
Abstract
In the present work we show how many scientific illustrations of the early modern period can be used to track the evolution of visual knowledge and to detect historical communities involved in the production of the editions analyzed. In particular, we define three sorts of historically meaningful similarities among scientific illustrations, we show how such illustrations can be extracted from the sources and then clustered by means of fully computer-based methods, and finally we conclude with an example to show the potential of our approach.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
In the present work we intend to show how to establish kinds of similarities among early modern scientific illustrations. The reason for such an investigation is related to the needs emerging in the frame of computational history, and specifically to our investigation “The Sphere: Knowledge System Evolution and the Shared Scientific Identity of Europe.”
The general goal of our research is to reconstruct the transformation process a specific group of historical sources underwent. We refer to university textbooks used for the teaching of astronomy and cosmology all over Europe between the end of the fifteenth century and 1650. To accomplish this goal, we collected a batch of sources consisting of a corpus of early modern printed books that contain, in different forms, a specific treatise on cosmology: Johannes de Sacrobosco’s (died ca. 1265) Tractatus de sphaera, a university textbook used for a qualitative introduction to geocentric cosmology, first compiled within the university of Paris during the thirteenth century. The corpus is also populated with 126 editions of university textbooks used for teaching the same subject that do not contain Sacrobosco’s treatise, but rather an introduction to spherical astronomy that follows the same design of Sacrobosco’s work, discusses the same subjects in the same order, and makes at least a partial use of the same visual apparatus. In total, 359 different editions were identified.Footnote 1
To reconstruct the process of the transformation of knowledge taught in Europe we decided to extract a series of data that we conceive as highly representative for the scientific content of the textbooks at hand. For this reason, we called these data “knowledge atoms,” purposely referring to the atomization of texts within the framework of commentary, a standard procedure to create new scientific knowledge from antiquity until the end of the early modern period (Grafton 2013).
Our knowledge atoms are texts (text parts), illustrations, and computational tables. We began with the text parts. By means of electronic copies of all sources, the texts were carefully atomized into “text parts.” A text part is a textual passage that cannot be formally smaller than a paragraph and covers a well-defined subject with completeness. A text part in the corpus of Sacrobosco’s De sphaera, for instance, might be the Theoricae novae planetarum of Georg von Peuerbach (1423–1461),Footnote 2 as this text began being printed together with the Sphaera as early as 1482 and had been reprinted together with the Sphaera seventeen times by 1537. If literary compositions—ordinarily printed in scientific books beginning in the sixteenth century—are considered, a text part can be much more modest in length. A representative example might be the short carmen written by Donato Villalta and dedicated to the scholar Pierio Valeriano (1477–1558),Footnote 3 printed for the first time in 1537Footnote 4 and then reprinted another thirty-two times. Another example of a text part—which can be seen as both a literary composition and a scientific contribution—is the famous letter to Simon Grynaeus (1493–1541) written by Philipp Melanchthon (1497–1560)Footnote 5 in defense of astrology as a teaching subject in the Reformed countries. The letter was printed, together with Sacrobosco’s text, for the first time in 1531Footnote 6 and then another sixty-four times.
The advantage of such a textual “dissection” of the editions under investigation is evident when it becomes clear that many such text parts actually recur. On the basis of the recurrences of the text parts we were then able to analyze how the textbooks evolved.
Text-part analysis applied to the editions of the corpus resulted in the identification of a total of 563 text parts. Their identification is based on the principle of first appearance along the chronological line. Moreover, we considered only those text parts that were reprinted and re-published at least once, at least one year after their first appearance. By applying these criteria, 239 text parts remain, meaning that 324 text parts were published either only once or more than once but in the same year. Focusing on the remaining 239 text parts, their total number of recurrences (in the total timespan of 175 years considered here) is 1,653.
We first focused on the mechanisms of production of knowledge rather than on the content; therefore we created an ontology of text parts that allowed us to connect them and their recurrences on the basis of a taxonomy that includes the following categories: original text and text of reference, commentary, translation, and fragment. All the identified text parts were catalogued by making use of one or more of these categories. For instance, the quadrivial professor at the university of Leipzig active at the beginning of the sixteenth century, Konrad Tockler (1470–1530), authored a commentary on De sphaera. Such commentary is a text part in itself and was re-published twice, in 1503 and 1509.Footnote 7 The first time, the commentary was published together with one text part, namely a fragment of Thābit ibn Qurra’s (836–901) De imaginatione spere et circulorum. The second time, however, it was published with three text parts: the fragment, Tockler’s introduction, and finally his description on how to build an armillary sphere.Footnote 8 According to our ontology, therefore, Tockler’s commentary allows us to connect not only these two editions because they contain the same commentary, but also all editions that contain the commentary on the same reference text, or all editions that contain one of the other text parts that were printed together with the commentary at hand.
To exploit all these possibilities and the high dimensionality of the dataset that we collected, we conceived a multi-layer network able to show us, in graphs, all possible connections along their temporal axis and, ultimately, to give as a formal system to be analyzed by means of methods typical of complex systems studies (Fig. 4.1).Footnote 9

In previous studies based solely on the dynamics of the text parts, we were able for instance to identify editions that became dominant all over Europe, meaning that their content was “borrowed” from other printers and publishers. In particular, such dominance was executed by editions printed in recently reformed Wittenberg, illustrating how the Reformation produced scientific and pedagogic content able to influence the entire continent beyond confessional boundaries. Moreover, we were also able to show that a relatively small number of editions printed and published during the brief window between 1549 and 1562 acted as knowledge bridges (“great transmitters”) by mixing old and traditional texts with innovations that emerged in the two decades before, and that such transmitters became the paradigms until long after the turn of the century.Footnote 10
After the accomplishment of these studies, we decided to continue our research by approaching the second of the knowledge atoms listed above, namely the illustrations of the corpus. Our ultimate goal in this respect is not only to capture all the illustrations printed in the textbooks but also to conceive an ontology for the illustrations that allows us to enlarge our network by adding layers so that we can finally compare the dynamics of the scientific illustrations with that of the scientific texts and, in the end, accomplish more comprehensive research concerned with the knowledge transformation process these sources underwent.
In the following therefore we will describe first the dataset of illustrations that we collected, including the method used to extract these data, and second the ontology we conceived in order to group the images according to historically meaningful principles that allow us to represent processes of the innovation, oblivion and diffusion of knowledge related to the scientific visual material. After this theoretical argument, we show how we technically realize clusters of illustrations in order to meet the requirements developed in the historical interpretative framework. Finally, we conclude with an example of the results we can achieve.
2 The Role of a Scientific Illustration
The illustrations have been manually annotated (captured) by a team of student assistants, using the Mirador IIIF viewer (Project Mirador 2014). The illustrations are stored as regions on the digitized pages. This means that for later analysis we are able to associate an illustration with the edition it originates from, its author, printer, publisher, the specific text part an image appears in, etc. The data is stored as RDF triples according to a CIDOC-CRM data model (Kräutli and Valleriani 2018).
The annotations have been classified as either Content Illustrations, Initials, Printer’s Marks, and Decorations. We also distinguish whether these elements are printed on title pages or inside the book. As in the case of the text parts, this taxonomy describes the mechanisms of production of knowledge more than the content of the books themselves. Moreover, as we are interested in reconstructing the process of evolution of astronomic and cosmological knowledge represented by these textbooks, we ignore for the moment illustrations of initials and decorations. Given the relatively low number (maximally as many as the editions collected: 359) of printer’s marks and title page illustrations, our method will focus on the largest of the groups of illustrations realized through the data extraction: the content illustrations. These amount to 21,407 images; all, in our corpus, are woodblock prints in the tradition of the early modern printing workshops (Reeves 2017; Werner 2019, 65–71).
Content illustrations are carriers of knowledge that we keep ontologically distinguished from the texts within which they are inserted. In the case of our textbooks, they can be scientific diagrams, flattened representations of the cosmos, geometric figures, or any kind of visual aid to describe, enrich, criticize, or explain what is expressed textually. But they can also constitute the central piece of information, which the text describes, enriches, explains, and criticizes.
To give an example, we could consider one of the oldest visual aids and that can be traced back in the manuscript material, inserted in the Tractatus de sphaera during the late medieval period. This image (Fig. 4.2), which is then taken over into the new medium of print, illustrates the sphericity of the element water around the element earth, in accord with the orthodox Aristotelian cosmological view.

