
Abstract
The purpose of model evaluation is to assess the model’s suitability for the intended purpose. In the evaluation of clinical models, we consider three levels of evaluation. At the core, we are concerned with predictive performance, namely whether the model we constructed has sufficiently high predictive ability. On the next level, we are concerned with generalizability. We wish to ensure the model is robust to changes over time and we may wish to know whether the model can generalize to different demographics at different geographic locations or to a different service with different disease severity. Finally, on the third level, we evaluate the model from the perspective of achieving the clinical objective and doing so at a cost that is acceptable to the health system.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others
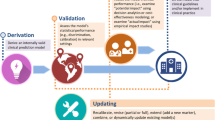


The purpose of evaluating a clinical model is to ensure that a model has sufficient performance, is valid in the target population (and any other population of interest), and is capable of achieving the clinical objectives at a cost that is acceptable to the health system.
We consider three levels of model evaluation. Let us illustrate these levels through the hypothetical example of developing a screening test. Suppose a diagnostic test for a disease exists, it is reliable, but invasive and can cause serious adverse events. We wish to develop a machine learning based screening model that determines whether a patient needs to undergo this invasive diagnostic test. We evaluate this screening model.
On the first layer, we have to ensure that the model can predict the outcome and has sufficiently high predictive performance to capture patients at high risk of the outcome who really need to undergo the invasive diagnostic test.
On the second layer, we are concerned with the validity of the model. As we discussed in chapter “Data Design”, the model is developed on a discovery sample with the intent of applying it in the target population. We discussed two kinds of validations. First, internal validation is concerned with generalization from the discovery sample to the accessible population; and external validation is concerned with generalizability to the target population and other populations of interest. More formally, external validation refers to validating a model in a setting that is different from the setting of the accessible population. The setting can differ, for example, in the time frame, geographic location, data collection method, or clinical setting (clinical application).
Finally, on the third layer, we wish to ensure that the model achieves the health objective of reducing adverse events from the invasive test without missing too many patients with the disease. We wish to do this at a reasonable cost; ideally, the added cost of the ML-based screening test is offset by the savings on the invasive diagnostic test and its adverse events.
Section “Evaluating Model Performance” focuses on the core evaluation, where we discuss the predictive performance of a model. In sections “Clinical Usefullness” and “Health Economic Evaluation”, we evaluate the clinical utility and health economic impact of the model. Finally, in section “Estimators of Model Performance”, we discuss internal and external validation, as well as “estimators”, methods for estimating model performance in the context of generalizability.
Evaluating Model Performance
In this section, we focus on common measures (or metrics) of model performance. In the course of writing this book, we found over 30 different measures of model performance just for time-to-event outcomes alone, many of which were proposed recently. Therefore, complete coverage of the measures in existence is impractical. Instead, we aim to provide an extensive overview of measures, and we specifically strive to include measures that measure different aspects of model performance, that have different properties, or measures that are derived from different principles (e.g. how close is the estimate to the actual value; how does the estimate co-vary with the actual value, or how well does the model fit the data). Not all of these measures are commonly used. For example, among the 30 performance measures for time-to-event outcomes, one measure, Harrell’s C statistic, covers 63% of the published literature [1]. To guide the reader, we will indicate which measures are commonly used, which combinations of measures provide complementary information and under what conditions is a combination preferable over another.
Best Practice 9.1.1
Use evaluation metrics appropriate for the outcome type.
Best Practice 9.1.2
Multiple metrics are needed to cover different aspects of model performance. Use sets of measures that provide complementary information.
We present the measures organized by model outcome types. In this section, we discuss measures for categorical (including binary and multinomial); in the subsequent two sections, we discuss continuous (Gaussian and non-Gaussian) and time-to-event outcomes. Finally, we discuss calibration in section “Calibration”, which applies to all of the above outcome types.
Model Performance Metrics for Classification
We grouped measures of classification performance into two groups. The first group is directly based on the contingency matrix (and thus misclassifications). These methods typically require the prediction, which is often a score or a probability, to be converted into an actual predicted class label. The second group, which we call discrimination-based measures, do not require the conversion of a score into predicted class labels.
Performance Metrics Based on the Contingency Matrix
At the core of the first group of evaluation metrics lies the contingency table (sometimes called the misclassification table or confusion matrix) depicted in Table 1 [2,3,4]. In binary (two-class) classification problems, a subject can be predicted to be positive or negative. If the subject is predicted positive, they fall into the first column; if predicted negative, into the second column. In reality, the subject can be positive or negative. If the subject is a positive, they fall into the first row of the table (actual positive, AP), and if they are actual negative, they fall into the second row (actual negative, AN). Subjects who are predicted to be positive (first column) and are actually positive (first row) are true positives (TP); subjects who are predicted positive (first column) but are actually negative (second row) are false positives (FP). Analogously, subjects who are predicted negative (second column) and are actually positive (first row) are false negatives (FN); and subjects who are predicted to be negative (second column) and are actually negatives (second row) are true negatives (TN).
Based on the contingency table, the following measures can be defined (Table 2).
A number of additional measures can also be defined (Table 3) and these are used in some fields of study.
Mathematically related measures. Table 3 contains measures in pairs, where the top measure is mathematically related to the measure below. They describe the same aspect of a classifier. For example, true positive rate TPR is the proportion of true positives among the actual positives. Since the actual positives are TP + FN, the false negative rate (FNR), which describes the false negatives among the actual positives, is simply 1-TPR. FNR offers no information about the classifier beyond what TPR already offered.
Complementary measures. Each pair of complementary measures describes different aspects of the classifier. For example, one measure can describe how well the classifier performs on actual positive subjects, while the second measure can describe how well the classifier performs on actual negative subjects. Common pairs include precision and recall. Precision describes how selective the classifier is for positive subjects, but does not tell us what percentage of the actual positives we selected. A classifier that only classifies a single subject as positive, and that subject is actually positive, has a precision of 1 (100%) but is very likely useless, since it fails to identify the vast majority of the positive cases. In a complementary manner, recall provides exactly this missing piece of information. Similarly, sensitivity and specificity are a commonly used pair. Sensitivity tells us what percentage of the actual positives the classifier classified as positive, while specificity tells us the percentage of actual negatives classified as negative. A trivial classifier, which classifies every subject as positive, has sensitivity of 1 (100%), but is useless. In a complementary manner, specificity would show that this classifier captured none of the actual negatives, thus it has specificity of 0. A third complementary pair that is commonly used is bias and discrimination, which we will describe later.
Pitfall 9.1.1
Don’t use mathematically related measures together. They do not provide additional information.
Best Practice 9.1.3
Common complementary pairs of classifier performance evaluation metrics include: (1) precision/recall; (2) specificity/sensitivity; (3) bias/discrimination.
Measures that Describe the Performance with Respect to Both Positives and Negatives
Given these complementary pairs of measures, it is reasonable to ask whether there are measures that can do both: describe positives and negatives. There are two commonly used measures that achieve this goal. First is accuracy (percent correctly classified).
While accuracy involves both the true positives and negatives, as a percentage of the entire population, it is very sensitive to the distribution of actual positives and negatives in the population. Suppose only 1% of the population is positive, then a trivial classifier, which classifies nobody as positive, achieves a seemingly very high 99% accuracy, yet this classifier is completely uninformative.
Pitfall 9.1.2
Accuracy is very sensitive to the prevalence of actual positives and negatives.
Another measure that combines performance with respect to positive and negative subjects is F-measure
where ‘prec’ denotes precision (predictive positive value). One drawback of the F-measure (specifically the F1 measure) is that it assigns equal importance to precision and recall.
Weighted Confusion Matrices
In some applications, the cost of misclassification can be different between false positives and false negatives. For example, in case of a screening test, the harm caused by false positives (the screening test incorrectly reports the patient as having the disease) is often lower than the harm caused by false negatives (the screening test missed a case completely). In the former case, the patient may undergo a more invasive diagnostic test that determines that the patient does not actually have the disease, while in the latter case, the patient may remain undiagnosed for possibly a long period of time, suffering the consequences of the undiagnosed disease.
The confusion matrix can be element-wise multiplied with the weight matrix (Table 4) and weighted versions of the measures from Tables 2 and 3 can be computed. For example, a weighted version of accuracy would become
When different types of misclassifications have different consequences, the TP, TN, FP and FNs can be assigned weights in the computation of the evaluation measures based on contingency tables.
Measures of Discrimination
Many classifier models produce a score or a probability of a subject belonging to one class versus another. Confusion matrices require that we dichotomize the score into a predicted class: subjects with a score above a threshold are considered positive, those with a score below the threshold are classified as negative. The values in the confusion matrix, namely the number of TP, TN, FP, NF are influenced by this threshold, and thus the metrics we compute from the confusion matrix are influenced by this threshold. Consequently, when we compare two classifiers, our preference for one over the other may also be influenced by this threshold.
For classifiers that output a score or probability of an instance belonging to the positive class, measures of classifier performance in Tables 2 and 3 require the specification of a threshold for classifying an instance positive (above the threshold) or negative (at or below the threshold). This threshold influences the performance measurements.
In this section, we look at measures of discrimination, the classifier’s ability to distinguish between the two classes, without requiring such a threshold.
Concordance
Concordance operates directly on the score without having to threshold it into a decision. Concordance (C-statistic or discrimination by other names) is the probability that in a randomly selected pair of patients, one actual positive and one actual negative, the actual positive patient has a higher score than the actual negative patient. For binary classification, the C-statistic can be computed as the area under the ROC (to be described next) and thus it is also known as Area Under the ROC (AUC).
Concordance is related to the measures based on the confusion matrix. Consider every distinct score S a classifier produces. We use each score as the threshold for determining a predicted label: patients with scores above this threshold are predicted positive (PP) and at the score or below are predicted negative (PN). We can now compute the true positive rate (TPR) and the false positive rate (FPR). The S different thresholds result in S different TPR-FPR pairs, which we can plot. The resulting curve is called the Receiver Operating Curve (ROC).
Example 9.1.1
Consider a hypothetical classifier that produced the following predictions on a hypothetical data set (0.01, 0.02, 0.05, 0.19, 0.21, 0.3) with the corresponding true outcomes being (0, 1, 0, 1, 0, 1). These six distinct predicted probabilities yield seven different thresholds as summarized in Table 5.
-
With a cutoff of 0, observations with predicted probability >0 are classified as positive. In this case all observations have predicted probability >0, thus all observations are predicted positives. Among these 3 are actual positive and 3 are actual negative observations. Therefore, we have 3 true positives (TP = 3) and 3 false positives (FP = 3). The sensitivity is 3/3 = 1 and the specificity is 0/3 = 0.
-
When we increase the cutoff to 0.01, the one observation with predicted probability of 0.01 becomes predicted negative and all other observations (with predicted probability >0.01) remain predicted positives. Given that this observation is an actual negative, the number of true negatives increases (to 1) and the number of false positives decreases (to 2). This yields a sensitivity of 3/3 = 1 and a specificity of 1/3 = 0.333.
-
As the cutoff increases to 0.02, one actual positive patient gets reclassified from predicted positive to predicted negative, thus sensitivity becomes 2/3 = 0.667 and specificity remains 1/3 = 0.333. Proceeding in the same manner, the last cutoff is 0.3. At this cutoff, nobody is classified as predicted positive (since no predicted probability > 0.3), thus sensitivity is 0 and specificity is 1.
The ROC for this example is shown in Fig. 1. The seven rows of the table correspond to the seven points in the plot, with the first row being the lightest blue and the last row being the darkest blue.

The ROC based on Table 5. The point corresponding to the first row of the table is the darkest blue and the last row is the lightest blue
The ROCs are plots of the classifier’s performance at various thresholds (for classifying an instance positive). Sensitivity is plotted against 1-specificity.
The ideal classifier has a FPR of zero, meaning that none of the actual negative subjects were classifiers as (false) positives. It has a TPR of 1, meaning that every actual postive patient is classified as positive. The ideal classifier would reside in the top left corner of the ROC. A completely uninformative classifier resides on a diagonal line from (0, 0) to (1, 1) with an AUC of 0.5.
Interpretation of the ROC. Figure 2 depicts two classifiers, Model 1 and 2, built on the same data set, having the same AUC of 0.7, but different characteristics. The horizontal axis is (1-specificity), also known as the false positive rate, which is the proportion of false positives among the actual negatives. The vertical axis is sensitivity (also known as recall), which is the proportion of true positives among the actual positives. When the false positive rate is low (1-Specificity < 0.5), Model 1, depicted in blue, achieves higher sensitivity, than Model 2 (depicted in orange). Conversely, when the false positive rate is high, Model 2 has higher sensitivity. If the application of the modeling requires low false positive rate, then Model 1 is preferable; but if for a different application, false positives are less of a concern than false negatives, then we may prefer Model 2. For example, Model 1 is preferable as a risk model, which targets an intervention to a small portion of the population at high risk, while Model 2 would be preferable as a screening model, where the main objective is to identify as many true positives as possible.

