
Abstract
Formal verification provides a rigorous and systematic approach to ensure the correctness and reliability of software systems. Yet, constructing specifications for the full proof relies on domain expertise and non-trivial manpower. In view of such needs, an automated approach for specification synthesis is desired. While existing automated approaches are limited in their versatility, i.e., they either focus only on synthesizing loop invariants for numerical programs, or are tailored for specific types of programs or invariants. Programs involving multiple complicated data types (e.g., arrays, pointers) and code structures (e.g., nested loops, function calls) are often beyond their capabilities. To help bridge this gap, we present AutoSpec, an automated approach to synthesize specifications for automated program verification. It overcomes the shortcomings of existing work in specification versatility, synthesizing satisfiable and adequate specifications for full proof. It is driven by static analysis and program verification, and is empowered by large language models (LLMs). AutoSpec addresses the practical challenges in three ways: (1) driving AutoSpec by static analysis and program verification, LLMs serve as generators to generate candidate specifications, (2) programs are decomposed to direct the attention of LLMs, and (3) candidate specifications are validated in each round to avoid error accumulation during the interaction with LLMs. In this way, AutoSpec can incrementally and iteratively generate satisfiable and adequate specifications. The evaluation shows its effectiveness and usefulness, as it outperforms existing works by successfully verifying 79% of programs through automatic specification synthesis, a significant improvement of 1.592x. It can also be successfully applied to verify the programs in a real-world X509-parser project.
You have full access to this open access chapter, Download conference paper PDF
1 Introduction
Program verification offers a rigorous way to assuring the important properties of a program. Its automation, however, needs to address the challenge of proof construction [1, 2]. Domain expertise is required for non-trivial proof construction, where human experts identify important program properties, write the specifications (e.g., the pre/post-conditions, invariants, and contracts written in certain specification languages), and then use these specifications to prove the properties.
Despite the immense demand for software verification in the industry [3,4,5,6,7], manual verification by experts remains the primary approach in practice. To reduce human effort, automated specification synthesis is desired. Ideally, given a program and a property to be verified, we expect the specifications that are sufficient for a full proof could be synthesized automatically.
Research gap – Prior works are limited in versatility, i.e., the ability to simultaneously handle different types of specifications (e.g., invariants, preconditions, postconditions), code structures (e.g., multiple function calls, multiple/nested loops), and data structures (e.g., arrays, pointers), leaving room for improvement towards achieving full automation in proof construction. Existing works focus only on loop invariants [8,9,10], preconditions [11, 12], or postconditions [13,14,15]. Moreover, most works on loop invariant synthesis can only handle numerical programs [2, 16,17,18] or are tailored for specific types of programs or invariants [19,20,21,22,23,24]. To handle various types of specifications simultaneously and to process programs with various code and data structures, a versatile approach is required.
Challenges – Although the use of large language models (LLMs) such as ChatGPT may provide a straightforward solution to program specification generation, it is not a panacea. The generated specifications are mostly incorrect due to three intrinsic weaknesses of LLMs. First, LLMs can make mistakes. Even for the well-trained programming language Python, ChatGPT-4 and ChatGPT-3.5 only achieve 67.0% and 48.1% accuracy in program synthesis [25]. In comparison with programming languages, LLMs are much less trained in specification languages. Therefore, LLMs generally perform worse in synthesizing specifications than programs. Since the generated specifications are error-prone, we need an effective technique to detect incorrect specifications, which are meaningless to verify. Second, LLMs may not attend to the tokens we want them to. Self-attention may pay no, less, or wrong attention to the tokens that we want it to. Recent research even pointed out a phenomenon called “lost in the middle” [26], observing that LLMs pay little attention to the middle if the context goes extra long. In our case, the synthesized specifications are desired to capture and describe as many program behaviors as possible. Directly adopting the holistic synthesis (i.e., synthesizing all specifications at once) may yield unsatisfactory outcomes. Third, errors accumulate in the output of LLMs. LLMs are auto-regressive. If they make mistakes, these wrong outputs get added to their inputs in the next round, leading to way more wrong outputs. It lays a hidden risk when taking advantage of LLMs’ dialogue features, especially in an incremental manner (i.e., incrementally synthesizing specifications based on previously generated ones).
Insight – To address the above challenges, our key insight is to let static analysis and program verification take the lead, while hiring LLMs to synthesize candidate specifications. Static analysis parses a given program into pieces, and passes each program piece in turn to LLMs by inserting a placeholder in it. Paying attention to the spotted part, LLMs generate a list of specifications as candidates. Subsequently, a theorem prover validates the generated specifications and keeps the validated ones in the next round of synthesis. The iteration process terminates when the property under verification has been proved, or the iteration reaches a predefined limit.
Solution – Bearing the insight, we present AutoSpec, an LLM-empowered framework for generating specifications. It tackles the three above-mentioned limitations of directly adopting LLM in three perspectives. First, it decomposes the program hierarchically and employs LLMs to generate specifications incrementally in a bottom-up manner. This allows LLMs to focus on a selected part of the program and generate specifications only for the selected context. Thus, the limitation of context fragmentation could be largely alleviated. Second, it validates the generated specifications using theorem provers. Specifications that are inconsistent with programs’ behaviors and contradict the properties under verification will be discarded. This post-process ensures that the generated specifications are satisfiable by the source code and the properties under verification. Third, it iteratively enhances the specifications by employing LLMs to generate more specifications until they are adequate to verify the properties under verification or the number of iterations reaches the predefined upper bound.
We evaluate the effectiveness of AutoSpec by conducting experiments on 251 C programs across four benchmarks, each with specific properties to be verified. We compare AutoSpec with three state-of-the-art approaches: Pilat, Code2inv, and CLN2Inv. The result shows AutoSpec can successfully handle 79% (= 199 / 251) programs with various structures (e.g., linear/multiple/nested loops, arrays, pointers), while existing approaches can only handle programs with linear loops. As a result, 59.2% (= (199 – 125) / 125) more programs can be successfully handled by AutoSpec. The result also shows that AutoSpec outperforms these approaches’ effectiveness and expressiveness when accurately inferring program specifications. To further indicate its usefulness, we apply AutoSpec to a real-world X509-parser project, demonstrating its ability to automatically generate satisfiable and adequate specifications for six functions within a few minutes. Also, the ablation study reveals that the program decomposition and the hierarchical specification generation components contribute most to performance improvement. This paper makes the following contributions:
-
Significance. We present an automated specification synthesis approach, AutoSpec, for program verification. AutoSpec is driven by static analysis and program verification, and empowered by LLMs. It can synthesize different types of specifications (e.g., invariants, preconditions, postconditions) for programs with various structures (e.g., linear/multiple/nested loops, arrays, pointers).
-
Originality. AutoSpec tackles the practical challenges for applying LLMs to specification synthesis: It decomposes the programs hierarchically to lead LLMs’ attention, and validates the specifications at each round to avoid error accumulation. By doing so, AutoSpec can incrementally and iteratively generate satisfiable and adequate specifications to verify the desired properties.
-
Usefulness. We evaluate AutoSpec on four benchmarks and a real-world X509-parser. The four benchmarks include 251 programs with linear/multiple/nested loops, array structures, pointers, etc.. AutoSpec can successfully handle 79% of them, 1.592x outperforming existing works. The experiment result shows the effectiveness, expressiveness, and generalizability of AutoSpec.