In the first chapter of the Tractatus de sphaera, Sacrobosco demonstrates the sphericity of the element water around the Earth by means of the empirical example of a ship leaving a shore. From (Sacrobosco et al. 1490, a-III-5). Courtesy of the Library of the Max Planck Institute for the History of Science
Since time immemorial, it was a well-known that when a ship is approaching the shore, an observer positioned at the top of the mast can see the shore earlier than another observer positioned on the hull of the ship. Since classical antiquity this phenomenon was used to explain the sphericity of our planet and, more precisely, that the element of water, according to the Aristotelian view, floats over the element of earth because it is less heavy.
For some time in the context of the historical sources collected in our corpus, the description of phenomena did not change. However, after the experiences of the journeys of exploration began entering the academic conversation, it became urgent to start claiming the obvious: that we do not inhabit a water globe dotted with a portion of emerged earth where life takes place; it is a terraqueous globe (Fig. 4.3).

With the accumulation of experience from the journeys of exploration the planet starts being visually represented as a terraqueous globe. The content of the demonstration of the sphericity of the element water is not changed in the text, neither is the issue of the distribution of the element earth and the dissolution of the idea of an Oikumene. From (Sacrobosco and Melanchthon 1568, b-5-4). Courtesy of the Library of the Max Planck Institute for the History of Science
The new illustration obviously represents a strong departure from the Aristotelian view, and an aspect of nature that cannot be explained on the basis of the Aristotelian worldview. Nevertheless, the new composition retains the previous meaning and function of the illustration and still represents a demonstration of the sphericity of the water globe. The text that accompanies the illustration, however, remained completely unaltered for a very long time, except in a few editions, implying that the illustration is commenting on the textual content by criticizing it.Footnote 11
With our goal in mind of creating connections among editions based on the content illustrations in order to allow us to analyze how the scientific content of the treatises (or more precisely, how the method of production of scientific content) changed over time, we faced the task of identifying elements and characteristics of content-illustrations that express meaningful historical information.
In the same way that we used to connect editions on the basis of particular relations among text parts, we define three forms of similarity among illustrations, on whose basis we can create networks among the editions of the corpus that formally describe the process of transformation we want to reconstruct. Such similarities will then allow us to group the content-illustrations on their basis; such groups, ordered chronologically by the dates of publication of the editions in which they were printed, will furnish us the data to finally create the graphs or layers of the network. In the present work we will describe these three forms of similarity and show how we grouped the illustrations. The analysis itself of the graphs will be accomplished in future works.
3 Three Historically Meaningful Forms of Similarity Among Early Modern Scientific Illustrations
The three forms of similarities that we have conceived allow us to group the content-illustrations following an operative hierarchal order, meaning that the formation of the first groups on the basis of the first form of similarity is a necessary condition for the formation of the second group, and so forth.
The first form is called “philological similarity,” on whose basis we create “philological groups” of illustrations. Philological similarity implies that two illustrations are similar to each other if they are identical.
As we know from book historians (Nuovo 2013), the investment of a printer in producing a book was roughly subdivided into one-third for the costs of the paper and two-thirds for the preparation of the text, namely configuration of the page and the actual printing. However, the situation changed dramatically when an edition was supposed to include several or many illustrations. This change happened for two reasons related to the production process for printed books. The first concerns the fact that there was no way to print both text and illustrations in the same act. This means that each sheet that was supposed to display at least one image needed to be placed under the press twice, enormously lengthening the use of human resources (the press men) and influencing the consumption of the instruments and tools (the press). The second, eventually even more relevant from an economic point of view, was the need to first produce woodblocks. Such production was extremely costly because of the material and the human work. That said, the life of woodblocks could be extremely long; though they needed to be repaired or restyled every once in a while, they could eventually be reused, for longer than a century in certain cases.Footnote 12 Because of the high number of illustrations in the editions constituting our corpus (these are mathematical books) this factor matters for our study.
In fact, the combination of these two characteristics of the woodblocks—expensive but long-living objects—transformed the woodblocks into economic goods of exchange among printers, publishers, and booksellers (when they also acted as publishers): blocks were lent, borrowed, sold, and scrupulously inherited. For this reason, if illustrations are grouped because they are identical to each other, and assuming that this means that they have been produced by means of the same woodblock, we can create a graph of connections between editions of treatises of our corpus that, at the same time, identifies networks of printers and publishers in economic relationship among each other on the basis of the exchange of woodblocks.
Two limits concerning the applicability of our conception are related to the actual use of woodblocks. The first is due to the fact that, in principle, no illustration can be truly identical to another. In the course of a print run—and even for two subsequently printed sheets—the woodblock underwent a process of wear, plus new ink was added, and a different sheet, though probably extremely similar, was used. Secondly, the case is not infrequent that a woodblock was flipped upside down by accident or otherwise. As will be shown in the following, however, our method is able to cope with these inconsistencies.
There is finally a third limit, this time concerned with the actual practice of early modern printers’ workshops: there were frequent cases in which printers replicated illustrations printed in other printers’ editions by carving the woodblock while keeping a printed illustration on it; they copied it without “permissions,” as we would express this practice nowadays. This was indeed a practice that reflected the period’s conceptions of originality, invention, and especially reproduction, whose consequence was the lack of a normative framework in reference to engravers and their products (Pon 2004; Witcombe 2004, 10–20).
This particular case cannot be detected with our method but gave us the ability to design our second form of similarity, the one we defined as “same types of representation.”
The case in which a printer reproduced an illustration in an identical or almost identical way by carving a new woodblock is a special, peripheral case in this second form of similarity. More generally, we speak about same types of representations when illustrations that express the same scientific meaning also “look similar.” It is probably easier to express this form of similarity by means of a few examples.
To begin with, we could reuse the representation of the sphericity of the element water (Fig. 4.2) and compare it with another illustration, whose aim is to express the same scientific meaning but by means of a different form (Fig. 4.4).

Illustration describing the demonstration of the sphericity of the element water around the Earth. From (Sacrobosco and Nuñez 1537, a-IIII). Reprint. München: Obernetter, 1915
The overall representation is very similar (it shows a ship leaving shore) and no further scientific meanings are transmitted thereby. On the other hand, it diverges because of some small differences in the representation. For instance, the second observer is not positioned on the hull but at the bow and there is small boat close to the ship, possibly representing an additional observer positioned at an even lower position.
According to the first form of similarity, Figs. 4.2 and 4.4 do not belong to the same group but they are indeed the same type of representation and, according to our categorization, belong to the same group as defined by the “same type of representation.”
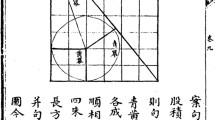
Another example will assist in understanding this type of similarity, especially its historical meaning. We will then discuss its limits of applicability and thence move to the next form of similarity. A subject that is always discussed in the textbooks constituting our corpus is the phenomenon of the lunar eclipse. This subject is always discussed toward the end of the Tractatus de sphaera, in its final chapter (Chap. 4). The illustration shows that the lunar eclipse takes place because of an alignment of sun, Earth, and moon so that a shadow is cast over the moon, which then appears obscured to observers on the Earth (Fig. 4.5).

The type of representation of this illustration is very common in our corpus and many illustrations somehow reproduce it—as, for instance, in the next example (Fig. 4.6).

