
Abstract
Latinos have higher incidence rates of cervical, gall bladder, liver, and gastric cancer, and higher mortality rates for six cancer sites than US Whites. This review chapter focuses on Latino cancer disparities, how the exposome can be applied to understanding Latino cancer disparities, and how environmental exposures lead to alterations in key biological pathways at the cellular, molecular, and system level, helping to explain the increased risk for population level cancer disparities among Latinos. An exposome-wide association study (ExWAS) approach is proposed as a novel conceptual framework to assess the role of multiple chemical and non-chemical exposures in the cause and progression of cancer among Latinos across the life course. Also discussed is how this strategy could be exploited by using biomarkers of susceptibility, exposure, and effect; and how a trans-omics approach, using recent advances in genomics, epigenomics, transcriptomics, metabolomics, proteomics, and lipidomics, could be used to deploy new biomarkers that serve both prognostic and diagnostic purposes. Also outlined are the knowledge gaps and scope for future studies in this area with implications for public health and policy interventions.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
Introduction
Exposome
The exposome was introduced into the literature by Dr. Christopher Wild in 2005 [1] as all exposures a person has in one’s lifetime and the biological mechanisms and processes through which those exposures affect health. Introduction of the exposome paradigm has challenged us to reconsider how we consider the causes of cancer and other chronic diseases; research methods and analytics we use to understand them; and the implications for clinical practice, health disparities, and public health policy. Key elements of the exposome include a real-world approach, inclusion of multiple environmental exposures and internal and external environments, and the ability to assess the effects of exposures at key developmental periods across the life course and trans-generationally. The main aim of exposomics is to provide an early warning system for understanding disease pathways, which will allow early targeting of prevention and early intervention strategies.
The exposome consists of one’s internal and external environments. The external or eco-exposome has been operationalized by Juarez [2] as four broad domains: the natural, built, social, and policy environments. He later added health and healthcare as a fifth domain. Each domain consists of subdomains: natural (air, water, land), built (places you live, work, and play), social (demographic, social, economic, and political factors), and policy (federal, state, and local government policies and regulations). Each subdomain is further broken down into categories, subcategories, and variables. Juarez and colleagues have developed a national, public health exposome, relational-data repository with metadata, comprising over 55,000 variables covering the period 2003–2018 [3].
The internal or endo-exposome, on the other hand, has been described as the body’s endogenous metabolic response to environmental influences, which modulate vulnerability to subsequent exposures [4]. Understanding the biological effects and responses to environmental exposures can shed light onto the mechanistic connections between exposures and health [5]. An exposome approach provides a dynamic risk profile of multiple risk and protective factors and thus is particularly applicable to chronic disease onset, progression, and outcomes.
Applying an exposome-wide association study (ExWAS) approach to cancer and cancer disparities provides a novel way for conceptualizing the relationships of multiple chemical and non-chemical exposures in the etiology and progression of cancer at key developmental periods, over the life course, and across generations. Understanding the biological effects of exposures provides new opportunities for measuring why populations with similar exposure profiles experience similar poor health outcomes [6].
Public Health Exposome
Juarez [2] created an ontology, called the public health exposome (PHE), to represent the vast array of external environmental exposures. In addition, he has curated a database, that to date, includes over 55,000 variables. The PHE data repository contains both annual and county measures of health and environmental exposures from the natural, built, social, and policy environments for 3141 counties and county equivalents over 15 years (2003–2018) (Fig. 2.1). The PHE is fully curated with metadata and a searchable data dictionary. Metadata include names and definitions of variables; units of measurement; date, time, and location of data collection; the identity of the individual who collected the data; and sampling design. The PHE data repository has been geocoded and harmonized at an annual and county level and provides spatial–temporal and contextual environmental data for understanding place-based health disparities. The data repository includes crosswalks that allow for the aggregation of data obtained in smaller geographic and temporal units upward to the county or annual levels. Other spatial resolutions included in the data repository are point, polygon, block groups, census tracts, zip codes, 3 km grids, 1 km grids, metropolitan statistical areas (MSAs), states, and regions. Other temporal units included in the dataset are daily, monthly, quarterly, and annual measures.

ExWAS approach to Latino cancer disparities
Most of the data in the PHE data repository were obtained from publicly available web sites at no or low cost, such as Centers for Disease Control and Prevention (WONDER, BRFSS, CDC Tracking Network, National Center for Health Statistics, National Diabetes Surveillance System), National Cancer Institute (small area estimates for cancer-related measures), North American Land Data Assimilation System, National Oceanic and Atmospheric Administration, Federal Emergency Management Agency (National Flood Hazard Layer), US Environmental Protection Agency (EJ Screen, Superfund sites, Environmental Quality Index, National Air Toxics Assessment), US Geological Survey (water usage), HRSA Data Warehouse (health professions shortage areas, medically underserved areas), Health Indicators Warehouse (morbidity, mortality), US Department of Agriculture (Food Environment Atlas), Robert Wood Johnson (County Health Rankings), US Census (2000, 2010, decennial census, bridged race population estimates, small area income and poverty estimates), American Community Survey, Agency for Toxic Substances and Disease Registry (Social Vulnerability Index), Dartmouth Atlas (Medicare claims data), AIDSVU, Department of Labor (unemployment statistics), Department of Education (graduation rate, student enrollment, adult literacy), US Department of Interior (National Land Cover/Land Use), and US Post Office (residential and business vacancies).
