
Abstract
In this chapter we introduce methods for evaluating Feynman loop integrals. We introduce basic methods such as Feynman and Mellin parametrisations, and present a number of one-loop examples. Working in dimensional regularisation, we discuss ultraviolet and infrared divergences. We then introduce special functions encountered in loop calculations and discuss their properties. Focusing on their defining differential equations, we show how the symbol method is a useful tool for keeping track of functional identities. We then connect back to Feynman integrals by showing how differential equations can be effectively used to read off the special functions appearing in them. In particular, we discuss residue-based methods that streamline such computations.
You have full access to this open access chapter, Download chapter PDF
4.1 Introduction to Loop Integrals
Feynman integrals play a crucial role in quantum field theory, as they often arise when seeking to make perturbative predictions. As such, it is important to understand how to evaluate them or at least have some knowledge of their behaviour. One example of where Feynman integrals appear is in the study of correlation functions in position space. At the loop level, these integrals depend on the positions of the operators. Another example is the computation of anomalous dimensions of composite local operators, which are of particular interest due to their dependence on the coupling constant. In momentum space, Feynman integrals also appear in the calculation of scattering amplitudes and other on-shell processes. Feynman integrals also have applications in other areas, such as gravitational wave physics and cosmology. While the specific types of integrals may vary in these different scenarios, methods known from particle physics are often applicable. In particular, the differential equation method discussed in this chapter has already proven to be useful in these areas.
One key point is that we can gain insight into these loop integrals by examining the properties of their rational integrands. We have a lot of knowledge about these rational functions and how to analyse them, such as through recursion relations or generalised unitarity. The challenge is to understand what happens when we perform the \(D-\)dimensional, or four-dimensional, integration over internal loop momenta. This transforms the rational functions into special functions, such as logarithms, polylogarithms, and their generalisations. It is interesting to consider how the properties of these special functions come from the integrand and how we can utilise this understanding. We will discuss their properties and how to best think about them. We will explore the connection between Feynman integrals and differential equations. We will learn how to apply the differential equation method and how to use hints from the integrands to simplify the procedure.
This chapter is organised as follows. Section 4.2 quickly recalls prerequisites from quantum field theory and establishes conventions. For background material, we refer to standard textbooks, such as [1]. For a general and more extensive introduction to Feynman integrals, we refer to the useful book [2] and the very comprehensive monograph [3]. Both of these references contain many further specialised topics that go beyond the scope of these lecture notes. In Sect. 4.4 we discuss relevant special functions from a differential equation viewpoint that facilitates seeing the connection to Feynman integrals. In Sect. 4.5 we then discuss the differential equations method for Feynman integrals. This chapter is complementary to the lecture notes [4].
We cover the following topics: conventions, Feynman parametrisation, Mellin-Barnes representation. We introduce two one-loop examples of Feynman integrals that will be useful throughout this chapter: the two-dimensional massive bubble integral, and the four-dimensional massless box integrals, that are relevant to the scattering processes discussed in the rest of these lecture notes.
4.2 Conventions and Basic Methods
4.2.1 Conventions for Minkowski-Space Integrals
Unless otherwise stated, integrals are defined in Minkowski space with “mostly-minus” metric, i.e. \(\eta _{\mu \nu }=\text{diag}(+,-,-,-)\) in four dimensions. When discussing quantities in general dimension D, likewise we take the metric to be \(\eta _{\mu \nu }=\text{diag}(+,-,\ldots ,-,-)\). Up to overall factors, the momentum-space Feynman propagator in D dimensions for a particle of mass m and with momentum p reads
Here the Feynman prescription “\(\mathrm {i} 0\)” stands for a small, positive imaginary part that moves the poles of the propagator off the real axis. It is important for causality.
Kinematics
Momentum-space Feynman integrals depend on external momenta and other parameters such as masses of particles. The external momenta are usually denoted by \(p_{i}\), \(i=1,\ldots , n\). The Feynman integrand depends on these momenta, and in addition on loop momenta, that are integrated over. The result of the integration depends on the external momenta via Lorentz invariants, such as \(p_i \cdot p_j = \eta _{\mu \nu } p^{\mu }_{i} p^{\nu }_{j}\), where \(\eta _{\mu \nu }\) is the metric tensor, for example.
At loop level, one encounters integrals over loop momenta, with the integrand being given by propagators and possibly numerator factors. Let us begin by discussing the loop integrals with trivial numerators first.
In order to explain how to define integrals in D-dimensional Minkowski space, we begin with the following example:
where \(k = (k_0, \mathbf {k})\). We will see presently what range of the parameters D and a is allowed for the integral to converge. Consider the integration over \(k_{0}\). We see that there are two poles in the complex \(k_{0}\) plane, at \(k_{0}^\pm = \pm \sqrt { {\mathbf {k}}^2+m^2 } \mp \mathrm {i} 0\).Footnote 1 We can rotate the contour of integration for \(k_{0}\) in the complex plane (Wick rotation) so that the integration contour becomes parallel to the imaginary axis, \(k_{0} = \mathrm {i} k_{0,E}\). This is done in a way that avoids crossing the propagator poles, see Fig. 4.1. Defining a Euclidean D-dimensional vector \(k_E = (k_{0,E},\mathbf {k})\) we arrive at

Wick rotation: the \(k_{0}\) integration contour is rotated from being parallel to the horizontal axis, to being parallel to the vertical axis, avoiding the propagator poles (which have a small imaginary part due to the Feynman \(\mathrm {i} 0\) prescription)
This is now in the form of a Euclidean-space integral, and we could drop the \(\mathrm {i} 0\) prescription. For integer D, this integral can be carried out using the following three steps. First, we write the propagator in the Schwinger parametrisation,
This formula can also be interpreted as the definition of the \(\mathnormal {\varGamma }\) function, which we will encounter frequently in the context of Feynman integrals. Note that the RHS of Eq. (4.4) is well-defined for \(a>0\). Second, we use Gaussian integral formula,
to carry out the D-dimensional loop integration over k (assuming integer D). Third, we use Eq. (4.4) again, to obtain
Note that the dependence on \(m^2\) in Eq. (4.6) could have been determined in advance by dimensional analysis. Another simple consistency check can be performed by differentiating w.r.t. \(m^2\), which gives a recursion relation in a.
Useful Convention Choices
We follow the conventions of [2], which helps to sort out many trivial factors of \(-1, \mathrm {i},\) and \(\pi \).
-
Choice of loop integration measure. Our choice of \({\mathrm {d}^{D}k}/({\mathrm {i} \pi ^{D/2}})\) has the following desirable features. Firstly, the factor of \(\mathrm {i}\) disappears after Wick rotation, and secondly the factors of \(\pi \) compensate for the “volume factor” from the D-dimensional Gaussian integration (4.5). Experience shows that our definition of loop measure is natural from the viewpoint of transcendental weight properties to be discussed later, and in particular the occurrences of \(\pi \) that appear after integration have a less trivial origin.
-
Choice of “effective coupling”. Note that the above choice of measure differs from the factor of \((2 \pi )^{-D}\) that Feynman rules give per loop, so we recommend splitting this factor up when defining the loop expansion. Often one organises the perturbative expansion in terms of an “effective” coupling, such as \(g_{\mathrm {YM}}^2/\pi ^2\) in four-dimensional Yang-Mills theory, to absorb factors of \(\pi \). In QCD, \(\alpha _s = g_{\mathrm {QCD}}^2/(4 \pi )\) is commonly used.
-
Choice of propagator factors. We included a minus sign in the propagator on the LHS of Eq. (4.6). This avoids minus signs on the RHS, and has the effect that, for certain integrals, the RHS is positive definite for certain values of the parameters. Equation (4.6) is a case in point.
When dealing with massless particles, we may also encounter the situation where we need to evaluate the RHS of Eq. (4.6) for \(m=0\). In this case, the only answer consistent with scaling is zero (for \(a -D/2\neq 0\)). We therefore set all scaleless integrals in dimensional regularisation to zero.
4.2.2 Divergences and Dimensional Regularisation
The derivation of Eq. (4.6) assumed integer D (and a). Moreover, when considering the convergence conditions for the different computational steps, we find the conditions \(a>0\) and \(a-D/2>0\). We can also see this by inspecting the arguments of the \(\mathnormal {\varGamma }\) functions in the final formula (4.6). So, for example, the integral is well-defined for \(a=3, D=4\). It will be important in the following to extend the range of validity to non-integer values of a and D, and beyond the range indicated by the inequalities. But what is meant by integration for fractional dimension D? Since we know the answer only for integer D, the analytic continuation is not unique. Therefore we need to make a choice. We can do so by taking the RHS of Eq. (4.6) as the definition for the integral in D dimensions. As we will see, all other, more complicated, integrals can be related to this one.
One of the main motivations for defining integrals for non-integer D is that in quantum field theory one frequently encounters divergences. Ultraviolet (UV) divergences are well known from textbooks. They are related to renormalisation of wavefunctions, masses and the coupling in QFT, and as such play an important role in making the theory well-defined. Beyond that, they can also lead to coupling-dependent scaling dimensions of operators in QFT, which are relevant for example in strong interaction physics, for example, or in describing critical phenomena in condensed matter physics. While in principle ultraviolet divergences could be dealt with by introducing certain cutoffs, it is both practically and conceptually very convenient to regularise them dimensionally, i.e. by setting \(D=4-2\epsilon \), for \(\epsilon >0\) (see the discussion on power counting in Chap. 3), and by considering the Laurent expansion as \(\epsilon \) is small.
Another type of divergences are infrared (IR) ones. These can occur when on-shell processes involving massless particles are considered. One way of thinking about this is to start from UV-finite momentum-space correlation functions in general kinematics, and then to specialise them to on-shell kinematics, for example by setting \(p_i^2=0\) in the case of external massless particles. In general, this leads to a new type of divergence. The most common case corresponds to the following regions of loop momenta: soft (all components of the loop momentum are small) and collinear (a loop momentum becomes collinear to an external on-shell momentum). The behaviour of loop integrands in these configurations is closely related to the properties of tree-level amplitudes discussed in Sect. 2.1. Such infrared divergences can also be treated within dimensional regularisation, but with with \(\epsilon <0\).Footnote 2
4.2.3 Statement of the General Problem
The main goal is the computation of Feynman integrals, represented by the function F, which depend on various parameters such as momenta \(p_i\) and masses \(m_j\), and on the number of space-time dimensions D:
These integrals are defined in D dimensions, where \(D=4-2 \epsilon \) in dimensional regularisation. The method we discuss can be applied to a range of theories and models, though the complexity of the result increases with the number of parameters considered.
As an example, consider a scattering process involving incoming and outgoing particles, for which we want to compute the corresponding Feynman integrals. To approach this problem, we will start with special functions that are known to appear in certain calculations and then generalise from there. For one-loop calculations in four dimensions, it has been observed that apart from logarithms, only a class of functions called dilogarithms are needed. We will discuss the latter in more detail in Sect. 4.4. Consider a Feynman integral F that depends on \(D=4-2 \epsilon \) and has a small \(\epsilon \) expansion
Since we are ultimately interested in finite results for four-dimensional observables, we can typically truncate the expansion at a certain order \(j_{\mathrm {max}}\) and discard the higher order in \(\epsilon \) terms.
For example, in the case of one-loop amplitudes, the leading term is a double pole (\(j_{0}=-2\)), and one might neglect evanescent terms—that is, terms which vanish in \(D=4\) dimensions—by setting \(j_{\mathrm {max}}=0\). In this case, it is known that only logarithms and dilogarithms are needed to express the answer.
Let us consider a generic one-loop scalar n-point Feynman integral, as in Chap. 3,
see Fig. 3.2, where the external momenta \(p_{i}\) may or may not satisfy on-shell conditions. It is convenient to introduce dual, or region coordinates\(x_i\). Each dual coordinate labels one of the regions that the Feynman diagram separates the plane into, as in Fig. 4.2.Footnote 3 The momentum flowing in each of the edges of the graph is then given by the difference of the coordinates of the adjacent dual regions,
with the identification \(x_{j+n} \equiv x_{j}\). Then the integral above takes the simple form
where \(x_{ij} := x_{i} - x_{j}\). Translation invariance in the dual space corresponds to the freedom of redefining the loop integration variables k in the initial integral. Momentum conservation implies that the external momenta form a closed polygon in dual space, with the vertices being the dual coordinates \(x_{i}\) and the edges being the momenta \(p_{i}\).

Generic one-loop n-point Feynman diagram and dual coordinates x. The latter denote the different dual regions
4.2.4 Feynman Parametrisation
It is often convenient to exchange the integration over space-time for parametric integrals. Formulae for doing so for general Feynman integrals are given in ref. [2].
The idea of Feynman parametrisation is to exchange the space-time integration for a certain number of auxiliary integrations (over Feynman parameters). This can be done systematically. Let us show how it is done explicitly at one loop. The starting point is the general one-loop integral given in Eq. (4.11). The goal is to relate this to the case in Eq. (4.6), by introducing auxiliary integration parameters.
This method is closely related to the Schwinger formula (4.4) encountered earlier. The Feynman trick is based on the following identity:
The RHS of this formula requires some explanation. The form on the RHS is invariant under general linear (GL) transformations, i.e. arbitrary rescalings of \(\alpha _1\) and \(\alpha _2\). The measure \({\mathrm {d}\alpha _1 \mathrm {d}\alpha _2}/{\mathrm {GL}(1)}\) means that one “mods out” by such transformations, so that in effect the integration is only one-dimensional. For example, one could fix \(\alpha _2 = 1\), upon which the integration measure becomes \(\int _0^\infty \mathrm {d}\alpha _1\). Another common choice is to set \(\alpha _1 + \alpha _2 = 1\). In other words, modding out by the \(\mathrm {GL}(1)\) transformations amounts to inserting a Dirac \(\delta \) function —e.g. \(\delta (\alpha _1+\alpha _2-1)\) or \(\delta (\alpha _2-1)\)—under the integral sign in Eq. (4.12).
Feynman integrals typically have many propagators (corresponding to the number of edges), so we need a generalisation of Eq. (4.12) to an arbitrary number n of denominator factors:
This can be shown by mathematical induction.
