
Abstract
With the advent of digitalisation and big data sources, new advanced tools are needed to precisely project safety-critical system outcomes. Existing systems safety analysis methods, such as fault tree analysis (FTA), lack systematic and structured approaches to specifically account for system event consequences. Consequently, we proposed an algorithmic extension of FTA for the purposes of: (a) analysis of the severity of consequences of both top and intermediate events as part of a fault tree (FT) and (b) risk assessment at both the event and cut set level. The ultimate objective of the algorithm is to provide a fine-grained analysis of FT event and cut set risks as a basis for precise and cost-effective safety control measure prescription by practitioners.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
6.1 Motivation
“Digitalisation” in contemporary industrial processes and workplaces has been defined as access to “big data”, artificial intelligence (AI) tools/machine learning (ML), and algorithmic methods for the purposes of operation and management of safety-critical systems [5]. In this definition, algorithmic method is a reference to “algorithmic management”, or the use of new technological tools for remote workforce organisation and tasking. Such methods have been identified as a developing practice also having the potential to create new “hazards” in complex human-automated systems [5]. As such, algorithmic methods, and the broader technology of AI, imply a need for advances in systems safety practice and, specifically, methods for (near) real-time and highly accurate assessments of risks associated with digital process hazards.
In some industrial domains, such as continuous flow manufacturing and petrochemical processing, there has emerged an abundance of digital technologies, including low-cost data sensors and new real-time signal processing devices. The flow of data in these domains has driven the need for development of new AI tools, such as deep-learning neural networks, for real-time system state classification and prescription of control actions, based on large numbers of process measures. One concern that has emerged based on this big data and availability of new computational analytical tools is how management and systems safety practices may be affected. For example, how do we ensure that data streams do not reflect spurious phenomenon and the output of AI algorithms is accurate and valid as a basis for safe operational decision-making.
Having posed this concern, it should be observed that the emergence of big data in some existing industrial applications may not extend to new highly automated processes involving human–autonomy teaming scenarios, as in algorithmic management approaches. That is, there may be an absence of empirical observation of novel work systems and, consequently, sparse data relative to the number of decision variables that must be considered in risk assessment and safety practice. In data analytics, this problem is referred as the “curse of dimensionality”, where available process data records are sparse compared with the number of attributes being measured. The curse of dimensionality poses fundamental issues of sensitivity and reliability of any data analytics or statistical analysis. Thus, in some truly unique algorithmic management applications, there may also be a need to identify alternative AI or advanced analytical methods by which to generate field-relevant data/estimates as a basis for application of modeling and decision analysis tools.
It is anticipated that new computational capabilities and AI algorithms may also provide a platform for more computationally sophisticated (real-time) safety analysis methods. For example, more demanding modeling approaches, including high dimensional structures, can be processed by new AI supercomputers in a matter of milliseconds. However, such data-driven computational safety analysis methods may lack the scientific basis and systematic nature of traditional systems safety analysis (SSA) methods. For example, results of ML methods tend to be unique to a specific system, rather than generalisable across application domains. On the other hand, existing traditional SSA methods may not be able to accommodate big data sources. For example, traditional fault tree analysis (FTA) methods do not account for potential event consequences, which can be estimated based on big (process) data.
In general, there is a need for enhanced risk assessment methods to ensure that new management approaches and safety controls, as part of digital industrial processes, are compatible and jointly effective. The specific research question we seek to address is whether new advanced tools can be created for precise projections of safety-critical system outcomes, given high-dimensional decision spaces? Such spaces are characterised by sources of harm in a work system leading to numerous safety-related events (or mechanisms) to negative outcomes. Ultimately, we also need to investigate how such technologies can be exploited to better support work performance and safety.
6.2 Background
A fundamental challenge for safety science has been to determine how to minimise hazard exposure without compromising work productivity. Unfortunately, traditional SSA methods for mitigating exposure have trailed behind industry applications, not even considering the various forms of digitalisation identified by Le Coze and Antonsen [5]. In the early 1980s, the Air Force developed a collection of formal SSA methods as part of MIL-STD-882 [8]. These methods primarily focused on the frequency of hazard exposure vs. severity of outcomes or degree of loss. It took another 14 years for NIOSH (National Institute for Occupational Safety and Health) to develop a guide to further disseminate these methods [2]. Unfortunately, there have been limited advances in formal SSA methods since that time.
