
Abstract
The emotions that students experience when engaging in tasks critically influence their performance and many models of learning and competence include assumptions about affective variables and respective emotions. However, while researchers agree about the importance of emotions for learning, it remains challenging to connect momentary affect, i.e., emotions, to learning processes. Advances in automated speech recognition and natural language processing (NLP) allow real time detection of emotions in recorded language. We use NLP and machine learning techniques to automatically extract information about students’ motivational states while engaging in the construction of explanations and investigate how this information can help more accurately predict students’ learning over the course of a 10-week energy unit. Our results show how NLP and ML techniques allow the use of different modalities of the same data in order to better understand individual differences in students’ performances. However, in realistic settings, this task remains far from trivial and requires extensive preprocessing of the data and the results need to be interpreted with care and caution. Thus, future research is needed before these methods can be deployed at scale.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
Learning is an emotional enterprise. The texts that students study in language classes can spark joy, sadness, or anger, experiments in science class can spark awe, and a challenging mathematical problem can lead to confusion. Models of competence or literacy (Nokes & Belenky, 2011; Sinatra, 2005) and educational standards (Secretariat der ständigen Konferenz, 2020; National Research Council, 2012; OECD, 2016) generally acknowledge the role that emotions – or affect more generally – play in learning and applying knowledge. However, as Fortus (Fortus, 2014) lamented in 2014, the level of attention given to emotions and affect remains low. A state of affairs that has not changed much since and continues to limit our understanding of and ability to support learning.
This state can in part be explained by the challenges in capturing the dynamic nature of emotions with the temporal resolution necessary to meaningfully relate them to learning processes without interrupting these very processes by the measurement process when traditional self-report measures are used. MultimodalFootnote 1 learning analytics have the potential to solve this issue as advances in techniques such as automated affect recognition and natural language processing allow continuous tracking of emotions and affect, e.g., using voice or facial recordings (D’Mello & Kory, 2015). Combined with process data of learning activities or performances, this allows the relation and integration of affective and cognitive measures, thus better reflecting models of competence and learning.
The remainder of this chapter is structured in the following way: first, we provide a brief introduction to emotions (Sect. 2) and the relevant literature on emotions and learning (Sect. 3). Then, we will dive into the challenges of measuring emotions more deeply and discuss the potentials of multimodal learning analytics (Sect. 4). Turning to the practical side of things next, we will demonstrate the application of multimodal learning analytics in a worked example (Sect. 5). Finally, we conclude with recommendations and open questions for future work (Sect. 6).
2 What Are Emotions?
Emotions are complex phenomena comprising affective, cognitive, physiological, motivational, and expressive components (Pekrun & Linnenbrink-Garcia, 2014; Damasio, 2004). The joy a student feels when they for example, has been accepted at Harvard, is an amalgam of positive, happy feelings (affective), thoughts about how that might shape her future (cognitive), increased heart rate (physiological), the impulse to tell her friends and family (motivational), and a smile on her face (expressive). Emotions are different from moods as emotions are more intense than moods but also last shorter. Further, emotions are usually responses to specific stimuli. The connection to contexts and the temporal dynamics are important when the interplay between moods and emotions is considered, e.g., when a student often feels anxiety when answering a question in class, this may lead to an anxious mood over time. Thus overall, moods can be interpreted as a low intensity state version of the high intensity trait emotion (Pekrun, 2006). Together, emotions and moods make up the more general category of affect.
Affective states can be described along the two dimensions of valence and activation (Shuman & Scherer, 2014). Valence ranges from positive states such as happiness or satisfaction to negative states such as frustration or sadness. Activation distinguishes between physiologically activating and deactivating states. For example, enjoyment and relief have both positive valence but enjoyment is activating whereas relief is deactivating. Similarly, anger and hopelessness are both negative emotions, anger being activating and hopelessness deactivating. Research may either resolve individual emotions or focus on broader omnibus constructs such as positive or negative affect that encompass multiple positive or negative states.
Individual emotions (also referred to as discrete emotions) can also be categorized on the basis of their focus (Pekrun, 2006). With regard to the study of teaching and learning, achievement emotions, epistemic emotions, topic emotions, and social emotions are important foci of emotions (Pekrun & Linnenbrink-Garcia, 2014). Pekrun (2006) defines achievement emotions “as emotions tied directly to achievement activities or achievement outcomes.” Achievement emotions can be related to activities such as engaging in a learning task or outcomes such as exams. Epistemic emotions relate to the cognitive processes of information processing (D’Mello & Graesser, 2012), e.g., when experimental results violate expectations in a significant way, this may cause surprise or even awe (Valdesolo et al., 2017). Topic emotions are evoked by the contents of a learning environment (Broughton et al., 2013), e.g., the study of human evolutionary history may cause anxiousness for some students. While the emotions that specific topics cause can vary greatly between individuals, they can have a profound influence on learning outcomes (Broughton et al., 2013). Lastly, teaching and learning – as all human activity – is situated in a social context. The emotions related to the other persons inhabiting this context are social emotions and can have a profound influence on how teachers and students and students among each other interact (Linnenbrink-Garcia et al., 2011).
In sum, emotions provide a precise language and mature theory that can complement the affective aspects of learning theories. Further, they are the concrete momentary manifestations that mediate (González et al., 2017; Pekrun et al., 2009) motivational omnibus constructs such as goal orientation (Elliot et al., 1999) or self-efficacy (Bandura, 1977).
