
Abstract
Exploiting open data in the web community is an established movement that is growing these recent years. Government public data is probably the most common and visible part of the later phenomena. What about companies and business data? Even if the kickoff was slow, forward-thinking companies and businesses are embracing semantic technologies to manage their corporate information. The availability of various sources, be they internal or external, the maturity of semantic standards and frameworks, the emergence of big data technologies for managing huge volumes of data have fostered the companies to migrate their internal information systems from traditional silos of corporate data into semantic business data hubs. In other words, the shift from conventional enterprise information management into Linked Opened Data compliant paradigm is a strong trend in enterprise roadmaps. This chapter discusses a set of guidelines and best practices that eases this migration within the context of a corporate application.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Linked Data, Open Data and Linked Open Data (LOD) are three concepts that are very popular nowadays in the semantic community. Various initiatives, like openspending.org, are gaining ground to promote the openness of data for more transparency of institutions. But what is the difference between these three concepts?
Linked Data refers to the way of structuring the data and creates relationships between them. Open Data similar to open-source, opens content to make it available to citizens, developers, etc. for use with as limited restrictions as possible (legal, technological, financial, license). Linked Open Data, that we refer to as LOD, is the combination of both: to structure data and to make it available for others to be reused.
The LOD paradigm democratized the approach of opening data sources and interlinking content from various locations to express semantic connections like similarity or equivalence relationships for example. In business environment, data interlinking practice is highly recommended for lowering technological and cost barriers of data aggregation processes. In fact, semantic links between data nuggets from separate corporate sources, be they internal or external, facilitate the reconciliation processes between data references, enhance semantic enrichment procedures of data like for example propagating annotations from similar references to incomplete data, etc.
In the context of enterprises, the LOD paradigm opens new scientific and technical challenges to answer emerging semantic requirements in business data integration. The impact of LOD in enterprises can be measured by the deep change that such an approach brings in strategic enterprise processes like domain data workflows. In fact, semantic enrichment and data interlinking contribute to optimize business data lifecycle as they shorten the data integration time and cost. Moreover, when data is semantically managed from its source, i.e. from its acquisition or creation, less time and efforts are required to process and integrate it in business applications. This semantic management implies a set of procedures and techniques like data identification as resources using uris, metadata annotations using w3c standards, interlink with other data preferably from authority sources or domain taxonomies, etc.
On the other hand, LOD techniques foster the creation of advanced data applications and services by mashing up various heterogeneous content and data:
-
from internal sources like crm, erp, dbms, filesystems;
-
from external sources like emails, web sources, social networks, forums.
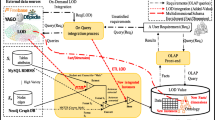
As a consequence, new perspectives are open to offer innovative channels to consume, exploit and monetize business data and assets. To understand the rationale behind this new perspectives, Fig. 1 depicts a generic enterprise semantic data lifecycle from the acquisition to the final consumption.

Data workflow in enterprise application
2 The Landscape of Enterprise and Corporate Data Today
Data integration and the efficient use of the available information in a business context are major challenges. A typical enterprise has critical applications from different vendors running on various technologies, platforms and communicating via different routes and protocols within and outside an Enterprise. These applications create disparate data sources, data silos and introduce enormous costs. To manage this complexity, an enterprise it eco-system is viewed as a set of interconnected (or partially connected) applications managing different processes of the enterprise, where separation of the applications often means replication of the same data in different forms. Each process manipulates different kinds of data and produces new data in a structured or unstructured fashion as it is depicted in Fig. 2.

Classical Enterprise Information System
Existing technological approaches such as Enterprise Application Integration (eai) create middleware between all these diverse information sources making use of several architectural models with examples being Event Driven Architecture (eda) or Service Oriented Architecture (soa) which are usually implemented with web services and soap. Common approaches in the enterprises typically include Data Warehousing and Master Data Management.