The persistence of workplace deaths and injuries underscores the need for enhancement of existing SSA methods to better support industry in precision loss assessment and control when applying digital technologies and process management. This research need is further motivated by economics. The Liberty Mutual (LM) 2019 Worker’s Compensation Claims (WCC) Index revealed $46.93 B per year in losses for US industry from the top-10 most disabling worker injuries. The insurance carrier estimated industry costs at over $1 B per week [6]. This level of loss is unacceptable with respect to industry financial stability and US global competitiveness. Comprehensive and valid safety critical engineering methods represent one potential solution to reducing total incident rates (TIRs) in industry.
6.3 Objective
We present a new algorithm for advancing an existing SSA technique, specifically fault tree analysis (FTA), by integrating consideration of the severity of consequences of safety-critical system events for design and operational risk assessment. Such considerations can now be made based on big data sources in digital process scenarios. As the reader may be aware, traditional FTA only accounts for the likelihood of occurrence of system fault states but not the probability of various degrees of system or operational loss, given the occurrence of a fault [2]. Although FTA has realised substantial application in government/military and industrial applications since its conception, the method has always represented an incomplete risk assessment approach. Furthermore, it requires substantial analyst time and effort, even when addressing a single fault event. Another limitation of FTA is that the method considers only the outcome of an identified undesirable and credible (“top”) fault event for which an analyst must have prior knowledge. There is no analysis of potential negative outcomes of predecessor (intermediate) events to the top event that are causal in nature. Consequently, any FTA provides an incomplete picture of the total level of system risk posed by a top event, intermediate events and basic sources of harm in a work environment.
The way that these FTA shortcomings have been addressed is by an analyst applying other safety analysis techniques, including but not limited to FMEA (Failure Modes and Effects Analysis (FMEA), Event-tree Analysis (ETA), Probabilistic Risk Assessment (PRA), Cause-consequence Analysis (CCA), etc., in conjunction with FTA [3]. Most of these additional methods make use of FTA outputs to facilitate evaluation of the severity of specific system faults. The common FTA outputs include identification of a minimum set of basic initiators and intermediate events guaranteeing occurrence of the top event [i.e., minimal cut sets (MCSs)] or the exact probability of a top event. Related to this, we only found one study in the literature that addressed severity of hazard exposure in application of FTA. Lindhe et al. [7] presented a dynamic fault tree (FT) with hazard risk determined by means of Monte Carlo simulation [7]. However, any intermediate events in the FT were not identified as having unique outcomes relative to the top event.
In summary, with the advent of digitalisation and big data sources, it may now be possible to predict system event consequences and probabilities for more accurate risk assessment methods. However, there remains an absence of systematic and structured approaches to account for this information as part of FTA. This methodological situation limits the accuracy of SSA as a basis for risk assessment and supporting system design, which should be particularly critical for highly automated and high-risk work environments.
6.4 Review of Traditional FTA
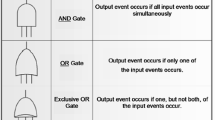
In the traditional FTA approach, we initially construct a FT diagram (see Fig. 6.1) and identify relationships among all process events deduced to contribute to the top event (fault state). Logic (AND/OR) gates are used to create connections between the events (see Fig. 6.2).

Example FT. Note Tree has five layers with eight basic events/initiators (\(B_{i}\)), six intermediate events (\(E_{i}\)), and one top event (\(ET\)). An example AND gate integrates inputs from E1 · B4 · E3; an example OR gate integrates inputs from E2 + B3

Each intermediate event in a FT may represent a top event in another FT. For each intermediate event, we specify a set of negative outcomes and levels of associated severity as bases for the CSPIM analysis
We subsequently assign probability values to the occurrence of basic sources of harm in the environment (or initiators). Typically, an analyst makes use of a historical database or safety records for probability data. In the case of novel human–autonomy teaming applications, such data may not be available and, consequently, expert judgements and advanced analytical methods may be necessary to generate probability estimates for analysis (we say more on this below). In traditional FTA, we calculate the probability of the top event and intermediate events, based on initiator probabilities \(\left( {P\left( {B_{i} } \right)} \right)\), and use of Boolean algebra.
