
Abstract
Generative models have been very successful over the years and have received significant attention for synthetic data generation. As deep learning models are getting more and more complex, they require large amounts of data to perform accurately. In medical image analysis, such generative models play a crucial role as the available data is limited due to challenges related to data privacy, lack of data diversity, or uneven data distributions. In this paper, we present a method to generate brain tumor MRI images using generative adversarial networks. We have utilized StyleGAN2 with ADA methodology to generate high-quality brain MRI with tumors while using a significantly smaller amount of training data when compared to the existing approaches. We use three pre-trained models for transfer learning. Results demonstrate that the proposed method can learn the distributions of brain tumors. Furthermore, the model can generate high-quality synthetic brain MRI with a tumor that can limit the small sample size issues. The approach can addresses the limited data availability by generating realistic-looking brain MRI with tumors. The code is available at: https://github.com/rizwanqureshi123/Brain-Tumor-Synthetic-Data.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Due to the advancements in computational power and a large amount of high-quality datasets, deep learning has become the state-of-the-art technology in computer vision, natural language processing, and others [1]. Deep learning has also made remarkable progress in all areas of medical image analysis, including segmentation, detection, and classification [1]. However, deep learning models are trained on large datasets, which may not be available in the medical domain due to privacy and ethical concerns [2]. Medical experts find it difficult to publicize the majority of medical images without patients’ consent. In addition, the public datasets are also small and lack expert annotations, thus, hindering their use for training deep neural networks. Furthermore, most of the available datasets might contain unbalanced classes that may hinder the performance of deep learning models and may not produce critical biological insights.
To overcome the problem of data unavailability, many researchers use generative models [3] to generate realistic synthetic images with diverse distributions for training complex deep learning models for medical analysis. Generative Adversarial Networks (GAN), a type of neural network, comprises two neural networks, one of which focuses on image production and the other on discrimination. The training of GAN involves a contest between the generator G and the discriminator D. The discriminator D is a binary classifier that determines if the data generated by G belongs to the training set or not (real versus unreal). GANs can be used to create synthetic medical images, image captioning, and cross-modality image generation [4, 5]. Due to the adversarial training scheme’s success in creating new image samples and utility in preventing domain shift, GANs have drawn great interest from the research community. However, a GAN with insufficient training data leads to over-fitting the discriminator. The feedback to the generator becomes meaningless, and the training starts to diverge [6]. A common approach to overcome over-fitting is data augmentation. For instance, training an image classifier by including images with rotation, noise, or scaling may increase the classifier’s invariance to certain semantics-preserving distortions, which is a very desired quality. On the other hand, a GAN trained with comparable dataset augmentations learns to produce the augmented distribution [7].
Medical image analysis tasks such as brain tumor diagnosis [8] are critical where one would wish for minimum error from a computer model. Brain tumor refers to excessive growth of cells in regions of the brain. An early diagnosis of a brain tumor increases the effectiveness of the treatment and hence, the survival rates. Early diagnosis of a brain tumor is necessary in order to treat it properly; otherwise, it might cause severe damage to the brain that can eventually be fatal. Magnetic Resonance Imaging (MRI) is the most popular way to generate brain scans and detect tumors in different regions of the brain. Many deep learning models [9] have been introduced recently to detect tumors in brain MRIs. However, progress is generally hindered by the lack of enough data. Traditional data augmentation methods, such as rotation, translation, mirror, and lightning, are not sufficient to generate a diverse, realistic dataset for brain tumor diagnosis. Synthetic images can be generated for this purpose which can address the problems associated with data acquisition, such as; privacy concerns, class imbalance, and small sample size.
