
Abstract
In this paper we aim to determine the location and orientation of a ground-level query image by matching to a reference database of overhead (e.g. satellite) images. For this task we collect a new dataset with one million pairs of street view and overhead images sampled from eleven U.S. cities. We explore several deep CNN architectures for cross-domain matching – Classification, Hybrid, Siamese, and Triplet networks. Classification and Hybrid architectures are accurate but slow since they allow only partial feature precomputation. We propose a new loss function which significantly improves the accuracy of Siamese and Triplet embedding networks while maintaining their applicability to large-scale retrieval tasks like image geolocalization. This image matching task is challenging not just because of the dramatic viewpoint difference between ground-level and overhead imagery but because the orientation (i.e. azimuth) of the street views is unknown making correspondence even more difficult. We examine several mechanisms to match in spite of this – training for rotation invariance, sampling possible rotations at query time, and explicitly predicting relative rotation of ground and overhead images with our deep networks. It turns out that explicit orientation supervision also improves location prediction accuracy. Our best performing architectures are roughly 2.5 times as accurate as the commonly used Siamese network baseline.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
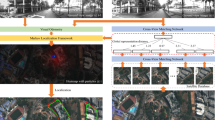
In this work we propose deep learning approaches to the problem of ground to overhead image matching. Such approaches enable large scale image geolocalization techniques to use widely-available overhead/satellite imagery to estimate the location of ground level photos. This is in contrast to typical image geolocalization which relies on matching “ground-to-ground” using a reference database of geotagged photographs. It is comparatively easy (for humans and machines) to determine if two ground level photographs depict the same location, but the world is very non-uniformly sampled by tourists and street-view vehicles. On the other hand, overhead imagery densely covers the Earth thanks to satellites and other aerial surveys. Because of this widespread coverage, matching ground-level photos to overhead imagery has become an attractive geolocalization approach [18]. However, it is a very challenging task (even for humans) because of the huge viewpoint variation and often lighting and seasonal variations, too. In this paper we try to learn how to match urban and suburban images from street-view to overhead-view imagery at fine-scale. As shown in Fig. 1, once the matching is done, the results can be ranked to generate a location estimate for a ground-level query.
To address cross-view geolocalization, the community has recently found deep learning techniques to outperform hand-crafted features [19, 33]. These approaches adopt architectures from the similar task of face verification [7, 28]. The method is as follows: a CNN, more specifically a Siamese architecture network [5, 7], is used to learn a common low dimensional feature representation for both ground level and aerial image, where they can be compared to determine a matching score. While being superior to non-deep approaches (or pre-trained deep features), we show there is significant room for improvement.

Street-view to overhead-view image matching
To that end we study different deep learning approaches for matching/verification and ranking/retrieval tasks. We develop better loss functions using the novel distance based logistic (DBL) layer. To further improve the performance, we show that good representations can be learned by incorporating rotational invariance (RI) and orientation regression (OR) during training. Experiments are performed on a new large scale dataset which will be published to encourage future research. We believe the findings here generalize to similar matching and ranking problems.
1.1 Related Work
Image geolocalization uses recognition techniques from computer vision to estimate the location (at city, region, or global scale) of ordinary ground level photographs. Early work by Hays and Efros [12] studied the feasibility of this task by leveraging millions GPS-tagged images from the Internet. In [36], image localization is done efficiently by building a dataset of Google street-view images from which SIFT features are extracted, indexed and used for localization of a query image by voting. Lin et al. [18] propose the first ground-to-overhead geolocalization method. No attempt is made to learn a common feature space or match directly across views. Instead, ground-to-ground matching to a reference database of ground-overhead view pairs is used to predict the overhead features of a ground-level query. Bansal et al. [3] match street-level images to aerial images by proposing a feature which encodes facade structure self-similarity. Shan et al. [26] propose a fully automated system that registers ground-based multi-view Stereo models to aerial imagery using traditional multi-view and Structure from Motion technique.
