
Abstract
The major obstacle to use multicores for real-time applications is that we may not predict and provide any guarantee on real-time properties of embedded software on such platforms; the way of handling the on-chip shared resources such as L2 cache may have a significant impact on the timing predictability.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Notes
- 1.
We focus on the interference caused by the shared L2 cache, and there could be other interference between tasks running simultaneously. However, we believe the scheduling algorithm and analysis techniques in this paper is a necessary step towards completely avoiding interference between tasks running on multicores, and can be integrated with techniques of performance isolation on other shared resources, for instance, the work in [167] to avoid interference caused by the shared on-chip bus.
- 2.
Note that this is just an example of how cache partitioning can be achieved; by no means is virtual memory a necessity to the results presented in this chapter.
References
V. Suhendra, T. Mitra, Exploring locking and partitioning for predictable shared caches on multi-cores, in DAC, 2008
R. Wilhelm, J. Engblom, A. Ermedahl, N. Holsti, S. Thesing, D. Whalley, G. Bernat, C. FerdinanRd, R. Heckmann, T. Mitra, F. Mueller, I. Puaut, P. Puschner, J. Staschulat, P. Stenström, The worst-case execution-time problem overview of methods and survey of tools. ACM Trans. Embed. Comput. Syst. 7(3), 36:1–36:53 (2008)
J. Carpenter, S. Funk, P. Holman, A. Srinivasan, J. Anderson, S. Baruah, A categorization of real-time multiprocessor scheduling problems and algorithms, in Handbook of Scheduling - Algorithms, Models, and Performance Analysis (2004). http://www.crcnetbase.com/doi/abs/10.1201/9780203489802.ch30
B. Andersson, S. Baruah, J. Jonsson, Static-priority scheduling on multiprocessors, in RTSS, 2001
T.P. Baker, Multiprocessor edf and deadline monotonic schedulability analysis, in RTSS, 2003
M. Bertogna, M. Cirinei, G. Lipari, Improved schedulability analysis of edf on multiprocessor platforms, in ECRTS, 2005
J. Yan, W. Zhang, Wcet analysis for multi-core processors with shared l2 instruction caches, in RTAS, 2008
M. Berkelaar, lp_solve: (mixed integer) linear programming problem solver (2003). Available from ftp://ftp.es.ele.tue.nl/pub/lp_solve
N. Guan, W. Yi, Z. Gu, Q. Deng, G. Yu, New schedulability test conditions for non-preemptive scheduling on multiprocessor platforms, in RTSS, 2008
T.P. Baker, A comparison of global and partitioned edf schedulability tests for multiprocessors. Technical Report, Department of Computer Science, Florida State University, FL, 2005
H. Leontyev, J.H. Anderson, A unified hard/soft real-time schedulability test for global edf multiprocessor scheduling, in Proceedings of the 29th IEEE Real-Time Systems Symposium (RTSS), 2008
B.K. Bershad, B.J. Chen, D. Lee, T.H. Romer, Avoiding conflict misses dynamically in large direct mapped caches, in ASPLOS, 1994
J. Herter, J. Reineke, R. Wilhelm, Cama: cache-aware memory allocation for wcet analysis, in ECRTS, 2008
J. Rosen, A. Andrei, P. Eles, Z. Peng, Bus access optimization for predictable implementation of real-time applications on multiprocessor systems-on-chip, in RTSS, 2007
A. Fedorova, M. Seltzer, C. Small, D. Nussbaum, Throughput-oriented scheduling on chip multithreading systems. Technical Report, Harvard University, 2005
D. Chandra, F. Guo, S. Kim, Y. Solihin, Predicting inter-thread cache contention on a multi-processor architecture, in HPCA, 2005
J.H. Anderson, J.M. Calandrino, U.C. Devi, Real-time scheduling on multicore platforms, in RTAS, 2006
J.M. Calandrino, J.H. Anderson, Cache-aware real-time scheduling on multicore platforms: heuristics and a case study, in ECRTS, 2008
K. Danne, M. Platzner, An edf schedulability test for periodic tasks on reconfigurable hardware devices, in LCTES, 2006
N. Guan, Q. Deng, Z. Gu, W. Xu, G. Yu, Schedulability analysis of preemptive and non-preemptive edf on partial runtime-reconfigurable fpgas, in ACM Transaction on Design Automation of Electronic Systems, vol. 13, no. 4 (2008)
N. Fisher, J. Anderson, S. Baruah, Task partitioning upon memory-constrained multiprocessors, in RTCSA, 2005, p. 1
V. Suhendra, C. Raghavan, T. Mitra, Integrated scratchpad memory optimization and task scheduling for mpsoc architectures, in CASES, 2006
H. Salamy, J. Ramanujam, A framework for task scheduling and memory partitioning for multi-processor system-on-chip, in HiPEAC, 2009
A. Wolfe, Software-based cache partitioning for real-time applications. J. Comput. Softw. Eng. 2(3), 315–327 (1994). http://dl.acm.org/citation.cfm?id=200781.200792
B.D. Bui, M. Caccamo, L. Sha, J. Martinez, Impact of cache partitioning on multi-tasking real time embedded systems, in RTCSA, 2008
D. Chiou, S. Devadas, L. Rudolph, B.S. Ang, Dynamic cache partitioning via columnization. Technical Report, MIT, 1999
D. Tam, R. Azimi, M. Stumm, L. Soares, Managing shared l2 caches on multicore systems in software, WIOSCA, 2007
J. Liedtke, H. Hartig, M. Hohmuth, Os-controlled cache predictability for real-time systems, in RTAS, 1997
N. Guan, M. Stigge, W. Yi, G. Yu, Cache-aware scheduling and analysis for multicores. Technical Report, Uppsala University, (http://user.it.uu.se/yi), 2009
C. Kim, D. Burger, S.W. Keckler, An adaptive, nonuniform cache structure for wiredelay dominated on-chip caches, in ASPLOS, 2002
Author information
Authors and Affiliations
Appendix: Improving the Interference Computation
Appendix: Improving the Interference Computation
The computation of \(I_{k}^{i}\), an upper bound of the interference caused by τ i over J k , in Eq. (8.3) (Sect. 8.5.1) is grossly over-pessimistic. In the following we will present a more precise computation of \(I_{k}^{i}\) by carefully identifying the worst-case scenario of τ i ’s interference.
