
Abstract
In Chap. 2, we have described how point neuron and exponential synapse models can be obtained as an abstraction of the complex electrochemical dynamics of neurons and synapses observed in vivo. Throughout the remainder of this thesis, we shall continue working with such abstract models, in particular point LIF and AdEx neurons with either current or conductance-based synapses with an exponential interaction kernel.
The miracle of the appropriateness of the language of mathematics for the formulation of the laws of physics is a wonderful gift which we neither understand nor deserve. We should be grateful for it and hope that it will remain valid in future research and that it will extend, for better or for worse, to our pleasure, even though perhaps also to our bafflement, to wide branches of learning.
Eugene Wigner, The Unreasonable Effectiveness of Mathematics in the Natural Sciences, 1960
Eugene Wigner wrote a famous essay on the unreasonable effectiveness of mathematics in natural sciences. He meant physics, of course. There is only one thing which is more unreasonable than the unreasonable effectiveness of mathematics in physics, and this is the unreasonable ineffectiveness of mathematics in biology.
Israel Gelfand, alleged quote
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Notes
- 1.
Sometimes, the covariance matrix is simply called a variance, regardless of the dimensionality of the RV. This denomination is meant to show how the variance matrix of multidimensional RVs is a natural extension of the scalar variance of scalar RVs. The term “covariance matrix”, on the other hand, points towards the fact that individual matrix elements of \(\varvec{\Sigma }_{\varvec{Z}}\) are, indeed, covariances between the scalar components of \(\varvec{Z}\).
- 2.
For a good review with a comprehensive bibliography, see Destexhe (2007).
- 3.
The Picard-Lindelöf theorem guarantees existence and uniqueness for our particular case, but it only applies between two consecutive spikes.
- 4.
We loosely define the duration of a kernel as the time interval over which it is significantly different from 0. For example, we could choose the duration of \(\kappa (t)\) as the length \(\Delta t = t_2 - t_1\) of the shortest interval \([t_1, t_2)\) with the property that \(\int \limits _{t_1}^{t_2} \kappa (t) \, dt > (1-\epsilon ) \int \limits _{-\infty }^{\infty } |\kappa (t)| \, dt\) for some predefined “allowed relative error” \(\epsilon \).
- 5.
For a monotonically decreasing \(\kappa \) we can calculate the CDF of \(Y_i\):
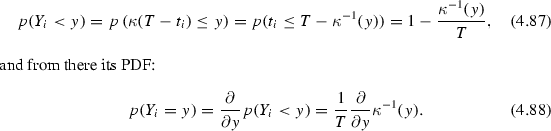
For non-monotonic kernels, the support of \(\kappa \) can simply be partitioned into a set of intervals on each of which \(\kappa \) is monotonic and the CDF becomes a sum of terms that have the same form as the one in Eq. 4.87.
- 6.
The relation

follows directly from the Cauchy–Schwartz inequality for the inner product space of square-integrable functions (to which finite-variance Gaussian PDFs belong by definition)
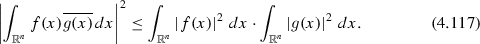
.
- 7.
Here, we explicitly allow the violation of Dale’s law, which would, in principle, not only require \(\mathrm {sgn} (w_{1j})=\mathrm {sgn} (w_{1j})\), but also \(\tau ^\mathrm {syn} _{1j}=\tau ^\mathrm {syn} _{2j}\), since the synaptic transmission should be mediated by the same type of neurotransmitters (see Sect. 2.1.3). However, Dale’s law does not necessarily apply to artificial neural networks in general. In particular, allowing it to be violated turns out to be quite useful, such as for various types of neuromorphic hardware or for the specific class of networks we discuss in Chap. 6.
- 8.
A property holds “almost everywhere” if, the set for which the property does not hold has measure zero. In other words, the set for which the property holds takes up almost the entire configuration space. Its analog in probability theory is “almost surely” (see, e.g., the statement of the CLT from Sect. 4.3.2).
- 9.
Albeit not necessarily in the same way as we do here. More often than using a box function, spike trains are convolved with exponential or Gaussian functions. Yet another popular method of processing a spike train is by binning, thereby effectively discretizing time and treating the output of a neuron as a firing rate.
- 10.
The Kullback–Leibler divergence is not symmetric, i.e., in general,
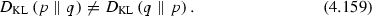
- 11.
For a continuous \(\Omega \), the sum is replaced by an integral.
- 12.
Herein lies the main difference between the CC and the SU. The former is a measure of correlation, which discerns between positive (\(\rho >0\)) and negative (\(\rho <0\)) correlation, whereas the latter is a measure of dependence (mutual information). As usual, correlation implies dependence (\(\rho \in \{-1,1\} \Rightarrow \tilde{I} =1\)). Conversely, independence implies zero correlation (\(\tilde{I} =0 \Rightarrow \rho =0\)).
- 13.
The notation represents a reference to the Gaussian approximation for the free membrane potential PDF.
- 14.
We have kept this notation for historical reasons. Earlier versions of our theory used a modified synaptic conductance trace instead of the free membrane potential, for which we used the term “load function”.




References
C.M. Bishop, Pattern Recognition and Machine Learning, vol. 1. springer, New York (2009)
O. Breitwieser, Towards a neuromorphic implementation of spike-based expectation maximization. Master thesis, Ruprecht-Karls-Universität Heidelberg, 2015
I. Bytschok, From shared input to correlated neuron dynamics: Development of a predictive framework, Ph.D. thesis, Diploma thesis, University of Heidelberg, 2011
A. Destexhe, High-conductance state. Scholarpedia 2(11), 1341 (2007)
S. Habenschuss, J. Bill, B. Nessler, Homeostatic plasticity in bayesian spiking networks as expectation maximization with posterior constraints. Adv. Neural Inf. Proc. Syst. 25, (2012)
M.M. Halldórsson, J. Radhakrishnan, Greed is good: approximating independent sets in sparse and bounded-degree graphs. Algorithmica 18(1), 145–163 (1997)
B. Nessler, M. Pfeiffer, W. Maass, STDP enables spiking neurons to detect hidden causes of their inputs, in NIPS (2009), pp. 1357–1365
B. Nessler, M. Pfeiffer, L. Buesing, W. Maass, Bayesian computation emerges in generic cortical microcircuits through spike-timing-dependent plasticity. PLoS Comput. Biol. 9(4), e1003037 (2013)
M.A. Petrovici, J. Bill, A New Method for Quantifying and Predicting Neural Response Correlations: Internal Report (2009)
M.J. Richardson, W. Gerstner, Statistics of subthreshold neuronal voltage fluctuations due to conductance-based synaptic shot noise. Chaos: An Interdisciplinary. J. Nonlinear Sci. 16(2), 026106 (2006)
I.H. Witten, E. Frank, Data Mining: Practical Machine Learning Tools and Techniques. Morgan Kaufmann, Massachusetts (2005)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Petrovici, M.A. (2016). Dynamics and Statistics of Poisson-Driven LIF Neurons. In: Form Versus Function: Theory and Models for Neuronal Substrates . Springer Theses. Springer, Cham. https://doi.org/10.1007/978-3-319-39552-4_4
Download citation
DOI: https://doi.org/10.1007/978-3-319-39552-4_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-39551-7
Online ISBN: 978-3-319-39552-4
eBook Packages: Physics and AstronomyPhysics and Astronomy (R0)