
Abstract
Machine learning (ML) algorithms have become popular in recent years and have found increasing utility in the field of medical imaging, specifically in positron emission tomography (PET) imaging. The interest in ML in PET imaging for the study of neurodegenerative diseases stems from the potential of these techniques to analyze and predict the physiological parameters of biomarkers such as the total volume of distribution (V\(_{\text {t}}\)) in the organ or a structure of the organ to be explored. In this paper, we investigated whether the V\(_{\text {t}}\) of [\(^{18}\)F]-FEPPA radiotracer, an indicator of neuroinflammation, could be estimated directly in a non-invasive way, given the activity of the radiotracer in brain tissue. The study used several regression models to predict the [\(^{18}\)F]-FEPPA V\(_{\text {t}}\) in different brain regions where 31 regions of interest were defined for each of 24 patients with Parkinson disease and 20 healthy subjects, and were used to train four tree-based regression models. The predicted and reference values were compared by Bland-Altman analysis and regression model’s performance was evaluated by the mean absolute error (MAE). The best result was obtained by the XGBoost model with a MAE of 2.6. Bland-Altman analysis results indicate that predicted V\(_{\text {t}}\) are in average very close to the reference with a bias of 0.23  2.82. Significant main effect of genotype on [\(^{18}\)F]-FEPPA in both caudate and putamen have been preserved by predicted Vt values (p < 0.05). The results of paired t-test indicate that the difference between predicted and reference V\(_{\text {t}}\) is not statistically significant in 6 out of 8 groups. The proposed algorithms provide a non-invasive and efficient tool to predict [\(^{18}\)F]-FEPPA V\(_{\text {t}}\) values, a hallmark of neuroinflammation that is believed to be a potential trigger for Parkinson’s disease development.
2.82. Significant main effect of genotype on [\(^{18}\)F]-FEPPA in both caudate and putamen have been preserved by predicted Vt values (p < 0.05). The results of paired t-test indicate that the difference between predicted and reference V\(_{\text {t}}\) is not statistically significant in 6 out of 8 groups. The proposed algorithms provide a non-invasive and efficient tool to predict [\(^{18}\)F]-FEPPA V\(_{\text {t}}\) values, a hallmark of neuroinflammation that is believed to be a potential trigger for Parkinson’s disease development.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction and Related Work
Machine learning (ML) is on the verge of revolutionizing medical diagnosis, especially in imaging-based specialties such as PET. This new discipline is bringing a wealth of innovations to the analysis of large datasets in critical clinical studies like those focused on neurodegenerative diseases. In this article, we propose a set of ML-based regression models to reproduce [\(^{18}\)F]-FEPPA V\(_{\text {t}}\) values, which are a neuroinflammation hallmark, in a non-invasive way.
Neuroinflammation is a complex process involving the activation of immune cells within the central nervous system (CNS) in response to injury or infection [1]. While it is normal and essential for a neuroinflammation to occur in the brain as a response to previous triggers, it has been proven that an excessive or chronic inflammation may lead to the development and progression of neurodegenerative diseases such as Parkinson’s disease (PD) [2] and lead consequently to a loss of dopamine levels in the striatum region of the brain, more specifically in caudate and putamen regions.
Many factors contribute to this loss, including genetic factors [3], environmental factors [4], age [5], etc. Furthermore, several studies have shown that the activation of inflammatory pathways in the brain can contribute to the death of more dopamine neurons and amplify the motor symptoms of PD [6]. The inflammation in PD is actually characterized by the activation of particular glial cells in CNS, called microglia [7]. Recent studies have shown that a chronic activation of these cells can become harmful to the CNS [8]. Based on that, researchers have targeted neuroinflammation as a hallmark feature for PD’s disease, as well as for other neurodegenerative diseases such as Alzheimer’s disease [9], Huntington’s disease [10], etc. Tracking neuroinflammation can potentially provide valuable insights into the mechanisms underlying these diseases, in addition to an accurate and earlier detection and diagnosis, enabling earlier interventions and treatments [11]. PET uses a special scanner to detect radiation emitted by a small amount of radioactive substance called radiotracer or radiopharmaceutical, that has been injected into the body. The used radiotracer binds to markers of inflammation or other physiological processes that are associated with these diseases.