3 Emotions and Learning
In the literature on emotions and learning, two broad strands can be distinguished: (1) research that focuses on relations between emotions and learning outcomes e.g., (González et al., 2017; Pekrun et al., 2009; Frenzel et al., 2007) and (2) research that focuses on the role of emotions in different learning processes e.g., (D’Mello & Graesser, 2012; Frenzel et al., 2007; Muis et al., 2015).
3.1 Emotions and Learning Outcomes
Pekrun’s (2006) control-value theory of achievement emotions has been highly influential in describing distal and proximal antecedents to and outcomes of achievement emotions. In essence, it states that the emotions students experience in achievement situations depend on the extent to which they feel in or out of control in these situations and to what extent these achievement situations are important to them (Pekrun & Perry, 2014). The appraisal of the importance of the achievement situation has been linked to students’ achievement goals (Elliot et al., 1999). Students may endorse mastery goals, that is, students focus on deep understanding and care little about social comparisons. In contrast, students may also endorse performance goals, that is, students focus on social comparisons, i.e., being better than others (performance approach) or not being worse than others (performance avoidance) and care little about deep understanding. As an example, take a student that endorses performance avoidance goals and is about to write an important exam but did not find time to study. In this situation, the student has little control over the outcome as they are not prepared and failing the exam has high value in the sense that it is subjectively important to them not to perform worse than others. According to Pekrun (2006), this leads to a feeling of hopelessness. In contrast, a student that did find sufficient time to study can control the outcome of the exam. Having control about the outcome of the important exam would predict a feeling of hope or even anticipatory joy.
The emotions that students feel in achievement situations impact numerous cognitive and motivational processes that ultimately determine students’ performances. Unpleasant emotions can draw on working memory resources or stifle engagement in a task. Pleasant emotions promote heuristic and flexible information processing and support self-regulation (Kahneman, 2012). Table 1 gives an overview of the empirically found relations between achievement emotions and student performance based on a sample of 218 undergraduate students. In all cases, achievement emotions mediated the effects of achievement goals.
Similarly, Gonzalez, Fernandez, and Paoloni (2017) found in an empirical study with 520 Spanish high school students, that hope and anxiety mediated the effect of self-efficacy (Bandura, 1977) on performance in physics. Further, they demonstrated hope and anxiety affect performance through their influence on self-regulatory processes such as monitoring or planning strategies. Taken together, these findings show how achievement emotions impact students’ performance and suggest avenues for interventions to support students, e.g., supporting students in emotion regulation. However, in the studies mentioned here, emotions were measured using paper-pencil questionnaires, i.e., relatively distal measures. Similarly, student performance was assessed using the relatively distal and not necessarily valid nor reliable measure of grades. Thus, these studies remain on a coarser grain size that does not resolve the role of emotions and their dynamics for learning processes.
3.1.1 Emotions and Learning Processes
Following Piaget (2013), learning processes can be understood in terms of two adaptive processes: assimilation and accommodation. Assimilation describes processes of adjusting the perception of the external world to the structures of the individuals’ internal world. Assimilation is associated with little effort, creativity, and generally positive affect. In contrast, accommodation requires the reconfiguration of the individuals’ internal structures to the external world and is more challenging and associated with negative affect. As an example for these processes, consider a child that is familiar with local birds seeing a rarer bird, such as an owl in a visit to the zoo. The child will have little trouble in identifying the owl as another instance of the concept bird. In this assimilation process, the child maps the internal concept of bird on the perceived outside world. Now consider the same child seeing a penguin later and being told that a penguin is also a bird. This information requires modification of the child’s concept of bird because the child will have to adjust the importance of being able to fly in their concept of bird, i.e., in this accommodation process, the child modified their mental structure to fit the outside world.
Accommodation processes have been the focus of extensive research under the conceptual change tradition in the learning sciences (Posner et al., 1982; Amin & Levrini, 2018). Despite these efforts, our understanding of conceptual change and how students can be supported in this process remains limited (Amin & Levrini, 2018), partly because research has focused on cognitive aspects of conceptual change, neglecting complex interactions between cognitive and affective processes (Pintrich et al., 1993; Mason et al., 2008). Recently however, a number of studies have started to investigate the role of emotions in learning processes.
D’Mello & Graesser (2012) observed the affective states of students as they worked with an automated tutor for Newtonian physics. They were able to relate distinct emotions and transitions between these emotions to students’ learning processes (see Fig. 1). They found that when students engaged in a learning activity are confronted with information that does not easily fit into their mental models, i.e., they encounter a situation that leads to an impasse and requires conceptual change, they transition from a state of flow and engagement to confusion. If students were then able to resolve the impasse, they transitioned back to a state of engagement/flow. This can form a loop of transitions between flow / engagement and confusion that lead to successful deep learning. However, students may also fail to resolve the impasse, get stuck and become frustrated. Frustration as a negative but activating emotion can then lead to increased effort.

Affect dynamics and related learning processes. (Adapted from D’Mello and Graesser 2012)
If the increased effort leads to a resolution of the impasse, students may transition back to successful learning. However, if the increased effort does not lead to success, persistent failure leads to a state of disengagement and boredom. Thus, this research shows that epistemic emotions like confusion play an integral part in deep learning as confusion accompanies the necessary deep processing.