Comparing the ROCs for two models built on the same data set that achieve the same AUC (of 0.7) but have different characteristics
In addition, the following probabilistic relationships are valid interpretations of the AUC ROC:
-
The probability that a random positive case is ranked before a random negative case. (= probability that a random pair with one positive and one negative case are ranked correctly).
-
The proportion of positives ranked before a random negative case.
-
The proportion of negatives ranked after a random positive case.
-
The expected true positive rate if the ranking is split just before a random negative case.
-
The expected false positive rate if the ranking is split just after a uniformly drawn random positive.
Lorenz Curve
Lorenz curves [5] were originally introduced in econometrics in 1905 to depict the distribution of wealth. The horizontal axis shows the cumulative distribution of the population in increasing order of wealth and the vertical axis corresponds to the cumulative distribution of wealth. The Lorenz curve has been adapted to health sciences.
The Lorenz curve depicts classifier performance. The horizontal axis represents the cumulative distribution of observations that are predicted positives ordered in increasing order of risk and the vertical axis is the cumulative distribution of positive outcomes.
Other parameterizations of the axes are possible: patients could be ordered in decreasing order of risk and the vertical axis could represent the cumulative distribution of the missed negatives (false negatives).
Interpreting the Lorenz curve (Fig. 3). The interpretation of the Lorenz curves is more straightforward than that of an ROC. The horizontal axis corresponds to the cumulative proportion of the population classified as positive when ordered in increasing order of risk. In plain English, the value p on the horizontal axis corresponds to the 100p percent of patients with the lowest predicted risk. The vertical axis is sensitivity (recall). The orange line, corresponding to Model 2, shows that the 30% of the population with the lowest predicted risk (0.25 on the horizontal axis) contains no actual positives (sensitivity = 0), while the blue line (corresponding to Model 1) indicates that Model 1 included 10% of the positives. If we used 0.25 as the classification threshold, namely, subjects with predicted probability of outcome in excess of 0.25 are predicted positives, classification by Model 1 would have resulted in 10% false negatives and no false negatives by Model 2. Again, Model 2 (orange) is better at identifying low risk patients, while Model 1 (blue) is better at identifying high risk patients.

Comparing the Lorenz curves of the two models from Fig. 2. The two models were built on the same data set, achieve the same AUC (of 0.7) but have different characteristics
Comparing the ROC and the Lorenz Curves
Figure 4 depicts the ROC for the two models and also the “inverted” Lorenz curve, where the Lorenz curve is “flipped” along both axes. We can see that the “inverted” Lorenz curve and the ROC are very similar. Also, the differences between the two models are also very similar regardless of which curves we use.

Comparison of the ROCs for the two models from Fig. 2 along with the “inverted” Lorenz curves. The “inverted” Lorenz curve is “flipped” along both axes
Lorenz curves offer two key benefits. (1) Their interpretation is more straightforward than that of ROCs. (2) The Lorenz curves are advantageous when we are interested in predictive performance on low-risk patients. Predictive performance for the high-risk patients looks very similar to the ROC, and we can thus approximately interpret the ROC as a Lorenz curve with respect to the high-risk patients.
The Lorenz curves and the ROC contain similar information and are generally similar.
Best Practice 9.1.4
The ROC is much more commonly used than the Lorenz curve and is more familiar to many readers.
Best Practice 9.1.5
Consider showing the Lorenz curve (possibly in combination with the ROC) when low-risk patients are of particular interest.
For both ROC and Lorenz curves, the uninformative model, i.e. model with AUC of 0.5, is a diagonal line from (0, 0) to (1,1). The ideal point on an ROC curve is where the false positive rate is 0 and the sensitivity is 1. This is the top left corner. The ideal point on the Lorenz curve is where the model classifies all negatives as negative without any false negatives. This point is (1-prevalence) on the horizontal axis and 0 on the vertical axis.
Pitfall 9.1.3
Lorenz curves depend on the prevalence of the disease; ROCs do not.
Another consequence of the dependence on the outcome prevalence is that Lorenz curves are only comparable within the same population (or populations with the same outcome prevalence). Generally, models are compared within the same population, so this is more of a theoretical limitation.
Precision-Recall (PR) Curve and AUC-PR
The precision-recall (PR) [6] curve plots the performance of a classifier in a way that is similar to the ROC. The horizontal axis is recall and the vertical axis is precision. Each point corresponds to a classification threshold. Recall that for classifiers that produce a score, observations with a score above the threshold are classified as positive and (at or) below the threshold as negative.
Analogously to AUC for the ROC, the PR curve also has a summary statistic, which is the area under the PR curve (AUC-PR, also known as AUPRC).
Multi-Class Classification
Confusion matrices for the multi-class classification setting with k classes (typically, k>2) will have k columns corresponding to the k predicted labels and k rows corresponding to the k actual labels [7].
A measure like accuracy can be computed in a straightforward manner, representing the proportion of subjects correctly classified.
A key disadvantage of accuracy, as we discussed earlier, is that it is affected by the prior probabilities of the classes. Cohen’s kappa is a measurement of agreement between two sets of classifications (the predicted and the true in this application). Unlike accuracy, Cohen’s kappa takes the agreement that arises by chance between the two classifications into agreement [7]. However, under some unbalanced conditions, it has been shown to be incoherent, assigning better score to the worse classifier [8].
While additional metrics that are specific to multi-class classification exist (e.g. Matthews Correlation Coefficient; MCC [8]), in the followings, we focus on general strategies to convert the evaluation of multi-class classification into a sequence of binary classifications. This strategy has the advantage that it can be used with virtually all of the above measures.
In a multi-class classification problem with k classes, the computation of most performance measures requires that the multi-class problem is broken down into a series of binary classifications following one of two main strategies, One-Vs-One or One-vs-All.
These strategies perform a sequence of evaluations. In the One-Vs-One strategy, each evaluation corresponds to a pair of class labels, measuring the model’s ability to classify one of these two classes versus the other. One evaluation is carried out for all pairs of classes. In the One-Vs-All strategy, each evaluation measures the model’s ability to classify one class versus all other classes [9].
The binary classification metrics are computed for each comparison and are averaged. For example, computing the precision of a k-class classification model using the One-vs-All strategy will initially result in k precision values which are later averaged. Averaging can be done by computing the arithmetic mean of the k performance metrics or by computing the weighted average of these metrics, where the weight is proportional to the number of instances belonging to the class.
To incorporate the cost of misclassification, the multi-class confusion matrix can be element-wise multiplied by a k-by-k weight matrix, where each cell contains the weight associated with the misclassification cost.
Model Performance Measures for Continuous Outcomes
-
Measures of predictive model performance for continuous outcomes fall into two groups: those that examine the residuals (difference between the prediction and the actual value) and aggregate them into an overall value; and (2) metrics that measure how well the prediction covaries with the actual value.
The first group is (somewhat) analogous to the misclassification-based measures, while the second group is analogous to concordance in classification [10]. We explore these two groups in the following two sections.
Residual Based Metrics
Let \( \hat{y}_i \) denote the prediction from a model and let yi denote the actual value. The squared residual (squared error; SE) is defined as
Because of the square, large residuals contribute disproportionately (quadratically) large errors. The absolute error (absolute deviation) is defined as the absolute value of the residual \( \mid {r}_i\mid =\mid \hat{y_i}-{y}_i\mid \) and all residuals have a proportionate contribution. In some cases, it is useful to make the error proportional to the amplitude of the prediction, so that the same deviation contributes less error if the predicted value is higher. The Pearson residual is defined as
Based on these residuals, we can define the following commonly used metrics (Table 6).
Variations of these measures are also in use. For example, sum squared error (SSE) is N × MSE, and root mean squared error (RMSE) is \( \sqrt{MSE} \).
Concordance-Analogue Metrics
The next set of metrics measure how well the predictions co-vary with the actual values.
The most fundamental such metric is R2 and it measures linear correlation between the predicted and actual values
An R2 of 0 indicates random prediction while an R2 of 1 indicates that the prediction is perfectly (positively) correlated with the actual value.
Ideally, R2 is computed on a validation set. When no validation set is available, R2 can be adjusted for model complexity, penalizing large numbers of predictors relative to the number of observations. The adjusted R2 is defined as
where N denotes the number of observations and K the number of predictors.
The main drawback of R2 is that it measures a linear relationship. When linearity is undesirable, Spearman correlation can be used instead.
Example 9.1.2
[Influence of outliers in Gaussian data.]
In the absence of outliers and extreme values (that are highly unlikely under the model), the relationship between the predicted values and the actual values can be assumed linear when the data generating process is approximately Gaussian. However, outliers introduce outsized residuals and possibly quadratically disproportionate errors (if we are using squared errors), breaking the linear relationship between predicted and actual values. In this example, we study how the outliers influence various metrics.
Using an arbitrary known linear function f(x) we generated predictor x and outcome y pairs with standard normal noise added: y~f(x) + ε, ε~Normal(0, σ). We used the true generating function as the “model”. We then mixed in 0, 1, 5 and 10% outliers. For the outliers, their “predicted” value is the prediction from the “model” f(x) and their actual value is the 99.9th quantile of the possible predicted values under the “model” given the predictors, that is the 99.9th percentile of Normal(f(x), σ). We evaluated the predictions using the above metrics and summarized the results in the Table 7 below.
The interpretation of the table is as follows. If we use the true “model” on a test set without outliers, it achieves an MSE (second row) of 0.933 (second column), but if we add 1% outliers to the test data sets, the apparent MSE of the model increases to 1.019 (column 3). This 9% difference is solely due to outliers and does not actually reflect a difference in the goodness of the model: the model is the same true data generating model but evaluated on a data set that contains outliers.
As expected, with increasing outliers, the apparent model performance decreases the most when we use MSE as the evaluation metric. Adding 1% outliers increases the MSE by 9%, adding 5% outliers by 44% and adding 10% outliers increases the MSE by 84%. In comparison, when we used MAE as the evaluation metric, the corresponding changes were 3%, 14.3% and 27.2%; and when we used MAD, the difference further decreased to 0%, 4.6% and 9.9%. MAE and MAD are indeed more robust in face of outliers.
The use of the Pearson residual is not ideal for Gaussian data. It utilizes squared error (it is sensitive to outliers) and is normalized by the prediction. If an outlier has an expected value close to 0, the Pearson residual can become very large, because a large squared residual is divided by a value close to 0.
The R2 statistic indicates better model performance in the presence of outliers than in their absence. This is merely a coincidence. The outliers are chosen to be incongruent with the data generation process, so we should not see an improvement in the model performance.
The Spearman correlation became worse in the presence of outliers, showing a decrease of 2, 6.7 and 11.1%.
Best Practice 9.1.6
All of these measures are appropriate for Gaussian data.
Best Practice 9.1.7
MSE is more sensitive to outliers than MAD.
Pitfall 9.1.4
Pearson residual is sensitive to small predictive values.
Example 9.1.3
[Non-gaussian Data]
Another assumption that many of the residuals and the R2 statistic makes is homoscedasticity: the variance of an observation is constant across the observations. This assumption does not hold for many exponential family distributions, including the Poisson distribution which we often use to model counts.
Given predictors x, and a generating function f, in this example, we generated Poisson outcomes y as y~Poisson(λ = f(x)). To this data, we fitted an ordinary least-square (OLS) regression model and a Poisson model. We also generated an independent test set and evaluated the two models on this test set using the above metrics.
Figure 5 shows a smoothed plot of the residuals of the test set against the log of the true value for three commonly used residuals: square, absolute and Pearson. We can see that both the squared and the absolute residuals increase as the true value y increases. This suggests that in the evaluation, observations with large true values have an outsized impact. Note, that this not large errors having an outside impact; this is large true values having an outsized impact. In contrast, the Pearson residual remains mostly flat, because the residual is normalized with respect to the predicted value. This suggests that no particular range of the true outcome has an outsized impact. As a side note, notice that the log (true value) starts at 0.5 and thus the predicted values are ~1.5. If the predicted values were close to 0, dividing by the predicted value could create unduly large Pearson residuals (as we saw in the previous example).