Researches have proved that measuring microglia activation can be performed through quantifying a protein called translocator 18 kDa protein (TSPO). The expression of TSPO is upregulated when microglia are activated in response to injury or other stimuli in the brain, hence the interest of researchers to develop TSPO radiotracers [12, 13]. [\(^{18}\)F]-FEPPA is one of the newest second generation TSPO PET radiotracer with greater affinity for its target. However, the quantification of its distribution in the brain cells requires the determination of a metabolite-corrected arterial input function (AIF), which is practically done through arterial cannulation. Although the risk related to arterial cannulation is low, it represents an invasive and logistically demanding procedure. Besides, the discomfort caused by this procedure often discourages subjects from participating in PET studies. Given these considerations, much studies have been carried out to obviate the need for arterial cannulation such as Population-Based Input Function (PBIF) [14,15,16,17] and Image Derived Input Function (IDIF) [18,19,20,21].
Recent studies have explored the use of machine learning (ML) approaches for estimating AIF [22,23,24]. While the use of these approaches has not been extensively investigated, recent studies have reported promising results. As the aforementioned methods, MLIF has different challenges to be addressed like the high dependency of its results on the quantity and quality of the available training data.
To the best of our knowledge, this is the first study to investigate the estimation of pharmacokinetic parameters directly from the given Time Activity Curves (TACs) of different brain regions and, hence, avoid any use of AIF. By using ML models, we were able to give an approximate value of V\(_{\text {t}}\), in a non-invasive way. Our results provide a novel perspective on PET images quantification.
Our paper addresses leveraging appropriate ML techniques to predict, in a non-invasive manner, the total volume of distribution (V\(_{\text {t}}\)) given the regional TACs. The data used in this study was acquired with [\(^{18}\)F]-FEPPA radiotracer. We organized our paper as follows: in the first section, we will give an overview of the dataset acquisition, the reference V\(_{\text {t}}\) estimation and the methods we used for Vt prediction. Next, we will discuss the results obtained from our ML models. In the conclusion, we will suggest some directions for future work.
2 Methods
In this section, we present details on features that have been used as input to our models, including data acquisition, region of interest (ROI) delineation, TACs generation, input function used in the quantification of PET data previously published in [25] and the genotype of the subjects included in the analysis. The training data contain relevant information about the biochemical transformations of the tracer in each of the brain regions and the genotype of the studied subject, as well as the correct response to the [\(^{18}\)F]-FEPPA V\(_{\text {t}}\).
2.1 Data Acquisition
Twenty four subjects with Parkinson’s Disease and twenty healthy controls underwent an [\(^{18}\)F]-FEPPA PET and magnetic resonance imaging scan. After radiotracer administration into the body of the patient and PET data acquisition, the collected PET raw data were reconstructed into images using ordered subset expectation maximization with point spread function (OSEM+PSF) reconstruction [26].
2.2 ROI-Based Time Activity Curve Generation
MRI images for all the subjects were acquired for co-registration with the corresponding PET images and the anatomical delineation of the 31 ROIs. The ROI template is transferred to the PET image space to extract the time activity curve for each ROI. The TACs are graphical representations of how radioactive tracers distribute and accumulate within tissues over time. In our study, dynamical series of images of [\(^{18}\)F]-FEPPA PET have been visually checked for head-motion and corrected using frame-by-frame realignment [25].
2.3 Input Function Measurement
AIF is determined during the PET scanning by gathering blood samples at discrete time points from the subject’s radial artery and measuring the concentration of the radioactive compound in every sample. Arterial blood was taken continuously at a rate 2.5 mL/min for the first 22.5 min after radioligand injection and the blood radioactivity levels were measured using an automatic blood sampling system (Model PBS-101 from Veenstra Instruments, Joure, The Netherlands). In addition, 4 to 8 ml manual arterial blood samples were obtained at 2.5, 7, 12, 15, 30, 45, 60, 90, and 120 min relative to time of injection. A bi-exponential function was used to fit the blood-to-plasma ratios. A Hill function was used to fit the percentage of unmetabolized radioligand. The dispersion effect was modeled as to the convolution with a monoexponential with dispersion coefficient of 16 s and corrected with iterative deconvolution [27].