Further evidence for the importance of epistemic emotions in facilitating learning through inducing different processing strategies comes from a study by Muis et al. (2015). Drawing on a sample of 495 undergraduate students from the United States, Canada, and Germany, they found that epistemic emotions predicted learning strategies which then mediated the effects of epistemic emotions on learning outcomes. More specifically, they found curiosity and anxiety leading to critical thinking, curiosity and enjoyment leading to elaboration, and enjoyment also leading to rehearsal. At first, it may seem counterintuitive that anxiety leads to critical thinking and thus higher achievement but some unpleasant emotions are known to facilitate careful, deep processing (Kahneman, 2012). Similarly, enjoyment does not only lead to elaboration but also to a shallow strategy like rehearsal. This underlines that valence alone does often not sufficiently resolve affective processes to understand learning. Instead, distinct emotions need to be considered to better understand the complex interplay of affect and cognition.
In sum, the results from D’Mello and Greasser (2012) and Muis et al. (2015) underline that emotions play an important role for successful learning and that cognitive and affective processes interact in complex, dynamic ways. Measuring cognitive and affective processes on the relatively short time scales necessary to better resolve these complex, dynamic interactions however remains challenging. Answering this challenge will not only help our understanding of student learning but also open up new possibilities to support students, e.g., through affect sensitive feedback (Grawemeyer et al., 2017) or emotion regulation support (D’Mello, 2017).
4 Measuring Emotions
Two approaches to measuring emotions in learning environments can be distinguished: self-report and observation. Self-report measures, that is, questionnaires, have been used with great success in research on academic emotions and learning outcomes. While valid and reliable questionnaires are available (Pekrun & Bühner, 2014), capturing the dynamics of emotions in realistic learning environments is challenging due to practical constraints – how often and how extensive can self-report measures be administered without interfering with the affective and cognitive processes that students undergo, thus invalidating the measurement? Observational measures, e.g., facial expressions, can account for some of these limitations but do not scale economically. However, recent advances in automated affect detection, drawing on machine learning and large annotated observational data sets, have the potential to solve this issue (Reisenzein et al., 2014). From a learning analytics perspective, the most relevant, that is, available, data modalities are text, voice, and facial data. Learners produce text across a variety of learning activities and in different formats, ranging from short responses to questions about a reading to elaborate essays. In order to measure affect from such texts, one can either use sentiment analysis (see e.g., Veltri, 2013; Veltri & Atanasova, 2017) or trained Natural Language Processing (NLP) algorithms. Sentiment analysis uses annotated corpora of text to determine the valence and sometimes distinct emotions that are associated with words. Trained NLP algorithms often rely on trained supervised machine learning models to assign valence or distinct emotions to text. Automatic detection of emotions from voice or facial data often also draws on trained machine learning models to determine valence or distinct emotions. A comprehensive review (D’Mello & Kory, 2015) found that combining multiple data sources yields better results, making a strong argument in favor of multimodal approaches. However, practical considerations often limit the range of data sources available, e.g., when working with students in schools, it is hard to have high quality video and audio data from every student and data protection concerns may inhibit the collection of video data. Further, the extent to which these techniques, especially using ready trained machine learning models, yield valid results in realistic learning environments remains questionable as they are often based on “clean” data sources (see e.g., (Lima et al., 2013)), e.g., voice samples for emotion recognition is often recorded with adults in professional studios and not with students from highly varying demographics in noisy classrooms.
5 An Applied Example
In the following, we will demonstrate how NLP and machine learning (ML) techniques can be used to extract information about students’ affect as they engage in a typical classroom activity and how this information can help to better understand students’ learning.
5.1 Data Sources
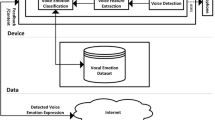
In our example, we draw on data from a larger study on students’ learning about energy in middle school (see Fortus et al., 2019 for more details). Figure 2 shows the overall design.

Overall design and data sources
In total, 423 students form three schools in the midwestern United States participated in the study. Before and after the unit, all students answered a goal orientation survey and answered a knowledge-in-use about energy tests. In addition, a subsample of 71 students was interviewed after the unit. Students were selected by the teachers to cover the whole range of student abilities. Based on the energy knowledge-in-use assessments after the unit, the interviewed students represent a slightly positive selection which is to be expected with students that are willing to be interviewed.
Goal Orientation Survey
The goal orientation measure was adopted from Vedder-Weiss and Fortus (2011). Here, we focus on the mastery goal orientation scale. It consisted of five items with a five-point Likert-scale. Students rated statements from “not true at all” (1) to “very true” (5). The statements in the items reflect aspects of mastery goal orientation. In consequence, higher scores indicate stronger endorsement of mastery goal orientation. Higher mastery goal orientation is associated with deeper processing strategies and thus higher task performance and improved learning (see e.g., (Elliot et al., 1999)). The effect of mastery goal orientation however is known to be mediated by (academic) emotions (Pekrun et al., 2009).
In order to obtain a measure of students’ mastery orientation, a polytomous Rasch analysis was performed (DeMars, 2010). Reliability proved satisfactory (α = 0.84) and all items fell within satisfactory infit and outfit limits (Bond & Fox, 2015).
Energy Knowledge-in-Use Test
Students’ understanding of energy was assessed using open-ended tasks which required that students blend disciplinary knowledge, science practices, and cross-cutting concepts in order to make sense of real-world phenomena, i.e., demonstrate knowledge-in-use about energy (Harris et al., 2016). Figure 3 shows an example item. The tasks were scaled using polytomous Rasch techniques. The Weighted Likelihood Estimates (WLE) for person separation reliability was found to be satisfactory (0.64) and all items fell within satisfactory infit and outfit limits. For more details on the task design, validation, and psychometric properties see Fortus et al., 2019.