ACSL Annotations to Functional Proof of Bubble Sort
2 Background and Motivation
Listing 1 illustrates a C program that implements the bubble sort (sorting a 5000-element array of integers in ascending order), where the property to be verified (line 48) prescribes that after sorting, any index i between 1 and 4999, the element at array[i-1] is no larger than the element at array[i]. To verify the property, we use a specification language for C programs, ACSL [27] (ANSI/ISO-C Specification Language) to write the proof. It appears in the form of code comments (annotated by
 or
or
 ) and does not affect the program execution. The ACSL-annotated program can be directly fed to auto-active verification tool (Frama-C [28] in this paper) to prove the properties (Fig. 1).
) and does not affect the program execution. The ACSL-annotated program can be directly fed to auto-active verification tool (Frama-C [28] in this paper) to prove the properties (Fig. 1).
In the running example, specifications in the program prescribe the preconditions (begin with
 ), postconditions (begin with
), postconditions (begin with
 ), and loop invariants (begin with
), and loop invariants (begin with
 )Footnote 1. To prove the property in line 48, practitioners usually write specifications in a bottom-up manner, that is, from line 47 tracing to bubbleSort (line 21), then from line 39, tracing to swap (line 10). Starting from swap, practitioners identify the inputs and outputs of the swap function and write the pre/post-conditions (lines 4–8). In particular, the precondition (lines 4–5) requires the two input pointers to be valid (i.e., they can be safely accessed), which is necessary to ensure the safe execution of the operations involving dereferencing. Additionally, the postcondition ensures that the values of *a and *b are swapped (lines 6–7) and assigned (line 8) during execution.
)Footnote 1. To prove the property in line 48, practitioners usually write specifications in a bottom-up manner, that is, from line 47 tracing to bubbleSort (line 21), then from line 39, tracing to swap (line 10). Starting from swap, practitioners identify the inputs and outputs of the swap function and write the pre/post-conditions (lines 4–8). In particular, the precondition (lines 4–5) requires the two input pointers to be valid (i.e., they can be safely accessed), which is necessary to ensure the safe execution of the operations involving dereferencing. Additionally, the postcondition ensures that the values of *a and *b are swapped (lines 6–7) and assigned (line 8) during execution.
Then tracing back to where swap is called, i.e., inside bubbleSort, it can be challenging because it contains nested loops. In a bottom-up manner, the inner loop of bubbleSort (lines 37–41) is first analyzed. In particular, to verify a loop, it is composed of (1) loop invariants (i.e., general conditions that hold before/during/after the loop execution, begin with
 ), and possibly (2) the list of assigned variables (begin with
), and possibly (2) the list of assigned variables (begin with
 ). In the example, practitioners analyze the inner loop and write specifications in lines 31–36. Specifically, the index j should fall into the range of 0 to n (line 32), the elements from index 0 to j are not larger than the element at j (line 33), and all elements from index 0 to i are smaller than or equal to the element at i+1 (line 34). Also, the variables to be assigned in this inner loop include j and first-i elements in the array (line 35). Similarly, for the outer loop (lines 30–42), lines 24–29 describe the range of index i (line 25), invariants (lines 26–27) and assigned variables (line 28).
). In the example, practitioners analyze the inner loop and write specifications in lines 31–36. Specifically, the index j should fall into the range of 0 to n (line 32), the elements from index 0 to j are not larger than the element at j (line 33), and all elements from index 0 to i are smaller than or equal to the element at i+1 (line 34). Also, the variables to be assigned in this inner loop include j and first-i elements in the array (line 35). Similarly, for the outer loop (lines 30–42), lines 24–29 describe the range of index i (line 25), invariants (lines 26–27) and assigned variables (line 28).
Finally, practitioners analyze bubbleSort (lines 21–43), identifying that the first-n elements of array can be safely accessed (line 17), n must be greater than zero (line 18). After execution, the array is in ascending order (line 19). Once all the specifications are written, they are fed into a prover/verification tool), Frama-C [28] which supports ACSL to verify the satisfiability (i.e., the specifications satisfy the program) and adequacy (i.e., the specifications are sufficient to verify the desired properties) of all specifications until the desired property verification succeeds. If the verification fails, practitioners debug and refine the specifications.
From this example, we can see that the manual efforts to write specifications are non-trivial. Even for a simple algorithm such as bubble sort. In practice, the program under verification could be on a far larger scale, which brings a huge workload to practitioners, motivating the automated specification synthesis.
Motivation – Existing related works can only synthesize loop invariants for programs with a single loop [2, 16] or multiple loops [29] on the numerical program. These approaches cannot generate satisfiable and adequate specifications to fully prove the correctness of basic programs such as bubble sort.
Motivated by the research gap, AutoSpec is presented. It synthesizes specification in a bottom-up manner, synthesizing versatile specifications (i.e., not only loop invariants, but also precondition, postcondition, and assigned variables, which are necessary for the full proof). It validates the satisfiability of specifications whenever specifications are synthesized, and verifies the adequacy of specifications after all specifications are synthesized.

User Scenario of AutoSpec
User Scenario – We envision the user scenario of AutoSpec in Fig. 2. Given a program and properties under verification, AutoSpec provides a fully automated verification process. It synthesizes the specifications for the program, validates the satisfiability of specifications, verifies the specifications against the desired properties, and outputs the verification result with proof if any.
Note that proof can be provided by AutoSpec if the program is correctly implemented (i.e., the properties can be verified). When the given program is syntactically buggy, the program reports the syntactic error at the beginning before launching AutoSpec. If the given program is semantically buggy, then AutoSpec cannot synthesize adequate specifications for verification, the synthesis terminates when the maximum iteration number is reached.

Overview of AutoSpec
3 Methodology
Figure 3 shows an overview of AutoSpec. The workflow comprises three main steps: ➊ Code Decomposition (Sect. 3.1). AutoSpec statically analyzes a C program by decomposing it into a call graph, where loops are also represented as nodes. The aim of the first step is to generalize the procedure that was previously discussed in Sect. 2 to include the implicit knowledge of simulating interactions between humans and verification tools. By decomposing the program into smaller components, LLMs can iteratively focus on different code components for a more comprehensive specification generation. ➋ Hierarchical specification generation (Sect. 3.2). Based on the call graph with loops, AutoSpec inserts placeholders in each level of the graph in a bottom-up manner. Taking the program in Listing 1 for example, AutoSpec inserts the first placeholder (
 ) before swap, and then inserts the second placeholder in the inner loop of Sort. Then, AutoSpec iteratively masks the placeholder one at a time with “
) before swap, and then inserts the second placeholder in the inner loop of Sort. Then, AutoSpec iteratively masks the placeholder one at a time with “
 ” and feeds the masked code into LLMs together with few-shot examples. After querying LLMs, they reply with a set of specifications. AutoSpec then fills the generated specifications into the placeholder and proceeds to the next one. Once all the placeholders are filled with LLM-generated specifications, AutoSpec proceeds to the next step. ➌ Specification Validation (Sect. 3.3). AutoSpec feeds the verification conditions of each generated specification into a theorem prover to verify their satisfiability. If the theorem prover confirms the satisfiability of the specifications, they will be annotated as a comment in the source code. Otherwise, if the theorem prover identifies any unsatisfiable specifications (i.e., cannot be satisfied by the program), AutoSpec removes those specifications and annotates program with the remaining specifications. Then, AutoSpec returns to the second step to insert additional placeholders immediately after the specifications generated in the previous iteration and generate more specifications. This iterative process continues until all the specifications are successfully verified by the prover or until the number of iterations reaches the predefined upper limit (in our evaluation, it is set to 5). We will explain the methodology of each step in detail.
