
Abstract
Recommender systems are increasingly used in e-learning to provide users with personalized services and advice. Depending on the specific context for which the system is implemented (e.g., homework on a specific subject for university students, new training courses for life-long learners), the objectives and proposed items, the chosen recommendation techniques, the features that are considered, the way the recommendations are presented to the users are closely related to the designers’ perception of learners and knowledge. The various approaches reflect different epistemic and ethical viewpoints; for example, representing people using fixed models is easier to process, diagnose, predict and explain, but presents a partial view of reality and obscures the fact that they are complex and evolving individuals. Similarly, some filtering methods can restrict the view of available courses to items considered similar to those that the learner has already followed, thus promoting specialization rather than diversification and openness. This aspect is closely related to fundamental issues involved in the theory of knowledge, questioning the notions of utility and purposes of science, as well as a key issue for academic change and, more fundamentally, that of modern societies. Indeed, these issues should be seen in a broader context of reflection about the economic changes and ideological transformations of a society grounded on neoliberal capitalism. The main goal of this study is to explain how the design of recommender systems in e-learning has both ethical and practical implications since it reflects an ideological conception of science and techniques, thus requiring a previous examination of these issues in order to define the theoretical model of knowledge in which it takes place. For that purpose, we study the certain visions of teaching and learning that can be brought about by algorithms and models used by existing recommender systems in e-learning.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others

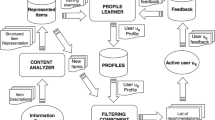

Keywords
1 Introduction
Recommender systems are widely used in e-commerce, social networks, Video On Demand, etc. They are based on collected information about user preferences, which can be acquired implicitly (e.g., collecting the data describing the users’ behavior) or explicitly (e.g., collecting the users’ ratings, using social and demographic information). They aim at guiding users within the wide range of products offered by e-platforms so that they can find the items that they are most likely to engage with. Similarly, recommender systems for e-learning are used to help learners to deal with the abundant learning resources and activities available on e-learning platforms. They are used to support individual learning and provide the learner with the appearance of personalized tutoring in environments of large classes but limited human contact (i.e., reduced teacher to student ratio). In the context of the ongoing COVID-19 pandemic, the use of such recommender systems appeared crucial for the student’s involvement and engagement, and to help teachers optimize the assistance they provide. They are also expected to efficiently help students to choose their learning paths, efficient pedagogical activities, and suitable course material. Indeed, many papers present good results concerning the effectiveness of their recommendation approach, whether it be based on task difficulty ranking (Segal et al. 2014), learning material or path recommendation (Mbipom et al. 2018; Ye et al. 2015; Shi et al. 2020), friend recommendation (Rafaeli et al. 2005), learning object recommendation (Gallego et al. 2012; Fraihat and Shambour 2015), or performance evaluation (Amasha et al. 2020; Moore et al. 2019). Furthermore, from the institution’s perspective, they can be used to increase their economic benefits, since they enable larger volumes of students with fewer teachers.
However, if lucrative economic interests come first, this may raise a number of ethical concerns, both theoretically and practically (Beach and Dovemark 2009). Recommender systems are widely used for e-commerce and entertainment (i.e. music, video on demand (VOD), video game platforms, etc.). In early 2000, the first notable applications appeared in the domain of education (Manouselis et al. 2012). The development of the Internet has stimulated the research in recommender systems in order to improve the filtering and assessment methods, in particular through the involvement of economic actors who encourage them to increase their benefits (e.g. the Netflix prize that challenged machine learning and data mining). Such practices not only promote algorithmic development but also affect our relationship to education, culture, etc. (Hallinan and Striphas 2016).
First of all, as Catherine Hayles (1999) shows, new technological contexts (thus by inclusion new algorithmic contexts) change our relationship to our environment and, more fundamentally, alter our meaning of humanity, culture, sociality, etc. Moreover, the methods developed for VOD, e-commerce, e-learning etc. are the same; thus, the methods used to sell products and increase the benefits of an enterprise are also used to recommend learning items to students, which may cause problems. Indeed, recommendations in e-commerce can be accused of being more meant to help sellers than customers, just as advertising is. In e-commerce, the sellers use recommender systems to increase the number of sales and their income, sometimes with very little concern about what their customers really need. From this standpoint, they can be considered as the real customers of recommender systems, instead of the sellers’ customers. Some studies have shown that recommender systems in e-commerce not only help the sellers’ customers to get what they prefer: they also contribute to shaping their preferences (Adomavicius et al. 2019). Yet, even though this very practice is already highly questionable in e-commerce, it is even more critical in the case of e-learning. In particular, recommender systems in e-learning cannot pretend to stand apart from the academic debates about university, notably concerning its aims and values. For example, should university train future workers with competencies consistent to the job market, or whole citizens who will be able to take an active part in the social and political life of the society? (Florian 2018; Brighouse and McPherson 2015) Is university threatened by a commodification of knowledge process? (Jacob 2003).
As part of the reflection about education trends and policies, and besides all its potential benefits, the development of recommender systems in e-learning gives rise to ethical and social issues, including privacy problems, lack of control, etc. Just as the other personalized e-learning functions, the recommender systems use personal information, generally using algorithms poorly understood by the users, in order to offer them services. Consequently, the opacity of such systems raises a main issue because the users are recommended items without being provided with the knowledge to understand these recommendations, thus knowing when to choose to follow them or not. In order to understand why it can be problematic, we will explain how recommender systems can promote particular visions about education, pointing out that these assumptions need to be disclosed.
The paper is organized as follows: Section 11.2 presents the main methods used in recommender systems; Section 11.3 exposes the potential problems posed by applying them in the field of pedagogical recommender systems; the problem statement is exposed in Sect. 11.4, which is followed by an outline of proposals to overcome some harmful consequences of the use of recommender systems for e-learning (Sect. 11.5).
2 Methods of Recommender Systems
In the literature, recommender systems are generally classified into two types, depending on how the recommendations are made: content-based and collaborative filtering. Also other methods, such as knowledge-based filtering, more complex and difficult to implement, receive attention in specific fields, such as e-learning.
Content-based filtering (Van Meteren and Van Someren 2000; Pazzani and Billsus 2007) is a very common method for recommendations in e-commerce, VOD, etc. because it is both efficient and easy to implement. The principle is very simple, and entirely centered on the comparison between the user’s interests and the item’s features. The user is recommended items that most resemble the items that they have already liked, or just consulted. For that purpose, the system analyzes the user’s favorite items and the features of these items to identify the user’s preferences. It only requires building a model of the user preferences, using the item features and a history of the user’s consultations, likes and dislikes, etc. But other information can be taken into account to build the user model, such as demographic characteristics (e.g. age, nationality, gender).