The value of the event probabilities is a sufficient basis for calculating the importance of initiating events and cuts sets (minimum combinations of events causing the top event). It is necessary to make use of a method to obtain cut sets (MOCUS) or Boolean equivalent tree construction to identify the MCSs for a FT (but event probabilities are not necessary). For the example tree in Fig. 6.1, we determined three MCSs, including: {\(B_{3}\), \(B_{4}\)}, {\(B_{1}\), \(B_{2}\), \(B_{4}\), \(B_{5}\)} and {\(B_{1}\), \(B_{2}\), \(B_{4}\), \(B_{6}\), \(B_{7}\), \(B_{8}\)}. These are guaranteed pathways to the top event or system fault state and represent decision alternatives/priorities for a safety engineer. In traditional FTA, MCSs represent areas of greatest system vulnerability and the most likely targets for safety countermeasures.
For each of the MCSs, we determine a probability of occurrence as well as an importance value and ranking of the cut sets. Traditional FTA limits MCS importance to the impact on the top event probability of occurrence. The probability of a cut set can be calculated as the product of the probabilities of embedded initiators (\(P_{k} { } = \prod\nolimits_{B = 1}^{m} {P_{{\text{B}}} } { }\)), where \(P_{k} { }\) is the \(k\) th cut set probability and \(\prod\nolimits_{B = 1}^{m} {P_{{\text{B}}} }\) represents the product of the probabilities of \(m\) initiators in \(k\) th MCS. The importance is the ratio of the MCS probability to top event likelihood: \(I_{k} = \frac{{P_{k} }}{{P_{{\text{T}}} }}\), where \(P_{{\text{T}}}\) is the estimated probability of the top event (based on data or expert judgment) and \(I_{k}\) is the \(k\) th cut importance value.
On the basis of this analysis, cut sets can be ranked in terms of importance and the ranking can be used as a basis for safety resource allocation. The MCS with the greatest importance ratio is the most likely set of initiators to cause the top event. An analyst might recommend changing the system structure (or FT event relationships) to increase the number of initiators in the top-rank MCS and reduce the probability of its occurrence. An analyst might also recommend changing system components, materials or procedures to reduce the likelihood of initiators as part of the top-rank MCS.
These traditional FTA outcomes are all fine and good but, as we noted in the literature review, the method does not capture the contributions of initiators to the severity of consequences of the intermediate and top events, nor does it support event risk assessment; i.e., \(R_{i} = P\left( {E_{i} } \right) \cdot S\), where \(R_{i}\) is the hazard risk for event \(E_{i}\) and \(S\) is the severity of outcome of exposure. However, this kind of information is very important in most safety analyses as those initiators primarily contributing to the occurrence of an event may not be one in the same with those factors contributing to the degree of loss, given the occurrence of the event.
6.5 A Consequence Severity-Probability Importance Measure Algorithm for FTA
On the basis of the literature and review of traditional FTA, we propose an algorithmic extension of FTA with the purposes of: (a) analysis of the severity of consequences of both top and intermediate events as part of a FT and (b) risk assessment at both the event and cut set level. The ultimate objective of the algorithm is to provide a fine-grained analysis of FT event and cut set risk as a basis for precise and cost-effective safety control measure prescription by practitioners. Here, it is important to note that we elect to extend the existing FTA method due to its scientific basis and systematic approach to generating results for specific system fault states that may generalise to other domains. These features are desirable relative to a ML/neural network approaches that can only reveal combinations of initiators guaranteeing a system fault but do not identify various event pathways to the fault.