Comparison of three common types of residuals plotted against the log of the true value
In Gaussian regression, observations are assumed homoscedastic: all observations are assumed to have the same variance. In contrast, when we model counts, the variance of the observations is related to their predicted values: the variance of the Poisson distribution is the same as its mean. Therefore, higher predicted values have higher variance. The Pearson residual is the squared residual divided by the variance, thus it is the square of the residual measured in standard deviations.
Pitfall 9.1.5
When the outcome is not homoscedastic, some ranges of the outcome value (larger values) can dominate the evaluation.
Best Practice 9.1.8
When evaluating predictive model with continuous outcomes that are heteroscedastic, consider using a residual that normalizes the expected variance (such as the Pearson residual for counts) or at least for the predicted value.
Pitfall 9.1.6
R2 is designed to measure the linear correlation between the predicted and actual values. When this is not linear, R2 is inappropriate.
Best Practice 9.1.9
When the relationship between the predicted and actual values is not linear, consider using a rank-based measure such as Spearman or Kendall correlation.
Time-to-Event Outcomes
The evaluation of time-to-event models differs from the evaluation of models for categorical or continuous outcomes in two ways. First, the outcome is time-dependent: the state of the outcome changes over time. A subject without an event at the beginning of the follow-up period may develop an event over time. Second, the outcome is not observable for censored patients.
The prediction from the time-to-even model can also differ. Some predictions are time dependent (e.g. survival probability or cumulative hazard), while other predictions are not (e.g. (log) risk score from a Cox proportional hazards model). Time-dependent and independent predictions require different evaluation methods.
Several factors complicate the evaluation of time-to-event models: (1) the true outcome is time dependent, (2) the prediction itself can be time-dependent, and (3) subject may be lost to follow-up.
Time-independent predictions can be transformed into time-dependent predictions and vice versa.
For example, a time independent measure, specifically the risk score, can be converted into a time-dependent measure by multiplying it with a (time-dependent) baseline hazard. When a software package (e.g. a deep learning package) only provides risk scores, a Cox model can be fit with the risk score as the sole independent variable to obtain the baseline hazard function. With the baseline hazard function in hand, survival probabilities can be computed. Conversely, a time dependent measure can be converted into “time-independent” by taking its value at a single clinically relevant time point. Alternatively, the time-dependent measure can be integrated over time [1].
Survival Concordance. This is an extension of the concordance measure (C-statistic) to time-to-event outcomes.
The C-statistic is the probability that in a randomly selected pair of patients, where one had an event earlier than the other had the event or got censored, the one with the event has a shorter predicted time to event.
Several versions of the C-statistic for time-to-event models exist, chiefly differing in the way they address censoring.
The most commonly used C-statistic is Harrell’s C. The scikit documentation [11] and the vignette for the random survival forest R package [12] provide an exact algorithm for the respective implementations. Harrell’s C has been shown to depend on the censoring distribution of the training data and to be biased when the proportion of censored subjects is high (~50% or above). Uno’s C statistic [13] addresses this issue by using inverse probability of censoring weighting.
Measures based on prediction error: IAE, ISE, Brier Score, and IBS. When the prediction from the time-to-event model is a (time-dependent) survival probability, the prediction error at the time can be computed as
where \( \hat{S{(t)}_i} \) is the predicted survival probability of subject i at time t and S(t)i is the actual survival curve for subject i; or as
where δ(t)i is the disease status of subject i at time t. Using the prediction error as a residual in conjunction with a loss function (such as absolute error or squared error) and integrating it over time yields the Integrated Absolute Error (IAE), ∫|PE(t)i| dt, which uses the absolute prediction error, and similarly, the Integrated Squared Error (ISE), \( \int PE{(t)}_i^2\mathrm{d}t \), which uses the squared prediction error.
To address censoring, the individual time points can be weighted by the inverse propensity of censoring. The Brier Score, at a time point t, is essentially an inverse propensity of censoring weighted squared prediction error
where Ti is the time of event for subject i, G(t) is the propensity of censoring as estimated through a Kaplan-Meier estimator [12]. The BS can be integrated over time to obtain the Integrated Brier Score (IBS), which is no longer time-dependent.
Time-dependent ROC and iAUROC. ROCs are useful tools for evaluating classifiers. The time-dependent ROC analysis views time-to-event modeling as a sequence of binary classification tasks evaluated either at a single clinically meaningful time point or at multiple time points. For this analysis, at a time point t, the prediction from the time-to-event model needs to be converted into a classification outcome. Heagerty and Zheng [14] have proposed three main strategies: cumulative/dynamic (C/D), incident/dynamic (I/D), and incident/static (I/S) that chiefly differ in the definition of a case, a control and the risk set. In case of C/D, at a time t, a case is a subject with an event time < = t (but after time 0), a control is a subject with follow-up up to t and no event, and the risk set consists of all cases and controls. This is “cumulative” because patients with events accumulate and is “dynamic” because the risk set depends on t. The I/D strategy defines a case as a patient who suffered an event exactly at time t; and defines controls as subjects remaining event-free at time t. This strategy excludes patients who developed an event before t. Finally, the I/S strategy defines cases identically to I/D but the risk set is static; it consists of all patients present at a separate time point t*, the time point when the cohort is defined.
Based on the definitions of cases/controls, the specificity and sensitivity can be computed, the ROC curve can be drawn, and the AUC can be computed.
Similarly to C-statistic, the sensitivity in the AUC computation can be weighed by the inverse propensity of censoring to make the estimates more robust in face of censoring. The AUC values at different time points can be integrated over a pre-selected set of time points to obtain the integrated AUROC or (iAUROC).
Best Practice 9.1.10
The most common evaluation metric of a time-to-event model is Harell’s C statistic (survival concordance) [13].
Pitfall 9.1.7
When a model produces time-dependent predictions, these need to be summarized into a single value before the C statistic can be computed.
Best Practice 9.1.11
Time-dependent predictions can be summarized into a single value as (1) survival probability at the end of the study, (2) survival probability at the median survival time, (3) or survival probability at some clinically relevant time.
Best Practice 9.1.12
If an ROC is desired, time-to-event prediction can be converted into classification outcomes at a specific (clinically relevant) time point using the C/D strategy to plot the ROC.
Calibration
Discrimination tells us how well the model can rank patients on their risk of outcome. Calibration tells us complementary information [2, 3, 15, 16].
Calibration tells us how reliable the estimates are in different ranges of the predicted risk of outcome.
There are four types of calibrations: mean, weak, moderate and strong, satisfying increasingly stringent criteria.
Mean calibration, also known as calibration-in-the-large, simply ascertains that the mean of the predicted risk of outcome coincides with the mean observed outcome in the sample. Many algorithms, including regression models, guarantee mean calibration in the development sample, thus discrimination is more important. On the other hand, in an external sample, the model may not be mean-calibrated.
Weak calibration assures that the model does not provide overly small or large predictions (relative to the actual incidence or prevalence) or that the model is not too close to the mean event rate (or prevalence). The principal tool for weak calibration is the calibration model, which is a regression model, regressing the observed outcome on the predicted risk. For continuous outcomes, the calibration model takes the form
where \( \hat y \) is the prediction from the model, β0 is the calibration intercept and βy is the calibration slope. In a well-calibrated model, the slope is 1 and the intercept is 0.
When the outcome is binary, Cox’s method is used, where the calibration model takes the form of
Weak calibration suffers from several shortcomings.
Pitfall 9.1.8
Weak calibration can only detect miscalibrations that are affine, involving a shift or a scale.
Pitfall 9.1.9
A model, that is well calibrated by the weak calibration criterion, does not guarantee to be well calibrated in all regions of the predicted outcome.
Hosmer-Lemeshow test. Both of these limitations stem from the fact that the calibration model is a (generalized) linear model. The Hosmer-Lemeshow test has been proposed to overcome these limitations. It performs a chi-square test comparing the sum predicted probability of outcome with the sum of the events in the 10 deciles of the predicted probability range. The test has 8 degrees of freedom internally and 9 externally. The chi-square test does not rely on the linearity assumption, however, it is not powerful and requires a certain minimum sample size.
Moderate calibration checks whether the model is unbiased over the entire range of the predicted probabilities. Typically, a flexible calibration curve, such as local polynomial regression (loess), is used to model the observed outcome as a function of the predicted risk. Figure 6 shows the calibration curve of a model on a hypothetical data set.

Calibration curve of a model
In the figure, the horizontal axis corresponds to the predicted probabilities of the outcome and the vertical axis to the observed probabilities. The diagonal dashed line represents a perfectly calibrated model, one where the predicted and observed probabilities always coincide. The model slightly underestimates the risk when the predicted probability is between 10 and 20% and slightly overestimates the risk when the predicted probability is between 20 and 40%.
It may be desirable to summarize the calibration curve into a single number. Let \( \hat{y} \) denote the probability of outcome predicted by the model, yc denote the smoothed observed probability of outcome (when the predicted probability is y) and f() the density of \( \hat{y} \). The Integrated Calibration Index (ICI) is defined as
the absolute difference between the predicted and (smoothed) observed probability is integrated over the range of predicted probabilities weighed by the density of the predicted probability.
Another summary statistic of the calibration curve is Harrell’s E. Harrell’s E(q) is the qth quantile of the \( \mid y-\hat {y}_c\mid \) distribution. For example, E50 is the median difference between the predicted and (smoothed) observed probabilities of outcome.
Pitfall 9.1.10
Flexible calibration curves depend on the smoothing applied to the curve.
Strong calibration ensures that the model predictions are unbiased for every possible input combination. This is often impossible to achieve in practice.
Example 9.1.4 [Weak calibration]
We created a synthetic data set with 10 predictors, 1000 observations and outcome prevalence of 20%. We first checked calibration-in-the-large. The mean predicted probability in the entire training sample was 0.199, while the mean outcome was 0.2 (p-value 0.99).
Next we checked weak calibration. The model
yielded βo = 0.063 (p-value 0.61) and βy = 0.063 (p-value 0.440). With both the calibration intercept and slope being non-significant, the model is considered well-calibrated in the weak calibration sense.
Example 9.1.5 [Poorly calibrated models]
To illustrate the effect of the calibration intercept and slope, we took the above well-calibrated model and intentionally mis-calibrated it by adding +1 and − 1 to the intercept and using 1.5 and 0.5 as the slope. Figure 7 shows the resultant calibration curves. These are flexible (loess) curves.

Shows flexible calibration curves. The gray dashed line represents perfect calibration and the black curve is a well-calibrated model from Example 9.1.5. The blue curves are miscalibrated, the calibration intercepts are + 1 (dashed line) and − 1 (solid line). The orange curves are also miscalibrated, their calibration slopes are 0.5 (solid line) and 1.5 (dashed line)
Blue lines in Fig. 7 show curves with non-zero calibration intercept. This makes the model consistently over- or underestimate the risk over the entire range of predicted probabilities. Orange curves represent miscalibrations where the calibration slope is not 1. When it is larger than 1, the model produces more extreme estimates: it underestimates the risk in the low probability range and overestimates the risk for higher predicted risks. Conversely, when the calibration slope is less than 1, the model produces estimates that are closer to the prior probability of the outcome.
Example 9.1.6 [Sensitivity of moderate calibration to smoothing]
We created a synthetic data set with 10 predictors and 1000 observations and fit a model to this data. We checked moderate calibration on the training data. For the calibration curve, we used local weighted least squares smoothing (loess) with four different smoothing parameters. Figure 8 shows the resulting calibration curves.

