
Abstract
This chapter reviews a number of typical combinatorial optimization problems. It illustrates the tenuous border that sometimes exists between an easy problem, for which effective algorithms are known, and an intractable one that differs merely by a small detail that may appear innocuous at first sight
You have full access to this open access chapter, Download chapter PDF
After reviewing the main definitions of graph theory and complexity theory, this chapter reviews several combinatorial optimization problems. Some of these are easy, but adding a seemingly trivial constraint can make them difficult. We also briefly review the operating principle of simple algorithms for solving some of these problems. Indeed, some of these algorithms, producing a globally optimal solution for easy problems, have strongly inspired heuristic methods for intractable ones; in this case, they obviously do not guarantee that an optimal solution is obtained.
1 Optimal Trees
Finding a connected sub-graph of optimal weight is a fundamental problem in graph theory. Many applications require discovering such a structure as a preliminary step. A typical example is the search for a minimum cost connected network (water pipes, electrical cables). Algorithmic solutions to this type of problem were already proposed in the 1930s [1, 2].
1.1 Minimum Spanning Tree
The minimum spanning tree problem can be formulated as follows: given an undirected network R = (V, E, w) on a set V of vertices, a set E of edges with a weight function \(w \rightarrow \mathbb {R}\), we are looking for a connected, cycle-free subset whose total edge weight is as small as possible. Mathematically, the minimum spanning tree problem is not so simple to formulate. An integer linear program containing an exponential number of constraints is:
where E(S) is the subset of edges with both ends in the vertex subset S.
The variables x e are constrained to be binary by (2.2). They indicate if edge e is part of the tree (x e = 1) or not (x e = 0). Constraint (2.3) ensures that enough edges are selected for ensuring connectivity. Constraints (2.4) eliminate the cycles in the solution. Such a mathematical model cannot be used as is, since the number of constraints is far too large. It can be used interactively. The problem is solved without cycle elimination constraints. If the solution contains a cycle on the vertices of a subset S, the constraint that eliminates it is specifically added before restarting.
Such an approach is fastidious. Fortunately, there are very simple methods for finding a minimum spanning tree. The most famous algorithms to solve this problem are those of Kruskal and Prim. They are both based on a greedy method. Greedy algorithms are discussed in Sect. 4.3. They build a solution incrementally from scratch. At each step, an element is included in the structure in construction, never changing the choice of this element later.
The Kruskal Algorithm 2.2 starts with a graph \(T = (V, E_T = \varnothing )\). It successively adds an edge of weight as low as possible to E T while ensuring no cycle is created.
Algorithm 2.1: (Kruskal) Building a minimum spanning tree. Efficient implementations use a special data structure for managing disjoint datasets. This is required to test if the tentative edge to add is part of the same connected component or not. In this case, the complexity of the algorithm is O(|E| log |E|)

Algorithm 2.2: (Jarník) Building a minimum spanning tree. The algorithm was later rediscovered by Prim and by Dijkstra. It is commonly referred to as Prim or Prim-Dijkstra algorithm. For an efficient implementation, an adequate data structure must be used to extract the vertex of L with the smallest weight (Line 8) and to change the weights (Line 14). A Fibonacci heap or a Brodal queue allow an implementation of the algorithm in \(O(|E| + |V|\log \ |V|)\)

The Prim Algorithm 2.2 starts with a graph \(T = (V' = \{s\}, E_T = \varnothing )\) and successively adds a vertex v to V ′ and an edge e to E T, such that the weight of e is as low as possible and one of its ends is part of V ′ and the other not. Put differently, Kruskal starts with a forest with as many trees as there are vertices and seeks to merge all these trees into a single one while Prim starts with a tree consisting of a single vertex and seeks to make it growing until comprising all vertices.
1.2 Steiner Tree
The Steiner tree problem is very close to that of the minimum spanning tree. The sole difference is that the vertices of a subset S ⊂ V must not necessarily appear in the tree. S is the set of Steiner vertices. The other ones that must belong to the tree are designated as terminal vertices. The Euclidean version of the Steiner tree is to connect a given set of terminal points on the plane by lines whose length is as short as possible. Figure 2.1 shows the minimum spanning tree, using solely the edges directly connecting the terminals and a Steiner tree. The weight of the minimum spanning tree may be larger than that of a Steiner tree where appropriately Steiner nodes are added. The combinatorial choice of vertices to add makes the problem NP-hard.

Minimum spanning tree using only terminal nodes, which are, therefore, directly connected to each other and minimum weight Steiner tree, where additional nodes can be used
2 Optimal Paths
Searching for optimal paths is as old as the world. Everyone is aware of this problem, especially since cars are built with a navigation system. Knowing the current position on a transport network, the aim is to identify the best route to a given destination. The usual criterion for the optimality of the path is time, but it can also be distance, especially if it is a walking route.
2.1 Shortest Path
Formally, let R = (V, E, w) be a directed network. We want to find a shortest walk starting at node s and ending at node t. Naturally, “shortest” is an abuse of language and designates the sum of the edge weight. The lasts can represent something other than a distance, such as a time, energy consumption, etc. Considering the algorithmic complexity, it is not more expensive to find the optimum walks from a particular node s to, or from all the vertices of V .
This formulation can be problematic in the case of a general weighting function. Indeed, if there are negative weights, the shortest walk may not exist if one has a negative length circuit. Dijkstra’s algorithm is the most effective one to discover the shortest path in a network where the weighting function is not negative: \(w(e)~\geqslant ~0\ \forall e \in E\). It is formalized by Algorithm 2.3.
Algorithm 2.3: (Dijkstra) Searching for a shortest path from s to all other nodes in a non-negative weighting network. The red color highlights the two differences between this algorithm and Prim’s one (Algorithm 2.2)