Applying Eq. (4.13) to the one-loop formula (4.11) yields an integral over a single factor in the integrand. By performing a change of variables in the integration variables k, this can be brought into the form of Eq. (4.6), and hence the space-time integration can be performed (see Exercise 4.1 for an example). The result is
where \(U = \sum _{i=1}^{n} \alpha _{i}\) and \(V = \sum _{i<j} \alpha _i \alpha _j (-x_{ij}^2)\). These polynomials, called Symanzik polynomials, have a graph-theoretical interpretation, see e.g. [2]. Consider the graph corresponding to the propagators forming the loop, where an edge corresponding to a denominator \(X_i\) has label \(\alpha _i\). Then, consider all ways of removing a minimal number of lines so that the graph becomes a tree. To each such term, associate the product of \(\alpha _i\) factors of the removed factors. Summing over all such terms gives U. Similarly, to define V , one considers all ways of removing factors to obtain two trees, and again takes the products of the \(\alpha _i\), but this time weighted by (minus) the momentum squared flowing through these lines, which yields \(-\alpha _i \alpha _j x_{ij}^2\) at one loop.
Depending on the situation, different choices of fixing the \(\mathrm {GL}(1)\) invariance in Eq. (4.14) may be particularly convenient. One may fix \(U=1\), for example, or alternatively one may set one of the Feynman parameters \(\alpha _i\) to 1.
Exercise 4.1 (The Massless Bubble Integral)
Consider the bubble integral, cf. Fig. 4.3a, with massless propagators but generic propagator powers:
-
(a)
Use the identity (4.12) to write down the Feynman parameterisation. Verify that it matches the general formula (4.14), and read off the Symanzik polynomials.
Fig. 4.3 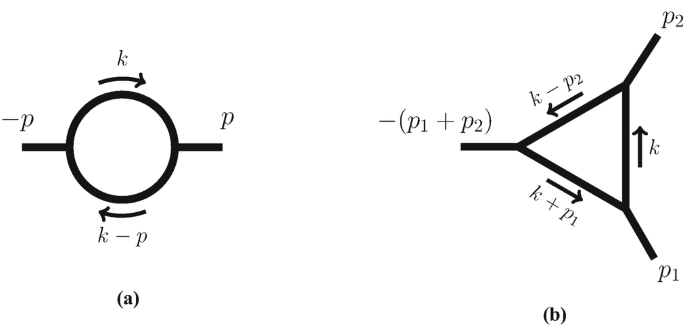
Bubble and triangle Feynman integrals discussed in the main text. The arrows denote the direction of the momenta
-
(b)
Show that the integral evaluates to
$$\displaystyle \begin{aligned} {} F_{2}\left( a_1,a_2 ; D \right) = B\left(a_1, a_2 \right) \, \bigl(-p^2 - \mathrm{i} 0 \bigr)^{\frac{D}{2}-a_1-a_2} \,, \end{aligned} $$(4.16)with
$$\displaystyle \begin{aligned} {} B\left(a_1,a_2 ; D\right) = \frac{\mathnormal{\varGamma}\left(a_1+a_2-\frac{D}{2}\right) \mathnormal{\varGamma}\left(\frac{D}{2}-a_1\right) \mathnormal{\varGamma}\left(\frac{D}{2}-a_2\right)}{\mathnormal{\varGamma}\left(a_1\right) \mathnormal{\varGamma}\left(a_2\right) \mathnormal{\varGamma}\left(D-a_1-a_2\right)} \,. \end{aligned} $$(4.17)
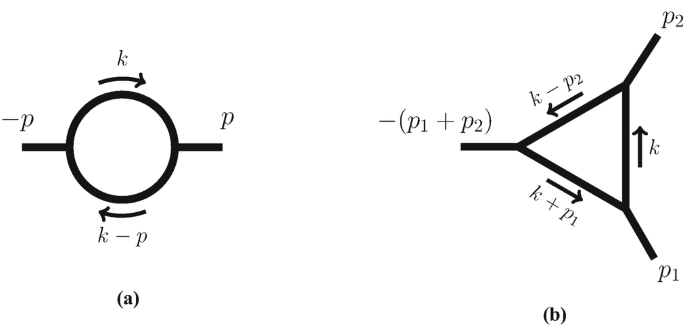
For the solution see Chap. 5.
Example: Infrared-Divergent Massless Triangle Integral
As an example of the one-loop Feynman parameter formula (4.14), let us consider the massless on-shell triangle diagram of Fig. 4.3b,
In order to use Eq. (4.14), we need to match the kinematics to the general notation used there. Note that Eq. (4.18) is a special case of Eq. (4.11) with \(n=3\) and the following choices: zero particle masses \(m_1=m_2=m_3=0\), and unit propagator exponents \(a_1 = a_2= a_3 =1\). Moreover, we consider the massless on-shell conditions \(p_{1}^2= p_{2}^2 = 0\), so that the integral depends on the dimensionful variable \(s = (p_{1}+p_{2})^2\), and on D. Translating this to dual coordinates, we have \(x_{12}^2= 0, x_{23}^2=0, x_{13}^2 =s\).
Exercise 4.2 (Feynman Parametrisation)
Draw the triangle diagram in Eq. (4.18) using both the momentum-space and the dual-space labelling, and verify the above identification of variables. Use this to write down the Feynman parametrisation for \(F_{3}\). For the solution see Chap. 5.
Having established this notation, we can readily employ our main one-loop formula 4.14. Setting \(D=4-2 \epsilon \), it gives
For simplicity, let us consider the so-called Euclidean kinematic region, where \(s<0\). In this case, we see that the denominator on the RHS is positive, and therefore the \(\mathrm {i} 0\) prescription is not needed. Later we may be interested in analytically continuing the integral to other kinematic regions. Noticing that the \(\alpha \)-parameter polynomial multiplying \(-s\) is positive, we can conveniently record the information on the correct analytic continuation prescription by giving a small imaginary part to s: \(s \to s + \mathrm {i} 0\). In the present case, the dependence on s is actually trivial: it is dictated by the overall dimensionality of the integral. This implies that \(F_3\) depends on s as \((-s-\mathrm {i} 0)^{-1-\epsilon }\).
Let us comment on the convergence properties of Eq. (4.19). The expression is valid for \(\epsilon <0\). This is consistent with our expectations, since this integral is UV-finite (see the power counting in Eq. (3.12)) but has IR divergences. The integral would actually be finite for \(p_1^2 \neq 0, p_2^2 \neq 0\). For on-shell kinematics \(p_1^2=p_2^2=0\), one can see there are problematic regions of loop momentum in Eq. (4.18) that lead to divergences when integrating in \(D=4\) dimensions. The soft region occurs when all components of k in Eq. (4.18) are small. On top of this, there are two collinear regions, where \(k \sim p_1\) and \(k\sim p_2\), respectively. One may convince oneself by power counting (see e.g. [5] for more details) that these regions lead to logarithmic divergences (\(1/\epsilon \) in dimensional regularisation). Moreover, each collinear region overlaps with the soft region, so that the divergences can appear simultaneously. We therefore expect the leading term of \(F_3\) as \(\epsilon \to 0\) to be a double pole \(1/\epsilon ^2\).
Let us now verify this explicitly. In order to carry out the \(\alpha \) integrals we introduce the following useful formula,
Applying this to Eq. (4.19), for \(b_1=-\epsilon , b_2 = 1, b_3=-\epsilon \), we find
We wish to expand this formula for small \(\epsilon \). To do so, we need to familiarise us with the properties of the \(\mathnormal {\varGamma }\) function.
Important Properties of the Γ$$\mathnormal {\varGamma }$$ Function
In the calculation above we encountered a first special function, the \(\mathnormal {\varGamma }\) function. It is defined as
This formula converges for \(x >0\). To define \(\mathnormal {\varGamma }(x)\) for complex x, one uses analytic continuation. Here we collect several important properties of the \(\mathnormal {\varGamma }\) function. It satisfies the recurrence
It has the expansion
for \(|x|<1\). Here, Euler’s constant is
and Riemann’s zeta constants appear,
For even n, these evaluate to powers of \(\pi \), e.g. \(\zeta _2 = \pi ^2/6\) and \(\zeta _{4} = \pi ^4/90\).
Using the expansion (4.24), as well as Eq. (4.23), we find
Here we multiplied \(F_{3}\) by a factor of \(\mathrm {e}^{\epsilon \gamma _{\mathrm {E}}}\) (in general, one takes one such factor per loop order), in order to avoid the explicit appearance of \(\gamma _{\mathrm {E}}\) in the expansion.
Exercise 4.3 (Taylor Series of the Log-Gamma Function)
In this guided exercise we prove the Taylor series of the Log-Gamma function in Eq. (4.24). The Taylor series of \(\log \mathnormal {\varGamma }(1+x)\) around \(x=0\) is given by
The first-order derivative by definition gives Euler’s constant \(\gamma _{\text{E}}\) (4.25). In order to compute the higher-order derivatives, we derive a series representation for the digamma function\(\psi (x)\), i.e. the logarithmic derivative of the gamma function,
-
(a)
Prove the following recurrence relation for the digamma function,
$$\displaystyle \begin{aligned} {} \psi(x+n) = \psi(x) + \sum_{k=0}^{n-1} \frac{1}{x+k} \,, \qquad n \in \mathbb{N}\,. \end{aligned} $$(4.30) -
(b)
Prove the following series representation of the digamma function,
$$\displaystyle \begin{aligned} {} \psi(x) = - \gamma_{\text{E}} - \sum_{k=0}^{\infty} \left(\frac{1}{x+k}-\frac{1}{1+k} \right) \,. \end{aligned} $$(4.31)Hint: study the limit of \(\psi (x+n)-\psi (1+n)\) for \(n\to \infty \) using Stirling’s formula,
$$\displaystyle \begin{aligned} {} \mathnormal{\varGamma}(x+1) = \sqrt{2 \pi x} \, x^x \, \text{e}^{-x} \left[1 + \mathcal{O}\bigl(1/x\bigr) \right] \,. \end{aligned} $$(4.32) - (c)
For the solution see Chap. 5.
Example: Ultraviolet Divergent Bubble Integral
An important example throughout this chapter will be the one-loop massive bubble integral. The integral is defined as
The integrated function depends on the external momentum p via the Lorentz invariant \(s=p^2\). This is a special case of Eq. (4.11) with \(n=2\), with uniform internal masses \(m_1=m_2=m\), with unit propagator powers \(a_1=a_2=1\), and with the single kinematic variable \(x_{12}^2=p^2\). In slight abuse of notation, we denote this integral by the same letter \(F_2\) as we did for the massless bubble integral above.
Applying Eq. (4.14), we find
Just as in the triangle example above, we see that the integrand in this formula is positive definite in the Euclidean region \(s<0, m>0\), and that we can absorb the \(\mathrm {i} 0\) prescription into s. We see that \(\mathnormal {\varGamma }(2-D/2)\) is divergent for \(D \to 4\), and requires \(D<4\) for convergence. The parameter integral is instead well-defined for \(D=4\). Therefore we can compute the integral for \(D=4-2\epsilon \), with \(\epsilon >0\). In the limit \(\epsilon \to 0\), we find
This divergence is of ultraviolet origin. As we discussed in Chap. 3, we can understand it by doing power counting in the momentum-space representation (4.33). Consider the integrand for large loop momentum k. Switching to radial coordinates, the integration measure becomes \(\mathrm {d}^{D}k = r^{D-2} \mathrm {d} r \, \mathrm {d}\mathnormal {\varOmega }\), where r is the radial direction, and \(\mathnormal {\varOmega }\) represents the angular integrations. At large r, the integrand goes as \(\mathrm {d} r/r^{D-4}\). This converges for \(D<4\), but leads to a logarithmic divergence at \(D=4\). This is exactly what Eq. (4.35) encodes. With the same power counting, we see that the integral in Eq. (4.33) is finite in \(D=2\).
Exercise 4.4 (Finite Two-Dimensional Bubble Integral)
Starting from the Feynman parametrisation in Eq. (4.34), carry out the remaining integration for \(D=2\), for the kinematic region \(s<0, m^2>0\), to find
Hint: employ the change of variables \(-s/m^2 = (1-x)^2/x\), with \(0<x<1\). For the solution see Chap. 5.
We will also be interested in the dimensionally-regularised version of Eq. (4.33), i.e. the deformation where \(D=2-2 \epsilon \). This is interesting for several reasons. Firstly, we have seen in Chap. 3 that integrals in dimensions D and \(D\pm 2\) are related by certain recurrence relations, see Eq. (3.184) at one-loop order [6]. Secondly, this integral for \(D=2-2\epsilon \) will serve as a main example for understanding integration techniques in this chapter.
Before closing this section, let us mention the L-loop generalisation of Eq. (4.14).
Feynman Parametrisation for a ScalarL-Loop Feynman Diagram
Consider now an L-loop scalar Feynman integral with n denominator factors. The graph may be planar or non-planar. As before, we label the i-th factor (which may have a generic mass \(m_i^2\) and is raised to a power \(a_i\)) by the Feynman parameter \(\alpha _i\). Then, the generalisation of Eq. (4.14) is given by
Here \(a= \sum _i a_i\), and the Symanzik polynomials U and V have the same graph theoretical definition mentioned above. They have been implemented in various useful computer programs, for example [6].
4.2.5 Summary
In this section, we introduced conventions and notations for Feynman integrals. The integrals are initially defined as space-time integrals, but other representations are also useful. We showed how Feynman representations are obtained. We discussed a number of sample one-loop integrals, and showed how ultraviolet and infrared divergences are treated in dimensional regularisation. We also saw first examples of special functions appearing in the integrated answers, namely the \(\mathnormal {\varGamma }\) function and the logarithm. In the next sections, we introduce the Mellin-Barnes method, which will allow us to go beyond the cases treated so far, and see first examples of polylogarithms. After that we discuss more systematically special functions appearing in Feynman integrals, and propose a useful way for thinking about them in terms of their defining differential equations.
4.3 Mellin-Barnes Techniques
In the previous section we saw how to derive parameter-integral formulae for Feynman integrals. For a triangle diagram we derived the complete analytic answer by carrying out the parameter integrals, and we did the same for the finite two-dimensional massive bubble integral. In general, it is difficult to carry out the Feynman parameter integrals directly (see however interesting work in this direction, together with powerful algorithms [7]).