Common illustration to explain how lunar eclipses take place. It shows the same type of representation as Fig. 4.5. From (Piccolomini 1568, 122). Public domain: https://doi.org/10.3931/e-rara-19747
Once again, the two illustrations are clearly not identical, but they also clearly show the same type of visual representation.
From these two examples it is not difficult to understand the kind of historical meaning we can obtain by applying this category. By connecting the editions of our corpus on the basis of the illustrations contained therein—which belong to the groups defined by this second form of similarity and by ordering the editions chronologically—we are finally able to trace temporally and spatially the diffusion of specific scientific visual representations and, therefore, to trace their possible evolution. As we conceive of visual scientific illustrations as semantic carriers of scientific knowledge, then the evolution of the visual representation mirrors the evolution of scientific knowledge.
From an operative point of view, there is no need at this stage to compare all the illustrations again. What will be compared at this stage are single illustrations taken as representative of entire philological groups as defined above. In other words, groups of illustrations created on the basis of the identification of the same type of representation are constituted by philological groups, which in turn are constituted by illustrations. In this sense the two grouping methods are conceived as hierarchically ordered.
In the case of the types of representation, limits of applicability can also be easily detected. As the subject of the lunar eclipse is explained in nearly all the treatises of the corpus, there are obviously many different illustrations whose function is to explain it. A different example (Fig. 4.7) shows the same subject but with a clearly different, though not radically different, visual composition.

Visual explanation of the phenomenon of the lunar eclipse. The lunar nodes are visualized. From (Valeriano 1537, eII). Courtesy of the Library of the Max Planck Institute for the History of Science
What this last example teaches us is that it is easy to imagine cases in which the question of whether two philological groups of illustrations belong to a group defined on the basis of the similarity of the type of representation becomes a matter of debate and cannot be unequivocally defined once and for all. In this respect, we will also refer to opinions based on the expertise developed in the frame of art history and the history of the book (Müller 2008, 2011).
Figures 4.5, 4.6 and 4.7, for instance, explain the same scientific subject in a similar way. However, the connection we made between Figs. 4.5 and 4.6 was much more obvious and bold than their connection with Fig. 4.7. The main apparent differences between Figs. 4.5, 4.6, and 4.7 are:
-
Figures 4.5 and 4.6 include cartoon-like faces of the sun and moon;
-
Figures 4.5 and 4.6 use the medieval T-shaped world map of the earth;
-
Figures 4.5 and 4.6 use index letters, while in Fig. 4.7 the references are mentioned by the full words;
-
diagonal versus perpendicular compositions;
In spite of these differences, the images are not radically different. They use a similar visual language. However, the separation of both into two “type-of-representation” groups allows us to distinguish between different singular variations of the configuration. The hypothesis leading the research is that on the scale of the whole corpus, mapping different variations and visual formulations will exhibit specific paths of the evolution of the project’s visual language in a way that is both specific and general.
The evolution of scientific visual language during the Renaissance is often discussed in relation to descriptive sciences like botany, anatomy, etc. In his canonical work, Erwin Panofsky characterized the Renaissance as taking a new approach to the visible world and prescribing a new definition of artistic representation. Panofsky writes that art during this period became more systematically based on scientific investigations. Another characteristic of the period is the process of bridging the gap between “professors and practitioners” (Panofsky 1962).
Panofsky’s approach has been the subject of a large historical debate. Samuel Edgerton, for instance, has followed Panofsky and discussed the role of linear perspective in arts and its influence on the rise of experimental science. Other scholars have offered criticism of this approach—for example, considerations of the character of naturalistic representation (Givens 1999), the importance of decorations and aesthetic pleasure in scientific books (Kyle 2017), and the historically changing meaning of direct observation and its modes of documentation (Daston and Galison 1992; Daston 2015).
In this framework, astronomy is a unique case. Panofsky refers less to astronomy than to the descriptive sciences. According to Panofsky, before the Renaissance there was little contact between theoretical knowledge and practical observations and calculations. The bridging of practical and theoretical endeavors is expressed in astronomy by the theorization and systematization of practical endeavors, as well as in the theorization of practice (Panofsky 1962, 138–139). Concerning astronomical illustrations, however, an emphasis on observations that are documented and transmitted through art (as in the descriptive sciences) cannot be identified in the frame of astronomy because the subject of the illustration is not available at firsthand sight in the same manner, and cannot, in any circumstances, be drawn in its real dimensions. Accordingly, while abstraction is part of any process of drawing which translates three dimensional objects into two dimensions, it is even more prominent in astronomical illustrations. In contrast with medicine, revolutionary developments in astronomy were not accompanied by a shift in the style of the visual language. However, there were important changes in the ways illustrations were used in the context of each treatise (Kemp 1996; Pantin 2014).
As naturalism cannot be a prominent characteristic to evaluate the evolution of astronomical diagrams, we must search for different characteristics that allow us to distinguish among different types of astronomical representations. A fundamental distinction in this respect is between cartoon-like diagrams that express qualitative scientific knowledge and elements, such as diagrams, tables, and lists, that convey a knowledge of quantitative nature. Richard Oosterhoff, for example, in his discussion of the printed editions related to Jacques Lefèvre d'Étaples’ (1450–1536) commentary on De sphaera, addresses the subject of the mathematization of the treatise. According to Oosterhoff, the transition of De sphaera toward a mathematical treatise is first expressed in its visual language. Oosterhoff connects the cartoon-like elements common to the illustrative tradition of De sphaera—including faces of suns and moons (as seen in Figs. 4.5 and 4.6) or disproportional figures and details—with the qualitative character of the treatise.
As the treatise is meant to teach students the basic principles of the discipline, the illustrations are not accurate, and are aimed to explain a single and simple principle. In contrast, the editions including the commentary by Jacques Lefèvre d'Étaples, for instance, are mathematically more advanced. This advancement is expressed visually. Oosterhoff writes that “the visual rhetoric of the diagrams facilitates quantitative readings.” Mathematization is moreover also expressed in the replacement of full words in the images to index letters, which connect text and image, and in the priority given to geometrical lines over cartoon-like figures. The original De sphaera text now has a new subject and purpose. Instead of being a general and qualitative introduction, Lefevre’s new edition became an exact and practically oriented text, based on calculations. The rising discipline of cosmography prioritized the practical benefits of astronomical knowledge over the rational understanding of the ancients’ opinions (Oosterhoff 2018, 2020).
The transition of the visual rhetoric of the De sphaera tradition from qualitative and cartoon-like to accurate, quantitative, and geometrical, can supply an answer to the search for an evolution in the visual language of astronomical images, which reflects the beginning of modern scientific astronomical inquiry. Our example (Figs. 4.5, 4.6 and 4.7) does not display such a dichotomy. The two “type of representation” groups do not present such different modes of representation. The two groups (the group including Figs. 4.5 and 4.6 and the group including Fig. 4.7) indeed use a very similar visual language. However, recording the variations of uses of the different elements included in the illustrations throughout the full corpus can reveal patterns and mark the evolutionary path of the visual language in a continuous, less fragmented way.
The last comparison (Figs. 4.6 and 4.7) shows us how to enrich our taxonomy through a third form of similarity. If we reach the conclusion that the two last illustrations not only belong to two different philological groups but also that these two groups do not display the same type or representation, then we can nevertheless state that the two groups are related to each other because they express the same scientific meaning. In this way we build a new category of similarity that we call “content related” and we define “content-related” groups of illustrations.
From an operative point of view, however, there is no need to return to the philological groups, as content-related groups can easily be built by associating groups of the same type of representations. If we reconsider the first two illustrations of the sphericity of the element water (Figs. 4.2 and 4.3), for instance, they would belong to two different philological groups and, at the same time, to two different groups defined on the basis of the type of representation. At the level of content-related groups, however, they would be reunited, as they express the same scientific meaning at least partially, that being the demonstration of the sphericity of the element water. This also implies that content-related groups can unite groups based on the type of representation in multiple ways. Should we find, for instance, illustrations depicting the terraqueous globe with the intention of illustrating the different distribution of the two elements, but not demonstrating the sphericity of the element water, then these two groups would be united as different content-related groups. This last form of similarity is the one that, more than the others, also requires focus on the textual apparatus and that therefore includes the consideration of text-image relations.
A special case can further help us to appreciate the analytical power of our taxonomy and, especially, the kind of historical results the content-related groups can bring us. This case is concerned with visual representations of the geocentric cosmos. Needless to say, this kind of illustration is the most common in the treatises we are investigating. But in spite of their great similitude among each other, such representations also convey very different aspects and scientific subjects.
According to the standard view, the view imparted in the original treatise of Johannes de Sacrobosco, the concentric planetary spheres are nine: the seven planets, the firmament, and the primum mobile. At its center, the four elements are organized according to their heaviness and lightness. In the middle there is the earth surrounded by the water. Over the water there is the air in turn surrounded by the element fire. A glance through the treatises reveals a myriad of variants to such a standard view. Many explanations are possible. For instance, it is possible that the illustration is not intended to convey a different meaning but that either for technical reasons or because of the curatorial design, the illustration depicting the cosmos misses the opportunity to convey all these pieces of information (Fig. 4.8). In frequent cases, for example, the cosmos is represented without great attention to its center and only the spheres are printed properly. In other cases, however, we do find a complete representation of the elements at the center and, in addition, a different number of spheres (Fig. 4.9); it is not uncommon to discern ten spheres instead of nine, for example. We know that the addition of one sphere was often due to the recognition of an additional motion in the cosmos (the precession of the equinoxes) that could not be satisfactorily explained by the standard model. Therefore, a sphere was introduced with the “mechanical” task of producing a movement to justify the mutations observed. Such slow movement was called trepidatio (Nothaft 2017; Axworthy 2020).