Deep learning has been successfully applied to a wide range of computer vision tasks such as recognition of objects [16], places [37], faces [28]. Most recently, “PlaNet” [32] made use of a large amount of geo-tagged images, quantized the gps-coordinate into a number of regions and trained a CNN to classify an image’s location into one of those regions. More relevant to this work is deep learning applications in cross-view images matching [19, 33]. The most similar published work to ours is Lin et al. [19] which uses a Siamese network to learn a common deep representation of street-view images and 45 degree aerial or bird’s eye images. This representation is shown to be better than hand-crafted or off-the-shelf CNN features for matching buildings’ facades from different angles. In [33], Workman et al. show that by learning different CNNs for different scales (i.e. using aerial images at certain scales), geolocalization can be done at the local or continental level. Interestingly, they also showed that by fixing the representation of ground-level image, which is 205 categories scores learned from the Places database [37], the CNN will learn the same category scores for aerial images. Most recently, Altwaijry et al. [2] use a deep attentive architecture to match aerial images across wide baselines.
2 Dataset of Street View and Overhead Image Pairs
We study the problem of matching street-view image to overhead images for the application of image geolocalization. To that end, we collect a large scale dataset of street-view and overhead images. More specifically, we randomly queried street-view panorama images from Google Map of the US. For each panorama, we randomly made several crops and for each crop we queried Google Map for the overhead image at the finest scale, resulting in an aligned pair of street-view and overhead images. Note that we want to localize the scene depicted in the image and not necessarily the camera. This is possible since Google panorama images come with geo-tags and depth estimates. We performed this data collection procedure on 11 different cities in the US and produced more than 1 million pairs of images. Some example matches in Miami are shown in Fig. 2. We make this dataset available to the public.

On the left: visualization of the positions of all Miami’s panorama images that we randomly collect for further processing. On the right: examples of produced street-view and overhead pairs.
Some similar attempts to collect a dataset for cross-view images matching task are [19, 33], but neither are publicly available. We expect that the result and analysis here can be easily generalized across other datasets (or other applications like recognizing face or object instead of scene). While the technical aspects are similar, there will be qualitative differences: when training on [19], the network learns to match the facade which is visible from both views. On [33], the network learns to match similar categories of scenes or land cover types. And on our dataset, the network learns to recognize different fine-grained street scenes.
3 Cross-View Matching and Ranking with CNN
Before considering the ranking/retrieval task, we start with the matching/verification task formalized as following: during training phase, matched pairs of street-view and overhead images are provided as positive examples (negative examples can be easily generated by pairing up non-matched images) to learn a model. During testing, given a pair of images, the learned model is applied to classify if the pair is a match or not.
We use deep CNNs which have been shown to perform better than traditional hand-crafted features, especially for problems with significant training data available. We study 2 categories of CNNs (Fig. 3): the classification network for recognizing matches and the representation learning networks for embedding cross-view images into the same feature space. Note that the first category is not practical for the large-scale retrieval application and is used as a loose upper bound for comparison.

Different CNN architectures: on the left is the first category: the classification network and the Siamese-classification hybrid network, on the right is the second category: the Siamese network and the triplet network
The second category includes the popular Siamese-like network and the triplet network. We introduce another version of Siamese and triplet networks that use the distance based logistic layer, a novel loss function. For completeness we also include the Siamese-classification hybrid network (which will belong to the first category). In this section we will experiment with 6 networks in total.
3.1 Classification CNN for Image Matching
Since our task is basically classification, the first network we experiment with is AlexNet [16], originally demonstrated for object classification (Fig. 3(a)). It has 5 convolutional layers, followed by 3 fully-connected layers and a soft-max layer for classification. We make several modifications: (1) the input will be a 6-channel image, a concatenation of a street-view image and an overhead image, while the original AlexNet only takes 1-image input, (2) we double the number of filters in the first convolutional layer, (3) we remove the division of filters into 2 groups (this was done originally because of GPU memory limitation) and (4) the softmax layer produces 2 outputs instead of 1000 because our task is binary classification. Similar architectures have been used for comparing image patches [35].
