
Abstract
Online, Image-based monitoring of arc welding requires direct visual contact with the seam or the melt pool. During SAW, these regions are covered with flux, making it difficult to correlate temperature and spatial related features with the weld quality. In this study, by using a dual-camera setup, IR and RGB images depicting the irradiated flux during fillet welding of S335 structural steel beams are captured and utilized to develop a Deep Learning model capable of assessing the quality of the seam, according to four classes namely “no weld”, “good weld”, “porosity” and “undercut/overlap”, as they’ve emerged from visual offline inspection. The results proved that the camera-based monitoring could be a feasible online solution for defect classification in SAW with exceptional performance especially when a dual-modality setup is utilized. However, they’ve also pointed out that such a monitoring setup does not grand any real-world advantage when it comes to the classification of relatively large, defective seam regions.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Submerged Arc Welding (SAW) is a fusion welding process which due to its high heat input is used to weld thick-section carbon steels. It is typically utilized in shipbuilding and in fabrication of pipes, pressure vessels and structural components for bridges and buildings due to its high productivity, low cost, and fully automated operation [1]. Despite though this high level of automation on the welding floor, today’s SAW systems cannot be considered intelligent, as their autonomy and adaptability are limited and achieved by utilizing an entire ecosystem consisting of designers, skilled operators as well as auxiliary processes such as quality control [2]. This fact contradicts the case of other welding processes involved in light metal fabrication sectors like the automotive industry where key enabling technologies and frameworks such as Artificial Intelligence, Cyber-physical Systems, and the Internet of Things have been the moving force for introducing aspects of this intelligence to the welding systems [3].
From available solutions on the market [4,5,6] to advanced research approaches, systems or prototypes are integrating process monitoring, closed-loop control [7,8,9] and quality assessment functionalities [10,11,12,13] and thus implementing fractions of what is called Intelligent Welding System (IWS) [2]. On other hand, in case of SAW, the majority of the research studies are focused on process modeling [14,15,16] and process parameter optimization [17, 18] which although are enriching the existing knowledge base they are lacking a clear interface with the welding system and integrability. Nevertheless, holistic approaches are existing and focus mainly on the prediction and/or control of the seam’s geometrical features by utilizing either the nominal input parameters [19, 20] or real-time measurements from retrofitted sensors [21]. To this end by looking at paradigms of other welding processes, integrating knowledge for defect detection into a welding system seems to be favored by the utilization of image sensors, as they can provide high-dimensional information of the process in a single instance [22]. Along with that, image classification, although until recently was carried out based on custom feature extraction algorithms and classic Machine Learning (ML) models, thanks to the establishment of the Convolutional Neural Networks (CNN), these two mechanisms were integrated into one optimizable structure which given the appropriate amount of training data can achieve high performance on image classification tasks [23]. Indicatively in [12] the authors by training a CNN using the data from a high-speed CMOS camera were able to achieve a 96.1% pore classification accuracy for the laser keyhole welding of 6061 aluminum. In [24] a monitoring system by utilizing a CNN was capable of determine the penetration state for the laser welding of tailor blanks with an accuracy of 94.6%, while in [25] with an end-to-end CNN achieved a classification accuracy of 96.35% on the penetration status during gas tungsten arc welding of stainless steel by using images depicting the weld pool.
With that been said, driven by 1) the lack of online defect detection approaches for the SAW 2) the recent advances on Image-based defect-detection for welding applications 3) a study which indicates that IR monitoring of SAW is feasible even though the thick layer of slag covers the seam [21] and 4) the need for integrating knowledge from the welding floor to the welding system, this study investigates the feasibility of image-based monitoring for SAW as a mean for online quality assessment. This is validated by introducing both an IR and an RGB camera which are feeding 3 different CNN models for classifying defective segments of the seam online. Their capabilities are assessed both in terms of classification and real-time inference performance while the need for dual-modality monitoring is determined afterward.