Generative Adversarial Networks (GANs) have been very popular for generating realistic diversified datasets. In 2018 StyleGAN [10] was proposed, with the main aim to improve the existing generator architecture G. StyleGAN mainly improved the existing architecture of the generator network in ProGAN [11] for better performance and kept the discriminator D network and loss functions constant. The latent code (z) is transformed into an intermediate latent code (W) prior to feeding it into the network. The synthesis network (G) is supervised by affine transforms through an adaptive instance that adds random noise maps to the space W resulting in much entangled latent space. The proposed model is capable of generating realistic, high-quality images and offers control over the new style of the generated image.
StyleGAN2 [12] architecture was presented to overcome issues present in the initial images generated by StyleGAN, such as blob and phase artifacts. Two causes were identified for the artifacts introduced in StyleGAN such as; fixed positions of eyes and nose and water droplet effects. Upon investigating the cause of common bob-like artifacts, it was observed that it was generated by the generator in response to an architectural design defect. A new design was proposed for the normalization used in the generator, which removed artifacts.
In this paper, we used StyleGAN2 with adaptive discriminator augmentation (ADA) [6] for generating brain tumor MRI images of 512 \(\times \) 512 resolution while utilizing a significantly limited amount of training data when compared to the existing approaches. Our proposed approach effectively addresses the problem of data limitation by generating realistic brain MRI with tumor samples and can learn different data distributions from brain tumor raw images. The experiments are conducted on the brain tumor dataset. We utilized pre-trained models trained on FFHQ dataset [10], BreCaHaD dataset [13], and AFHQ dataset [14]. The experimental results indicate that these models can generate superior quality superior MRI tumor samples that can be effectively utilized for medical analysis. The remaining paper is organized as: Sect. 2 provides a review of the related literature. Section 3 explains the methodology and the architecture. Section 4 presents experiments, and Sect. 4 presents the results and discussion for the synthesis of brain MRI having tumors. Finally, Sect. 6 concludes the paper.
2 Literature Review
The SytleGAN architecture generates style images while controlling different high-level attributes of the images [10]. The generator architecture in this research was designed in such a way that helps to control the image synthesizing process by learning on a constant input of 4 \(\times \) 4 \(\times \) 512 and on each subsequent layer based on latent code for adjusting the style of the image. When noise is provided as an input to the network, this combined effect helps segregate high-level attributes from stochastic variation in generated images and allows for better style mixing and interpolation. The datasets used in the work are FFHQ [15], LSUN [16] and CelebA-HQ [17]. The concept of intermediate latent space was used, which significantly affected how variational factors are represented in the network and could be disentangled. Two metrics, i.e., the perceptual path length and linear separability, were used to estimate the degree of latent space disentanglement.
StyleGAN2 was introduced in [12] to address the characteristic artifacts and improve the output of StyleGAN. The first reason for the artifacts was the attempt of StyleGAN to evade a design flaw related to instance normalization used in AdaIN. The second type of artifact was related to progressive growth and was addressed in StyleGAN2 by changing the training method. A method for mapping low-resolution medical images to high-resolution medical images using generative models is presented in [18]. In [19], considering the limitation of GANs to generate high-quality images for domains that have very little data, one of the very recent breakthroughs in generative modeling is a text-driven method that allows domain adaptation capability to the generator model for generating images across a multitude of domains. A text-driven method for out-of-domain image synthesis is proposed. The domain shift was carried out by adjusting the generator’s weights in the direction of images aligned with the driving text. The network architecture is dependent on StyleGAN2 and Contrastive-Language-Image-Pre-training (CLIP) [20, 21].
CLIP model has been used for discovering semantically rich and meaningful latent manipulations in order to generate images with styles defined through text based interface. In the first stage, an optimization task has been applied using CLIP-based loss to manipulate a latent input vector. In the next stage, a latent mapper for an optimized text-based manipulation given an input image has been used. Effectively, mapping the text-based inputs in the direction of StyleGAN style space results in effective text-based image manipulation. Motivated by the potential of the StayleGAN2 architecture to generate improved images of human faces, we use the StyleGAN2-ADA architecture to synthesize brain MRI, as explained in the following sections.