The calibration curve for a single model using different smoothing parameters. Darker blue indicates more smoothing; the default value is 0.7. The black dashed line represents perfect calibration
In Table 8, we show the ICI, E50 and E90 for the model. These are the calibration indices of the same model; they only differ because of using a different smoothing parameter for the flexible calibration curve.
Table 8 shows the effect of varying the smoothing parameter on the Integrated Calibration Index (ICI), Harrell’s E50 and E90. These calibration indices were calculated for the same model; they only reflect changes in the smoothing parameter. The empirical confidence interval of ICI (at smoothing of 0.7) was computed using the data generating distribution of the outcome risk and was 0.011 to 0.041. Thus all ICI values, regardless of the smoothing parameter, fall into the confidence interval.
Clinical Usefulness
The measures discussed in section “Evaluating Model Performance” describe how well a model can predict but give us very little information about how useful a model would be in practice.
There are two critical concerns regarding the clinical utility of a model. First, the different types of misclassification errors a model makes can have different consequences and a balance has to be struck between the benefits and the adverse consequences of using the model. Second, when the model relates to treatment (or intervention), the effectiveness of this intervention needs to be evaluated.
Weighted Specificity/Sensitivity, Weighted Precision/Recall
One consideration is that the two kinds of errors a model may make can have different consequences. In an example of a cancer screening test, false positives, patients where the test erroneously predicted a healthy patient to have cancer can have less grave consequences than false negatives, where patients with cancer are erroneously reported as being cancer-free. We have discussed weighted confusion matrices earlier in this chapter as a means for taking the different consequences of false positives and false negatives into account.
Measures Related to Effectiveness
The expectation from an intervention is that it reduces some adverse outcome or increases some beneficial outcome. Measures of effectiveness compare rates of events among treated and untreated (control) patients.
The top portion of the Table 9 shows the number of patients with an event (‘Event’) and without an event (‘No-Event’) among the treated (column ‘Treated’) and untreated (column ‘Control’).
Absolute risk is the proportion of patients in the treated (ART) or control (ARC) groups with an event. This is a dimensionless measure ranging from 0 to 1. The difference between ART and ARC is the Absolute Risk Reduction (ARR), which directly relates to the effectiveness of treatment in absolute terms: an ARR of 0.09 reduces the risk of event by 0.09 in the treatment group relative to the control group. However, ARR offers no information about which part of the risk scale either the treatment or the control group lies. For example, the same reduction of 0.09 can be more meaningful when ART = 0.01 and ARC = 0.10, corresponding to ten fold reduction in risk, as compared to the case when ART = 0.40 and ARC = 0.49.
Number needed to treat (NNT) is the reciprocal of ARR. The desired interpretation of NNT is the number of patients needed to receive the treatment to prevent one event that would have happened otherwise. This interpretation is attractive in clinical practice because it is absolute and in a unit that is easy to interpret (number of patients). The interpretation of NNT, however, depends on clinical context, namely, the disease prevalence and consequences of leaving the disease untreated. Therefore direct comparison of NNT is only appropriate across treatments of the same disease with respect to the same outcome.
NNT and ARR are equivalent, but NNT suffers from a number of drawbacks that ARR does not. NNT is dimensioned (number of patients) while ARR is not; the range of NNT is unbounded, while ARR is in the range of −1 to 1. When the treatment is ineffective, ARR = 0. Testing the significance of ARR is straightforward by checking whether its confidence interval contains 0. Conversely, when the treatment is ineffective, NNT has a singularity. Therefore, statistically testing whether a treatment is effective is problematic with NNT. Moreover, the range of NNT has a “hole”: NNT cannot take values between −1 and 1. Computing the confidence interval of NNT is possible by inverting the upper and lower bounds of the confidence interval of ARR, but this does not yield a correct confidence interval.
Relative risk (RR) operates on the proportional scale as opposed to ARR’s absolute scale. RR thus eliminates the problem of having a particular absolute difference reflect very different effectiveness when clinical risk ranges are very different, but introduces a similar problem: the same RR in patients with low risk could correspond to a clinically meaningless risk reduction, while the same RR in higher risk patients can be very meaningful. It is therefore recommended to report both RR and ARR.
Since the measures form two large groups, OR and measures around ARR (including RR, RRR, and NNT), in Fig. 9, we compare the behavior of OR and ARR. We simulated two datasets. Both have 1000 patients in the treatment as well as the control groups. In one data set, we fixed the number of control patients with an event at 100 (corresponding to 10% ARC) and in the other we fixed it at 300 (30% ARC). We varied the number of patients with event in the treatment group from 50 to 350 (corresponding to ART of 5–35%). More effective treatments have lower ART. The left panel depicts the odds ratio (OR) and the right panel depicts absolute risk reduction (ARR). Note, that RRR is ARR/ARC, thus with fixed ARC, RRR is just a scaled version of ARR. Similarly, NNT is the reciprocal of ARR.

Odds Ratio compared to Absolute Risk Reduction. Number of treated and control patients is fixed at 1000. ART is varied from 5% to 35% and ARC is fixed at 30% (solid line) and at 10% (dashed line). The dotted line represents ineffective treatment
OR and ARR are consistent: when OR indicates better performance for the treatment (lower OR), ARR also indicates better performance (higher ARR). The event rate in the control group creates only a shift in ARR, while it shifts as well as scales OR. The same difference between two treatment effectiveness results can appear as a numerically larger difference in OR. This has shown to have influenced treatment decision,
Measures of effectiveness fall into two groups: odds ratio (OR) and measures related to absolute risk reduction (ARR) (including RRR, RR, NNT). Both are invariant to scaling the number of treated or control patients, but OR is also invariant to scaling the number of controls (relative to the patients with events).
Pitfall 9.2.1
In case/control studies, measures of effectiveness that depend on the prior of classes, are misleading when the balance of cases to controls in the samples differs from the balance in the target population.
Best Practice 9.2.1
For case/control designs, use OR.
Relative risk (RR) and relative risk reduction (RRR) are relative measures while absolute risk reduction (ARR) and number needed to treat (NNT) are absolute.
Best Practice 9.2.2
Absolute and relative risk measures provide complementary information, so whenever possible, both should be reported.
Best Practice 9.2.3
ARR and NNT convey the same information and differ in interpretation. ARR is dimensionless, while NNT is measuresd in number of patients and is preferred in clinical practice.
Pitfall 9.2.2
The range of NTT has a “hole”. This makes significance testing and constructing confidence intervals difficult.
Net Benefit
Net benefit is a measure of the clinical utility of a model, which takes into account not only the predictive ability of the model but also the potential harm the application of a model can cause in practice.
Let us consider the scenario of a screening test, where patients with positive screening result undergo a more invasive but more reliable diagnostic test, while patients with negative screening result are not considered further. The use of the screening test can cause (at least) two kinds of harm. First, false negatives, patients who have the disease but received a negative screening result, are left undiagnosed and consequently untreated, thus they have higher risk of harm from the disease. Second, false positives are patients who received a positive screening result, underwent the invasive diagnostic procedure, incurring the risk of adverse events associated with the diagnostic test, and were found disease free. Harm from diagnostic procedure can include avoidable stress, infection, or sepsis. Relative to applying the diagnostic test to every patient, using a screening test can reduce the number of patients who undergo the diagnostic test and thus reduces the harm associated with the diagnostic test, but increases the risk of leaving the disease undiagnosed (in false negative patients) and thus increases the risk of harm associated with the undiagnosed disease. The net benefit is defined as
where N is the total number of patients, TP and FP denote the (number of) true and false positives, respectively, and w is a weighing factor representing the tradeoff between the harm caused by false positives and false negatives. The weighing factor is determined by expert opinion, by physician-patient joint decision making, or by cost analysis.
Interpretation. The interpretation of net benefit is the increase in TP as a proportion of the population (or sample) after accounting for the risk of harm both from false positives and false negatives.
Example 9.2.1 [Net benefit]
Consider a population of 1000 patients and a disease with 20% prevalence. There are 200 patients with the disease and 800 without. Further, consider a screening test that reported a positive result for 500 patients and 160 of them were true positives (and 340 were false positives). There are 40 false negatives. A second test would report a positive result for 400 patients, 150 of them true positives and 250 false positives, yielding 50 false negatives.
The second test has 10 more false negatives than the first test but it has 90 fewer false positives. Suppose false negatives are very dangerous and false positives are trivial, say false negatives are 20 times more costly than false positives, then the net benefit of the first test is TP/N−w FP/N = 160/1000–1/20 * 340/1000 = 0.143. This is higher than the net benefit of the second test, which is 150/1000–1/20 * 250/1000 = 0.1375. Conversely, suppose that the screening test is repeated annually and the disease takes years to progress. In that case, the risk of false negatives can still be higher than the risk of false positives, but to lesser extent than in the previous example, say false negatives are “only” five times as costly as false positives. In that case, the net benefit of the first test is 160/1000−1/5*340/100 = 0.092, which is lower than the net benefit of the second test, which is 150/1000–1/5*250/100 = 0.10.
Decision Curve
Consider a screening test which yields a probability of outcome. To obtain a positive/negative classification, the probability is dichotomized using a threshold p: patients with predicted probability of disease above p are positive and undergo the diagnostic procedure, while patients with predicted probability of disease with less than (or equal to) p are declared free of disease and are not considered further. As we have already seen in this chapter, the choice of threshold p influences the predicted positives, TP and FP, thus it influences net benefit. In other words, a net benefit value can be computed for each possible (and reasonable) threshold p and FP-FN tradeoff w.
The threshold p and w are related. Consider a threshold, slightly higher than p. Without loss of generality, assume that reducing this threshold to p increases the number of predicted positives by one patient. If the model is well calibrated, then this patient has probability p of being a case (actual positive) and 1-p of being a control (actual negative). If the patient is an actual positive, then the number of true positives increased by one (with probability p). If the patient is an actual negative, then the number of false positives increased by one (with probability (1-p)). At equilibrium,
yielding the relationships between p and w
When the output from a predictive model needs to be thresholded into a clinical decision, (a) net benefit depends on this threshold and (b) the threshold can be computed based on the assumed ratio of harm caused by the two kinds of misclassifications, false negatives and false positives.
Example 9.2.2
Returning to the net benefit example, if the first test results in probabilities, and we believe that the consequence of false negatives is 20 times worse than that of false positives, then w = 1/20, and we should set the classification threshold to p = w/(1 + w) = 1/21.
Decision curves plot the net benefit as a function of p along with two default policies, Treat All and Treat None.
Figure 10 shows a decision curve for a hypothetical screening model.

Decision Curve for a hypothetical screening model. Horizontal axis denotes the classification threshold p, the vertical axis shows Net Benefit. The blue (solid) line represents the decision curve for the model, the orange (dashed) line represents the decision curve for the “Treat All” policy and the horizontal line (at 0) represents the decision curve for the “Treat None” policy
The horizontal axis corresponds to the classification threshold p, and the vertical axis is the net benefit. The three lines represents three policies. The blue solid line represents the policy of interest, which is based on a machine learnt model. The model estimates the probability of outcome in each patient. Patients with probability above the threshold receive the invasive diagnostic test (“treatment”), those below do not. The other two models are two default policies. The horizontal black line is the “Treat none” policy, where no patient is given the diagnostic test, while orange dashed line represents the “Treat all” policy where every patient is given the invasive diagnostic test (“treatment”).
Since net benefit measures the true positives treated under a policy as a proportion of the entire sample minus the risk of harm, the “Treat None” policy yields no true positives treated nor does it cause harm from treatment, since nobody is treated. The orange line represents the “Treat All” policy. Since we treat everyone, one would not expect the net benefit to depend on the threshold, however, the threshold is determined by the ratio of harm caused by false positives versus false negatives, denoted by w in earlier sections. Net benefit does depend on w. When the threshold is 0, p = 0, we assume that the treatment causes no harm w = p/(1-p) = 0, and thus the net benefit is the prevalence of disease in the sample. When the threshold is the prevalence of disease, 0.2 in this example, w = 0.2/0.8 = ¼, meaning that false negatives cause four times as much harm as false positives. In this case, the net benefit for the Treat All policy is TP/N - w FP/N = p - p/(1-p) (1-p) = 0. As the threshold exceeds the prevalence, in other words the ratio of harm from false negatives versus false positives exceeds p/(1-p), the Treat All policy has a negative net benefit.
The blue line has a similar interpretation. If we believe that the harm caused by false negatives is w times higher than the harm caused by false positives, we select p = w/(1 + w) as the threshold and the net benefit can be seen in the graph. For example, when the harm caused by false negatives versus false positives is 1:4, w = ¼, p = w/(1 + w) = 0.2 and the net benefit is 0.80. This is substantially higher than the other two policies, both of which have net benefit of 0.
The figure shows that the model-based policy (blue line) has superior net benefit over the two default policies over the entire range of FN:FP harm ratio, and consequently, the entire range of classification thresholds.
Relationship Between Net Benefit and AUC
Figure 11 depicts the relationship between AUC and decision curves. The three panels correspond to three different disease prevalence: 10%, 20% and 40% from left to right. Each panel is a decision curve plot, analogous to Example 9.2.2, comparing three model-based policies, based on models with AUC of 0.6, 0.7, and 0.8, and two default policies: “Treat All” and “Treat None”. The horizontal axis is the classification threshold p and the vertical axis is Net Benefit. Since the maximal net benefit (achievable when treating the false positives cannot cause harm) varies by the prevalence of disease, the vertical axis in the three panels use different scales, namely 0 to disease prevalence.