Another useful representation trades the Feynman parameter integrals for Mellin-Barnes integrals, as we describe presently. The resulting Mellin-Barnes representations makes certain properties of the integrals easier to see as compared to the Feynman parameter integrals. In particular, useful algorithms have been developed to resolve singularities in \(\epsilon \) and to provide representations of the terms in the Laurent expansion of the Feynman integrals. The key formula is the following,
where the integration contour is parallel to the imaginary axis, with real part c in the interval \(-a<c<0\). See Fig. 4.4. In general, the integration contour is chosen such that the poles of \(\mathnormal {\varGamma }\) functions of the type \(\mathnormal {\varGamma }(z+\ldots )\) lie to its left, and the poles of \(\mathnormal {\varGamma }(-z+\ldots )\) lie to its right.

Integration contour for Mellin-Barnes representation in Eq. (“refMB˙basic). The integration contour (dashed line) goes parallel to the vertical axis, with \(\mathrm {Re}(z)=c\), with \(-a<c<0\), i.e. to the right of the poles of \(\mathnormal {\varGamma }(-z)\), and to the left of the poles of \(\mathnormal {\varGamma }(z+a)\) (shaded area)
One can verify the validity of Eq. (4.38) by checking that the series expansions of its LHS and RHS agree. Let us see this in detail. Assume \(x<y\). Then the LHS of Eq. (4.38) has the following series representation,
Let us see how this arises from the RHS of Eq. (4.38). If \(x<y\) we can close the integration contour in Eq. (4.38) on the right, because the contribution from the semicircle at infinity vanishes. By complex analysis, we get a contribution from (minus) all poles of \(\mathnormal {\varGamma }(-z)\) situated at \(z_{n} = n\), with \(n = 0, 1, \ldots \). Taking into account that the corresponding residues are \(\text{Res}[\mathnormal {\varGamma }(-z), \, z=n]=(-1)^{n+1}/n!\) (see Exercise 4.5), one readily reproduces Eq. (4.39). One may verify similarly the validity of Eq. (4.38) for \(y<x\). In this case, one closes the integration contour on the left.
Equation (4.38) can be used to factorise expressions, e.g. the denominator factors appearing in Feynman parametrisation. Once factorised, Eq. (4.20) allows one to carry out the Feynman parameter integrals. In some sense, the Mellin-Barnes representation can therefore be considered the inverse of the Feynman parametrisation. Of course, this means that one is just trading one kind of integral representation for another. However, the Mellin-Barnes representation is very flexible, and has a number of useful features, as we will see shortly.
Exercise 4.5 (Laurent Expansion of the Gamma Function)
The Gamma function \(\mathnormal {\varGamma }(z)\) is holomorphic in the whole complex plane except for the non-positive integers, \(z=0,-1,-2,\ldots \), where it has simple poles.
-
(a)
Compute the Laurent expansion of \(\mathnormal {\varGamma }(z)\) around \(z=0\) up to order z,
$$\displaystyle \begin{aligned} {} \mathnormal{\varGamma}(z) = \frac{1}{z} - \gamma_{\text{E}} + \frac{z}{2}\left(\gamma_{\text{E}}^2 + \zeta_2\right) + \mathcal{O}\left(z^2 \right)\,. \end{aligned} $$(4.40) -
(b)
Using Eq. (4.40), show that the Laurent expansion of \(\mathnormal {\varGamma }(z)\) around \(z=-n\), with \(n\in \mathbb {N}_0\), is given by
$$\displaystyle \begin{aligned} {} \mathnormal{\varGamma}(z) &= \frac{(-1)^n}{n!} \left\{ \frac{1}{z+n} + H_n-\gamma_{\text{E}} \right.\\ &\quad \left.+ \frac{1}{2}(z+n) \left[\left(H_n - \gamma_{\text{E}}\right)^2 + \zeta_2 + H_{n,2} \right] \right\} + \ldots \,, \end{aligned} $$(4.41)where the ellipsis denotes terms of order \((z+n)^2\) or higher. Here, \(H_{n,r}\) is the n-th harmonic number of order r,
$$\displaystyle \begin{aligned} {} H_{n,r} := \sum_{k=1}^n \frac{1}{k^r} \,, \qquad \qquad H_{n} := H_{n,1} \,. \end{aligned} $$(4.42)
For the solution see Chap. 5.
4.3.1 Mellin-Barnes Representation of the One-Loop Box Integral
Let us apply the above procedure to the massless one-loop box integral, cf. Fig. 4.5:
with \(D=4-2\epsilon \). The \(\mathrm {i} 0\) prescription is understood. The external momenta are taken to be on-shell and massless, i.e. \(p_i^2=0\). It is a function of \(s=(p_1 + p_2 )^2\), \(t= (p_2 + p_3)^2 \), and \(\epsilon \). Power counting shows that this integral is ultraviolet finite, but it has soft and collinear divergences. Therefore we expect the leading term to be a double pole in \(\epsilon \), just as for the massless triangle integral computed above.

Massless one-loop four-point Feynman integral considered in the main text
We start by writing down a Feynman parametrisation, using Eq. (4.14),
Here we absorbed the \(\mathrm {i} 0\) prescription into s and t. In the following we take the kinematics to be in the Euclidean region \(s<0,t<0\). We can factorise the first factor of the integrand of Eq. (4.44) at the cost of introducing one Mellin-Barnes parameter integral, using Eq. (4.38). Then, the integral over the \(\alpha \) parameters can be done with the help of Eq. (4.20). We find
with
For the integrations leading to this expression to be well defined, the real part of the arguments of each \(\mathnormal {\varGamma }\) function must be positive. The pole structure of the relevant \(\mathnormal {\varGamma }\) functions is shown in Fig. 4.6. We see that this implies in particular that \(\epsilon <0\), which is expected since the integral is infrared divergent. We can choose e.g.
We will now explain how to analytically continue to \(\epsilon \to 0\).

Poles of the \(\mathnormal {\varGamma }\) functions involved in the Mellin-Barnes parameterisation of the one-loop box integral (“refeq:MBboxM) assuming \(-1<\epsilon <0\). For the integration in Eq. (“refMBbox) to be well defined, the real part of z must lie in the shaded area, between the right-most pole of the \(\mathnormal {\varGamma }\) functions of the type \(\mathnormal {\varGamma }(z+\ldots )\) and the left-most pole of those of the type \(\mathnormal {\varGamma }(-z+\ldots )\)
4.3.2 Resolution of Singularities in \(\epsilon \)
Here we follow ref. [8] and references therein. We saw that the integral in Eq. (4.45) is ill-defined for \(\epsilon = 0\). This can be traced back to the presence of the Gamma functions \(\mathnormal {\varGamma }(1+z)\) and \(\mathnormal {\varGamma }(-1-\epsilon -z)\). The contour for the z integration has to pass between the poles of these Gamma functions, which is only possible for \(\epsilon <0\). In other words, as \(\epsilon \) goes to 0, the shaded area in Fig. 4.6 is pinched between the right-most pole of \(\mathnormal {\varGamma }(1+z)\) and the left-most pole of \(\mathnormal {\varGamma }(-1-\epsilon -z)\). Before we can take the limit \(\epsilon \to 0\), we must therefore deform the integration contour for z, so that it does not become pinched when taking the limit. Let us deform the contour to the right. This leads to a contribution of the residue at \(z=-1-\epsilon \). In other words,
where \(-1-\epsilon < c < 0\). The value of this residue is
where \(\psi (z)\) is the digamma function, defined in Eq. (4.29) of Exercise 4.3.
In the second term, we can safely Taylor expand in \(\epsilon \). We see that it is of \(\mathcal {O}(\epsilon )\), due to the presence of the factor \(\mathnormal {\varGamma }(-2\epsilon )\) in the denominator. Here we keep only this leading term,
where \(-1<c<0\). Therefore, remembering that the residue A in Eq. (4.49) contributes with a minus sign, we find
In Exercise 4.6 we compute also the \(\mathcal {O}(\epsilon )\) term.
The Full\(--++\)Helicity QCD Amplitude
In Chap. 3, the one-loop four-gluon amplitude in the \(++--\) helicity configuration was given in Eq. (3.253) in terms of box and bubble Feynman integrals. Let us denote the ratio of the one-loop and the tree amplitude by
Using the results for the integrals from Eqs. (4.51) and (4.16), we find

Here we have reinstated the dimensional regularisation scale \(\mu _{\mathrm {R}}^2\). We can rewrite this in the following instructive form,

The special form of the poles in \(\epsilon \) in Eq. (4.54) is related to the structure of ultraviolet and infrared divergences in Yang-Mills theories. It is due to the fact that ultraviolet and infrared effects come from separate regions. For an introduction to infrared divergences in Yang-Mills theories, see e.g. ref. [5].
Exercise 4.6 (Massless One-Loop Box with Mellin-Barnes Parametrisation)
Compute the order-\(\epsilon \) term of the function B in Eq. (4.50). Putting the latter together with the Laurent expansion of the residue A in Eq. (4.49) gives the analytic expression of the massless one-loop box integral \(F_4\) up to order \(\epsilon \):
where \(x=t/s>0\). In this result we see for the first time the polylogarithm\(\mathrm {Li}_n(x)\), a special function which arises frequently in the computation of Feynman integrals. For \(|x|<1\), the n-th polylogarithm \(\mathrm {Li}_{n}(x)\) is defined as the power series
The definition can be extended to the rest the complex plane by analytic continuation, e.g. by viewing the polylogarithms as solutions to differential equations. We will take this viewpoint in Sect. 4.4. Note that the first polylogarithm is just a logarithm: \(\mathrm {Li}_{1}(x) = - \log (1-x)\). The second polylogarithm, \(\mathrm {Li}_2\), is typically referred to as dilogarithm. At unit argument, the polylogarithms with \(n\ge 2\) evaluate to Riemann’s zeta constants: \(\mathrm {Li}_n(1) = \zeta _n\). For the solution see Chap. 5.
4.4 Special Functions, Differential Equations, and Transcendental Weight
4.4.1 A First Look at Special Functions in Feynman Integrals
In the previous section, we have already seen a few examples of special functions appearing in Feynman integrals, namely the logarithm and the polylogarithm. We have also encountered special numbers: powers of \(\pi \), as well as other transcendental constants such as \(\zeta _3\). The latter appear on their own, or arise as special values of the special functions, as we see presently.
These transcendental numbers and functions are ubiquitous in quantum field theory. For example, they may appear in anomalous dimensions of local operators, in the \(\beta \) function governing the renormalisation group flow, or in scattering amplitudes. From a structural viewpoint it is very interesting to ask: what transcendental numbers may arise in a given computation? Some of the techniques discussed later in this chapter came together from insights into this and related questions.
A first useful concept is the notion of transcendental weight, or “transcendentality”. Roughly speaking, it describes the complexity of an expression. Rational numbers are assigned weight zero, while \(\pi \) is assigned weight one, and more generally \(\zeta _n\) is assigned weight n. Likewise, the logarithm is assigned weight one, while the polylogarithm \(\mathrm {Li}_n\) is assigned weight n. The first interest in this definition came from two observations. Firstly, in the special \({\mathcal {N}}=4\) super Yang-Mills theory, quantities appear to always have a fixed, uniform weight. Secondly, for certain anomalous dimensions in QCD, which are not uniform in weight, the highest-weight piece agrees with the one computed in \({\mathcal {N}}=4\) super Yang-Mills theory [9]. These first observations stimulated more research that eventually led to a better understanding of transcendental weight, which allows one to predict which Feynman integrals have the maximal weight property. This insight is useful for computing Feynman integrals, as we will discuss below.
We have seen a definition of the polylogarithm in Eq. (4.56). There are many examples of special functions in physics, and usually there exist several equivalent definitions. The same is the case here. In many cases, a definition in terms of a defining differential equation is convenient. We will follow this approach in this section, and will discover that it is very useful in the context of Feynman integrals. Therefore let us first review the functions we encountered so far from this perspective, which is closely related to integral representations, and discuss some of their key properties.
The logarithm can be defined as a single integral:
This equation is defined for real positive x. To extend the definition to complex argument, one places a branch cut along the negative real axis, and defines the answer in the cut complex plane by analytic continuation, i.e. by integrating along a contour from the base point \(x=1\) to the argument \(x \in \mathbb {C} \setminus \{x<0\}\), as shown in Fig. 4.7.

Integration contour to extend the definition of the logarithm to the complex plane with the branch cut along the negative real axis removed, as indicated by the zig-zag line
From Eq. (4.57) we can simply read off the derivative,
and we have \(\log 1 = 0\). Dilogarithms can be defined in a similar way, but with two integrals instead of one:
One may verify that this agrees with the series representation (4.56) by Taylor expanding the integrand in t. From this we can read off the derivatives,
as well as the special value \(\mathrm {Li}_{2}(0) = 0\). Like the logarithm, the dilogarithm \(\mathrm {Li}_2(x)\) is a multi-valued function. Its branch points are at \(x=1\) and infinity. Following the convention of the logarithm, the branch cut is along the positive real axis between \(x=1\) and infinity (see Exercise 4.7). For more information about the dilogarithm, see [10].
We have seen that this, as well as the trilogarithm encountered above, are part of a larger class of polylogarithms, defined in terms of series in Eq. (4.56). In the following, it will be useful to think of these functions in terms of iterated integrals. To establish the connection, we note that
which follows straightforwardly from Eq. (4.56). Therefore we can write
All polylogarithms \(\mathrm {Li}_{n}(x)\) are multi-valued functions, with a branch cut along the positive real axis between \(x=1\) and infinity. Note that we can think of all those functions as iterated integrals over certain logarithmic integration kernels: \(\mathrm {d} x/x\) and \(\mathrm {d} x/(x-1)\). This leads to another way to think about transcendental weight: it corresponds to the number of integrations in such an iterated-integral representation.