Example knowledge-in-use about energy task
Interviews
Students were interviewed individually following a semi-structured interview-about-instances protocol (Osborne & Gilbert, 1980). Following this protocol, students were shown short videos of five different phenomena, e.g., a bouncing ball or a cart oscillating between two springs. After each of the phenomena, the interviewer asked: “How can you use scientific ideas to explain why the [object in video] moves like it does?”. After students’ initial response, non-instructional prompts were used to clarify ambiguous student statements. All interviews were transcribed for analysis.
5.2 Analyses and Workflow
With the presented data at hand, we wanted to investigate how students’ motivation as measured by their mastery goal orientation and affect could help us to understand their performance on the energy knowledge-in-use assessments after the unit. With no dedicated affect measure available, we turned to the interview data and used two different approaches to extract information about students’ affect from it. First, we used the transcript and NLP techniques; next, we used machine learning techniques that took the actual audio data from the interviews as an input.
Using NLP to Obtain Valence
First, we decided to work from the transcripts of the interviews. Figure 4 shows an overview of the analysis process.

Analysis procedure to obtain a valence scores from the interview data
The EmoBank Dataset
In order to obtain valence measures from the students’ transcriptions, we trained a neural network NLP model on the EmoBank database, a large-scale text corpus manually annotated with emotion according to the psychological Valence-Arousal-Dominance Scheme (Buechel & Hahn, 2017a, b). This dataset contains 10 K sentences balancing multiple genres (News, Fictions, Blogs, Essays, Letters and Travel Guides) and each sentence is annotated with the emotion which is expressed by the writer and the emotion which is perceived by the readers. In our case, we used the combined ratings of both writer and readers to increase reliability, following the suggestions of the EmoBank’s authors (EmoBank Repository, n.d.). We trained our model on the task of outputting the combined valence score associated with each input sentence of the database. We used the EmoBank since some of the text samples are similar to the ones we found in the students’ interviews transcriptions (Table 2).
Preprocessing the Data
First, we performed a tokenization of the text, which consists of associating a unique integer (or token) to each word (or sub-word) of the vocabulary. Consequently, a sentence originally composed as a sequence of words is now represented as a sequence of tokens (which represent biunivocally the original words). In practice, the text was tokenized using the BERT tokenizer from the HuggingFace library (Wolf et al., 2020) after which the average number of tokens per instance is 21. In order to standardize the size of the input, each instance was padded to a maximum length of 50 tokens, so that most of the instances in the dataset remained complete (the percentage of truncated instances with originally more than 50 tokens is lower than 5%). We use the special token 0 to pad the instances with less than 50 tokens.
The Model Architecture
We used a simple architecture for our neural network, which consisted of an embedding layer initialized with the weights of the initial embeddings from a pre-trained BERT language model (Devlin et al., 2019), a sum layer and a feed forward neural network on top. The embedding layer associates to each token of the input a high dimensional vector obtained through a language model (the padding token 0 is associated with the null vector, so that the padding process doesn’t introduce noise to the input). In this work, we used a BERT pre-trained language model that allows us to work with tokens at the subword level, but any other word embedding language model (such as word2vec (Mikolov et al., 2013) or GloVe (Pennington et al., 2014)) can work for this purpose. We set this layer to be non-trainable in order to reduce the number of parameters that the neural network has to learn. Afterwards, we applied a sum layer to the output of the embedding layer, so that the different word vectors obtained previously are summed up into a single vector that summarizes all the information coming from the input. Finally, this last vector is fed up to a Feed Forward Neural Network (FFNN) with a single hidden layer. The output of this layer is the score for the valence measure. Furthermore, we added a batch-normalization (Ioffe & Szegedy, 2015) and a dropout (of 20%) regularization layer (Srivastava et al., 2014) before and after the hidden layer of the FFNN respectively to increase the generalization power of the model.
Model Training and Evaluation
We split the EmoBank database into 8062 samples for training, 791 samples for validation, and 1000 for testing, following the split recommended by the authors of the dataset. We trained our model through a classical gradient descent approach to optimize the Mean Squared Error (MSE) over the valence score using an ADAM optimizer (Kingma & Ba, 2017) for 100 epochs and we saved the weights at the epoch in which the loss on the validation set is minimal. We evaluated our model by measuring the Mean Absolute Error (MAE) and the Pearson’s correlation coefficient (r) between our predictions and the combined valence scores on the test set (Fig. 5), replicating what the authors of EmoBank used for measuring the inter-annotator agreement (IAA) (Buechel & Hahn, 2017b). We found a MAE of 0.213 and a r value of 0.567 (with a p-value <<0.05 on a two-sided p-value). We found that these results were satisfying comparing them with the IAA metrics reported by the EmoBank’s authors (Table 3) for the valence score (r value of 0.689 and 0.738, and MAE of 0.300 and 0.349 for the writers and readers respectively). Moreover, the r value obtained by our model for the valence score is higher than the one obtained by more complex models in the different domains of the EmoBank corpus (Zhu et al., 2019).

Predicted vs. real valence measure
Using ML to Obtain Discrete Emotions
In addition to the text data, we decided to use yet another modality of the data, i.e., the actual audio. Figure 6 shows an overview of the analysis process.

Analysis procedure to obtain discrete emotions from the interview data
Emo_DB and Surrey Audio-Visual Expressed Emotion (Savee) Databases
The Emo_DB database comprises about 800 sentences. Five female and five male actors simulated seven emotions (neutral, anger, fear, joy, sadness, disgust and boredom), producing 10 German utterances each (Burkhardt et al., 2005). The Surrey Audio-Visual Expressed Emotion (Savee) database consists of 480 recordings from four native English male actors in seven different emotions (neutral, anger, disgust, fear, happiness, sadness and surprise), generating 120 utterances per speaker (Haq et al., 2008).