2 Quality Assessment Method
2.1 Model Selection and Architecture
When it comes to image classification many options are available [26, 27] however, CNNs’ were selected in this study as they are incorporating beyond many well-known advantages [28] some unique features that are particularly suited to this application. As such the CNNs can be trained and operate directly with images without the need for additional feature extraction methods. A trained CNN can be re-trained with a lot less data, even for entirely different application [25, 29,30,31] while the development of end-to-end inference applications can be accelerated, as it comes standardized for the most part by the majority of Deep Learning tools and frameworks. Consequently, CNNs are presenting the required flexibility, adaptability, and ease of development that is expected by an IWS as regards its quality assurance capabilities.
On the other hand, while the CNN’s non-linear nature is one of the key ingredients to its flexibility for learning complex relationships within the data among other image classification approaches it makes also sensitive to initial conditions. A high variance/ low bias remedy to this problem has emerged from the “Ensembled Learning [32] which although typically utilizes data from a single source, recently has been applied to multimodal scenarios [33, 34]. Herein findings on the improvement of the classification accuracy when combining the predictions from multiple neural networks (NN), seems to add the required bias that in turn counters the variance of a single trained NN. The results are predictions that are less sensitive to the specifics of the training data, the choice of the training scheme, and the serendipity of a single training run.
Based on the above the authors propose a 2-Branch CNN which uses the features of two trained CNN to fit a NN model as typically performed by applying the ensemble learning algorithms called “stacking”. The top-level architecture of the 2-Branch CNN is depicted hereafter (Fig. 1). For each branch of the model 2 residual CNNs were user as feature extractors. The architecture of the CNN used to extract features from IR images (MRN) can be found in [35] while the architecture of the other one is the same with the ResNet18 [36], taking RGB images as input. The selection of residual architectures was made as the “shortcut” connection can “transform” a non-convex optimization problem (training of MRN and ResNet18) into a convex one (improve gradient flow) [37].

2-Branch CNN model architecture
2.2 Training of the CNNs
For the MRN and ResNet18 networks, data augmentation was performed during training, by apply a random rotational and scale transformation on the images of the training partition of the data (70%) on every epoch [38]. By that the model rarely encountered the same training example twice, as this is improbable given that the transformations are random. To update the networks’ weights and biases and minimize the loss function the Stochastic Gradient Descent with Momentum (SGDM) [39] was used. Beyond the training algorithm, an early stopping criterion was used to avoid overfitting. This was implemented by calculating the loss of the model on the test (30%) partition of the data. If the current loss was greater than the current value and this situation persisted for more than 5 consecutive epochs, then the training was stopped. The model weights were the ones the model have from its last update before stopping.
The 2-branch CNN as depicted in Fig. 1 takes as inputs the features vectors emerged from the last average-pooling layers of the above networks. Considering that the two cameras are operating on different frame rates a single frame from the RGB corresponds to a batch of 33 IR frames. Thus, during training and inference, a single IR frame was selected randomly from this batch. Once again SGDM was used for optimization and cross-entropy as the loss function.
The development of all the models in this study was carried out using MATLAB’s Deep Learning Toolbox [40]. The training was speeded up by utilizing a 4xGPU machine for linearly scaling the mini-batch size, distributing, and accelerating the computations.
3 Experimental Setup and Data Processing
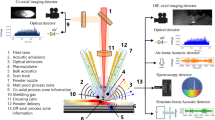
Two stationary, cameras were used to capture the visible and IR electromagnetic emissions of a SAW process. The high-speed IR camera (32 by 32 pixels, 1000 fps, 1–5 μm) by NIT [41] and the RGB web-camera (1920 by 1080 pixel, 30 fps) by Logitech [42] both placed at a working distance of 140 cm from the target (Fig. 2) were monitoring the fillet welding of structural steel beam (S335, 28 mm thickness). This placement is also convenient for the online use of the monitoring system. A Tandem Arc SAW machine with a stationary head was used with a 4 mm filler wire, at 29 V, 680–700 A, and a welding speed of 45 cm/min.