Exercise 4.7 (Discontinuities)
The discontinuity of a univariate function \(f(x)\) across the real x axis is defined as
-
(a)
Prove that the discontinuity of the logarithm is given by
$$\displaystyle \begin{aligned} {} \mathrm{Disc}_x \left[\log(x)\right] = 2 \pi \mathrm{i} \, \mathnormal{\varTheta}(-x) \,, \end{aligned} $$(4.65)where \(\mathnormal {\varTheta }\) denotes the Heaviside step function.
-
(b)
The dilogarithm \(\mathrm {Li}_2(x)\) has a branch cut along the real x axis for \(x>1\). Prove that the discontinuity is given by
$$\displaystyle \begin{aligned} {} \mathrm{Disc}_x \left[\text{Li}_2(x)\right] = 2 \pi \mathrm{i} \, \log(x) \, \mathnormal{\varTheta}(x-1) \,. \end{aligned} $$(4.66)Hint: use the identity
$$\displaystyle \begin{aligned} {} \mathrm{Li}_2(x) = - \mathrm{Li}_2(1-x) - \log(1-x) \log(x) + \zeta_2 \,, \end{aligned} $$(4.67)which we shall prove in Exercise 4.9.
For the solution see Chap. 5.
4.4.2 Special Functions from Differential Equations: The Dilogarithm
Let us now see how we can think of these functions conveniently from a differential equations approach. Say we are interested in the function \(\mathrm {Li}_{2}(1-x)\), perhaps because we know that it can appear in a certain calculation. Our goal is to find a defining set of differential equations for this function. Inspecting Eq. (4.61), we see that \(\log (x)\) appears in its derivative, so we consider this function also, as well as the constant 1, which is required to write the derivative of \(\log (x)\). Let us put these key functions into a vector,
A short calculation then shows that the following differential equation is satisfied,
with the matrices
The first-order differential equations (4.69), together with the boundary condition \(\mathbf {f}(x=1) = (0,0,1)^{\top }\), uniquely fix the answer.
Equation (4.69) encodes the singular points \(x=0,1,\infty \) of the functions. As we will see later, the leading behaviour of \(\mathbf {f}(x)\) is governed by the coefficient matrices of those singular points, which are \(A_0,A_1,A_{\infty }=-A_0-A_1\), respectively. The last point can be understood by changing variables to \(y=1/x\), and inspecting the singularity at \(y=0\).
Let us now see how this connects to the concept of transcendental weight. Recall that, when referring to iterated integrals, the weight counts the number of integrations. So the rational constant has weight zero, a logarithm has weight one, the dilogarithm has weight two, and so on. Looking at Eq. (4.68), we see that the different components of \(\mathbf {f}\) have different weight. In order to remedy this, we introduce a weight-counting factor \(\epsilon \), to which we assign the weight \(-1\) [11]. For the moment, this is a purely formal definition. However, later we will see that this is natural in the context of dimensional regularisation.Footnote 4 With the weight-counting parameter \(\epsilon \) at our disposal, we can define
This vector has uniform weight zero by definition. We find that it satisfies the following differential equations:
It is instructive to rewrite this in differential form, as
where \(\mathrm {d}= \mathrm {d} x \frac {\partial }{\partial x}\). We can see that the weights in this equation are consistent: \(\mathrm {d}\) and \(\epsilon \) have weight \(-1\), \(\log \) has weight \(+1\), and the constant matrices \(A_0\) and \(A_1\) have weight zero. Therefore g has weight zero. Since g depends on \(\epsilon \), this means that when expanding in a series around \(\epsilon =0\), the weight of the coefficients increases with the order in \(\epsilon \), starting with weight zero at order \(\epsilon ^0\). This is of course exactly what is expected from Eq. (4.71).
Let us now see how this arises from solving Eq. (4.73). Plugging the ansatz
into the DE, and looking at the different orders in \(\epsilon \), we see that the equations decouple. The first few orders read
at order \(\epsilon ^{0}, \epsilon ^{1}, \epsilon ^{2}\), respectively, and so on. Recalling the boundary condition \(\mathbf {g}(1,\epsilon ) = (0,0,1)^{\top }\), the equations are readily solved, giving
The higher-order equations read \( \partial _x {\mathbf {g}}^{(3)}(x) = A(x) \cdot {\mathbf {g}}^{(2)}(x) =0 \), which lead to \({\mathbf {g}}^{(3)}(x) = (0,0,0)^{\top }\), and similarly at higher orders. In other words, the \(\epsilon \) expansion stops at \(\epsilon ^2\). The reason is that, in this specific case, \(A(x)\) is a nilpotent matrix, i.e., \(A(x)^3 = 0\). This will be different for general Feynman integrals in \(D=4-2\epsilon \) dimensions, but it will not limit the usefulness of the method.
\(\blacktriangleright \)It Is Useful to Think About Special Functions in Terms of Their Defining Differential Equations
Just as in familiar textbook examples from quantum mechanics, differential equations turn out to be a useful way of defining classes of special functions. We shall see later in this chapter that this strategy is particularly effective for Feynman integrals.
4.4.3 Comments on Properties of the Defining Differential Equations
Let us make a number of important comments on the differential equations (4.73) discussed in the last subsection.
-
1.
Fuchsian nature of the singularities. Equation (4.73) has several special features. One of them is the nature of its singularities. We see that the matrices on its RHS have only simple poles at each singular point. It implies that the asymptotic solution near any singular limit, say \(x\to 0\), can be expressed in terms of powers of x and logarithms of x. This type of singularity is called Fuchsian. In contrast, consider differential equations with a non-Fuchsian singularity, e.g.
$$\displaystyle \begin{aligned} {} \partial_x f(x) = \frac{a}{x^2} \, f(x) \,. \end{aligned} $$(4.79)The solution to Eq. (4.79) reads
$$\displaystyle \begin{aligned} f(x) = \mathrm{e}^{-a/x} f_0\,, \end{aligned} $$(4.80)for some boundary constant \(f_0\). This has non-analytic behaviour at \(x=0\), which is not expected from individual Feynman integrals.
We will see in Sect. 4.5 that the Fuchsian property is useful in several regards. Firstly, it may help in finding simple forms of the differential equations. Secondly, analysing the behaviour of the equations near singular points provides crucial information for fixing integration constants based on physical principles, without additional calculations [12]. Thirdly, the asymptotic expansion of an integral in a certain limit can be read off easily from the differential equations.
-
2.
“Gauge dependence” of the differential equations. The differential equations
$$\displaystyle \begin{aligned} {} \partial_x \mathbf{f}(x,\epsilon) = A(x,\epsilon) \cdot \mathbf{f}(x,\epsilon) \end{aligned} $$(4.81)are not unique in the following sense. Consider an invertible matrix \(T(x,\epsilon )\), such that we can define the following change of basis,
$$\displaystyle \begin{aligned} {} \mathbf{f} = T \cdot \mathbf{g} \,. \end{aligned} $$(4.82)Then the new basis \(\mathbf {g}\) satisfies similar differential equations, \(\partial _x \mathbf {g} = B \cdot \mathbf {g}\), with a different matrix
$$\displaystyle \begin{aligned} {} B = T^{-1} \cdot A \cdot T - T^{-1} \cdot \partial_x T \,. \end{aligned} $$(4.83)Note that the “connection matrix” A transforms to B as under a gauge transformation.
For this reason, even if a simple form of the differential equations such as Eq. (4.73) exists, this fact might be obscured if an unfortunate choice of basis is made. In particular, the Fuchsian property mentioned above may be obscured in this way. However, a judicious basis choice can reveal the simplicity of the answer.
For example, consider the following matrix,
$$\displaystyle \begin{aligned} T= {\begin{pmatrix} 1+x & 0 & 1 \\ 1 & -x & 0 \\ 0 & 0 & 1 \end{pmatrix}} \,,\quad \mathrm{with} \quad T^{-1} = {\begin{pmatrix} \frac{1}{1+x} & 0 & -\frac{1}{1+x} \\ \frac{1}{x (1+x)} & -\frac{1}{x} & -\frac{1}{x (1+x)} \\ 0 & 0 & 1 \end{pmatrix}} \,. \end{aligned} $$(4.84)Applying this to \(A= A_0/x + A_1/(x-1)\) with (4.70), we find that Eq. (4.83) evaluates to
$$\displaystyle \begin{aligned} B = {\begin{pmatrix} \frac{1-\epsilon-x}{(x-1)(x+1)} & \frac{\epsilon x}{(x-1)(x+1)} & 0 \\ \frac{1-\epsilon-x}{(x-1)(x+1)x} & \frac{1+\epsilon x-x^2}{(x-1)(x+1)x} & -\frac{\epsilon}{x^2} \\ 0 & 0 & 0 \end{pmatrix}} \,. \end{aligned} $$(4.85)This new form of the DE is far worse compared to the original one, for three reasons. First, the factorised \(\epsilon \)-dependence is lost. Second, there is a spurious divergence at \(x=-1\). Third, the Fuchsian property at \(x=0\) is no longer manifest, due to the \(1/x^2\) term. This example underlines the importance of good guiding principles when dealing with this type of differential equations.
-
3.
Solution as a path-ordered exponential. The analogy with gauge transformations mentioned in point 2 above allows us to write down the solution to the general differential equations (4.81). The latter is given by the following expression
$$\displaystyle \begin{aligned} {} \mathbf{f}(x) = {\mathbb P} \exp\left[ \int_{\mathcal{C}} A(x') \mathrm{d} x' \right] \cdot \mathbf{f}(x_0) \,. \end{aligned} $$(4.86)Here \(\mathcal {C}\) is a path connecting the base point\(x_{0}\) to the function argument x, \({\mathbb P}\) stands for path ordering along this path, and \(f(x_{0})\) is the value of the function at the base point.
In the formal expansion of the matrix exponential appearing in Eq. (4.86), the arguments are evaluated at different points \(x'\) along the path \(\mathcal {C}\). In practice, one may consider the pull-back of the form \(A(x') \mathrm {d} x'\) to the unit interval, parametrised by a parameter \(t\in [0,1]\). The path-ordering then dictates that the matrices are ordered according to the ordering on the unit interval.
Equation (4.86) may be familiar to readers. On the one hand, the path ordering also shows up as time-ordering in the evolution operator in quantum mechanics. On the other hand, somewhat more advanced, it shows up in gauge theory: given a gauge field A, the matrix \( {\mathbb P} \exp \bigl [ \int _{\mathcal {C}} A(x') \mathrm {d} x' \bigr ]\) represents a Wilson line connecting two points \(x_0\) and x, along a contour \(\mathcal {C}\).
This second analogy also makes it clear that Eq. (4.86) enjoys a manifest homotopy invariance: two contours \(\mathcal {C}\) and \(\mathcal {C}'\) (connecting x and \(x_0\)) give the same value, as long as they can be smoothly deformed into each other, without crossing poles of A.
For general A, the RHS of Eq. (4.86) is somewhat formal. However, in the cases considered in these lectures, it can be made very explicit. Firstly, in the dilogarithm example of Sect. 4.4.2, A is nilpotent, and hence the path-ordered exponential has a finite number of terms (and hence number of iterated integrals) only. Secondly, in a later section we propose a method that achieves that \(A \sim \epsilon \), which allows us to write the path-ordered exponential as a Taylor series in \(\epsilon \). This is analogous to a perturbative expansion in the Yang-Mills coupling in gauge theory.
-
4.
Discontinuities (see Exercise 4.7) are also solutions to the differential equations. This is obvious from the form (4.86) of the general solution. Indeed, consider two contours \(\mathcal {C}\) and \(\mathcal {C}'\) that differ by a contour encircling a pole of A. Since both \(\mathcal {C}\) and \(\mathcal {C}'\) are solutions to Eq. (4.81), so is their difference. The latter corresponds to taking a discontinuity of \(\mathbf {f}\). For instance, in our example above (Eq. (4.69)), we may consider two contours \(\mathcal {C}\) and \(\mathcal {C}^{\prime }\) as in Fig. 4.8, with \(\mathcal {C}^{\prime }\) crossing the branch cut starting from \(x=0\). In this case, for \(x\in \mathbb {C} \setminus \{x<0\}\), we find that
$$\displaystyle \begin{aligned} {} \begin{aligned} \mathrm{Disc}_{x=0} \, \mathbf{f}(x) & = \left\{ \mathbb{P} \, \mathrm{exp}\left[\int_{\mathcal{C}} A(x') \mathrm{d} x' \right] - \mathbb{P} \, \mathrm{exp}\left[\int_{\mathcal{C}^{\prime}} A(x') \mathrm{d} x' \right] \right\} \cdot \mathbf{f}(x_0) \\ & = 2 \pi \mathrm{i} \, \begin{pmatrix} -\log(1-x) \\ 1 \\ 0 \end{pmatrix} \,, \end{aligned} \end{aligned} $$(4.87)Fig. 4.8 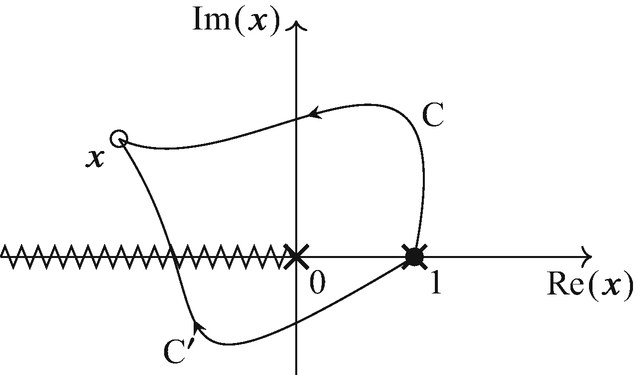
Integration contours for solving the defining DE of the dilogarithm \(\mathrm {Li}_2(1-x)\), Eq. (“refexampleDELi2matrix2). The zig-zag line denotes the branch cut, and the crosses the poles of the connection matrix. The difference between integrating the DE along the two contours gives the discontinuity of the solution
which is equally a solution to Eq. (4.69). This way of defining the discontinuity is more general than the one we have seen in Exercise 4.7 and Chap. 3—which was restricted to the real axis—and is more suitable to functions involving multiple branch points.Footnote 5 For this reason we indicate the branch point in the subscript of the discontinuity in Eq. (4.87). This property of the discontinuity will be useful when analysing Feynman integrals.