Natural Environment
The natural environment consists of datasets of climate, weather, and natural resources that affect human survival and economic activity. It includes chemical exposures found in the air, water, and land that humans interact with on a daily basis. Studies have shown that exposure to different components of the natural environment can have an independent, positive or negative effect on health and health-related behaviors. While much is known about the adverse effects of chemical emissions that are released into the air, water, and land, there is growing evidence that exposure to positive attributes of the natural environment, such as green space and state and national parks and forests, can mitigate the impact of chemical and non-chemical stressors on health and health-related behavior. The PHE database includes spatial–temporal measures of exposure from the air, water, and land that humans interact with on a daily basis such as meteorological conditions (particulate matter, minimum/maximum temperature, and maximum Heat Index); EPA Air Quality System (criteria pollutants, particulates, toxins); and chemicals from emissions, pesticides, and land cover/land use.
Fine particulate matter measures (PM2.5) and heat metrics data were determined using models developed by Dr. Mohammad Al-Hamdan (USRA) for an EPA STAR grant; he developed algorithms to generate high resolution, daily, 3-km, PM2.5 and 1-km, heat exposure products (minimum/maximum and maximum heat index) for the period 2003–2018 for 12 southern states. Through a subcontract with the HDRCOE at Meharry (Juarez, PD, PI), Dr. Al-Hamdan applied a novel spatial surfacing algorithm to estimate daily, 3-km, PM2.5 surfaces/grids in the 12 southeastern states. He did this by combining PM2.5 data derived from MODIS AOD satellite data (12 km grid) with ground observations of PM2.5 data reported from EPA ambient air quality monitoring stations of the EPA Air Quality System (AQS). To generate high resolution daily exposure measures, Al-Hamdan first validated AOD-PM2.5 regression models for 36 cities across the 12 southeastern states of the SCCS. These combined regional regression models then were integrated into a modified version of a spatial surfacing algorithm that merges the MODIS-derived and EPA/AQS PM2.5 data to create daily, 3-km, PM2.5 spatial surfaces/grids for the 12 southeastern states, geographic region of the SCCS. These data are available to center investigators [7].
Built Environment
The built environment includes the physical characteristics of places we live, work, and play (e.g., homes, buildings, streets, open spaces, and infrastructure) as well as patterns and types of development, building location and design, and transportation infrastructure in communities that can have a direct or indirect impact on health. The degree to which the built environment is important to health may differ, depending on the broader social context. For instance, the location of supermarkets, fast-food restaurants, farmers’ markets, liquor stores, pharmacies, and health-care facilities can have a significant effect on people’s diets and their health. Likewise, inaccessible or nonexistent sidewalks and bicycle or walking paths may contribute to sedentary habits and a person’s level of physical activity and can contribute to poor health outcomes such as obesity, cardiovascular disease, stroke, and diabetes. Measures of the built environment included in the public health exposome database include land use, TRI facilities, highways, neighborhood resources, health-care facilities, green space, parks, and occupational codes.
Social Environment
The social environment (i.e., social determinants of health) constitutes the conditions in which people are born, grow, work, live, and age and are shaped by social/cultural norms, economic and employment policies and systems, the distribution of money, power, and resources, and political systems. Social determinants constitute the conditions of daily life and include factors like socioeconomic status, poverty, education, employment, crime, residential segregation, and social support networks, and provision of and access to culturally and linguistically appropriate health-care services. Social environmental stressors in the public health exposome database include population level measures of social, demographic, economic, and political variables derived principally from the US Census/American Community Survey, as well as measures of crime and social stress, such as GINI (measure of economic inequality), residential segregation, and multidimensional measures of social deprivation.
Applying an Exposome-wide Association Study (ExWAS) Approach to Latino Cancer Disparities
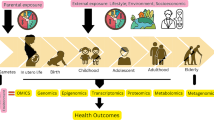
There is no single cause of Latino cancer disparities. First, cancer is not a single disease. Rather, cancer can start anywhere in the body; where it starts is how it is named (lung, breast, colorectal, etc.). The causes of cancer arise from genetic mutations, often caused by the body’s response to chemical and non-chemical exposures in one’s environment. Cancers are alike in some ways, but they are different in the ways they grow and spread. An ExWAS approach to Latino cancer disparities provides a framework for understanding how multiple environmental exposures lead to biological changes that produce certain health outcomes and lead to population-level disparities (Fig. 2.1).
Population-level cancer disparities may arise from common exposures experienced by subpopulations across a state or region or from place-based environmental exposures experienced by people who live in a neighborhood. While much attention has been given to the role of social determinants in Latino cancer disparities, to date, much remains unknown about how social determinants get under the skin to actually cause cancer and lead to disparate outcomes. The exposome provides a model for understanding the biological mechanisms and pathways through which non-chemical stressors, such as social factors, can lead to cancer.
Cancers in Latinos and Health Disparities
Cancer statistics compiled by the American Cancer Society [8] for the years 2018–2020 indicate that among Latinos, lung, liver, and colorectal cancer were expected to account for 16, 12, and 11%, respectively, of the deaths in men; while breast, lung, and colorectal were expected to contribute to 16, 13, and 9%, respectively, of the deaths in women. In regard to the emergence of new cases, prostate, colon, and lung cancers were expected to constitute 21, 12, and 8%, respectively, in men; while breast, thyroid, and uterine cancers amount to 29, 8, and 8%, respectively, in women. From a health disparities standpoint, the following are the predominant cancers in Latinos.
