
Abstract
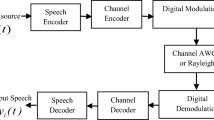
The performance of the GMM-UBM-I vector in a forensic speaker verification system has been examined in the context of noisy speech samples. This analysis utilised both Mel-frequency cepstral coefficients (MFCC) and MFCCs generated from auto-correlated speech signals. The noisy signal’s auto correlation coefficients are concentrated around the lower lag, whereas the autocorrelation coefficients near the higher lag are very small. Thus, in addition to retain the periodic nature, autocorrelation-based MFCC is also robust for analyzing speech signals in intense background noise. The performance of MFCC and auto-correlated MFCC depends heavily on the quality of the sample. It works best with data that is free of noise, but it suffers when used on real-world examples, ie, with noisy data. The experiment on speaker verification for forensic purposes involved the addition of White Gaussian Noise, Red Noise, and Pink Noise, with a Signal-to-Noise Ratio (SNR) range spanning from −20 dB to + 20 dB. The performance of both methods was affected drastically in call cases but autocorrelation-based MFCC gave better results than MFCC. Thus, autocorrelation-based MFCC is a valuable method for robust feature extraction when compared with MFCC for speaker verification purposes in intense background noise. The verification accuracy in our method is improved even in very high noise levels (−20 dB) than the reported research work.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Furui, S.: Speaker-independent and speaker-adaptive recognition techniques. Adv. Speech Signal Process. 597–622 (1992)
Chiu, T.-L., Liou, H.-C., Yeh, Y.: A study of web-based oral activities enhanced by automatic speech recognition for EFL college learning. Comput. Assisted Lang. Learn. 20(3), 209–233 (2007)
Kabir, M.M., et al.: A survey of speaker recognition: fundamental theories, recognition methods and opportunities. IEEE Access 9, 79236–79263 (2021)
Ajili, M., et al.: Phonological content impact on wrongful convictions in forensic voice comparison context. In: 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE (2017)
Amino, K., Osanai, T., Kamada, T., Makinae, H., Arai, T.: Historical and procedural overview of forensic speaker recognition as a science. In: Neustein, A., Patil, H. (eds.) Forensic Speaker Recognition, pp. 3–20. Springer, New York (2012). https://doi.org/10.1007/978-1-4614-0263-3_1
Tull, R.G., Rutledge, J.C.: Cold speech for automatic speaker recognition. In: Acoustical Society of America 131st Meeting Lay Language Papers (1996)
Benzeghiba, M., et al.: Impact of variabilities on speech recognition. In: Proceeding of the SPECOM (2006)
Mandasari, M., McLaren, M., van Leeuwen, D.A.: The effect of noise on modern automatic speaker recognition systems. In: 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE (2012)
Hasan, T., et al.: CRSS systems for 2012 NIST speaker recognition evaluation. In: 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE (2013)
Logan, B.: Mel frequency cepstral coefficients for music modeling. ISMIR 270(1) (2000)
Atal, B.S.: The history of linear prediction. IEEE Signal Process. Mag. 23(2), 154–161 (2006)
Hariharan, M., Chee, L.S., Yaacob, S.: Analysis of infant cry through weighted linear prediction cepstral coefficients and probabilistic neural network. J. Med. Syst. 36, 1309–1315 (2012)
Hermansky, H.: Perceptual linear predictive (PLP) analysis of speech. J. Acoustical Soc. Am. 87(4), 1738–1752 (1990)
Naing, H.M.S., et al.: Filterbank analysis of MFCC feature extraction in robust children speech recognition. In: 2019 International Symposium on Multimedia and Communication Technology (ISMAC). IEEE (2019)
Bai, Z., Zhang, X.-L.: Speaker recognition based on deep learning: an overview. Neural Netw. 140, 65–99 (2021)
Reynolds, D.A., Quatieri, T.F., Dunn, R.B.: Speaker verification using adapted Gaussian mixture models. Digit. Signal Process. 10(1–3), 19–41 (2000)
Kenny, P., et al.: Joint factor analysis versus eigenchannels in speaker recognition. IEEE Trans. Audio Speech Lang. Process. 15(4), 1435–1447 (2007)
Kenny, P., et al.: A study of interspeaker variability in speaker verification. IEEE Trans. Audio Speech Lang. Process. 16(5), 980–988 (2008)
Dehak, N., et al.: Cosine similarity scoring without score normalization techniques. Odyssey (2010)
Matějka, P., et al.: Full-covariance UBM and heavy-tailed PLDA in I-vector speaker verification. In: 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE (2011)
Dehak, N., et al.: Front-end factor analysis for speaker verification. IEEE Trans. Audio Speech Lang. Process. 19(4), 788–798 (2010)
Dev, A., Bansal, P.: Robust features for noisy speech recognition using MFCC computation from magnitude spectrum of higher order autocorrelation coefficients. Int. J. Comput. Appl. 10(8), 36–38 (2010)
Farahani, G., Ahadi, S.M.: Robust features for noisy speech recognition based on filtering and spectral peaks in autocorrelation domain. In: 2005 13th European Signal Processing Conference, pp. 1–4. IEEE (2005)
Shan, Z., Yang, Y.: Scores selection for emotional speaker recognition. In: Tistarelli, M., Nixon, M.S. (eds.) ICB 2009. LNCS, vol. 5558, pp. 494–502. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-01793-3_51
Lau, L.: This is a sample template for authors. J. Digit. Forensics Secur. Law 9(2), 1–2 (2014)
Farahani, G.: Autocorrelation-based noise subtraction method with smoothing, overestimation, energy, and cepstral mean and variance normalization for noisy speech recognition. EURASIP J. Audio Speech Music Process. 2017(1), 1–16 (2017). https://doi.org/10.1186/s13636-017-0110-8
Bibish Kumar, K.T., Sunil Kumar, R.K.: Viseme identification and analysis for recognition of Malayalam speech intense background noise. Ph.D. thesis (2021)
Kim, J., et al.: Extended U-net for speaker verification in noisy environments. arXiv:2206.13044v1 (2022)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Aljinu Khadar, K.V., Sunil Kumar, R.K., Sreekanth, N.S. (2024). Adapting to Noise in Forensic Speaker Verification Using GMM-UBM I-Vector Method in High-Noise Backgrounds. In: Aurelia, S., J., C., Immanuel, A., Mani, J., Padmanabha, V. (eds) Computational Sciences and Sustainable Technologies. ICCSST 2023. Communications in Computer and Information Science, vol 1973. Springer, Cham. https://doi.org/10.1007/978-3-031-50993-3_22
Download citation
DOI: https://doi.org/10.1007/978-3-031-50993-3_22
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-50992-6
Online ISBN: 978-3-031-50993-3
eBook Packages: Computer ScienceComputer Science (R0)