The idea behind this algorithm is to store, in a set L, the vertices for which the shortest path from the starting vertex s has not yet been definitively identified. A value λ i is associated with each vertex i. This value represents the length of an already discovered path from s. Since we suppose non-negative weights, the node i ∈ L with the smallest value is a new vertex for which the shortest path is definitively known. The node i can, therefore, be removed from L while checking whether its adjacent vertices could be reached with a shorter path passing through i.
For an efficient implementation, an adequate data structure must be used to extract the vertex of L with the smallest value (Line 8) and to change the values (Line 12) of its adjacent nodes. Similarly to Prim’s Algorithm 2.3, a Fibonacci heap or a Brodal queue allows an implementation of the algorithm in \(O(|E| + |V| \log \ |V|)\).
It is interesting to highlight the significant similarity between this algorithm and that of Prim 2.2 for finding a minimum spanning tree. The recipe that worked for this problem still works, with some restrictions, for discovering a shortest path. The general framework of the greedy methods, on which this recipe is based, is presented in Sect. 4.3 of the chapter devoted to constructive methods. Code 2.1 provides an implementation of Dijkstra’s algorithm, in case the network is dense enough for reasonably specifying it with a square matrix.
Code 2.1 dijkstra.py Implementation of Dijkstra’s algorithm for a complete network specified by a matrix (d ij) providing the weight of each arc (i, j). In this case, managing L with a simple array is optimal

Also note that Code 4.3 implements one of the most popular greedy heuristics for the traveling salesman problem. It displays exactly the same structure as Code 2.1.
When the weights can be negative, the shortest walk exists only if there is no negative length circuit in the network. Written differently, this walk must be a simple path. A more general algorithm to find shortest paths was proposed by Bellman and Ford (see Algorithm 2.4). It is based on verifying, for each arc, that the Bellman conditions are satisfied: \(\lambda _j \leqslant \lambda _i + w(i,j)\). In other words, the length of the path from s to j should not exceed that of s to i plus the length of the arc (i, j). If it were the case, there would be an even shorter path up to j, passing through i.
Algorithm 2.4: (Bellman–Ford) Finding shortest paths from s to all other nodes in any network. The algorithm indicates if the network has a negative length circuit accessible from s, which means that the (negative) length of the shortest walk is unbounded. This algorithm is excessively simple to implement (the code is hardly longer than the pseudo-code provided here). Its complexity is in O(|E||V |)

The working principle of this algorithm is completely different from the greedy algorithms we have seen so far. Rather than definitively including an element to a partial solution at each step, the idea is to try to improve a complete starting solution. The last can be a very bad one, easy to build. The general framework of this algorithm is that of a local improvement method. At each step of the algorithm, the Bellman conditions are checked for all the arcs. If they are satisfied, all the shortest paths have been found. If one finds a vertex j for which λ j > λ i + w(i, j), the best path known to the node j is updated by storing the node i as its predecessor. Making such a modification can invalidate the Bellman conditions for other arcs. It is, therefore, necessary to check again, for all arcs, if a modification has no domino effect.
A question arises: without further precaution, does an algorithm based on this labeling update stop for any entry? The answer is no: if the network has a negative length circuit, there are endless modifications. In case the network does not have a negative length circuit, the algorithm stops after a maximum of |V | scans of the Bellman conditions for all the arcs of E. Indeed, if a shortest path exists, its number of arcs is at most |V |− 1. Each scan of the arcs of E definitively fixes a value satisfying the Bellman condition for at least one vertex.
The Bellman–Ford algorithm is based on an improvement method with a well-defined stopping criterion: if there are still values updated after |V | steps, then the network has a negative length circuit and the algorithm stops. If a scan finds out that the Bellman conditions are satisfied for all the arcs, then all the shortest paths are identified and the algorithm stops.
Seeking optimal paths appears in many applications, especially in project planning and scheduling. The problems that can be solved by dynamic programming can be formulated as finding an optimal path in a layered network. This technique uses the special network topology to find the solution without having to explicitly construct the network.
2.1.1 Linear Programming Formulation of the Shortest Path
It is relatively easy to formulate the problem of finding the shortest path from a vertex s to a vertex t in a network under the form of a linear program. For this purpose, a variable x ij is introduced for each arc (i, j) to indicate whether the last is part of the shortest path. The formulation below may seem incomplete: indeed, the variables x ij should either take the value 0 (indicating the arc (i, j) is not part of the shortest path) or the value 1 (the arc is part of it). Constraints (2.8) are sufficient: if a variable receives a fractional value in the optimal solution, it means there are several shortest paths from s to t. Constraint (2.7) imposes that there is a unit “quantity” arriving in t. This amount can be split inside the network, but each fraction must use a shortest path. Constraints (2.6) impose that the quantity arriving at any intermediate node j must depart from it. It is not required to explicitly impose that a unit quantity leaves s. Such a constraint would be redundant with (2.7). The objective (2.5) is to minimize the cost of the arcs retained.
Another formulation of this problem is to directly look for the lengths λ i of the shortest paths by imposing the Bellman conditions. This leads to the following linear program, which is the dual of the previous one.
Duality carries out a significant role in linear programming. Indeed, it is shown that any feasible solution to the primal problem has a value that cannot be lower than a feasible solution value to the dual. If a feasible solution value to the primal problem exactly reaches a feasible solution value to the dual, then both solutions are optimal. For the shortest path problem, the optimal λ t value corresponds to the sum of the lengths of the arcs that must be used in an optimum path from s to t.
2.2 Elementary Shortest Path: Traveling Salesman
The shortest walk problem is poorly defined, because of the negative length circuits. However, one could add a very natural constraint, which makes it perfectly defined: look for the shortest elementary path from a particular node s to all the others. It is recalled that an elementary path visits each vertex at most once. In this case, even if there are negative length circuits, the problem has a finite solution. Unfortunately, adding this little constraint makes the problem difficult. Indeed, it can be shown that the traveling salesman problem, notoriously NP-hard, can transform polynomially into the elementary shortest path problem.
The traveling salesman problem (TSP) is the archetype of hard combinatorial optimization, on the one hand, because of the simplicity of its formulation and, on the other hand, because it appears in many applications, particularly in vehicle routing.
The first practical application of the traveling salesman problem is clearly finding a shortest tour for a trading clerk. In the nineteenth century, Voigt edited a book exhibiting how to make a round trip in Germany and Switzerland [5].
There are many practical applications to this problem. For instance, Sect. 2.2.3, shows that vehicle routing implies solving many traveling salesman instances. As presented further (see Sect. 3.3.1), it can also appear in problems that have nothing to do with routing.
In combinatorial optimization, the TSP is most likely the one that has received the most attention. Large Euclidean instances—more than 10,000 nodes—have been optimally solved. There are solutions that do not deviate from more than a fraction of a percent from the optimum for instances with several million cities. Since this problem is NP-hard, there are much smaller examples that cannot be solved by exact solution methods. The TSP polynomially transforms into the shortest elementary path as follows.
A vertex is duplicated in two vertices s and t and the weight w(i, j) of all the arcs is replaced by w(i, j) − M, where M is a positive constant larger than the largest weight of an arc. If there is no arc between s and t, the shortest elementary path from s and t corresponds to a minimum tour length for the traveling salesman. Figure 2.2 illustrates the principle of this transformation. Knowing that the TSP is NP-hard, it proves that the shortest elementary path is NP-hard too.