-
5.
Relation to Picard-Fuchs equation. The issue raised in the previous point can be addressed in part in the following way. We can trade the first-order system of differential equations for higher-order equations for one of the integrals, called Picard-Fuchs equations [13]. Let us illustrate this for the \(\mathrm {Li}_{2}(1-x)\), which is the first component of \(\mathbf {f}\) in Eq. (4.68). Differentiating \(\mathbf {f}\) multiple times with the help of Eq. (4.69)), one obtains a system of equations, from which one eliminates all functions except \({\mathbf {f}}_{1}\) and its derivatives. In the present case we get
$$\displaystyle \begin{aligned} \partial_x x \partial_x (1-x) \partial_x \mathrm{Li}_{2}(1-x) = 0\,. \end{aligned} $$(4.88)An advantage of this representation as compared to Eq. (4.73) is that it depends only on one function, \(\mathrm {Li}_{2}(1-x)\), and not on the other elements in the vector \(\mathbf {f}\). As such it does not suffer from the gauge dependence mentioned above.
-
6.
Dependence on the weight-counting parameter\(\epsilon \). Recall that we assigned to \(\epsilon \) transcendental weight \(-1\). We saw that when each w-fold iterated integral appearing in the basis \(\mathbf {f}\) was multiplied by a factor \(\epsilon ^w\), then the differential equations had a simple, factorised dependence on \(\epsilon \), cf. Eq. (4.73). Conversely, had we considered linear combinations of mixed weight, or had we not normalised the integrals appropriately, the dependence on \(\epsilon \) would have been more complicated. This is important to bear in mind when applying the above philosophy to Feynman integrals.
-
7.
Uniform weight functions and pure functions. It turns out that the simplicity of the differential equations considered in this chapter can be easily understood. For this it is useful to introduce the following concepts. A uniform weight function is a linear combination of functions of some uniform weight w, with coefficients that may be rational or algebraic functions. An example is
$$\displaystyle \begin{aligned} \frac{1}{1+x} \mathrm{Li}_{2}(1-x) + \frac{x}{1-x} \log^2(1+ x) \,. \end{aligned} $$(4.89)Such a function does not satisfy particularly nice differential equations. The reason is that a derivative \(\partial _x\) can act either on one of the prefactors, or on the transcendental functions. As a result, one obtains a function of mixed transcendental weight. In contrast, consider a pure function, which is a \({\mathbb Q}\)-linear combination of functions of some uniform weight w. An example for \(w=2\) is
$$\displaystyle \begin{aligned} \mathrm{Li}_{2}(1-x) + \log^2(1+ x) \,. \end{aligned} $$(4.90)Its derivative is
$$\displaystyle \begin{aligned} \frac{1}{1-x} \log x + \frac{2}{1+x} \log(1+x) \,, \end{aligned} $$(4.91)which has weight one, i.e. one less than the original function. It is built from two new pure functions, for which we could iterate the differential procedure. In this way one can construct a system of differential equations similar to the one considered above for any pure function. This also generalises naturally to multi-variable functions.

4.4.4 Functional Identities and Symbol Method
We will see that the key properties of the special functions can be encoded in so-called symbols. Roughly speaking, symbols preserve the information on the integration kernels but disregard the integration constants. In this context, the integration kernels are called letters, and their ensemble alphabet. For example, the alphabet associated with the DE (4.73) has two letters: \(\mathrm {d} \log (x)\) and \(\mathrm {d} \log (1-x)\).Footnote 6 Concatenating different alphabet letters into words corresponds to specific iterated integrals. Leveraging the basic addition identity of the logarithm, the symbol technique allows one to detect function identities by simple algebra.
Consider as an example the following function,
Let us consider this for \(x<0\), such that we stay away from branch cuts, and all summands are real-valued. We now wish to show that \(g(x) =0\). It is instructive to do this in the most elementary way, namely to show that \(g'(x) =0\), and that the identity is true at some value of x. Using Eq. (4.61) we have
In the last step, we have assumed \(x<0\), so that we can use \(\log (a b) = \log (a) + \log (b)\) for \(a,b>0\). Moreover, using \(\mathrm {Li}_{2}(-1) = -\pi ^2/12\), one verifies that \(g(-1) = 0\). This completes the proof of the dilogarithm inversion identity \(g(x)=0\).
The symbol method can streamline finding avatars of such identities, i.e. identities up to possibly integration constants. It leverages the fact that we are dealing with iterated integrals, whose integration kernels satisfy the basic logarithm identity
Unlike the analogous identity for the logarithm, Eq. (4.94) holds for any non-vanishing a and b, as \(\mathrm {d} \log c = 0\) for any constant c. Let us now see this in practice, first giving an intuitive explanation, and then a formal definition. Given an iterated integral, say
we read off its logarithmic integration kernels, which are \(\mathrm {d}\log (1-z)\) and \(\mathrm {d}\log (y)\), respectively, and record their arguments in the symbol, denoted by square brackets,
An alternative notation in the literature is \(- (1-x) \otimes x\). We prefer the bracket notation to make it clear that the minus sign in Eq. (4.96) multiplies the symbol, rather than being one of its entries.
Note that the order of integration kernels in the symbol \([\ldots ]\) is opposite to that in the integral representation, Eq. (4.95). Readers might find confusing why the entries of the symbol in Eq. (4.96) depend on x, while in Eq. (4.95) they depend on the (mute) integration variables. To clarify this, we find it best to give the following formal definition of the symbol.
Recursive Symbol Definition for Iterated Integrals
Let \(f^{(w)}\) be a uniform weight-w function whose derivative is given by
where \(c_{i}\) are kinematic-independent constants, \(f_{i}^{(w-1)}\) are uniform weight-\((w-1)\) functions, and \(\alpha _i\) are algebraic expressions depending on the kinematic variables. Then we define the symbol \(\mathcal {S}\) of \(f^{(w)}\) iteratively to be
The iterative definition starts at weight 0 with the “empty” symbol \([] := \mathcal {S}(1)\). Applying this definition to the logarithm gives
while for the dilogarithm we readily recover Eq. (4.96).
Exercise 4.8 (The Symbol of a Transcendental Function)
Compute the symbol of \(\log (x) \log (1-x)\). For the solution see Chap. 5.
Note that Eq. (4.97), and hence the definition of the symbol (4.98), does not know about integration constants. In particular, constants such as \(\pi ^2/6\) in Eq. (4.92) are set to zero by the symbol map. Moreover, since the definition is recursive, at weight w the symbol in principle misses w integration constants. Nevertheless, the symbol is very useful: it provides a shortcut to discovering that an identity between transcendental functions exists. Let us now see how this works.
Basic Symbol Properties
It follows from the basic identity (4.94) that the symbol satisfies
Moreover, \([\ldots , c , \ldots ] = 0\) if c is a constant.
Let us see how this works on \(g(x)\) of Eq. (4.92). We have
From this we readily conclude that the symbol identity \(\mathcal {S}\bigl ( g(x) \bigr ) = 0\) holds. What this means is the following.
\(\blacktriangleright \)Symbols Allow Us to Effortlessly Find “Avatars” of Identities Between Transcendental Functions
Finding a symbol identity implies a corresponding functional identity, with integration constants yet to be fixed. This can be done systematically. The “beyond-the-symbol terms” may in general involve constants times lower-weight functions.
Connection Between First and Last Entries to Discontinuities and Differentiation, Respectively
By definition (4.97), the last entry tells us how a symbol behaves under differentiation. Interestingly, the first entry also has an important meaning: it is related to discontinuities. Both these properties can be understood by thinking about symbols as iterated integrals.
For a logarithm \(\log x\), the symbol is just \([x]\). Taking the discontinuity (normalised by \(1/(2 \pi \mathrm {i})\)) across the negative real axis corresponds to replacing \([x] \to 1\). Higher-weight functions are more interesting. For example, taking a discontinuity of \(-[x,1-x]\), which is the symbol of \(\mathrm {Li}_{2}(1-x)\), yields \(-[1-x] = {\mathcal S}\bigl (- \log (1-x) \bigr )\). For more details, see Exercise 4.7. In summary, we have that
We thus see that, on top of providing a short-cut to finding functional relations, the symbol also encodes manifestly the branch-cut structure and the derivatives of the functions.
Function Basis at Weight Two
The symbol method is very useful when looking for simplifications, or when comparing results of different calculations. In fact, for a given symbol alphabet (i.e., a given set of integration kernels), and up to a given weight, it is possible to classify the full space of possible functions.
Let us discuss this in more detail for the alphabet consisting of \(\{x, 1-x \}\) that we are already familiar with. At weight two, there are four symbols we can build from these letters, namely
Once we write down a basis for this space, we can then rewrite any other weight-two function with those integration kernels in terms of that basis.
Exercise 4.9 (Symbol Basis and Weight-Two Identities)
-
(a)
Verify that
$$\displaystyle \begin{aligned} {} \bigl\{ \log^2(x), \, \log^2 (1-x), \, \log(x) \log (1-x), \, \mathrm{Li}_{2}(1-x)\bigr\} \end{aligned} $$(4.107)provides a basis for Eq. (4.106).
-
(b)
Compute the symbols of
$$\displaystyle \begin{aligned} {} \mathrm{Li}_{2}(x) \,, \ \mathrm{Li}_{2}(1/x) \,, \ \mathrm{Li}_{2}\left(1/(1-x)\right) \,, \ \mathrm{Li}_{2}\left(x/(x-1)\right) \,, \ \mathrm{ Li}_{2}\left((x-1)/x\right) \,, \end{aligned} $$(4.108)and show that they “live” in the space spanned by the symbols in Eq. (4.106).
-
(c)
Derive the identities (at symbol level) for rewriting the functions in point b in terms of the basis given in point a.
For the solution see Chap. 5.
\(\blacktriangleright \)Knowledge of the Symbol Alphabet Dramatically Restricts the Answer
If the symbol alphabet is known (or conjectured) for a given scattering amplitude, this places strong constraints on the answer. Combined with additional information, such as for example the behaviour of the amplitudes in certain limits, this can sometimes be used to entirely “bootstrap” the answer, i.e. to obtain it without actually performing a Feynman-diagram calculation. For more information, see [14] and references therein.
So far we have discussed how to obtain the symbol of a given function, and used this for finding identities. A related application can be to find simplifications. This is relevant if the symbols of individual terms in an expression are more complicated than the symbol of their sum. It may even be that individual terms contain spurious symbol letters, i.e. letters that cancel in the sum. In such cases the symbol is a good starting point for finding a simplified answer. Given the simplified symbol, the task is then to come up with a (simple) function representation. At weight two, it turns out that only dilogarithms and products of logarithms are needed, for suitable arguments. It is easy to make an ansatz for such arguments: given that the symbol of \(\mathrm {Li}_{2}(z)\) contains both z and \(1-z\), these two expressions should be part of the symbol alphabet. We can see this explicitly for the example considered above. For example, both \(z=x/(x-1)\) and \(1-z = 1/(1-x)\) have factors within the \(\{x,1-x\}\) alphabet, and therefore z is a suitable dilogarithm argument for this alphabet. Conversely, \(z=-x\) would lead to a new letter \(1-z=1+x\). For further reading, cf. [15].
Multi-Variable Example
The definitions (4.97) and (4.98)) apply also to the multi-variable case. To illustrate this, let us consider the following function, which appears in the six-dimensional one-loop box integral (or, equivalently, it appears in the finite part of the corresponding four-dimensional box),
Looking at the symbols of the individual summands, one notices that the following symbol letters appear,
However, the full symbol is much simpler,
It only requires four of the five symbol letters. Moreover, the first entry is either u or v, which tells us that \(f_1\) has branch cuts only along the negative real u and v axes. In contrast, the individual terms in Eq. (4.109) have a (spurious) cut also at \(u+v=1\). All of this tells us that a simpler function representation exists. Readers who worked through the exercise above might be able to guess one, e.g.
The full identity can be verified as was done for Eq. (4.92). In Eq. (4.112), real-valuedness for \(u>0,v>0\) is manifest.
Exercise 4.10 (Simplifying Functions Using the Symbol)
Prove that the symbol of \(f_1(u,v)\) is given by Eq. (4.111), and verify that \(\mathcal {S}(f_{2}(u,v)) = \mathcal {S}(f_{1}(u,v))\). For the solution see Chap. 5.
For further interesting applications of the symbol method, interested readers can find how a twenty-page expression for a six-particle amplitude in \(\mathcal {N}=4\) super Yang-Mills theory was famously simplified to just a few lines [15], applications to Higgs boson amplitudes [16], and an example for simplifying functions appearing in the anomalous magnetic moment [14].
4.4.5 What Differential Equations Do Feynman Integrals Satisfy?
In the previous subsection, we analysed defining differential equations for the logarithm and dilogarithm. These functions are sufficient to describe one-loop Feynman integrals in four dimensions. We have already seen that at higher orders in the dimensional regulator, further functions, such as the trilogarithm \(\mathrm {Li}_{3}\), make an appearance, and more complicated functions are expected at higher loops. Furthermore, Feynman integrals depend in general on multiple kinematic or mass variables, so a generalisation to this case is needed as well. It turns out that there are natural extensions in both directions.
How could the most general differential equations that Feynman integrals satisfy look like? Inspired by the dilogarithm toy example above, we start by making a few observations that are helpful in guiding us.