Seam IR and RGB image concatenation & quality labels.
The defects were artificially introduced by applying to the surface of the beam’s flange a grease-based layer for half of the beam’s length. This had, as a result, the electrical connection with the workpiece to be compromised and the root and leg of the weld to be contaminated. The welded beam was inspected for defects across its length visually by authorized personnel and four classes were derived for segments of the seam and the corresponding image data (Fig. 2). These segments were labeled as: No Weld (NW), Good Weld (GW), Porosity (EP), and undercut/overlap (PP). Two of these classes were representing defective regions as defined in [1, 43]. The data were captured manually using the software provided by the camera manufacturer. As in a single frame, more than one defect may be present, the matching of a quality stamp with a frame was made based on the point that this frame’s center was representing on the seam. For the IR camera due to the prolonged recording duration, the thermal drifting of the entire FPA was significant although linear [10]. Thus, to compensate that the minimum value of each frame was subtracted from the rest of the same frame. This step was integrated into the classification models’ architecture. The last step regarding image processing, concerned the synchronization of the two videos as the recording was not triggered by a common signal. Thus, this was carried out by using a single synchronization point located at the center of each frame which corresponded to the start of the seam. Following that, as the framerates of the two cameras were different, a map was created matching a batch of 33 IR frames to a single RGB frame.
4 Results and Discussion
It is noted that, regarding training, the learning rate decayed over time with each iteration having as a result the algorithm to oscillate less as approached minima (see Fig. 3). The training process was carried out using an early stopping criterion with a patience value of 1 epoch and using the same test a train partition of the data as with the previous models. The network’s parameters corresponding to the minimum loss observed during training were kept as the optimal ones. The classification performances of the MRN, ResNet18, and 2-Branch models on the test partition of the data are given in the Table 1 where the recall and precision metrics are calculated for each class [44]. The real-time inference performance of the models was evaluated by generating CUDA® [45] code for each model and using a MEX function as an entry point.

Training progress of the 2-branch CNN
The networks after loaded to the memory were fed with the number of frames that would have been received for 10 s. The frames were passed as single instances to the models and the overall procedure was repeated 20 times. The average inference time for the MRN (10000 frames) was 7.4 s, for the ResNet18 (303 frames) was 1.7 s and for the 2-Branch (303 frames) was 2.3 s.
From Table 1 the ability of all the models to identify the GW and NW classes is superior compared to the EP and PP classes. This can be easily justified for the GW class as it includes the most instances and thus adding the most bias to the model’s training. However, the same cannot be said for the NW class where the number of training instances was the smallest. Looking at the channels of the 1st convolutional layer it can be observed, especially for the RGB case, that the activations are more, and stronger when an image belongs to the NW class (see Fig. 4 - left).

Left - Activation of the first convolutional layer of ResNet18, right – Misclassification across the seam’s length by the 3 models
In a real-world scenario, as well as in this approach the defects are the exception (minority) meaning that when one has occurred the system must be able to identify it. On the other hand, misfiring on such events and halting the production would raise the production cost. Hence, selecting the best model out of three comes down to calculating which has both the highest recall and precision scores for the PP and EP classes. This typically can be combined into a single metric namely F1 score [44]. As expected, the higher F1 score for these classes was achieved by the 2-Branch model (EP: 98.3%, PP: 97.7%) while to our surprise the ResNet18 model followed by slight margin (EP: 98.1%, PP: 97.6%). These findings highlighted that the main contribution regarding the identification of the EP and PP class are most probably due to the RGB images.
Before deriving a final conclusion, it must be taken into consideration that the models presented herein are meant to assess the quality of a seam across its length. In the figure above (see Fig. 4 - right) the target classes are plotted against the length of the seam. Additionally, the points where misclassification occurred by the models are plotted using a simple binary indicator. The misclassification of the EP and PP defects mainly occurred at the transition points and not along the area for which these defects persist. Considering that from the seam inspection results, the minimum length between two different quality labels was approximately 10mm and the maximum length for a misclassified area was a lot less than 10mm (Fig. 4 - right), the F1 score for these classes cannot affect the real-world performance of the model, as the process is fairly slow, and the models can offer real-time inference, below 1ms.