” and feeds the masked code into LLMs together with few-shot examples. After querying LLMs, they reply with a set of specifications. AutoSpec then fills the generated specifications into the placeholder and proceeds to the next one. Once all the placeholders are filled with LLM-generated specifications, AutoSpec proceeds to the next step. ➌ Specification Validation (Sect. 3.3). AutoSpec feeds the verification conditions of each generated specification into a theorem prover to verify their satisfiability. If the theorem prover confirms the satisfiability of the specifications, they will be annotated as a comment in the source code. Otherwise, if the theorem prover identifies any unsatisfiable specifications (i.e., cannot be satisfied by the program), AutoSpec removes those specifications and annotates program with the remaining specifications. Then, AutoSpec returns to the second step to insert additional placeholders immediately after the specifications generated in the previous iteration and generate more specifications. This iterative process continues until all the specifications are successfully verified by the prover or until the number of iterations reaches the predefined upper limit (in our evaluation, it is set to 5). We will explain the methodology of each step in detail.
3.1 Code Decomposition
Using static analysis, AutoSpec constructs a comprehensive call graph for the given program to identify the specific locations where specifications should be added and determine the order in which these specifications should be added. This call graph is an extended version of the traditional one, where loops are also treated as nodes, in addition to functions. This is particularly useful for complex programs where loops can significantly affect the program’s behavior.
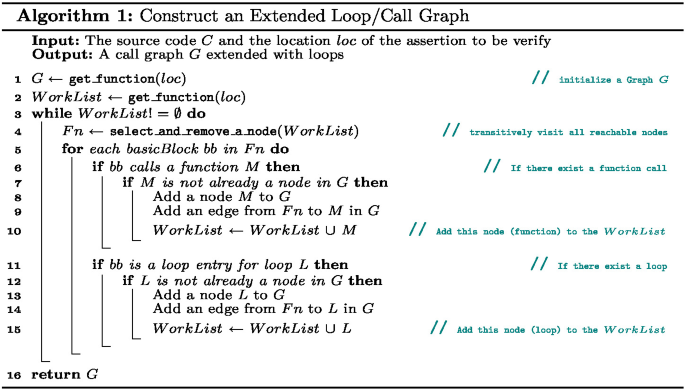
The algorithm for constructing such a call graph is shown in Algorithm 1. Specifically, the algorithm selects a function that contains the target assertion to be verified as the entry point for the call graph construction. Then, it traverses the abstract syntax tree (AST) of the source code to identify all functions and loops and their calling relationships. For instance, the extended call graph generated for the program in Listing 1 is given in Fig. 3(A).
Then, the specifications are generated step-by-step based on the nodes in the extended call graph. When generating the specification for a node, one only needs to consider the code captured by the node and the specifications of its callees in the extended call graph. Furthermore, modeling loops in addition to functions as separate nodes in the extended call graph allows AutoSpec to generate loop invariants, which are essential to program verification. Therefore, code decomposition allows LLMs to focus on small program components to generate specifications, thus reducing the complexity of specification generation and making it more manageable and efficient. And traversing the extended call graph from bottom to top can simulate the programmers’ verification process.
3.2 Hierarchical Specification Generation
AutoSpec generates specifications for each node in the extended call graph in a hierarchical manner. It starts from the leaf nodes and moves upward to the root node. This bottom-up approach ensures that the specifications for each function or loop are generated within the context of their callers. Algorithm 2 shows the algorithm of hierarchical specification generation. The algorithm takes as input an extended call graph G, an iteration bound t, a large language model, and the assertion to be verified; and outputs an annotated code C with generated specifications. In detail, the algorithm works as follows: First, the algorithm initializes a code template C with the original code without specifications (line 1). The code template, similar to Fig. 3(B), includes placeholders. Each placeholder corresponds to a node in the call graph. These placeholders will be iteratively replaced with the valid specifications generated by the LLMs and validated by the theorem prover, within a maximum of t iterations (line 2).
In each iteration, the algorithm performs the following steps. First, AutoSpec initializes a stack S with the root node of graph G, which is the target function containing the assertion to be verified (line 3). Second, AutoSpec pushes the nodes that require specification generation into the stack S and traverses the stack S in a depth-first manner (lines 4–15). For each node f in the stack, the algorithm checks if all the callees of f have their specifications generated in this iteration (lines 7–8). If not, the algorithm pushes the callee nodes into the stack and marks f as not ready for specification generation (lines 9–10). If all of the functions called by f have had their specifications generated, the algorithm will then proceed to generate the specifications for f. (lines 11–15). In particular, AutoSpec queries the LLMs to generate a set of candidate specifications \(spec_{tmp}\) for f (line 12), and validates \(spec_{tmp}\) by examining their syntactic and semantic validity. Any illegal or unsatisfiable specifications are eliminated, and the remaining valid specifications are referred to as \(spec_{f}\) (line 13). The validation process may employ existing provers/verification tools to guarantee soundness. Then, AutoSpec inserts the validated specifications into the source code C at the placeholder of f (line 14), and pops up the node f from the stack, indicating that f has its specification generated in this iteration (line 15). Third, AutoSpec examines whether the whole verification task has been completed, that is, whether the generated specifications are adequate to verify the target assertion (line 16). If it does, AutoSpec proceeds to simplify the annotated code C by eliminating redundant or unnecessary specifications (line 17) and then terminates (line 18). Otherwise, it is assumed that the specifications generated so far are satisfiable, though they may be inadequate. And AutoSpec will start another iteration to generate additional specifications while retaining those already generated. Finally, the algorithm returns the annotated code C with the generated specifications as the output (line 19). After several iterations, if the whole verification task remains incomplete, the programmer can make a decision on whether to involve professionals to continue with the verification process for the annotated code C.

Consider the extended call graph in Fig. 3(A) for example. AutoSpec first pushes the main function, the sort function, the sort.loop1 loop, the sort.loop2 loop, and the swap function into the stack in order, as all of them, except the swap function have some callee nodes that require specification generation. Then, it generates specifications for each function or loop in the stack in reserve order. This order echoes what is described in Sect. 2. AutoSpec will leverage the power of LLMs to generate candidate specifications for each component/function (i.e., spec_generation function in line 12). In the following, we discuss how AutoSpec utilizes LLMs for generating specifications.