2.4 Polymorphism Genotyping
The quantitative interpretations of [\(^{18}\)F]-FEPPA are impacted by the large inter-individual variability in binding affinity, which displays a trimodal distribution compatible with a co-dominant genetic trait [28]. Study of TSPO polymorphism explained the heterogeneity in binding potential by the difference in the affinity of the second-generation PET ligands for this protein. [\(^{18}\)F]-FEPPA radiotracers bind TSPO in brain tissue from different subjects in one of three ways: high-affinity binders, mixed affinity binders, and low-affinity binders (HABs, MABs and LABs). The transport rate of radiotracer is 1.5 to 2-fold higher in HABs than MABs and 4-fold higher in HABs than LABs. Since LABs are very rare, we limited our data collection to the two groups HABs and MABs only. More insights on TSPO polymorphism can be found in [29].
2.5 Kinetic Analysis
Kinetic modeling is a mathematical approach used in PET imaging to quantify the pharmacokinetics of a radiotracer in various tissues. In this study, we used the 2-compartmental model (2-TCM) [30] to fit our data. This model assumes that the radiotracer in the tissue compartment can be either specifically bound to the target receptor (specifically bound compartment) or it can be free (non-specifically bound compartment). The kinetics of tracer uptake have thus been modeled mathematically through differential equations describing the exchange rate of tracer concentrations among compartments in function of time as follows (1):
where:
\(C_1\) is the tracer concentration in the non-displaceable compartment of the tissue (free and nonspecifically bound), \(C_p\) is the tracer concentration in the plasma also known as Arterial Input Function (AIF), \(C_2\) is the tracer concentration bound to the target receptors, \(K_1\) is the rate constant for transfer of tracer from plasma to the tissue, \(k_2\) is the rate constants for transfer of tracer from tissue to plasma, \(k_3\) and \(k_4\) are the rate constants for transfer of tracer from the non-displaceable compartment to the specific binding compartment of the tissue and vice versa, respectively. Knowing the tissue compartment comprises two different states of binding (non-displaceable + specific binding), the tissue concentration, \(C_t(t)\), is equal to the sum of the two states
Using the aforementioned differential equations, \(C_t(t)\) can be defined as follows:
where \(b_1\) and \(b_2\) expressions are

and \(\otimes \) denotes the mathematical convolution. In this study, we have a particular interest in deriving quantitative information about the total volume of distribution of the radiotracer as this kinetic parameter reflects the overall density and distribution of the TSPO receptors in the brain. Precisely, V\(_{\text {t}}\) represents the ratio of the tracer amount in the target tissue at equilibrium to the amount of tracer in the plasma at the same time point. Mathematically, V\(_{\text {t}}\) can be expressed in function of model rate constants as follows:
In TSPO studies, a higher V\(_{\text {t}}\) indicates a greater amount of tracer binding to the target protein, suggesting a higher level of neuroinflammation in the tissue [31].
2.6 Estimation of Reference Total Volume of Distribution
An estimate of V\(_{\text {t}}\) values was derived using the kinetic modeling tool of PMOD (https://www.pmod.com/web/). We utilized the blood TACs, plasma TACs, and regional TACs of the brain for each subject in our dataset to fit a reversible 2-TCM model, enabling us to estimate Vt values.
2.7 Total Volume of Distribution Prediction
After estimating the reference V\(_{\text {t}}\) values corresponding to each brain region and for each subject, we built our dataset by concatenating the TACs of different subjects. Initially, the TAC file of each subject contains the different intervals of scans, defined by the start and end time of the scan, and the corresponding radiotracer concentration at this interval, with respect to each brain region. On average, we have 31 ROIs for each subject. Then, we added to our dataset 3 categorical variables specifying the brain ROI, the genotype (HAB or MAB) and the health status (Healthy Control or Parkinson). For V\(_{\text {t}}\) prediction, a total of 44 subjects were included for the purpose of establishing predictive models using ML. Our predictive models are tree-based regression models, which use decision trees to predict continuous numerical values. The rationale behind choosing these approaches for our regression problem is their ability to handle the mixture of categorical and continuous variables as inputs, and to capture the non-linear relationships between variables. To find the optimal hyperparameters for our predictive models, a grid search approach was employed. Rather than dividing the available data into separate training and testing groups, 10-fold cross validation was utilized and the average performance was recorded.
