
Abstract
Industrializing metal additive manufacturing for mass production requires a consistent manufacturing process that reliably produces high-quality end products. In order to meet these quality requirements, layer-wise in-situ monitoring data is captured to detect process deviations that potentially lead to product defects. However, this way of process monitoring is limited to a retrospective analysis, where defect development is usually unavoidable. Still, accurate forecasting of part fabrication within the same or subsequent layers would allow a timely corrective adjustment of the control strategy. In our work, we formulate the forecasting of part fabrication as an image inpainting problem, where areas of the part that have not been printed yet, are treated as missing regions within layer-wise in-situ image data. We propose to train generative inpainting models to fill in these missing regions, thus predicting possible outcomes of the printing process. In our experiments, we train a generative neural architecture on layer-wise images of heat signatures that were captured with an optical tomography monitoring system during Laser Powder Bed Fusion (LPBF) processes. By varying machine parameter configurations and part geometry, we evaluate the prediction capabilities of the model. Our results reveal, that our model is capable of accurately predicting realistic outcomes of LPBF processes using in-situ monitoring data with a sufficient level of detail. From that we conclude, that generative models show promising results towards an online defect prediction system, that allows a timely intervention of the current control strategy. With our approach, we lay the foundation of a model-based control framework that may prevent product defects from forming.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Laser Powder Bed Fusion (LPBF) is a layerwise manufacturing process that fabricates metallic components from powder. During the fabrication process, a laser melts powdered particles to fuse them with the underlying layer [1]. Compared to traditional manufacturing approaches, almost arbitrary geometries can be manufactured directly from a 3D model without machine preprocessing. However, due to the stochastic nature of the process, the fabrication outcome is unpredictable and therefore quality standards cannot be met consistently.
In order to mitigate the manufacturing of low-quality products, quality assurance approaches are applied either during (in-situ) or after (ex-situ) the fabrication process. Ex-situ solutions require the destruction of the fabricated part (e.g., mechanical tests), or are time and cost-expensive (e.g., computer tomography scans). Alternatively, recent research efforts aim to leverage the layerwise procedure of the manufacturing process, to monitor defect flaws within the geometry in an in-situ fashion [2]. This form of in-situ monitoring potentially enables closed-loop control systems to detect and negate the occurrence of defects during part fabrication.
With the advancement of sensor technology and the increase in data quality and quantity, machine learning (ML) technology has been extensively explored to detect part defects and process deviations within in-situ monitoring data [3]. However, these proposed solutions are usually limited by their capability of detecting defects from a retrospective perspective. In particular, their detections are applied on data from already printed areas. Consequently, these detection solutions may not be in time for a closed-loop control system.
To address this issue, we propose to use generative models to forecast the fabrication process through in-situ image data. We simplify the fabrication forecasting problem to an image inpainting problem; Image inpainting describes the task of filling missing regions within an image so that the inpainted regions match their surroundings semantically. This task simplification is possible, due to the limited exposure time of our monitoring system, where only a fraction of the whole layer is captured in a single image. By treating the missing areas within the in-situ monitoring data as holes to be filled, we train a generative model to inpaint these regions and thus forecast the fabrication process. We believe that our approach enables model-based control strategies that are capable of mitigating part defects.
Our contributions are summarized as follows:
-
We reformulate the fabrication forecasting task as an image inpainting problem (cf. Sect. 3.3) by using masks which separate regions with available information from regions with missing information (cf. Sect. 3.2).
-
We propose a hyperparameter tuning pipeline to steer the hyperparameter search towards the generation of high-quality images (cf. Sect. 4.1).
-
We quantitatively and qualitatively evaluate the forecasting performance of an image inpainting model (cf. Sect. 4.2).
2 Related Work
Currently, image-based in-situ monitoring data is mainly used to detect defects during the fabrication process. Most commonly, the developed solutions analyse images of each layer and highlight areas within the image that corresponds to a potential defect or irregularity. Specifically where LPBF processes are monitored with optical tomography (OT) sensors, that are identical to the ones from our monitoring setup (cf. Sect. 3.1), both discriminative and generative ML approaches were investigated to learn the relationship between OT image and quality metric.
Within investigated discriminative approaches, one way to use in-situ monitoring data is to detect defects through hotspots within each layer [4]. In their work, the authors propose to train a classification model in a semi-supervised fashion. Within their experiments, they show that a transfer to part geometries with increased complexity is possible.