Specification generation by LLMs. To employ LLMs in producing precise and reliable responses in the specified format, AutoSpec automatically generates a prompt for each specification generation task. This prompt is a natural language query that includes the role setting, task description, a few examples showing the desired specifications, and the source code with a highlighted placeholder (e.g., Fig. 3(C)). The prompt template used in AutoSpec is shown in Fig. 3(D). Specifically, a prompt typically consists of the following elements: a system message, code with a placeholder, and an output indicator. The system message provides the specification generation task description and the specification language, which are called context. AutoSpec sets the role of LLMs as “As an experienced C/C++ programmer, I employ a behavioral interface specification language that utilizes Hoare style pre/post-conditions, as well as invariants, to annotate my C/C++ source code”. The system message also indicates the task’s instructions, such as “
 ”. As explained in Sect. 3.1, when querying LLMs for the specifications of a component (i.e., a function or loop), the code of this component and the specifications of its callees in the call graph are needed. That is to say, the irrelevant code that is not called by this component can be omitted, allowing LLMs to maintain their focus on the target component and reduces unnecessary token costs. Finally, AutoSpec uses the output format
”. As explained in Sect. 3.1, when querying LLMs for the specifications of a component (i.e., a function or loop), the code of this component and the specifications of its callees in the call graph are needed. That is to say, the irrelevant code that is not called by this component can be omitted, allowing LLMs to maintain their focus on the target component and reduces unnecessary token costs. Finally, AutoSpec uses the output format
 to indicate the generated specifications, which is crucial for programmatically processing the responses of LLMs.
to indicate the generated specifications, which is crucial for programmatically processing the responses of LLMs.
To improve the quality of the generated specifications, AutoSpec employs the prompt engineering technique of few-shot prompting [30]. To achieve this, the prompts are designed to include a few relevant input-output examples. Feeding LLMs a few examples can guide them in leveraging previous knowledge and experiences to generate the desired outputs. This, in turn, enables LLMs to effectively handle novel situations. In particular, few-shot prompting allows LLMs to facilitate the learning of syntax and semantics of specification language through in-context learning. For example, consider a prompt that includes an input-output example with a loop invariant for an array that initializes all elements to 0, such as
 . With this example, AutoSpec is able to generate a valid loop invariant that involves using quantifiers for the inner loop of bubbleSort in a single query.
. With this example, AutoSpec is able to generate a valid loop invariant that involves using quantifiers for the inner loop of bubbleSort in a single query.
3.3 Specification Validation
The hierarchical specification generation algorithm also employs specification validation (i.e., spec_validation() in line 13) and specification simplification (i.e., simplify() in line 17) techniques to ensure the quality of the specifications.
Specification Validation. Once candidate specifications have been generated for a component, AutoSpec will check their syntactic and semantic validity (i.e., legality and satisfiability), as shown in Fig. 3(F). Specifically, for a function, the legality and satisfiability of the generated specifications are checked immediately. While for a loop, the legality is checked immediately, but the satisfiability check is postponed until the outermost loop. This is because inner loops often use variables defined in some of their outer loops (e.g., variable i in the bubbleSort example), and the satisfiability of all loop invariants needs to be verified simultaneously.
AutoSpec leverages the verification tool (i.e., Frama-C) to verify the specifications. If the verification tool returns a compilation error, AutoSpec identifies the illegal specification where the error occurs and continues verifying without it if there are still some candidates. Otherwise, if the verification tool returns a verification failure, AutoSpec identifies the unsatisfiable specification which fails during verification and continues verifying without it if there are still some candidates. Finally, if the verification succeeds, the specifications will be correspondingly inserted into the code as a comment (Fig. 3(G)).
In addition, AutoSpec also validates whether the generated specifications are adequate to verify the target assertion (line 16), which is the same as the validation above but with the target assertion. Note that, the validation phase is crucial to AutoSpec as it ensures that the generated specifications are not only legal and satisfiable but also adequate to verify the target assertion (Fig. 3(I)).
Specification Simplification (Optional). The objective of specification simplification is to provide users with a concise and elegant specification that facilitates manual inspection and aids in understanding the implementation. This process could be optional if one’s goal is simply to complete the verification task without placing importance on the specifications. After successfully verifying the assertion, we proceed to systematically remove specifications that are not needed for their verification, one by one. Our main idea is that a specification is unnecessary if the assertion is still verifiable without it. We repeat this process until we reach the minimal set of specifications for manual reading.
There are two main reasons to eliminate specifications: (1) The specification is considered weak and does not capture relevant properties of the verification task. For example, both the loop invariant
 and
and
 are satisfiable, but
are satisfiable, but
 can be safely removed. (2) The specification is semantically similar to another specification. For example, both
can be safely removed. (2) The specification is semantically similar to another specification. For example, both
 and
and
 accurately describe the post-condition of bubbleSort. Removing either of them has no impact on the verification results.
accurately describe the post-condition of bubbleSort. Removing either of them has no impact on the verification results.
4 Evaluation
The experiments aim to answer the following research questions:
-
RQ1. Can AutoSpec generate specifications for various properties effectively? We aim to comprehensively characterize the effectiveness of AutoSpec against various types of specifications including pre/post-conditions, loop invariants.
-
RQ2. Can AutoSpec generate specifications for loop invariant effectively? Loop invariant, as a major specification type, is known for its difficulty and significance. We select three benchmarks with linear and nested loop structures and compare them with state-of-the-art approaches.
-
RQ3. Is AutoSpec efficient? We compare the AutoSpec ’s overhead incurred by LLM querying and theorem proving with the baselines.
-
RQ4. Does every step of AutoSpec contribute to the final effectiveness? We conduct an ablation study on each part of the AutoSpec ’s design, showing the distinct contribution made independently.
4.1 Evaluation Setup
Benchmark. We conducted evaluations on four benchmarks and a real-world project. The statistical details of these benchmarks can be found in Table 1. The Frama-C-problems [31] benchmark and the X509-parser [32] comprises programs that involve multiple functions or loops, requiring the formulation of pre/post-conditions, loop invariants, etc.. The SyGuS [33] benchmark only includes programs with linear loop structures. While the OOPSLA-13 [34] and SV-COMP [35] benchmarks include programs with nested or multiple loops, making them suitable for evaluating the versatility and diversity of generated specifications. Please note that we assume the programs being verified are free of compilation errors, and the properties being verified are consistent with the programs. If there are any inconsistencies between the code and properties, AutoSpec is expected to fail the verification after the iterations end.
Baselines. For RQ1, as previous works have primarily relied on manually written specifications for the deductive verification of functional correctness for C/C++ programs [36, 37], we then conduct our approach based on this baseline, and use the ablation study to demonstrate the contribution of different parts of the design in AutoSpec in RQ4. For RQ2, we compare with Code2Inv [2], a learning-based approach for generating linear loop invariantsFootnote 2. Although there are newer approaches built on Code2Inv such as CLN2INV [16], their replicable toolkit is only applicable to the benchmark they used (i.e., SyGuS [33]) and incomplete, failing to apply to other benchmarks. Additionally, for RQ2, we also compared with Pilat [29] using the default settings.
Configuration. For implementation, we use ChatGPT’s API gpt-3.5-turbo-0613. We configure the parameters in API as follows: max_token: 2048, temperature: 0.7. To show the generalizability of AutoSpec, we also utilize Llama-2-70b for conducting a comparable experiment (Sect. 5). Lastly, we employ Frama-C [28, 38] and its WP plugin to verify the specifications.