Representation of the geocentric universe showing nine concentric spheres, a specific distribution of the elements in the center, and a T–O map of the planet. From (Sacrobosco et al. 1490, aIII-4). Courtesy of the Library of the Max Planck Institute for the History of Science

Representation of the geocentric universe showing ten concentric spheres and a different distribution of the four elements in the center. From (Sacrobosco 1516, aIII). Public domain: https://doi.org/10.3931/e-rara-2230
Both of the illustrations recur many times and therefore belong each to a different philological group. Moreover, they show the same type of representation mostly because both use concentric circles to represent the concentric spheres of the cosmos. However, they do not belong to the same content-related group because they convey different meanings—meanings that might have to be investigated case by case by reading the textual apparatus and/or commentary in which the illustration is inserted. For this reason, content-related groups express a historical meaning that can and will diverge from the meaning expressed by groupings based on the analysis of the type of representation only.
In the following we will show how we technically group and cluster this corpus of illustrations of exceptional dimensions, and we will show how the entire procedure is based on a visual analysis of the vision material: “vision on vision.” Before describing such a method, however, we will first describe our dataset of illustrations.
4 Statistics and Tools
For every edition in our corpus we obtained a digitized PDF copy. Through the database interface the PDF is accessible, along with its individual pages, which can be viewed through the Mirador IIIIF Viewer (Project Mirador 2014) that the student assistants worked with when capturing the illustrations. The process of analyzing a printed layout for the purpose of extracting illustrations could in principle also be automated. Many off-the-shelf OCR tools are capable of this for contemporary print material, and libraries such as dhSegment (Ares Oliveira et al. 2018) reproduce this functionality for historical documents.
We originally envisaged using dhSegment for automatically extracting the illustrations. However, the corpus was small enough to allow our student assistants to work through the material quicker than we managed to get the automated method functioning. The manual process also meant that the obtained dataset of illustrations was relatively clean from the start. An automatic extraction would need to undergo a manual cleaning process in order to weed out illustrations that had been misidentified (false positives) as well as illustrations that had not been captured (false negatives). While false positives can be identified quite quickly, recognizing false negatives is more time consuming. Every page would need to be inspected in order to spot illustrations that had not been identified. Due to the inevitable manual cleaning process, automated data extraction often saves less time than first hoped.
Before we go into the process of how we establish the aforementioned types of similarities between images, we want to take a brief look at the illustrations themselves and in relation to the metadata we have already gathered on the editions in our corpus. We recorded bibliographic data on the editions' printers and publishers, the place and date of publication, their language, size, etc. We begin by looking at the temporal distribution of the collected illustrations, in the first instance without taking into account the philological groups. We first plotted the total number of illustrations identified per decade in the observed timeframe (Fig. 4.10). The distribution of illustrations largely follows the overall distribution of printed editions (Fig. 4.11), including the lower number of illustrations in the years 1520–1529. Yet if we look at the number of illustrations in relation to the number of pages these books contain, we see a slightly negative correlation (Fig. 4.12).

The absolute number of content illustrations in our dataset is mapped against the date of publication of the book they appear in. The pattern largely corresponds to the overall temporal distribution of books in our dataset (Fig. 4.11)

The temporal distribution of the books in our corpus. Most books have been published around mid sixteenth century

The average number of content illustrations that a book contains in relation to its number of pages declines over time. While the later books in our corpus contain on average more texts, those texts are not as richly illustrated as the Tractatus, which contributes most of the illustrations in our collection
Although the average number of pages an edition contains increases over time, those pages contain a decreasing proportion of illustrations. A possible explanation of this pattern can be found in the fact that a total of 11,365, or roughly half of all the collected illustrations have been printed in the text part identified with Sacrobosco's Tractatus de Sphaera and its commentaries. Additional text parts that have been added to later publications do overall contain fewer illustrations. An exception is the Theorica novae planetarum by Georg von Peuerbach, which contributes a total of 1,293 illustrations to the total collection. The total number of illustrations each (original) text part contributes to our collection can therefore be displayed. We can now also look at the number of illustrations each original part contains (Fig. 4.13). A 1611 edition printed by Reinhard Eltz in Mainz contains a richly illustrated text on astrolabes by Christoph Clavius (1538–1612), featuring 339 illustrations (Sacrobosco and Clavius 1611) (Fig. 4.14).

In absolute numbers, most of the illustrations in our corpus originate from the Tractatus de sphaera. This comes as no surprise as the Tractatus forms the basis of our collection and is generally richly illustrated

Looking at how many illustrations an individual part contains on average, a text on astrolabes by the Jesuit mathematician Christoph Clavius stands out. It appears in only one edition in our collection, a 1611 work published in Mainz, where it is illustrated by a total of 339 illustrations
As may be expected, the physical format of a publication does relate to the number of illustrations included, with quartos and octavos containing about half as many illustrations per page as folios (Fig. 4.15).

Books that are printed in the large folio format contain on average 121 illustrations, more than twice as many as those produced in the smaller octavo and quarto formats
In order to go beyond statistical insights and look at the visual imagery, we adapted two existing tools that are geared toward the visualization of large image datasets: Coins, a tool that was originally developed to visualize the numismatic collection of the Berlin Münzkabinett, and VikusViewer, a generic visualization tool for large image collections (Glinka et al. 2017; Gortana et al. 2017).
Using Coins, we are able to visualize the extracted content illustration in relation to other metadata that we gathered. Mapping the illustrations against the text parts they appear in and the dates of their publication, we see that the temporal distribution of our extracted illustration is uneven. The illustrations from the Tractatus appear throughout the timeframe of our corpus, while most other illustrations (along with the parts they appear in) were only introduced after about 1530 (Fig. 4.16). We can also spot some patterns when mapping the illustrations by their date and place of publication (Fig. 4.17).

Content illustrations visualized using Coins. The content illustrations visualized on a horizontal time dimension and separated vertically by the text part they appear in. Most illustrations other than those originating from the Tractatus have been published only after around 1530

The patterns that appear when visualising content illustrations by time and place of publication corresponds to the periods of local book production as a whole and are not representative of the production of illustrations specifically
A gap appears around 1530 among the images printed in Venice. The earliest images from Wittenberg appear at the same time. These patterns have nothing to do with the production of illustrations, but merely stem from the fact that our corpus does not contain any editions that were published in these places at these times. It is crucial to be aware, when analyzing data through visualization, that not all dimensions of our data are being visualized. Patterns that emerge through visualization may in fact stem from invisible dimensions.
VikusViewer's main view is a temporal histogram composed of the images themselves, with the ability to zoom in for close-up inspection (Fig. 4.18). Here we see the same patterns that we identified in our earlier analysis. In addition to the histogram, VikusViewer offers a t-SNE layout, which arranges the images by visual similarity (Fig. 4.19). The method works by classifying each image using a neural network trained for image recognition, in this case the MobileNet network. Instead of using the classification label, the entire output vector of the network is used as a “fingerprint” for the images. This 1,000-dimensional vector is then projected into a two-dimensional space using the t-SNE algorithm, which visually positions images in proximity proportional to their relationship in the high-dimensional space. We can already identify groups of recurring images and, most importantly, large enough groups to enable us to build a dense network of books based on image similarities (Fig. 4.20). The grouping established by the t-SNE algorithm is however purely visual. We need additional algorithms to organize the images into groups that we can then use to establish our network. We will discuss the necessary steps below.