The CSPIM algorithm begins just like traditional FTA, including constructing a FT diagram and assigning probability values to initiators. The FT identifies relationships among the top event and hardware failures, environmental factors, system command faults, etc. For initiator probabilities, we make use of any available system performance data, observations on legacy systems, benchmarking of competing technologies, or expert estimates. In the latter case, estimates are used to address the curse of dimensionality that can occur in FTA, specifically the number of pathways to a top event may exceed the data available for estimating the likelihood of events in a pathway. Consequently, there is a need for estimates and advanced analytical approaches to facilitate accurate decision making on safety controls. Lavasani et al. [4] showed how a fuzzy estimation approach can be applied to judgements of event possibilities by a group of experts. Linguistic terms (of probability) are translated to predetermined intervals of possibility values using fuzzy sets. Possibility estimates are aggregated across experts with mean values being defuzzified to crisp possibility scores. These scores are mathematically transformed to initiator probability values. Here, it is important to note that experts are typically senior systems operators, who are initially interviewed individually for event likelihood estimates. This step is followed by expert group review and discussion on likelihoods in which some individual estimates may be adjusted. Lastly, all estimates are transformed to probability scores, and aggregate values are calculated. This process is most applicable to unique work systems with limited data for safety decision analyses.
At this stage, CSPIM departs from traditional FTA. We identify consequences associated with each event (intermediate and top) and qualitatively categorise consequences according to levels of severity (\(S\)). (See Fig. 6.2 for a conceptual representation of this step, as an extension of traditional FTA.) For this purpose, we use the Hazard Severity Category (HSC) scheme provided in MIL-STD-882E (1984; \(S_{1}\) = “catastrophic”; \(S_{2}\) = “critical”, \(S_{3}\) = “marginal”; \(S_{4}\) = “negligible”). An analyst may also use other severity ranking scales appropriate to the specific industry or develop a custom scale based on prior company safety experience/accidents. The consequences of \(ET\) and \(E_{i}\) may occur at many different levels of severity (\(S_{c}\)). Therefore, it is necessary to assign a set of conditional probabilities for levels of severity of outcome for each intermediate event (\(P\left( {S_{1} |E_{j} } \right);P\left( {S_{2} |E_{j} } \right);P\left( {S_{3} |E_{j} } \right);P\left( {S_{4} |E_{j} } \right)\)) as well as the top event, producing a matrix of severity probabilities for the FT. Ordinarily, these data would also be based on prior system experience but expert judgements can be used as well for novel applications.
As with traditional FTA, the CSPIM algorithm requires that we use initiator probabilities and Boolean algebra to calculate the top event and intermediate event probabilities. These values are then used as bases for calculating and assessing composite event risk values. We calculate the product of the probability of the fault event, the probability of a specific severity of consequence (assuming fault occurrence) and the severity level, written as: \(R_{{j{\text{c}}}} = P\left( {E_{j} } \right) \cdot P\left( {S_{{\text{c}}} |E_{j} } \right) \cdot S_{{\text{c}}}\), where \(c\) is the level of consequence severity. As all the variables in this equation should actually appear in a risk matrix for all FT events and all consequence severity levels, the equation should be rewritten using matrix notation as: \({\varvec{R}}_{{\varvec{E}}} = {\varvec{P}}\left( {\varvec{E}} \right) \cdot {\varvec{P}}\left( {{\varvec{S}}|{\varvec{E}}} \right) \cdot {\varvec{S}}\).
The composite risk value of events are compared with an established (or custom) Hazard Risk Index (HRI), such as that from MIL-STD-882E. This index facilitates classification of risk outcomes in terms of hazard exposure and severity of outcomes and identifies HRI levels. Using the risk assessment matrix, an analyst codes the composite risk values as representing “low”, “medium”, “serious” and “high” exposures. The MIL-STD index also provides for general safety control actions based on HRI levels.
At this stage, the analyst is looking for any events that represent serious or high-level risks. According to the MIL-STD, high risks are “unacceptable” and serious risks are “undesirable”, which means response countermeasures should be taken as soon as possible to mitigate the probability or severity of a specific outcome.
As with the traditional FTA method, we use MOCUS or Boolean equivalent tree construction, as part of the CSPIM algorithm, to identify the MCSs for the FT. It is also necessary for an analyst to identify any and all intermediate events triggered by initiators as part of different MCSs. In Fig. 6.3, we have marked in “red” the {\(B_{3}\), \(B_{4}\)} MCS as well as the intermediate events triggered by this cut set. This step should also be applied to the other two identified MCSs. (It should be noted that this diagram does not represent a complete visualisation of the new CSPIM outcomes, as modelled in Fig. 6.2. A full CSPIM visualisation includes presentation of all negative consequences for each intermediate, and the top event, along with the severity of outcome indicators and probabilities for each consequence.)