4.2 RQ1. Effectiveness on General Specification
Table 2 shows the results of AutoSpec on the Frama-C-problems benchmark. This benchmark consists of 51 C programs, divided into eight categories (as indicated in the entry Type). Each type contains several programs. The size of the programs ranges from 9 to 36 lines of code (the entry LoC). We also list the number of functions and loop structures defined in the program. Most programs contain a main function, with one or more loop structures. Since we could not find other previous work that can automatically generate various types of specifications to complete the verification task on Frama-C-problems benchmark, we hereby show the effectiveness of AutoSpec in detail.
Overall, 31/51 of these programs can be successfully solved by AutoSpec. In particular, due to the randomness of LLMs, we ran the experiment five times for each program and reported the detailed results. The success rate is tabulated in Table 2, column Ratio. It shows that the results are stable over five runs. Almost all passed cases can be successfully solved in five runs, with only a few exceptions (e.g., 1/5, 4/5). The stable result shows that the randomness of LLMs has little impact on the effectiveness of AutoSpec. Furthermore, AutoSpec enables an iterative enhancement on specification generation. We hereby show the number of iterations used for success generation (column Iterations). Most cases can be solved in the first iteration. While the iterative enhancement also contributes to certain improvements. For example, add_pointers_3_vars.c in the pointers category needs two more iterations to generate adequate specifications to pass the theorem prover. In addition, we also report the number of generated specifications that are correct by using the ground truth in the benchmark as a reference, as shown in column Correct Spec. We can see that for the failed cases, there is at least one generated specification that is correct. This shows that the generated specifications are not excessive, and still have the potential to improve. Finally, in terms of overhead (column Time(s)), AutoSpec processes a case in minutes, from 2.53 s to 12 min, with an average of 89.17 s.
A Real-World X509 Parser Project. The X509-parser project, which aims to ensure the absence of runtime errors, has undergone verification by Frama-C and the ACSL specification language. Note that the specifications for this project were manually added throughout 5 months [3]. It is currently impractical to seamlessly apply AutoSpec to the entire project without human intervention. We manually extracted 6 representative functions without specifications. These functions handle pointer dereference, multiple data types, shift operations, etc.. For each function, we set a verification target that accurately describes its functional correctness properties. AutoSpec generates specifications for these functions, as shown in Table 3. Surprisingly, all 6 functions were solved by AutoSpec. Through our comprehensive manual examination of the generated specifications, we found that AutoSpec can generate a variety of specifications not previously written by the developer. These specifications play a crucial role in ensuring functional correctness. Considering that it takes five calendar months to write specifications for the whole X509-parser project [3], AutoSpec can automatically generate the required specifications for the functions in X509-parser in a few minutes. We believe that AutoSpec could be useful for real-world verification tasks.
4.3 RQ2. Effectiveness on Loop Invariants
Table 4 shows the effectiveness of AutoSpec in generating specifications of loop invariants compared with three baselines. In particular, the SyGuS benchmark consists of 133 C programs. Each program contains only one loop structure. We compare AutoSpec with three baselines: Pilat [29], Code2Inv [2] and CLN2INV [16] on this benchmark. The result is shown in Table 4 under SyGuS entry. Pailt fails to generate valid specifications for all cases in this benchmark, as all the specifications it generates are either unsatisfiable or irrelevant. On the other hand, Code2Inv and CLN2INV perform better, solving 73 and 124 programs, respectively. AutoSpec can handle a comparable number of cases, namely, 114 programs in this benchmark. Although CLN2INV can solve 10 more cases in this benchmark, it cannot handle any cases in the OOPSLA-13 benchmark. Although CLN2INV can successfully parse 19 out of 46 cases (denoted as ❌), CLN2INV fails to construct satisfiable invariants that are adequate to verify the programs, resulting in a score of 0/46. This could be due to the overfitting of machine learning methods to specific datasets. Code2Inv, on the other hand, can handle 9 out of 46 cases. In comparison, AutoSpec can solve 38/46 (82.60%), which significantly outperforms existing approaches.
Furthermore, we consider a more difficult benchmark, SV-COMP. Due to the unsatisfactory results of the existing approaches, we have opted to exclusively present the results obtained using AutoSpec. As shown in Table 4 under SV-COMP entry, AutoSpec can solve 16 out of 21 programs with an average time of 3 min. Note that there are three programs with 3-fold nested loop structures in this benchmark. AutoSpec can solve one of them, while for the other two programs, AutoSpec can generate several satisfiable specifications, but there are still one or two specifications that cannot be generated after five iterations.

Overhead of AutoSpec on Four Benchmarks.
4.4 RQ3. Efficiency of AutoSpec
In the first RQs, we can observe that AutoSpec can generate satisfiable and adequate specifications for the proof ranging from 2.35 to 739.62 s (i.e., 0.04 to 12.33 min). In this RQ, we illustrate the composition of the overhead in AutoSpec across sub-tasks, i.e., the time required for querying the LLM for specifications, validating and verifying the specifications against the theorem prover, and simplifying the specifications (optional). The results for these four benchmarks are presented in Fig. 4.
We can see that for the four benchmarks, validating and verifying the specifications (Validate) takes the most time, ranging from 1.3 to 994.9 s. Querying the LLMs (Query) takes the least time, averaging less than 10 s. It is noteworthy that, unlike existing works that tend to generate a lot of candidate specifications and check their validity for one hour [16] to 12 h [2], AutoSpec takes far less time in validating (e.g., 1.2 s to 3.88 min). This is because AutoSpec generates fewer but higher-quality specifications. The efficiency of AutoSpec makes it both practical and cost-effective for various applications.
In addition, the time required for simplifying the specifications (Simplify) may vary depending on the number of generated specifications. A larger number of specifications leads to a longer simplification process. Nonetheless, given the fact that the simplification step is optional in AutoSpec, and considering the benefit of faster solving brought about by the concise and elegant specifications, the cost of simplification is justified.
4.5 RQ4. Ablation Study
Finally, we evaluate the contribution made by each part of AutoSpec ’s design. The results are shown in Table 5. We conduct the evaluation on Frama-C-problems benchmark [31] under seven settings: (1) - (4) settings under Base ChatGPT entry directly feed the C program together with the desired properties to be verified into ChatGPT, with zero-/one-/two-/three-shot. These settings are designed to compare with the decomposed manner adopted by AutoSpec. Setting (5) under entry Decomposed adopts the code decomposition (i.e., Step 1 of AutoSpec) with three-shot, because it shows the best result according to the results of the previous settings. Settings (6) and (7) are respectively configured with only one pass (i.e., without enhancement) and five iterations (i.e., with enhancement), showing the improvement brought by the iterative enhancement (Step (K) in Fig. 3). The last row shows the total number of programs that can be successfully solved under the corresponding settings.
Table 5 shows an ascending trend in the number of solved programs, from 5 to 31 over 51. On the one hand, it is hardly possible to directly ask ChatGPT to generate specifications for the entire program. The input-output examples bring only a limited improvement (from 5 to 9) in the performance. On the other hand, code decomposition and hierarchical specification generation bring a significant improvement (from 9 to 26). This shows the contribution made by the first two steps of AutoSpec. Furthermore, the contribution of iterative enhancement can be observed in the last two columns, from 27 to 31. Overall, the ablation study shows that every step in AutoSpec has a positive impact on the final result and that the idea of code decomposition and hierarchical specification generation brings the biggest improvement.