StyleGAN2-ADA (a) Generator. Based on the incoming style, the modulation scales each input feature map of the convolution, and the demodulation module is used to remove the droplet artifacts. (b) Discriminator. After the input vectors of the components, StyleGAN2-ADA performs data augmentation.
3 Methodology
We have utilized StyleGAN2 with ADA methodology to generate high-quality MRI brain tumor images while using a significantly limited amount of training data. The proposed pipeline of StyleGANs with ADA is shown in Fig. 1. StyleGAN2 [12] introduced several changes in the architecture to overcome the issues in StyleGAN. Many viewers observed distinctive artifacts in StyleGAN images. Two key issues were identified in the output of StyleGAN, and changes were introduced in the architecture and the training method accordingly. Upon investigating the cause of common blob-like artifacts, it was observed that the blobs were generated in response to an architectural design defect. A new design was proposed for the normalization used in the generator, which helped in removing the artifacts. It was concluded that the artifacts related to progressive growing have been quite effective at stabilizing high-resolution GAN training. Overall, the following major improvements were made in the G network considering issues in StyleGAN:
-
StyleGAN used a constant input c as the model input directly, it was modified to input C by adding noise and bias.
-
Noise and bias were moved outside the style block.
-
Only the standard deviation value of every feature map was modified instead of modifying both the standard deviation and the mean values.
-
Demodulation module was introduced to overcome the droplet artifacts.
Weight Demodulation: Similar to StyleGAN, StyleGAN2 makes use of a normalization technique to provide styles from the W vector using learning to transform A into the source image. Here, the weight demodulation handles the droplet artifacts.
Lazy Regularization: StyleGAN2 computes regularization terms once after 16 mini-batches compared to StyleGAN, which computes both the main loss function and regularization for every mini-batch with heavy memory consumption and high computation cost. This change in approach is to compute the cost function, which has no major effects in terms of model efficiency but speeds up the training.
Path Length Regularization: Introducing path length regularization [22] allows the same displacement in the latent space that would produce the same magnitude change in the image space regardless of the value of the latent factor.
Removing Progressive Growing: Progressive growth in StyleGAN causes phase artifacts (location preference for facial features). StyleGAN2 overcomes the issue by using a different network design based on skip connections similar to that of ResNet architectures.
Adaptive Control Scheme: In order to have dynamic control over the augmentation strength parameter p to avoid over-fitting, an adaptive control scheme [23] has been used instead of manually tuning the augmentation strength. With the introduction of two heuristics to detect over-fitting in the discriminator, we are going to increase the magnitude of the augmentation to have dynamic scheduling.
where \(r_v\) is the first heuristic which refers to the validation set results relative to the training set and images generated given in Eq. (1). \(r_t\) is the second heuristic that refers to the training set that generates positive discriminator outputs given in Eq. (2).
4 Experiments
Style transfer learning mechanism is used for model training. Transfer learning [24] is used to reduce the training data by using the weights of the model already trained on a dataset [7, 25,26,27].
4.1 Datasets
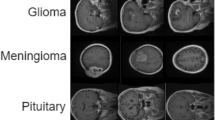
We applied the models to the brain tumor dataset [28, 29], as available via Kaggle [30]. This dataset includes 154 brain MRI samples and contains 3064 T1-weighted images with high contrast consisting of three kinds of brain tumors which are classified as Glioma, Meningioma, and Pituitary Tumor, as shown in Fig. 2.

Brain tumor dataset sample images. Each row represents one type of tumor.
4.2 Implementation Details
We resize all training images to 512 \(\times \) 512 resolution. We used Google Colab Pro platform for the training model as it allows access to faster GPUs which helps in speeding up the training. The model was trained on a Tesla P100 GPU with 25 GB RAM. For monitoring and managing GPU resources, NVIDIA System Management Interface (nvidia-smi) driver version 460.32.03 and Cuda version 11.2 has been used for the management and monitoring of NVIDIA GPU devices. We converted all images into TFR records, enabling StyleGAN2 ADA to read data and improving the import pipeline’s performance. We utilized pre-trained models trained on FFHQ dataset [10], BreCaHaD dataset [13], AFHQ [14].