Coming to this point it is safe to conclude that all the models within the context of the current approach are capable of assessing the seam quality in real-time with 100% accuracy for all the classes. This implies that even with a cost-effective monitoring setup (RGB camera) the implementation of a quality assessment system for SAW is feasible without compromising the classification performance. Reaching the inference limits of the current approach as presented previously, would require on the one-hand a high spatial-resolution for the seam inspection procedure and on the other hand, a quite fast welding process given the fact that each camera is capable/configured for 1p/1mm.
5 Conclusions and Future Outlook
In this study, a non-invasive, online quality assessment approach was proposed for identifying defects for the SAW. Its feasibility was evaluated from the high-classification and real-time inference performance of the CNN models which achieved an average F1 score of 98.0% as regards the identification of porosity and undercut/overlap defects and inference time for a single frame <1 ms.
While the dual-modality monitoring setup increased the defect-identification performance, this was done by a very small amount. Additionally, it was observed that the misclassification was not persisted for a length greater than the smallest length for which the seam has been inspected. This implies that for that level of accuracy choosing a specific monitoring setup will not grand any real-world advantage.
From a system perspective, with the utilization of CNNs, the knowledge integration was proven once again that is moving towards standardization with the quality assessment functionalities to be as easy to integrate into a welding system as labeling some images. With such capacity both in terms of real-time utilization, assessment per length, future work would aim at the one hand to exhaust the capabilities of the system on faster welding scenarios (laser welding), test its adaptability, and introduce a standardized welding system development as regards quality assessment.
For future research, the maximum sampling rate for both cameras should be investigated, so that adequate information on the process is able to aggregated. Furthermore, there is still pending work to be done in multi-modal monitoring setup, as different types of manufacturing processes should be tested to check the complementarity of various sensors used.
References
ASM Handbook committee: ASM Handbook: Welding, Brazing, and Soldering, 1st edn. ASM Int. (1993)
Wang, B., Hu, S.J., Sun, L., Freiheit, T.: Intelligent welding system technologies: state-of-the-art review and perspectives. J. Manuf. Syst. 56, 373–391 (2020)
Mourtzis, D., Angelopoulos, J., Panopoulos, N.: Design and development of an IoT enabled platform for remote monitoring and predictive maintenance of industrial equipment. Procedia Manuf. 54, 166–171 (2021)
CLAMIR. https://www.clamir.com/en/. Accessed 13 Feb 2022
Precitec Laser Welding Monitor LWM. https://www.precitec.com/laser-welding/products/process-monitoring/laser-welding-monitor/. Accessed 13 Feb 2022
4D Photonics GmbH WeldWatcher®. https://4d-gmbh.de/how-is-process-monitoring-realized-by-the-weldwatcher/?lang=en. Accessed 13 Feb 2022
Günther, J., Pilarski, P.M., Helfrich, G., Shen, H., Diepold, K.: Intelligent laser welding through representation, prediction, and control learning: an architecture with deep neural networks and reinforcement learning. Mechatronics 34, 1–11 (2019)
Masinelli, G., Le-Quang, T., Zanoli, S., Wasmer, K., Shevchik, S.A.: Adaptive laser welding control: a reinforcement learning approach. IEEE Access 8, 103803–103814 (2020)