Collaborative filtering (Schafer et al. 2007; Afoudi et al. 2018) is another common method, in which the user is recommended the favorite items of the users with similar tastes. For that purpose, the system identifies the active user’s closest users and the items that they have liked but that the active user has never consulted yet, in order to recommend them. The recommendation can be based on the values of recorded interactions only (memory-based approaches) or on a generative model that explains the user-item interactions in order to make predictions (model-based approaches). This method has been popularized by Amazon, considering that whether a user has consulted a product x, they should be also interested in a product z, but it is mostly used by social networks to recommend new social connections (e.g. friends, groups).
Knowledge-based filtering (Aggarwal 2016; Bouraga et al. 2014) is far more difficult to implement. It consists in recommending items based on explicit recommendation criteria, information about the user preferences, and all the characteristics of every available item. The system resorts to knowledge representation, for example in the form of rules about how an item meets a particular user. In e-commerce, they are generally used for items that are not purchased very often, such as a car, tourist destination, etc.
Since every method has drawbacks and limits (e.g. cold-start problem of collaborative filtering: in case of new users, the system does not have information about their preferences in order to make recommendations (Lika et al. 2014)), hybridization (Burke 2007; Isinkaye et al. 2015) is increasingly used to overcome them. It consists in coupling different filtering methods to make better recommendations. Many hybrid methods can be used, such as cascade (i.e. one recommender produces recommendations that will be refined by the other) or switching (i.e. the system uses a criterion dependent on the situation to switch between recommendation techniques).
Different evaluation metrics can be used to assess how a recommender system performs (Isinkaye et al. 2015). Among the most commonly used are the methods based on precision (i.e. number of selected items that are relevant) and recall (i.e. number of relevant items that are selected). In such methods, the assessment uses the user’s ratings to know which items are relevant. For example, the system tries to predict the score that a user would grant to an item, then calculate how much the predicted score is from the actual score.
3 Recommender Systems in e-Learning
E-learning recommender systems are based on the same methods as recommender systems for e-commerce, VOD, etc. (i.e. content-based, collaborative, and knowledge-based filtering, or hybrid methods). Due to the numerous and various courses, programs, pedagogical resources, and activities available online, more and more research is conducted to propose recommender systems able to support learners, either students in school or long-life learners, in deciding which courses to follow, what resources to consult, depending on their preferences, their needs, their expectations, their skills, at a given time.
We consider that a recommender system in e-learning can be described by the following dimensions:
-
1.
The features used to describe the learner (e.g., learning styles, explicit preferences, implicit preferences, demographic information, current skills).
-
2.
The nature of the items to recommend (e.g., courses, friends, learning materials, graduate programs, keywords) and the features used to describe them (e.g., general topic, main concepts, format, authors, popularity).
-
3.
The filtering techniques.
Some recommender systems are described by an additional dimension:
-
4.
The teaching model that describes how the recommendations are provided to the student (e.g. the rules of item selection, the granularity of recommendations, the communication acts).
To a certain extent, recommender systems in e-learning have similarities with recommender systems in e-commerce. For example, they use the same filtering techniques (i.e. content-based filtering, collaborative filtering, knowledge-based filtering, or hybridization). But we notice that they also have some specificities:
-
1.
The information can be imprecise and ambiguous. For example, learners may know what job they want to do but may not know which skills and knowledge are required.
-
2.
The course sequencing may be crucial because some pedagogical activities need prerequisites.
-
3.
Acquiring some knowledge is not like acquiring a concrete object: it is not enough to purchase it to get it. The context is particularly important in learning and it is crucial to determine which item is best adapted to a given situation. For example, long-life learners may be unable to devote more than fragmented periods to learning, and thus prefer short activities, while full-time students may prefer intensive and long courses.
There is not one good way to model a recommender system in e-learning. The efficiency and the relevance of the methods and features used may vary depending on the problems (i.e. the learning objectives, the intended users, the variety and the degree of specialization of course material, etc.). But, beyond their purely practical aspects (i.e. efficiency and accuracy of the recommendations, system speed and responsiveness, adaptability, etc.), some ethical issues intrinsic to the field of learning are specific to recommender systems in e-learning and have some direct practical implications. In particular, the choices of filtering techniques, learner model, and assessment methods have direct consequences on social and epistemic open-mindedness, the diversity of thinking, and the conception of knowledge and learning. As we will see, these issues are closely related to the aforementioned debates about the function and the utility of knowledge.
3.1 Filtering Techniques: What Implications on Social and Epistemic Open-Mindedness?
Recommender systems in e-learning use the same methods and adapt them to the specific educational field; but some of them are more likely to offer the user a choice of tools directly relevant to the current job market, thus promoting a utilitarian vision of science, while others tend to encourage and support the idealist perception of holistic knowledge by proposing more diversified courses, maybe dealing with rarely studied subjects. For example, one shortcoming of content-based methods is that they induce a lack of serendipity, that is, very few encounters with the unexpected when seeking something else. The lack of serendipitous exposure has been denounced as harmful in social media and online newspapers since it causes the apparition of “filter bubbles”, seen as huge threats to democracy and social links, polarizing and fragmenting the social space (Pariser 2011). This method is sometimes used in e-learning recommender systems, such as labelled items (Li et al. 2008) and distance between concept vectors (i.e. measurement of the difference between two concepts that are described through mathematical variables) (Ye et al. 2015),
In e-learning, these methods tend to propose courses directly related to the one that the learner has just finished, encouraging specialization. For example, in the case of content-similarity based on the distance between concept vectors (Ye et al. 2015), only the semantic relatedness is taken into account, using an automatically calculated relatedness matrix. Therefore, in this case, whether a student has just finished a course about Python programming essentials for data analysis, which deals with Python programming language, data science, and object-oriented programming, they could be proposed courses about the basics of Python programming language, dealing with Python programming language and object-oriented programming, and courses about graphics for data visualization, dealing with Python programming language, data science, and graphic tools, rather than a course about the ethical issues of AI. Still, these ethical issues could be very relevant for their whole training. Thus, some learning materials will never be proposed to the students and will even be overshadowed by the propositions of the algorithm. On the one hand, it allows scientific expertise and a good and deep comprehension of the non-trivial scientific objects that are specific to one discipline, thus increasing the learner’s understanding of structures and processes. On the other hand, a certain amount of openness may be essential to remind learners of the multiplicity of the reality levels and the necessity to look beyond the disciplines, because knowledge is in essence an opening to the external world: learning is always a coming out from oneself and an act of inhabiting the world, through insights, perception, and intentionality.