All the content illustrations in our collection are visualized in a temporal histogram using VikusViewer

The t-SNE view in VikusViewer groups the illustrations in our collection by visual similarity

A close-up of the VikusViewer t-SNE view (Fig. 4.19) with distinct groups of visually similar content illustrations
As a final visual exploration of the dataset of content illustrations, we have trained a generative adversarial network to analyze and visualize the data using artificially generated recurring image patterns learned from the Sphaera-images dataset. We have used the “Progressive growing” of GAN’s training method because it suits our contextually and visually diverse data well (Karras et al. 2017).
A GAN creates a generative model to create new unique data from trained patterns, in our case from the Sphaera-image data. A generative adversarial network consists of a “Generator” and a “Discriminator.” The Generator tries to make a new image, then the algorithm mixes generated images with real images to which the discriminator has to give a probability of reality. The goal of the Generator is to become a good forger and for the Discriminator to become a good curator. Through a feedback loop they keep improving each other until a good generative model is created.
To prepare our data for use with the algorithm, we had to gather a selection of images which could be made uniform in size. We decided to use all images from our set which had an aspect ratio of between 1:1.25 and 0.75:1 and contained at least 9 * 105 pixels. The images then were transformed to a 1:1 aspect ratio with 1024 × 1024 pixels. Most images already qualified unedited; all the others were transformed and interpolated to said size. A total 14,383 images qualified according to our preparation criteria.
The results gathered from the fully trained network were then cross analyzed by using the t-SNE method previously mentioned, to see if there were overarching groups to be recognized and to find advantages and disadvantages to the various methods, as well as whether this method brought us similar groupings when compared to the other visual techniques.
We saw that the generated images performed similarly to the real images when analyzed by our image similarity algorithm, although images that were scaled too much fell short. It did create a good overview of the dataset and a good clear visual representation of the different image patterns found therein. It also pointed out that many images, although visually/contextually similar, were grouped or created in another place in the latent space.
As the different forms of similarity are all hierarchically based on the philological groups, it will suffice to show our methods in creating such a cluster. The last section will show one example.
5 Clustering of Philological Groups
With clustering we try to group illustrations together by using data points obtained from abstractions generated from the illustrations in our dataset. We judge a clustering methods effectiveness by how it detects increasing similarity among the created groups and then we score the group on how well it matches an initial philological group that we formed manually.
5.1 Methods to Cluster
For the clustering we have used two different methods to compare and utilize different approaches. They both follow the same steps:
-
Create a value (usually a vector) from an abstraction of each image in a dataset;
-
Map each vector to a space for the entire dataset;
-
Calculate distance between the mapped points;
-
Group images according to a distance-based grouping scheme.
We have analyzed prevalent methods of abstracting and comparing images to achieve a better understanding and to select the right method for this particular task (Fig. 4.21). These methods are convolutional neural networks, residual neural networks, and differential hashing (Kravetz 2013). There also are older techniques studied such as ORB (Rublee et al. 2011), histogram distance, pre-neural-network-template-matching, and SIFT (Lowe 2004). We have studied how well these performed on our set of images using a purpose-built application. These techniques however did not deliver results that were comparable in quality to those previously mentioned.

Example of calculation of the Hamming distance of two dHash abstractions. The Euclidean distance of the ResNet Abstractions is also shown. Abstraction Analyzer tool Max Planck Institute for the History of Science
As mentioned, we use and compare two different methods to group illustrations while looking for identical ones. The first one is a conventional method that uses the Differential hashing (Kravetz 2013) of images and the Hamming distance between those hashes (Hamming 2013). We choose this method primarily for its transparency and explainability, as well as its efficiency and speed. The second grouping method uses a residual neural network, namely a ResNet-50v2 (He 2015) for the abstractions and k-means for the mapping and grouping. We have selected this process based on its proven high accuracy in recent computer science literature. A residual neural network is a suitable process for training a very deep convolutional neural network that creates abstractions from the images in our dataset. These abstractions then get clustered with a vector quantization method, in our case k-means. k-means-clustering is a vector quantization method that clusters the abstractions into a predetermined number of clusters with the nearest mean. These processes together give us a more complete understanding and overview of the data analyzed.
Process A
-
a.
Differential hashing
We use the difference hash—or dHash—algorithm, as this algorithm is both performant and, thanks to its relatively simple implementation, transparent in its operation. The steps for calculating the 8-byte dHash for a given image are as follows:
-
Reduce the image size to 9 × 8 pixels;
-
Convert the image to grayscale;
-
For every pixel, calculate the difference to adjacent pixels;
-
For every pixel, assign 1 when brighter, 0 when darker.
-
b.
Hamming distance
The hamming distance is an error measurement which compares two strings or lists, in our case binary strings. It starts at 0 and increases by 1 for every difference found between the binary strings:
-
Calculate the hamming distance between all images;
-
Save the nearest neighboring (lowest hamming distance) image for every image;
-
The output is a list with format (image original, image nearest neighbor, hamming distance).
-
c.
Cutoff grouping
-
Go over the list of nearest neighbors;
-
If hamming distance is higher than the threshold (9 in 8 byte), remove from list.
This method gives us the final grouping by adding all the images that are linked to the same group (Fig. 4.22).

Visualization of two images being compared by using a dHash abstractions and hamming distance. Screenshot of Abstraction Analyser, a purpose-built application to evaluate different image comparison algorithms developed by Daan Lockhorst
Process B
-
a.
Residual neural network
Neural networks have the highest image classification scores measured today in some of the more popular image dataset classification competitions (Russakovski et al. 2015). We have taken updated versions of xception (Chollet 2017), vgg19 (Simonyan and Zisserman 2014) and a ResNet-50v2 (He 2015), all implemented in the framework Keras (Chollet 2015). The ResNet-50v2 came out as the highest scoring after grouping it with k-means compared to our own philological group. We choose algorithms that have been part of scientific computing for some years but have recently been updated with newer technologies, over newer networks with a slightly higher possible score.
This process takes in an image scaled to 224 × 224 pixels with 3 color channels and returns a similar output vector to the dHash, though sized differently as a 128-byte string. All of the strings put together in a list can be represented as a high- (1,024) dimensional dataset and then reduced to a 2-dimensional dataset and mapped to a plane using a dimension reduction technique like t-SNE (Maaten and Hinton 2008) (Fig. 4.23).

Visualization in an adapted version of VikusViewer. In the top menu there all the dHash groups which can be selected to be highlighted. Distances between the images have been equalized
-
b.
Clustering the network output
Although it is possible to group the images using t-SNE and a distance grouping scheme, this can easily go wrong (Wattenberg et al. 2016). t-SNE loses some information every time it removes a dimension. Therefore, we use it solely for visualization in a dimension we can understand, so we use it solely for its visualization abilities. We have decided to map the input to a plane and to use a distance scheme to group, as is typical among image datasets. A well-trained, specialized final network output would yield higher results than a means, but we would lose the process’ general functionality and we would train and optimize for our own dataset alone. Replacing this last step with a neural network that is trained solely on a single grouping scheme can be an improvement if a higher score is needed.
For the clustering and grouping we use k-means (Lloyd 1982) implemented by Scikit-Learn, a tried and proven vector quantization method in which the amount of expected clusters has to be predefined. We had a good approximation of this information, but if it is not available or remains the subject of research, we recommend a different clustering scheme or that the number of groups found in the first round be utilized. This method finds a group for every image in the dataset. k-means clustering tries to minimize intra-cluster variances in an iterative manner by using their squared Euclidean distances as the vector to minimize. This process puts the data points in voronoi cells (Voronoï 1908), which indicate and visualize the border of each cluster (Fig. 4.24).

k-means clustering of the Sphaera-image dataset visualized with t-SNE. The white dots are the clusters centroids (https://scikit-learn.org Last accessed June 17, 2020)
5.2 Results
The scores of the dHash method (Process A) finds 43% of images correctly and the residual neural network method (Process B) 72%. We expected some loss of accuracy compared to the imagenet benchmark (83%) mainly because of the generalized approach inherent in using the k-means method to group our output and differing dataset to imagenet. The dHash score is around its expected score for similar tasks (Fig. 4.25).