Lung Cancer
Even though lung cancer is one of the leading causes of deaths in Latinos, mortality due to this disease is low compared to other racial groups [9]. A study conducted in South Florida revealed that men of Cuban decent have higher mortality rates than their counterparts from Puerto Rico and South America [10]. It has been reported that 48% of Latino patients with metastatic lung adenocarcinomas have epidermal growth factor receptor (EGFR) gene mutations [11].
Breast Cancer
A greater incidence of breast cancer was noticed among Latinas living in the Southwestern United States and South Florida [12]. However, in a cohort of breast cancer patients from Puerto Rico, the prominent subtypes were found to be Luminal A (69%), followed by triple negative (15%), Luminal B (10%), and human epidermal growth factor receptor 2 positive (HER2+; 6%). The clinicopathological characterization of breast cancer in this cohort was incomplete because of study limitations (late-stage diagnosis, missing mammography records) and lack of insurance coverage, which presents a health disparity [13].
Liver Cancer (Hepatocellular Carcinoma; HCC)
Chronic liver disease, including cancer, ranked fourth in terms of deaths for Latino men between ages 55 and 64, and Latinos are 1.6 times more likely to die from liver disease compared to the US general population [14]. Consumption of contaminated diet and viral infections were the reported contributors to liver cancer in Latinos. A study conducted by Ramirez et al. [15] found that Latinos in Texas who had liver cancer had greater levels of aflatoxins (carcinogenic chemicals found in contaminated corn, nuts, seeds, and rice) than those without the disease. The Ramirez team also reported that Latinos in Texas had the highest incidence of liver cancer in the United States [16].
Hepatitis C virus (HCV) infection is another risk factor for liver cancer. HCV infection was found to be significantly higher in Latinos from South Texas compared to controls [16]. Aflatoxin exposures and Hepatitis B infections were reported to show an additive effect toward development of HCC [17]. A systematic review of HCC among Latinos in South Texas revealed that metabolic syndrome (diabetes and obesity), viral hepatitis (B and C), genetic predisposition, environmental exposures, diet (consumption of aflatoxin-contaminated diet), and lifestyle (smoking) were the most likely risk factors [18].
Colorectal Cancer (CRC)
CRC was the second most diagnosed cancer accounting for 13% of cancer deaths (in each sex) in Puerto Rico, and lack of knowledge about this disease was responsible for a low screening rate [19]. The incidence of CRC was reported to be high in Latinos living near the United States–Mexico border [20] and also in New Mexico [21]. Latinos were reported to develop distal colon tumors more frequently compared to the general population [22] and when detected they were at a late-stage CRC compared to their non-Latino counterparts [21]. The development of CRC has been attributed to environmental exposures, smoking, diet, and obesity [20].
Prostate Cancer
Even though prostate cancer incidence among Latino men is lower than other racial groups, it still ranks fourth in terms of mortalities [23], and first among the new cancer cases to be detected [8]. Prostate cancer shows heterogeneity among Latinos. A 20-year Surveillance Epidemiology and End Results Program (SEER) data analysis revealed that prostate cancer characteristics in Latinos living in the United States were specific to their country of origin. Mexicans, Cubans, and Puerto Ricans registered higher prostate-specific antigen scores and advanced stage cancer compared to Dominicans and South-Central Americans [24].
Thyroid Cancer
The SEER data revealed that the age-adjusted incidence of papillary thyroid carcinoma was high in Puerto Rican women compared to the mainland Latinos, non-Latino Whites and Blacks [25]. Thyroid cancer in Puerto Rican men showed a similar trend, with a lower incidence than women. The follicular histology, occurrence of large tumors, localization of disease, and single nucleotide polymorphisms are some characteristics of Latino thyroid cancer patients [26].
Uterine and Cervical Cancer
The SEER database review revealed that both endometrioid and non-endometrioid carcinoma rates are on the rise among Latinos [27]. Latinos had more advanced cervical cancer disease and higher mortalities compared to Caucasians, African Americans, Asians, and other racial groups [28, 29]. The incidence of HPV-related cancers was also high in Latinos, and the risk was higher among HIV-infected Latinos than in the general population [30].
Biomarkers of Cancer
Biomarkers from the Perspective of Exposure Biology
As mentioned, environmental and life-style factors play a major role in assessing the etiology of cancer. In this regard, biomarkers play a dominant role in delineating the exposome as they are measures of either healthy or carcinogenic processes. The three major categories of biomarkers that assist in cancer risk assessment are as follows.
Biomarkers of Susceptibility
These are markers of increased vulnerability to the effects of suspected environmental carcinogens, which can be measured in a tumor sample or organ system. As most cancers arise from gene–environment interactions (individuals’ genetic susceptibilities against their chemical exposure histories), these markers are used to identify individuals/populations that are at risk from carcinogenic exposures. The biomarkers that come under this category are variants in genes that encode biotransformation enzymes such as cytochrome P450 (CYP) isozymes CYP1A1, CYP2C9, CYP2E1; N-acetyltransferase 2 (NAT2); serum paraoxonase and arylesterase 1 (PON1); epoxide hydrolase 1 (EPHX1); aryl hydrocarbon receptor (AhR); glutathione S-transferase theta 1 (GSTT1) null phenotype; DNA repair and oxidative damage repair genes (risks for leukemia and non-Hodgkins Lymphoma) [31].