2.8 Total Volume of Distribution Evaluation
To evaluate our models, the predicted V\(_{\text {t}}\) values were compared with the ones estimated by kinetic modeling and denoted as reference V\(_{\text {t}}\), for each region of interest, by the mean absolute error (MAE),
We also used Bland-Altman as a graphical method, to compare the predicted values of our ML models against the reference values, and asses the level of agreement between them. By plotting the difference between \(\hat{V_t}\) and \(V_t\) against their mean, it will help to identify any systematic bias between the two measurements, as well as the range of differences and outliers.
3 Results and Discussion
Results from comparisons between the reference and the predicted \(V_{t}\) in terms of MAE are summarized in Table 1. As shown in this table, all the tree models have predicted V\(_{\text {t}}\) with a mean absolute error ranging between 2.62 and 3, which is within an acceptable range of error for our particular problem, considering the median value of reference V\(_{\text {t}}\). These results indicate that our models are able to predict the target variable with reasonable accuracy and provide a good fit to the data. After evaluating the performance of the four tree-based models, we found that XGBoost outperformed the other models in terms of its evaluation metrics. It specifically achieved a lower MAE, equal to 2.62 compared to other models, indicating that it has a better overall performance and it can predict the target variable with greater precision. For this model, we investigated the relative importance of each feature in predicting the target variable. Based on the importance scores of XGBoost model, we can conclude that the tracer uptake concentration for the first 7 timepoints are the most influential features in making V\(_{\text {t}}\) predictions. In other words, these features are the most utilized by XGBoost in a split decision, while creating its decision trees.
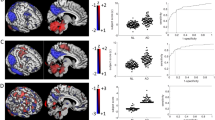
In order to provide a more comprehensive evaluation of the performance of XGBoost, we used the bland-altman plots as showed in Fig. 1. Central and outer dashed lines indicate mean value and mean ± 1.96 SD. It is important to mention that bland-altman is displaying the difference and average between the reference and predicted V\(_{\text {t}}\) for all the tissues of test data subjects. Figure 1 shows that the mean difference is 0 with a bias of 0.23 ± 2.82, among brain tissues, and 1.96 SD interval equal to −5.30 and +5.77, which is believed to be a tolerable result for a first attempt of predicting V\(_{\text {t}}\) directly from tracer uptake concentration in brain tissues. Furthermore, we can observe that the majority of the data points fell within the limits of agreement, reflecting an overall good agreement between the reference and predicted values of V\(_{\text {t}}\).

Bland-Altman plots of predicted and reference total volume of distribution \(V_{t}\) using XGBoost model for all brain tissue regions.
To further validate the results given by XGBoost, we investigated the ability of our model to highlight the genetic subgroup effects on TSPO binding. These effects have been previously explored in [25]. We are interested in reproducing these results, as we are analyzing the same dataset. In this part of our study, we will be focusing on putamen and caudate nucleus regions, as these regions are critically involved in the pathophysiology of Parkinson’s disease. Given the two possible studied genetic subgroups (HAB or MAB) and health status (HC or PD), we can distinguish between 4 groups as shown in Fig. 2. A total of 12 subjects were substracted from the initial data, 3 subjects from each group (HAB-HC, HAB-PD, MAB-HC and MAB-PD) to constitute the test data and we trained XGBoost model on the remaining data. The results showing the effect of genotype (MAB or HAB) on estimated V\(_{\text {t}}\) and predicted V\(_{\text {t}}\) for the caudate nucleus and putamen are illustrated in Fig. 2. This figure suggests that we can preserve the same effect of genotype revealed by the kinetic modeling estimated V\(_{\text {t}}\), with the exception of caudate V\(_{\text {t}}\) values of one group, which is the PD group. According to ML predicted V\(_{\text {t}}\), there is no significant difference in caudate V\(_{\text {t}}\) values within MAB-PD and HAB-PD, which is not the case for caudate V\(_{\text {t}}\) values, estimated using kinetic modeling. Still we have consistent findings for HC group in both putamen and caudate V\(_{\text {t}}\), and for PD group with regard to putamen V\(_{\text {t}}\) values, which can be considered as satisfactory results.