Simple xml messages and other b2b standards ensure the “flow” of information across internal systems in an easy-to-use and efficient manner. In some cases this is enough but, for example, with a portfolio of over 30,000 offered products and services it is not possible to describe complex components with a handful of simple xml elements. There is a clear need for providing clear definitions or semantics to the data to facilitate integration at the data layer.
However, integration in the data layer is far from being a straightforward task and the Linked Data paradigm provides a solution to some of the common problems in data integration. The two technological approaches, i.e. eai and LOD, are not contradictory but rather complementary. soa architecture deployed in an eai approach works with service oriented whereas LOD works with hyperlinked resources (data, data sets, documents, ...). Note that soa architecture needs many custom services where LOD uses only a few services (sparql, rest) and hyperlinking with the referenced resources. Both approaches have complementary standardization efforts (on metadata vs. services) which makes them better suited for different tasks. eai-soa approach is well suited for well-defined tasks on well-defined service data whereas LOD is more targeted for innovative tasks involving semantics (integrations, mappings, reporting, etc.).
3 Why Should My Company Assets Go Linked Open Data?
The benefit of the adoption of Linked Data technologies in enterprises is multidimensional:
-
address the problem of data heterogeneity and integration within the business;
-
create value chains inside and across companies;
-
meaning on data enables search for relevant information;
-
increase value of existing data and create new insights using bi and predictive analytics techniques;
-
Linked Data is an add-on technology which means no need to change the existing infrastructure and models;
-
get a competitive advantage by being an earlier adaptor of LOD technologies.
These benefits are better detailed in Fig. 3 taken from Deloitte report “Open data: Driving growth, ingenuity and innovation”Footnote 1.

Benefits for businesses to go LOD
4 LOD Enterprise Architectures
When adopting LOD principles, the Classical Enterprise it Architecture (Fig. 2) is enhanced for working over the Internet with means to overcome the technical barriers of the format and semantic differences of exchanged and manipulated data. This generates a data processing workflow that is described in the following three figures:
-
1.
Figure 4 evolves the legacy or classic architecture by replacing the Enterprise Software Bus (esb) with Linked Open Data protocols for data published on an external server.
-
2.
Figure 5 evolves the legacy or classic architecture by replacing the Enterprise Software Bus with Linked Open Data protocols among the enterprise LOD publishing servers.
-
3.
Figure 6 zooms-in on a publishing workflow, a transformation pipeline that is added on top of the legacy enterprise services (crm, erp, ...). Some legacy systems may evolve and upgrade to include LOD publishing or they may provide feeds into the LOD publishing workflow.

LOD Enterprise Architecture

LOD Enterprise Integration Architecture

Transformation pipeline
4.1 LOD Enterprise Architecture with a Publishing Workflow
Figure 4 illustrates the LOD Enterprise architecture where the middleware framework (esb) of the Classical it architecture (Fig. 2) is replaced with the LOD cloud. This architecture shows two types of data publishing, with the enterprise putting their rdf data on an external LOD server (server 5 in Fig. 4) according to one of two scenarios:
-
1.
An rdf data set is produced from various data sources and subsystems (box 1 in Fig. 4) and is transferred to an external central LOD server.
-
2.
Metadata is added to a classic web site using semantic metadata annotations (e.g. rdfa, Schema.org) on the html pages (box 3 in Fig. 4). An LOD server extracts this metadata, organizes it and makes it accessible as a central service (box 4 in Fig. 4).
The Ontology Schema Server (box 2 in Fig. 4) hosts the used ontologies capturing the semantics of the Linked Open Data. It may be standard (preferred) or custom designed. Other application services or platforms (server 4 in Fig. 4) may use the central LOD services to build specific calculations and reports. Business niches or completely new business opportunities can be created with visualizations and aggregations of data.
Example
A head-hunter can crawl job postings and match with cvs. Aggregations of offered vacancies in real-estates can create new insights. Search engines may use the data for advanced searching while portalsFootnote 2 can harvest data sets from other portals and publish them from a single point of access in a LOD server (server 5 in Fig. 4).