That is why it must be an informed designer choice, for example when an online platform is explicitly designed to improve the learners’ expertise in one targeted field. Indeed, such platforms can be very useful for learners (e.g. when they need to master a specific tool) and teachers (e.g. in the frame of one specific subject taught by a teacher, with defined resources and activities, and for which the possibility of distance-learning is offered), but they are not appropriate for general-interest e-learning platforms, where learners want to enrich their global knowledge. Since they facilitate in-depth study of one field or subject, they can hinder openness. Not only does serendipity allow one to compare and further up one’s knowledge with other forms of knowledge, models, and paradigms, but it also brings interest to the discovery. More generally, the models on which the recommendations are based are important too.
3.2 Model Selection: A Risk of Thinking Homogenization?
As mentioned, recommender systems generally use two different information sources: the features of users and the features of items. A user model (i.e. the system’s internal representation of the user’s preferences, needs, expectations, etc.) can be built mainly based on users’ ratings on items, users’ previous navigation patterns, or the content features of purchased items. Similarly, in e-learning, a learner model, which corresponds to the user model, is mostly used to make personalized recommendations, also based on the features of the learning material, activities, paths, etc. Although some e-learning recommender systems do not use any (Ye et al. 2015), even most content-based recommender systems are based on a learner model, which expresses the learner’s interests (Shu et al. 2018), internet history (Khribi et al. 2008), learning styles (Dwivedi and Bharadwaj 2013; Severac et al. 2012), etc. The choice of what is represented through this model is crucial since it refers to a specific conception of learners and strongly influences the recommendation. For example, in the Fuzzy Tree Matching-Based Personalized E-Learning Recommender System developed by Wu et al. (2015), the learner profile contains the learner’s background, learning goals, prior knowledge, and learner characteristics, specified by the learner themselves when they registered; while in the Hybrid Attribute-based Recommender System for E-learning Material Recommendation proposed by Salehi and Kmalabadi (2012), the learner profile refers to their preferences obtained from their ratings. Sometimes, but rarely, educational recommender systems use a teaching model. For example, the adaptive neuro-fuzzy pedagogical recommender designed by Sevarac et al. (2012) integrate a set of modal rules based on the student’s knowledge, the course sequencing, etc. in order to determine what the system should recommend to the student in a specific situation. They show that this model is very beneficial for the quality of the recommendations because, although more complex, the learner model is mostly different from the models used, either consciously or unconsciously, by the teachers to make recommendations to their students. Some learner models can encourage overspecialization and pattern reproduction, they can cause a split between different ways of thinking and ignorance of other beliefs, approaches, etc. Since they help learners to filter out information, they prevent them from being exposed to new learning perspectives.
For example, the recommender agent for e-learning systems developed by Zaiane (2002) uses data mining techniques such as association rules mining in order to build a model that represents on-line user behaviors, to suggest activities. In this case, the prediction is based on the current sequence of activities or pages visited by the learner and the other users’ frequent sequences of visited pages: basically, the system “learns” from the past activities of one user or a group of users and predicts activities or pages that a given user might be interested in before suggesting them to the user. Thus, learners do not have personalized activity recommendations since these lead to the same learning patterns reproduction. This recommender agent is also based on the course sequencing: if a learner has studied the A course, then they should study the B course. Here again, the recommendations are called “personalized” while it is in fact only an appearance of tailored assistance: the learner model is just based on the history of the followed courses in order to recommend the next one. Other works use a student modelling based on the learning style (Dwivedi and Bharadwaj 2013; Severac et al. 2012). The learning style approach has been widely called into question by recent researches in education (Rohrer and Pashler 2012; Kirschner, 2017), in which it was pointed out it that this approach can have prejudicial effects, such as freezing the students in one single way of learning thus being counterproductive to the development of varied skills. However, since these models remain easy to implement, they are still often used by recommender system’s designers. Such systems can reduce the learner’s exposition to new ways of learning, new kinds of informational sources. Here again, this can be a pedagogical choice. Indeed, even though differentiated learning is now widely identified as a crucial approach to improve student academic engagement and success and has become a standard requirement in educative policy led in various countries (e.g. England (Mills et al. 2014), France (Kahn 2017)) notably with the aim to promote social justice, there are also strong critics, notably conceptual (Needham 2011), practical (Mahony and Hextall 2009), and ideological (Pykett 2010; Beach and Dovemark (2009)). The problem is that recommendations provided by recommender systems in e-learning are generally misleadingly presented as personalized. This lack of variety can prevent students from getting used to seeking and exploiting new information vehicles, which can be problematic if teachers expect the recommender system to take over students’ exposition to multiple kinds of information. Due to their opacity, the models and data on which recommendations are based remain unknown by teachers and students, who do not have information necessary to understand what “personalized” really means in the case of the systems they use. There is a lack of information and transparency that can prevent teachers from choosing a system that really suits their pedagogical strategy and appropriately use it.
3.3 Assessment Methods: What Do They Value?
In some papers (Khribi et al. 2008; Wu et al. 2015; Salehi 2013), the limitations of content-based and collaborative filtering are reported in order to propose better recommendation methods, such as hybridization, coupling content-based and collaborative filtering, but they do not all result in more serendipity. For example, when designers choose the cascade method to couple the content-based and collaborative filtering, the cold-start problem is overcome, thus the recommendation results can be better, but the system still encourages overspecialization. Indeed, the collaborative filtering step only refines the results obtained by the content-based filtering step. The main problem comes from the metrics used to evaluate the system and what is actually valued.
Several methods are used to evaluate recommender systems in e-learning, such as surveys (Sevarac et al. 2012), the evolution of the number of requests after cleansing the data (Khribi et al. 2008), MAE (Bobadilla et al. 2009). Depending on the method used, various characteristics can be as assessed: surveys assess the user’s satisfaction, the evolution of the number of requests assesses the utility, MAE assesses the accuracy, etc. The choice of the evaluation method and what needs to be evaluated is crucial because it both reflects the purchased main goals of the system and contributes to defining the final system design. Indeed, for example, the assessment methods can be applied to different versions of the system to decide which one to choose. It can also be applied to a single version of the system in order to know whether it can be deployed or whether the design has to be modified.
As previously mentioned, even though some researchers use more qualitative methods to assess their recommender systems in e-learning, it remains that, in many works, the metrics and assessment tools used are those developed for e-commerce recommender systems, which especially value the adequacy between the student tastes and the system suggestions. Thus, most recommender systems base their recommendations on the rating estimations (Wu et al. 2015; Salehi and Kmalabadi 2012; Bobadilla et al. 2009): given the active user’s actual ratings, the system predicts the score they would give to the other available items. For instance, according to the standard assessment method, the precision can be calculated using the 80/20 method. 80% of the already rated items are used to train the system and calculate predicted ratings for the remaining 20%. Then, these predictions are compared to the actual ratings of these items. In e-commerce, precision is crucial in order to propose to the consumer items that they are likely to desire to buy. But in e-learning, this assessment method raises various issues, either pedagogical or ideological, which could seem crucial for teachers.