Franciosa, P., Sokolov, M., Sinha, S., Sun, T., Ceglarek, D.: Deep learning enhanced digital twin for closed-loop in-process quality improvement. CIRP Ann. 69(1), 369–372 (2020)
Stavropoulos, P., Sabatakakis, K., Papacharalampopoulos, A., Mourtzis, D.: Infrared (IR) quality assessment of robotized resistance spot welding based on machine learning. Int. J. Adv. Manuf. Technol., 1–22 (2021). https://doi.org/10.1007/s00170-021-08320-8
Stavridis, J., Papacharalampopoulos, A., Stavropoulos, P.: Quality assessment in laser welding: a critical review. Int. J.Adv. Manuf. Technol. 94(5–8), 1825–1847 (2018). https://doi.org/10.1007/s00170-017-0461-4
Zhang, B., Hong, K.M., Shin, Y.C.: Deep-learning-based porosity monitoring of laser welding process. Manuf. Lett. 23, 62–66 (2020)
Zhang, Z., Wen, G., Chen, S.: Weld image deep learning-based on-line defects detection using convolutional neural networks for Al alloy in robotic arc welding. J. Manuf. Process. 45, 208–216 (2019)
Cho, D.W., Song, W.H., Cho, M.H., Na, S.J.: Analysis of submerged arc welding process by three-dimensional computational fluid dynamics simulations. J. Mater. Process. Technol. 213(12), 2278–2291 (2013)
Nezamdost, M.R., Esfahani, M.R.N., Hashemi, S.H., Mirbozorgi, S.A.: Investigation of temperature and residual stresses field of submerged arc welding by finite element method and experiments. Int. J. Adv. Manuf. Technol. 87(1–4), 615–624 (2016). https://doi.org/10.1007/s00170-016-8509-4
Wen, S.W., Hilton, P., Farrugia, D.C.J.: Finite element modelling of a submerged arc welding process. J. Mater. Process. Technol. 119(1–3), 203–209 (2001)
Karaoğlu, S., Secgin, A.: Sensitivity analysis of submerged arc welding process parameters. J. Mater. Process. Technol. 202(1–3), 500–507 (2008)
Tarng, Y.S., Juang, S.C., Chang, C.H.: The use of grey-based Taguchi methods to determine submerged arc welding process parameters in hardfacing. J. Mater. Process. Technol. 128(1–3), 1–6 (2002)
Gunaraj, V., Murugan, N.: Application of response surface methodology for predicting weld bead quality in submerged arc welding of pipes. J. Mater. Process. Technol. 88(1–3), 266–275 (1999)
Murugan, N., Gunaraj, V.: Prediction and control of weld bead geometry and shape relationships in submerged arc welding of pipes. J. Mater. Process. Technol. 168(3), 478–487 (2005)
Wikle III, H.C., Kottilingam, S., Zee, R.H., Chin, B.A.: Infrared sensing techniques for penetration depth control of the submerged arc welding process. J. Mater. Process. Technol. 113(1–3), 228–233 (2001)
Knaak, C., Thombansen, U., Abels, P., Kröger, M.: Machine learning as a comparative tool to determine the relevance of signal features in laser welding. Procedia CIRP 74, 623–627 (2018)
Cheon, S., Lee, H., Kim, C.O., Lee, S.H.: Convolutional neural network for wafer surface defect classification and the detection of unknown defect class. IEEE Trans. Semicond. Manuf. 32(2), 163–170 (2019)
Zhang, Z., Li, B., Zhang, W., Lu, R., Wada, S., Zhang, Y.: Real-time penetration state monitoring using convolutional neural network for laser welding of tailor rolled blanks. J. Manuf. Syst. 54, 348–360 (2020)
Jiao, W., Wang, Q., Cheng, Y., Zhang, Y.: End-to-end pre-diction of weld penetration: a deep learning and transfer learning based method. J. Manuf. Process. 63, 191–197 (2021)
Liu, C., Law, A.C.C., Roberson, D., Kong, Z.J.: Image analysis-based closed loop quality control for additive manufacturing with fused filament fabrication. J. Manuf. Syst. 51, 75–86 (2019)