Training the CNN is done by minimizing this loss function:
where A and B are the 2 input images, \(l \in \{0, 1\}\) is the label indicating if it’s a match, \(I = concatenation(A, B)\) and f(.) is the AlexNet that outputs class scores.
3.2 Siamese-Like CNN for Learning Image Features
The Siamese-like network, shown in Fig. 3(b), has been used for cross-view image matching [19, 33] and retrieval [4, 29]. It consists of 2 separate CNNs. Each subnetwork takes 1 image as input and output a feature vector. Formally, given 2 images A and B, we can apply the learned network to produce the representation f(A) and f(B) that can be used for matching. This is done by computing the distance between these 2 vectors and classifying it as a match if the distance is small enough. During training, the contrastive loss is used:
where D is the squared distance between f(A) and f(B), and m is the margin parameter that omits the penalization if the distance of non-matched pair is big enough. This loss function encourages the two features to be similar if the images are a match and separates them otherwise; this is visualized in Fig. 4(left).
In the original Siamese network [10], the subnetworks (f(A) and f(B)) have the same architecture and share weights. In our implementation, each subnetwork will be an AlexNet without weight sharing since the images are of different domains: one is street view and the other is overhead.
3.3 Siamese-Classification Hybrid Network
The hybrid network is similar to the Siamese in that the input images are processed independently to produce output features and it is similar to the classification network that the features are concatenated to jointly infer the matching probability (Fig. 3(c)). Similar architectures have been used for used for cross-view matching and feature learning [1, 2, 11, 35].
Formally let AlexNet (f) is consist of 2 parts: the set of convolutional layers (\(f_{conv}\)) and the set of fully-connected layers (\(f_{fc}\)), the loss function is:
Where \(I_{conv} = concatenation(f_{conv}(A), f_{conv}(B))\). We expect this network to approach the accuracy of the classification network, while being slightly more efficient because intermediate features only need to be computed once per image.

Visualization of Siamese network training. We represent other instances (matches and non-matches) relative to a fixed instance (called the anchor). Left: with contrastive loss, matched instances keep being pulled closer, while non-matches are pushed away until they are out of the margin boundary, Right: log-loss with DBL: matched/nonmatched instances are pushed away from the “boundary” in the inward/outward direction.
3.4 Triplet Network for Learning Image Features
The fourth network that we call the triplet network or ranking network, shown in Fig. 3(c), is popular for image feature learning and retrieval [23–25, 30, 31, 34], though its effectiveness has not been explored in cross-view image matching. More specifically it aims to learn a representation for ranking relevance between images. It consists of 3 separate CNNs instead of 2 in the Siamese network. Formally, the network takes 3 images A, B and C as inputs, where (A,B) is a match and (A,C) is not, and minimizes this hinge loss for triplet (which has been explored before its application in deep learning [6, 21]):
Where D is the squared distances between the features f(A), f(B), f(C), and m is the margin parameter to omit the penalization if the gap between 2 distances is big enough. This loss layer encourages the distance of the more relevant pair to be smaller than the less relevant pair (Fig. 5(left)).
In the context of image matching, a pair of matched images (as the anchor and the match), plus a random image (as the non-match) is used as training example. With the learned representation, matching can be done by thresholding just like the Siamese network case.
3.5 Learning Image Representations with Distance-Based Logistic Loss
Despite being intuitive to understand, common loss functions based on euclidean distance might not be optimal for recognition. We instead advocate loss functions similar to the standard softmax, log-loss.