4.2 LOD Enterprise Architecture Integration
In the previous LOD Enterprise Architecture (Fig. 4 on p. 160) the business operations are described where Linked Data were produced or semantic annotations were made to the corporate content. The data produced (or extracted from crawling through websites) was not published by the enterprise but was made available to the community. Any external LOD server could be used for the publishing of the data, depending on the needs and requirements of the re-users.
In Fig. 5 the highlight is put on the operation of an enterprise that publishes its own data on a LOD server. Furthermore, the enabled integration is illustrated between various networks whether they belong to different branches of the same enterprise or entirely different companies. Figure 5 on p. 160 shows two company owned LOD publishing services (box 1 and 3 in Fig. 5). The published rdf is put on the company owned (corporate or enterprise) server platform. Other application services or platforms (server 4 in Fig. 5) may use the owned LOD services to build specific calculations and reports. Such application services may be on a dedicated external platform or they may be on one or more of the corporate owned LOD platforms/end-points. The Ontology Schema Server (box 2 in Fig. 5) hosts the used ontologies capturing the semantics of the Linked Open Data. It may be standard (preferred) or custom designed.
4.3 Transformation Pipeline to LOD Enterprise Architecture
The implementation of the previously described types of LOD architectures (shown in Figs. 4 and 5) is based on a transformation pipeline that is added on top of the legacy enterprise services (e.g. crm, erp, etc.). The pipeline includes:
-
1.
Identification of the types of data which are available, i.e. separate data into public and private and define access security strategy, identify data sources, design retrieval procedures, setting data versions, provide data provenance;
-
2.
Modelling with domain-specific vocabularies;
-
3.
Designing the uri Strategy for accessing the information, i.e. how the model and associated data should be accessed;
-
4.
Publishing the data which includes extraction as rdf, storage and querying;
-
5.
Interlinking with other data.
5 Best Practices
5.1 Data Sources Identification
Corporate information can be defined as the data that is used and shared by the different employees, departments, processes (it or not) of a company. Depending on the information security policy, corporate data can be accessed, processed and published via different business applications of the enterprise it system. Note that it may be spread across different locations (internal departments and entities, regional or cross countries subsidiaries, etc.).
When integrating LOD technologies into an existing enterprise it system or application, the first recommendation is to perform an audit on the different business data sources used by the company. This audit should include the following elements:
-
Classification of business data sources according to their importance to the operation of strategic business processes.
-
Cartography of data workflow between the identified data sources to discover missing, redundant or incomplete information exchanged, the type of data (structured, unstructured), etc.
-
Mapping table between native business data formats and the corresponding standard formats (preferably w3c rdf like formats) and the impact from shifting from the native to the standard format.
This audit allows the data architects to better understand the corporate applications’ functioning and help them evaluating the cost of integrating LOD technology. According to the required effort and cost, the first best practice consists on migrating as much as possible native formats to standards, preferably rdf-like w3c standards when possible. This considerably eases the publishing, annotation and interlinking of business data.
To comply with the openness criterion of LOD paradigm, publishing data is a major recommendation in the “LODification” process of corporate data. To do so, a licensing scheme must be released to define how the opened data can be reused and exploited by third-party users, applications and services. Considering the company interest, a compromise must be found to open as much data as possible and maintaining a good balance between keeping strategic enterprise data confidential, like the know-how for example, and the rest of data open. Lot of reusable licensing schemes can be considered.
Last but not least, the opened data license scheme must guarantee the reuse principle of data by third-party applications with as few technical, financial and legal restrictions as possible. One way of achieving these goals is to provide rich metadata descriptions of the opened data with appropriate vocabularies, like DCATFootnote 3, VoIDFootnote 4, DublinCoreFootnote 5, etc. To make the opened and published data understandable and retrievable, the metadata description must provide key elements like the copyright and associated license, update frequency of data, publication formats, data provenance, data version, textual description of the data set, contact point when necessary to report inconsistencies or errors for example, etc.