Concerning the pedagogical issues, it could be pointed out notably the fact that, when using this method, it is assumed that the score prediction precision is the most important metric to assess the recommendation quality, that is, the most important consideration is the student’s likes or dislikes. However, this assumption could be questioned. There are various reasons why other considerations should be considered. For example, the learning courses, activities, and materials need to be arranged in order to ensure that the prerequisites of some courses are acquired. Moreover, how can we know what the scores provided by the learners are based upon? Did they assess the form or the content? If they have scored the content, did they find it interesting, easily understood, useful for their whole training, or relevant to their current concerns? Were they happy to acquire new knowledge, face new and challenging issues, or have a quick and easy task? Yet, whether learners have to like their course material and learning activities is a philosophical, educational, and sociological issue, which could be seriously questioned. For example, even though it is proven that enjoyment positively influences the didactic process and the memorization of information (Hernik and Jaworska 2018; Pekrun et al. 2009) in particular by increasing motivation, positive emotions do not always result in efficient learning: for example, relaxation can affect learning by causing over-confidence (Pekrun et al. 2011). In particular, Henritius et al. (2019) argue that students’ satisfaction can be a misleading indicator of learning, which often requires stepping outside one’s comfort zone, thereby creating emotions (such as discomfort) rarely associated with satisfaction. Furthermore, efficiency of the encoding and memorization of information may not be the more essential criterion. Indeed, more fundamentally, the very aim (or aims) of following courses has to be examined: it can be defended that the pursued goal is acquiring knowledge, or mastering mental tools (e.g. scientific methods) to understand and analyze the world, developing a critical mind, etc. Yet, in this latter perspective, the confrontation of students to questions, information, and ideas that they do not like could be also useful, and even necessary. Moreover, the context of learning is important too, and the learner’s needs can change over time, depending on their projects, the knowledge they acquire, the new challenges they meet, the techniques they master, etc.
Secondly, from an ideological point of view, teachers could fear that such a method can result in the commodification of knowledge, which is a process accused of valuing knowledge in relation to its economic productivity, and transforming students into consumers who can expect that a commodity offers the service for which it has been produced. This issue is closely related to the concept of “Cognitive capitalism” (Blondeau and Latrive 2020; Fumagalli and Lucarelli 2010) which involves the transformation of an intellectual good into a commodity and/or a resource. It could seem problematic for several reasons. First of all, it may be argued that it is hardly compatible with the idea of a free and disinterested activity, an activity with no defined goal, a praxis that is summoned whatever the purpose is. The economic rationale is built on an instrumental rationale, on predictable behaviors and results. A second fear could be that the creation of a knowledge market requires regulating and restricting access to knowledge, leading to inequality issues since access to knowledge depends, among other things, on the economic conditions of an individual. Finally, and above all, according to Blondeau and Latrive, cognitive capitalism encourages eliminating the knowledge regarded as useless or even counterproductive because of time-wasting (Blondeau and Latrive 2020): if only knowledge that supports growth is useful and deserves to be transmitted, the rest leads to nothing but sterile debates and questionings. From this standpoint, the knowledge about emerging technologies, for example, is valued, since it can lead to a continuous producing and selling of endlessly improved items. On the contrary, philosophical concepts such as ethics are often and prejudicially neglected, as shown in some papers (Lauer 2021), and social issues are considered as secondary. Some studies have shown that, although social sciences are essential to address climate change and energy transition, these fields receive very little funding for climate-related research (Overland and Sovacool 2020). This is a crucial and structural problem; yet, it is well-known now that artificial intelligence tends to reproduce biases inherent to data used for machine learning.
In addition to the ideology and the perception of education conveyed by such practices, they have effects on student learning, which should be known before choosing to integrate them in a pedagogical platform or strategy. For example, some students take online courses with the only purpose of being awarded a certification. Similarly, in order to increase their revenue, some institutions offer online courses so that they can reduce the number of actual human teachers while proposing courses to a higher number of students. From this standpoint, providing the students with quick access to resources and activities can be regarded as beneficial. But the other side of the coin is that learners develop a habit to trust the recommendations of the algorithms, instead of seeking and selecting the appropriate information on their own, yet this cognitive routine should be encouraged and trained. This is particularly true with recommender systems that propose keywords for the student’s requests (Li et al. 2008) or ordered items in terms of supposed relevancy. Indeed, education is not only transmission of learning content and vocational knowledge and know-how, but also about teaching critical thinking and reasoning, seeking information and comparing sources, debating and discussing. Both are not mutually exclusive and reuniting them is maybe one of the main challenges that universities must face in these times of quest for profits and efficiency.
4 Problem Statement
According to the previous analyses, we have identified three main issues that could seem problematic for teachers and institutions when they choose to integrate a recommender system in their learning strategy or platform:
-
The commodification of knowledge, which is pointed out for valuing it in relation to its economic productivity, subjecting knowledge to the market law and transforming students into consumers.
-
The specialization effect, that is the fostering of students’ exposure to close learning contents or forms.
-
The rationalization process, which is conceptualized by those who oppose it a trend to establish as indisputable truth the results coming from dominating models, promote the idea of a scientific consensus on many subjects and break with the prolific scientific method and philosophical methods, which prompt caution, comparison, verification, and dialectics.
The preoccupations raised by these issues are mainly ideological and pedagogical. We think that there are three sides of the problem:
-
1.
The rigidity of recommender systems, which are generally unable to adapt their recommendations to the teacher’s pedagogical approach and needs
-
2.
The lack of specialists in the science of education in recommender system designer teams
-
3.
The lack of transparency about how recommender systems deployed for students’ learning work
Since these issues seem very controversial in scientific literature about education, we argue that addressing these both problems is a crucial ethical matter.
For this purpose, we propose these main lines of improvement: fostering systems able to adapt to the teacher’s specific pedagogical approach requirements, ensuring an epistemic liability of the models used to design recommender systems, allowing users to understand the underpinning reasons of recommendations, their potentialities and their limits.
5 Some Proposals
5.1 Knowledge-Based Recommendations
In the case of e-learning platforms proposing a wide range of courses, knowledge-based methods appear to be a promising way to connect concepts and give them meaning, thus drawing a network of possible paths. Ontologies can be a good solution to encode the semantic and modal relationships between the concepts. In this way, the system could be able to recommend a variety of different courses and contents, in a relevant proportion, given the degree of correspondence between the course that the student is currently following and the available items.