-
One important guiding principle when looking for suitable more general differential equations are the general properties that are expected for Feynman integrals. A property is the behaviour in asymptotic limits, which implies that the differential equations are Fuchsian. Let us consider some N-vector of functions \(\mathbf {f}(x)\) (generalising Eq. (4.68)) that satisfies a set of differential equations of the formFootnote 7
$$\displaystyle \begin{aligned} \partial_x \mathbf{f}(x) = A(x) \cdot \mathbf{f}(x) \,, \end{aligned} $$(4.113)for some \(N\times N\) matrix \(A(x)\). \(A(x)\) will in general have singularities at certain locations \(x_k\). In view of the gauge dependence discussed in the preceding subsection, the exact form of \(A(x)\) depends on the basis choice for \(\mathbf {f}\). For this reason, \(A(x)\) may have higher poles at any of the \(x_k\). However, the Fuchsian property guarantees that for each singular point \(x_k\), a gauge transformation exists such that \(A(x)\) has only a single pole \(1/(x-x_{k})\) as \(x \to x_{k}\). We will assume in the following that this is possible to achieve simultaneously for all singular points, although mathematical counterexamples exist.Footnote 8
-
As far as we are aware, in all cases known in the literature, the special functions needed to express Feynman integrals in are iterated integrals (defined over a certain set of integration kernels). In line with the previous point, we assume that the latter can be chosen such that they make the Fuchsian property manifest. The simplest examples of such integration kernels are \(\mathrm {d} x/(x-x_k) = \mathrm {d} \log (x-x_k)\) for a single variable x; in the case of multiple variables \(\mathbf {x}\), it could be \(\mathrm {d}\log \alpha (\mathbf {x})\), for some algebraic function \(\alpha \). However, the literature knows also elliptic integration kernels (which locally behave as \(\mathrm {d} x/x\)).
-
We use the fact that iterated integrals have a natural notion of transcendental weight. While a Feynman integral could have terms of mixed weight, we can imagine a “gauge transformation” that disentangles such admixtures, so that each term is a pure function of uniform weight. If we then further normalise such pure functions by a weight-counting parameter \(\epsilon \), one may expect \(\epsilon \)-factorised differential equations, as e.g. Eq. (4.73).
These considerations lead us to natural generalisations of the dilogarithm example.
Generalisation of the Differential Equations to Multiple Singular Points
The simplest form of \(A(x)\) that achieves the above properties is the following:
with constant rational matrices \(A_k\). The associated class of special functions, sometimes called multiple polylogarithms, Goncharov polylogarithms, or hyperlogarithms, are important in the Feynman integrals literature. Since they go beyond the scope of these lecture notes, we refer interested readers to [18] and references therein. Being iterated integrals with logarithmic integration kernels, these functions admit the notion of transcendental weight discussed above. Let us therefore normalise the functions of weight w with \(\epsilon ^{w}\), and arrange them into the vector \(\mathbf {f}(x;\epsilon )\). This leads to a natural generalisation of Eq. (4.73), namely
where \(\mathbf {f}\) is a vector with N components, and \(A_{k}\) are constant \(N \times N\) matrices.
Examples
All presently known four-point box integrals satisfy this equation with \(x_{k} = \{0,1\}\). The number N depends on the specific Feynman integrals, and is 3 for a one-loop box integral, 8 for a two-loop double-box integral, and for non-planar three-loop integrals the number can be in the hundreds, see [12].
Generalisation to Multiple Variables
It is instructive to rewrite Eq. (4.115) in differential form, using \(\mathrm {d}= \mathrm {d} x \, \partial _x\), similarly to Eq. (4.73). Then it becomes
This form is suitable for generalisation to multiple variables. Indeed, if in Eq. (4.116) the positions \(x_{k}\) depend on some other variables, then one may consider partial derivatives in those variables as well. However, there are also Feynman integrals with more complicated dependence on the arguments. For example, in the case of a bubble diagram with an internal mass m, we found the following logarithm, see Eq. (4.36),
Although it is possible to perform a change of variables that removes the square root and allows one to treat this integral in terms of the differential equations written above (see Exercise 4.4), it is a harbinger of more general structures. Equation (4.117) motivates a further generalisation where one keeps the \(\mathrm {d} \log (\ldots )\) structure of the integration kernels, but allows for more general arguments than \(x-x_k\). In particular, it is natural to allow arbitrary algebraic expressions. Let us therefore denote by x a set of variables, and let \(\alpha (x)\) be a set of algebraic expressions. Then a generalisation of Eq. (4.116) is
This is what is called canonical form of the differential equations in the case of logarithmic integration kernels. See Table 4.1 for examples of integration kernels \(\{ \alpha _k \}\) of one-loop integrals.
Generalisation Beyond \(\mathrm {d}\log \) Integation Kernels
Equation (4.118) covers a large class of cases. As we hinted at above, even more general cases exist, where the connection matrix is not written as a sum of logarithms:
Here the assumed iterative structure of the special functions is realised by having \(\epsilon \) as a book-keeping variable for the complexity. It is not yet understood what the most general form of the connection matrix \(\tilde {A}\) is. The Fuchsian property restricts the form of the integration kernels. Say \(\tilde {A}(\mathbf {x})\) is singular at \({\mathbf {x}}_{0}\). Parametrising the limit \(\mathbf {x} = {\mathbf {x}}_{0} + \tau \, \mathbf {y}\) for generic \(\mathbf {y}\), we have the requirement
for some matrix B. In other words \(\tilde {A}(\mathbf {x})\)locally behaves as a logarithm. This however leaves open the possibility that globally\(\tilde {A}(\mathbf {x})\) is more complicated.
The first example of such integration kernels occurs in the so-called sunrise integral, see [19] and references therein. The special functions one finds are multiple elliptic polylogarithms and generalisations thereof. It is an active topic of research how to best think about these functions, in particular in terms of canonical differential Eq. (4.119) with specific differential forms. An open question is what form such equations take, generalising Eq. (4.118), but being more specific than the very general form (4.119).
\(\blacktriangleright \)Canonical Differential Equations Are a Useful Language for Describing the Invariant Information Content of Feynman Integrals
Providing the alphabet of integration kernels, together with the corresponding constant matrices, i.e. the sets \(\alpha _k\) and \(A_k\) of Eq. (4.118), is arguably the neatest way of encoding what the Feynman integral actually is. This is also very flexible, thanks to the homotopy invariance of the solution (4.86). The latter is completely analytic, and can be a good starting point for the numerical evaluation as well, see e.g. [20].
We conclude this survey of special functions relevant for Feynman integrals. Readers may wonder how these “thought experiments” are actually operationalised for Feynman integrals. This question will be answered in Sect. 4.5. Here we just satisfy a first curiosity: what is the weight-counting parameter for Feynman diagrams, and does it have anything to do with the \(\epsilon \) in dimensional regularisation? And if so, how could this possibly make any sense? The answer is yes, and it actually turns out that the dimensional regularisation parameter can naturally be thought of as having transcendental weight \(-1\). The reason is that a pole \(1/\epsilon \) in dimensional regularisation could equivalently be described by \(\log \mathnormal {\varLambda }\), where \(\mathnormal {\varLambda }\) is some cutoff. For this reason it is natural to identify \(\epsilon \) from our toy example above with the dimensional regularisation parameter!
4.5 Differential Equations for Feynman Integrals
In this section we explain the differential equations method for computing Feynman integrals. The main steps are to obtain the relevant differential equations, and then to put them into a convenient form that makes it easy to solve for them—the canonical form we encountered in the previous section. For the first step algorithms have existed for a long time, and we follow here the strategy introduced by Laporta [21]. Novel ideas stemming from the experience with loop integrals in supersymmetric theories have streamlined the second step.
The upcoming subsections will delve into the method’s details, but let us anticipate here the main steps:
-
1.
Define a “family” of Feynman graphs of interest (cf. Sect. 4.5.1).
-
2.
Write down the integration by parts identities (cf. Sect. 4.5.1).
-
3.
Find a basis of so-called master integrals (cf. Sect. 4.5.1).
-
4.
Set up differential equations for the basis integrals (cf. Sect. 4.5.2).
-
5.
Perform consistency checks (cf. Sect. 4.5.3).
- 6.
-
7.
Transform the differential equations to canonical form (cf. Sect. 4.5.4).
-
8.
Fix the boundary values (cf. Sect. 4.5.5).
-
9.
Solve the differential equations (cf. Sect. 4.5.5).
4.5.1 Organisation of the Calculation in Terms of Integral Families
Let us illustrate how to organise a general calculation using the massive bubble integrals (cf. Fig. 4.3a) as an example. As explained in Chap. 3, it is sufficient to consider scalar integrals. Given a Feynman diagram, it turns out to be useful to define an integral family, where the propagators are raised to arbitrary (integer) powers:
where we omitted the \(\mathrm {i} 0\) prescription, and we recall that \(s=p^2\). It turns out that integrals with different values of propagator powers \((a_1, a_2)\) satisfy linear relations. One can define a (finite-dimensional) basis in this space. The basis elements are called master integrals.
Integration-by-Parts Identities in Momentum Space
We have that
for any four-vector \(v^\mu \). This follows simply from integrating by parts the total derivative. The boundary terms at infinity vanish, at least for some range of \(a_1, a_2, D\), and, by analytic continuation, everywhere. Writing this equation for \(v^\mu =k^\mu \) yields the following integration-by-parts (IBP) relation:
A second relation follows from \(v=k+p\) or, equivalently, from noticing that
by symmetry.
Master Integrals and Basis Choice
From the IBP relation (4.123) and its symmetric version it follows that there are two master integrals (MIs). In practice, one generates a system of identities for a range of values \((a_1, a_2)\), and then performs a Gauss elimination procedure (with some ranking, e.g. preferring integrals with lower indices \(a_i\), or with lower \(a_1+a_2\)) [21].
The master integrals can be chosen for example as
The statement that these two integrals are master integrals, or basis integrals, means that for any \(a_1,a_2\) there exist some \(c_1, c_2\), such that
The \(c_i\) are rational functions in \(m^2, s, D\).
For example, we have (setting \(D=2-2\epsilon \) without loss of generality)
A number of comments are due.
-
There exist several computer algebra implementations and publicly available codes for generating and solving IBP relations. See Exercises 4.12 and 4.16 for examples.
-
The number of master integrals can be determined in various ways [22, 23]. Note however that what is counted exactly, i.e. what is meant by the number of master integrals, may differ depending on the reference. In general it is advisable to compute this number, and then compare with the result obtained from analysing the IBP relations.
-
It is useful to organise master integrals according to their number of propagators. One speaks of integral “sectors”. One useful feature is that integral sectors correspond to certain blocks in the differential equations satisfied by the integrals. For example, the “tadpole” integrals form a subsector within the bubble integral family. We will see this explicitly in Sect. 4.5.2.
-
The choice of master integrals is important, and can significantly impact how easy or complicated a calculation is. In Sect. 4.6 we introduce a method for choosing the master integrals wisely, motivated by the properties of transcendental functions discussed in Sect. 4.4.
Exercise 4.11 (The Massless Two-Loop Kite Integral)
Consider the following massless two-loop Feynman integral,

All propagators are massless, and \(s=p^2\). Define the corresponding integral family. Write down the integration by parts identities for one of the triangle sub-integrals, and use them to express \(F_{\text{kite}}\left (s; D\right )\) in terms of one-loop bubble integrals. Use the formula (4.16) to rewrite the latter in terms of \(\mathnormal {\varGamma }\) functions, and show that
For the solution see Chap. 5.
4.5.2 Obtaining the Differential Equations
We know that for the bubble integral family (4.121) there are two master integrals, which can be chosen as in Eq. (4.125). We wish to know the derivatives of these integrals, as this would amount to knowing the derivative of any integral in the family.
For any integral of the form (4.121), it is straightforward to compute the derivative w.r.t. \(m^2\). For example, we have
Applying this for the two master integrals, we simply have
Then, using the IBP relations (4.127), we find
Similarly, one can obtain the differential equations w.r.t. s by using \( \partial _s = 1/(2 s) p^{\mu } \partial _{p^{\mu }}\). One finds
4.5.3 Dimensional Analysis and Integrability Check
There are two simple consistency checks we can perform of the differential equation matrices just obtained.
-
1.
Scaling relation. The integral \(G_{a_1,a_2}(s,m^2;D)\) has overall (mass) dimension \(D-2 a_1 - 2 a_2\). In other words, one can write
$$\displaystyle \begin{aligned} {} G_{a_1,a_2}(s,m^2;D) = m^{D-2 a_1 -2 a_2} \, g(s/m^2;D)\,, \end{aligned} $$(4.135)for some function g. This implies the differential equation (dilatation relation)
$$\displaystyle \begin{aligned} \left[ s \, \partial_s + m^2 \partial_{m^2} \right] G_{a_1,a_2} = (D/2-a_1-a_2) \, G_{a_1,a_2} \,. \end{aligned} $$(4.136)Indeed, applying this differential operator to the massive bubble example, and using Eqs. (4.133) and (4.134), we find
$$\displaystyle \begin{aligned} {} \left[ s \, \partial_s + m^2 \partial_{m^2} \right] \begin{pmatrix} G_{0,1} \\ G_{1,1} \end{pmatrix} = \begin{pmatrix} -\epsilon & 0 \\ 0 & -1-\epsilon \end{pmatrix} \cdot \begin{pmatrix} G_{0,1} \\ G_{1,1} \end{pmatrix}\,. \end{aligned} $$(4.137)Equation (4.137) is as expected. It is a diagonal matrix, with the diagonal entries corresponding to the scaling dimensions, measured in units of the dimension of \(m^2\), cf. Eq. (4.135). The latter can be verified by dimensional analysis of the original definition in terms of loop integrals.
We remark that one could modify the definition of the master integrals, by simply rescaling them with a dimensional prefactor, to set their overall scaling dimension to zero. In our case \((m^2)^{\epsilon }\) and \((m^2)^{1+\epsilon }\) would achieve this. This would allow us to talk about single-variable differential equations in the variable \(s/m^2\), as in Eq. (4.135). However, in general we prefer not to include fractional terms such as \((m^2)^{\epsilon }\) in the definition, as this may obscure physical properties, e.g. when considering a limit \(m\to 0\) or \(m\to \infty \). Moreover, as we shall see, within the setup proposed here, dealing with multiple variables is not substantially more complicated as acompared to one variable.
-
2.
Integrability conditions. A second check follows from the commutativity of partial derivatives, in our case \(\partial _s \partial _{m^2} -\partial _{m^2} \partial _{s} = 0\). Applying this to our basis of master integrals, we get
$$\displaystyle \begin{aligned} {} \left( \partial_{s} A_{m^2} - \partial_{m^2} A_{s} + A_{m^2} \cdot A_{s} - A_{s} \cdot A_{m^2} \right) \cdot \begin{pmatrix} G_{0,1} \\ G_{1,1} \end{pmatrix} =0 \,. \end{aligned} $$(4.138)One can verify indeed that the matrix appearing in Eq. (4.138) vanishes identically.