Preprocessing the Data
Audio files were recorded at a sampling rate of 44,100 Hz and lasted, on average, 9 minutes (range between 4 and 16 minutes). The preprocessing consists in splitting the audio files using Audacity in order to extract the students-only voice, this task was performed manually since speaker diarization with childrens’ data in noisy settings (The interview was performed in a room with noise and the presence of teachers and students coming in and out the room.) is a difficult task and rare, showing that the performance is lower than other difficult tasks (see Cristia et al., 2018). The split sample consisted of 1492 audio segments, with an average of 53 audio segments per student. There were segments related to administrative talk, when students say their names and agree to participate in the study. The majority of segments were physical ideas explained by students, sometimes the interviewer asked the students to explain some concepts deeper so students rephrase or explain their ideas in other words.
Emotion Classification and Interview
With the splitting task completed, the audio segments were later classified into five different emotions (neutral, happy, sad, angry and fear) with the free version of Vokaturi (n.d.): OpenVokaturi SDK (Garcia-Garcia et al., 2017), which uses two databases detailed above to train the emotion recognition algorithms, so no model training was needed as we use the architecture of the OpenVokaturi as it is. The output is the probability distribution of each of the emotions.
5.2.1 Statistical Analyses
Valence Based Analyses
The NLP Model provided us with a valence measure for every utterance of the student in an interview. To be able to relate students’ valence with their performance on the energy test after the unit and their mastery goal orientation, we needed to aggregate the data. After taking a look at the distribution of valence scores across the sample (Fig. 7), we decided to use each students’ median to characterize their valence during the interview. Next, we calculated correlations between students’ valence, mastery goal orientation, and score on the energy test. Finally, we used regression models to further investigate how valence could help us to better understand students’ performance on the energy test after the unit.

Ridgeplot of students’ valence score distributions
Discrete Emotions Based Analyses
Vokaturi’s ML model provided us with a probability for each students’ utterance to reflect either happiness, sadness, anger, joy, or a neutral emotional state. In a first step, we decided to focus only on those utterances where the algorithm identified the emotional state with a probability of at least 80%. Figure 8 shows the resulting counts of emotional states for each student. It becomes apparent that the students did not primarily experience single emotions but must have transitioned through numerous emotional states during the interview. Further, neutral and fear show little variance compared to the other three emotions. In consequence, we decided that students’ emotions could best be characterized by their emotional profiles.

Counts of each students’ emotional states during the interviews
We used the tidyLPA package (Rosenberg et al., 2018) in R (R Development Core Team, 2008) to identify the profiles through a latent profile analysis. Following the selection procedure by Akogul & Erisoglu (Akogul & Erisoglu, 2017), a three profile solution based on the data from all emotions provided the best fit. As fear and neutral showed little variance, we also conducted a latent profile analysis based on angry, happy, and sad only. Again, a three-profile solution showed the best fit according to the Akogul & Erisoglu procedure. This solution also provided slightly better overall fit compared to the solution obtained with all emotions. Therefore, we chose to continue our analyses with the solution obtained from angry, happy, and sad only. Figure 9 shows the three different profiles.

The profile solution
Profile 1 shows relatively low numbers regarding all emotional episodes. Profile 2 exhibits the highest number of happy episodes and comparable numbers of sad and angry episodes with reference to profile 1. Profile 3 shows a pattern of only few happy and angry episodes but the highest number of sad episodes. With these profile solutions at hand, we proceeded with regression models to further investigate how students’ emotional profiles could help us to better understand students’ performance on the energy test after the unit.
5.3 Results
Valence Based Results
Table 4 shows the correlations between valence, students’ energy knowledge-in-use after the unit, and their mastery goal orientation.
While valence and mastery goal orientation are both statistically significantly related with students’ performance on the energy knowledge-in-use test, valence and mastery goal orientation themselves appear not to be related.
Table 5 shows the results from a regression model with students’ knowledge-in-use about energy after the unit as a dependent variable. The results show that higher valence is related to higher test performance while adjusting for mastery goal orientation and students’ prior knowledge. Further, when we compared this model to a version that did not include valence, we found that it explained 8 percentage points more of the variance (F(1,45) = 4.55, p = 0.04). Thus, our results suggest that higher valence is related with higher student performance and helps explain an additional significant portion of variance in students’ performance than just mastery goal orientation and students’ prior knowledge.
Discrete Emotions-Based Results
Table 6 shows the results from a regression model with students’ knowledge-in-use about energy after the unit as a dependent variable. The results indicate that students in profile 3 perform statistically significantly better on the knowledge-in-use energy assessments after unit than students in profile 1 or 2 while adjusting for students’ prior knowledge. Further, when we compared this model to a version that did not include the emotional profiles, we found that it explained 50 percentage points more of the variance. However, given that profile 3 was the profile with the high number of sad episodes pattern, we considered these results with caution as sadness is usually not related to higher academic performance. Thus, we decided to investigate how the valence measure was related to the different emotional profiles. Surprisingly, we found that valence was the highest for students in profile 3 while it was lower and similarly distributed in profiles 1 and 2. In sum, our results suggest that the emotional profiles help explain a large amount of the individual differences between students’ performance on the knowledge-in-use assessments after the energy unit. However, the fact that profile 3 which showed a prevalence of sad emotional states was related to improved performance and the fact that profile 3 was also associated with relatively high valence requires further discussion.