It can also be interesting within the scope of a specific course, when the recommender system is used to help the student find appropriate resources or activities when they feel blocked, want to go further, etc. Besides, in order to implement a teaching model (i.e. implementation of the teachers’ pedagogical strategies), some works already propose knowledge-based recommender systems. It is a very interesting approach since it allows us to integrate and use more complex information and bond them in order to propose a more tailored assistance. For example, Sevarac (2012) proposes to define high-level rules, easily understood and used by teachers, so that they can decide what activities will be recommended for every set of learners. The fuzzy sets describe the student’s knowledge of some topics and the preferred learning style. In this proposed solution, teachers do not have much room for maneuver yet and the student model (i.e., current knowledge and learning styles) still appears limited, all the more as the use of learning style is questionable. But it gives a good idea of what can be done, and what should be improved to provide the students with assistance tailored to suit the teacher’s approach, thus ensuring pedagogical continuity, while doing their homework for example. This requires close interactions between recommender systems and teachers, by means of meaningful feedback, and easy to learn and use setting-up tools.
5.2 A Learner Model Coming from Cognitive and Educational Sciences
Intelligent tutoring systems are often based on learning and teaching models, chosen according to several characteristics such as the pedagogical goals and available resources. Proposing a suitable learner model, not judgmental and able to meet the real and precise needs of every student, is a major challenge for e-learning recommender systems. Indeed, conceiving an AI-system, which necessarily works using categories and labelling, whose recommendations could suit the individual characteristics of human students, seems very difficult and requires careful design. For that purpose, a solution can be to use learner models that come from the cognitive and educational sciences, since a deep reflection has already been led to conceive models that at best allow to express and represent the learners’ specificities. Of course, there is not any ideal model that enables a representation of all the most relevant characteristics of learners, and a meticulous analysis should be systematically conducted to find the most accurate and appropriate one, depending on the specific aims of every recommender system and the kind of assistance that is expected to be provided. For example, in intelligent tutoring systems dedicated to assisting learning, the cognitivist approach (Anderson and Gluck 2001), as opposed to behaviorism, aims to explain the learner’s behavior changes through mental operations. Indeed, in the behaviorist approach, learning is viewed through the prism of the stimulus-response relationship. The complexity of the learner’s cognition is not denied but it is considered as a black box that is not intended to be opened (Skinner 1974). On the contrary, in the cognitivist approach (Anderson 1996), the cognitive box is opened: the learner’s cognitive processes are broken down into interconnected sub-processes and stages.
5.3 A Teaching Model Based on Empiric Analyses
Teachers have various strategies to take decisions about the right didactic action to take in response to the student’s observed situation, in particular basing their choice on some epistemic factors such as the knowledge at stake and the learner’s knowledge state. The teacher’s diagnosis of this situation is crucial for their recommendations. In recommender systems, the learning models allow for the representation of these learning situations, but they have thereafter to be adequately interpreted to produce recommendations with real pedagogical value. In such a perspective, building pedagogical scenarios is not enough, since they do not ensure that the epistemic dimensions (e.g., the knowledge organization and acquisition) will be taken into account. A teaching model has therefore to be used in order to organize knowledge acquisition in a given learning situation. Teaching models are generally given by empiric analyses conducted by teachers. For example, they can be based on generic models such as the Socratic method (i.e., a dialogue about the studied issue is carried on by the system with the student, for example by presenting them with different cases, probing for relevant factors, asking for predictions, entrapping the student when they have not identified all necessary factors, presenting counterexamples, etc.), implemented in several versions (Collins and Stevens 1991; Lepper et al. 1993) or the analysis of the teacher’s expertise (Lajoie et al. 2001; Heffernan and Koedinger 2002). Schoenfeld (1998) studies the teacher’s behavior without proposing an automatic model but by investigating, for example, the role played by beliefs, knowledge, goals, etc. in school management, teaching practice, adaptation, etc.
5.4 Explainable Recommendations
In e-commerce, recommender systems are mostly designed to act alone. Yet, in e-learning, it would seem very relevant to use a recommender system to team up / collaborate with humans, either teacher or learner, or both. It could serve many objectives. First, regarding learners, a recommender system could be used to both assist them and guide them through the wide range of proposed resources, just as they already do, and improve learner agency. For that purpose, the system should be explainable. In e-commerce, some systems are described as explainable because the reason why the items are suggested is made explicit. For example, on marketplaces, customers can read explanations such as “people who liked this item also liked this one”, “you liked this item, you may be interested in this one”, etc. The main goal is to increase the user’s attention and interest. But, in e-learning, on the student side, the main goals would be to actively engage the students in their learning, provide them with the tools to understand their learning behavior, thus think over it and adapt it, and help them to decide whether they want to follow the recommendations or not. It is about making the learners able to understand and deal with their metacognitive strategies. Indeed, this approach, coupled with the use of learner models coming from educational sciences, could help students to understand their mental mechanisms and act on their motivation, learning strategies, etc.
On the teacher side, the goal would be to increase their understanding of their students’ behavior and improve following-up and monitoring through scoreboards and alerts for example, as well to have control over the models used and the recommendations made, so that they can implement their teaching model. Indeed, there are reasons to believe that teachers should be assisted instead of excluded from the recommendation process (i.e. AI-systems should be used to team up with humans instead of replacing them). First, recent research has demonstrated that enhanced AI-systems accuracy does not always lead to better system performance (Yin et al. 2019; Lai and Tan 2019) because performance is rather closely linked to the quality of the relationship between the human and the AI as a team (i.e. trust, knowledge of the limits and the potentials of the AI, understanding of system operation, etc.). Moreover, as we have mentioned, even though there are techniques to assess system accuracy, the teacher remains the most qualified to evaluate the relevance of a didactic recommendation and its ability to match to their expectations. For example, they can examine precisely whether the system has taken into account the suitable epistemic factors to make the right decision, and whether the recommendation fits their own pedagogical model. Finally, despite teacher shortage (Flynt and Morton 2009; Hutchison 2012; Ingersoll and May 2011; Martino Rezai-Rashti 2010), various arguments emerge for slowing down the excessive automation of education, including the issues about data privacy, lack of control, responsibility, etc. For example, in studying the impact of artificial intelligence on learning, teaching, and education, Tuomi (2018) explains that AI can limit the domain where humans express their agency. They also remind us that there may be fundamental theoretical and practical limits in designing AI systems that can explain their behavior and decisions so that it is important to keep humans in the decision-making loop. Similarly, Selwyn (2019) expresses his mistrusts (e.g. concerns about inaccuracies, misrecognition, and faulty decision-making) with regard to the very fast spread of AI-systems in every sphere of our lives and the strong enthusiasm, insufficiently supported by philosophical questioning, though, for its potentialities.