For the Siamese network, instead of the contrastive loss, we define the distance based logistic (DBL) layer for pairs of inputs as:
This outputs a value between 0 and 1, as the probability of the match given the squared distance. Then we can use the log-loss like the classification case for optimization:

Visualization of triplet network training. Each straight line originating from the anchor represents a triple. Left: with triplet/ranking loss, instances are pulled and pushed until the difference between the match distance and the non-match distance is bigger than the threshold, Right: log loss with DBL for triple. Similar to the ranking loss, but instead of relying on the threshold, the “force” depends on the current performance and confidence of the network.
The behavior of this loss is visualized in Fig. 4(right). Notice the difference from the traditional contrastive loss.
For the triplet network, we define the DBL for triple as following:
This represents the probability that it’s a valid triple: B is more relevant to A than C is to A (note that \(p(A, B, C) + p(A, C, B) = 1\)). Similarly the log-loss function is used, so:
The behavior of this loss is visualized in Fig. 5(right).
With this novel layer, we obtain Siamese and triplet DBL-Net that allow us to optimize for the recognition accuracy more directly. As with the original loss functions, the learned feature representation can be used for efficient matching and ranking at test time (when the DBL layer is not involved).
4 Learning to Perform Rotation Invariant Matching
As we are considering the task of fine-grained street view to overhead view matching, not only spatial but also orientation alignment is important, i.e. rotating the overhead image according to the street-view’s orientation instead of keeping the overhead image north oriented.
We aim to learn a rotation invariant (RI) representation of the overhead images. Similarly, Ke et al. [15] studied the problem of shape recognition without explicit alignment. In [20], nearby filters are untied to potentially allow pooling on output of different filters. This helps to learn complex representation without big filters or increasing the number of filters; however that doesn’t result in an explicit RI property like we desire. Deep symmetry network [9] is capable of encoding such a property, though its advantage is not significant when training data is sufficient for traditional CNN to learn that on its own. More relevant, [8] uses data augmentation and concatenation of features from different viewpoints. However our training data comes with orientation aligned images (though not the test sets), which can potentially provide stronger supervision during training. In this section we explore techniques to take advantage of such information.
4.1 Partial Rotation Invariance by Data Augmentation
Training with multiple rotation samples: Rotation invariance (RI) can be encouraged simply by performing random rotation of overhead training images. Although invariance can help to a certain extent, there is a trade-off with discriminative ability. We propose to control the amount of rotation that the matching process will be invariant to, i.e. partial RI. Specifically this is done by adding a random amount of rotation within a certain range to the aligned overhead images. For example a \(90^{\circ }\) RI is achieved by rotating by an amount from \(-45^{\circ }\) to \(45^{\circ }\); \(360^{\circ }\) RI means fully RI.
Testing with multiple rotation samples/crops: since we don’t know the correct orientation alignment at test time, if our representation is only partially rotation invariant, we have to test with multiple rotated version of the original image to find the best one. For example: with \(360^{\circ }\) RI representation, 1 sample is enough, with \(180^{\circ }\) RI representation, at least 2 rotation samples (that are \(180^{\circ }\) apart) are needed. Similar to multi-crop in classification tasks, we find that using more test time samples improves the result slightly (e.g. using 16 rotation samples at test time even if the network was trained to be \(90^{\circ }\) RI).
Multi-orientation feature averaging: as we use more rotation samples than needed, not only one but multiple of them should be good matches. For example testing with 16 rotation, we expect 16 of the them are good matches under \(360^{\circ }\) RI range, 4 under \(90^{\circ }\) RI range, etc. Therefore it makes sense to, instead of matching with a single best rotation (nearest neighbor), match with the best sequence of rotations. We propose to, depending on the degree of RI, average the features of multiple rotation samples during indexing time to obtain more stable features. This technique is especially useful in full RI case: all samples are averaged to produce a single feature, so the cost during query time is the same as using 1 sample.
4.2 Learning Better Representations with Orientation Regression
Next we propose to add an auxiliary loss function for orientation regression, where the amount of added rotation during training can be used as label for supervision. As shown in Fig. 6, the features from the last hidden layer (fc7) are concatenated, then we add 2 fully connected layers (one acting as hidden layer and one as output layer) and use Euclidean distance as our loss function for regression.