6 Discussion
Our results demonstrate how NLP and ML techniques allow us to use different modalities of the same data, voice and transcript, and different modalities of different data sources, voice data from interviews, answers to a goal orientation questionnaire, and answers to open ended questions about energy, in order to better understand individual differences in students’ performances. The valence based analysis supports that students’ emotions play an important role in understanding students’ academic performances beyond cognitive variables such as prior knowledge, and motivational traits such as goal orientation (Pekrun et al., 2009). The analysis based on discrete emotions obtained via ML further supports the role of emotions in students’ academic achievement but also shows where automated procedures need to be used with care and domain expertise is crucial when interpreting the results.
6.1 Valence Based Results
The substantive and positive correlation between students’ valence and their academic achievement, i.e., their score on the knowledge-in-use energy assessment, aligns well with the literature on academic emotion (Pekrun & Linnenbrink-Garcia, 2014; González et al., 2017; Pekrun et al., 2017). The small correlation between students’ mastery goal orientation and valence resembles the findings in (Pekrun et al., 2017). Taken together, this provides evidence for the (external) validity of the extracted valence. Finally, the explanatory power of valence in students’ performance on the energy knowledge-in-use assessments after the unit beyond students’ goal orientation and prior knowledge also aligns well with previous research on the relationship between academic emotions, goal orientation and achievement and extends those findings from achievement in psychology to achievement in physics (Pekrun et al., 2009). In this sense, our results affirm the inclusion of emotions in models of competence (Nokes & Belenky, 2011; Sinatra, 2005) and demonstrate that accounting for them can lead to a better understanding of individual differences in student performance.
The approach demonstrated here has a huge potential for classroom applications as students learning is happening increasingly in digital ecologies (Neumann & Waight, 2020). Whenever students produce text in these in their learning activities, valence measures can easily be obtained and used in order to identify students that may need emotional support or to tailor how automated feedback is delivered (for an example see (Grawemeyer et al., 2017)). Further, the affect measure could be used to identify in what part of the learning process and related affect dynamics students are (D’Mello & Graesser, 2012). Such data could then be used to inform the design of learning environments that help students stay in the productive loop (oscillating between equilibrium/flow and disequilibrium (Fig. 1)) or escape the unproductive loop (oscillating between stuck and disengagement (Fig. 1)). For such applications however, it would be beneficial to be able to extract discrete emotions and the intensity of these emotions from students’ texts. At the moment, there is a lack of annotated text data to train ML algorithms for such applications.
6.2 Discrete Emotions-Based Results
The results based on the discrete emotions extracted from the actual audio are at the same time impressive and sobering. On the one hand, using out of the box software and real-life data, i.e., not lab-based data, we were able to extract emotional profiles that helped explain students’ performance on the knowledge-in-use assessments after the energy unit. On the other hand, students with the emotional profile that had the highest number of sad episodes performed the best and showed the highest valence values. These results make little sense from a theoretical perspective (Linnenbrink-Garcia et al., 2011). How can we explain these results then? After listening closely to the respective interview section again, we concluded that what the software had identified as sadness seemed more like slight anxiety or calmness to us. Students in this profile appeared to be rather confident in their answers, providing their explanations in a very matter of fact manner and only sometimes hesitating about details. The interpretation that what the algorithm identified as sadness was in fact calmness or very small levels of anxiety aligns well with previous research (Muis et al., 2015; Kahneman, 2012; Fiedler & Beier, 2014). Further, interpreting students’ answers as competently answering science questions would also align well with the high valence extracted from the text data. Finally, it seems plausible that a ML model that was trained on acted, professionally recorded audio data from adults might struggle to correctly identify children’s emotions. However compelling our interpretation may be, in the end, the results based on the discrete emotions extracted from the audio data are nowhere as clear-cut as the valence-based results. Thus, out of the box software cannot be expected to just run and provide sensible results. Instead, careful interpretation and triangulation with other data sources appears necessary, underlining the need for further research on automated affect detection in real-life settings expressed by D’Mello and Kory (2015) and potentially the need for building training datasets that better reflect the characteristic of classroom audio data.
6.3 Challenges in Multi-Modal Affect Detection
The source of challenges discussed in this chapter are two folded: the source of the data and obtaining labelled data. In the first place, data in a real learning environment is noisy, not structured and context dependent. In particular, we struggled with identifying the audio segments which contained students’ interaction. On the other side, speaker diarization, the task of identifying who is speaking and when, has caught the attention of researchers and there are several methods which perform quite well. The diarization task in real-world scenarios is one of the hardest and is relatively rare. Cristia et al. (2018) tried to perform this task with children’s speech in different scenarios and their performance was much lower than on other difficult machine learning tasks. Moreover, Kumar et al. (2020) studied diarization focusing on adult-child interactions and identified contextual factors which affect diarization. They found that a state-of-the-art diarization system does not perform well on real child-speech interactions, children interactions tend to be classified as adult interaction when they are short utterances, intense and with high relative strength between noise-only and speech-only components. In the same line, we also faced difficulties segmenting the audio files in order to obtain the students-only utterances in the interview automatically. Thus, we decided to split the audio manually, which was time consuming and, therefore, led to a lower number of students considered in the applied example.