4.6 Case Studies
We discuss 3 representative cases to show how iterative enhancement contributes (Fig. 5), and situations where AutoSpec fails to handle (Fig. 6 and Fig. 7).
Case 1. A Success Case Made by Validation and Iterative Enhancement. We show how specification validation and iterative enhancement help AutoSpec to generate satisfiable and adequate specifications. The program presented below computes the sum of three values stored in pointers. In the first iteration, only two specifications (lines 2 and 3) are generated, which respectively require three pointers should be valid (line 2), and the result of add is the sum (line 3). However, these two specifications alone are inadequate to verify the property due to the lack of a specification describing whether the values of the pointers have been modified within the add function. AutoSpec then inserts placeholders immediately after the two generated specifications and continues to the second iteration of enhancement. The subsequently generated specification (line 4) states the add function has no assignment behavior, making the verification succeed.

Case 1

Case 2
Case 2. A Failing Case Due to Missing Context. We present an example where AutoSpec fails to generate adequate specifications due to the lack of necessary context. The code for the pow in <math.h> is not directly accessible. Currently, AutoSpec does not automatically trace all the dependencies and include their code in the prompt. LLMs can hardly figure out what pow is expected to do. As a result, the specification for this function cannot be generated despite all attempts made by AutoSpec. This case shows a possible improvement by adding more dependencies in the prompt.
Case 3. A Failing Case Due to the Need for User-Defined Axioms. We illustrate an example where AutoSpec fails to produce sufficient specifications, necessitating user-defined axioms. The factorial function encompasses a nonlinear loop, typically necessitating the formulation of axioms or lemmas by domain experts to aid in the proof process. Presently, AutoSpec does not include axioms in the prompt or provided examples, posing a challenge for LLM to generate these supportive axioms. This example underscores the importance of addressing the axiom generation issue for AutoSpec for future work, in order to handle intricate examples effectively.

Case 3
5 Threats to Validity
There are three major validity threats. The first concerns the data leakage problem. We addressed this threat in two folds. First, we directly apply LLMs to generate the specifications (Sect. 4.5). The unsatisfactory result (success rate: 5/51) shows that the chance of overfitting to the benchmark is low. Second, we followed a recent practice [39] for the data leakage threat. We randomly sampled 100 programs from three benchmarks in RQ2 (i.e., SyGuS, OOPSLA-13, and SV-COMP) in a ratio of 50:25:25 and mutated these programs by variable renaming (e.g., renaming x to m) and statement/branch switching (e.g., negotiating the if-condition, and switching the statements in if and else branches) without changing the semantics of the program manually. Then we applied AutoSpec over the 100 mutated programs. The experiment shows that 98% results hold after the programs are mutated. It further confirmed that the validity threat of data leakage is low. The second concerns the generalizability to different LLMs. To address this concern, we implemented AutoSpec to a popular and open-source LLM called Llama-2-70b and ran it on the same benchmark used in RQ1. Similar results were observed, with AutoSpec (Llama2) achieving a score of 25/51 compared to the score of 31/51 achieved by AutoSpec (ChatGPT). The third concerns the scalability of AutoSpec. We have evaluated a real-world X509-parser project and achieved unexpectedly good performance. However, completing the whole verification task on the entire project remains challenging. The evidence suggests that AutoSpec has the potential to assist participants in writing specifications for real-world programs.
6 Related Work
Specification Synthesis. While there exist various approaches and techniques for generating program specifications from natural language [40,41,42], this paper primarily focuses on specification generation based on the programming language. There has been work using data mining to infer specifications [43,44,45,46]. Several of these techniques use dynamic traces to infer possible invariants and preconditions from test cases, and static analysis to check the validity and completeness of the inferred specifications [47,48,49]. While others apply domain knowledge and statically infer specifications from the source code [43, 50, 51]. Several works have been conducted to address the challenging sub-problem of loop invariant inference, including CLN2INV [16], Code2Inv [2], G-CLN [17] and Fib [52]. Additionally, there are also studies dedicated to termination specification inference [23]. A recent study, SpecFuzzer [53], combines grammar-based fuzzing, dynamic invariant detection, and mutation analysis to generate class specifications for Java methods in an automated manner. Our approach differs from these techniques as it statically generates comprehensive contracts for each loop and function, yielding reliable outcomes necessary for verification.
Assisting Program Analysis and Verification with LLMs. In recent years, there has been a growing interest in applying LLMs to assist program analysis tasks [54], such as fuzz testing [55, 56], static analysis [57,58,59], program verification [60,61,62], bug reproduction [63] and bug repair [64,65,66]. For example, Baldur [60] is a proof-synthesis tool that uses transformer-based pre-trained large language models fine-tuned on proofs to generate and repair whole proofs. In contrast, AutoSpec focuses on generating various types of program specifications and leveraging the auto-active verification tool to complete the verification task, while Baldur focuses on automatically generating proofs for the theorems. Li et al. [59] investigated the potential of LLMs in enhancing static analysis by posing relevant queries. They specifically focused on UBITest [67], a bug-finding tool for detecting use-before-initialization bugs. The study revealed that those false positives can be significantly reduced by asking precisely crafted questions related to function-level behaviors or summaries. Ma et al. [68] and Sun et al. [58] explore the capabilities of LLMs when performing various program analysis tasks such as control flow graph construction, call graph analysis, and code summarization. Pei et al. [69] use LLMs to reason about program invariants with decent performance. These diverse applications underline the vast potential of LLMs in program analysis. AutoSpec complements these efforts by showcasing the effectiveness of LLMs in generating practical and elegant program specifications, thereby enabling complete automation of deductive verification.
7 Conclusion
In this paper, we presented AutoSpec, a novel approach for generating program specifications from source code. Our approach leverages the power of Large Language Models (LLMs) to infer the candidate program specifications in a bottom-up manner, and then validates them using provers/verification tools and iteratively enhances them. The evaluation results demonstrate that our approach to specification generation achieves full automation and cost-effectiveness, which is a major bottleneck for formal verification.
Notes
- 1.
ACSL has more keywords with rich expressiveness. Refer to the documentation [27].
- 2.
We reproduce their implementation using the provided replicable package and run the tool on two additional benchmarks following their instructions. However, in their original setting, the maximal time limit for each program is set to 12 h, which is far from affordable. So we lowered the threshold to 1 h for efficiency.