Finally, on the system side, the aim is to be able to learn, not only automatically but also with the human feedback and settings up, as well as the integration of teaching rules. For example, in the system that we are currently developing with my team, teachers receive information about a given student (i.e., their general profile, their current on-task behavior, the improvements that should be done by the student on the current task, the recommendations provided by the system to the student, and the student’s feedback about the recommendations and their explanation). In this way, the teacher has full information to decide whether the recommendations were appropriate or not and readjust the settings of the recommender system if necessary (Roux et al. 2021).
6 Discussion and Conclusion
In the complex environment in which we live, it appears important to be able to think and question the different objects we have to deal with. Many matters about AI for example (but it is true for other fields as well) cannot be reduced to the technological perspective: they also require philosophical, sociological, economic, anthropological, etc. views since experts may have to put different concepts and reality levels into dialogue. Making recommendations of learning objects for students goes beyond technical issues, thus it is not enough to rely on the methods that work for sales and VOD: such project require knowledge and understanding of pedagogical issues in order to choose the algorithms and models that appear the more relevant for a given pedagogical context and purpose. Moreover, this context and purpose should be well-defined and made clear to users, so that teachers can make informed choice when selecting a recommender system and integrating it in their pedagogical strategy.
Thus, the current questionings about the lack of transparency and fairness of recommender systems dedicated to e-commerce are all the more crucial in education because it deeply affects the individuals’ relationship to the world. Our study show that any existing educational recommender systems encourage overspecialization and the reproduction of the same behavioral patterns, at the expense of openness and diversity. Some of them also result in reducing the individual abilities to seek and compare information, verify the sources, and make their own informed choices. The use of recommender systems can be beneficial for reducing the inequalities in learning, for example, to enable working students to access online courses and help teachers in monitoring; but studies have shown that it also can have harmful effects if their design is only driven by economic imperatives, or the ethical and social consequences are not carefully examined. One of the main problems is that e-learning recommender systems use the same methods (e.g. filtering and assessment methods) as the recommender systems designed for e-commerce, whose main purposes are profits and speed, even if this means deteriorating the forum of public discourse and amplifying patterns of discrimination and disadvantage (Milano et al. 2021).
While using the usual techniques of recommender systems without questioning their implications is a root source of these problems, some solutions, both technical and educational, can be proposed to address it. Designing knowledge-based methods, using learner models based on careful educational and cognitive studies, and providing explained recommendations that enable learners to be actively involved in their training can be part of a solution. Other avenues could be explored, for example investigating the most appropriate items to recommend (e.g., keywords for queries, friends, pedagogical activities) and the way to present them (e.g., top-ranked lists, ordered lists, a spontaneous recommendation for one single item). All of these suggestions raise technical, educational, and social questions that should be the objects of debate and careful examination when designing a recommender system. Finally, and above all, systematic ethical and epistemic questioning should become the guiding principles of any technical research.
References
Adomavicius, G., J. Bockstedt, S.P. Curley, J. Zhang, and S. Ransbotham. 2019. The Hidden Side Effects of Recommendation Systems. MIT Sloan Management Review 60 (2): 1.
Afoudi, Y., M. Lazaar, and M. Al Achhab. 2018. Collaborative Filtering Recommender System. In Proceedings of the International Conference on Advanced Intelligent Systems for Sustainable Development, 332–345. Cairo/Cham: Springer. https://doi.org/10.1007/978-3-030-11928-7_30.
Aggarwal, C.C. 2016. Knowledge-Based Recommender Systems. In Recommender Systems, 167–197. Cham: Springer. https://doi.org/10.1007/978-3-319-29659-3_5.
Amasha, M.A., M.F. Areed, S. Alkhalaf, R.A. Abougalala, S.M. Elatawy, and D. Khairy. 2020. The Future of Using Internet of Things (loTs) and Context-Aware Technology in E-learning. In Proceedings of the 2020 9th International Conference on Educational and Information Technology, 114–123. Oxford: Association for Computing Machinery. https://doi.org/10.1145/3383923.3383970.
Anderson, J.R. 1996. ACT: A Simple Theory of Complex Cognition. American Psychologist 51 (4): 355. https://doi.org/10.1037/0003-066X.51.4.355.
Anderson, J. R., and K. Gluck. 2001. What Role Do Cognitive Architectures Play in Intelligent Tutoring Systems. In Cognition & Instruction: Twenty-Five Years of Progress, ed. Carver, vol. 35, issue 6, 689–704.
Beach, D., and M. Dovemark. 2009. Making ‘right’choices? An ethnographic account of creativity, performativity and personalised learning policy, concepts and practices. Oxford Review of Education 35 (6): 689–704.
Blondeau, O., and F. Latrive. 2020. Libres enfants du savoir numérique. Une anthologie du “Libre”. Paris: l’Éclat.
Bobadilla, J., F.J. Serradilla, and A. Hernando. 2009. Collaborative Filtering Adapted to Recommender Systems of E-Learning. Knowledge-Based Systems 22 (4): 261–265. https://doi.org/10.1016/j.knosys.2009.01.008.
Bouraga, S., I. Jureta, S. Faulkner, and C. Herssens. 2014. Knowledge-Based Recommendation Systems: A Survey. International Journal of Intelligent Information Technologies (IJIIT) 10 (2): 1–19. https://doi.org/10.4018/ijiit.2014040101.
Brighouse, H., and M. McPherson. 2015. The Aims of Higher Education. Chicago: University of Chicago Press.
Burke, R. 2007. Hybrid Web Recommender Systems. In The Adaptive Web, ed. Peter Brusilovsky, Alfred Kobsa, and Wolfgang Nejdl, 377–408. Berlin/Heidelberg: Springer. https://doi.org/10.1007/978-3-540-72079-9.
Collins, A., and A.L. Stevens. 1991. A Cognitive Theory of Inquiry Teaching. In Teaching Knowledge and Intelligent Tutoring, ed. Peter Goodyear, 203–230. Norwood: Ablex Publishing.
Dwivedi, P., and K.K. Bharadwaj. 2013. Effective Trust-Aware E-Learning Recommender System Based on Learning Styles and Knowledge Levels. Journal of Educational Technology & Society 16 (4): 201–216. https://www.jstor.org/stable/jeductechsoci.16.4.201.
Florian, O. 2018. Le rôle attribué par les étudiants aux études: un utilitarisme dominant? Cahiers de la recherche sur l’éducation et les savoirs 17: 239–258. http://journals.openedition.org/cres/3807.
Flynt, S.W., and R.C. Morton. 2009. The Teacher Shortage in America: Pressing concerns. National Forum of Teacher Education Journal 19 (3): 1–5. http://www.nationalforum.com/Electronic%20Journal%20Volumes/Flynt,%20Samuel%20Teacher%20Shortage%20in%20America.pdf.