Visualization in an adapted version of VikusViewer. Above there are the dHash groups which can now be compared: Group 0 is selected (all the images without a group)
5.3 Evaluation
We have learned that different approaches are advantageous in investigating a collection of images for their philological similarity. The various approaches can be used to yield false positives in one another's results by cross referencing and finding mistakes made in the general process.
The conventional method using the dHash algorithm is very fast, and the process is explainable. When investigating a dataset for irregularities, checking the quality of the data collected and the data preparation, it is a useful tool. If proof or explanation is needed, it is an advantage to have a clearly explainable algorithm. The neural network however boasts unprecedented accuracy in finding and mapping the groups of images into an easily visualizable space for analysis. In applying this method, we point our attention to one of the illustrations presented here: the representation of the terraqueous globe.
6 Diffusion, Communities, and Outlook
With our method, we were able to identify a group of 154 images representing the terraqueous globe as in (Fig. 4.3). The first advantage of such grouping becomes immediately evident when the illustrations are cross matched with standard metadata. By way of example, we show here the places of publication of the illustrations along a timeline (Fig. 4.26).

Diffusion of the illustration representing the terraqueous globe from its first occurrence in Ingolstadt in 1526 toward other places of publication until ca. 1620. To improve visibility, we have deleted the instances for Rome (5 illustrations), Cologne (5 illustrations), Saint Gervais (2 illustrations), Geneva (1 illustration), and Padua (1 illustration)
This visualization shows that this illustration was first printed in Ingolstadt (Sacobosco and Apian 1526) and then was rapidly adopted in Wittenberg, probably by re-carving the woodblock. Consistent with our results mentioned at the beginning of this work, the Wittenberg occurrence served as an amplifier all over Europe as shown by the adoption of the illustrations in the major early modern centers of book production: Venice, Paris, Antwerp, and Lyon.
In order to display the potential of our approach, we created a network to represent a community of book producers. In particular, we applied two conditions on the group of illustrations: we connected two book producers to each other when (a) at least one edition of each of them contains the illustration at hand, and (b) the two editions of each book producer were put on the market one after the other but within a time interval defined by the overlap of the two periods of work activity in the life of the two book producers. Moreover, as the scope of the present work is shy of a final encompassing historical interpretation (which would require work with all the clusters produced out of all the illustrations), we simplified the task by focusing only on the printers and ignoring the publishers, a choice that would prevent us from detecting the continuity of woodblock transmission. But that, at this stage, can nevertheless be neglected. Because of the fact that the group of illustrations at hand still requires a final round of clustering and cleaning, the resulting network displays possible commercial activities (due to travelling woodblocks) between places very distant from each other but in unrealistically short time intervals. To artificially avoid this problem—which will not appear when the analysis of the historical sources is completed at a deeper and more precise level—we decided to break down the entire network into as many network regions as there are regional areas represented in the data. These are regions that hold historical significance, such as those of Padua and Venice, or the great region of Paris, or the region that is delimited by Cologne, Frankfurt am Main, and Mainz. In this way we obtained a network constituted of seven discrete regions, each one chronologically oriented and representing a specific geographic area where treatises containing the illustration we are following were published. In this way, we can be more confident in defining communities of printers on the basis of woodblock circulation—at least more confident than we could be without any geographic or temporal limits. By way of example, we have zoomed in on the Venetian region (Fig. 4.27).