References
Hähnle, R., Huisman, M.: Deductive software verification: from pen-and-paper proofs to industrial tools. In: Steffen, B., Woeginger, G. (eds.) Computing and Software Science. LNCS, vol. 10000, pp. 345–373. Springer, Cham (2019). https://doi.org/10.1007/978-3-319-91908-9_18
Si, X., Dai, H., Raghothaman, M., Naik, M., Song, L.: Learning loop invariants for program verification. Adv. Neural Inf. Process. Syst. 31, 1–12 (2018)
Ebalard, A., Mouy, P., Benadjila, R.: Journey to a rte-free x. 509 parser. In: Symposium sur la sécurité des technologies de l’information et des communications (SSTIC 2019) (2019)
Efremov, D., Mandrykin, M., Khoroshilov, A.: Deductive verification of unmodified linux kernel library functions. In: Margaria, T., Steffen, B. (eds.) ISoLA 2018. LNCS, vol. 11245, pp. 216–234. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-03421-4_15
Dordowsky, F.: An experimental study using acsl and frama-c to formulate and verify low-level requirements from a do-178c compliant avionics project. arXiv preprint arXiv:1508.03894 (2015)
Blanchard, A., Kosmatov, N., Lemerre, M., Loulergue, F.: A case study on formal verification of the anaxagoros hypervisor paging system with frama-C. In: Núñez, M., Güdemann, M. (eds.) FMICS 2015. LNCS, vol. 9128, pp. 15–30. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-19458-5_2
Kosmatov, N., Lemerre, M., Alec, C.: A case study on verification of a cloud hypervisor by proof and structural testing. In: Seidl, M., Tillmann, N. (eds.) TAP 2014. LNCS, vol. 8570, pp. 158–164. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-09099-3_12
Dillig, I., Dillig, T., Li, B., McMillan, K.: Inductive invariant generation via abductive inference. Acm Sigplan Not. 48(10), 443–456 (2013)
Lin, Y., et al.: Inferring loop invariants for multi-path loops. In: 2021 International Symposium on Theoretical Aspects of Software Engineering (TASE), pp. 63–70. IEEE (2021)
Yu, S., Wang, T., Wang, J.: Loop invariant inference through smt solving enhanced reinforcement learning. In: Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, pp. 175–187 (2023)
Cousot, P., Cousot, R., Fähndrich, M., Logozzo, F.: Automatic inference of necessary preconditions. In: Giacobazzi, R., Berdine, J., Mastroeni, I. (eds.) VMCAI 2013. LNCS, vol. 7737, pp. 128–148. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-35873-9_10
Padhi, S., Sharma, R., Millstein, T.: Data-driven precondition inference with learned features. ACM SIGPLAN Not. 51(6), 42–56 (2016)
Popeea, C., Chin, W.-N.: Inferring disjunctive postconditions. In: Okada, M., Satoh, I. (eds.) ASIAN 2006. LNCS, vol. 4435, pp. 331–345. Springer, Heidelberg (2007). https://doi.org/10.1007/978-3-540-77505-8_26
Su, J., Arafat, M., Dyer, R.: Using consensus to automatically infer post-conditions. In: Proceedings of the 40th International Conference on Software Engineering: Companion Proceedings, pp. 202–203 (2018)
Singleton, J.L., Leavens, G.T., Rajan, H., Cok, D.: An algorithm and tool to infer practical postconditions. In: Proceedings of the 40th International Conference on Software Engineering: Companion Proceedings, pp. 313–314 (2018)
Ryan, G., Wong, J., Yao, J., Gu, R., Jana, S.: Cln2inv: learning loop invariants with continuous logic network. In: International Conference on Learning Representations (2020)
Yao, J., Ryan, G., Wong, J., Jana, S., Gu, R.: Learning nonlinear loop invariants with gated continuous logic networks. In: Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation, pp. 106–120 (2020)
Gupta, A., Rybalchenko, A.: InvGen: an efficient invariant generator. In: Bouajjani, A., Maler, O. (eds.) CAV 2009. LNCS, vol. 5643, pp. 634–640. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-02658-4_48
Le, Q.L., Gherghina, C., Qin, S., Chin, W.-N.: Shape analysis via second-order bi-abduction. In: Biere, A., Bloem, R. (eds.) CAV 2014. LNCS, vol. 8559, pp. 52–68. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-08867-9_4
Wang, Q., Chen, M., Xue, B., Zhan, N., Katoen, J.-P.: Synthesizing invariant barrier certificates via difference-of-convex programming. In: Silva, A., Leino, K.R.M. (eds.) CAV 2021. LNCS, vol. 12759, pp. 443–466. Springer, Cham (2021). https://doi.org/10.1007/978-3-030-81685-8_21
Feng, Y., Zhang, L., Jansen, D.N., Zhan, N., Xia, B.: Finding polynomial loop invariants for probabilistic programs. In: D’Souza, D., Narayan Kumar, K. (eds.) ATVA 2017. LNCS, vol. 10482, pp. 400–416. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-68167-2_26
Gan, T., Xia, B., Xue, B., Zhan, N., Dai, L.: Nonlinear craig interpolant generation. In: Lahiri, S.K., Wang, C. (eds.) CAV 2020. LNCS, vol. 12224, pp. 415–438. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-53288-8_20
Le, T.C., Qin, S., Chin, W.N.: Termination and non-termination specification inference. In: The 36th ACM SIGPLAN Conference on Programming Language Design and Implementation, pp. 489–498 (2015)
Vazquez-Chanlatte, M., Seshia, S.A.: Maximum causal entropy specification inference from demonstrations. In: Lahiri, S.K., Wang, C. (eds.) CAV 2020. LNCS, vol. 12225, pp. 255–278. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-53291-8_15
OpenAI. GPT-4 technical report. CoRR arxiv:2303.08774 (2023)
Liu, N.F., et al.: Lost in the middle: how language models use long contexts. arXiv preprint arXiv:2307.03172 (2023)
Baudin, P., Filliâtre, J.-C., Marché, C., Monate, B., Moy, Y., Prevosto, V.: Acsl: Ansi/iso c specification (2021)
Frama-C. Frama-c, software analyzer. Accessed 15 Jan 2024
de Oliveira, S., Bensalem, S., Prevosto, V.: Polynomial invariants by linear algebra. In: Artho, C., Legay, A., Peled, D. (eds.) ATVA 2016. LNCS, vol. 9938, pp. 479–494. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46520-3_30
Brown, T.B., et al.: Language models are few-shot learners. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H.T. (eds.) Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, 6–12 December 2020, virtual (2020)
Frama-C. A repository dedicated for problems related to verification of programs using the tool frama-c. Accessed 15 Jan 2024
A rte-free x.509 parser. Accessed 15 Jan 2024
Alur, R., Fisman, D., Padhi, S., Singh, R., Udupa, A.: Sygus-comp 2018: results and analysis. CoRR arxiv:1904.07146 (2019)
Dillig, I., Dillig, T., Li, B., McMillan, K.: Inductive invariant generation via abductive inference. In: Proceedings of the 2013 ACM SIGPLAN International Conference on Object Oriented Programming Systems Languages & Applications, OOPSLA 2013, pp. 443–456. Association for Computing Machinery, New York (2013)
Beyer, D.: Progress on software verification: SV-COMP 2022. In: TACAS 2022. LNCS, vol. 13244, pp. 375–402. Springer, Cham (2022). https://doi.org/10.1007/978-3-030-99527-0_20
Baudin, P., Bobot, F., Correnson, L., Dargaye, Z., Blanchard, A.: Wp plug-in manual. Frama-c. com (2020)
Blanchard, A., Loulergue, F., Kosmatov, N.: Towards full proof automation in frama-C using auto-active verification. In: Badger, J.M., Rozier, K.Y. (eds.) NFM 2019. LNCS, vol. 11460, pp. 88–105. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-20652-9_6