Biomarkers of Exposure
These markers highlight the significance of various exposure pathways and cancer risk; they allow measurement of carcinogens of interest in the body from an accessible biological matrix such as blood, urine, normal, and tumor tissues. For individuals who are either occupationally or dietarily exposed to polycyclic aromatic hydrocarbons (PAHs) (risks for lung cancer [32]) or aflatoxin B (risks for liver cancer [15]) either individually or in mixtures, metabolites of these chemicals in serum or urine serve as markers of exposure.
Biomarkers of Effect
These markers are responses elicited as a result of interaction of an organism with the exposome mentioned in the earlier sections. The responses are measured at the level of tissue, organ, and whole organism etiology. The widely measured biomarkers of cancer are F2 isoprostanes (risks for prostate cancer [33], C-reactive protein (CRP), interleukin (IL) 6 (risks for lung cancer [34]), expression of p53, estrogen receptor α and β, progesterone receptor, cytokeratin 5 and 6, cell proliferation marker Ki-67, cancer antigen 125 marker (risks for breast and ovarian cancers [13]), and micro RNAs (risks for CRC [35]).
Biomarkers from the Perspective of Systems Biology
Most of the cellular macromolecules such as proteins, DNA, RNA, and lipids are regulated in cancer through various pathways. Their altered profiles in blood and tissues provide clues on their role in tumor formation, progression, and metastasis. Some omics data are potential biomarkers of aggressiveness of dysplastic cells and underlying pathways (diagnostic markers), while in some instances the altered pathways may serve as markers of intermediate steps or likelihood of more changes downstream (prognostic markers). Gaining awareness of the dynamics of various systems in the body and how vulnerabilities in one system and the associated symptoms (tumor growth) could impact other systems brought into light the importance of the systems biology concept in cancer research [36]. The systems biology approach could be capitalized by employing “omics” approaches. These approaches will unravel new biomarkers, which when standardized and validated could provide information on mechanism of action for carcinogens and the key biochemical and molecular pathways involved. Mentioned below are some examples of different omics approaches used by researchers to study the cancer disparities in Latinos. Most of the studies reported herein are one-step omics studies (discovery only). Very few studies have conducted two-step studies (discovery and validation). In addition to lack of literature, the small sample size used in the published studies is another limitation.
Genomics
Single nucleotide polymorphism (SNP) studies have revealed that polymorphisms associated with nicotine metabolism and DNA repair genes are responsible for higher lung cancer risk in Latinos. Additionally, the predominant driver oncogenes reported were EGFR, Kirsten Rat Sarcoma (KRAS), and c-raf murine sarcoma viral oncogene homolog B1 (BRAF) [37]. Genome-wide association studies (GWAS) conducted to find SNPs associated with colon cancer in Latinos discovered 17 genetic variants across four independent regions [38]. Another GWAS with Latino breast cancer patients revealed SNPs at 6q25 locus were associated with a low risk of estrogen receptor (ER) negative breast cancer risk in Latinas with indigenous American ancestry [39]. A significant association between thyroid cancer and five specific SNPs were detected in Latinos living in Columbia [26].
Epigenomics
Changes in DNA methylation, a well-known epigenetic modification, are dynamic and influenced by both intrinsic (genetic) and extrinsic (environmental, lifestyle) factors [40]. Unlike DNA sequence mutations, DNA methylation can be changeable throughout a lifetime and can be altered by environmental exposure [41]. Associated with cancer, DNA methylation can alter the regulation of diverse cellular processes [42]. The global loss of methylation, often measured by Long Interspersed Element-1 (LINE-1), is associated with cancer incidence and mortality [43,44,45,46]. Additionally, genome-wide methylation studies have revealed numbers of cancer site-specific, hyper- and hypo-methylation across the genome as potential biomarkers for diagnosis, treatment, and prognosis [47,48,49]. Thus, many studies have focused on the relationship between DNA methylation and cancer, but notably in Caucasians [50, 51] and far more limited for Latinos. Based on individuals (n = 573) from diverse Hispanic origins, one study identified 916 methylation sites that differ between ethnic subgroups (Mexican, Puerto Rican, Mixed Latino, Other Latino) [52]. Among those sites, 66% were associated with intrinsic factors (ancestry) and 34% were associated with extrinsic factors (e.g., cultural, economic, environmental, and social exposures) [52]. Compared to non-Latino whites, Latinos have increased risk for hypermethylation of some lung cancer-related tumor suppressor genes, for example, transcription factors that bind to the DNA sequence GATA, sulfatase 2 (SULF2), and protocadherin 20 (PCDH20) in exfoliated lung cells [53]. In global DNA, significantly lower levels of LINE-1 were found in Latinos relative to non-Latino whites [54]. A family history of breast cancer (mother with breast cancer susceptibility protein 1 [BRCA1] or BRCA2 mutations) influences lower LINE-1 methylation (18.8%, 95% CI = −42.7%, 5.1%), indicating DNA methylation as a marker of inherited breast cancer susceptibility among Latina women [55]. Thus, in Latinos, DNA methylation differs by a combination of factors, including genetic susceptibility, socioeconomic status, lifestyle factors, and the environment, suggesting an epigenetic biomarker for understanding cancer disparities.