Fraihat, Salam, and Qusai Shambour. 2015. A Framework of Semantic Recommender System for e-Learning. Journal of Software 10 (3): 317–330. https://doi.org/10.17706/jsw.10.3.317-330.
Fumagalli, A., and S. Lucarelli. 2010. Cognitive Capitalism as a Financial Economy of Production. In Cognitive Capitalism and its Reflections in South-Eastern Europe, ed. Vladimir Cvijanovic, Andrea Fumagalli, and Carlo Vercellone, 9–40. Frankfurt: Peter Lang.
Gallego, D., E. Barra, S. Aguirre, and G. Huecas. 2012. A Model for Generating Proactive Context-Aware Recommendations in e-Learning Systems. In Proceedings of the 2012 Frontiers in Education Conference, 1–6. Seattle: IEEE. https://doi.org/10.1109/FIE18277.2012.
Hallinan, B., and T. Striphas. 2016. Recommended for You: The Netflix Prize and the Production of Algorithmic Culture. New Media & Society 18 (1): 117–137. https://doi.org/10.1177/1461444814538646.
Hayles, N.K. 1999. How We Became Posthuman: Virtual Bodies in Cybernetics, Literature, and Informatics. Chicago: University of Chicago Press.
Heffernan, N.T., and K.R. Koedinger. 2002. An Intelligent Tutoring System Incorporating a Model of an Experienced Human Tutor. In Proceedings of the 6th International Conference “Intelligent Tutoring System”, 596–608. Biarritz: Springer.
Henritius, E., E. Löfström, and M.S. Hannula. 2019. University Students’ Emotions in Virtual Learning: A Review of Empirical Research in the 21st Century. British Journal of Educational Technology 50 (1): 80–100. https://doi.org/10.1111/bjet.12699.
Hernik, J., and E. Jaworska. 2018. The Effect of Enjoyment on Learning. In Proceedings of the INTED2018 Conference, 508–514. Valencia: IATED. https://doi.org/10.21125/inted.2018.
Hutchison, L.F. 2012. Addressing the STEM Teacher Shortage in American Schools: Ways to Recruit and Retain Effective STEM Teachers. Action in Teacher Education 34 (5–6): 541–550. https://doi.org/10.1080/01626620.2012.729483.
Ingersoll, R.M., and H. May. 2011. The Minority Teacher Shortage: Fact or Fable? Phi Delta Kappan 93 (1): 62–65. https://doi.org/10.1177/003172171109300111.
Isinkaye, F.O., Y.O. Folajimi, and B.A. Ojokoh. 2015. Recommendation Systems: Principles, Methods and Evaluation. Egyptian Informatics Journal 16 (3): 261–273. https://doi.org/10.1016/j.eij.2015.06.005.
Jacob, M. 2003. Rethinking Science and Commodifying Knowledge. Policy Futures in Education 1 (1): 125–142. https://doi.org/10.2304/pfie.2003.1.1.3.
Kahn, S. (2017). Pédagogie différenciée: Guide pédagogique. De Boeck (Pédagogie et Formation).
Khribi, M.K., M. Jemni, and O. Nasraoui. 2008. Automatic Recommendations for E-Learning Personalization Based on Web Usage Mining Techniques and Information Retrieval. In Proceedings of the 2008 Eighth IEEE International Conference on Advanced Learning Technologies, 241–245. Santander: IEEE Computer Society. https://doi.org/10.1109/ICALT.2008.198.
Kirschner, P.A. 2017. Stop Propagating the Learning Styles Myth. Computers & Education 106: 166–171.
Lai, V., and C. Tan. 2019. On Human Predictions with Explanations and Predictions of Machine Learning Models: A Case Study on Deception Detection. In Proceedings of the Conference on Fairness, Accountability, and Transparency, 29–38. New York: Association for Computing Machinery. https://doi.org/10.1145/3287560.3287590.
Lajoie, S.P., J. Wiseman, and S. Faremo. 2001. Identifying Human Tutoring Strategies for Effective Instruction in Internal Medicine. International Journal of Artificial Intelligence in Education: 293–309. http://users.sussex.ac.uk/~bend/its2000/lajoie.pdf.
Lauer, D. 2021. You Cannot Have AI Ethics Without Ethics. AI and Ethics 1 (1): 21–25. https://doi.org/10.1007/s43681-020-00013-4.
Lepper, M.R., M. Woolverton, D.L. Mumme, and J. Gurtner. 1993. Motivational Techniques of Expert Human Tutors: Lessons for the Design of Computer-based Tutors. In Computers as Cognitive Tools, ed. Susanne P. Lajoie and Sharon J. Derry, 75–105. Mahwah: Lawrence Erlbaum Associates.
Li, L., Z. Yang, L. Liu, and M. Kitsuregawa. 2008. Query-URL Bipartite Based Approach to Personalized Query Recommendation. In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence, 1189–1194. Chicago: AAAI Press. https://www.aaai.org/Papers/AAAI/2008/AAAI08-188.pdf.
Lika, B., K. Kolomvatsos, and S. Hadjiefthymiades. 2014. Facing the Cold Start Problem in Recommender Systems. Expert Systems with Applications 41 (4): 2065–2073. https://doi.org/10.1016/j.eswa.2013.09.005.
Mahony, P., & I. Hextall. 2009. Building schools for the future and the implications for becoming a teacher. Paper presented at the European Conference on Educational Research, Vienna, 28–30 September.
Manouselis, N., H. Drachsler, K. Verbert, and E. Duval. 2012. Recommender Systems for Learning. New York: Springer.
Martino, W., and G.M. Rezai-Rashti. 2010. Male Teacher Shortage: Black Teachers’ Perspectives. Gender & Education 22 (3): 247–262. https://doi.org/10.1080/09540250903474582.
Mbipom, B., S. Massie, and S. Craw. 2018. An E-learning Recommender that Helps Learners Find the Right Materials. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, vol. 32, issue 1. Palo Alto: AAAI Press. https://doi.org/10.1609/aaai.v32i1.11389.
Milano, S., B. Mittelstadt, S. Wachter, and C. Russell. 2021. “Epistemic Fragmentation Poses a Threat to the Governance of Online Targeting.” Nature Machine Intelligence 3 (6): 466–472. https://doi.org/https://doi.org/10.1038/s42256-021-00358-3.
Mills, M., S. Monk, A. Keddie, P. Renshaw, P. Christie, D. Geelan, and C. Gowlett. 2014. Differentiated Learning: From Policy to Classroom. Oxford Review of Education 40 (3): 331–348.