5.2 Modelling for the Specific Domain
In order to transform the existing model of an enterprise to a more interoperable schema, best practices focus on the use of common vocabularies. Using terms of existing vocabularies is easier for the publisher and contributes a lot in the re-use and the seamless information exchange of enterprise data.
As a first step, the inherent structure of the legacy data has to be analysed. If no specified hierarchy exists, it can often be created based on expert knowledge of the data. If such an organization of the data is not possible, then only a list of concepts, basically a glossary, can be constructed. Depending on the complexity of the data and how the entities are related, different data schemas can be used to express them.
5.3 Migration of Legacy Vocabularies
The migration of an existing vocabulary to an rdf scheme varies in complexity from case to case, but there are some steps that are common in most situations. Transforming enterprise data to rdf requires:
-
Translating between the source model and the rdf model is a complex task with many alternative mappings. To reduce problems, the simplest solution that preserves the intended semantics should be used.
-
The basic entity of rdf is a resource and all resources have to have a unique identifier, a uri in this case. If the data itself does not provide identifiers that can be converted to URIs, then a strategy has to be developed for creating uri for all the resources that are to be generated (see Sect. 5.4).
-
Preserve original naming as much as possible. Preserving the original naming of entities results in clearer and traceable conversions. Prefix duplicate property names with the name of the source entity to make them unique.
-
Use xml support for data-typing. Simple built-in xml Schema datatypes such as xsd:date and xsd:integer are useful to supply schemas with information on property ranges.
-
The meaning of a class or property can be explicated by adding an “
 ”, preferably containing a definition from the original documentation. If documentation is available online, “
”, preferably containing a definition from the original documentation. If documentation is available online, “ ” or “
” or “ ” statements can be used to link to the original documentation and/or definition.
” statements can be used to link to the original documentation and/or definition.
 ”, preferably containing a definition from the original documentation. If documentation is available online, “
”, preferably containing a definition from the original documentation. If documentation is available online, “ ” or “
” or “ ” statements can be used to link to the original documentation and/or definition.
” statements can be used to link to the original documentation and/or definition.Domain specific data, can be modelled with vocabularies like OrgFootnote 6 or GoodRelationsFootnote 7. Only when existing vocabularies do not cover ones needs new schemas should be developed. Data sets that will be published on the web should be described with metadata vocabularies such as VoiD, so that people can learn what the data is about from just looking at its content.
Where suitable vocabularies to describe the business data do not exist, one possibility is to develop a skos thesaurus instead of an rdfs model (e.g. taxonomies, organizations, document types). This approach is easier to follow for organisations new to rdf. Tools such as PoolPartyFootnote 8 exist and support users in such a task. The most recent international standard regarding thesaurus development is the ISO 25964Footnote 9. This standard provides detailed guidelines and best practices that interested readers should consider.
Once the data is in this format it can be loaded in a triple store like Virtuoso and published internally or on the web.
5.4 Definition of the uri Strategy
To meet high quality standards for managing business data, a company must define a persistent data representation policy for identifying each data item from the enterprise data universe. Such a policy must include the addressing schemes for locating data resources within the enterprise space. An uri Footnote 10 is a relevant mechanism for defining a global representation scheme of the enterprise business data space.
Identification of Business Items as Resources Referenced by uri s
The first recommendation in building a coherent and persistent representation policy is to identify business data items as resources, which can be individually referenced. To conform to the LOD principles, uris should be used as the identification mechanism for referencing the business information resources.
Use HTTP/DNS Based uri s
A uri is a mechanism that can be used for identifying different objects and concepts. Some of these objects and concepts may have a physical existence like books for example with ISBN, web page with URL locations. Other concepts are abstract and represent conceptual things like ontology concepts or data items. Different schemes of uris exist for representing a resource: uris based on dns (Domain Name Server) names, ark (Archival Resource Key) and uris based on names and ids like isbn (International Standard Book Number), doi (Digital Object Identifiers), Barcodes, etc. Some of the schemes described above can be inadequate to implement basic Linked Open Data features like publishing, referencing and interlinking. Therefore, it is strongly recommended to use uris based on http protocol and dns names (like urls and ark) to ensure visibility, accessibility and reuse of business items in external applications and to third party users.
