
Abstract
With the increased adoption of Hadoop-based big data systems for the analysis of large volume and variety of data, an effective and common benchmark for big data deployments is needed. There have been a number of proposals from industry and academia to address this challenge. While most either have basic workloads (e.g. word counting), or port existing benchmarks to big data systems (e.g. TPC-H or TPC-DS), some are specifically designed for big data challenges. The most comprehensive proposal among these is the BigBench benchmark, recently standardized by the Transaction Processing Performance Council as TPCx-BB. In this paper, we discuss the progress made since the original BigBench proposal to the standardized TPCx-BB. In addition, we will share the thought process went into creating the specification, challenges in navigating the uncharted territories of a complex benchmark for a fast moving technology domain, and analyze the functionality of the benchmark suite on different Hadoop- and non-Hadoop-based big data engines. We will provide insights on the first official result of TPCx-BB and finally discuss, in brief, other relevant and fast growing big data analytic use cases to be addressed in future big data benchmarks.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others



Notes
- 1.
Transaction Processing Performance Council – www.tpc.org.
- 2.
- 3.
- 4.
Examples are clustering, logistic regression, and sentiment analysis.
- 5.
Hewlett Packard Enterprise ProLiant DL for Big Data – http://www.tpc.org/3501.
References
McSherry, F., Isard, M., Murray, D.G.: Scalability! But at what COST? In: HotOS 2015 (2015)
Ghazal, A., Rabl, T., Hu, M., Raab, F., Poess, M., Crolotte, A., Jacobsen, H.-A.: BigBench: towards an industry standard benchmark for big data analytics. In: SIGMOD 2013 (2013)
Nambiar, R.O., Poess, M., Dey, A., Cao, P., Magdon-Ismail, T., Ren, D.Q.: Andrew bond: introducing TPCx-HS: the first industry standard for benchmarking big data systems. In: Nambiar, R., Poess, M. (eds.) TPCTC 2014. LNCS, vol. 8904, pp. 1–12. Springer, Cham (2014)
Poess, M., Nambiar, R.O., Walrath, D.: Why you should run TPC-DS: a workload analysis. In: VLDB 2007 (2007)
Baru, C., Bhandarkar, M., Nambiar, R., Poess, M., Rabl, T.: Setting the Direction for Big Data Benchmark Standards. In: Nambiar, R., Poess, M. (eds.) TPCTC 2012. LNCS, vol. 7755, pp. 197–208. Springer, Heidelberg (2013). doi:10.1007/978-3-642-36727-4_14
Ghat, D., Rorke, D., Kumar, D.: New SQL Benchmarks: Apache Impala (incubating) Uniquely Delivers Analytic Database Performance. https://blog.cloudera.com/blog/2016/02/new-sql-benchmarks-apache-impala-incubating-2-3-uniquely-delivers-analytic-database-performance/
Transaction Processing Performance Council. TPC Express Benchmark™ BB. http://www.tpc.org/tpcx-bb
Baru, C., Bhandarkar, M., Curino, C., Danisch, M., Frank, M., Gowda, B., Huang, J., Jacobsen, H.-A., Kumar, D., Nambiar, R., Poess, M., Raab, F., Rabl, T., Ravi, N., Sachs, K., Yi, L., Youn, C.: An analysis of the BigBench workload. In: TPCTC 2014 (2014)
Rabl, T., Frank, M., Sergieh, H.M., Kosch, H.: A data generator for cloud-scale benchmarking. In: Nambiar, R., Poess, M. (eds.) TPCTC 2010. LNCS, vol. 6417, pp. 41–56. Springer, Heidelberg (2011). doi:10.1007/978-3-642-18206-8_4
Alexandrov, A., Bergmann, R., Ewen, S., Freytag, J.-C., Hueske, F., Heise, A., Kao, O., Leich, M., Leser, U., Markl, V., Naumann, F., Peters, M., Rheinländer, A., Sax, M.J., Schelter, S., Höger, M., Tzoumas, K., Warneke, D.: The stratosphere platform for big data analytics. VLDB J. 23(6), 939–964 (2014)
Boehm, M., Burdick, D., Evfimievski, A.V., Reinwald, B., Sen, P., Tatikonda, S., Tian, Y.: Compiling machine learning algorithms with SystemML. In: SoCC 2013 (2013)