Moore, P., Z. Zhao, and H. van Pham. 2019. Towards Cloud-Based Personalised Student-Centric Context-Aware e-Learning Pedagogic Systems. In Proceedings of the 13th Conference on Complex, Intelligent, and Software Intensive Systems, 331–342. Cham: Springer. https://doi.org/10.1007/978-3-030-22354-0_30.
Needham, C. 2011. Personalization: From Story-Line to Practice. Social Policy and Administration 45 (1): 54–68.
Overland, I., and B.K. Sovacool. 2020. The Misallocation of Climate Research Funding. Energy Research & Social Science 62: 101349.
Pariser, E. 2011. The Filter Bubble: What the Internet is Hiding from you. London: Penguin UK.
Pazzani, M.J., and D. Billsus. 2007. Content-Based Recommendation Systems. In The Adaptive Web, ed. Peter Brusilovsky, Alfred Kobsa, and Wolfgang Nejdl, 325–341. Berlin: Springer. https://doi.org/10.1007/978-3-540-72079-9_10.
Pekrun, R., A.J. Elliot, and M.A. Maier. 2009. Achievement Goals and Achievement Emotions: Testing a Model of their Joint Relations with Academic Performance. Journal of Educational Psychology 101 (1): 115–135. https://doi.org/10.1037/a0013383.
Pekrun, R., T. Goetz, A.C. Frenzeld, P. Barchfeld, and R.P. Perrye. 2011. Measuring Emotions in Students’ Learning and Performance: The Achievement Emotions Questionnaire (AEQ). Contemporary Educational Psychology 36 (1): 36–48. https://doi.org/10.1016/j.cedpsych.2010.10.002.
Pykett, J. 2010. Personalised governing through behaviour change and re-education. PSA Conference Paper, Edinburgh.
Rafaeli, S., Y. Dan-Gur, and M. Barak. 2005. Social Recommender Systems: Recommendations in Support of e-learning. International Journal of Distance Education Technologies (IJDET) 3 (2): 30–47. https://doi.org/10.4018/jdet.2005040103.
Rohrer, D., and H. Pashler. 2012. Learning Styles: Where’s the Evidence? Online Submission 46 (7): 634–635.
Roux, L, P. Dagorret, T. Etcheverry, T. Nodenot, C. Marquesuzaa, and P. Lopisteguy. 2021. A Multi-Layer Architecture for an E-Learning Hybrid Recommender System. Paper presented at the 18th International Conference on Cognition and Exploratory Learning in Digital Age. IADIS Press.
Salehi, M. 2013. Application of Implicit and Explicit Attribute Based Collaborative Filtering and BIDE for Learning Resource Recommendation. Data & Knowledge Engineering 87: 130–145. https://doi.org/10.1016/j.datak.2013.07.001.
Salehi, M., and I.N. Kmalabadi. 2012. A Hybrid Attribute–Based Recommender System for E–learning Material Recommendation. IERI Procedia 2: 565–570. https://doi.org/10.1016/j.ieri.2012.06.135.
Schafer, J.B., D. Frankowski, J. Herlocker, and Shilad Sen. 2007. Collaborative Filtering Recommender Systems. In The Adaptive Web, ed. Peter Brusilovsky, Alfred Kobsa, and Wolfgang Nejdl, 291–324. Berlin: Springer. https://doi.org/10.1007/978-3-540-72079-9_9.
Schoenfeld, A.H. 1998. Towards a theory of teaching-in-context. Issues in Education 4 (1): 1–94. https://doi.org/10.1016/S1080-9724(99)80076-7.
Segal, A., Z. Katzir, Y. Gal, G. Shani, and B. Shapira. 2014. Edurank: A Collaborative Filtering Approach to Personalization in E-Learning. In Proceedings of the Seventh International Conference on Educational Data Mining, 68–75. London: International Educational Data Mining Society.
Selwyn, N. 2019. Should Robots Replace Teachers?: AI and the Future of Education. Cambridge: Polity Press.
Sevarac, Z., V. Devedzic, and J. Jovanovic. 2012. Adaptive Neuro-fuzzy Pedagogical Recommender. Expert Systems with Applications 39 (10): 9797–9806. https://doi.org/10.1016/j.eswa.2012.02.174.
Shi, D., T. Wanga, H. Xinga, and H. Xu. 2020. A Learning Path Recommendation Model Based on a Multidimensional Knowledge Graph Framework for E-Learning. Knowledge-Based Systems 195: 105618. https://doi.org/10.1016/j.knosys.2020.105618.
Shu, J., X. Shen, H. Liu, B. Yi, and Z. Zhang. 2018. A Content-Based Recommendation Algorithm for Learning Resources. Multimedia Systems 24 (2): 163–173. https://doi.org/10.1007/s00530-017-0539-8.
Skinner, B.F. 1974. About Behaviorism. New York: Random House.
Tuomi, I. 2018. The Impact of Artificial Intelligence on Learning, Teaching, and Education. Luxembourg: Publications Office of the European Union.
Van Meteren, R., and M. van Someren. 2000. Using Content-Based Filtering for Recommendation. In Proceedings of the Machine Learning in the New Information Age MLnet/ECML2000 Workshop, 47–56.
Wu, D., J. Lu, and G. Zhang. 2015. A Fuzzy Tree Matching-Based Personalized E-Learning Recommender System. IEEE Transactions Fuzzy Systems 23 (6): 2412–2426. https://doi.org/10.1109/TFUZZ.2015.2426201.
Ye, M., Z. Tang, J. Xu, and L. Jin. 2015. Recommender System for E-Learning Based on Semantic Relatedness of Concepts. Information 6 (3): 443–453. https://doi.org/10.3390/info6030443.
Yin, M., J. Wortman Vaughan, and H. Wallach. 2019. Under-Standing the Effect of Accuracy on Trust in Machine Learning Models. In Proceedings of the 2019 chi Conference on Human Factors in Computing Systems, 1–12. Glasgow: Association for Computing Machinery.
Zaiane, O.R. 2002. Building a Recommender Agent for E-Learning Systems. In International Conference on Computers in Education, 55–59. Washington, D.C.: IEEE Computer Society. https://doi.org/10.1109/CIE.2002.
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this chapter

Cite this chapter
Roux, L., Nodenot, T. (2023). Ethics of E-Learning Recommender Systems: Epistemic Positioning and Ideological Orientation. In: Genovesi, S., Kaesling, K., Robbins, S. (eds) Recommender Systems: Legal and Ethical Issues. The International Library of Ethics, Law and Technology, vol 40. Springer, Cham. https://doi.org/10.1007/978-3-031-34804-4_11
Download citation
DOI: https://doi.org/10.1007/978-3-031-34804-4_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-34803-7
Online ISBN: 978-3-031-34804-4
eBook Packages: Religion and PhilosophyPhilosophy and Religion (R0)