We close this subsection with a comment. Whenever one of the two checks discussed here fails, e.g. when one gets a non-vanishing matrix on the RHS of Eq. (4.138), this most likely points to some mistake in a calculation or implementation step. However, note that Eq. (4.138) also admits solutions for non-vanishing matrices on the right-hand side if the master integrals are not linearly independent. It can indeed happen in practice that there are “hidden” IBP relations (that would e.g. be discovered by considering a larger set of IBP relations). In this case these checks may give hints for such missing relations. Note however that the converse is not true: successful scaling and integrability tests do not guarantee that one has found all IBP relations.
4.5.4 Canonical Differential Equations
The differential equations (4.133) and (4.134) are already rather simple, however by comparing to Eq. (4.118) we see that they are not yet quite in canonical form. In particular, they contain a \(\epsilon ^0\) term. We will see in Sect. 4.6 how to directly find canonical differential equations but, for now, let us proceed in a more pedestrian way. We may attempt to “integrate out” the unwanted \(\epsilon ^0\) term, by changing basis from
to
for some suitable invertible matrix T. The differential equations for the new basis \(\mathbf {f}\) are governed by Eq. (4.83). Demanding that this matrix is free of \(\epsilon ^0\) terms leads us to the following auxiliary problem:
This leads to the transformation matrix
and hence to the following new basisFootnote 9
Assuming \(s<0,m^2>0\), one finds
There is a similar equation for \(\partial _s\).
So, structurally we have two differential equations
The two partial derivative equations can be combined in a single equation using the total differential \(\mathrm {d} = \mathrm {d} s \, \partial _s + \mathrm {d}{m^2} \, \partial _{m^2}\). Then we have
provided that \(\tilde {A}\) satisfies
We find the following \(\tilde {A}\) solves these equations,
Equations (4.146) and (4.148) are an example of canonical differential equations for Feynman integrals [11]. The specific form (4.148) is an instance of the general case (4.118), with \(N=2\). There are three alphabet letters, namely
4.5.5 Solving the Differential Equations
General Solution to the Differential Equations
Here we discuss how to solve the canonical differential equations. We had already seen in Sect. 4.4.2 that the general solution takes the form of a path-ordered exponential, cf. (4.86). Adopting this equation to the present case, we have
with \(\tilde {A}\) from Eq. (4.148), and where \(\mathbf {x}\) refers collectively to the set of kinematic variables \(\mathbf {x}=(s,m^2)\), and \({\mathbf {x}}_0\) is an arbitrary base point for the integral, which takes the value \(\mathbf {f}({\mathbf {x}}_0;\epsilon )\) there. This corresponds to the fact that the system of first-order equations uniquely fixes the answer up to a boundary condition. We will discuss this presently.
There are simplifications thanks to the fact that the matrix in the exponent on the RHS of Eq. (4.150) is proportional to \(\epsilon \). Therefore we can expand the exponential perturbatively in \(\epsilon \). Moreover, due to the fact that the matrix on the RHS (cf. Eq. (4.148)) contains only logarithmic integration kernels, the answer are iterated integrals with the alphabet of Eq. (4.149). In fact, we shall see presently that the answer up to the finite part is written in terms of much simpler functions. But this is not essential. The main message is that the class of special functions at our disposal is large enough to express the general solution to Eq. (4.146) with Eq. (4.148).
In Eq. (4.150), \(\mathbf {f}({\mathbf {x}}_0;\epsilon )\) is a boundary vector at a given base point \({\mathbf {x}}_{0}\). As such, Eq. (4.150) expresses the general solution to the differential equations. In most cases, one is interested in the specific solution that corresponds to the Feynman integrals at hand. This means that it is necessary to provide a boundary condition. In other words, for a Feynman integral depending on multiple variables \(\mathbf {x}\), one needs to know its value at one specific point \({\mathbf {x}}_{0}\).
\(\blacktriangleright \)Fixing the Boundary Conditions from Physical Consistency Conditions
One might naively think that a completely separate calculation is needed for this. However, experience shows that one can obtain the boundary information from physical consistency conditions. This approach is well known in the literature, but turns out to be especially easy within the canonical differential equations approach, which moreover offers additional insights [12]. As a result, in most calculations this allows one to fix all integration constants, up to an overall normalisation.
The key is to consider the behaviour near singular points (or rather singular kinematic subvarieties) of the differential equations. The singular points are easily identified from the alphabet (4.148). They correspond to kinematic configurations where alphabet letters tend to zero or infinity. In our case, this corresponds to \(s=0, s=m^2, s=\infty , m^2=0, m^2 =\infty \).
In the present case, it turns out that \(s=0\) is a suitable boundary configuration. The reason is that, physically, one knows that this limit is non-singular (due to the presence of the internal mass). In other words, we can simply set \(p=0\) in Eq. (4.33). This reduces the bubble integral to a tadpole integral. However, since its normalisation factor in Eq. (4.143) vanishes, we do not even need to know its value. This fixes the boundary constant at \(s=0\), up to the value of the tadpole integral. The calculation of the latter is elementary, with the result
which follows from Eq. (4.6) with \(a=1\) and \(D=2 -2 \epsilon \). Therefore the boundary condition is
This fixes the answer of the differential equation to all orders in \(\epsilon \).
Solution in Terms of Multiple Polylogarithms
The alphabet Eq. (4.149) can be rationalised using a simple change of variables. Indeed, setting \(s = -m^2 (1-x)^2/x\), and assuming \(0<x<1\), Eq. (4.149) becomes
i.e. the alphabet, written in the independent variables \(m^2\) and x is simply
This means that the answer can be written in terms of a special subclass of iterated integrals, called harmonic polylogarithms.Footnote 10 Moreover, the dependence on \(m^2\) in the new alphabet becomes trivial, as it corresponds to the overall scale. We can therefore set \(m^2=1\) without loss of generality, and solve the equations as a function of x only. Equivalently, we could multiply all integrals by \((m^2)^{-\epsilon }\).
With this in mind, let us make the following final basis choice (the normalisation is motivated by Eq. (4.152)):
It satisfies the differential equations
with the boundary condition
More explicitly, Eq. (4.156) is
We can now solve this equation, together with the boundary condition (4.157), order by order in \(\epsilon \). To do so, we set
up to some order in \(\epsilon \). The key point is that the equations (4.156) decouple order by order in \(\epsilon \), when expressed in terms of \( {\mathbf {f}}^{(k)}(x)\). For the first few orders, we straightforwardly find
and
Recalling the definition (4.155), this gives
This agrees with Eq. (4.36). Furthermore, Eq. (4.161) provides the next term in the \(\epsilon \) expansion, and higher-order terms can be straightforwardly generated.
Exercise 4.12 (The Massive Bubble Integrals with the Differential Equations Method)
Write a Mathematica notebook for computing the massive bubble integrals (4.121) with \(D=2-2\epsilon \) following step by step the discussion in Sect. 4.5. Use the package LiteRed [6] to perform the IBP reductions and differentiate the integrals. For the solution see the Mathematica notebook Ex4.12_BubbleDE.wl [24].
4.6 Feynman Integrals of Uniform Transcendental Weight
In the previous subsections, we have discussed special functions appearing in Feynman diagrams. We have seen in the preceding chapters that they satisfy simple, canonical differential equations. However, we have also seen that the equations have a gauge degree of freedom, which corresponds to making a basis choice for the coupled system of N equations. This freedom implies that the DE may be written in an equivalent, albeit unnecessarily complicated form. Therefore an important question is: how can we make sure that the equations we get for Feynman integrals will have the desired simple, canonical form?
We address this problem in this section. This builds on the observations of Sect. 4.4.3 that pure uniform weight functions satisfy canonical differential equations. In this section we present a conjecture that gives a criterium for when a Feynman integral evaluates to such functions. Taken together, this provides the information for how to choose a set of Feynman integrals that satisfy canonical differential equations.
4.6.1 Connection to Differential Equations and (Unitarity) Cuts
We have already seen in Sect. 4.4.3 that, in the context of the differential equations satisfied by Feynman integrals, it is natural to consider discontinuities. It turns out that there is a useful connection to (generalised) unitarity methods.
This is based on the important observation that unitarity cuts of an integral satisfy the same differential equations, albeit with different boundary conditions. We can see this in the following way [25]. When we “cut” a propagator, we effectively replace \(1/(-k^2+m^2)\) by \(\delta (-k^2+m^2)\). As was discussed in Sect. 3.3 of Chap. 3, the cut can be written as a difference of propagators with different \(\mathrm {i} 0\) prescriptions. However, this prescription does not affect the derivation of the IBP relations, and hence one gets the same differential equations. Of course, the boundary values of the cut integrals differ from the original ones, and in particular one could put to zero integrals that obviously vanish on a cut because the relevant cut propagators are absent.
Consider the one-loop massive bubble integrals \(G_{1,1}\) and \(G_{1,0}\) of Eq. (4.33) as an example. Applying an s-channel unitarity cut, and settingFootnote 11\(D=2\) we obtain
This is exactly the factor we introduced in Eq. (4.143) to remove the \(\epsilon =0\) part of the differential equation. Performing the same cut on the tadpole integral \(G_{1,0}\) vanishes, simply because it is missing one propagator that was cut. Indeed, by cutting all propagators—whose number happens to coincide here with the space-time dimension \(D=2\)—we are taking a so-called maximal cut. This allows us to focus on a given integral sector. In terms of the differential equations, this means that this cut describes a block of the differential equations, whose size corresponds to the number of relevant master integrals. In the present case, there is just one master integral with two propagators, so the block corresponds of one element of the differential equations.
We can also learn something about the tadpole integral, by considering generalised unitarity cuts. The most obvious is to cut the one propagator that is present. It is instructive to do this:
It is convenient to introduce two light-like vectors \(p_1\) and \(p_2\), with \(p_1^2 = p_2^2 = 0\), such that \(p=p_1 + p_2\), and \(2 \, p_1 \cdot p_2 = s\). This allows us to parametrise \(k= \beta _1 p_1 + \beta _2 p_2\). Taking into account the Jacobian from the change of variables, and using the delta function to fix one integration, we find
Unlike Eq. (4.163), here the integrations are not fully fixed. Moreover, the first integration has produced a new singularity, \(1/\beta _2\), that was not present initially. This is a typical situation in generalised unitarity. We can define a further cut and localise the integral at one of its singularities, either \(\beta _2= 0\) or \(\beta _2 = \infty \). The result is just \(\pm 1\), which confirms the normalisation choice in Eq. (4.143).
4.6.2 Integrals with Constant Leading Singularities and Uniform Weight Conjecture
The calculations above provided useful insight about diagonal blocks of the differential equations (in the present case, the diagonal elements, since the block size happened to be one). Can one also learn something about the off-diagonal terms with this method? The answer—conjecturally—is yes. The idea is first to think of the above calculations not of changing the integrand, but instead of changing the integration contour. The original integration is over two-dimensional Minkowski space. In the calculations above, we have effectively replaced this by certain residue calculations. The idea then is to generalise this to arbitrary residues we can take for a given loop integrand. In the case where those residues completely localise the loop integrations, one speaks specifically of leading singularities. We know that leading singularities that correspond to maximal cuts inform us about diagonal blocks of the differential equations. The assumption is that the other residues “know about” the off-diagonal parts, even though we do not know the precise mapping. However, for the present purposes, this precise map is not relevant: if we can normalise all leading singularities to constants, then their derivatives will obviously be trivial. This gives us a useful tool for obtaining differential equations whose RHS is proportional to \(\epsilon \).
How does one see that all leading singularities are kinematic-independent constants? Let us review the tadpole and bubble integrands from this viewpoint. As explained, we now focus on the integrand,
where we have used the same loop parametrisation as above. Integrating one variable at a time, we can write this in the following way,
Here \(\mathrm {d}= \mathrm {d}\beta _1 \, \partial _{\beta _1} + \mathrm {d}\beta _2 \, \partial _{\beta _2}\). The differential forms satisfy \(\mathrm {d}\beta _i \mathrm {d}\beta _j = - \mathrm {d}\beta _j \mathrm {d}\beta _i\), and hence e.g. \(\mathrm {d}\beta _2 \mathrm {d}\beta _2 =0\). In other words, upon further changing variables, the form reads
This makes it clear that any leading singularity of this integral evaluates to a constant, and hence that any of its derivatives vanishes, as desired.
Repeating this analysis for the bubble is slightly more interesting. We leave it as an exercise to readers. The result can be written as
Here \(k_{\pm }\) is any of the two solutions to the cut equations \(-k^2+m^2=-(k+p)^2+m^2=0\). This expression makes it manifest that \(\omega _{1,1}\) has only logarithmic singularities (i.e., of type \(\mathrm {d} x/x\)), and its maximal residue (i.e., its leading singularity) is
Therefore we conclude that the integral \( {\sqrt {(-s)(4m^2-s)}} \, \int \omega _{1,1}\) is a good basis integral that may lead to canonical differential equations. Indeed, note that this is consistent with Eq. (4.36).
Exercise 4.13 (“\(\mathrm {d} \log \)” form of the Massive Bubble Integrand with \(D=2\))
Use the parameterisation introduced above (\(k=\beta _1 p_1 + \beta _2 p_2\)) to prove that the integrand of the massive bubble in \(D=2\) dimensions can be expressed as a “\(\mathrm {d} \log \)” form. Show that the latter is equivalent to the momentum-space \(\mathrm {d} \log \) form in Eq. (4.169). For the solution see Chap. 5.
Interestingly, the question of which Feynman integrals evaluate to uniform weight functions was previously studied independently from the differential equations. Understanding initially came from studies of scattering amplitudes in \({\mathcal N} =4\) super Yang-Mills theory, but it turned out that the observations made there were applicable more generally [11, 26]. This led to the following conjecture. A Feynman integral integrates to a pure function if
-
1.
its integrand, and iterated residues thereof, only contains simple poles,
-
2.
the maximal residues are normalised to constants.