Relationship between AUC and net benefit. In each panel, the decision curves for three model-based policies, based on models with AUCs of 0.6, 0.7, and 0.8, and the two default policies are plotted. The three panels represent three diseases with prevalence of 10%, 20% and 40%. Note that the scale of the vertical axis is different across the three panels
Generally, higher AUC results in higher Net Benefit regardless of disease prevalence.
However, even models with reasonable AUC can underperform a default policy of “Treat All”. For all three prevalence, the model-based policy based on AUC of 0.6 performed worse than the “Treat All” policy. When the prevalence is low (left panel), the extent to which it underperformed (relative to the maximal achievable Net Benefit) is greater than when the prevalence is high (right panel). Similar to the “Treat All” policy, the model-based policy, even when based on a reasonable model (AUC > 0.5), can have negative net benefit. This happens when the cost of false positives is high and the predicted positives do not have sufficient true positives to compensate for the risk of harm from false positives.
Pitfall 9.2.3
Even models with reasonable AUC can underperform a default policy of “Treat All”.
To further explore the relationship between Net Benefit and AUC, Net Benefit can be expressed in terms of sensitivity and specificity.
This shows that similarly to AUC, NB is also balancing between sensitivity and 1-specificity, however it adjusts for the prevalence of the outcome and also for the ratio of harm caused by the two kinds of misclassifications (false positives and false negatives).
Key references for clinical effectives are (chapter “Regulatory Aspects and Ethical Legal Societal Implications (ELSI)” in [2], [17,18,19,20].
Health Economic Evaluation
In this section, we provide an overview of evaluating the health economic effect of a new model or intervention [21,22,23]. Health economic evaluations focus on evaluating health-related actions, such as new models, interventions, therapies, practices, or policies, in terms of their cost and consequences. Without loss of generality, we call these actions “interventions”. Consequences include health benefits or disbenefits from the new interventions, their side effects, and effects this new intervention may have on other parts of the health system.
Health economic evaluations aim to evaluate the health benefits and disbenefits of an intervention taking their cost into account.
Several kinds of health economic evaluations exist. Cost effectiveness analysis (CEA) compares interventions that relate to a single common effect that may differ in magnitude between alternative interventions. For example, two treatments of the same disease may both extend life (common effect) but to varying degrees at varying costs. Analyzing the degree of extending life as a function of costs incurred constitutes a CEA.
Although technically not a CEA, Cost Minimization Analysis (CMA) is related. CMAs are applicable when two treatments achieve the same outcome (to the same degree) but at different costs. In this case, the treatment with the lower cost would be chosen.
The second type of health economic analysis is Cost Utility Analysis (CUA). Similarly to CEAs, CUAs also compare two interventions in terms of costs and health consequences, but unlike CEAs, the health consequences of the interventions do not need to be common. Instead of a specific clinical endpoint, CUAs utilize generic measures of health gain, making the consequences comparable. This allows for the comparison of programs across different areas of health care, where a common clinical endpoint would not make sense. When a new program is implemented, often another area needs to be disinvested. CUAs also allows for accounting for health lost in the disinvested area in comparison to health gained in the new program on the same scale. Such generic measures of health include Quality-Adjusted Life Years (QALY), Disability-Adjusted Life Years (DALY), and Healthy years equivalent (HYE), which we introduce in the next section.
The final type of health economic analysis we look at is Cost Benefit Analysis (CBA). CBAs compare interventions, more generally, policies, in terms of their costs and consequences, where the consequence is also expressed in monetary terms. This can be useful for policy decisions, where one of the interventions is not health-related and thus a health-related consequence is inappropriate. Such analyses require quantifying the monetary value of health, which is a complex topic in its own right. In this section, we do not consider CBAs any further and focus on CUAs, which are the most common types of health economic evaluations, and CEAs, which are common when two treatments of the same disease are compared (Table 10).
Components of a CEA and CUA
Health economic analyses have three main components: (1) alternative interventions compared, (2) estimation of costs, and (3) estimation of benefit (consequence).
Alternative Interventions
To determine whether a new intervention is to be adopted, it needs to be compared with alternative interventions. One of the alternatives can be the current standard of care. Different alternatives can be mutually exclusive, in which case they can be compared directly. The new intervention can be used together with alternatives (adjuvant therapy), in which case comparisons can be made among combinations of treatments or sequences of treatments.
Care must be taken to include all relevant alternatives. The proposed new intervention may outperform some but not all alternatives. Many cost effectiveness measures posit that the new intervention can only be adopted if it outperforms all alternatives.
Best Practice 9.3.1
Include all alternative interventions in a health economic evaluation.
Estimating Costs
Estimating costs naturally includes the direct cost of the intervention. In an environment, where resources are limited, there is also an opportunity cost associated with the intervention. When resources are allocated for a particular intervention/program, other interventions/programs may have to be disinvested. These disinvested programs give up benefits, which is an opportunity cost, and it also needs to be included in the cost calculation.
Best Practice 9.3.2
Include the opportunity cost as cost of intervention/program in a health economic evaluation.
Measures of Benefit
CEAs and CUAs both measure the benefit of a new intervention in terms of health gained. CEAs use more direct clinical outcomes, while CUAs use generic measures of health. In this section, we review metrics of health.
Direct clinical outcomes are very similar to clinical trial endpoints and are usually natural measures of the outcome of interest.
For example, for lipid lowering drug, the clinical endpoint could be reduction of major cardio-vascular events and a natural measure of that could be 8-year incidence of major cardio-vascular events.
A common direct clinical outcome is mortality. Several natural measurements exist for mortality including the extension of life in years (a time to event outcome) or an incidence (e.g. 8-year mortality risk).
When the clinical outcome of interest takes place in a long time frame that makes analysis impractical, an intermediate end-point and its natural measure can be used. Continuing with the lipid-lowering example, an intermediate endpoint can be cholesterol reduction achieved and its natural measure is the corresponding lab result. Another kind of intermediate measures include cases detected in a screening test, or process measures of diabetic control (such as percentage of patients with a1c measured, feet examined, etc). Intermediate measures have to be linkable to the clinical outcome of interest and the quality of these measures depends on how strongly the intermediate outcome is linked to the actual clinical outcome of interest.
Best Practice 9.3.3
Do not use intermediate end-points unless they are very strongly linked to the outcome of interest.
Health is multidimensional and the above clinical outcome measures typically capture one aspect of it: either the length of life or an aspect that relates to the disease of interest. Generic health scores have been proposed to measure multiple aspects of health simultaneously.
Health related quality of life (HRQoL) scores are generic health scores that measure a patient’s health from multiple perspectives and do not concentrate on specific diseases.
A commonly used measure HRQoL is the Short Form 13 (SF-13) consisting of 13 multiple choice questions and the SF-36 consisting of 36 questions [24]. Both cover major health domains including whether health problems limit patients’ daily activity, mental health problems limiting daily activity, level of pain, vitality, and how patients perceive their health. One problem with such multidimensional measures is that the different dimensions, or the answers to the 36 questions, often need to be summarized into a single value for analysis.
Another problem with the current measures is that quality of life and length of life can represent a tradeoff. For example, a cancer patient may select a treatment that offers better quality but shorter life over another treatment with longer but lower-quality life. Ideally, a health measure can capture both of these aspects of health into a single value. The solution is to adjust the life years for quality of life giving rise to the following measures.
Quality Adjusted Life Years (QALY) is a measure that weighs each remaining life year proportionally to the quality of life. The weight is determined by patient preference. QALY is a continuous valued measure, where, by convention, 0 often represents death and 1 perfect health. This is an interval measure, where 0 is arbitrary and health states worse than death can take negative values.
Disability Adjusted Life Years (DALY) weighs each remaining life year proportional to (the lack of) disabilities. Weights are determined by a committee and are fixed. DALY is a discrete measure that can only take seven different values.
Healthy Years Equivalent (HYE) creates a mapping, based on patient preferences, from years remaining to equivalent years of completely healthy life. The mapping can be determined, for example, by using a series of questions asking the patients whether they prefer y years (y > 1) in their current health or 1 year completely healthy life. When the patients are indifferent, that is the equivalence point.
Generic measure of health that summarize a patient’s health into a unidimensional measure include QALY, DALY, and HYE.
Decision Making Using CEA and CUA
Once alternative treatments are identified, associated costs are estimated and a measure of benefit is selected, we now continue to describe how these can be used for decision making.
Consider two treatment alternatives, A and B; B is the new treatment and A is an alternative treatment such as the current standard of care.
Incremental cost ΔC is the difference in cost between A and B. It includes the additional acquisition cost of B (vs A) and any and all additional opportunity costs. The incremental cost is not necessarily positive: the new treatment can save cost or even an expensive new pharmaceutical may lower opportunity costs. Incremental health benefit Δh is the difference in health outcomes between A and B. If health benefit is measured in QALYs, this represents the extra QALYs achieved by using B over A.
Incremental cost effectiveness ratio (ICER) is the ratio Δc/Δh, which quantifies the cost increase (Δc) incurred to achieve a unit health gain (e.g. 1 QALY).
A treatment is deemed cost effective if ICER < k, where k is the cost-effectiveness threshold. The cost effectiveness threshold means that diverting k units of health care resources from other parts of the healthcare system to the new intervention is expected to displace 1 QALY of health elsewhere in the health system.
Example 9.3.1 [Cost effectiveness]
Suppose treatment B has an incremental cost of $20,000 and an incremental benefit of 2 QALYs. When the cost effectiveness threshold k is $20,000/QALY, we expect to lose 1 QALY in the health system per every $20,000. Therefore, using treatment B at the incremental cost of $20,000, we expected to lose 1 QALY elsewhere in the health system. Now, B also provides us health benefits. The incremental health benefit Δh from treatment B is 2 QALY; while the health disbenefit lost in the system is Δc/k = $20,000/$20,000 QALY = 1 QALY. Thus, the incremental net health benefit is 1 QALY, which is positive, thus the treatment B is considered cost effective.
There are three equivalent criteria for cost effectiveness:
-
ICER < cost-effectiveness threshold: \( \frac{\varDelta_c}{\varDelta_h}<k \)
-
Incremental net health benefit is positive: \( {\varDelta}_h-\frac{\varDelta_c}{k}>0 \)
-
Incremental net monetary benefit is positive: Δhk − Δc > 0.
The first criterion is the definition of cost effectiveness: cost effectiveness, that is cost per unit health gained, needs to be less than a threshold k.
The second criterion examines cost effectiveness from the perspective of health gained. The incremental health benefit Δh from the new treatment is larger than the health we lose in other parts of the health system (Δc/k) due to diverting Δc cost to treatment B.
The third criterion looks at cost effectiveness from a cost perspective. It would cost Δhk dollars to achieve the same health benefit (Δh) that treatment B offers at the cost of Δc. If the cost through treatment B is lower, then treatment B is cost effective.
Cost Effectiveness Analysis Example
In this section, we present an illustration of how the health economic impact of a machine learned model can be evaluated. The example is adopted from [22] with the author’s permission.
Epithelial ovarian cancer has the highest mortality rate among cancers. 20–30% of the patients do not respond to the standard treatment of cytoreductive surgery and platinum-based chemotherapy, and even in patients with an initial response, 80% will recur and develop drug resistant disease. Against this background, novel, targeted therapy agents, such as Bevacizumab, have been developed. Earlier studies found Bevacizumab to dominate (be more effective at a lower cost) the standard treatment.
A ML model based on genetic biomarkers and clinical outcomes, was developed to provide progression-free survival (PFS) benefit estimates for patients on Bevacizumab therapy. Based on the predicted PFS probabilities, patients were categorized into three groups: (1) 40% of the patients without statistically significant PFS gain (1.28 ± 1.45 months), (2) 40% with medium gain (5.79 ± 2.12 months), and (3) 20% with the highest FPS gain (9.95 ± 1.53 months).
Three therapeutic strategies are compared. First, is the platinum-based chemotherapy, the current standard of care at the time of the writing. Second, Bevacizumab therapy added to the current standard for all patients (universal). Third, Bevacizumab therapy is added to the current standard for only the 20% patients who are predicted to benefit the most.
Strategy | Incremental cost | Incremental health benefit | ICER |
|---|---|---|---|
Baseline | – | – | – |
Universal application | $60 k for bevacizumab = $3B per year | 4.818 months = 2 quality adjusted months | $360 k |
ML-guided application | $2 k for test for all patients $60 k for bevacizumab × for 20% of patients = $700 M per year | 9.95 months = 4.13 quality adjusted months | $203 k |
Assumptions. The genetic test for the ML-based signature costs $2k per patient. The Bevacizumab therapy costs $60k, including acquisition, administrative and adverse events-related costs. The quality of life adjustment is assumed to be the same across the three strategies and is taken from [23]. Last, we assume 50k patients per year.
Universal application. Bevacizumab is given to all patients, thus no testing is required. It is given in addition to the baseline treatment, thus the incremental cost is $60k per patients, equaling $3B. On average, patients gain additional 4.818 months (=2 quality adjusted months) of life relative to the standard care, yielding an incremental health benefit of 50 k × 2 = 100k quality adjusted life months = 8.3k QALY. The incremental cost effectiveness ratio (ICER) is $3B/ (8.3k QALY) = $360k per QALY.
ML-guided application. Bevacizumab is given only to the 20% patients in the highest benefit group. The genetic test needs to be applied to all patients and then 20% of the patients (10k patients) receive the Bevacizumab therapy on top of the standard care. This leads to an incremental cost of 50k × $2k for testing and 10k × $60k for the Bevacizumab therapy, $700M in total. The patients who received this therapy experience a health benefit of 9.95 months = 4.13 quality-adjusted months on average yielding an incremental health benefit of 10k × 4.13 × 12 = 3.44k QALY. The ICER is $700M/ (3.44 QALY) = $203k per QALY.
Although the Universal application yields a higher incremental health benefit (8.3k vs 4.13k QALY) it does so at a disproportionately higher cost ($3B vs $700M), leading to a higher ICER.
The impact of model performance. The increased effectiveness of the ML-guided application stems from the ML model’s ability to correctly identify patients who benefit from the Bevacizumab treatment. A ML model with lower performance could select patients with lower benefit, yielding a lower incremental health benefit at the same incremental cost (same number of patients treated), reducing the ICER, possibly rendering the treatment ineffective. If a priori known, the institution’s willing-to-pay threshold (highest ICER they are willing to pay for) can be used to determine the minimal necessary model performance.
Calibration. The main responsibility of the model is to distinguish between the 20% and the bottom 80% benefit groups. The implication is that among models with similar discrimination, we prefer models that are better calibrated at the higher end over those better calibrated at the lower end of the estimated probability progression-free survival scale.
Estimators of Model Performance
Recall from chapter “Data Design” that modeling is inference, where a model is constructed on a discovery sample, and we wish to use it in the target population. To determine whether the model is suitable for use in the target population, we have to estimate its performance in the target population using the discovery sample. In this chapter, we present several methods to achieve this.
The term estimator refers to the method we apply to estimate the performance of a model. We compare estimators by assessing how well and how consistently they can estimate the model performance. Bias is the difference between the model performance estimated from the discovery sample and the model performance in the (entire) target population. Variance is the variability of the performance estimate across multiple discovery samples. Specifically, if we were to repeat the analytic process using different discovery samples, build a model on each sample, and apply the estimator to compute the performance of the model, we would obtain multiple estimates of the model’s performance. Variance of the estimator is the variance of these performance estimates.
The goal of performance estimation is to infer the performance of a model in the target population based the discovery sample. The method used to estimate the model performance is referred to as an estimator.
Using the Plug-In Estimator is Generally a Bad Idea
The simplest method is to build a model on the entire discovery sample, measure the model’s performance on the same discovery sample and use this estimate as a “plug-in” estimate for the target population. This estimate is also known as the resubstitution estimate, or resubstitution error for error estimates.
From a very large population, a sample of 10, 20, …, 2000 patients were drawn as a discovery sample. On this discovery sample a model (with 10 parameters) was constructed and was evaluated on the same discovery sample. Then the performance of this model was evaluated in the original population and compared to the estimated performance. Figure 12 shows the estimated performance (blue line) and the actual performance (orange line) as a function of the size of the discovery sample.