Transcriptomics
Latino patients have been reported to experience a greater incidence of gastric cancer compared to Asians and Whites, and they have a greater proportion of genomically stable subtype tumors. Transcriptomic studies (whole-exome and RNA sequencing) revealed that 16% of patients possess unique molecular signatures, including a high proportion of cadherin 1 (CDH1) germline variants, which could be responsible for the aggressive gastric cancer phenotypes [56]. Transcriptomic studies of kidney cancer patients showed differential expression of almost 300 genes between tumors with different stage, size, and stage of kidney tumors, while advanced stage tumors showed overexpression of glucose-6-phosphate dehydrogenase (G6PD), amyloid-like protein 1 (APLP1), glucosaminyl (N-acetyl) transferase 3, mucin type (GCNT3), and phospholipid phosphatase 2 (PLPP2) genes [57].
Proteomics
A proteomics study of Puerto Rican CRC patients revealed lower frequency of microsatellite instability (MSI)-related proteins, which result from DNA mismatch repair genes (MMR). Higher prevalence of the mismatch repair gene MutL homolog 1, colon cancer, nonpolyposis type 2 (MLH1) was found in 6–9% of colon tumors [58].
Metabolomics
In a study on plasma metabolic profiling of breast cancer patients, Zhao et al. [59] reported that 14 metabolites showed a significant difference between Latino and non-Latino African American women. The identified metabolites were associated with citrate cycle, arginine-, proline-, and linoleic acid metabolic pathways.
Lipidomics
No studies have been done on altered lipid profiles in US-based Latino breast cancer patients. However, lipidomic and metabolomic fingerprints of Latina women from Columbia who had breast cancer revealed a specific pattern of metabolites that were associated with glycerolipid, glycerophospholipid, amino acid, and fatty acid metabolism. These profiles were similar but not identical to those from non-Latina women [60].
Knowledge Gaps and Future Directions
The trans-omics approach, also known as multi-omics, poly-omics, and pan-omics, embraces integration of multidimensional omics data to provide a comprehensive assessment of a cancer in question [61]. This is an interesting approach to adopt because the etiology of a disease such as cancer is complex owing to its multiple causative factors. Single-level omics approaches help in identifying specific cancer-related mutations, epigenetic changes, and molecular characterization of tumors to different subtypes on the basis of gene–protein expressions. However, multi-omics approaches offer several advantages as they can dissect cancer cells in multiple dimensions and probe deeper to bring into light the mechanisms (molecular and biochemical) that underlie different phenotypes of a particular cancer. Additionally, these strategies can not only examine the response to suspected causative agent (carcinogen) exposure but also to chemo- and/or immunotherapies. Another beneficial outcome of these trans-omics approaches is the discovery of new diagnostic/prognostic markers for various types of cancer [62].
One shortcoming in assessing cancer disparities in Latinos is viewing health outcomes as a whole instead of taking subgroup heterogeneity into consideration [63]. Given the fact that Latinos comprise European, Native American (Amerindian), and African ancestries [23], assessing health disparities among Latinos is a daunting task. In this context, employing the trans-omics approach is expected to yield robust information.
These advantages aside, the trans-omics approach has some challenges as well. Each omics cancer dataset by itself is complex for reasons such as the quality of output in analytical platform and heterogeneity of data [64]. Issues pertaining to processing these enormous data volumes could be resolved by the Big Data to Knowledge (BD2K) technologies mentioned in Paten et al. [65] and Juarez et al. [66].
Another research area worth considering from a trans-omics perspective is the microbiome. Microbiota of the gut has been implicated in cancer [67]. Microbes contribute to cancer both in direct and indirect ways. While some microbes such as the bacterium Helicobacter pylori contribute to gastric cancer and some viruses such as HPV and HIV contribute to cervical cancers, other microbes contribute to cancer through altered metabolism. However, the role of microbiome in cancer is not completely understood and may require additional investigations [68].
References
Wild CP. Complementing the genome with an “exposome”: the outstanding challenge of environmental exposure measurement in molecular epidemiology. Cancer Epidemiol Biomark Prev. 2005;14(8):1847–50. https://doi.org/10.1158/1055-9965.Epi-05-0456.
Juarez PD. (2019). The public health exposome. In Unraveling the Exposome (pp. 23–61). Springer, Cham. https://doi.org/10.1007/978-3-319-89321-1_2
Juarez PD, Matthews-Juarez P, Hood DB, Im W, Levine RS, Kilbourne BJ, et al. The public health exposome: a population-based, exposure science approach to health disparities research. Int J Environ Res Public Health. 2014;11(12):12866–95. https://doi.org/10.3390/ijerph111212866.
Miller GW, Jones DP. The nature of nurture: refining the definition of the exposome. Toxicol Sci. 2014;137(1):1–2. https://doi.org/10.1093/toxsci/kft251.
Agache I, Miller R, Gern JE, Hellings PW, Jutel M, Muraro A, et al. Emerging concepts and challenges in implementing the exposome paradigm in allergic diseases and asthma: a Practall document. Allergy. 2019;74(3):449–63. https://doi.org/10.1111/all.13690.
Juarez PD, Matthews-Juarez P. Applying an exposome-wide (ExWAS) approach to cancer research. Front Oncol. 2018;8:313. https://doi.org/10.3389/fonc.2018.00313.
Juarez PD, Tabatabai M, Valdez RB, Hood DB, Im W, Mouton C, et al. The effects of social, personal, and behavioral risk factors and PM2.5 on cardio-metabolic disparities in a cohort of community health center patient. Int J Environ Res Public Health. 2020;17:3561.
American Cancer Society. Cancer facts & figures for Hispanics/Latinos 2018–2020. Atlanta: American Cancer Society, Inc.; 2018.