Comparison of kinetic modeling estimated \(V_{t}\) and ML predicted \(V_{t}\) in the caudate nucleus and in the putamen, for different genetic subgroups. The two Asterisks in the plot indicate statistical difference between two groups.
In Fig. 3, we conducted a paired t-test to determine if there were any significant differences between the reference and predicted values of V\(_{\text {t}}\). We found that predicted V\(_{\text {t}}\) are significantly different from reference V\(_{\text {t}}\) for MAB-PD and MAB-HC, respectively in the caudate nucleus and putamen regions. On the other hand, we have a good agreement between ML and kinetic modeling results for the remaining groups, in both regions, highlighting the consistency of our ML findings.

Paired t-test showing differences of reference \(V_{t}\) and predicted \(V_{t}\) within subjects of the same subgroup, in both caudate nucleus and putamen tissues. The two Asterisks in the plot indicate statistical difference between two groups.
In summary, conventional methods used for quantitative evaluation of PET imaging are achieved by means of kinetic modeling, based on compartmental and non-compartmental approaches. This requires an accurate measurement of IF as well as the application of complex kinetic modeling approaches depending on the used tracer. One of the limitations of compartment modeling is that these models use iterative fitting including IF to calculate the least squares between the measured data and the model data, which can lead to problems of overfitting and lack of reproducibility. In particular, an inappropriate IF often leads to imprecision of the assessed rates. In contrast, our proposed method, based on machine learning approaches and the [\(^{18}\)F]-FEPPA radiotracer dataset, provides a robust and reproducible solution. It is independent of the input function, representing a novelty in the quantitative analysis of PET.
4 Conclusion
In this paper, we investigated the feasibility of non-invasively estimating the V\(_{\text {t}}\) of [\(^{18}\)F]-FEPPA radiotracer, an indicator of neuroinflammation, using its activity concentration in brain tissue. We used several non-linear regression models to predict the [\(^{18}\)F]-FEPPA V\(_{\text {t}}\) in 31 brain regions of interest over 24 patients with Parkinson Disease and 20 healthy subjects. The XGBoost model showed the best results with a MAE of 2.6. Bland-Altman analysis results indicate that predicted V\(_{\text {t}}\) are in average very close to the reference with a bias of 0.23  2.82. We also found that significant main effect of genotype on [\(^{18}\)F]-FEPPA in both caudate and putamen have been preserved by predicted V\(_{\text {t}}\) values (p < 0.05) for the majority of groups. The results of paired t-test indicate that the difference between predicted and reference V\(_{\text {t}}\) is not statistically significant in 6 out of 8 groups. This study opens a new research direction in applying machine learning algorithms to provide a non-invasive and efficient tool to predict [\(^{18}\)F]-FEPPA V\(_{\text {t}}\) values, a hallmark of neuroinflammation that is believed to be a potential trigger for Parkinson’s disease development. As part of future work, our goal will be to develop predictive models to estimate the four pharmacokinetic parameters, namely K1, k2, k3, and k4. By accurately deriving these parameters, we aim to improve the estimation of the physiological parameters of the total volume of distribution V\(_{\text {t}}\) and the binding potential BP.
2.82. We also found that significant main effect of genotype on [\(^{18}\)F]-FEPPA in both caudate and putamen have been preserved by predicted V\(_{\text {t}}\) values (p < 0.05) for the majority of groups. The results of paired t-test indicate that the difference between predicted and reference V\(_{\text {t}}\) is not statistically significant in 6 out of 8 groups. This study opens a new research direction in applying machine learning algorithms to provide a non-invasive and efficient tool to predict [\(^{18}\)F]-FEPPA V\(_{\text {t}}\) values, a hallmark of neuroinflammation that is believed to be a potential trigger for Parkinson’s disease development. As part of future work, our goal will be to develop predictive models to estimate the four pharmacokinetic parameters, namely K1, k2, k3, and k4. By accurately deriving these parameters, we aim to improve the estimation of the physiological parameters of the total volume of distribution V\(_{\text {t}}\) and the binding potential BP.