Use De-referenceable uri s
Human users associate mechanically http based uris to urls and expect to have a web page when pasting a uri into a browser address bar. Unfortunately, the association of a uri to a web page is not always true and automatic. For some businesses, such a situation may generate confusion and frustration. To avoid such misunderstanding, it is highly recommended to provide means to have “dereferenceable” and resolvable uris, i.e. uris that return meaningful responses when pasted into a browser’s address bar. A typical meaningful response could be an html page containing a complete or partial description, including the properties of the corresponding resource.
Separate Resource and Resource Representation
Making business items accessible and dereferenceable through the http protocol may generate a conceptual confusion between the resource itself and the document describing it (the html answer for example when requesting the resource over http). The resource itself as a business data item should be identified by a uri that is different from the possible representations that one could generate to describe the resource (an html, rdf, xml or json description document, a document in a given language, a document using a given technology: php, html, etc.). w3c proposes two technical solutions to avoid the previous confusion: use of hash uris and use of 303 uris:
-
Hash uris - This solution consists in using fragment uris to reference a non-document business resource. A fragment uri is a uri that separates the resource identifier part from the DNS server path location part using the hash symbol ‘#’. For example, a book reference 2-253-09634-2 in a library business application could be dissociated from its description using a hash uri as follows: http://www.mylibrary.com/books/about#2-253-09634-2. With this example, the library can manage a repository of books in one single big rdf file containing all the books references and their properties. When accessing 2-253-09634-2 book, a selection query can be applied on that rdf document to extract the rdf fragment corresponding to 2-253-09634-2 triples. The http server managing the de-referencement of uris will apply business specific rules to render the rdf fragment in the desired technology (as json, html, xml, etc.).
-
303 uris - This solution consists in implementing a redirection mechanism represented by the http response code 303 to indicate that the resource has been identified and the server is redirecting the request to the appropriate description option. In the example of the library, the uri could be http://www.mylibrary.com/books/2-253-09634-2. The http server will answer to the request of that uri by a redirect (
 ) to a new location; let’s say http://www.library.com/books/2-253-09634-2.about.html, to provide the description of the requested resource.
) to a new location; let’s say http://www.library.com/books/2-253-09634-2.about.html, to provide the description of the requested resource.
 ) to a new location; let’s say
) to a new location; let’s say Both techniques have advantages and drawbacks as discussed by Sir Tim Berners Lee here: http://www.w3.org/Provider/Style/URI. Whereas hash uri technique may look restrictive due to the same root part uri (before the hash) for different resources, the 303 uri technique introduces latency in requests due to the redirection mechanism.
Design Cool uri s
On the conceptual design side of uris, Sir Tim Berners Lee proposes the notion of Cool uris to guarantee that uris are maintainable, persistent and simple (see http://www.w3.org/TR/cooluris/). To ensure sustainable uris, it is important to design a “cool” uri scheme that doesn’t change over time. To do so one has to follow these basic rules, resumed in Fig. 7:
-
Make the uri independent from the underlying technology used to generate or describe the resource. This means avoid extensions such as .php, .cgi and .html in the uri path. To know what to return when a resource is requested (without any extension), it is recommended to implement a content negotiation mechanism in the http server that is able to outstream the appropriate content.
-
Make also the uri independent of the physical location of the file describing the resource. Never forget that physical locations are subject to change.
-
Make sure that resource metadata are not included in the uri because of their evolution over time. In other words, one has to not encode the following in the uri the authorship, the status of the resource (final, old, latest, etc.), the access rights (public, private, etc.) since this may change over time.