Recall that the problem window \([r_{k},l_{k}]\) is a time frame of a given length (\(l_{k} - r_{k} = S_{k}\)) for which we want to derive a bound of how much interference a task τ i (or rather its jobs) can cause to possibly prevent J k from running. We can compute \(I_{k}^{i}\) using the following lemma:
Lemma 8.2.
An upper bound of the interference contributed by τ i in the problem window of length S k can be computed by
where
Proof.
The lemma is proved in the following cases:
-
1.
i < k, i.e., τ i ’s priority is higher than τ k ’s.
If \(S_{k} <C_{i}\), i.e., a job of τ i can execute even longer than J k ’s slack, trivially \(I_{k}^{i} = S_{k}\) is a safe bound.
If \(S_{k} \geq C_{i}\), the worst-case for \(I_{k}^{i}\) occurs when
-
(a)
one of τ i ’s jobs is released at \(l_{k} - C_{k}\),
-
(b)
all jobs are released with period T i , and
-
(c)
the carry-in job executes as late as possible.
See Fig. 8.8. To see that this is indeed the worst-case, we imagine to move the release times of τ i ’s jobs leftwards for a distance \(\epsilon ^{l} <T_{i} - C_{i}\) or rightwards for a distance \(\epsilon ^{r} <C_{i}\), to see if it is possible to increase \(I_{k}^{i}\) by doing so. (It’s easy to see that moving τ i ’s jobs’ releases more in either direction creates a situation equivalent to one of these two cases. Further, \(I_{k}^{i}\) cannot be increased if the number of τ i ’s jobs in \([r_{k},l_{k}]\) is decreased, which means we only need to consider the scenario that all jobs are released periodically.) If it is moved leftwards by ε l, τ i ’s interference cannot increase at neither the left nor the right end of the interval \([r_{k},l_{k}]\), so moving leftwards for a distance \(\epsilon ^{l} <T_{i} - C_{i}\) will not increase the interference. On the other hand, when moving rightwards by ε r, the interference is increased by no more than ε r at the left end, but decreased by ε r at the right end, so moving rightwards for a distance \(\epsilon ^{r} <C_{i}\) will also not increase the interference. In summary, based on the scenario in Fig. 8.8, \(I_{k}^{i}\) cannot be increased no matter how we move the release time of τ i . With this worst-case scenario, we can see that the interference contributed by the carry-out job is C i , the number of the body jobs is \(\lfloor (S_{k} - C_{i})/T_{i}\rfloor\) (each contributing C i interference), and the interference contributed by the carry-in job is bounded by both C i and the distance between r k and the carry-in job’s deadline. Thus, for each task τ i with \(i <k \wedge S_{k} \geq C_{i}\), we can compute \(I_{k}^{i}\) by
$$\displaystyle{ I_{k}^{i} = \left \lfloor \frac{S_{k} - C_{i}} {T_{i}} \right \rfloor C_{i} + C_{i}+\omega }$$(8.12)where ω is defined as in Eq. (8.11).
Fig. 8.8 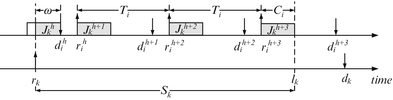
Computation of \(I_{k}^{i}\) if i < k and \(S_{k} \geq C_{i}\)
-
(a)
-
2.
i = k, i.e., τ i is the analyzed task. Since \(D_{k} \leq T_{k}\) holds for each task τ k , the other jobs of τ k cannot interfere with J k , so in this case we have
$$\displaystyle{ I_{k}^{i} = 0 }$$(8.13) -
3.
i > k, i.e., τ i ’s priority is lower than τ k .
In FP CA , a job \(J_{i}^{h}\) with lower priority than J k can interfere with J k only if it is released earlier than r k . Therefore, τ i can only cause interference to J k with at most one job, so its interference is bounded by C i . The interference is also bounded by the length of the problem window S k . Thus, for i > k, we can compute \(I_{k}^{i}\) by
$$\displaystyle{ I_{k}^{i} =\min (C_{ i},S_{k}) }$$(8.14)

Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Guan, N. (2016). Cache-Aware Scheduling. In: Techniques for Building Timing-Predictable Embedded Systems. Springer, Cham. https://doi.org/10.1007/978-3-319-27198-9_8
Download citation
DOI: https://doi.org/10.1007/978-3-319-27198-9_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-27196-5
Online ISBN: 978-3-319-27198-9
eBook Packages: EngineeringEngineering (R0)