Miller K, Goding Sauer A, Ortiz A, Fedewa S, Pinheiro P, Tortolero-Luna G, et al. Cancer statistics for Hispanics/Latinos, 2018. CA Cancer J Clin. 2018;68(9):425–45. https://doi.org/10.3322/caac.21494.
Pinheiro PS, Callahan KE, Koru-Sengul T, Ransdell J, Bouzoubaa L, Brown CP, et al. Risk of cancer death among white, black, and Hispanic populations in South Florida. Prev Chronic Dis. 2019;16:E83. https://doi.org/10.5888/pcd16.180529.
Steuer C, Behera M, Berry L, Kim S, Rossi M, Sica G, et al. Role of race in oncogenic driver prevalence and outcomes in lung adenocarcinoma: results from the Lung Cancer Mutation Consortium. Cancer. 2016;122(5):766–72. https://doi.org/10.1002/cncr.29812.
Moore JX, Royston KJ, Langston ME, Griffin R, Hidalgo B, Wang HE, et al. Mapping hot spots of breast cancer mortality in the United States: place matters for Blacks and Hispanics. Cancer Causes Control. 2018;29(8):737–50. https://doi.org/10.1007/s10552-018-1051-y.
Rodriguez-Velazquez A, Velez R, Lafontaine JC, Colon-Echevarria CB, Lamboy-Caraballo RD, Ramirez I, et al. Prevalence of breast and ovarian cancer subtypes in Hispanic populations from Puerto Rico. BMC Cancer. 2018;18(1):1177. https://doi.org/10.1186/s12885-018-5077-z.
Centers for Disease Control and Prevention. Web-based injury statistics query and reporting system (WISQARS) 2020. http://www.cdc.gov/injury/wisqars/fatal.html. Accessed 23 June 2020.
Ramirez AG, Muñoz E, Parma DL, Michalek JE, Holden AEC, Phillips TD, et al. Lifestyle and clinical correlates of hepatocellular carcinoma in South Texas: a matched case-control study. Clin Gastroenterol Hepatol. 2017;15(8):1311–2. https://doi.org/10.1016/j.cgh.2017.03.022.
Ramirez AG, Munoz E, Holden AEC, Adeigbe RT, Suarez L. Incidence of hepatocellular carcinoma in Texas Latinos, 1995–2010: an update. PLoS One. 2014;9(6):e99365.
Wu HC, Santella R. The role of aflatoxins in hepatocellular carcinoma. Hepat Mon. 2012;12(10HCC):e7238.
Ha J, Chaudhri A, Avirineni A, Pan JJ. Burden of hepatocellular carcinoma among Hispanics in South Texas: a systematic review. Biomark Res. 2017;5(15). https://doi.org/10.1186/s40364-017-0096-5.
Ramírez-Amill R, Soto-Salgado M, Vázquez-Santos C, Corzo-Pedrosa M, Cruz-Correa MR. Assessing colorectal cancer knowledge among Puerto Rican Hispanics: implications for cancer prevention and control. J Community Health. 2017;42(6):1141–7. https://doi.org/10.1007/s10900-017-0363-2.
Robles A, Bashashati M, Contreras A, Chávez LO, Cerro-Rondón AD, Cu C, et al. Colorectal cancer in Hispanics living near the U.S.-Mexico border. Rev Invest Clin. 2019;71(5):306–10. https://doi.org/10.24875/RIC.19003026.
Gonzales M, Qeadan F, Mishra SI, Rajput A, Hoffman RM. Racial-ethnic disparities in late-stage colorectal cancer among Hispanics and Non-Hispanic Whites of New Mexico. Hisp Health Care Int. 2017;15(4):180–8. https://doi.org/10.1177/1540415317746317.
Chattar-Cora D, Onime GD, Coppa GF, Valentine IS, Rivera L. Anatomic, age, and sex distribution of colorectal cancer in a New York City Hispanic population. J Natl Med Assoc. 1998;90(1):19–24.
Stern MC. Prostate cancer in US Latinos; what have we learned and where should we focus our attention. In: Ramirez AG, Trapido EJ, editors. Advancing the science of cancer in Latinos. Cham: Springer; 2020. p. 57–67.
Dobbs RW, Malhotra NR, Abern MR, Moreira DM. Prostate cancer disparities in Hispanics by country of origin: a nationwide population-based analysis. Prostate Cancer Prostatic Dis. 2019;22(1):159–67. https://doi.org/10.1038/s41391-018-0097-y.
Tortolero-Luna G, Torres-Cintrón CR, Alvarado-Ortiz M, Ortiz-Ortiz KJ, Zavala-Zegarra DE, Mora-Piñero E. Incidence of thyroid cancer in Puerto Rico and the US by racial/ethnic group, 2011–2015. BMC Cancer. 2019;19(1). https://doi.org/10.1186/s12885-019-5854-3.
Estrada-Florez AP, Bohórquez ME, Sahasrabudhe R, Prieto R, Lott P, Duque CS, et al. Clinical features of Hispanic thyroid cancer cases and the role of known genetic variants on disease risk. Medicine. 2016;95(32):e4148. https://doi.org/10.1097/MD.0000000000004148.
Clarke MA, Devesa SS, Harvey SV, Wentzensen N. Hysterectomy-corrected uterine corpus cancer incidence trends and differences in relative survival reveal racial disparities and rising rates of nonendometrioid cancers. J Clin Oncol. 2019;37(22):1895–908. https://doi.org/10.1200/JCO.19.00151.