Polynomial transformation from a traveling salesman into an elementary shortest path. Vertex 1 is duplicated and the weight of each edge is set to the original weight minus 50. Finding the shortest elementary path from s to t is equivalent to finding the optimal TSP tour in the original network
2.2.1 Integer Linear Programs for the TSP
There are numerous integer linear programs modeling the TSP. Two of the best known are presented here.
Dantzig-Fulkerson-Johnson The Dantzig-Fulkerson-Johnson formulation introduces an exponential number of sub-tour elimination constraints. The binary variables x ij take the value 1 if the arc (i, j) is used in the tour and 0 otherwise.
Constraints (2.14) impose to enter exactly once in each city. Constraints (2.15) impose to come out exactly once from each city. Constraints (2.16) ensures that no proper subset S contains a sub-tour.
Compared to the linear program for finding a minimum weight tree, it differs only in Constraints (2.14) and (2.15) which replace Constraint (2.3).
Miller–Tucker–Zemlin The Miller–Tucker–Zemlin formulation replaces the exponential number of constraints (2.16) by a polynomial number of constraints and introducing |V |− 1 continuous variables u i, (i = 2…|V |). The new variables provide tour ordering. If u i < u j, then city i is visited before city j. In this formulation, constraints (2.13)–(2.15) are retained and constraints (2.16) are replaced by:
This integer linear program is probably not the most efficient one, but it has relatively few variables and constraints.
2.3 Vehicle Routing
Problems using the traveling salesman as a sub-problem naturally appear in the vehicle routing problem (VRP). In its simplest form, the last can be formulated as follows: let V be a set of customers requesting quantities q i of goods (i = 1, …, |V |). They are delivered by a vehicle with capacity Q, starting from and returning to a warehouse d. The customers must be split into m subsets V 1, …V m such that \(\sum _{i \in V_i}{q_i} \leqslant Q\). For each subset V j ∪{d}, (j = 1, …, m), a traveling salesman tour as short as possible must be determined. Figure 2.3 illustrates a solution of a small VRP instance.

Vehicle routing problem instance. Trips from and to the warehouse are not drawn for not overloading the illustration. This solution was discovered by means of a taboo search, but it took decades before its optimality was proven. This gives an idea of the difficulty of the problem
This problem naturally occurs for delivering or collecting goods and in home service planning. In concrete applications, many complications exist:
-
The number m of tours can be fixed or minimized;
-
The maximum length of the tours can be limited;
-
The clients specify one or more time windows during which they should be serviced;
-
The goods can be split implying multiple passages at the same client;
-
A tour can both collect and deliver goods;
-
There is more than one warehouse;
-
Warehouses are hosting heterogeneous fleets of vehicles;
-
The warehouses locations can be chosen;
-
etc.
Since the problem is to find the service order of customers, the problem is also referred to as “Vehicle Scheduling.”
3 Scheduling
Scheduling is to determine the order to process a number of operations. Their processing consumes resources, for instance, time on a machine. Operations that need to be processed in a specific order are grouped into jobs. The purpose of scheduling is to optimize resource consumption. Various optimization criteria are commonly used: minimizing the makespan; minimizing the total time; minimizing the average delay; etc. A frequent constraint in scheduling is that a resource cannot perform several operations simultaneously and that two operations of a job cannot be performed simultaneously. Operations may include various features according to applications:
- Resource:
-
An operation must take place on a given resource or subset of resources or must require several resources simultaneously.
- Duration:
-
Processing an operation takes time, which may depend on the operating resource.
- Set-up time:
-
Before performing an operation, the resource requires a set-up time depending on the previously completed operation.
- Interrupt:
-
After an operation has started, it can be suspended before ending.
- Pre-emption:
-
A resource can interrupt an operation to process another one.
- Waiting time:
-
There can be either a waiting time between two successive operations of the same task or a waiting time is prohibited.
- Release date:
-
An operation cannot take place before being available.
- Deadline:
-
An operation cannot be processed after a given date.
In addition, resources may have a variety of features. They can be mobile in the case of carriers, resulting in colliding problems. There may be several machines of the same type, machines that can perform different operations, etc.
3.1 Permutation Flowshop Scheduling
A fundamental scheduling problem is the permutation flowshop. This problem occurs, for example, in an assembly line in which the n jobs must be successively processed on the machines 1, 2, …, m, in that order. A job j must, therefore, undergo m operations which take a time t ij, (i = 1, …, m, j = 1, …, n). The goal is to find the order to process the job in the assembly line. Written differently, to find a permutation of the job such that the last job on the last machine finishes as early as possible. There is a buffer that may store jobs between each machine. Hence, the jobs can possibly wait for the next machine to finish processing a job that has arrived earlier. A convenient way to represent a scheduling solution is the Gannt chart . The x-axis represents time and the y-axis represents resources.
Figure 2.4 provides both Gannt charts of a non-optimal solution, where each operation is planned as early as possible as well as an optimal scheduling where each operation starts as late as possible.