Performance of a model estimated from discovery samples of various sizes compared to its actual performance on the target population.
For all sample sizes, the performance estimate is optimistic; for small sample sizes, it is excessively optimistic. For small sample sizes, the performance estimate has no variability, it is always 1. When the sample size becomes large, the performance is estimated reasonably correctly. Unfortunately, the sample size that is “sufficiently large” is not known a priori, it depends on the number of parameters in the model and also on the data itself: when predictors have high collinearity, a much larger sample size is required, as compared to independent predictors.
Pitfall 9.4.1
Do not use the plug-in estimator. Its estimate is always optimistic, sometimes excessively so.
The use of the plug-in estimator for estimating the performance of models is not recommended at any sample size. When the sample size is small, the plug-in estimate has the apparent advantage of using all samples to build the model, but the performance estimates can be arbitrarily biased. When the sample size is large, the plug-in estimate has the apparent advantage of building only one model (which can be costly at large sample sizes), but other estimators, e.g. the Leave-out estimate, also builds only one model but gives a less biased performance estimate.
Internal Validation
We will discuss problems with model fitting in chapter “Overfitting, Underfitting and General Model Overconfidence and Under-Performance: Pitfalls and Best Practices in Machine Learning and AI” in greater detail, but for the current discussion, we consider two problems: underfitting and overfitting. A model is underfitting the data if the model fails to capture all available signal from the training data. This generally happens, when the model has insufficient complexity. Conversely, a model is overfitting the data, if the model also fitted to the noise in the data. This typically happens when the model complexity is too high.
Overfitting can be detected if a second sample from the same population is available. The first sample, which was used to develop the model is called the training sample (or development sample), while the second sample is referred to as the validation sample (or test sample). When a model is overfitting, its performance on the training sample will be higher than on the test sample. The purpose of validation is to ensure that the model performance estimated from the training sample remains similar in the population. If this is true, the model is said to generalize to that population. If this population is the accessible population, the validation is an internal validation; otherwise, it is external validation. In this section, we focus on model performance estimators utilizing internal validation and in the next section, we dive into the different kinds of validations a little deeper.
In internal validation, the goal is to verify that the model developed on the discovery sample generalizes to the accessible population.
Leave Out Validation
In leave-out-validation, a randomly selected portion of the discovery sample, a validation sample, is put aside, left out from training. The discovery sample is thus randomly divided into a training sample and a validation sample, implying that the training sample and the validation sample are two independent random samples from the accessible population. As long as the accessible population can be viewed as a random sample of the target population, the training and test samples are two independent samples of the target population. Thus the performance of a model on the validation sample will be representative of its performance on the target population.
In leave out validation, the discovery sample is divided into a training sample for model development and a validation sample for model evaluation.
For successful validation we have to pay attention to two details: the definition of the sampling unit and the size of the validation sample relative to the discovery sample.
Sampling unit. The discovery sample is a random sample from the accessible population: whether a unit is selected from the accessible population to the discovery sample does not depend on the selection of other units. For example, in a diabetes risk model example, a sampling unit can be a patient. Assume that from the accessible population, the set of patients in the catchment area of the health system, a discovery sample of patients is drawn at random. The probability of being included in the discovery sample is constant across the patients in the accessible population. Each patient can contribute multiple records. Typically, all records of the selected patients are included. Thus, the discovery sample is not a random sample at the level of records (if one record of a specific patient is included, another record of the same patient has a very high probability of being included) but is a random sample at the level of patients. When the discovery sample is further sampled to create the training and validation sets, the same sampling unit must be used. If in the above example, records of one patient are split across the training and test sets, the training and test sets are no longer independent, even at the patient level: if some records of a patient are in the training set, the probability of another record of the same patient being in the test set is higher than the probability that a record of a random patient from the accessible population is included. For this example, sampling must be done at the patient level: if a patient is selected to be a training patient, all records of this patient must be included in the training sample; if the patient is a validation patient, then all records of the patient must be included in the validation sample.
Best Practice 9.4.1
Consider the sampling unit carefully.
Relative Size of the Training Versus Validation Samples
Best Practice 9.4.2
A typical leave-out validation size is 30% of the sample.
Pitfall 9.4.2
If 70% of the discovery sample is insufficient training data, you need to consider other performance estimators (such bootstrapping or cross-validation).
To illustrate the effect of the proportion of samples left out for validation, we simulated a large population of observations with outcomes. From this population, we draw discovery samples of varying sizes, ranging from 50 to 5000. A 10-parameter model was constructed for the outcome and its performance was estimated from the leave-out sample (validation sample). The left panel in Fig. 13 depicts the bias, which is the average absolute difference between the performance estimate from the validation sample versus the actual performance on the population. The right panel depicts the variability of the performance estimate. For each discovery sample size, the experiment was repeated 50 times and the standard deviation of the 50 performance estimates are reported.

Example showing the impact of the proportion of samples left out for validation. The bias (left panel) and variance (on the standard deviation scale) (right panel) of the performance estimates of models constructed on discovery sample sizes varying from 50 to 5000 (horizontal axis) and the portion of the discovery sample left out for validation ranging from 10% to 50% (darker blue indicates larger validation sample size)
As the fraction of samples left out for validation increases, the samples available for training decreases. Figure 13 shows that the larger the training sample size, the higher the actual performance. As the fraction of samples left out for validation decreases, the validation sample becomes too small to estimate the performance, and as Fig. 13 shows, this results in both high variance and large bias. The typical percentage of samples left out for validation is 30%. When the discovery sample is sufficient for building a good model from 70% of the samples, the remaining 30% is typically sufficient to estimate the model performance.
Property. Even for modest sample sizes, the leave-out estimator is relatively unbiased, however, it has very high variance.
Repeated Holdout
To reduce the variance of the holdout estimator, the estimation can be repeated multiple m times, each with a different partitioning. This process results in m performance (or error) estimates, which need to be averaged.
Property. The repeated holdout estimator retains the same low bias and achieves significantly lower variance than the (single, non-repeated) holdout estimator. However, repeating the holdout estimation results in higher computation cost.
Cross-Validation
There are two problems with leave-out validation. First, we use a small portion of the discovery sample for training as we have to leave out a portion of it for validation. This increases bias. Second, the portion left out for validation is relatively small so the variance of the performance estimate can be large. Cross validation addresses both of these problems.
In k-fold cross validation, the data set is divided into k equal partitions at random. Model evaluation proceeds iteratively, in k iterations. In the kth iteration, the kth partition (fold) is left out for validation and the remaining k-1 partitions are used for training. A model is constructed on the k-1 partitions and predictions are made on the leave out partition. Over the k iterations, we obtain predictions for all k partitions and the predictions are evaluated.
Best Practice 9.4.3
For cross validation a typical number of folds is 10 in moderate sample size and 5 in large sample sizes.
In ten-fold cross validation (CV), in each of the 10 iterations, 9 out of 10 partitions are used for training, thus the model is constructed on 90% of the discovery sample. By the end of the 10 iterations, predictions are obtained for all observations, thus the predictive performance is evaluated on all instances in the discovery sample. The downsides are twofold. First, in 10 iterations, we have built 10 models. If building a model is costly, cross-validation can become very expensive. This can be mitigated by choosing a smaller k. Second, the procedure does not evaluate the performance of a specific model, but rather the expected performance of a hypothetical model that we would obtain by building it on (k-1)/k portion of the discovery samples.
Choosing k
The choice of k mainly impacts the sample size available for training (model construction), which in turn, impacts performance in the population. Any k ≥ 5 was found to yield very similar performance: whether the model is constructed on 80% of the discovery sample (k = 5) or 98% (k = 50) only had an impact on the performance for small sample sizes. The larger the number of folds, the smaller the bias and the variance (standard deviation of the performance estimates across 50 runs for k and each discovery sample size combination), however the effect diminishes beyond k = 5 (Fig. 14).

The effect of the number of cross-validation folds. Model performance was estimated using k-fold cross validation (k = 2, 5, 10, 50). The bias (top left panel), standard deviation (top right panel) and model performance in the population (bottom panel) are depicted as a function of the analytic sample size ranging from 50 to 2000. The color of the curves represents k
Leave One Out Cross Validation (LOOCV)
Leave One Out Cross Validation (LOOCV) is a special case of cross validation, where every observation is a partition. In other words, k = N. LOOCV is most useful for small data sets, because in each iteration, only a single observation is left out for validation. The key drawback is the computation cost: by the completion of the LOOCV process, N models will have been constructed.
Property. Cross-validation has low bias, but high variance. It has significantly higher computation cost than the holdout estimation.
Repeated Cross-Validation
K-fold cross validation has low bias but relatively high variance. Some of this variance, the so-called internal variance [25], is due to the randomness induced by the partitioning. In order to reduce variance, repeated cross-validation can be performed, where the k-fold cross-validation process is repeated m times and the estimates are averaged over the m repetitions.
Bootstrap
As k-fold cross validation represents a tradeoff of increased compute cost to reduce estimation bias and variance, bootstrap is another step in the same direction. In bootstrap estimation, replicas of the discovery sample are constructed. If the discovery sample has N observation, a replica of N observations is created by sampling from the discovery sample with replacement. The replica will contain approximately two thirds of the observations from the original discovery sample, with some observations included multiple times. Conversely, about a third of the original samples are not included in the replica. These samples are called the out-of-bag (OOB) samples. A model is constructed on the replica, and evaluated on the OOB samples. This process is repeated typically 50 to several hundred times.
The advantage of the bootstrap is that the model is evaluated on the OOB samples over multiple runs, thus the evaluation uses most (if not all) discovery samples multiple times, yielding a stable estimate. The drawback of the method is that it is known to be (pessimistically) biased even on large samples and it is costly as it builds a model on each replica, requiring the construction of potentially hundreds of models. Similarly to cross-validation, the performance estimate is not the performance of a specific model, but rather the expected performance of a model that will be built on the discovery sample with the same parameterization as the models in the bootstrap.
Effect of the Number of Bootstrap Iterations
Figure 15 shows the effect of the bootstrap iterations on the bias (top left panel) and variance (top right panel) of the performance estimate. The bottom panel depicts the performance of the models in the target population. Since each bootstrap iteration uses a replica data set that has the same number of samples as the entire discovery sample, the performance of the models in the population does not depend on the number of bootstrap iterations. There is some variation in the amount of bias as a function of the number of bootstrap iterations, but the differences are not statistically significant. The main difference due to the number of bootstrap iterations is the variance of the performance estimate. The higher the number of bootstrap iterations, the smaller the variance. Consistent with recommendations in the literature, performing iterations in excess of 100 or 200 has no appreciable effect.