URI Design rules
Opaque vs. Non opaque uri s
Designing mnemonic and readable uris for identifying business resources can help human users to get preliminary knowledge on the targeted item. However, from a business point of view, this readability may have side effects if it also reveals an internal organisation system structure. Non Opaque uri may reveal conceptual structure but never should reveal physical or logical data structures. In fact, third party users or external applications can attempt to hack the uri scheme, reverse engineer all business resources and abuse the access to some strategic assets. When there are security risks, it is recommended to use opaque uris instead of readable ones. An opaque uri is a uri conforming to a scheme that satisfies the following conditions:
-
Addressable and accessible resources should be referenced by identifiers instead of human readable labels.
-
The resource uri should not contain explicit path hierarchy that can be hacked to retrieve sibling resources for example.
-
The uri content should not provide means to gain information on the referenced resource, i.e., a third party client cannot analyse the uri string to extract useful knowledge on the resource.
For non-opaque uri, only the first constraint is not followed.
5.5 Publishing
Publishing procedures in Linked Data follows the identification of data sources and the modelling phase and actually refers to the description of the data as rdf and the storing and serving of the data. A variety of tools have been created to assist the different aspects of this phase from different vendors and include a variety of features. According to the needs of each specific business case and the nature of the original enterprise data, shorter publishing patterns can be created.
5.5.1 Publishing Pattern for Relational Data
Relational databases (rdb) are the core asset in the existing state-of-art of data management and will remain a prevalent source of data in enterprises. Therefore the interest of the research communityFootnote 11 \(^{,}\) Footnote 12 has gathered around the development of mapping approaches and techniques in moving from rdb to rdf data. These approaches will enable businesses to:
-
Integrate their rdb with another structured source in rdb, xls, csv, etc. (or unstructured html, pdf, etc.) source, so they must convert rdb to rdf and assume any other structured (or unstructured) source can also be in rdf.
-
Integrate their rdb with existing rdf on the web (Linked Data), so they must convert to rdf and then be able to link and integrate.
-
Make their rdb data to be available for sparql or other rdf-based querying, and/or for others to integrate with other data sources (structured, rdf, unstructured).

rdb2rdf publishing pattern
Two key points should be taken into consideration and addressed within the enterprise (see Fig. 8):
Definition of the Mapping Language from RDB2RDF
Automatic mappings provided by tools such as d2r Footnote 13 and Virtuoso rdf Views provide a good starting point especially in cases when there is no existing Domain Ontology to map the relational schema to. However, most commonly the manual definition of the mappings is necessary to allow users to declare domain-semantics in the mapping configuration and take advantage of the integration and linking facilities of Linked Data. r2rml Footnote 14, a w3c recommendation language for expressing such customized mappings, is supported from several tools including Virtuoso rdf Views and d2r.
Materializing the Data
A common feature of rdb2rdf tools is the ability to create a “semantic view” of the contents of the relational database. In these cases, an rdf version of the database is produced so that content can be provided through a sparql endpoint and a Linked Data interface that works directly on top of the source relational database, creating a virtual “view” of the database. Such a “semantic view” guarantees up-to-date access to the source business data, which is particularly important when the data is frequently updated. In contrast, generating and storing rdf requires synchronization whenever either the source data model, the target rdf model, or the mapping logic between them changes. However, if business decisions and planning require running complicated graph queries, maintaining a separate rdf store becomes more competitive and should be taken under consideration.
5.5.2 Publishing Pattern for Excel/CSV Data
When the original data reside in Excel or CSV format, describing them with rdf would be a first step of a publishing pattern while hosting and serving it on the Web follows. LODRefine is a stack component, well-suited to automating and easing the “RDFizing” procedure. Usage brings direct added business value:
-
powerful cleaning capabilities on the original business data.
-
reconciliation capabilities, in case it is needed, to find similar data in the LOD cloud and make the original business data compatible with well-known Linked Data sources.
-
augmenting capabilities, where columns can be added from DBpedia or other sources to the original data set based on the previous mentioned reconciliation services.