Permutation flowshop scheduling. Gantt chart for a small instance with 4 resources and 5 jobs. Top: non-optimal schedule with the earliest starting time for each operation. Bottom: optimal scheduling with the latest starting time
For problem instances with only 2 machines, there is a greedy algorithm finding an optimal solution to this problem. The operations are ordered by increasing durations and put in a list. The operation with the shortest duration is first selected. If this operation takes place on the first machine, the corresponding job is placed at the very beginning of the sequence. Else, if the operation takes place on the second machine, the job is placed at the very end of the sequence. The operation is removed from the list before examining the subsequent operation. The sequence is thus completed by dispatching the jobs either after the block processed at the beginning of the sequence or before the block at the end. As soon as the instance has more than 2 machines, the problem is NP-hard. A mixed integer linear program for the permutation flowshop is as follows:
Objective (2.19) is to minimize the makespan d ω. The variable d ij corresponds to the starting time of job j on machine i. Constraints (2.20) require that the end of the process of each object j on the last machine occurs not later than the makespan. A job j must have finished its processing on a machine i before being processed by the machine i + 1 (2.21). The y jk variables indicate whether the job j should be processed before the job k. Only n ⋅ (n − 1)∕2 of these y .. variables are introduced, since y kj should take the complementary value 1 − y jk. Both Constraints (2.22) and (2.23) involve a large constant M for expressing disjunctive constraints: either the job j is processed before the job k or k before j. If y jk = 1, j is processed before k and Constraints (2.23) are trivially satisfied for any machine i, provided M is large enough. Conversely, if y jk = 0, Constraints (2.22) are trivially satisfied while Constraints (2.23) require finishing the processing of k on the machine i before the latter can start the processing of j.
3.2 Jobshop Scheduling
The jobshop scheduling problem is somewhat more general. Each job undergoes a certain number of operations, each of them being processed by a given machine. The operation sequence for a job is fixed, but different jobs do not necessarily have the same sequence and the jobs are not required to be processed by all machines.
Figure 2.5 illustrates how to express this problem in terms of a graph: Each operation is associated with a vertex. Two fictitious vertices-operations are added: start (α) and end (ω). If operation k immediately follows operation i on the same job, an arc (i, j) is introduced. The length of the arc is t i, corresponding to the duration of operation i. Arcs of length 0 are added from start to the first operations of each job. Arcs with a length corresponding to the duration of the last operation of each job are connecting the end vertex.

Graph corresponding to the solution of a jobshop instance with three machines. One job undergoes 3 operations while two others have only 2. The weighting of the arcs corresponds to the duration of the corresponding operation. The arcs representing the precedence relations of the operations belonging to the same job are in dotted lines. The longest path from α to ω is shown in bold. It is referred to as the critical path
All operations taking place on the same machine are forming a clique. The goal of the problem is to direct the edges of these cliques to minimize the length of the longest path from start to end.
An integer linear program for the jobshop is as follows:
The variable d i is the starting time of operation i. The goal is to minimize the makespan d ω (the starting time of the dummy operation ω). Constraints (2.27) require that operation i must be completed before starting operation j if i precedes j for a given job. Constraints (2.28) require that the end of processing times for all operations precede the end of the project. The variables y ik associated with the disjunctive constraints (2.29) and (2.30) determine whether operation i precedes operation k, which takes place on the same machine.
4 Flows in Networks
The concept of flow arises naturally when considering material, people, or electricity that must be transported over a network. In each node one must have the equivalent to Kirchhoff’s current law: the amount of flow coming to a node must be equal to the amount going out of that node.
The most elementary form of flow problems is as follows. Let R = (V, E, w) be a network. Flows values x ij passing through the arcs (i, j) ∈ E are sought such that the sum of the flows issuing from a particular source-node s to reach a sink-node t is maximized. The conservation of flows must be respected: the sum of the flows entering a vertex must equal that of exiting the vertex, except for s and t. Then, the flows x ij cannot be negative and cannot exceed the positive value w(i, j) associated with the arcs. To solve this problem, Ford and Fulkerson proposed the relatively simple Algorithm 2.5.
Algorithm 2.5: (Ford and Fulkerson) Maximum flow from s to t

It is based on an improvement method: its start from a null flow (which is always feasible) increasing it at each step along a path from s to t until reaching the optimum flow. The first step of this algorithm is illustrated in Fig. 2.6. However, we can be blocked in a situation where there is no augmenting path from s to t while not having the maximal flow.

Representation of a flow problem in terms of graphs. An empty triangle indicates an unused flow capacity. A unit flow passing through an arc is indicated by a filled triangle. The Ford and Fulkerson algorithm starts from a null flow (top) and finds the largest increase along a path from s to t. For this example, the first path discovered is s − 1 − 2 − t. After augmenting the flow along this path, there is no direct augmenting path (bottom)
To overcome this difficulty, it should be noted that we can virtually increase the flow from a vertex j to a vertex i by decreasing it from i to j. Therefore, at each stage of the algorithm, a residual network is considered.
The last is built as follows: an arc (i, j) with capacity w(i, j) and with a flow x ij passing through is replaced by two arcs, one from the vertex i to j with capacity w(i, j) − x ij (only if this value is strictly positive) and the other one from j to i with capacity x ij. Figure 2.7 illustrates this principle.