Network architecture with data augmentation by random rotation and an additional branch that performs orientation regression
It is known that additional or ‘auxiliary’ losses can be very useful. For example, ranking can be improved by adding a classification layer predicting category [4, 24] or attributes [13]. In [27], co-training of verification and classification is done to obtain a good representation for faces. Somewhat differently, our auxiliary loss is not directly related to the main task and its label is randomly generated by data augmentation. As the inference is done on 2 images jointly, its effect on each individual’s representation can be difficult to interpret. The motivation, beyond being able to predict query orientation, is that this will make the network more orientation-aware and therefore produce a better feature representation for the localization task.
5 Experiments
Data preparation: we use our dataset of more than 1 million matched pairs of street-view and overhead-view images randomly collected from Google Maps of 11 different US cities (Sect. 2). We use all the cross-view pairs in 8 cities as training data (a total of 900k examples) and the remaining 3 cities as 3 test sets (around 70k examples per set).
We learn with mini-batch stochastic gradient descent, the standard optimization technique for training deep networks. Our batch size is 128 (64 of which are positive examples while 64 are negative examples). Training starts with a large learning rate (experimentally chosen) and get smaller as the network converges. The number of training iterations is 150k. We use Caffe framework [14].
Data augmentation: we apply random rotation of overhead images during training and use multiple rotation samples during testing (described in Sect. 4). The effect will be studied in detail in Sect. 5.2 We also apply a small amount of random cropping and random scaling.
Image Ranking and Geolocalization. While we have thus far considered location matching as a binary classification problem, our end goal is to use it for geolocalization. This application can be framed as a ranking or retrieval problem: given a query street view image and a repository of overhead images, one of which is the match, we want to rank the overhead images according to their relevance to the query so that the true match image is ranked as high as possible. The ranking task is typically approached as following: the representation learning networks are applied to the query image and the repository’s images to obtain their feature vectors. Then these overhead images can be ranked by sorting the distance from their features to the query image’s feature. The localization is considered successful if the true match overhead image is ranked within a certain top percentile.
Metrics: We measure both the classification and ranking performance on each test set. The classification accuracy is computed by using the best threshold on the each test set (random chance performance is 50 %). For the ranking task, we use mean recall at top K% as our measurement (the percentage of cases in which the correct overhead match of the query street view image is ranked within top K percentile, chance performance is K%). Some ranking examples are shown in Fig. 7.

Ranking result examples on the Denver test set (reference set of 70k reference images)
5.1 Comparison of CNN Architectures
We train and compare 6 variants of CNN described in Sect. 3. All are initialized from scratch (no pretraining), trained to be \(90^{\circ }\) RI, and tested with 16 rotation samples. Quantitative comparisons are shown in the top of Table 1.
Not surprisingly, both classification networks achieved better accuracy than the representation learning Siamese and triplet networks. This is because they jointly extract and exchange information from both input images. Somewhat unexpectedly, in our experiments the hybrid network is the better of the two. Even-though the ‘pure’ classification network should be capable of producing the same mapping as the hybrid, it might have trouble learning to process both images from the 1st layer.
Between the Siamese and triplet network, the triplet network outperforms the Siamese by a surprisingly large margin on both tasks. While both networks try to separate matches from non-matches, the contrastive loss function works toward a secondary objective: drive the distance between matched pair as close to 0 as possible (Fig. 8). Note that this might be a good property for the learned representation to have; but for the task of matching and ranking we found that this might compromise the main objective. One way to alleviate this problem is to add another margin to the contrastive loss function to cut the loss when the distance is small enough [17].
