ISMIS 2008. LNCS, vol. 4994, pp. 150–159. Springer, Heidelberg (2008). doi:10.1007/978-3-540-68123-6_17
Conforti, R., Rosa, M.L., ter Hofstede, A.H.M.: Filtering out infrequent behavior from business process event logs. IEEE Trans. Knowl. Data Eng. 29(2), 300–314 (2017)
Rozinat, A., Mans, R.S., Song, M., van der Aalst, W.M.P.: Discovering simulation models. Inf. Syst. 34(3), 305–327 (2009)
de Leoni, M., van der Aalst, W.M.P.: Data-aware process mining: discovering decisions in processes using alignments. In: SAC 2013, pp. 1454–1461. ACM (2013)
Bazhenova, E., Buelow, S., Weske, M.: Discovering decision models from event logs. In: Abramowicz, W., Alt, R., Franczyk, B. (eds.) BIS 2016. LNBIP, vol. 255, pp. 237–251. Springer, Cham (2016). doi:10.1007/978-3-319-39426-8_19
Schönig, S., Ciccio, C., Maggi, F.M., Mendling, J.: Discovery of multi-perspective declarative process models. In: Sheng, Q.Z., Stroulia, E., Tata, S., Bhiri, S. (eds.) ICSOC 2016. LNCS, vol. 9936, pp. 87–103. Springer, Cham (2016). doi:10.1007/978-3-319-46295-0_6
van der Aalst, W., Adriansyah, A., van Dongen, B.: Causal nets: a modeling language tailored towards process discovery. In: Katoen, J.-P., König, B. (eds.) CONCUR 2011. LNCS, vol. 6901, pp. 28–42. Springer, Heidelberg (2011). doi:10.1007/978-3-642-23217-6_3
Quinlan, J.R.: C4.5: Programs for Machine Learning. Morgan Kaufmann, Burlington (1993)
Cohen, J.: A coefficient of agreement for nominal scales. Educ. Psychol. Measur. 20(1), 37–46 (1960)
Ben-David, A.: About the relationship between ROC curves and Cohen’s kappa. Eng. Appl. Artif. Intell. 21(6), 874–882 (2008)
vanden Broucke, S.: Advances in process mining: artificial negative events and othertechniques. Ph.D. thesis, KU Leuven (2014)
Dijkman, R., Dumas, M., García-Bañuelos, L.: Graph matching algorithms for business process model similarity search. In: Dayal, U., Eder, J., Koehler, J., Reijers, H.A. (eds.) BPM 2009. LNCS, vol. 5701, pp. 48–63. Springer, Heidelberg (2009). doi:10.1007/978-3-642-03848-8_5
de Leoni, M., Mannhardt, F.: Road traffic fine management process (2015). doi:10.4121/uuid:270fd440-1057-4fb9-89a9-b699b47990f5
Mannhardt, F., de Leoni, M., Reijers, H.A., van der Aalst, W.M.P.: Balanced multi-perspective checking of process conformance. Computing 98(4), 407–437 (2016)
Augusto, A., Conforti, R., Dumas, M., Rosa, M., Bruno, G.: Automated discovery of structured process models: discover structured vs. discover and structure. In: Comyn-Wattiau, I., Tanaka, K., Song, I.-Y., Yamamoto, S., Saeki, M. (eds.) ER 2016. LNCS, vol. 9974, pp. 313–329. Springer, Cham (2016). doi:10.1007/978-3-319-46397-1_25
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Mannhardt, F., de Leoni, M., Reijers, H.A., van der Aalst, W.M.P. (2017). Data-Driven Process Discovery - Revealing Conditional Infrequent Behavior from Event Logs. In: Dubois, E., Pohl, K. (eds) Advanced Information Systems Engineering. CAiSE 2017. Lecture Notes in Computer Science(), vol 10253. Springer, Cham. https://doi.org/10.1007/978-3-319-59536-8_34
Download citation
DOI: https://doi.org/10.1007/978-3-319-59536-8_34
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-59535-1
Online ISBN: 978-3-319-59536-8
eBook Packages: Computer ScienceComputer Science (R0)