Mann L, Foley KL, Tanner AE, Sun CJ, Rhodes SD. Increasing cervical cancer screening among US Hispanics/Latinas: a qualitative systematic review. J Cancer Educ. 2015;30(2):165–8.
Eng TY, Chen T, Vincent J, Patel AJ, Clyburn V, Ha CS. Persistent disparities in Hispanics with cervical cancer in a major city. J Racial Ethn Health Disparities. 2017;4(2):165–8.
Ortiz AP, Engels EA, Nogueras-González GM, Colón-López V, Soto–Salgado M, Vargas A, et al. Disparities in human papillomavirus-related cancer incidence and survival among human immunodeficiency virus-infected Hispanics living in the United States. Cancer. 2018;124(23):4520–8.
Kelly RS, Vineis P. Biomarkers of susceptibility to chemical carcinogens: the example of non-Hodgkin lymphomas. Br Med Bull. 2014;111(1):89–100. https://doi.org/10.1093/bmb/ldu015.
Grebenshchikov IS, Studennikov AE, Ivanov VI, Ivanova NV, Titov VA, Vergbickaya NE, et al. Idiotypic and anti-idiotypic antibodies against polycyclic aromatic hydrocarbon in human blood serum are new biomarkers of lung cancer. Oncotarget. 2019;10(49):5070–81.
Barocas DA, Motley S, Cookson MS, Chang SS, Penson DF, Dai Q, et al. Oxidative stress measured by urine F2-isoprostane level is associated with prostate cancer. J Urol. 2011;85(6):2102–7. https://doi.org/10.1016/j.juro.2011.02.020.
Zhou B, Liu J, Wang ZM, Xi T. C-reactive protein, interleukin 6 and lung cancer risk: a meta-analysis. PLoS One. 2012;7(8):e43075. https://doi.org/10.1371/journal.pone.0043075.
Yang Y, Meng WJ, Wang ZQ. MicroRNAs in colon and rectal cancer--novel biomarkers from diagnosis to therapy. Endocr Metab Immune Disord Drug Targets. 2020. Published online ahead of print, 2020 May 5. https://doi.org/10.2174/1871530320666200506075219.
Knox SS. From ‘omics’ to complex disease: a systems biology approach to gene-environment interactions in cancer. Cancer Cell Int. 2010;10(11). https://doi.org/10.1186/1475-2867-10-11.
Cress WD, Chiappori A, Santiago P, Muñoz-Antonia T. Lung cancer mutations and use of targeted agents in Hispanics. Rev Recent Clin Trials. 2014;9(4):225–32. https://doi.org/10.2174/1574887110666150127103555.
Schmit SL, Schumacher FR, Edlund CK, Conti DV, Ihenacho U, Wan P, et al. Genome-wide association study of colorectal cancer in Hispanics. Carcinogenesis. 2016;37(6):547–56. https://doi.org/10.1093/carcin/bgw046.
Hoffman J, Fejerman L, Hu D, Huntsman S, Li M, John EM, et al. Identification of novel common breast cancer risk variants at the 6q25 locus among Latinas. Breast Cancer Res Treat. 2019;21(1):3. https://doi.org/10.1186/s13058-018-1085-9.
Jaenisch R, Bird A. Epigenetic regulation of gene expression: how the genome integrates intrinsic and environmental signals. Nat Genet. 2003;33(Suppl):345–54.
Dor Y, Cedar H. Principles of DNA methylation and their implications for biology and medicine. Lancet. 2018;392(10149):777–86.
Luo C, Hajkova P, Ecker JR. Dynamic DNA methylation: in the right place at the right time. Science. 2018;361(6409):1336–40.
Ehrlich M. DNA hypomethylation in cancer cells. Epigenomics. 2009;1(2):239–59.
Joyce BT, Gao T, Zheng Y, Liu L, Zhang W, Dai Q, et al. Prospective changes in global DNA methylation and cancer incidence and mortality. Br J Cancer. 2016;115(4):465–72.
King WD, Ashbury JE, Taylor SA, Yat Tse M, Pang SC, Louw JA, et al. A cross-sectional study of global DNA methylation and risk of colorectal adenoma. BMC Cancer. 2014;14:488.
Saghafinia S, Mina M, Riggi N, Hanahan D, Ciriello G. Pan-cancer landscape of aberrant DNA methylation across human tumors. Cell Rep. 2018;25(4):1066–80.
Fan J, Li J, Guo S, Tao C, Zhang H, Wang W, et al. Genome-wide DNA methylation profiles of low- and high-grade adenoma reveals potential biomarkers for early detection of colorectal carcinoma. Clin Epigenetics. 2020;12(1):56.
Ding W, Chen G, Shi T. Integrative analysis identifies potential DNA methylation biomarkers for pan-cancer diagnosis and prognosis. Epigenetics. 2019;14(1):67–80.
Hao X, Luo H, Krawczyk M, Wei W, Wang W, Wang J, et al. DNA methylation markers for diagnosis and prognosis of common cancers. Proc Natl Acad Sci U S A. 2017;114(28):7414–9.
Yang Y, Wu L, Shu XO, Cai Q, Shu X, Li B, et al. Genetically predicted levels of DNA methylation biomarkers and breast cancer risk: data from 228 951 women of European descent. J Natl Cancer Inst Monogr. 2020;112(3):295–304.