-
extraction facilities when entities reside inside the text of the cells.
5.5.3 Publishing Pattern for xml Data
When the original data is in xml format an xslt transformation to transform the xml document into a set of rdf triples is the appropriate solution. The original files will not change; rather a new document is created based on the content of the existing one. The basic idea is that specific structures are recognized and they are transformed into triples with a certain resource, predicate and value. The LOD2 stack supports xml to rdf/xml xslt transformations. The resulting triples are saved as an rdf/xml graph/file that can follow the same hosting and serving procedures explained in the previous section.
5.5.4 Publishing Pattern for Unstructured Data
Despite the evolution of complex storage facilities, the enterprise environment is still a major repository paradigm for unstructured and semi-structured content. Basic corporate information and knowledge is stored in a variety of formats such as pdf, text files, e-mails, classic or semantic annotated websites, may come from Web 2.0 applications like social networks or may need to be acquired from specific web API’s like GeonamesFootnote 15, FreebaseFootnote 16 etc. Linked Data extraction and instance data generation tools maps the extracted data to appropriate ontologies en route to produce rdf data and facilitate the consolidation of enterprise information. A prominent example of a tool from the LOD2 stack that facilitate the transformation of such types of data to rdf graphs is Virtuoso Sponger.
Virtuoso SpongerFootnote 17 is a Linked Data middleware that generates Linked Data from a big variety of non-structured formats. Its basic functionality is based on Cartridges, that each one provides data extraction from various data source and mapping capabilities to existing ontologies. The data sources can be in rdfa formatFootnote 18, GRDDL Footnote 19, Microsoft Documents, and MicroformatsFootnote 20 or can be specific vendor data sources and others provided by API’s. The Cartridges are highly customizable so to enable generation of structured Linked Data from virtually any resource type, rather than limiting users to resource types supported by the default Sponger Cartridge collection bundled as part of the Virtuoso Sponger.
The PoolParty Thesaurus ServerFootnote 21 is used to create thesauri and other controlled vocabularies and offers the possibility to instantly publish them and display their concepts as html while additionally providing machine-readable rdf versions via content negotiation. This means that anyone using PoolParty can become a w3c standards compliant Linked Data publisher without having to know anything about Semantic Web technicalities. The design of all pages on the Linked Data front-end can be controlled by the developer who can use his own style sheets and create views on the data with velocity templates.
DBpedia SpotlightFootnote 22 is a tool for automatically annotating mentions of DBpedia resources in text, providing a solution for linking unstructured information sources to the Linked Open Data cloud through DBpedia. DBpedia Spotlight recognizes that names of concepts or entities have been mentioned. Besides common entity classes such as people, locations and organisations, DBpedia Spotlight also spots concepts from any of the 320 classes in the DBpedia Ontology. The tool currently specializes in English language, the support for other languages is currently being tested, and it is provided as an open source web service.
StanbolFootnote 23 is another tool for extracting information from CMS or other web application with the use of a Restful API and represents it as rdf. Both Dbpedia Spotlight and Stanbol support NIF implementation (NIF will soon become a w3c recommendation) to standardise the output rdf aiming on achieving interoperability between Natural Language Processing (NLP) tools, language resources and annotations.
5.5.5 Hosting and Serving
The publishing phase usually involves the following steps:
-
1.
storing the data in a Triple Store,
-
2.
make them available from a sparql endpoint,
-
3.
make their uris dereferenceable so that people and machines can look them up though the Web, and
-
4.
provide them as an rdf dump so that data can easily be re-used.
The first three steps can be fully addressed with a LOD2 stack component called Virtuoso, while uploading the rdf file to CKANFootnote 24 would be the procedure to make the rdf public.