Obtaining and labelling data is indeed a costly process especially in the context of education, in which the labelling process requires the participation of educational researchers or trained observers (e.g., for coding emotions in students’ transcriptions or for performing classroom observation out of recorded class lessons). In general, supervised (labelled/coded) data is limited, which represents one of the major challenges for building robust and reliable multimodal models. In fact, training a model on a reduced dataset introduces a bias to the model, affecting the validity of the model’s predictions when the data inputs come from a different distribution than the training set. For example, in our particular case there are few open datasets for “emotion detection from texts”, none of them containing specifically interview transcriptions from young students. This suggests that using these datasets for training an emotion detection model may introduce a significant bias to the model, since the data for which we want to obtain predictions (the students’ interview transcriptions) is likely to come from a different distribution than the one in which we want to train our model. More generally, this example shows a relevant limitation in the multimodal affect detection setting in the context of education, where input data for ML models will often be composed of speech audio signals, speech text transcriptions, and/or video recordings of facial expressions or body gestures. In fact, this type of data is likely to be biased towards particular characteristics of its origin. For example, the tone of voice and even the facial expressions in response to a particular stimulus can change dramatically for different ages and cultures, so that building up a robust data set might require the participation of several individuals of different characteristics. Furthermore, in some cases, the training data is generated in lab conditions in which people act different emotions or responses that can differ dramatically from real classroom conditions.
In acknowledgment of the previous limitation, in our experiment we used the EmoBank dataset, since we found some similarity between some of its text samples and the transcribed lines of the students’ interviews. Moreover, the multiple genres present in the dataset reduce the previous bias towards a particular text type.
However, on a more general level, we would like to point out that automatically detecting emotions is not only challenging on a technical level but more fundamentally on a theoretical and ethical level. First, although there has been substantial development in the research on emotions, debate remains active about even basic questions such as “What is an emotion?” (Adolphs et al., 2019). Second, assumptions about the universality of emotions and their expression, especially in facial features, have recently received extensive scrutiny and are increasingly questioned (Crawford, 2021). In consequence, researchers who wish to employ emotion analytics need to very carefully consider and operationalize what they mean by the term emotion (or affect). Further, with the universality of emotions in question, researchers need to be especially careful when it comes to selecting training data or applying pre-trained systems and diligently consider the validity of their results, especially in light of the recent examples where neglect in the selection of training data resulted in discriminatory systems (Benjamin, 2019). This last point is especially relevant when it comes to the probably most interesting use of ML and NLP: the case where we use these methods to do something that goes beyond human abilities. When we used the textual modality of the data to obtain a valence measure, we were getting valence values for utterances that hardly contain valence information for the human eye. Yet, having enough valence annotated text at our disposal, we could train a computer system that picked up patterns beyond our recognition. At least, that is what the patterns of correlations with other measures suggests because they fit with well-established theoretical expectations. However, how could we detect bias and misclassification, for example of racial minorities, in this case? Such an analysis would have been possible for the analysis where we obtained discrete emotions from the audio data because in this case humans are actually able to do the classification. Thus, we may find ourselves Scylla and Charybdis when the most interesting uses of ML and NLP – where computers do things that humans cannot – are those where the arguments for the validity of our results are the least defensible.
7 Conclusion
Overall, we see a great promise in exploiting the multimodality of data in order to extract information about students’ emotions or affect more generally and the valence base analysis in this chapter provides a compelling example. At the same time, similar to the conclusion of D’Mello & Kory (2015), the discrete emotions based analysis showed that we are not quite there yet. Using audio (or video) from classroom settings still requires extensive preprocessing and the results need to be interpreted with care and caution. However, given the potential for better understanding the relation between learning and affect, resolving individual differences between students, and implementing respective supports, we urge the field to take on those challenges. Taking algorithms out of labs and into the wild will help to identify the limitations of the current systems and to further improve them. At the same time, there is a need to build large annotated databases that better reflect the characteristics of the real-life settings in which we as researchers want to apply automated affect detection systems as the quality of any ML system crucially relies on the data used to train it.
Notes
- 1.
Throughout this article, we use multimodal to refer to the (combined) analysis of multiple modalities of the same data, i.e., audio recordings of interviews carry content but also pragmatic information, e.g., in the form of stress and inflection.
References
Adolphs, R., Mlodinow, L., & Barrett, L. F. (2019). What is an emotion? Current Biology, 29, R1060–R1064. https://doi.org/10.1016/j.cub.2019.09.008
Akogul, S., & Erisoglu, M. (2017). An approach for determining the number of clusters in a model-based cluster analysis. Entropy, 19, 452. https://doi.org/10.3390/e19090452
Amin, T., & Levrini, O. (Eds.). (2018). Converging perspectives on conceptual change: Mapping an emerging paradigm in the learning sciences. Routledge.
Bandura, A. (1977). Self-efficacy: Toward a unifying theory of behavioral change. Psychological Review, 84, 191–215. https://doi.org/10.1037/0033-295X.84.2.191
Benjamin, R. (2019). Race after technology: Abolitionist tools for the new Jim code. Polity.
Bond, T. G., & Fox, C. M. (2015). Applying the Rasch model: Fundamental measurement in the human sciences. Routledge/Taylor and Francis Group.
Broughton, S. H., Sinatra, G. M., & Nussbaum, E. M. (2013). “Pluto Has Been a Planet My Whole Life!” Emotions, attitudes, and conceptual change in elementary students’ learning about Pluto’s reclassification. Research in Science Education, 43, 529–550. https://doi.org/10.1007/s11165-011-9274-x
Buechel, S., & Hahn, U. (2017a). Readers vs. writers vs. texts: Coping with different perspectives of text understanding in emotion annotation. In Proceedings of the 11th linguistic annotation workshop (pp. 1–12).
Buechel, S., & Hahn, U. (2017b). Emobank: Studying the impact of annotation perspective and representation format on dimensional emotion analysis. In Proceedings of the 15th conference of the European chapter of the association for computational linguistics (Vol. 2, Short Papers, pp. 578–585).