Social network of Venetian early modern printers defined on the basis of the production of editions of the Tractatus that contain the illustration representing the terraqueous globe so to assume that those printers were using the same woodblock to print this specific illustration
As mentioned, the network shown here cannot yet be seen as the final empirical network as extracted from the historical sources; some further clustering and cleaning are still needed and the role of the publishers (as distinguished from the one of the printers) must also be taken into consideration. However, it can already be observed that the great printer Girolamo Scoto (1505–1572), active on an international level, lies between the main sub-regions of the Venetian network. Moreover, the graph also displays the well-known economic vicinity of printers such as Domenico Basa (1500–1596) and Giovanni Battista Ciotti (1583–1635).
The empirical corroboration of all philological groups is not yet concluded. Thereafter, other groups, based on other forms of similarity, will be built according to the theoretical apparatus described in this essay. The community network, as well as the graphs that formalize the diffusion of visual knowledge in general, will finally become a mathematical matrix of the process of the evolution of visual knowledge in the cosmological textbooks of Europe in the early modern period. In general, we believe that this approach and this method will be transformed into a standard of the emerging field of computational history (Siebold et al. 2022).Footnote 13
Notes
- 1.
The corpus has been collected for the project “The Sphere: Knowledge System Evolution and the Shared Scientific Identity of Europe.” The collection is available online through the project website: https://sphaera.mpiwg-berlin.mpg.de (Last accessed 23 September 2022). For the function of this treatise and how it transformed over the centuries, see (Valleriani 2017). For a description of the corpus, concerning the places were the editions were printed, their book formats, their authors, printers, and publishers, as well as their language, see (Valleriani 2020).
- 2.
For Georg von Peuerbach’s role in the frame of the corpus of De sphaera, see Valleriani, M., Kräutli, F. et al. 2019. Peuerbach, Georg von. In Sphaera Database. Available at: hdl.handle.net/21.11103/sphaera.100965. Accessed 21 February 2021.
- 3.
For Pierio Valeriano’s role in the frame of the corpus of De sphaera, see Valleriani, M., Kräutli, F. et al. 2019. Valeriano, Pierio. In Sphaera Database. Available at: hdl.handle.net/21.11103/sphaera.100963. Accessed 21 February 2021.
- 4.
Donato Villalta’s carmen was printed for the first time in Valleriani, M., Kräutli, F. et al. 2019. Compendium in sphaeram per Pierium Valerianum Bellunensem. In Sphaera Database. Available at: hdl.handle.net/21.11103/sphaera.101194. Accessed 21 February 2021.
- 5.
For Philipp Melanchthon’s role in the frame of the corpus De sphaera, see Valleriani, M., Kräutli, F. et al. 2019. Melanchthon, Philipp. In Sphaera Database. Available at: hdl.handle.net/21.11103/sphaera.101002. Accessed 21 February 2021.
- 6.
Philipp Melanchthoin’s letter to Grynaeus was printed for the first time in Valleriani, M., Kräutli, F. et al. 2019. Liber Iohannis de Sacro Busto, de Sphaera. In Sphaera Database. Available at: hdl.handle.net/21.11103/sphaera.100138. Accessed 21 February 2021.
- 7.
The 1503 edition is Valleriani, M., Kräutli, F. et al. 2019. Textus Spere materialis Joannis de Sacrobusto. In Sphaera Database. Available at: hdl.handle.net/21.11103/sphaera.100931 (Accessed 21 February 2021). The 1509 edition is Valleriani, M., Kräutli, F. et al. 2019. Textus Spere materialis Joannis de Sacrobusto. In Sphaera Database. Available at: hdl.handle.net/21.11103/sphaera.101042 (Accessed 21 February 2021).
- 8.
For an analysis of Konrad Tockler’s scientific agenda and the positioning of his commentaries, see (Valleriani and Citron 2020).
- 9.
For the complete description of our ontology of text parts, see Sect. 3.1 of (Valleriani et al. 2019).
- 10.
- 11.
For more information about the diffusion of the illustration representing the terraqueous globe, see (Pantin 2020).
- 12.
For an interesting case of extremely long re-usage of a set of woodblocks in the context of different semantic scientific areas, see (Moran 2017).
- 13.
The encompassing historical research is being accomplished in a PhD dissertation by one of the authors of the present work, Noga Shlomi. The title of the work is “The Evolution of Scientific Visual Language in Early Modern Science: A Machine-Learning Based Analysis,” supported by the Cohn Institute for the History and Philosophy of Science and Ideas (Tel Aviv University), the Max Planck Institute for the History of Science (Berlin), and the Minerva Program of the Max Planck Society.
References
Ares Oliveira, S., B. Seguin, and F. Kaplan. 2018. dhSegment: A generic deep-learning approach for document segmentation. https://doi.org/10.1109/ICFHR-2018.2018.00011.
Axworthy, Angela. 2020. Oronce Fine and Sacrobosco: From the edition of the Tractatus de sphaera (1516) to the Cosmographia (1532). In De sphaera of Johannes de Sacrobosco in the early modern period: The authors of the commentaries, ed. Matteo Valleriani, 185–264. Cham: Springer Nature. https://doi.org/10.1007/978-3-030-30833-9_8.
Chollet, F. 2015. keras. https://github.com/keras-team/keras. Accessed 20 June 2020.
Chollet, F. 2017. Xception: Deep learning with depthwise separable convolutions. In 2017 IEEE Conference on computer vision and pattern recognition (CVPR), 1800–1807. Honolulu, HI. https://doi.org/10.1109/CVPR.2017.195.
Daston, Lorraine. 2015. Epistemic images. In Vision and its instruments: Art, science, and technology in early modern Europe, ed. Alina Payne, 13–35. University Park, Pa.: The Pennsylvania State University Press.
Daston, Lorraine, and Peter Galison. 1992. The image of objectivity. Representations 40: 81–128.
De Domenico, Manlio, Mason A. Porter, and Alex Arenas. 2015. Multilayer analysis and visualization of networks. Journal of Complex Networks 3: 159–176.
Givens, Jean A. 1999. Observation and image-making in Gothic art. Endeavour 23 (4): 162–166.
Glinka, K., C. Pietsch, and M. Dörk. 2017. Past visions and reconciling views: Visualizing time, texture and themes in cultural collections. Digital Humanities Quarterly 11 (2).
Gortana, F., F. von Tenspolde, D. Guhlmann, and M. Dörk. 2017. Coins. https://uclab.fh-potsdam.de/projects/coins.
Grafton, Anthony T. 2013. Commentary. In The classical tradition, ed. Anthony T. Grafton, Glenn W. Most, and Salvatore Settis, 225–233. Harvard, Ma.: The Harvard University Press.
Hamming, R.W. 2013. Error detecting and error correcting codes. The Bell System Technical Journal 29 (2): 147–160. https://doi.org/10.1002/j.1538-7305.1950.tb00463.x.
He, R.W. 2015. Deep residual learning for image recognition. arXiv:1512.03385v03381.
Karras, Tero, Timo Aila, Samuli Laine, and Jaakko Lehtinen. 2017. Progressive growing of GANs for improved quality, stability, and variation. arXiv:1710.10196v10193.
Kemp, Martin. 1996. Temples of the body and temples of the Cosmos: Vision and visualization in the Vesalian and Copernican Revolutions. In Picturing knowledge: Historical and philosophical problems concerning the use of art in science, ed. Brian S. Baigrie, 40–85. Toronto: University of Toronto Press.
Kräutli, Florian, and Matteo Valleriani. 2018. CorpusTracer: A CIDOC database for tracing knowledge networks. Digital Scholarship in the Humanities 33: 336–346. https://doi.org/10.1093/llc/fqx047.
Kravetz, N. 2013. Kind of like that. The Hacker Factor (blog). http://www.hackerfactor.com/blog/index.php?/archives/529-Kind-of-Like-That.html. Accessed 21 Jan 2013.
Kyle, Sarah Rozalja. 2017. Medicine and humanism in late Medieval Italy: The Carrara Herbal, in Padua. New York: Routledge.
Lloyd, S. 1982. Least squares quantization in PCM. IEEE Transactions on Information Theory 28 (2): 129–137. https://doi.org/10.1109/TIT.1982.1056489.
Lowe, David G. 2004. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision. https://doi.org/10.1023/B:VISI.0000029664.99615.94.
Maaten, Laurens van der, and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of Machine Learning Research 9: 2579–2605.
Moran, Bruce T. 2017. Preserving the cutting edge: Traveling woodblocks, material networks, and visualizing plants in early modern Europe. In The structures of practical knowledge, ed. Matteo Valleriani, 393–420. Cham: Springer Nature.
Müller, Kathrin. 2008. Visuelle Weltaneignung. Astronomische und kosmologische Diagramme in Handschriften des Mittelalters. Göttingen: Vandenhoeck & Ruprecht.
Müller, Kathrin. 2011. Gott ist (k)eine Sphäre. Visualisierungen des Göttlichen in geometrisch-abstrakten Diagrammen des Mittelalters. In Handbuch der Bildtheologie: Zwischen Zeichen und Präsenz, ed. Reinhard Hoeps, 311–355. Paderborn: F. Schöningh.
Nothaft, C. Philipp E. 2017. Criticism of trepidation models and advocacy of uniform precession in Medieval Latin astronomy. Berlin-Heidelberg: Springer.
Nuovo, Angela. 2013. The book trade in the Italian Renaissance. Leiden: Brill.
Oosterhoff, Richard J. 2018. Making mathematical culture: University and print in the circle of Lefèvre d’Étaples. Oxford: Oxford University Press.