Analysis of Siamese and triplet network’s performance has helped us develop the DBL layer. As the result, both DBL-Nets significantly outperform the original networks. While the Siamese with DBL and triplet network with DBL have comparable performances, it seems that the triplet DBL-Net is slightly better at ranking. Note that for most of the experiments we have been conducting, the performance of these two tasks strongly correlate. We use the triplet network with DBL layer for all following experiments.

Histograms of pairwise distances of features produced by the Siamese network-contrastive loss (left) and the triplet network (right). Note the crowding near zero distance for the Siamese network, which may explain poor performance for fine-grained retrieval tasks when it is important to compare small distances.
5.2 Rotation Invariance
We experiment with partial rotation invariance (RI) and orientation regression (OR) (described in Sect. 4) for matching and ranking using the triplet DBL-Net. The result is shown in Table 2.
As an upper bound, we train a network where overhead images are aligned to the ground truth camera direction of the street view image (1GT). This is not a realistic usage scenario for image geolocalization since camera azimuth would typically be unknown. As expected, the network without RI performs very well when true alignment is provided during testing (1GT), but performs poorly otherwise. This baseline shows how challenging the problem has become because of orientation ambiguity. As the degree of RI during training is increased, the performance improves.
Observe that fewer numbers of test time rotated crops/samples doesn’t work well if the amount of RI is limited. The full RI setting is the best when testing with a single sample. As the number of rotations increase, the performance improves, especially for the partially RI networks. Using 16 rotations, the \(90^{\circ }\) RI network has the highest performance. It might be the best setting for compromising between invariance and discriminate power (this might not be the case when using hundreds of samples, but we found that it’s not computationally practical and the improvement is not significant).
Orientation regression’s impact on the \(360^{\circ }\) RI network is surprisingly significant; its performance improves by 30 % (relatively). However OR doesn’t affect \(90^{\circ }\) RI network positively, suggesting that the 2 techniques might not complement each other. It’s interesting that the OR is useful even though its effect during learning is not as intuitive to understand as partial RI. As a by-product, the network can align matches. The orientation prediction has an average error of \(17^{\circ }\) for the ground truth matching overhead image and is discussed more in the supplemental document.
Finally we show the effect of applying multi-orientation feature averaging on \(360^{\circ }\) RI + OR network. By averaging the feature of 16 samples, we obtain comparable performance to exhaustively testing with 16 samples (result on all 3 test sets is shown in the 2nd part of Table 1). Though not shown here, applying this strategy to partial RI networks also slightly improve their performances.
5.3 Triplet Sampling by Exhausting Mini-batch
To speed up the training of triplet networks with the triplet hinge loss, clever triplet sampling and hard negative mining is usually applied [25, 30, 31]. This is because the triplet not violating the margin does not contribute to the learning. However it can skew the input distribution if not handled carefully (for instance, only mine hardest examples); different schemes were used in [25, 30, 31].
On the other hand, our DBL-log loss is practically a smoothed version of the hinge loss. We propose to use every possible triplet in the mini-batch. We experiment with using a mini-batch of 128 pairs of (matched) images. Since each image in our data has a single unique match only, we can generate a total of 256 * 127 triplets (256 different anchors, 1 match and 127 non-matches per anchor). This is done within our exhausting DBL log loss layer implementation (eDBL); hence the cost of processing the mini-batch is not much more expensive. In a similar spirit, recent work [22] proposes a loss function that considers the relationship between every examples in each training batch.
We train a triplet eDBL-Net+\(360^{\circ }\)RI+OR+avg16. Its effect is very positive: the convergence is much faster, after around 30k iterations the network achieved similar performance as in previous experiments where each network was trained with 150k iterations using the same batch size. After 80k iterations, we achieve even better ranking performance, shown at the bottom of Table 1.
6 Conclusion
We introduce a new large scale cross-view data of street scenes from ground level and overhead. On this dataset, we have experimented with different CNN architectures extensively; the reported results and analysis can be generalized to other ranking and embedding problems. The result indicates that the Siamese network with contrastive loss is the least competitive even though it has been popular for cross-view matching. Our proposed DBL layer has significantly improved representation learning networks. Last but not least, we show how to further improve ranking performance by incorporating supervised alignment information to learn a rotational invariant representation.