These two criteria are in one-to-one correspondence to the properties discussed above. The first requirement is intended to remove less than maximal weight functions, and therefore lead to integrals with uniform and maximal weight. See Exercise 4.14 for an example of an integrand with a double pole, which is a sign for a weight-drop. As computed explicitly in Exercise 4.11, the answer has weight three, which is less than the maximal weight four expected for two-loop integrals in four dimensions. The second requirement addresses another potential problem: if an integral is a sum of maximal weight functions with different algebraic prefactors, this spoils the desired simple structure under differentiation. Normalising all prefactors to kinematic-independent constants solves this issue.
\(\blacktriangleright \)Integrand Conjecture as a Practical Tool for Finding Canonical Differential Equations
The above integrand conjecture has proven preciously useful for choosing bases of Feynman integrals that satisfy canonical differential equations. What renders this method particularly powerful is that the method can be used at the level of the loop integrand, independently of questions about IBP identities, and without knowledge of the differential equations.
Exercise 4.14 (An Integrand with Double Poles: The Two-Loop Kite in \(D=4\))
Compute the four-dimensional maximal cut of the two-loop kite integral defined in Exercise 4.11, and show that—on the maximal cut—its integrand has a double pole. Hint: introduce two auxiliary light-like momenta \(p_1\) and \(p_2\) (\(p_i^2=0\)) such that \(p=p_1+p_2\), and use the spinors associated with them to construct a basis in which to expand the loop momenta. For the solution see Chap. 5.
Exercise 4.15 (Computing Leading Singularities with DlogBasis)
The Mathematica package DlogBasis [12] provides a suite of tools for computing leading singularities and checking whether a given integrand can be cast into \(\mathrm {d} \log \) form, based on the partial fractioning procedure we used to solve Exercise 4.13. Use DlogBasis to do the following.
-
(a)
Verify the leading singularities of the massive tadpole and bubble integrals given in Eqs. (4.168) and (4.170).
-
(b)
Verify that the integrand of the two-loop kite integral with \(D=4\) studied in Exercise 4.14 has a double pole.
-
(c)
Consider the integrands of the following massless box and triangle integrals,
 (4.171)
(4.171)with \(p_i^2 = 0\). Show that their leading singularities in \(D=4\) dimensions are
$$\displaystyle \begin{aligned} \oint \omega^{\text{box}} \propto \frac{1}{s \, t} \,, \qquad \quad \oint \omega^{\text{tr.}}_s \propto \frac{1}{s} \,, \qquad \quad \oint \omega^{\text{tr.}}_t \propto \frac{1}{t} \,, \end{aligned} $$(4.172)where \(s=2 \, p_1 \cdot p_2\) and \(t = 2\, p_2 \cdot p_3\). Parametrise the integrands using DlogBasis’ utilities to expand the loop momentum in a four-dimensional basis constructed from the spinors associated with \(p_1\) and \(p_2\).

For the solution see the Mathematica notebook Ex4.15_LeadingSingularities.wl [24].
Exercise 4.16 (The Box Integrals with the Differential Equations Method)
Write a Mathematica notebook to compute the massless one-loop box integrals,
where
with \(p_i^2=0\) and \(p_1+p_2+p_3+p_4=0\), using the method of DEs. Parameterise the kinematics in terms of \(s = 2 \, p_1 \cdot p_2\) and \(t = 2 \, p_2 \cdot p_3\), and assume that \(s<0\) and \(t<0\). In this domain, called Euclidean region, the integrals are real valued, and we may thus neglect the \(\mathrm {i} 0\)’s. Use the package LiteRed [6] to perform the IBP reductions and differentiate the integrals.
-
(a)
Define the family and solve the IBP relations to find a basis of master integrals.
-
(b)
Compute the DEs satisfied by the master integrals as functions of s and t. Check the scaling relation and the integrability conditions.
-
(c)
Change basis of master integrals to
$$\displaystyle \begin{aligned} {} \mathbf{f}(s,t;\epsilon) = c(\epsilon) \, \begin{pmatrix} s \, t \, G^{\text{box}}_{1,1,1,1} \\ s \, G^{\text{box}}_{1,1,1,0} \\ t \, G^{\text{box}}_{1,1,0,1} \end{pmatrix} \,, \end{aligned} $$(4.175)where \(c(\epsilon ) = \epsilon ^2 \, \text{e}^{\epsilon \gamma _{\text{E}}}\). From Exercise 4.15 we know that, for \(D=4\), the integrals in \(\mathbf {f}\) contain only simple poles at the integrand level, and have constant leading singularities. Compute the transformation matrix and the DEs satisfied by \(\mathbf {f}\). Verify that the latter are in canonical form.
-
(d)
Change variables from \((s,t)\) to \((s,x)\), with \(x=t/s\).
-
(e)
Determine the weight-0 boundary values. Use the results of Exercise 4.1 for the master integrals of bubble type. Fix the remaining value by imposing that the solution to the DEs is finite at \(u=-s-t = 0\) (\(x=-1\)). Write a function which produces the symbol of the solution up to a given order in \(\epsilon \).
-
(f)
Determine the boundary values at the basepoint \(x_0 = 1\) order by order in \(\epsilon \). Write a function which produces the analytic solution up to a given order in \(\epsilon \).
-
(g)
Verify that the solution for the box integral \(G^{\text{box}}_{1,1,1,1}\) agrees with the result obtained through the Mellin-Barnes method in Eq. (4.55).
For the solution see Chap. 5 and the Mathematica notebook Ex4.16_BoxDE.wl [24].
Notes
- 1.
Note that \(\mathrm {i} 0\) is understood as a positive infinitesimal quantity. For this reason, we have absorbed a positive factor of \(2\sqrt { {\mathbf {k}}^2+m^2}\) into \(\mathrm {i} 0\), and we have dropped terms of order \((\mathrm {i} 0)^{2}\).
- 2.
In practice, one may have situations where infrared and ultraviolet divergences are present at the same time. Thanks to analytic continuation, these divergences can be treated consistently within dimensional regularisation.
- 3.
For this purpose, we view the external legs as extending to infinity.
- 4.
In particular, poles \(1/\epsilon \) in dimensional regularisation correspond to \(\log \mathnormal {\varLambda }\) terms in cutoff regularisations, so it is natural that \(1/\epsilon \) has the same weight as a logarithm.
- 5.
In fact, note that the connection matrix in the DE (4.69) has a pole also at \(x=1\). This branch point is “hidden” in the principal branch of \(\mathrm {Li}_2(1-x)\), but comes to light when we cross the branch cut starting from \(x=0\). Indeed, we see in Eq. (4.87) that the discontinuity of \(\mathrm {Li}_2(1-x)\) has itself a branch point at \(x=1\).
- 6.
Whenever the alphabet contains only \(\mathrm {d} \log \)-type integration kernels, it is sufficient to keep track of their arguments. In the case of Eq. (4.73), for instance, one would say that the alphabet is \(\{x,1-x\}\).
- 7.
For simplicity of notation, we suppress the dependence on \(\epsilon \) for the moment.
- 8.
- 9.
In Sect. 4.6 we will see that this basis can be motivated in an entirely different way, without the need to analyse differential equations.
- 10.
For more information on particular classes of special functions, and how to handle them efficiently, we refer interested readers to [18] and references therein.
- 11.
One key feature of the canonical differential equations is that their RHS vanishes for \(\epsilon =0\). It is therefore interesting to ask whether we can solve for the \(\epsilon =0\) part of the differential equations. However, it is also interesting (albeit more involved) to study cut integrals for general D.
References
M.E. Peskin, D.V. Schroeder, An introduction to quantum field theory (Addison-Wesley, Boston, 1995). ISBN 978-0-201-50397-5
V.A. Smirnov, Analytic tools for Feynman integrals. Springer Tracts Mod. Phys. 250, 1–296 (2012). https://doi.org/10.1007/978-3-642-34886-0
S. Weinzierl, Feynman integrals (2022). https://doi.org/10.1007/978-3-030-99558-4 [arXiv:2201.03593 [hep-th]]
J.M. Henn, Lectures on differential equations for Feynman integrals. J. Phys. A 48, 153001 (2015). https://doi.org/10.1088/1751-8113/48/15/153001 [arXiv:1412.2296 [hep-ph]]
N. Agarwal, L. Magnea, C. Signorile-Signorile, A. Tripathi, The infrared structure of perturbative gauge theories. Phys. Rept. 994, 1–120 (2023). https://doi.org/10.1016/j.physrep.2022.10.001 [arXiv:2112.07099 [hep-ph]]
R.N. Lee, Presenting LiteRed: a tool for the loop InTEgrals REDuction (2012) [arXiv:1212.2685 [hep-ph]]
E. Panzer, Algorithms for the symbolic integration of hyperlogarithms with applications to Feynman integrals. Comput. Phys. Commun. 188, 148–166 (2015). https://doi.org/10.1016/j.cpc.2014.10.019 [arXiv:1403.3385 [hep-th]]
M. Czakon, Automatized analytic continuation of Mellin-Barnes integrals. Comput. Phys. Commun. 175, 559–571 (2006). https://doi.org/10.1016/j.cpc.2006.07.002 [arXiv:hep-ph/0511200 [hep-ph]]
A.V. Kotikov, L.N. Lipatov, DGLAP and BFKL equations in the \(N=4\) supersymmetric gauge theory. Nucl. Phys. B 661, 19–61 (2003) [erratum: Nucl. Phys. B 685, 405–407 (2004)]. https://doi.org/10.1016/S0550-3213(03)00264-5 [arXiv:hep-ph/0208220 [hep-ph]]
D. Zagier, The dilogarithm function (2007). https://doi.org/10.1007/978-3-540-30308-4_1
J.M. Henn, Multiloop integrals in dimensional regularization made simple. Phys. Rev. Lett. 110, 251601 (2013). https://doi.org/10.1103/PhysRevLett.110.251601 [arXiv:1304.1806 [hep-th]]
J. Henn, B. Mistlberger, V.A. Smirnov, P. Wasser, Constructing d-log integrands and computing master integrals for three-loop four-particle scattering. J. High Energy Phys. 04, 167 (2020). https://doi.org/10.1007/JHEP04(2020)167 [arXiv:2002.09492 [hep-ph]]
S. Müller-Stach, S. Weinzierl, R. Zayadeh, Picard-Fuchs equations for Feynman integrals. Commun. Math. Phys. 326, 237–249 (2014). https://doi.org/10.1007/s00220-013-1838-3 [arXiv:1212.4389 [hep-ph]]
J.M. Henn, What can we learn about QCD and Collider physics from N=4 super Yang–Mills? Ann. Rev. Nucl. Part. Sci. 71, 87–112 (2021). https://doi.org/10.1146/annurev-nucl-102819-100428 [arXiv:2006.00361 [hep-th]]
A.B. Goncharov, M. Spradlin, C. Vergu, A. Volovich, Classical polylogarithms for amplitudes and Wilson loops. Phys. Rev. Lett. 105, 151605 (2010). https://doi.org/10.1103/PhysRevLett.105.151605 [arXiv:1006.5703 [hep-th]]
C. Duhr, Hopf algebras, coproducts and symbols: an application to Higgs boson amplitudes. J. High Energy Phys. 08, 043 (2012). https://doi.org/10.1007/JHEP08(2012)043 [arXiv:1203.0454 [hep-ph]]
R.N. Lee, Reducing differential equations for multiloop master integrals. J. High Energy Phys. 04, 108 (2015). https://doi.org/10.1007/JHEP04(2015)108 [arXiv:1411.0911 [hep-ph]]
C. Duhr, Function theory for multiloop Feynman integrals. Ann. Rev. Nucl. Part. Sci. 69, 15–39 (2019). https://doi.org/10.1146/annurev-nucl-101918-023551
J.L. Bourjaily, J. Broedel, E. Chaubey, C. Duhr, H. Frellesvig, M. Hidding, R. Marzucca, A.J. McLeod, M. Spradlin, L. Tancredi et al., Functions beyond multiple polylogarithms for precision Collider physics (2022). [arXiv:2203.07088 [hep-ph]]
D. Chicherin, V. Sotnikov, S. Zoia, Pentagon functions for one-mass planar scattering amplitudes. J. High Energy Phys. 01, 096 (2022). https://doi.org/10.1007/JHEP01(2022)096 [arXiv:2110.10111 [hep-ph]]
S. Laporta, High precision calculation of multiloop Feynman integrals by difference equations. Int. J. Mod. Phys. A 15, 5087–5159 (2000). https://doi.org/10.1142/S0217751X00002159 [arXiv:hep-ph/0102033 [hep-ph]]
R.N. Lee, A.A. Pomeransky, Critical points and number of master integrals. J. High Energy Phys. 11, 165 (2013). https://doi.org/10.1007/JHEP11(2013)165 [arXiv:1308.6676 [hep-ph]]
T. Bitoun, C. Bogner, R.P. Klausen, E. Panzer, Feynman integral relations from parametric annihilators. Lett. Math. Phys. 109(3), 497–564 (2019). https://doi.org/10.1007/s11005-018-1114-8 [arXiv:1712.09215 [hep-th]]
https://scattering-amplitudes.mpp.mpg.de/scattering-amplitudes-in-qft/Exercises/.
C. Anastasiou, K. Melnikov, Higgs boson production at hadron colliders in NNLO QCD. Nucl. Phys. B 646, 220–256 (2002). https://doi.org/10.1016/S0550-3213(02)00837-4 [arXiv:hep-ph/0207004 [hep-ph]]
N. Arkani-Hamed, J.L. Bourjaily, F. Cachazo, J. Trnka, Local integrals for planar scattering amplitudes. J. High Energy Phys. 06, 125 (2012). https://doi.org/10.1007/JHEP06(2012)125 [arXiv:1012.6032 [hep-th]]
Author information
Authors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2024 The Author(s)
About this chapter

Cite this chapter
Badger, S., Henn, J., Plefka, J.C., Zoia, S. (2024). Loop Integration Techniques and Special Functions. In: Scattering Amplitudes in Quantum Field Theory. Lecture Notes in Physics, vol 1021. Springer, Cham. https://doi.org/10.1007/978-3-031-46987-9_4
Download citation
DOI: https://doi.org/10.1007/978-3-031-46987-9_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-46986-2
Online ISBN: 978-3-031-46987-9
eBook Packages: Physics and AstronomyPhysics and Astronomy (R0)