Residual network associated with the flow of Fig. 2.6
Once a flow is found in the residual network, it is superimposed on the flow obtained previously. This is shown in Fig. 2.8.

The complexity of this algorithm depends on the network size. Indeed, we have to seek a path from s to t for each increasing flow. It also depends on the number of augmenting paths. Unluckily, the increase can be marginal in the worst case. For networks with integer capacities, the increase can be only 1. If the maximum capacity of an edge is m, the complexity of the algorithm is in O(m ⋅ (|E| + |V |)). If m is small, for example, if the capacity of all the arcs is 1, the Ford and Fulkerson algorithm is fast.
We will see in Sect. 2.8.1 how to solve the edge coloring problem of a bipartite graph by solving maximum flow problems in a network where all the capacities are 1. Its complexity can be significantly diminished by using a breadth-first search as a sub-algorithm to discover a path from s to t in the residual network. Hence, the flow is increased along the shortest path at each step. This improvement has been proposed by Edmonds and Karp.
Since the number of arcs of the path cannot decrease from one step to the next, no more than |E| steps are performed with a given number of arcs. Since the number of arcs of a path is between 1 and |V |, we deduce that the complexity can be reduced to O(|V ||E|2). In the case of a dense network (with |E|∈ O(|V 2|))), the complexity simplifies to O(|V |5). Many algorithms have been proposed for solving the maximum flow problem. For general networks, the algorithmic complexity has been recently reduced to O(|V ||E|).
For many applications, each unit of flow in arc (i, j) costs c(i, j). We, therefore, consider a network R = (V, E, w, c), where w(i, j) is the capacity of the arc (i, j) and c(i, j) the cost of a unit flow through this arc. Then arises the problem of the maximum flow at minimum cost. This problem can be solved with Algorithm 2.6 of Busacker and Gowen, provided the network does not contain a negative cost circuit.
Algorithm 2.6: (Busacker and Gowen) Maximum flow from s to t with minimum cost

As noted for the algorithms of Prim and Dijkstra, there is a very slight difference between Algorithms 2.5 and 2.6. Once more, we do not alter a winning formula! When constructing the residual network, the costs should be taken into account. If there is a flow x ij > 0 through the arc (i, j), then the residual network includes an arc (i, j) with capacity w(i, j) − x ij (provided this capacity is positive) with an unchanged cost c(i, j) and a reversed arc (j, i) with capacity x ij and cost − c(i, j).
In the general case, finding the maximum flow with minimum cost is NP-hard. Indeed, the TSP can be polynomially transformed into this problem. The transformation is similar to that of the shortest elementary path (see Fig. 2.2).
The algorithms for finding the optimal flows presented above can solve many problems directly related to flow management, like electric power distribution or transportation problems. However, they are chiefly exploited for solving assignment problems (see next Chapter for modeling the linear assignment as a flow problem).
5 Assignment Problems
Assignment or matching problems occur frequently in practice. This is to match the elements of two different sets like teachers to classes, symbols to keyboard keys, and tasks to employees.
5.1 Linear Assignment
The linear assignment problem can be formalized as follows. Given an n × n matrix of costs C = (c iu) each element i ∈ I must be assigned to an element u ∈ U (i, u = 1, …, n) in such a way that the sum of costs (2.33) is minimized. This problem can be modeled by an integer linear program:
Constraints (2.34) ensure to assign exactly one element of U to each element of I. Constraints (2.35) ensure to assign exactly one element of I to each element of U. Hence, these two sets of constraints ensure a perfect matching between the elements of I and U. The integrality constraint (2.36) prevents elements of I to share fractions of elements of U.
A more concise formulation of the linear assignment problem is to find a permutation p of the n elements of the set U which minimizes \(\sum _{i=1}^n{c_{i p_i}}\). The value p i is the element of U assigned to i.
5.2 Generalized Assignment
In some cases, it is not necessary to have a perfect matching. This is particularly the case if the size of the sets I and U differ. To fix the ideas, let I be a set of n tasks to be performed by a set U of m employees, with m < n. If employee u performs task i, the cost is c iu and the employee needs a time of w iu to perform this task. Each employee u has a time budget limited by t u.
This problem, called the generalized assignment problem, occurs in various practical situations. For instance, it is closely related to the distribution of the loads between vehicles for the vehicle routing problems presented in Sect. 2.2.3. The generalized assignment problem can be modeled by the integer linear program:
This small modification of the assignment problem makes it NP-hard.
5.3 Knapsack
A special case of the generalized assignment problem (see Exercise 2.9) is the knapsack problem. It is certainly the simplest NP-hard problem to formulate in terms of integer linear programming:
Items of volume v i and value c i, (i = 1, …, n) can be put into a knapsack of volume V . The volume of the items put in the knapsack cannot be larger than V . The value of the selected items must be maximized.
This problem is used in this book to illustrate the working principles of a few methods. The reader interested in knapsack problems and extensions like bin-packing, subset-sum, and generalized assignment can refer to [4].
5.4 Quadratic Assignment
There is another assignment problem where the elements of the set I have interactions with each other. An assignment chosen for an element i ∈ I has repercussions for the set of all the elements of I. Let us take the example of assigning n offices to a set of n employees.
In the linear assignment problem, the c iu values only measure the interest for the employee i to be assigned the office u. Assigning the office u to the employee i has no other consequence than the office u is no longer available for another employee. In practice, employees are required to collaborate, which causes them to have to move from one office to another. Let a ij be the frequency the employee i meets the employee j. Let b uv the travel time from office u to office v. If we assign the office v to the employee j and the office u to the employee i, the last loses a time given by a ij ⋅ b uv for traveling, on average. Minimizing the total time lost can be modeled by the following quadratic 0-1 program, where the variable x iu takes the value 1 if the employee i occupies the office u and the value 0 otherwise:
This formulation brings out the quadratic side of the objective due to the product of the variables x iu ⋅ x jv. Constraints (2.45)–(2.47) are typical for assignment problems. So, this problem is called the quadratic assignment problem. A more concise model is searching for a permutation p that minimizes
Many practical applications can be formulated as a quadratic assignment problem (QAP):
- Allocation of offices to employees:
-
This is the example just cited formerly.
- Allocation of blocks in an FPGA:
-
A Field Programmable Gate Array requires connecting logic blocks on a silicon chip. These blocks allow implementing logic equations, multiplexers, or memory elements. Configuring an FPGA starts by establishing the way the modules must be connected. This can be described by means of a routing matrix A = (a ij) which gives the number of connections between modules i and j. Next, each module i must be assigned a logic block p i on the chip. Since the signal propagation delay depends on the length of the links, the assignment must be carefully performed. Therefore, knowing the length b uv of the link between logic blocks u and v, the problem of minimizing the sum of the propagation times is a quadratic assignment problem.
- Configuring a keypad:
-
To enter text on a cellular phone keypad, the 26 letters of the alphabet, as well as space, have been assigned to the keys 0, 2, 3, …, 9. As standard, these 27 signs are distributed according to the configuration of Fig. 2.9a.
Fig. 2.9 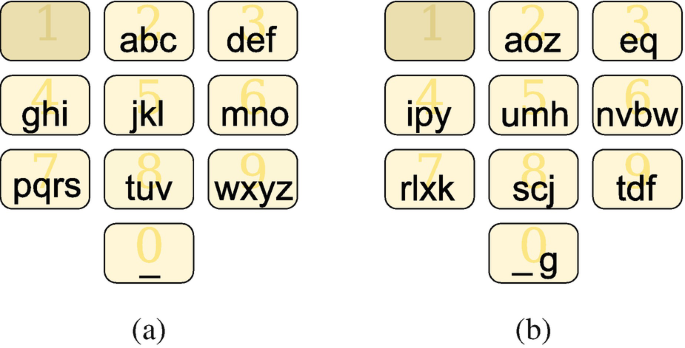
Standard cellular phone keyboard and keyboard optimized for the French language. (a) Standard keyboard. (b) Optimized keyboard
Assume that typing a key takes one unit of time, moving from one key to another takes two units of time, and finally that we have to wait 6 units of time before we can start typing a new symbol positioned on the same key. Then it takes 70 units of time to type the text “a ce soir bisous.”
Indeed, it takes 1 unit to enter the “a” on key 2, then moving to key 0 takes two units, then 1 unit to press once for space, then 2 units to move to key 2 again and 3 units for seizing “c,” etc. With the optimized keyboard (for the French language) given in Fig. 2.9, it takes only 51 units of time, almost a third less. This optimized keyboard was obtained by solving a quadratic assignment problem for which the a ij coefficients represent the frequency of occurrence of the symbol j after the symbol i in a typical text and b uv represents the time between the typing of a symbol placed in position u and another in position v.