Effect of the number of bootstrap iterations on the bias (top left panel), variance (top right panel) of the performance estimates and the actual performance of the models in the target population (bottom panel)
Best Practice 9.4.4
When using the bootstrap estimator select a number of repetitions that is sufficient for the problem based on related literature. Reported minimum repetitions generally range from 100 to >500.
Property. The bootstrap has low variance but can have high bias even when the sample size is large.
Best Practice 9.4.5
When using the bootstrap, estimate the bias and correct for it unless it is negligible. If the bias is unknown or cannot be corrected, then a different estimator must be used.
The 0.632 and the 0.632+ bootstrap
The key benefit of the bootstrap method is its low variance. However, the bootstrap can be pessimistically biased even for large sample sizes.
The 0.632 bootstrap [26] addresses this issue by taking a weighted average of the resubstitution error \( \hat{\varepsilon}_{resub} \) (which is typically very optimistic) and the bootstrap error \( \hat{\varepsilon}_{b0} \)
This correction was observed to be insufficient, thus when the overfitting is assumed to be substantial, more weight is placed on the bootstrap estimate. This gave rise to the 0.632+ bootstrap [27], defined as
where the exact formulate for the weighing factor \( \hat w \) can be found in [28].
Comparing the Different Estimators
Several studies [4, 25, 28,29,30] have addressed the issue of comparatively evaluating these estimators. The emerging conclusions are that:
-
(a)
LOOCV is unbiased but has high variance and can produce outlying estimates on small samples [25]
-
(b)
k-fold CV is nearly unbiased and with smaller variance than LOOCV.
-
(c)
Holdout estimator is unbiased but has high variance [30].
-
(d)
Bootstrapping is biased [28].
-
(e)
Repeating and averaging application of an estimator can drastically reduce its variance [28]. Recommended number of repeats is ≥50.
Best Practice 9.4.6
Use the least computationally expensive estimator that yields small enough bias and variance in the problem at hand.
For very small sample size: consider as first choice Leave One Out Cross Validation (LOOCV).
For small sample size: using a less-flexible classifier, the 0.632 bootstrap can offer the best performance but it can be biased [28].
For medium sample sizes: repeated balanced ten-fold cross validation.
For large samples sizes: holdout or five-fold Cross Validation or corrected bootstrap.
Performance Estimation in the Presence of Missing Values
When the analytic data set contains missing values, we can follow two strategies:
-
1.
We can first impute the entire analytic data set and then perform the evaluation on the imputed data set; OR
-
2.
We first partition (or resample) the analytic data set and then impute the missing values on each partition/resample separately.
The key issue is that when the model is implemented in practice, the data that the model will be operating on (test data) may contain missing values. If we follow strategy 1, our performance estimates may be too optimistic. Following strategy 2 is costly but eliminates the danger of biasing the error estimates (see also chapter “Overfitting, Underfitting and General Model Overconfidence and Under-Performance Pitfalls and Best Practices in Machine Learning and AI”).
Best Practice 9.4.7
Applying data imputation procedures on training data and using the imputation model on the test data (in cross validation estimators):
-
(a)
Ensures that bias is avoided.
-
(b)
Mimics practical implementation of the final model (which has to be eventually deployed without the benefit of seeing a large number of the application population).
Pitfall 9.4.3
Imputation on all data may bias the estimation of classifier errors (even if the imputation is blind to the outcome).
Parameter Tuning and Performance Estimation
Hyper parameter tuning as part of model selection is covered in chapter “Overfitting, Underfitting and General Model Overconfidence and Under-Performance Pitfalls and Best Practices in Machine Learning and AI”. Here we re-inforce an important practice:
Pitfall 9.4.4
Tuning hyper parameters or other procedures on the entire data first and then partition/resampling the data for evaluation can produce overly optimistic predictivity estimates.
Best Practice 9.4.8
Tune the parameters of an algorithm separately on each fold/resample.
Example 8.4.1 [Parameter tuning and bootstrap Estimsation]
To perform bootstrap estimation with B iterations, we proceed as follows. For each of the B iterations, we create a replica data set by resampling the analytic data set. The replica is then partitioned into a training and validation set. Models with various parameters are constructed on the training set and the optimal (for this iteration) parameter setting is selected using the validation set. A model is than constructed using the entire replica and the parameter setting we just selected. The performance of this model is then assessed using the out-of-bag data as usual, yielding one of the B performance estimates. At the end, the B performance estimates are summarized (e.g. arithmetic mean, weighted mean, confidence interval, etc). Note that the parameter settings do not necessarily coincide across the B iterations.
Example 8.4.2 [Parameter tuning and ten-fold cross validation]
The discovery sample is divided into 10 partitions. The estimation will proceed in 10 iterations. In the ith iteration, the ith partition will serve as test data and the remaining 9 partitions as development data. The development data is partitioned into training and test sets. Models with various parameter settings are built on the training set and the optimal (for this fold) setting is selected using the validation data (not to be confused with the test data – the test data (ith partition) is set aside and is not touched!). Then a model is constructed on the entire development data (9 partitions) with the parameter setting we just selected and predictions are made for the test data (ith partition). At the end, the predictions are evaluated. Note that the 10 parameter settings across the ten folds can be different.
A complete protocol for model selection is provided in chapter “The Development Process and Lifecycle of Clinical Grade and Other Safety and Performance-Sensitive AI/ML Models” and strategies to avoid overfitting in chapter “Overfitting, Underfitting and General Model Overconfidence and Under-Performance Pitfalls and Best Practices in Machine Learning and AI”.
Final Model
Model evaluation estimates the performance of a model construction procedure rather than the performance of a specific model.
Consider for instance the k-fold cross validation. At the end of the process, we have constructed k models. Similarly, a bootstrap estimation with B iterations produces B models. Clearly, the performance estimate we obtain is not the performance of any one of these models; it is the expected performance of a model following the same model construction procedure.
Best Practice 9.4.9
After error estimation has been accomplished and an optimal hyperparameter value assignment has been identified, the final model has to be built on the entire data set, with the same hyperparameter values, and without conducting further internal error estimation.
Even if you are using an estimator such as leave-out validation, which produces a model on the training set and evaluates this model on a validation set, as the final model, construct a new model on the entire discovery sample. The model constructed only on the training set utilized fewer observations and is thus less stable and possibly more biased than a model built on the entire discovery sample.
External Validation
The purpose of external validation is to ensure that a model derived from a discovery sample generalizes to the target population, or more precisely, to a different setting than that of the discovery sample.
Based on the changes in the setting, we distinguish between different kinds of external validations [2].
Temporal validation. The data for the population to which we apply the model is collected using a different time frame. As the standard of care changes, the validity (or at the least the predictive performance) of the model can vary. More recent patients, who are subject to the most recent standard of care, can be more indicative of the future performance of the model than earlier patients.
Temporal validation is performed by designating a particular time frame for training and a different time frame for validation.
A special case of temporal validation is pseudo-prospective evaluation. This is a leave-out validation, where patients with the most recent data are left out for validation and the model is constructed on the data of earlier patients.
Geographic validation. A model can be evaluated in a different geographic location than the one it was developed in. This can take two major forms. The first one is essentially an external validation of a model, where an existing model is evaluated at a new geographic location, for example, to determine whether the model can be applied to patients at this new location. The second one is multi-site development of a model. In this case, the discovery sample spans multiple geographic locations and the goal is to construct a model that works well at all geographic locations. Performance estimation in this context can take the form of a leave-one-site out cross-validation, where performance estimation is performed iteratively, in each iteration, leaving one site out and constructing the model on the remaining sites.
Spectrum validation. The model is validated on patients whose disease is more (or less) severe than those in the discovery sample. Such a validation is useful, for example, when (say) an ICU model is applied to patients “on the floor” (non-ICU wards).
Methodological validation. This is akin to sensitivity analysis. The model is applied to patients, whose data was collected and processed differently than the data of the discovery sample. This can be useful when we aim to ensure that a model developed on registry data is valid when applied to patient data from the EHR. It is reasonable to assume that the registry data is curated, and as a result, is more complete and is of higher quality.
Best Practice 9.4.10
If the sample size allows, pseudo-prospective (temporal) validation is recommended in addition to the internal validation and other planned external validations.
Best Practice 9.4.11
If the model was developed using public data, registry data, or other external data, always make sure that it is valid on the target population.
We conclude this chapter with the important observation that model performance is dependent on the evaluation metric. For example, for metric 1, model 1 > model 2; for metric 2 the reverse can be true. We discuss real life examples in multiple chapters of the book.
Key Messages and Concepts Discussed in Chapter “Evaluation”
The purpose of evaluating a clinical model is to ensure that a model has sufficient performance, is valid in the target population (and any other population of interest), and is capable of achieving the clinical objectives at a cost that is acceptable to the health system.
Confusion matrix (contingency tables) and related measures
Weighted confusion matrix, misclassification costs
ROC, Lorenz curves
Multiclass classification. One-vs-one, One-vs-All
Measures of predictive model performance for continuous outcomes.
Measures of predictive model performance for time-to-event outcomes.
Calibration. Calibration-in-the-large, weak, moderate and strong calibration.
Hosmer-Lemeshow test.
Measures of clinical effectiveness.
Net benefit and decision curve.
Health economic evaluation.
The goal of performance estimation is to infer the performance of a model in the target population based the discovery sample.
Performance /error estimator.
Internal validation
Holdout, Cross-validation, Repeated Cross-validation, Bootstrap, Bias corrected bootstrap
Combining imputation and hyperparameter tuning with error/performance estimation
External validation
Best Practices in Chapter “Evaluation”
Best Practice 9.1.1. Use evaluation metrics appropriate for the outcome type.
Best Practice 9.1.2. Multiple metrics are needed to cover different aspects of model performance. Use sets of measures that provide complementary information.
Best Practice 9.1.3. Common complementary pairs of classifier performance evaluation metrics include: (1) precision/recall; (2) specificity/sensitivity; (3) bias/discrimination.
Best Practice 9.1.4. The ROC is much more commonly used than the Lorenz curve and is more familiar to many readers.
Best Practice 9.1.5. Consider showing the Lorenz curve (possibly in combination with the ROC) when low-risk patients are of particular interest.
Best Practice 9.1.6 All of these measures are appropriate for Gaussian data.
Best Practice 9.1.7 MSE is more sensitive to outliers than MAD.
Best Practice 9.1.8. When evaluating predictive model with continuous outcomes that are heteroscedastic, consider using a residual that normalizes the expected variance (such as the Pearson residual for counts) or at least for the predicted value.
Best Practice 9.1.9. When the relationship between the predicted and actual values is not linear, consider using a rank-based measure such as Spearman or Kendall correlation.
Best Practice 9.1.10. The most common evaluation of a time-to-event model is Harell’s C statistic (survival concordance).
Best Practice 9.1.11 Time-dependent predictions can be summarized into a single value as (1) survival probability at the end of the study, (2) survival probability at the median survival time, (3) or survival probability at some clinically relevant time.
Best Practice 9.1.12 If an ROC is desired, time-to-event prediction can be converted into classification outcomes at a specific (clinically relevant) time point using the C/D strategy to plot the ROC.
Best Practice 9.2.1. For case/control designs, use OR.
Best Practice 9.2.2. Absolute and relative risk measures provide complementary information, so whenever possible, both should be reported.
Best Practice 9.2.3. ARR and NNT convey the same information and differ in interpretation. ARR is dimensionless, while NNT is measured in number of patients and is preferred in clinical practice.
Best Practice 9.3.1. Include all alternative interventions in a health economic evaluation.
Best Practice 9.3.2. Include the opportunity cost as cost of intervention/program in a health economic evaluation.
Best Practice 9.3.3 Do not use intermediate end-points unless they are very strongly linked to the outcome of interest.
Best Practice 9.4.1. Consider the sampling unit carefully.
Best Practice 9.4.2. A typical leave-out validation size is 30% of the sample.
Best Practice 9.4.3. For cross validation a typically number of folds is 10 in moderate sample size and 5 in large sample sizes.
Best Practice 9.4.4. When using the bootstrap estimator select a number of repetitions that is sufficient for the problem based on related literature. Reported minimum repetitions generally range from 100 to >500.
Best Practice 9.4.5. When using the bootstrap, estimate the bias and correct for it unless it is negligible. If the bias is unknown or cannot be corrected, then a different estimator must be used.