Yang Y, Wu L, Shu X, Lu Y, Shu XO, Cai Q, et al. Genetic data from nearly 63,000 women of European descent predicts DNA methylation biomarkers and epithelial ovarian cancer risk. Cancer Res. 2019;79(3):505–17.
Galanter JM, Gignoux CR, Oh SS, Torgerson D, Pino-Yanes M, Thakur N, et al. Differential methylation between ethnic sub-groups reflects the effect of genetic ancestry and environmental exposures. Elife. 2017;6:e20532.
Leng S, Liu Y, Thomas CL, Gauderman WJ, Picchi MA, Bruse SE, et al. Native American ancestry affects the risk for gene methylation in the lungs of Hispanic smokers from New Mexico. Am J Respir Crit Care Med. 2013;188(9):1110–6.
Zhang FF, Cardarelli R, Carroll J, Fulda KG, Kaur M, Gonzalez K, et al. Significant differences in global genomic DNA methylation by gender and race/ethnicity in peripheral blood. Epigenetics. 2011;6(5):623–9.
Delgado-Cruzata L, Wu HC, Liao Y, Santella RM, Terry MB. Differences in DNA methylation by extent of breast cancer family history in unaffected women. Epigenetics. 2014;9(2):243–8.
Wang SC, Yeu Y, Hammer STG, Xiao S, Zhu M, Hong C, et al. Adenocarcinoma have distinct molecular profiles including a high rate of germline CDH1 variants. Cancer Res. 2020;80(11):2114–24. https://doi.org/10.1158/0008-5472.CAN-19-2918.
Batai K, Imler E, Pangilinan J, Bell R, Lwin A, Price E, et al. Whole-transcriptome sequencing identified gene expression signatures associated with aggressive clear cell renal cell carcinoma. Genes Cancer. 2018;9(5–6):247–56. https://doi.org/10.18632/genesandcancer.183.
Reverón D, López C, Gutiérrez S, Sayegh ZE, Antonia T, Dutil J, et al. Frequency of mismatch repair protein deficiency in a Puerto Rican population with colonic adenoma and adenocarcinoma. Cancer Genomics Proteomics. 2018;15(4). https://doi.org/10.21873/cgp.20084.
Zhao H, Shen J, Moore SC, Ye Y, Wu X, Esteva FJ, et al. Breast cancer risk in relation to plasma metabolites among Hispanic and African American women. Breast Cancer Res Treat. 2019;6(3). https://doi.org/10.1007/s10549-019-05165-4687-96.
Cala MP, Aldana J, Medina J, Sánchez J, Guio J, Wist J, et al. Multiplatform plasma metabolic and lipid fingerprinting of breast cancer: a pilot control-case study in Colombian Hispanic women. PLoS One. 2018;13(2):e0190958. https://doi.org/10.1371/journal.pone.0190958.
Srivastava A, Kulkarni C, Mallick P, Huang K, Machiraju R. Building trans-omics evidence: using imaging and ‘omics’ to characterize cancer profiles. Pac Symp Biocomput. 2018;26:377–87.
Chakraborty S, Hosen MI, Ahmed M, Shekhar HU. Onco-multi-OMICS approach: a new frontier in cancer research. Biomed Res Int. 2018:9836256(e-collection). https://doi.org/10.1155/2018/9836256.
Velasquez MC, Chinea FM, Kwon D, Prakash NS, Barboza MP, Gonzalgo ML, et al. The influence of ethnic heterogeneity on prostate cancer mortality after radical prostatectomy in Hispanic or Latino men: a population-based analysis. Urology. 2018;117:108–14. https://doi.org/10.1016/j.urology.2018.03.036.
Buescher JM, Driggers EM. Integration of omics: more than the sum of its parts. Cancer Metab. 2016;4(4). https://doi.org/10.1186/s40170-016-0143-y.
Paten B, Diekhans M, Druker BJ, Friend S, Guinney J, Gassner N, et al. The NIH BD2K center for big data in translational genomics. J Am Med Inform Assoc. 2015;22(6):1143–7. https://doi.org/10.1093/jamia/ocv047.
Juarez PD, Hood DB, Song MA, Ramesh A. Use of an exposome approach to understand the effects of exposures from the natural, built, and social environments on cardio-vascular disease onset, progression, and outcomes. Front Public Health. 2020;17(10):3661. https://doi.org/10.3390/ijerph17103561.
Schwabe RF, Jobin C. The microbiome and cancer. Nat Rev Cancer. 2013;13(11):800–12. https://doi.org/10.1038/nrc3610.
Xavier JB, Young VB, Skufca J, Ginty F, Testerman T, Pearson AT, et al. The cancer microbiome: distinguishing direct and indirect effects requires a systemic view. Trends Cancer. 2020;8(3):192–204. https://doi.org/10.1016/j.trecan.2020.01.004.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this chapter

Cite this chapter
Juarez, P.D., Hood, D.B., Song, Ma., Ramesh, A. (2023). Applying an Exposome-wide Association Study (ExWAS) Approach to Latino Cancer Disparities. In: Ramirez, A.G., Trapido, E.J. (eds) Advancing the Science of Cancer in Latinos. Springer, Cham. https://doi.org/10.1007/978-3-031-14436-3_2
Download citation
DOI: https://doi.org/10.1007/978-3-031-14436-3_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-14435-6
Online ISBN: 978-3-031-14436-3
eBook Packages: MedicineMedicine (R0)