4.3 Pre-trained Models
FFHQ512 [10] pre-trained model is trained on Flickr-Faces high-quality images (FFHQ) dataset. The FFHQ is an image dataset containing high-quality images of human faces. It offers 70,000 PNG images at 512 \(\times \) 512 resolution that display diverse ages, ethnicity, image backgrounds, and accessories like hats and eyeglasses.
BreCaHaD [13] pre-trained model is trained on a dataset consisting of 162 breast cancer histopathology images that are distributed into 1944 partially overlapping crops of 512 \(\times \) 512. The dataset is widely used by the biomedical and computer vision research community to evaluate and develop novel methods for tumor detection and diagnosis of cancerous regions in breast cancer histopathology images.
Animal FacesHQ [15] (AFHQ) pre-trained model is trained on a dataset of 15,000 high-quality animal face images at 512 \(\times \) 512 resolution in three domains of cat, dog, and wildlife, with 5000 images per domain. AFHQ sets a more challenging image-to-image translation problem by having three domains and diverse images of various breeds. The images are vertically and horizontally aligned. The low-quality images were manually discarded. We used weights from the AFHQ (Cat) and AFHQ (Wild) pre-trained models.
4.4 Evaluation Metrics
Fréchet Inception Distance (FID) [31] is a metric for quantifying the distance between two distributions of images \(P_r\) and \(P_g\) where \(P_r\) is the probability distribution of real images, and \(P_g\) is the probability distribution of generated images. It is used to evaluate the quality of generated images and the performance of GANs. FID is defined as:
where (\(\boldsymbol{\mu }_{\boldsymbol{r}}\), \(\boldsymbol{\varSigma }_{\boldsymbol{r}}\)) and (\(\boldsymbol{\mu }_{\boldsymbol{g}}\boldsymbol{,}\boldsymbol{\varSigma }_{\boldsymbol{g}}\)) denote the mean vectors and covariance matrices of the Gaussian approximations for real and generated samples, respectively. The lower the FID value, the better the generated image quality. Kernel Inception Distance (KID) [32] is a metric which measures the dissimilarity between two probability distributions \(\boldsymbol{P}_{\boldsymbol{r}}\) and \(\boldsymbol{P}_{\boldsymbol{g}}\) using samples drawn independently from each distribution. KID is defined to be the squared maximum mean discrepancy (MMD) between the Inception features of real and generated images. A cubic polynomial kernel is used to map the real and generated images from the feature space of the Inception network, which is defined as:


Trend of FID and KID using transfer learning in generating synthetic brain MRI with tumor images of 512 \(\times \) 512 resolution trained on StyleGAN2 ADA.

Samples of initially generated images. Results show a visualization of the weights of the StyleGAN model trained on FFHQ, AFHQ (Cat), AFHQ (Wild), and BreCaHad images.

Synthetic images generated for the best FID and KID values.
5 Results and Discussion
FID is a commonly used metric for assessing the quality of the images generated by a model. However, FID is prone to be dominated by the inherent bias when the number of real images is not large enough. Hence, we used KID as an additional metric for evaluating our model performance. The trend for FID and KID using different pre-trained models is shown in Fig. 4. FID and KID values were recorded on every ten tick intervals for FFHQ, BreCaHaD, and AFHQ models, where tick interval refers to the number of iterations after the training snapshot has been taken. The results are summarized in Table 1.
The trend indicates a decrease in FID and KID values as tick intervals increase for FFHQ and AFHQ (Cat) models. For BreCaHaD and AFHQ (Wild) models, a decrease can be observed from 0–30 tick intervals. After that, an increase can be seen for both FID and KID values. Amongst the models evaluated, the BrecaHaD model had the worse performance, having the highest FID and lowest KID values.