References
Agrawal, P., Carreira, J., Malik, J.: Learning to see by moving. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 37–45 (2015)
Altwaijry, H., Trulls, E., Hays, J., Fua, P., Belongie, S.: Learning to match aerial images with deep attentive architectures. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016)
Bansal, M., Daniilidis, K., Sawhney, H.: Ultra-wide baseline facade matching for geo-localization. In: Fusiello, A., Murino, V., Cucchiara, R. (eds.) ECCV 2012. LNCS, vol. 7583, pp. 175–186. Springer, Heidelberg (2012). doi:10.1007/978-3-642-33863-2_18
Bell, S., Bala, K.: Learning visual similarity for product design with convolutional neural networks. ACM Trans. Graph. (TOG) 34(4), 98 (2015)
Bromley, J., Bentz, J.W., Bottou, L., Guyon, I., LeCun, Y., Moore, C., Säckinger, E., Shah, R.: Signature verification using a siamese time delay neural network. Int. J. Pattern Recogn. Artif. Intell. 7(4), 669–688 (1993)
Chechik, G., Sharma, V., Shalit, U., Bengio, S.: Large scale online learning of image similarity through ranking. J. Mach. Learn. Res. 11, 1109–1135 (2010)
Chopra, S., Hadsell, R., LeCun, Y.: Learning a similarity metric discriminatively, with application to face verification. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2005, vol. 1, pp. 539–546. IEEE (2005)
Dieleman, S., Willett, K.W., Dambre, J.: Rotation-invariant convolutional neural networks for galaxy morphology prediction. Mon. Not. R. Astron. Soc. 450(2), 1441–1459 (2015)
Gens, R., Domingos, P.M.: Deep symmetry networks. In: Advances in Neural Information Processing Systems, pp. 2537–2545 (2014)
Hadsell, R., Chopra, S., LeCun, Y.: Dimensionality reduction by learning an invariant mapping. In: 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, vol. 2, pp. 1735–1742. IEEE (2006)
Han, X., Leung, T., Jia, Y., Sukthankar, R., Berg, A.C.: MatchNet: unifying feature and metric learning for patch-based matching. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3279–3286 (2015)
Hays, J., Efros, A., et al.: IM2GPS: estimating geographic information from a single image. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2008, pp. 1–8. IEEE (2008)
Huang, J., Feris, R.S., Chen, Q., Yan, S.: Cross-domain image retrieval with a dual attribute-aware ranking network. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1062–1070 (2015)
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., Guadarrama, S., Darrell, T.: Caffe: convolutional architecture for fast feature embedding. arXiv preprint arXiv:1408.5093 (2014)
Ke, Q., Li, Y.: Is rotation a nuisance in shape recognition? In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4146–4153 (2014)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: Advances in Neural Information Processing Systems, pp. 1097–1105 (2012)
Lin, J., Morere, O., Chandrasekhar, V., Veillard, A., Goh, H.: DeepHash: getting regularization, depth and fine-tuning right. arXiv preprint arXiv:1501.04711 (2015)
Lin, T.Y., Belongie, S., Hays, J.: Cross-view image geolocalization. In: 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 891–898. IEEE (2013)
Lin, T.Y., Cui, Y., Belongie, S., Hays, J.: Learning deep representations for ground-to-aerial geolocalization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5007–5015 (2015)
Ngiam, J., Chen, Z., Chia, D., Koh, P.W., Le, Q.V., Ng, A.Y.: Tiled convolutional neural networks. In: Advances in Neural Information Processing Systems, pp. 1279–1287 (2010)
Norouzi, M., Fleet, D.J., Salakhutdinov, R.R.: Hamming distance metric learning. In: Advances in Neural Information Processing Systems, pp. 1061–1069 (2012)
Oh Song, H., Xiang, Y., Jegelka, S., Savarese, S.: Deep metric learning via lifted structured feature embedding. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