Minimal cut set {\(B_{3}\), \(B_{4}\)} and triggered events (in “red”) according to CSPIM method
Subsequently, we make a major departure from traditional FTA by determining a composite probability for each MCS, which includes the likelihoods for triggered intermediate and top events. (Here it should be noted that intermediate event probabilities account for the MCS initiator probabilities.) Related to this, the intermediate event probabilities will vary among cut sets depending on the different initiators included in the cut set and activated pathways to the intermediate event. Therefore, it is not appropriate to directly transfer the \(P\left( {E_{j} } \right)\) value from one cut set to another. We define \(P\left( {E_{kj} } \right)\) to represent the probability of \(E_{j}\) in the \(k\)th cut set. The composite probability value accounting for all events associated with the cut set that can lead to negative consequences is then defined as \({\varvec{P}}\left( {{\varvec{E}}_{k} } \right)\) for all j.
We then move on to calculation of the composite risk associated with the MCS. This step requires risk values for all intermediate and top events for the cut set at each level of severity of outcome, given as \(R_{{kj{\text{c}}}} = P\left( {E_{kj} } \right) \cdot P\left( {S_{{\text{c}}} |E_{kj} } \right) \cdot S_{{\text{c}}}\). For each specific level of severity (\(c\)), the composite risk of event \(E_{j}\) in the \(k\)th cut set is noted as \({\varvec{R}}_{kj}\). We can then obtain the total composite risk for the \(k\)th cut set at a given severity level as: \({\varvec{R}}_{{\varvec{k}}} = \sum\nolimits_{j = 1}^{{m_{k} }} {{\varvec{R}}_{{{\varvec{kj}}}} }\), where \(m_{k}\) is the number of events (intermediate and top) associated with \(k\)th cut set. These risk values are then used to determine and rank importance ratios for all MCSs.
The importance of each MCS will vary for different outcome severity levels; consequently, all of these values need to be calculated separately. We define the importance of the \(k\)th MCS at the \(c\)th severity level as the ratio of the composite risk value for the cut set to the total composite risk value for the given system with negative outcomes caused by all triggered events occurring at the \(c\)th severity level: \(I_{{k{\text{c}}}} = \frac{{R_{{k{\text{c}}}} }}{{R_{{\text{c}}} }}\), where \(R_{{\text{c}}}\) is the composite risk level for the system across all cut sets for the severity level \(c\) and \(I_{{k{\text{c}}}}\) is the importance of \(k\)th cut set at the \(c\)th severity level. On the basis of this analysis, cut sets can be ranked in terms of importance (as in traditional FTA) and the ranking can be used for safety resource allocation.
Following an almost identical methodology, an analyst can calculate and evaluate the importance of each initiator in an MCS. This additional analysis is used to identify primary risk factors contributing to negative system outcomes and to further refine risk mitigation strategies and target control measures.
As with the event risk analysis, the DoD HRI can be applied to the calculated cut set and initiator risk values. The values are classified as low, medium, serious and high risks, revealing initiators that should be a focal point for control measures to reduce the probability of occurrence or severity of associated event outcomes.
6.6 Conclusions
The contributions of this work include identification of the need for enhanced SSA methods for comprehensive risk analysis in digital industry processes, and a step-by-step algorithm extending traditional FTA. This new method can exercise big data and/or process estimates to account for both the likelihood of hazard exposure and severity of event outcomes and preserves the scientific and systematic nature of the original FTA method. The CSPIM algorithm involves determining risks for all basic, intermediate and top events in a FT based on additional data sources from new AI methods and/or expert judgements and advanced analytical techniques. Implicitly, the algorithm addresses all consequences of intermediate and top events and leads to an overall system risk assessment. The CSPIM algorithm generates new FTA outputs that are sensitive to the severity of event outcomes and allows for prioritisation of fault events for safety controls on the basis of potential risk. These capabilities are currently absent from traditional FTA and substantially enhance the method for new digital industry applications.