The quadratic assignment problem is NP-hard. In practice, this is one of the most difficult of this class. Yet, examples of problems of size n = 30 are not optimally solved. Many NP-hard problems can be transformed into quadratic assignment problems. Without being exhaustive, let us mention the traveling salesman, the linear ordering, the graph bipartition or the stable set problems. Naturally, modeling one of these problems under the form of a quadratic assignment is undoubtedly not leading to the most efficient solving method!
6 Stable Set
Finding the largest independent set—maximal stable set—is a classical graph theory problem. This problem is NP-difficult. Section 1.2.3.4 presents a polynomial transformation of satisfiability into stable set. The latter is equivalent to finding the largest subset of mutually adjacent nodes—a maximum clique—in the complementary graph. A variant of the maximum stable set is the maximum weight stable set, when weights are associated with vertices. In this case, we are looking for a subset of independent vertices whose sum of the weights is as high as possible. Naturally, if the weights are all the same, this variant is equivalent to the maximum stable set.
This problem appears in several practical applications: map labeling, berth allocation to ships or assigning flight level to aircrafts. This is discussed in Sect. 3.3.3.
7 Clustering
Like graph theory, clustering is a very useful modeling tool. There is a myriad of applications of clustering. Let us quote social network analysis, medical imaging, market segmentation, anomaly detection, and data compression. Clustering or unsupervised classification consists in grouping items that are similar and separating those that are not. There are specific algorithms to perform these tasks automatically. Figure 2.10 gives an example of a large clustering instance where a decomposition method, such as those presented in Sect. 6.4.2 is required. Image compression by vector quantization involves dealing with instances with millions of elements and thousands of clusters.

Compression by vector quantization. An image compression technique creates clustering instances with millions of items and thousands of clusters. Here, the initial image was divided into blocks of b = 3 × 5 pixels. We next looked for a palette of 2k “colors” seen as vectors of length b × 3, each pixel being characterized by its red, green, and blue brightness. For this image, we chose k = 14. Two of the 214 = 16, 384 “colors” are shown. The palette was found with a clustering method, each color being a centroid. Each block of the initial image is replaced by the most similar centroid. As a block of the compressed image can be represented by k bits, k∕b bits are enough to encode one pixel
The supervised classification considers labeled items. It is frequently used in artificial neural networks. These techniques are outside the scope of this book, as are phylogenetic trees, popularized by Darwin in the nineteenth century.
Creating clusters supposes we can quantify the dissimilarity \(d(i, j) \geqslant 0\) between two elements i and j belonging to the set E we are trying to classify. Often, the function d(i, j) is a distance, (with symmetry: d(i, j) = d(j, i), separation: d(i, j) = 0 ⇔ i = j and triangular inequality: \(d(i,k) \leqslant d(i,j) + d(j,k)\)), but not necessarily. However, to guarantee the stability of the algorithms, let us suppose that \(d(i, j) \geqslant 0\) and d(i, i) = 0, ∀i, j ∈ E. As soon as we have such a function, the homogeneity of a group G ⊂ E can be measured. Several definitions have been proposed. Figure 2.11 shows some dissimilarity measures for a group of 3 elements.