In another work, tree-based models were used to predict the likelihood of porosity through discretizing the volume derived from a layerwise stacking of OT images into cuboids [5]. A cuboid contains a fixed number of pixel values with equal size in width and length, thus containing information from multiple layers. Based on their results, they argue that an accurate porosity prediction using one layer is not sufficient due to the self-healing phenomena of melting underlying layers.
Further work uses a fully convolutional neural network to classify OT data into three defect classes [6]. Although the presented results of the model show high accuracy in distinguishing between different defect types, it is most likely unable to distinguish between defect-free and defective layers and thus not transferable to a production-ready setup.
Besides discriminative models of previous works, generative models were also sporadically investigated in the context of LPBF processes. The first contribution that uses in-situ OT image data to train generative models was presented in [7]. In their work, the authors were able to predict possible energy emissions layer-wise using the information on part contour and scan vector orientation, before printing the part with the machine. However, the model prediction ignores energy emission deviations from geometry information (e.g., overhang angle), that may impact the resulting energy distribution within a layer.
The work presented in [8] extends the results from [7] involving the part contour of multiple layers as input data to the generative model. The resulting model was capable of predicting laser emissions with overhang angles up to 45\(^\circ \). Both approaches aim to predict the fabrication outcome of a whole layer, without considering the sequential and fragmentary properties of the collected data. By conditioning the prediction on available information from already printed regions, we not only simplify the forecasting task, but also generate fabrication outcomes at any time step during the process.
3 Methods
Compared to the presented related work, we propose to use image inpainting models to forecast the fabrication process with in-situ monitoring data. For that, we first collect OT images during the printing process and derive a binary mask that separates fabricated areas from missing ones. With the acquired data, we train an image inpainting model to fill in the missing areas, which is equivalent to forecasting the fabrication process.
3.1 Data Acquisition
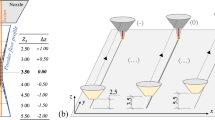
Our monitoring and manufacturing setup is based on the work of Zenzinger et al. [9]. We execute our printing jobs on a laboratory machine EOS M 290 in which a near-infrared (NIR) scientific complementary metal-oxide-semiconductor (sCMOS) camera PCO.edge 5.5 is integrated. The camera’s field of view covers the whole building platform, with a size of \(250 \times 250\) mm. Due to the limited camera exposure time of 2 s, multiple heat signature images are captured per layer throughout the continuous fabrication process. All thermal radiation emitted during the exposure time of the camera from the melt pool is aggregated into one heat signature image of the processing area. In fact, each layer composes of multiple heat signature images, where the exact number depends on part geometry and printing parameter (e.g., scanning speed). A photodiode was integrated into the machine setup to detect the printing start and end of each layer, therefore enabling a clear separation of all images into their corresponding layer number. Our whole setup is illustrated in Fig. 1.

LPBF experiment and monitoring setup, displayed (a) schematically with its corresponding (b) real-world implementation at the Digital Additive Production chair (DAP).
With the presented machine and monitoring setup, we print \(n_g=5\) different geometries, provided by the DIN EN ISO/ASTM 52902 [10], with different parameter combinations, depicted in Table 1. The selected geometries were a linear test body (LA), a circular-shaped test body (CA_F), and three resolution test bodies, one for holes (RH_F), one for slits (RS_F) and one for slit angles (RSA_F). The parts were arranged on the building platform as described in Fig. 3. Because the layer thickness is held constant, each geometry g consists of a different number of total layers \(L_g\).
3.2 Data Preprocessing
After capturing the OT image data, preprocessing steps are necessary to create a dataset suitable for model training. First, we use manually drawn rectangular bounding boxes, to crop image patches from the raw OT image data and afterwards sort out image patches that do not contain any heat signatures. Grouping all image patches based on part geometry g and part position p results in a sequence of images \(\mathcal {X} = \{x^{(t)} |\ t = 1 \dots T_l\}\) for each layer l, with sequence length \(T_l\). By summing up all images of \(\mathcal {X}\) pixelwise, we end up with an image \(x = \sum _{t=1}^{T_l} x^{(t)}\) that captures the heat signature of a whole layer of one part.
Given an image x and its corresponding sequence \(\mathcal {X}\), we derive a binary mask \(m^{(t)}\) from \(x^{(t)}\), which separates visible heat signature regions from missing ones. The mask is calculated according to Eq. (1) using Otsu thresholding \(\mathsf {O(\cdot )}\) [11], in which \([ \cdot \leftrightarrow \cdot ]\) denotes a pixel-wise logical biconditional operator. Thus, forming for each layer l equivalently to \(\mathcal {X}\) a sequence of masks \(\mathcal {M} = \{m^{(t)} |\ t = 1 \dots T_l\}\).