Chen, Y., Ganapathi, A., Griffith, R., Katz, R.: The case for evaluating MapReduce performance using workload suites. In: MASCOTS 2011 (2011)
Ousterhout, K., Rasti, R., Ratnasamy, S., Shenker, S., Chun, B.-G.: Making sense of performance in data analytics frameworks. In: NSDI 2015 (2015)
O’Leary, D.E.: ‘Big Data’, the ‘Internet of Things’ and the ‘Internet of Signs’. In: Intelligent Systems in Accounting, Finance and Management, vol. 20(1), pp. 53–65
Marz, N., Warren, J.: Big Data: Principles and Best Practices of Scalable Realtime Data Systems. Manning Publications, New York (2015)
Malewicz, G., Austern, M.H., Bik, A.J.C., Dehnert, J.C., Horn, I., Leiser, N., Czajkowski, G.: Pregel: a system for large-scale graph processing. In: SIGMOD 2010 (2010)
Ching, A., Edunov, S., Kabiljo, M., Logothetis, D., Muthukrishnan, S.: One trillion edges: graph processing at facebook-scale. PVLDB 8(12), 1804–1815 (2015)
Li, M., Tan, J., Wang, Y., Zhang, L., Salapura, V.: SparkBench: a comprehensive benchmarking suite for in memory data analytic platform Spark. In: CF 2015 (2015)
Cooper, B.F., Silberstein, A., Tam, E., Ramakrishnan, R., Sears, R.: Benchmarking cloud serving systems with YCSB. In: SoCC 2010 (2010)
Rabl, T., Frank, M., Danisch, M., Gowda, B., Jacobsen, H.-A.: Towards a complete BigBench implementation. In: Rabl, T., Sachs, K., Poess, M., Baru, C., Jacobson, H.-A. (eds.) WBDB 2015. LNCS, vol. 8991, pp. 3–11. Springer, Heidelberg (2015). doi:10.1007/978-3-319-20233-4_1
Chen, Y., Choi, A., Kumar, D., Rorke, D., Rus, S., Ghat, D.: How Impala Scales for Business Intelligence: New Test Results. http://blog.cloudera.com/blog/2015/09/how-impala-scales-for-business-intelligence-new-test-results/
Acknowledgements
We would like to thank Sreenivas Viswanada from Microsoft Corporation for running experiments on Metanautix. Yao Yi and Zhou Yi from Intel Corporation for their help to run 100 TB experiment. Michael Frank and Manuel Dansich from bankmark for their work on the TPCx-BB benchmark kit.
This work has been partially supported through grants by the German Ministry for Education and Research as Berlin Big Data Center BBDC (funding mark 01IS14013A) as well as through grants by the European Union’s Horizon 2020 research and innovation program under grant agreement 688191.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix A
Appendix A
K-Means using SQL. It is possible to write K-means using SQL and extensions in the Metanautix Quest system. The full implementation is complex, requiring an iteration (implemented using SQL triggers), but also rebalancing when a class becomes empty. For simplicity we assume that each point is described by an id, and a coordinate vector x. Using a SQL UDF, we can write the Distance function. A user-defined aggregation function, AVG_VECTOR, computes the average vector. We assume 50 classes. We outline the steps:
-
1.
Initialization of class centroids
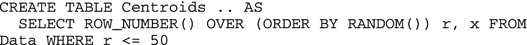
-
2.
Assigning data points to classes

-
3.
Compute new centroids

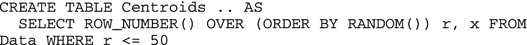


Using window functions. Window functions can be used where a MapReduce, or multiple passes would be otherwise required. As an example, we show how Query 02 can be rewritten.

Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Cao, P. et al. (2017). From BigBench to TPCx-BB: Standardization of a Big Data Benchmark. In: Nambiar, R., Poess, M. (eds) Performance Evaluation and Benchmarking. Traditional - Big Data - Internet of Things. TPCTC 2016. Lecture Notes in Computer Science(), vol 10080. Springer, Cham. https://doi.org/10.1007/978-3-319-54334-5_3
Download citation
DOI: https://doi.org/10.1007/978-3-319-54334-5_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-54333-8
Online ISBN: 978-3-319-54334-5
eBook Packages: Computer ScienceComputer Science (R0)