Optimal points for various homogeneity measures of a group with 3 elements in \(\mathbb {R}^2\)
- Diameter of a group :
-
Maximum value of the function d(i, j) for two entities i and j belonging to G: max i,j ∈ G d(i, j).
- Star :
-
Sum of the dissimilarities between the most representative element of G and the others: min j∑i ∈ G d(i, j). When this element j must be in G, j is called a medoid. For instance, if the elements are characterized by two numeric values and G = {(0, 1), (3, 3), (5, 0)}, the point j of \(\mathbb {R}^2\) minimizing the sum of the dissimilarities is \((5/2+1/\sqrt {12}, 1/2+5/\sqrt {12})\) with norm l 1 whereas it is the point (8∕3, 4∕3) if we consider the standard l 2 norm. In general, there is no analytical formula to find the central point with the l 1 norm (it can be numerically estimated). For the l 2 norm, the best point is the center of gravity or centroid (mean measurements on each coordinate). The medoid of G is (3, 3).
- Radius :
-
Maximum dissimilarity between the most representative element j and another of G: min j max i ∈ G d(i, j). This element is not necessarily part of G. For instance, we can take the median (on each characteristic) or the point which minimizes any dissimilarity function. Using the numerical example above, the median of the measures is (3, 1), which does not belong to G. By taking the ordinary distance (l 1 norm) or squared distance (l 2 norm) as a dissimilarity measure, the point (5∕2, 1∕2) minimizes the radius of G.
- Clique :
-
Sum of dissimilarities between all pairs of elements of G: ∑i ∈ G∑j ∈ G d(i, j).
Several definitions have been proposed to measure heterogeneity existing between two groups G and H:
- Separation :
-
Minimum distance between two elements belonging to different groups: min i ∈ G,j ∈ H d(i, j).
- Cut :
-
Sum of dissimilarities between elements of two different groups:
∑i ∈ G∑j ∈ H d(i, j).
- Normalized cut :
-
Average of the dissimilarities between elements of two different groups: ∑i ∈ G∑j ∈ H d(i, j)∕(|G|⋅|H|).
Once a criterion of homogeneity or heterogeneity has been defined, we can formulate the problem of classification into p groups G 1, …G p by an optimization problem using a global objective:
-
Maximize the smallest separation (or the smallest cut) between elements of different groups;
-
Minimize the largest diameter (or the largest radius, or the largest clique or even the largest star) of a group;
-
Minimize the sum of the stars (or the sum of the diameters, radius, clique).
7.1 k-Medoids or p-Median
The k-medoids problem is one of the best known in unsupervised classification. Frequently, the terms p-median or k-medians are used instead of k-medoids in location theory and statistics. Using the definitions presented above, it is about minimizing the sum of the stars. In other words, we have to find the k elements c 1, …, c k of E minimizing: ∑k∑i ∈ E min r=1,…,k d(i, c r). This problem is NP-hard.
A well-known heuristic algorithm is the Partition Around Medoids (PAM 2.7) . This algorithm is a local search improvement method. Various authors have proposed variations of this heuristic—while calling it PAM, which causes some confusion. The method originally proposed [3] is a local search with best improvement policy (see Sect. 5.1.2). This method requires an initial position of the centers. Different authors have suggested various methods to build an initial solution. Generally, greedy algorithms are used (see Sect. 4.3). Algorithm 2.7 does not specify how the latter is obtained; it is simply assumed that an initial solution is provided. A random solution perfectly works.
Algorithm 2.7: (PAM) Local search for clustering around medoids

The PAM algorithm has complexity in Ω(k ⋅ n 2). The computation of the cost of the new configuration on Line 6 of the algorithm requires an effort proportional to n. Indeed, it is necessary to check, for each element not associated with c j, if the new medoid i is closer to the current one. For the elements previously associated with the medoid c j, the best medoid is either the second best of the previous configuration, which can be pre-calculated and stored in Line 3, or the new medoid i tried.
The number of repetitions of the loop ending in Line 9 is difficult to assess. However, we observe a relatively low number in practice, depending on k more or less linearly (there is a high probability that each center will be repositioned once) and a sub-linear growth with n. If we want a number of clusters k proportional to n (for instance, if we want to decompose the set E into clusters comprising a fixed number of elements, on average), the complexity of Algorithm 2.7 is higher than n 4. Thus, the algorithm is unusable as soon as the number of elements exceeds a few thousand.
7.2 k-Means
In case the items are vectors of real numbers and the measurement of the dissimilarity corresponds to the square of the distance (l 2 norm), the point μ that minimizes the homogeneity of the star criterion associated with a group G is the arithmetic average of elements of G (the center of gravity). The k-means heuristic Algorithm 2.8 is probably the best known algorithm for clustering.
Algorithm 2.8: (k-means) Local search improvement method for clustering items of \(\mathbb {R}^d\) into k groups. The dissimilarity measure is the l 2 norm

Similar to the PAM algorithm, this is a local search improvement method. It starts with centers already placed. Frequently, the centers are randomly positioned. It alternates an assignment step of the item to their nearest center (Line 3) and an optimal repositioning step of the centers (Line 5). The algorithm stops when all items are optimally assigned and all centers optimally positioned considering their assigned items. This algorithm is relatively fast, in Ω(k ⋅ n). Unluckily, it is extremely sensitive to the initial center positions as well as isolated items. If the item dispersion is high, another dissimilarity measure should be used. For instance, the centers can be optimally repositioned considering the ordinary distance (l 1 norm) at Line 5. This variant is the Weber’s problem. By replacing the center c j on the medoid item of group G j at Line 5, a faster variant of Algorithm 2.7 is obtained.
8 Graph Coloring
Coloring the edges or the vertices of a graph allows us to mentally represent problems where incompatible items must be separated. Two compatible items can receive the same “color” while they must be colored differently if they are incompatible. Therefore, a color represents a class of compatible elements. In the edge coloring, two edges having a common incident vertex must receive different colors. In the vertex coloring, two adjacent vertices must receive different colors.
The edge coloring can be transformed into a vertex coloring in the line graph. Building the line graph L(G) from the graph G is illustrated in Fig. 2.12.