Such enhanced SSA methods facilitate higher resolution/precision risk assessment and control formulation maximising industry effectiveness in use of safety resources. At the same time, the CSPIM approach can minimise misallocation of design and administrative measures for safety-critical systems. Consequently, our response to the specific research question identified in the Motivation Section is that it is possible to create new advanced tools for comprehensive safety-critical systems analysis that can accommodate/exploit additional “big” data on event consequences and likelihoods by starting from existing formal SSA techniques.
Although there are advantages to the CSPIM algorithm, the approach is mathematically complex and computationally intensive. In this work, we have only considered application to a small FT; however, in actual industrial applications, such as offshore oil rig design, a FT may literally have thousands of intermediate events included in pathways to an undesired top event of platform failure. In this case, the risk calculations as part of the CSPIM algorithm could be extremely large and complex. Related to this, the recent advances in computational technologies and AI methods may support application of such analysis of high-dimensional system structures, even in the presence of sparse historical data for event probability assignment. As described, expert subjective judgements can be used to generate valuable estimates to support application of such methods when faced with the curse of dimensionality. As noted earlier, in real-world FTA applications, the number of decision variables, or pathways to a top event, can exceed the data available for estimating the frequency of occurrence of specific initiators or intermediate events comprising pathways as well as the data for estimates of event consequences and likelihoods of consequences. New advanced analytical and AI-based methods can be used to generate additional field-relevant data to limit the impact of the curse of dimensionality of safety risk analysis and mitigation strategy decisions.
In general, more SSA tools like the CSPIM algorithm need to be created to support safety engineers in dealing with the broad challenges of digitalisation and algorithmic management in industry, which Le Coze and Antonsen [5] have identified. This represents a challenge for the safety science community, which may be addressed through new computational systems and AI tools that are currently being developed by computer scientists for big data analysis. For example, new AI-based sensing methods may be effective for generating field-relevant data for analysis with advanced risk assessment methods. In addition, new AI-based simulation methods make possible the development of “digital-twins” for highly realistic models of actual systems and processes that support testing of safety controls in advance of actual implementation. These are new digitalisation trends that will have a major impact on the future application of systems safety analysis methods.
References
BLS, in National Census of Fatal Occupational Injuries in 2019 (News Release 12/16/20; BLS, Washington, D.C., 2020)
P. Clemens, R. Simmons, Systems Safety and Risk Management: A Guide for Engineering Educators (NIOSH Instruction Manual; US Department of Health and Human Services, Cincinnati, OH, 1998)
F. Khan, S. Rathnayaka, S. Ahmed, Methods and models in process safety and risk management: past, present and future. Process Saf. Environ. Prot. 98, 116–147 (2015)
S.M. Lavasani, N. Ramzali, F. Sabzalipour, E. Akyuz, Utilisation of fuzzy fault tree analysis (FFTA) for quantified risk analysis of leakage in abandoned oil and natural-gas wells. Ocean Eng. 108, 729–737 (2015)
J.-C. Le Coze, S. Antonsen, Algorithms, machine learning, big data and artificial intelligence, in Safety in a Digital Age: Old and New Problems, eds. by J.-C. Le Coze, S. Antonsen (Springer, 2023)
Liberty Mutual, in Workplace Safety Index Reveals Workplace Injuries Cost US Companies Over $1 billion per week (Press release: Avail. Online 8/19/21; Liberty Mutual, Hopkinton, MA, 2019)
A. Lindhe, L. Rosén, T. Norberg, O. Bergstedt, Fault tree analysis for integrated and probabilistic risk analysis of drinking water systems. Water Res. 43(6), 1641–1653 (2009)
MIL-STD-882B, in System Safety Program Requirements (Technical report) (Department of Defense, Washington, DC, 1984)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this chapter

Cite this chapter
Kaber, D.B., Liu, Y., Lau, M. (2023). Considering Severity of Safety-Critical System Outcomes in Risk Analysis: An Extension of Fault Tree Analysis. In: Le Coze, JC., Antonsen, S. (eds) Safety in the Digital Age. SpringerBriefs in Applied Sciences and Technology(). Springer, Cham. https://doi.org/10.1007/978-3-031-32633-2_6
Download citation
DOI: https://doi.org/10.1007/978-3-031-32633-2_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-32632-5
Online ISBN: 978-3-031-32633-2
eBook Packages: EngineeringEngineering (R0)