References
Scheiblich, H., Trombly, M., Ramirez, A., Heneka, M.T.: Neuroimmune connections in aging and neurodegenerative diseases. Trends Immunol. 41(4), 300–312 (2020)
Guzman-Martinez, L., Maccioni, R.B., Andrade, V., Navarrete, L.P., Pastor, M.G., Ramos-Escobar, N.: Neuroinflammation as a common feature of neurodegenerative disorders. Front. Pharmacol. 10, 1008 (2019)
Deng, H., Wang, P., Jankovic, J.: The genetics of Parkinson disease. Ageing Res. Rev. 42, 72–85 (2018)
Chen, H., Ritz, B.: The search for environmental causes of Parkinson’s disease: moving forward. J. Parkinson’s Dis. 8(s1), S9–S17 (2018)
Reeve, A., Simcox, E., Turnbull, D.: Ageing and Parkinson’s disease: why is advancing age the biggest risk factor? Ageing Res. Rev. 14, 19–30 (2014)
Tansey, M.G., Goldberg, M.S.: Neuroinflammation in Parkinson’s disease: its role in neuronal death and implications for therapeutic intervention. Neurobiol. Dis. 37(3), 510–518 (2010)
Lecours, C., Bordeleau, M., Cantin, L., Parent, M., Di Paolo, T., Tremblay, M.È.: Microglial implication in Parkinson’s disease: loss of beneficial physiological roles or gain of inflammatory functions? Front. Cell. Neurosci. 12, 282 (2018)
Tejera, D., Heneka, M.T.: Microglia in neurodegenerative disorders. In: Garaschuk, O., Verkhratsky, A. (eds.) Microglia. MMB, vol. 2034, pp. 57–67. Springer, New York (2019). https://doi.org/10.1007/978-1-4939-9658-2_5
Onyango, I.G., Jauregui, G.V., Čarná, M., Bennett Jr, J.P., Stokin, G.B.: Neuroinflammation in Alzheimer’s disease. Biomedicines 9(5), 524 (2021)
Palpagama, T.H., Waldvogel, H.J., Faull, R.L.M., Kwakowsky, A.: The role of microglia and astrocytes in Huntington’s disease. Front. Mol. Neurosci. 12, 258 (2019)
Narayanaswami, V., Dahl, K., Bernard-Gauthier, V., Josephson, L., Cumming, P., Vasdev, N.: Emerging PET radiotracers and targets for imaging of neuroinflammation in neurodegenerative diseases: outlook beyond TSPO. Mol. Imaging 17, 1536012118792317 (2018)
Janssen, B., Mach, R.H.: Development of brain pet imaging agents: strategies for imaging neuroinflammation in Alzheimer’s disease. Prog. Mol. Biol. Transl. Sci. 165, 371–399 (2019)
Best, L., Ghadery, C., Pavese, N., Tai, Y.F., Strafella, A.P.: New and old TSPO PET radioligands for imaging brain microglial activation in neurodegenerative disease. Curr. Neurol. Neurosci. Rep. 19, 1–10 (2019). https://doi.org/10.1007/s11910-019-0934-y
Rissanen, E., et al.: Automated reference region extraction and population-based input function for brain [\(^{11}\)C]TMSX PET image analyses. J. Cereb. Blood Flow Metab. 35(1), 157–165 (2015)
Mabrouk, R., et al.: Feasibility study of TSPO quantification with [\(^{18}\)F]FEPPA using population-based input function. PLoS One 12(5), e0177785 (2017)
Akerele, M.I., et al.: Population-based input function for TSPO quantification and kinetic modeling with [\(^{11}\)C]-DPA-713. EJNMMI Phys. 8(1), 39 (2021). https://doi.org/10.1186/s40658-021-00381-8
Naganawa, M., et al.: Assessment of population-based input functions for Patlak imaging of whole body dynamic \(^{18}\)F-FDG PET. EJNMMI Phys. 7(1), 1–15 (2020). https://doi.org/10.1186/s40658-020-00330-x