Proper edge coloring of a graph corresponding to the proper vertex coloring of its line graph
The vertex coloring problem is to find the chromatic index of the graph, that is to say, to minimize the number of colors of a feasible coloring. This problem is NP-hard in the general case. However, the edge coloring of a bipartite graph can be solved in polynomial time.
8.1 Edge Coloring of a Bipartite Graph
It is clear that the vertices of a bipartite graph can be colored with two colors. It is a bit more complicated to color the edges of a bipartite graph. But we can find an optimal coloring in polynomial time. For this, we begin by completing the bipartite graph G = (V = X ∪ Y, E) by adding vertices to the smallest subset X or Y so that they contain the same number of vertices. While maintaining it bipartite, edges are added to the graph so that all its vertices have the same degree. This degree equals the largest of a vertex of G.
Let us call G′ the bipartite graph so obtained. A perfect matching can be found in G′ by solving a maximum flow problem (see Sect. 2.5). The edges of this matching can use color number 1. Then, the edges of this matching are removed from G′ to obtain the graph G″. The last has the same properties as G′: it is bipartite, both subsets containing the same number of vertices and all their degree being the same. So, a perfect matching can be found in G″, the edges of this matching receiving the color number 2. The process is iterated until no edge remains in the graph. The coloring so obtained is optimal for G (and for G′) because the number of colors used is equals to the vertex of G with the highest degree. See also Problem 3.3.
Problems
2.1
Connecting Points
A set V of points on the Euclidean plane must be connected. How to proceed to minimize the total length of the connections? Application: consider the 3 points (0, 0), (30, 57), and (66, 0).
2.2
Accessibility by Lorries
In the road network of Fig. 2.13, the maximum load (in tons) is given for each edge. What is the weight of the heaviest lorry that can travel from A to B?

Maximum load problem in a road network
2.3
Network Reliability
Figure 2.14 gives a communication network where connections are subject to breakdowns. The reliability of the connections is given for each edge. How should we transmit a message from the vertex s to all the others with the highest possible reliability?

Reliability in a network
2.4
Ford and Fulkerson Algorithm Degeneracy
Show that the Ford and Fulkerson algorithm for finding a maximum flow is not polynomial.
2.5
TSP Permutation Model
Model the TSP under the form of finding an optimal permutation.
2.6
PAM and k-Means Implementation
Implement Algorithms 2.7 and 2.8 by initializing the k medoids or the k centers with the first k items. Investigate both methods on randomly generated problems in the unit square with n = 100, 200, 400, 1000, 2000 items and k = 5, 10, 20, 50, n∕20 centers. Estimate the empirical complexity of the algorithms. Compare the quality of the solutions obtained by Algorithm 2.8 when the k centers are initially placed on the medoids found by Algorithm 2.7 rather than randomly choosing them (with the k first items).
2.7
Optimality Criterion
Prove that the schedule given at the bottom of Fig. 2.4 is optimal.
2.8
Flowshop Makespan Evaluation
Knowing the processing time t ij of the object i on the machine j, how to evaluate the earliest ending time f ij and the latest starting time d ij for a permutation flowshop? The jobs are processed in an order given by the permutation p.
2.9
Transforming the Knapsack Problem into the Generalized Assignment
Knowing that the knapsack problem is NP-hard, show that the generalized assignment problem is also NP-hard.
References
Jarník, V.: O jistém problému minimálním. (Z dopisu panu O. Borůvkovi [On a certain problem of minimization (from a letter to O. Borůvka)], in Czech. Práce moravské přírodovědecké společnosti. 6(4), 57–63 (1930). http://dml.cz/dmlcz/500726
Jarník, V.: O minimálních grafech, obsahujících n daných bodů [On minimal graphs containing n given points], in Czech. Časopis pro Pěstování Matematiky a Fysiky. 63(8) 223–235 (1934). https://doi.org/10.21136/CPMF.1934.122548
Kaufman, L., Rousseeuw, P.J.: Clustering by means of Medoids. In: Dodge, Y. (ed.) Statistical Data Analysis Based on the L 1-Norm and Related Methods, pp. 405–416. North-Holland, Amsterdam (1987)
Martello, S., Toth, P.: Knapsack Problems — Algorithms and Computer Implementations. Wiley, Chichester (1990)
Voigt (ed.): Der Handlungsreisende wie er sein soll und was er zu thun hat, um Aufträge zu erhalten und eines glücklichen Erfolgs in seinen Geschäften gewiß zu sein ; Mit einem Titelkupf. Voigt, Ilmenau (1832)
Author information
Authors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this chapter

Cite this chapter
Taillard, É.D. (2023). A Short List of Combinatorial Optimization Problems. In: Design of Heuristic Algorithms for Hard Optimization. Graduate Texts in Operations Research. Springer, Cham. https://doi.org/10.1007/978-3-031-13714-3_2
Download citation
DOI: https://doi.org/10.1007/978-3-031-13714-3_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-13713-6
Online ISBN: 978-3-031-13714-3
eBook Packages: Business and ManagementBusiness and Management (R0)