Kirchner, F., Kosmatov, N., Prevosto, V., Signoles, J., Yakobowski, B.: Frama-c: a software analysis perspective. Formal Aspects Comput. 27, 573–609 (2015)
Wu, Y., et al.: How effective are neural networks for fixing security vulnerabilities. In: Just, R., Fraser, G. (eds.) Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2023, Seattle, WA, USA, 17–21 July 2023, pp. 1282–1294. ACM (2023)
Cosler, M., Hahn, C., Mendoza, D., Schmitt, F., Trippel, C.: nl2spec: interactively translating unstructured natural language to temporal logics with large language models. In: Enea, C., Lal, A. (eds.) Computer Aided Verification, pp. 383–396. Springer, Cham (2023). https://doi.org/10.1007/978-3-031-37703-7_18
Zhai, J., et al.: C2s: translating natural language comments to formal program specifications. In: Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pp. 25–37 (2020)
Giannakopoulou, D., Pressburger, T., Mavridou, A., Schumann, J.: Generation of formal requirements from structured natural language. In: Madhavji, N., Pasquale, L., Ferrari, A., Gnesi, S. (eds.) REFSQ 2020. LNCS, vol. 12045, pp. 19–35. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-44429-7_2
Beckman, N.E., Nori, A.V.: Probabilistic, modular and scalable inference of typestate specifications. In: Proceedings of the 32nd ACM SIGPLAN Conference on Programming Language Design and Implementation, pp. 211–221 (2011)
Lo, D., Khoo, S.C., Liu, C.: Efficient mining of iterative patterns for software specification discovery. In: The 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 460–469 (2007)
Le, T.B.D., Lo, D.: Deep specification mining. In: Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis, pp. 106–117 (2018)
Kang, H.J., Lo, D.: Adversarial specification mining. ACM Trans. Softw. Eng. Methodol. (TOSEM) 30(2), 1–40 (2021)
Ammons, G., Bodik, R., Larus, J.R.: Mining specifications. ACM Sigplan Notices 37(1), 4–16 (2002)
Yang, J., Evans, D., Bhardwaj, D., Bhat, T., Das, M.: Perracotta: mining temporal api rules from imperfect traces. In: Proceedings of the 28th International Conference on Software Engineering, pp. 282–291 (2006)
Nimmer, J.W.: Automatic generation and checking of program specifications. PhD thesis, Massachusetts Institute of Technology (2002)
Ramanathan, M.K., Grama, A., Jagannathan, S.: Static specification inference using predicate mining. ACM SIGPLAN Not. 42(6), 123–134 (2007)
Shoham, S., Yahav, E., Fink, S., Pistoia, M.: Static specification mining using automata-based abstractions. In: Proceedings of the 2007 International Symposium on Software Testing and Analysis, pp. 174–184 (2007)
Lin, S.W., Sun, J., Xiao, H., Liu, Y., Sanán, D., Hansen, H.: Fib: squeezing loop invariants by interpolation between forward/backward predicate transformers. In: 2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE), pp. 793–803 (2017)
Molina, F., d’Amorim, M., Aguirre, N.: Fuzzing class specifications. In: Proceedings of the 44th International Conference on Software Engineering, pp. 1008–1020 (2022)
Hou, X., et al.: Large language models for software engineering: a systematic literature review. CoRR arxiv:2308.10620 (2023)
Deng, Y., Xia, C.S., Peng, H., Yang, C., Zhang, L.: Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models. In: Just, R., Fraser, G. (eds.) Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2023, Seattle, WA, USA, 2023, pp. 423–435. ACM (2023)
Lemieux, C., Inala, J.P., Lahiri, S.K., Sen, S.: Codamosa: escaping coverage plateaus in test generation with pre-trained large language models. In: 45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, 2023, pp. 919–931. IEEE (2023)
Wen, C., et al.: Automatically inspecting thousands of static bug warnings with large language model: how far are we? ACM Trans. Knowl. Disc. Data 18(7), 1–34 (2024)
Sun, W., et al.: Automatic code summarization via chatgpt: how far are we? CoRR arxiv:2305.12865 (2023)
Li, H., Hao, Y., Zhai, Y., Qian, Z.: Poster: assisting static analysis with large language models: a chatgpt experiment. In: 44th IEEE Symposium on Security and Privacy, SP 2023, San Francisco, CA, USA, 2023. IEEE (2023)
First, E., Rabe, M.N., Ringer, T., Brun, Y.: Baldur: whole-proof generation and repair with large language models. In: ESEC/FSE ’23: 31th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ACM (2023)
Wu, H., Barrett, C., Narodytska, N.: Lemur: integrating large language models in automated program verification. arXiv preprint arXiv:2310.04870 (2023)
Yang, K., et al.: Leandojo: theorem proving with retrieval-augmented language models. arXiv preprint arXiv:2306.15626 (2023)
Kang, S., Yoon, J., Yoo, S.: Large language models are few-shot testers: exploring llm-based general bug reproduction. In: 45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, 14–20 May 2023, pp. 2312–2323. IEEE (2023)
Pearce, H., Tan, B., Ahmad, B., Karri, R., Dolan-Gavitt, B.: Examining zero-shot vulnerability repair with large language models. In: 44th IEEE Symposium on Security and Privacy, SP 2023, San Francisco, CA, USA, 21–25 May 2023, pp. 2339–2356. IEEE (2023)
Xia, C.S., Wei, Y., Zhang, L.: Automated program repair in the era of large pre-trained language models. In: 45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, 14–20 May 2023, pp. 1482–1494. IEEE (2023)
Fan, Z., Gao, X., Mirchev, M., Roychoudhury, A., Tan, S.H.: Automated repair of programs from large language models. In: 45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, 14–20 May 2023, pp. 1469–1481. IEEE (2023)
Zhai, Y., et al.: Ubitect: a precise and scalable method to detect use-before-initialization bugs in linux kernel. In: Devanbu, P., Cohen, M.B., Zimmermann, T. (eds.) ESEC/FSE ’20: 28th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, USA, 8–13 November 2020, pp. 221–232. ACM (2020)
Ma, W., et al.: The scope of chatgpt in software engineering: a thorough investigation. CoRR arxiv:2305.12138 (2023)
Pei, K., Bieber, D., Shi, K., Sutton, C., Yin, P.: Can large language models reason about program invariants? (2023)
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China (Nos. 62372304, 62302375, 62192734), the China Postdoctoral Science Foundation funded project (No. 2023M723736), the Fundamental Research Funds for the Central Universities, and the Hong Kong SAR RGC/GRF No. 16207120.
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2024 The Author(s)
About this paper

Cite this paper
Wen, C. et al. (2024). Enchanting Program Specification Synthesis by Large Language Models Using Static Analysis and Program Verification. In: Gurfinkel, A., Ganesh, V. (eds) Computer Aided Verification. CAV 2024. Lecture Notes in Computer Science, vol 14682. Springer, Cham. https://doi.org/10.1007/978-3-031-65630-9_16
Download citation
DOI: https://doi.org/10.1007/978-3-031-65630-9_16
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-65629-3
Online ISBN: 978-3-031-65630-9
eBook Packages: Computer ScienceComputer Science (R0)