Qualitative results of initially synthetically generated brain tumor images by different models are shown in Fig. 5. Using the best FID and KID of the pre-trained models, the brain MRI images generated by transfer learning are shown in Fig. 6. By analyzing our results, we find that FFHQ gives the lowest FID of 58.1097 and KID of 0.00862, and generates better quality images when compared with other pre-trained models. Figure 3 shows a comparison of the images generated using DCGAN [20], WGAN [33] and Ours (FFHQ) model using the brain tumor dataset. The results indicate Ours (FFHQ) generates better quality images when compared with the other GAN models.
6 Conclusion and Future Work
In this work, we presented a useful application of Adaptive StyleGANS for synthetic brain MRI images. Our results show that high-quality realistic MRI brain tumor images can be generated using pre-trained GAN models. By analyzing our results, we find that FFHQ gives the lowest FID and KID and generates better quality images when compared with other pre-trained models used in this research. This work will motivate other researchers to leverage the potential of StyleGAN in many applied domains of medical imaging research. For example, the models can be explored for modeling to detect the presence of tumors in body parts, perform tissue segmentation when training largely suffers due to the unavailability of high-quality data, and cross-modality medical image generation. The future work of this research is to explore the use of StyleGAN2-based architectures for the synthesis of high-quality medical images of other modalities such as Computed Tomography and histopathology images. It would be interesting to evaluate the model performance with other smaller medical imaging datasets. Similarly, an interesting direction is to explore the use of StyleGAN2 with StyleCLIP [19] for generating medical images from the text description.
References
Ker, J., Wang, L., Rao, J., Lim, T.: Deep learning applications in medical image analysis. IEEE Access 6, 9375–9389 (2017)
An, G., Akiba, M., Omodaka, K., Nakazawa, T., Yokota, H.: Hierarchical deep learning models using transfer learning for disease detection and classification based on small number of medical images. Sci Rep. 11(1), 1–9 (2021)
Goodfellow, I., et al.: Generative adversarial networks. Commun. ACM (2020)
Yi, X., Walia, E., Babyn, P.: Generative adversarial network in medical imaging: a review. Med. Image Anal. 58, 101552 (2019)
Ali, H., Biswas, R., Ali, F., Shah, U., Alamgir, A., Mousa, O., Shah, Z.: The role of generative adversarial networks in brain MRI: a scoping review. Insights Imaging 13(1), 1–15 (2022)
Karras, T., Aittala, M., Hellsten, J., Laine, S., Lehtinen, J., Aila, T.: Training generative adversarial networks with limited data. Adv. Neural. Inf. Process. Syst. 33, 12104–12114 (2020)
Zhao, Y., Li, C., Yu, P., Gao, J., Chen, C.: Feature quantization improves GAN training. arXiv preprint arXiv:2004.02088 (2020)
Işın, A., Direkoğlu, C., Şah, M.: Review of MRI-based brain tumor image segmentation using deep learning methods. Proc. Comput. Sci. 102, 317–324 (2016)
Díaz-Pernas, F.J., Martínez-Zarzuela, M.: A deep learning approach for brain tumor classification and segmentation using a multiscale convolutional neural network. Healthcare 9(2), 153 (2021)
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: IEEE CVPR, pp. 4396–4405 (2019)
Gao, H., Pei, J., Huang, H.: ProGAN: network embedding via proximity generative adversarial network. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 1308–1316 (2019)
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of StyleGAN. In: IEEE CVPR, pp. 8107–8116 (2020)