Sundar, L.K.S., et al.: Towards quantitative [18F]FDG-PET/MRI of the brain: automated MR-driven calculation of an image-derived input function for the non-invasive determination of cerebral glucose metabolic rates. J. Cereb. Blood Flow Metab. 39(8), 1516–1530 (2019)
Galovic, M., et al.: Validation of a combined image derived input function and venous sampling approach for the quantification of [\(^{18}\)F]GE-179 PET binding in the brain. Neuroimage 237, 118194 (2021)
Sari, H., et al.: Estimation of an image derived input function with MR-defined carotid arteries in FDG-PET human studies using a novel partial volume correction method. J. Cereb. Blood Flow Metab. 37(4), 1398–1409 (2017)
Fang, Y.-H.D., McConathy, J.E., Yacoubian, T.A., Zhang, Y., Kennedy, R.E., Standaert, D.G.: Image quantification for TSPO PET with a novel image-derived input function method. Diagnostics 12(5), 1161 (2022)
Kuttner, S., et al.: Cerebral blood flow measurements with \(^{15}\)O-water PET using a non-invasive machine-learning-derived arterial input function. J. Cereb. Blood Flow Metab. 41(9), 2229–2241 (2021)
Alf, M.F., Wyss, M.T., Buck, A., Weber, B., Schibli, R., Krämer, S.D.: Quantification of brain glucose metabolism by \(^{18}\)F-FDG PET with real-time arterial and image-derived input function in mice. J. Nucl. Med. 54(1), 132–138 (2013)
Kuttner, S., et al.: Machine learning derived input-function in a dynamic \(^{18}\)F-FDG PET study of mice. Biomed. Phys. Eng. Express 6(1), 015020 (2020)
Koshimori, Y., et al.: Imaging striatal microglial activation in patients with Parkinson’s disease. PLoS One 10(9), e0138721 (2015)
Mabrouk, R., et al.: Image derived input function for [\(^{18}\)F]-FEPPA: application to quantify translocator protein (18 kDa) in the human brain. PLoS One 9(12), e115768 (2014)
Rusjan, P.M., et al.: Kinetic modeling of the monoamine oxidase B radioligand [\(^{11}\)C]SL25.1188 in human brain with high-resolution positron emission tomography. J. Cereb. Blood Flow Metab. 34(5), 883–889 (2014)
Owen, D.R.J., et al.: Mixed-affinity binding in humans with 18-kDa translocator protein ligands. J. Nucl. Med. 52(1), 24–32 (2011)
Owen, D.R., et al.: An 18-kDa translocator protein (TSPO) polymorphism explains differences in binding affinity of the PET radioligand PBR28. J. Cereb. Blood Flow Metab. 32(1), 1–5 (2012)
Innis, R.B., et al.: Consensus nomenclature for in vivo imaging of reversibly binding radioligands. J. Cereb. Blood Flow Metab. 27(9), 1533–1539 (2007)
Kreisl, W.C., et al.: In vivo radioligand binding to translocator protein correlates with severity of Alzheimer’s disease. Brain 136(7), 2228–2238 (2013)
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this paper

Cite this paper
Gassara, O., Chikhaoui, B., Mabrouk, R., Wang, S. (2023). Deriving Physiological Information from PET Images Using Machine Learning. In: Jongbae, K., Mokhtari, M., Aloulou, H., Abdulrazak, B., Seungbok, L. (eds) Digital Health Transformation, Smart Ageing, and Managing Disability. ICOST 2023. Lecture Notes in Computer Science, vol 14237. Springer, Cham. https://doi.org/10.1007/978-3-031-43950-6_3
Download citation
DOI: https://doi.org/10.1007/978-3-031-43950-6_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-43949-0
Online ISBN: 978-3-031-43950-6
eBook Packages: Computer ScienceComputer Science (R0)