We end up with a dataset \(\mathcal {D}\) according to Eq. (2) of triplets containing, for each layer l, part position p and part geometry g, a sequence of images \(\mathcal {X}\) with their corresponding sequence of masks \(\mathcal {M}\) and a single image x that captures the heat signature of the part’s cross-section. Example images with their corresponding masks are illustrated in Fig. 2.

Example images of dataset \(\mathcal {D}\), of part geometry CA_F are shown. The first 4 columns depict pairs from sequences \(\mathcal {X}\) and \(\mathcal {M}\) at different time steps t and layer l. The last column shows the complete heat signature x of each layer.
3.3 Inpainting In-Situ Monitoring Data
Due to the sequential nature of the image capturing process, we rephrase the fabrication forecasting problem as a prediction task of heat signatures x for an arbitrary layer at time step \(\tau < T_l\), given its subsequence of images \(\mathcal {X}^\tau = \{x^{(t)} |\ t = 1 \dots \tau \} \subset \mathcal {X}\). Because the overlap between each \(x^{(t)} \in \mathcal {X}\) appears only at the edges of its heat signature, we further reformulate the forecasting problem as an image inpainting problem. That is, to fill in the missing regions of \(x_\tau = \sum _{t=1}^\tau x^{(t)}\), given its corresponding mask \(m_{\tau }\), which is similarly derived according to Eq. (1), with time step \(\tau < T_l\). With \(x_\tau \) and \(m_{\tau }\) defined, we train an image inpainting model \(f_\theta \) to predict an inpainted heat signature \(\hat{x}_\tau \) according to Eq. (3).
Model Architecture. With the fabrication forecasting problem defined, we train a U-Net architecture with partial convolutions (PConvUnet) [12] to inpaint missing regions of heat signatures. The authors of the model replaced the convolutional layers of a U-Net with partial convolutions. A partial convolution operates like a regular one but is conditioned on a mask, so that the kernel operation weights valid pixels higher.
Loss Functions. Besides the model architecture, the training of image inpainting models relies on the design of a loss function, which results in generated images that cover plausible inpaintings and display sharp image quality features. Consequently, we adopt the same approach of the original publication [12], where the loss function is a weighted sum of different loss terms, each covering separate image quality aspects of the generated image:
-
1.
The reconstruction loss enforces an accurate per-pixel reconstruction of the generated image. This is done by calculating the mean absolute error of all pixel values between the generated and the ground truth image.
-
2.
Compared to the reconstruction loss on pixel level, the perceptual and style loss uses a pretrained network \(\phi (\cdot )\) to extract high-level features from the generated image \(\hat{x}\) and the ground truth image x. This allows to calculate image differences on a higher feature level. Compared to the original approach in [12], we use a ResNet50 architecture from [13], that is pretrained on greyscale images.
Finally, each weight of the sum is determined through a hyperparameter search, which is described in our experimental setup in Sect. 4.1.

The layout of part position within our printing setup. On the left side, the building platform is depicted with its distinct \(n_p=8\) part positions. On the right side, a zoomed-in view of a part position p with its relative part geometry arrangement is presented.
4 Experiments
4.1 Model Training Setup
After describing the model architecture and loss function, we present our two-stage model training setup. First, we search for the best hyperparameter configuration that leads to the best-performing models, and second, we use the found hyperparameters to train ten models with different random seeds to derive a robust model performance evaluation.
Hyperparameter Tuning. During hyperparameter tuning, multiple trials are executed in which one model is trained with a fixed set of hyperparameters each. For each trial, the hyperparameter combination is sampled from a predefined parameter range, and after each training run the model is evaluated based on a predefined performance metric. For our experiments, we define our parameter ranges to be comparable to those proposed by the model’s authors. However, because the loss function does not necessarily correlate perfectly with image quality, we propose to use the HaarPSI (HPSI) [14] image quality metric to evaluate the performance of our models. In their work, the authors show that HPSI values fit well with human perception of image similarity. During tuning, we use the early stopping strategy Asynchronous Successive Halving Algorithm (ASHA) [15], which stops low performing runs early. We combine ASHA with a Tree-structured Parzan estimator approach (TPE) [16] that learns a probability distribution of the expected improvement of the model performance over the hyperparameter space and thus increases sample efficiency of hyperparameter combinations. We implement our whole training pipeline using the hyperparameter tuning framework ray-tune [17].