Aksac, A., Demetrick, D.J., Ozyer, T., Alhajj, R.: BreCaHAD: a dataset for breast cancer histopathological annotation and diagnosis. BMC. Res. Notes 12(1), 82 (2019)
Kumari, N., Zhang, R., Shechtman, E., Zhu, J.-Y.: Ensembling off-the-shelf models for GAN training. In: IEEE CVPR, pp. 10651–10662 (2022)
Choi, Y., Uh, Y., Yoo, J., Ha, J.-W.: StarGAN v2: diverse image synthesis for multiple domains. In: IEEE CVPR, pp. 8185–8194 (2020)
Yu, F., Seff, A., Zhang, Y., Song, S., Funkhouser, T., Xiao, J.: LSUN: construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365 (2015)
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196 (2017)
Ahmad, W., Ali, H., Shah, Z., Azmat, S.: A new generative adversarial network for medical images super resolution. Sci. Rep. 12(1), 1–20 (2022)
Patashnik, O., Wu, Z., Shechtman, E., Cohen-Or, D., Lischinski, D.: StyleCLIP: text-driven manipulation of StyleGAN imagery. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 2065–2074 (2021)
Radford, A., Metz, L., Chintala, S.: Unsupervised representation learning with deep convolutional generative adversarial networks. CoRR, vol. abs/1511.06434 (2016)
Radford, A., et al.: Learning transferable visual models from natural language supervision. In: ICML, pp. 8748–8763. PMLR (2021)
Peebles, W., Zhu, J.-Y., Zhang, R. Torralba, A., Efros, A.A., Shechtman, E.: GAN-supervised dense visual alignment. In: IEEE CVPR, pp. 13470–13481 (2022)
Ma, X., Jin, R., Sohn, K.-A., Paik, J.-Y., Chung, T.-S.: An adaptive control algorithm for stable training of generative adversarial networks. IEEE Access: Pract. Innov. Open Solut. 7, 184103–184114 (2019)
Weiss, K., Khoshgoftaar, T.M., Wang, D.: A survey of transfer learning. J. Big data 3(1), 1–40 (2016)
Wang, Y., Gonzalez-Garcia, A., Berga, D., Herranz, L., Khan, F.S., Weijer, J.V.D.: MineGAN: effective knowledge transfer from GANs to target domains with few images. In: IEEE CVPR, pp. 9332–9341 (2020)
Iqbal, T., Ali, H.: Generative adversarial network for medical images (mi-GAN). J. Med. Syst. 42(11), 1–11 (2018)
Wang, Y., Wu, C., Herranz, L., van de Weijer, J., Gonzalez-Garcia, A., Raducanu, B.: Transferring GANs: generating images from limited data. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 218–234 (2018)
Cheng, J., et al.: Enhanced performance of brain tumor classification via tumor region augmentation and partition. PLoS One 10(10), e0140381 (2015)
Singh, P., Sizikova, E., Cirrone, J.: CASS: cross architectural self-supervision for medical image analysis. ArXiv, vol. abs/2206.04170 (2022)
Chakrabarty, N.: Brain tumor dataset. Kaggle
Nunn, E.J., Khadivi, P., Samavi, S.: Compound frechet inception distance for quality assessment of GAN created images. arXiv [cs.CV] (2021)
Knop, S., Mazur, M., Spurek, P., Tabor, J., Podolak, I.: Generative models with kernel distance in data space. Neurocomputing 487, 119–129 (2022)
Arjovsky, M., Chintala, S., Bottou, L.: Wasserstein generative adversarial networks. In: 34th ICML, vol. 70, pp. 214–223. PMLR (2017)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this paper

Cite this paper
Tariq, U. et al. (2023). Brain Tumor Synthetic Data Generation with Adaptive StyleGANs. In: Longo, L., O’Reilly, R. (eds) Artificial Intelligence and Cognitive Science. AICS 2022. Communications in Computer and Information Science, vol 1662. Springer, Cham. https://doi.org/10.1007/978-3-031-26438-2_12
Download citation
DOI: https://doi.org/10.1007/978-3-031-26438-2_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-26437-5
Online ISBN: 978-3-031-26438-2
eBook Packages: Computer ScienceComputer Science (R0)