Best Practice 9.4.6. Use the least computationally expensive estimator that yields small enough bias and variance in the problem at hand.
For very small sample size: consider as first choice Leave One Out Cross Validation (LOOCV).
For small sample size, using a less-flexible classifier, the 0.632 bootstrap can offer the best performance but it can be biased [28].
For medium sample sizes repeated balanced ten-fold cross validation.
For large samples sizes: holdout or five-fold Cross Validation or corrected bootstrap.
Best Practice 9.4.7. Applying data imputation procedures on train data and using the imputation model on the test data (in cross validation estimators):
-
(a)
Ensures that bias is avoided.
-
(b)
Mimics practical implementation of the final model (which has to be eventually deployed without the benefit of seeing a large number of the application population).
Best Practice 9.4.8. Tune the parameters of an algorithm separately on each fold/resample.
Best Practice 9.4.9. After error estimation has been accomplished and an optimal hyperparameters value assignment have been identified, the final model has to be built on the entire data set, with the same hyper parameter values, and without conducting further internal error estimation.
Best Practice 9.4.10. If the sample size allows, pseudo-prospective (temporal) validation is recommended in addition to the internal validation and other planned external validations.
Best Practice 9.4.11. If your model was developed using public data, registry data, or other external data, always make sure that it is valid on the target institution’s internal data.
Pitfalls Discussed in Chapter “Evaluation”
Pitfall 9.1.1. Don’t use mathematically related measures together. They do not provide additional information.
Pitfall 9.1.2. Accuracy is very sensitive to the prevalence of actual positives and negatives.
Pitfall 9.1.3 Lorenz curves depend on the prevalence of the disease; ROCs do not.
Pitfall 9.1.4 Pearson residual is sensitive to small predictive values.
Pitfall 9.1.5. When the outcome is not homoscedastic, some ranges of the outcome value (larger values) can dominate the evaluation.
Pitfall 9.1.6. R2 is designed to measure the linear correlation between the predicted and actual values. When this is not linear, R2 is inappropriate.
Pitfall 9.1.7 When a model produces time-dependent predictions, these need to be summarized into a single value before the C statistic can be computed.
Pitfall 9.1.10. Flexible calibration curves depend on the smoothing applied to the curve.
Pitfall 9.2.1. In case/control studies, measures of effectiveness that depend on the prior of classes, are misleading when the balance of cases to controls in the samples differs from the balance in the target population.
Pitfall 9.2.2. The range of NTT has a “hole”. This makes significance testing and constructing confidence intervals difficult.
Pitfall 9.2.3 Even models with reasonable AUC can underperform a default policy of “Treat All”.
Pitfall 9.4.1. Do not use the plug-in estimator. Its estimate is always optimistic, sometimes excessively so.
Pitfall 8.4.2. If 70% of the discovery sample is insufficient training data, you need to consider other performance estimators (such bootstrapping or cross-validation).
Pitfall 9.4.3. Imputation on all data may bias the estimation of classifier errors (even if the imputation is blind to the outcome).
Pitfall 9.4.4 Tuning hyper parameters or other procedures on the entire data first and then partition/resampling the data for evaluation can produce overly optimistic predictivity estimates.
Classroom Questions, Chapter “Evaluation”
-
1.
Does a model with higher performance always have better clinical impact?
-
2.
A classifier recognizes the color of traffic lights: red, amber, green. How would you report the performance of this classifier? What metrics would you use?
-
3.
We discussed that there are two kinds of measures: those based on residuals and those that describe how the predicted value co-varies with the outcome.
-
(a)
Consider the log likelihood for a regression problem. Which group does it fall into?
-
(b)
Consider the log likelihood for a classification problem. Why would you put (or not put) the log likelihood into these two groups?
-
(a)
-
4.
For models that maximize a likelihood (or minimize a negative log likelihood), it is common to use a likelihood-based information criterion (e.g. BIC, AIC) for model selection. What is the advantage or disadvantage of using these criteria instead of direct measures of predictive performance? What if the model is not a predictive model (e.g. a clustering)?
-
5.
What is the key issue in evaluating a time-to-event model? If there is no censoring, can you use binary classification measures to evaluate a time-to-event model?
-
6.
The decision curve has p (the threshold for positive classification) on its horizontal axis. If a classifier produces labels (as opposed to a score), can the decision curve still be useful? What information can it provide? (Hint: think of the relationship between p and w.)
-
7.
How does the net benefit change if I use a positive classification threshold p that is different from w/(1 + w)?
-
8.
Can a classifier with AUC 0.9 have an unfavorable ICER?
-
9.
When can a really expensive clinical test have favorable (low) ICER?
-
(a)
The answer has to be verifiable through cost effectiveness analysis.
-
(b)
The answer has to be verifiable through cost utility analysis.
-
(a)
-
10.
Cost Benefit Analysis compares policies in terms of monetary benefits taking costs into account. Expressing health benefit as monetary benefit is very controversial. Can you think of a healthcare scenario, where this is inevitable?
-
11.
If you are a healthcare administrator and you are debating between spending resources on a diet program to reduce obesity versus a new cancer treatment, what kind of a health economic analysis are you conducting?
-
12.
The calibration model for binary outcomes is a logistic regression model. Derive the calibration model for count outcome. Hint: how is the poisson model linearized?
-
13.
Suppose you are a hospital administrator. If you are going to build a model for use in your hospital, you should fully optimize your model for your population and the performance of the resulting model on other populations is irrelevant.
-
(a)
Is this statement true?
-
(b)
Suppose your model has an AUC of 0.85 on your population. If you find that this model achieves an AUC of 0.75 on a similar population, what do you do? Can you ignore it?
-
(c)
Can you derive a benefit from training the model jointly on your and the other population and then updating it to better fit your own population?
-
What if the two populations only differ in a couple of variables?
-
What if most of the difference is due to the analyst’s definition of a disease?
-
What if the two population only differ in the prevalence of the disease? (Would that impact the AUC?)
-
(a)
-
14.
If your accessible population is the same as your target population, can external validation offer any benefit? (Hint: External validation is not limited to validation at other hospitals.)
-
15.
When you build your final model, you use the entire discovery sample. Let us focus on the bootstrap estimator. One reason for building a final model is that the bootstrap estimation process yields many models, one from each iteration. However, these models are all built on a replica of the discovery sample (has the same number of observations), so why can’t we just simply select one of the models and use that as the final model? What if we select that model at random? What if we select the best model?
-
16.
Examples 8.4.1 and 8.4.2 describe parameter tuning for bootstrapping and cross validation. In essence, we use leave-out validation on the model development data set to estimate the performance of the model for each parameter value. Is this the best approach if you have small data size? How could you use a more sample-efficient estimation method, such as cross-validation (instead of leave out validation) to tune the parameters? (Hint: the name of this approach is “nested cross-validation”.)
Notes
- 1.
The two key references for this chapter are [2] (chapters 14–17 and 19) and [3], both of which are textbooks. These cover basic concepts, such as validation, overfitting, evaluation metrics for binary and continuous outcomes. Time-to-even outcome has seen a lot of recent development and the key reference is [1]; and for calibration, we recommend [15]. [17] focuses in best practice for clinical effectiveness measures, and [31] covers net benefit and the decision curve. For the health economic impact, we recommend [21], which is a widely used textbook.
References
The two key references for this chapter are [2] (chapters 14–17 and 19) and [3], both of which are textbooks. These cover basic concepts, such as validation, overfitting, evaluation metrics for binary and continuous outcomes. Time-to-even outcome has seen a lot of recent development and the key reference is [1]; and for calibration, we recommend [15]. [17] focuses in best practice for clinical effectiveness measures, and [31] covers net benefit and the decision curve. For the health economic impact, we recommend [21], which is a widely used textbook.
Park SY, Park JE, Kim H, Park SH. Review of statistical methods for evaluating the performance of survival or other time-to-event prediction models (from conventional to deep learning approaches). Korean J Radiol. 2021;22(10):1697–707. [also says that 63% of the papers used Harrell’s C.] https://www.kjronline.org/pdf/10.3348/kjr.2021.0223.
Steyerberg EW. Clinical prediction models. A practical approach to development, validation and updating. 2nd ed. Cham: Springer; 2019.
Pepe MS. The statistical evaluation of medical test for classification and prediction. Oxford: Oxford University Press; 2003.
Rodriguez JD, Perez A, Lozano JA. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans Pattern Anal Mach Intell. 2009;32(3):569–75.
Steyerberg EW. Lorenz curve (chapter 15.2.6). In: Clinical prediction models. A practical approach to development, validation and updating. 2nd ed. Springer. Cham; 2019.
Davis J. and Goadrich M. The relationship between precision-recall and ROC curves., International Conference on Machine Learning, 2006.
Bex T, Comprehensive guide to multiclass classification metrics. Medium, 2021. https://towardsdatascience.com/comprehensive-guide-on-multiclass-classification-metrics-af94cfb83fbd.
Delgado R, Tibau X-A. Why Cohen’s kappa should be avoided as performance measure in classification. PLoS One. 2019;14(9):e0222916. https://doi.org/10.1371/journal.pone.0222916.
Tan P-N, Steinbach M, Karpatne A, Kumar V. Introduction to data mining. Pearson; 2018. ISBN:0133128903.
Biecek P, Burzykowski T. Exploratory model analysis. 2020. https://ema.drwhy.ai/modelPerformance.html.
Evaluating Survival Models. Scikit-survival 0.17.2 User Manual. https://scikit-survival.readthedocs.io/en/stable/user_guide/evaluating-survival-models.html.
Hanpu Z. Predictive Evaluation Metrics in Survival Analysis. R vignette. 2021. https://cran.r-project.org/web/packages/SurvMetrics/vignettes/SurvMetrics-vignette.html.
Rahman MS, Ambler G, Choodari-Oskooei B, Omar RZ. Review and evaluation of performance measures for survival prediction models in external validation settings. BMC Med Res Methodol. 2017;17:60. [Uno’s C] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5395888/.
Heagerty PJ, Zheng Y. Survival model predictive accuracy and ROC curves. Biometrics. 2005;61(1):92–105.
Calster BV, McLernon DJ, van Smeden M, Wynants L, Steyerberg EW. Calibration: the Achilles heel of predictive analytics. BMC Med, 2019;17(230) [Strong, moderate, weak and at-large calibration] https://bmcmedicine.biomedcentral.com/articles/10.1186/s12916-019-1466-7.:17.
Austin PC, Steyerberg EW. The Integrated Calibration Index (ICI) and related metrics for quantifying the calibration of logistic regression models. Stat Med. 2019;28(21) [Integrated Calibration Index (ICI), Harrell’s E (Emax, E50, E90)]:4051–65. https://doi.org/10.1002/sim.8281.
Schechtman E. Odds ratio, relative risk, absolute risk reduction, and the number needed to treat—which of these should we use? Value Health. 2002;5(5):431–6. https://doi.org/10.1046/J.1524-4733.2002.55150.x.
Hutton JL. Number needed to treat and number needed to harm are not the best way to report and assess the results of randomised clinical trials. British J of Hematol. 2009;146:27–30. https://doi.org/10.1111/j.1365-2141.2009.07707.x.
BMJ evidence based medicine toolkit. How to calculate risk? https://bestpractice.bmj.com/info/us/toolkit/learn-ebm/how-to-calculate-risk/. [Defines all these measures (except OR) without much fluff.]
Szumilas M. Explaining odds ratios. J Can Acad Child Adolesc Psychiatry. 2010;19(3):227–9. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2938757/.
Drummond MF, Sculpher MJ, Claxton K, Stoddart GL, Torrance GW. Method for the economic evaluation of health care Programmes. 4th ed. Oxford: Oxford University Press; 2019.
Winterhoff B, et al. Developing a clinico-molecular test for individualized treatment of ovarian cancer: the interplay of precision medicine informatics with clinical and health economics dimensions. AMIA Annu Symp Proc. 2018;2018:1093–102.
Barnett JC, Alvarez Secord A, Cohn DE, Leath CA, Myers ER, Havrilesky LJ. Cost effectiveness of alternative strategies for incorporating bevacizumab into the primary treatment of ovarian cancer. Cancer. 2013;119(20):3653–61.
Saris-Baglama RN, Dewey CJ, Chisholm GB, et al. QualityMetric health outcomes™ scoring software 4.0. Lincoln, RI: QualityMetric Incorporated; 2010. p. 138.
Braga-Neto UM, Dougherty ER. Is cross-validation valid for small-sample microarray classification? Bioinformatics. 2004;20(3):374–80.
Efron B. Estimating the error rate of a prediction rule: improvement on cross-validation. J Am Stat Assoc. 1983;78(382):316–31.
Efron B, Tibshirani R. Improvements on cross-validation: the 632+ bootstrap method. J Am Stat Assoc. 1997;92(438):548–60.
Kim JH. Estimating classification error rate: repeated cross-validation, repeated hold-out and bootstrap. Comput Stat Data Anal. 2009;53(11):3735–45.
Bengio Y, Grandvalet Y. No unbiased estimator of the variance of k-fold cross-validation. Adv Neural Inf Proces Syst. 2003:16.
Burman P. A comparative study of ordinary cross-validation, v-fold cross-validation and the repeated learning-testing methods. Biometrika. 1989;76(3):503–14.
Vickers AJ, Calster BV, Steyerberg EW. A step-by-step guide to interpreting decision curve analysis. Diagn Progn Res. 2019;3:18. https://doi.org/10.1186/s41512-019-0064-7.
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2024 The Author(s)
About this chapter

Cite this chapter
Simon, G., Aliferis, C. (2024). Evaluation. In: Simon, G.J., Aliferis, C. (eds) Artificial Intelligence and Machine Learning in Health Care and Medical Sciences. Health Informatics. Springer, Cham. https://doi.org/10.1007/978-3-031-39355-6_9
Download citation
DOI: https://doi.org/10.1007/978-3-031-39355-6_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-39354-9
Online ISBN: 978-3-031-39355-6
eBook Packages: MedicineMedicine (R0)