Data Augmentation. In order to further augment the available training samples, we load images during training with reflection padding and random cropping. Furthermore, we introduce an augmentation technique, that instead of using \(x_\tau \) adds up random subsequent \(x^{(t)}\) into one training instance \(x_{\tau :i}\) according to equation (4), where \(U(\cdot , \cdot )\) depicts a uniform distribution. By varying the available information through this sampling method, we increase the data variation during training.
4.2 Results
Through our experiments, we first investigate the influence of part geometry g, machine parameters represented by part position p and the amount of available information represented by time step \(\tau \) on the inpainting performance measured with image quality metric HPSI. Afterwards, we present samples of generated images to qualitatively demonstrate the models’ prediction ability and limitations.

In the pairwise matrix plot, part geometries are arranged column-wise and machine parameter configuration p row-wise. For each part geometry and machine parameter configuration, the frequency of HPSI values for generated images \(\hat{x}\) over \(\tau \) is displayed. For machine parameter configurations \(p>5\) the results were omitted, due to the high scanning speed v, resulting in distributions similar to that of geometry RH_F.
In Fig. 4 we can observe that for all five printed geometries and the depicted machine parameter configuration, an overall high HPSI score for the inpainted samples can be achieved. A higher HPSI value corresponds to a better match between \(\hat{x}\) and x. Thus, indicating good image quality of the model prediction. With the increase of available information, the inpainting task should become easier. Our results confirm this assumption, that indeed with increasing \(\tau \), which corresponds to the amount of available information, the probability of generating an image with high HPSI increases too. However, our results also show, that images with low HPSI were generated, despite the high amount of available information. This becomes especially relevant, for parts where one layer is printed in a few time steps, like LA and RH_F, so that an accurate prediction should be possible after one or two time steps t.

The top row depicts machine parameter configurations at position \(p=3\), and the bottom row depicts position \(p=5\). One square tile consists of \(x_\tau \) (top left), its corresponding mask \(m_\tau \) (top right), the cross-section heat signature x (bottom left) and the predicted image \(\hat{x}\) (bottom right). Other machine parameter configurations are omitted due to low energy distribution levels and therefore low image contrast.
Besides an overview of the distribution of HPSI values across different geometries and machine parameter configurations, we also show inpainting results with their corresponding HPSI values in Fig. 5. The generated samples display accurate heat signature levels, which can be visually confirmed by comparing the greyscale values of x and \(\hat{x}\). But under closer inspection, we observe that the model inpaintings are limited by their degree of detailed features. Especially in images, where bigger regions are missing (see Fig. 5 geometry CA_F and \(p=5\)), instead of detailed textures, the missing area was filled with an almost evenly distributed grey value. This indicates that the model learned to average over all possible solutions, instead of distinct detailed solutions. However, features like slits that occur in part geometries like RSA_F and RS_F are accurately extended, thus confirming that the model is capable of generating images with features of a limited level.
5 Discussion and Conclusion
With our results, we demonstrated the inpainting performance of our model to produce high-quality images with plausible heat signature levels and to some degree detailed feature continuity. High HPSI values of generated samples compared to corresponding ground truth instances indicate high fabrication forecasting accuracy. However, with the illustrated limited level of detail in the generated samples, small critical features like pores that cover a few pixels will not be predictable. We conclude from our results, that further inpainting performance improvements are required, by either adjusting the presented approach or modifying the model architecture.
Although previous work of Gobert et al. [7] and Zhang et al. [8] already applied generative models for LPBF in-situ OT monitoring data, their results are only comparable on an image-based qualitative level. In both works, the authors evaluate their models by manually comparing expected heat signature features between prediction and ground truth. Likewise, we validated the performance of our model through the continuity of slits, which arguably surpasses the level of detail from generated images in previously reported results. Because qualitative evaluations depend on the subjective opinion and domain expertise of the evaluator, we additionally introduced the usage of HPSI as an image quality metric to quantify our model performance. This not only enables better comparability between results, but also provides a model hyperparameter tuning objective. Although HPSI is reported to correlate with human perception, it remains up to debate, how to accurately measure fabrication forecasting performance for LPBF processes.
Our contribution and the associated improvement in fabrication forecasting enable more-profound decisions during process control. Although the presented forecasting capabilities are limited to the same layer and regarding the feature level of detail, they leverage the time dependant sequential property of the printing process and monitoring setup, to predict future fabrication outcomes. Given an accurate online forecasting model of the fabrication process, model-based predictive control strategies could use these forecasting predictions to steer the fabrication process towards a defect-free manufacturing result.