Parkhi, O.M., Vedaldi, A., Zisserman, A.: Deep face recognition. In: Proceedings of the British Machine Vision, vol. 1(3), p. 6 (2015)
Sangkloy, P., Burnell, N., Ham, C., Hays, J.: The sketchy database: learning to retrieve badly drawn bunnies. ACM Trans. Graph. (Proceedings of SIGGRAPH) (2016)
Schroff, F., Kalenichenko, D., Philbin, J.: FaceNet: a unified embedding for face recognition and clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 815–823 (2015)
Shan, Q., Wu, C., Curless, B., Furukawa, Y., Hernandez, C., Seitz, S.M.: Accurate geo-registration by ground-to-aerial image matching. In: 2014 2nd International Conference on 3D Vision (3DV), vol. 1, pp. 525–532. IEEE (2014)
Sun, Y., Chen, Y., Wang, X., Tang, X.: Deep learning face representation by joint identification-verification. In: Advances in Neural Information Processing Systems, pp. 1988–1996 (2014)
Taigman, Y., Yang, M., Ranzato, M., Wolf, L.: DeepFace: closing the gap to human-level performance in face verification. In: 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1701–1708. IEEE (2014)
Wang, F., Kang, L., Li, Y.: Sketch-based 3D shape retrieval using convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1875–1883 (2015)
Wang, J., Song, Y., Leung, T., Rosenberg, C., Wang, J., Philbin, J., Chen, B., Wu, Y.: Learning fine-grained image similarity with deep ranking. In: 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1386–1393. IEEE (2014)
Wang, X., Gupta, A.: Unsupervised learning of visual representations using videos. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2794–2802 (2015)
Weyand, T., Kostrikov, I., Philbin, J.: Planet - photo geolocation with convolutional neural networks. CoRR abs/1602.05314 (2016). http://arXiv.org/abs/1602.05314
Workman, S., Souvenir, R., Jacobs, N.: Wide-area image geolocalization with aerial reference imagery. In: ICCV 2015 (2015)
Wu, P., Hoi, S.C., Xia, H., Zhao, P., Wang, D., Miao, C.: Online multimodal deep similarity learning with application to image retrieval. In: Proceedings of the 21st ACM International Conference on Multimedia, pp. 153–162. ACM (2013)
Zagoruyko, S., Komodakis, N.: Learning to compare image patches via convolutional neural networks. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2015)
Zamir, A.R., Shah, M.: Accurate Image localization based on Google maps street view. In: Daniilidis, K., Maragos, P., Paragios, N. (eds.) ECCV 2010. LNCS, vol. 6314, pp. 255–268. Springer, Heidelberg (2010). doi:10.1007/978-3-642-15561-1_19
Zhou, B., Lapedriza, A., Xiao, J., Torralba, A., Oliva, A.: Learning deep features for scene recognition using places database. In: Advances in Neural Information Processing Systems, pp. 487–495 (2014)
Acknowledgments
Supported by the Intelligence Advanced Research Projects Activity (IARPA) via Air Force Research Laboratory, contract FA8650-12-C-7212. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright annotation thereon. Disclaimer: The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of IARPA, AFRL, or the U.S. Government.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing AG
About this paper
Cite this paper
Vo, N.N., Hays, J. (2016). Localizing and Orienting Street Views Using Overhead Imagery. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds) Computer Vision – ECCV 2016. ECCV 2016. Lecture Notes in Computer Science(), vol 9905. Springer, Cham. https://doi.org/10.1007/978-3-319-46448-0_30
Download citation
DOI: https://doi.org/10.1007/978-3-319-46448-0_30
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-46447-3
Online ISBN: 978-3-319-46448-0
eBook Packages: Computer ScienceComputer Science (R0)