Oosterhoff, Richard J. 2020. A lathe and the material sphaera: Astronomical technique at the origins of the cosmographical handbook. In De sphaera of Johannes de Sacrobosco in the early modern period: The authors of the commentaries, ed. Matteo Valleriani, 25–52. Cham: Springer Nature. https://doi.org/10.1007/978-3-030-30833-9_2.
Panofsky, Erwin. 1962. Artist, scientist, genius: Notes on the ‘Renaissance-Dämmerung.’ In The Renaissance: Six essays, ed. Ferguson K. Wallace, 121–184. New York: Harper & Row.
Pantin, Isabelle. 2014. Analogy and difference. A comparative study of medical and astronomical images in books, 1470–1550. In Observing the world through images: Diagrams and figures in the early-modern art and sciences, ed. Nicholas Jardine and Isla Fay, 9–43. Leiden: Brill.
Pantin, Isabelle. 2020. Borrowers and innovators in the printing history of Sacrobosco: The case of the “in-octavo” tradition. In De sphaera of Johannes de Sacrobosco in the early modern period: The authors of the commentaries, ed. Matteo Valleriani, 265–312. Cham: Springer Nature. https://doi.org/10.1007/978-3-030-30833-9_9.
Piccolomini, Alessandro. 1553. Editione Tertia. Della Sfera del Mondo di M. Alisandro Piccolomini, divisa in libri quattro, i quali non per via di traduttione, ne à qual si voglia particolare scrittore obligati, ma parte da migliori raccogliendo, e parte di nuovo producendo, contengano in se tutto quel ch'intorno à tal materia si possa desiderare, ridotti a tanta agevolezza, et à cosi facil modo di dimostrare, che qual si voglia poco essercitato ne gli studij di Mathematica potrà agevolißimamente, et con prestezza incenderne il tutto. Di nuovo ricorretta, et ampliata. Delle Stelle Fisse. Libro uno con le sue figure et con le sue tavole, dove con maravigliosa agevolezza potrà ciascuno conoscere qualunque stella delle quarantaotto imagini del Cielo stellato, et le favole loro integramente, et sapere in ogni tempo del'anno, à qual si voglia hora di notte, in che parte del Cielo si truovino, non solo le dette imagini, ma qualunque stella di quelle. Venice: Bartolomeo Cesano. https://hdl.handle.net/21.11103/sphaera.101047.
Piccolomini, Alessandro.1568. Alexandri Picolhominei de sphaera libri quatuor, ex Italico in Latinum sermonem conversi. Eiusdem compendium de cognoscendis stellis fixis: & de magnitudine Terrae & Aquae liber unus, it idem Latinus factus. Ioan. Nicol. Stupano Rheto interprete. Basel: Pietro Perna. https://hdl.handle.net/21.11103/sphaera.101113.
Pon, Lisa. 2004. Raphael, Dürer, and Marcantonio Raimondi: Copying and the Italian Renaissance Print. New Haven and London: Yale University Press.
Project Mirador. 2014. Mirador IIIF image viewer. http://projectmirador.org/.
Reeves, Eileen. 2017. The chiaroscuro woodcut in the early modern period. In the structures of practical knowledge, ed. Matteo Valleriani, 189–222. Cham: Springer Nature.
Rublee, E., V. Rabaud, K. Konolige, and G. Bradski. 2011. ORB: An efficient alternative to SIFT or SURF. In 2011 International conference on computer vision. Barcelona. https://doi.org/10.1109/ICCV.2011.6126544.
Russakovski, Olga, Kia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Muang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. 2015. ImageNet large scale visual recognition challenge. International Journal of Computer Vision. https://doi.org/10.1007/s11263-015-0816-y.
Sacobosco, Johannes de, and Petrus Apian. 1526. Sphaera Iani de Sacrobusto astronomiae ac cosmographiae candidatis scitu apprime necessaria per Petrum Apianum accuratissima diligentia denuo recognita ac emendata. Ingolstadt: Petrus Apianus. https://hdl.handle.net/21.11103/sphaera.100070.
Sacrobosco, Johannes de. 1516. Sphera materialis. Nuremberg: Jobst Gutknecht. https://hdl.handle.net/21.11103/sphaera.100186.
Sacrobosco, Johannes de, and Christoph Clavius. 1611. Christophori Clavii Bambergensis e Societate Iesu Operum Mathematicorum Tomus Tertius Complectens Commentarium in Sphaeram Ioannis de Sacro Bosco, & Astrolabium. Mainz: Reinhard Eltz for Anton I Heirat. Reprint, Clavius, Christoph. In Sphaeram Ioannis de Sacro Bosco commentarius, ed. Eberhard Knobloch. Hildesheim: Olms-Weidmann, 1999. https://hdl.handle.net/21.11103/sphaera.100383.
Sacrobosco, Johannes de, and Philipp Melanchthon. 1568. Iohannis de Sacro Busto Libellus de sphaera. Accessit eiusdem autoris computus ecclesiasticus, Et alia quaedam, in studiosorum gratiam edita. Cum praefatione Philippi Melanthonis. Wittenberg: Johann Krafft the Elder. https://hdl.handle.net/21.11103/sphaera.101112.
Sacrobosco, Johannes de, and Pedro Nuñez. 1537. Tratado da sphera com a Theorica do Sol et da Lua. E ho primeiro livro da Geographia de Claudio Ptolomeo Alexandrino. Tirados novamente de Latim em lingoagem pello Doutor Pero Nunez Cosmographo del Rey Don João ho terceyro deste nome nosso Senhor. E acrecentatos de muitas annotaçiones et figuras per que mays facilmente se podem entender. Item dous tratados quo mesmo Doutor fez sobre a carta de marear. Em os quaes se decrarano todas as principaes du vidas da navegação. Con as tavoas do movimento do sol: et sua declinação. Eo regimento da altura assi ao meyo dia: como nos outros tempos. Com previlegio real. Lisbon: Galharde. https://hdl.handle.net/21.11103/sphaera.101010.
Sacrobosco, Johannes de, Joannes Regiomontanus, and Georg von Peurbach. 1490. Spaerae mundi compendium foeliciter inchoat. Noviciis adolescentibus: ad astronomicam rem publicam capessendam aditum impetrantibus: pro brevi rectoque tramite a vulgari vestigio semoto: Ioannis de Sacro busto sphaericum opusculum una cum additionibus nonnullis littera A sparsim ubi intersertae sint signatis: Contraque cremonensia in planetarum theoricas delyramenta Ioannis de monte regio disputationes tam acuratiss. atque utills. Nec non Georgii purbachii in erundem motus planetarum acuratiss. theoricae: dicatum opus: utili serie contextum: fausto sidere inchoat. Venice: Ottaviano Scoto I. https://hdl.handle.net/21.11103/sphaera.100885.
Siebold, Anna and Matteo, Valleriani. 2022. Digital Perspectives in History. Histories 2(2): 170–177. https://doi.org/10.3390/histories2020013
Simonyan, Karen, and Andrew Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. https://arxiv.org/abs/1409.1556.
Valeriano, Pierio. 1537. Compendium in sphaeram per Pierium Valerianum Bellunensem. Rome: Antonio Blado. https://hdl.handle.net/21.11103/sphaera.101194.
Valleriani, Matteo. 2017. The tracts on the sphere. Knowledge restructured over a network. In Structures of practical knowledge, ed. Matteo Valleriani, 421–473. Dordrecht: Springer.
Valleriani, Matteo. 2020. Prolegomena to the study of early modern commentators on Johannes de Sacrobosco’s Tractatus de sphaera. In De sphaera of Johannes de Sacrobosco in the early modern period: The authors of the commentaries, ed. Matteo Valleriani, 1–23. Cham: Springer Nature. https://doi.org/10.1007/978-3-030-30833-9_1.
Valleriani, Matteo, and Nana Citron. 2020. Conrad Tockler’s research agenda. In De sphaera of Johannes de Sacrobosco in the early modern period: The authors of the commentaries, ed. Matteo Valleriani, 111–136. Cham: Sringer Nature. https://doi.org/10.1007/978-3-030-30833-9_5.
Valleriani, Matteo, Florian Kräutli, Maryam Zamani, Alejandro Tejedor, Christoph Sander, Malte Vogl, Sabine Bertram, Gesa Funke, and Holger Kantz. 2019. The emergence of epistemic communities in the Sphaera Corpus: Mechanisms of knowledge evolution. Journal of Historical Network Research 3: 50–91. https://doi.org/10.25517/jhnr.v3i1.63.
Voronoï, Georges. 1908. Nouvelles applications des paramètres continus à la théorie des formes quadratiques. Deuxième mémoire. Recherches sur les parallélloèdres primitifs. Journal Für Die Reine Und Angewandte Mathematik 134: 198–287.
Wattenberg, Martin, Fernanda Viégas, and Ian Johnson. 2016. How to use t-SNE effectively. Distill. https://doi.org/10.23915/distill.00002.
Werner, Sarah. 2019. Studying early printed books. 1450–1800. A practical guide. Hoboken, NJ: Wiley Blackwell.
Witcombe, Christopher L.C.E. 2004. Copyright in the renaissance: Prints and the privilegio in sixteenth-century Venice and Rome. Leiden: Brill.
Zamani, Maryam, Alejandro Tejedor, Malte Vogl, Florian Kräutli, Matteo Valleriani, and Holger Kantz. 2020. Evolution and transformation of early modern cosmological knowledge: A network study. Scientific Reports—Nature 10: 19822. https://doi.org/10.1038/s41598-020-76916-3.
Acknowledgements
The present work was also supported by the Berlin Institute for the Foundations of Learning and Data (BIFOLD-ref. 01IS18037A). We finally would like to express our gratitude to Beate Federau for her support in exploring the conceptual workflow for detecting communities among book producers through the identification of the circulation of woodblocks.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this chapter

Cite this chapter
Valleriani, M., Kräutli, F., Lockhorst, D., Shlomi, N. (2023). Vision on Vision: Defining Similarities Among Early Modern Illustrations on Cosmology. In: Valleriani, M., Giannini, G., Giannetto, E. (eds) Scientific Visual Representations in History. Springer, Cham. https://doi.org/10.1007/978-3-031-11317-8_4
Download citation
DOI: https://doi.org/10.1007/978-3-031-11317-8_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-11316-1
Online ISBN: 978-3-031-11317-8
eBook Packages: HistoryHistory (R0)