Sudhagar, S., Sakthivel, M., Ganeshkumar, P.: Monitoring of friction stir welding based on vision system coupled with machine learning algorithm. Measurement 144, 135–143 (2019)
Gu, J., Wang, Z., Kuen, J., Ma, L., Shahroudy, A., Shuai, B., et al.: Recent advances in convolutional neural networks. Pattern Recogn. 77, 354–377 (2018)
Pan, H., Pang, Z., Wang, Y., Wang, Y., Chen, L.: A new image recognition and classification method combining transfer learning algorithm and MobileNet model for welding defects. IEEE Access 8, 119951–119960 (2020)
Gellrich, S., et al.: Deep transfer learning for improved product quality prediction: a case study of aluminum gravity die casting. Procedia CIRP 104, 912–917 (2021)
Papacharalampopoulos, A., Tzimanis, K., Sabatakakis, K., Stavropoulos, P.: Deep quality assessment of a solar reflector based on synthetic data: detecting surficial defects from manufacturing and use phase. Sensors 20(19), 5481 (2020)
Friedman, J., Hastie, T., Tibshirani, R.: The Elements of Statistical Learning, 2nd edn. Springer, New York (2009). https://doi.org/10.1007/978-0-387-84858-7
Caggiano, A., Zhang, J., Alfieri, V., Caiazzo, F., Gao, R., Teti, R.: Machine learning-based image processing for on-line defect recognition in additive manufacturing. CIRP Ann. 64(1), 451–454 (2019)
Yang, Z., Baraldi, P., Zio, E.: A multi-branch deep neural network model for failure prognostics based on multimodal data. J. Manuf. Syst. 59, 42–50 (2021)
MATLAB Support Documentation. https://www.mathworks.com/help/deeplearning/ug/train-residual-network-for-image-classification.html. Accessed 13 Feb 2022
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Li, H., Xu, Z., Taylor, G., Studer, C., Goldstein, T.: Visualizing the loss landscape of neural nets. In: NeurIPS 2018, vol. 31 (2018)
Shorten, C., Khoshgoftaar, T.M.: A survey on image data augmentation for deep learning. J. Big Data 6(1), 1–48 (2019)
Murphy, K.P.: Machine Learning: A Probabilistic Perspective, 1st edn. The MIT Press, London (2012)
MATLAB Deep Learning Toolbox. https://www.mathworks.com/products/deep-learning.html. Accessed 13 Feb 2022
NIT TACHYON 1024 microCAMERA. https://www.niteurope.com/en/tachyon-1024-microcamera/. Accessed 13 Feb 2022
LOGITECH C922 PRO HD STREAM WEBCAM. https://www.logitech.com/en-us/products/webcams/c922-pro-stream-webcam.960-001087.html. Accessed 13 Feb 2022
Kobe Steel Ltd.: The ABC’s of Arc Welding and Inspection, 1st edn. Kobe Steel Ltd., Tokyo (2015)
Tharwat, A.: Classification assessment methods. Appl. Comput. Inform. 17(1), 168–192 (2021)
NVIDIA CUDA Toolkit Documentation. https://docs.nvidia.com/cuda/. Accessed 13 Feb 2022
Acknowledgements
This work is under the framework of EU Project AVANGARD, receiving funding from the European Union’s Horizon 2020 research and innovation program (869986). The dissemination of results herein reflects only the authors’ view and the Commission is not responsible for any use that may be made of the information it contains.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this paper

Cite this paper
Stavropoulos, P., Papacharalampopoulos, A., Sabatakakis, K. (2023). Online Quality Inspection Approach for Submerged Arc Welding (SAW) by Utilizing IR-RGB Multimodal Monitoring and Deep Learning. In: Kim, KY., Monplaisir, L., Rickli, J. (eds) Flexible Automation and Intelligent Manufacturing: The Human-Data-Technology Nexus . FAIM 2022. Lecture Notes in Mechanical Engineering. Springer, Cham. https://doi.org/10.1007/978-3-031-18326-3_16
Download citation
DOI: https://doi.org/10.1007/978-3-031-18326-3_16
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-18325-6
Online ISBN: 978-3-031-18326-3
eBook Packages: EngineeringEngineering (R0)