OpenLink Virtuoso Universal Server is a hybrid architecture that can run as storage for multiple data models, such as relational data, rdf, xml, and text documents. Virtuoso supports a repository management interface and faceted browsing of the data. It can run as a Web Document server, Linked Data server and Web Application server. The open source version of Virtuoso is included in the LOD2 stack and is widely used for uploading data in its Quad store, it offers a sparql endpoint and a mechanism called URL-Rewriter to make uris dereferenceable.
According to the fourth step, sharing the data in a well-known open datahub such as CKAN will facilitate their discovery from other businesses and data publishers. The functionality of CKAN is based on packages where data sets can be uploaded. CKAN enables also updates, keeps track of changes, versions and author information. It is advised as good practice to accompany the data sets with information files (e.g. VOID file) that contain relevant metadata (Figs. 9, 10).

Publishing pattern for registering data sets
5.6 Interlinking - The Creation of 5-Star Business Data
5-Star business dataFootnote 25 refers to Linked Open Data, the 5 stars being:
-
1.
data available on the web with an open-data license,
-
2.
the data is available in a machine readable form,
-
3.
the machine readable data is in a non-proprietary form (e.g. CSV),
-
4.
machine readable, non-proprietary using open standards to point to things,
-
5.
all the above, linked with other data providing context.

5 star data
To get the full benefits of linked data with the discovery of relevant new data and interlinking with it, requires the 5\(^{th}\) star, but that does not mean that benefits are not derived from the Linked Data approach before that point is reached. A good starting point can be business registers such as OpencorporatesFootnote 26 or UK Companies HouseFootnote 27 that contain the metadata description of other companies. The discovery of more related business data can further be facilitated with Linked Data browsers and search engines like SigmaEEFootnote 28. However, the implementation of interlinking between different data sources is not always a straightforward procedure. The discovery of joint points and the creation of explicit rdf links between the data in an automated way can be supported with tools both included in the Interlinking/Fusion LOD2 life cycle.
The process that is referred to as interlinking is the main idea behind the Web of Data and leads to the discovery of new knowledge and their combinations in unforeseen ways. Tools such as silk Footnote 29 offer a variety of metrics, transformation functions and aggregation operators to determine the similarity of the compared rdf properties or resources. It operates directly on sparql endpoints or rdf files and offers a convenient user interface namely Silk Workbench.
5.7 Vocabulary Mapping
Sometimes, an enterprise may need to develop a proprietary ontology when applying Linked Data principles. Mapping the terms that were used for publishing the triples with terms in existing vocabularies will facilitate the use of the enterprise data from third-party applications. A tool that supports this kind of mapping is r2r Footnote 30.
r2r searches the Web for mappings and apply the discovered mappings to translate Web data to the application’s target vocabulary. Currently it provides a convenient user interface that facilitates the user in a graphical way to select input data from a sparql endpoint as well as from rdf dumps, create the mappings and write them back to endpoints or rdf files.
6 Conclusion
In this chapter, we discussed the best practices to deploy in an enterprise application to ensure a full LOD paradigm compliant semantic dataflow. We also saw that deploying LOD tools and procedures does not necessary requires to start the IT design from scratch but can be deployed on top of existing applications. This guarantees low cost deployment and integration.
Notes
- 1.
- 2.
Such as ODP: http://open-data.europa.eu/en/data/
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
Uniform Resource Identifier: RFC3986 http://tools.ietf.org/html/rfc3986
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
This chapter is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
Copyright information
© 2014 The Author(s)
About this chapter
Cite this chapter
Mezaour, AD., Van Nuffelen, B., Blaschke, C. (2014). Building Enterprise Ready Applications Using Linked Open Data. In: Auer, S., Bryl, V., Tramp, S. (eds) Linked Open Data -- Creating Knowledge Out of Interlinked Data. Lecture Notes in Computer Science(), vol 8661. Springer, Cham. https://doi.org/10.1007/978-3-319-09846-3_8
Download citation
DOI: https://doi.org/10.1007/978-3-319-09846-3_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-09845-6
Online ISBN: 978-3-319-09846-3
eBook Packages: Computer ScienceComputer Science (R0)