References
Verein Deutscher Ingenieure: VDI 3405: Additive Fertigungsverfahren: Grundlagen. Begriffe, Verfahrensbeschreibungen (2014)
Grasso, M., Remani, A., Dickins, A., Colosimo, B.M., Leach, R.K.: In-situ measurement and monitoring methods for metal powder bed fusion: an updated review. Meas. Sci. Technol. 32(11), 112001 (2021)
Mahmoud, D., Magolon, M., Boer, J., Elbestawi, M.A., Mohammadi, M.G.: Applications of machine learning in process monitoring and controls of L-PBF additive manufacturing: a review. Appl. Sci. 11(24), 11910 (2021)
Yadav, P., Singh, V.K., Joffre, T., Rigo, O., Arvieu, C., Le Guen, E., Lacoste, E.: Inline drift detection using monitoring systems and machine learning in selective laser melting. Adv. Eng. Mater. 22(12), 2000660 (2020)
Feng, S., Chen, Z., Bircher, B., Ji, Z., Nyborg, L., Bigot, S.: Predicting laser powder bed fusion defects through in-process monitoring data and machine learning. Mater. Des. 222, 111115 (2022). https://ncedirect.com/science/article/pii/S0264127522007377
Schwerz, C., Nyborg, L.: A neural network for identification and classification of systematic internal flaws in laser powder bed fusion. CIRP J. Manuf. Sci. Technol. 37, 312–318 (2022)
Gobert, C., Arrieta, E., Belmontes, A., Wicker, R.B., Medina, F., McWilliams, B.: Conditional generative adversarial networks for in-situ layerwise additive manufacturing data (2019)
Zhang, S., Jahn, A., Jauer, L., Schleifenbaum, J.H.: Geometry-based radiation prediction of laser exposure area for laser powder bed fusion using deep learning. Appl. Sci. 12(17), 8854 (2022). https://www.mdpi.com/2076-3417/12/17/8854
Zenzinger, G., Bamberg, J., Ladewig, A., Hess, T., Henkel, B., Satzger, W.: Process monitoring of additive manufacturing by using optical tomography. In: AIP Conference Proceedings, pp. 164–170 (2015)
Deutsches Institut für Normung: DIN EN ISO/ASTM 52902:2020–05: Additive manufacturing - test artifacts - geometric capability assessment of additive manufacturing systems (ISO/ASTM 52902:2019); German version EN ISO/ASTM 52902:2019 (2020–05)
Otsu, N.: A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 9(1), 62–66 (1979)
Liu, G., Reda, F.A., Shih, K.J., Wang, T.-C., Tao, A., Catanzaro, B.: Image inpainting for irregular holes using partial convolutions. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11215, pp. 89–105. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01252-6_6
Zhao, Y., et al.: VCGAN: video colorization with hybrid generative adversarial network. IEEE Trans. Multimedia, 1 (2022). https://arxiv.org/pdf/2104.12357
Reisenhofer, R., Bosse, S., Kutyniok, G., Wiegand, T.: A Haar wavelet-based perceptual similarity index for image quality assessment. Sig. Process. Image Commun. 61, 33–43 (2018). https://www.sciencedirect.com/science/article/pii/S0923596517302187
Li, L., et al.: A system for massively parallel hyperparameter tuning. In: Conference on Machine Learning and Systems (2020). https://arxiv.org/pdf/1810.05934
Bergstra, J., Yamins, D., Cox, D.D.: Making a science of model search: hyperparameter optimization in hundreds of dimensions for vision architectures. In: Proceedings of the 30th International Conference on International Conference on Machine Learning - Volume 28, ICML 2013, pp. I-115–I-123. JMLR.org (2013)
Liaw, R., Liang, E., Nishihara, R., Moritz, P., Gonzalez, J.E., Stoica, I.: Tune: a research platform for distributed model selection and training. arXiv preprint arXiv:1807.05118 (2018)
Acknowledgments
Funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy - EXC-2023 Internet of Production - 390621612. Simulations were performed with computing resources granted by RWTH Aachen University under project rwth1228.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Zhou, H.A., Zhang, S., Kemmerling, M., Lütticke, D., Schleifenbaum, J.H., Schmitt, R.H. (2024). Fabrication Forecasting of LPBF Processes Through Image Inpainting with In-Situ Monitoring Data. In: Klahn, C., Meboldt, M., Ferchow, J. (eds) Industrializing Additive Manufacturing. AMPA 2023. Springer Tracts in Additive Manufacturing. Springer, Cham. https://doi.org/10.1007/978-3-031-42983-5_10
Download citation
DOI: https://doi.org/10.1007/978-3-031-42983-5_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-42982-8
Online ISBN: 978-3-031-42983-5
eBook Packages: EngineeringEngineering (R0)