Burkhardt, F., Paeschke, A., Rolfes, M., Sendlmeier, W. F., & Weiss, B. (2005). A database of German emotional speech. In Ninth European conference on speech communication and technology.
Crawford, K. (2021). Atlas of AI: Power, politics, and the planetary costs of artificial intelligence. Yale University Press.
Cristia, A., Ganesh, S., Casillas, M., & Ganapathy, S. (2018). Talker Diarization in the Wild: the Case of Child-centered Daylong Audio-recordings. In Interspeech 2018 (pp. 2583–2587). ISCA. https://doi.org/10.21437/Interspeech.2018-2078
D’Mello, S. (2017). Emotional learning analytics. In Columbia University, USA, C. Lang, G. Siemens, University of Texas at Arlington, USA, A. Wise, New York University, USA, D. Gasevic, & University of Edinburgh, UK (Eds.), Handbook of learning analytics (pp. 115–127). Society for Learning Analytics Research (SoLAR). https://doi.org/10.18608/hla17.010
D’Mello, S., & Graesser, A. (2012). Dynamics of affective states during complex learning. Learning and Instruction., 22, 145–157. https://doi.org/10.1016/j.learninstruc.2011.10.001
D’Mello, S. K., & Kory, J. (2015). A review and meta-analysis of multimodal affect detection systems. ACM Computing Surveys, 47, 1–36. https://doi.org/10.1145/2682899
Damasio, A. (2004). Emotions and feelings: A neurobiological perspective. In W: ASR Manstead, N. Frijda, A. Fischer (red.) (Ed.), Feelings and emotions (pp. 49–57). Cambridge University Press.
DeMars, C. (2010). Item response theory. Oxford University Press.
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding, arXiv:1810.04805 [cs].
Elliot, A. J., McGregor, H. A., & Gable, S. (1999). Achievement goals, study strategies, and exam performance: A mediational analysis. Journal of Educational Psychology, 91, 549–563. https://doi.org/10.1037/0022-0663.91.3.549
EmoBank Repository. https://github.com/JULIELab/EmoBank/tree/master/corpus
Fiedler, K., & Beier, S. (2014). Affect and cognitive processes in educational contexts. In International handbook of emotions in education (pp. 36–55). Routledge/Taylor & Francis Group.
Fortus, D. (2014). Attending to affect. Journal of Research in Science Teaching, 51, 821–835. https://doi.org/10.1002/tea.21155
Fortus, D., Kubsch, M., Bielik, T., Krajcik, J., Lehavi, Y., Neumann, K., Nordine, J., Opitz, S., & Touitou, I. (2019). Systems, transfer, and fields: Evaluating a new approach to energy instruction. Journal of Research in Science Teaching. https://doi.org/10.1002/tea.21556
Frenzel, A. C., Pekrun, R., & Goetz, T. (2007). Girls and mathematics—A “hopeless” issue? A control-value approach to gender differences in emotions towards mathematics. European Journal of Psychology of Education, 22, 497–514. https://doi.org/10.1007/BF03173468
Garcia-Garcia, J. M., Penichet, V. M. R., & Lozano, M. D. (2017). Emotion detection: A technology review. In Proceedings of the XVIII international conference on human computer interaction – Interacción ’17 (pp. 1–8). ACM Press. https://doi.org/10.1145/3123818.3123852
González, A., Fernández, M.-V. C., & Paoloni, P.-V. (2017). Hope and anxiety in physics class: Exploring their motivational antecedents and influence on metacognition and performance. Journal of Research in Science Teaching, 54, 558–585. https://doi.org/10.1002/tea.21377
Grawemeyer, B., Mavrikis, M., Holmes, W., Gutiérrez-Santos, S., Wiedmann, M., & Rummel, N. (2017). Affective learning: Improving engagement and enhancing learning with affect-aware feedback. User Modeling and User-Adapted Interaction, 27, 119–158. https://doi.org/10.1007/s11257-017-9188-z
Haq, S., Jackson, P. J., & Edge, J. (2008). Audio-visual feature selection and reduction for emotion classification. In Proceedings of the international conference on auditory-visual speech processing (AVSP’08). Tangalooma.
Harris, C. J., Krajcik, J. S., Pellegrino, J. W., & McElhaney, K. W. (2016). Constructing assessment tasks that blend disciplinary core ideas, crosscutting concepts, and science practices for classroom formative applications. SRI International.
Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift, arXiv:1502.03167 [cs].
Kahneman, D. (2012). Thinking, fast and slow. Penguin Books.
Kingma, D. P., & Ba, J. (2017). Adam: A method for stochastic optimization, arXiv:1412.6980 [cs].
Kumar, M., Kim, S. H., Lord, C., & Narayanan, S. (2020). Improving speaker diarization for naturalistic child-adult conversational interactions using contextual information. The Journal of the Acoustical Society of America, 147, EL196–EL200. https://doi.org/10.1121/10.0000736
Lima, C. F., Castro, S. L., & Scott, S. K. (2013). When voices get emotional: A corpus of nonverbal vocalizations for research on emotion processing. Behav Res., 45, 1234–1245. https://doi.org/10.3758/s13428-013-0324-3
Linnenbrink-Garcia, L., Rogat, T. K., & Koskey, K. L. K. (2011). Affect and engagement during small group instruction. Contemporary Educational Psychology, 36, 13–24. https://doi.org/10.1016/j.cedpsych.2010.09.001
Mason, L., Gava, M., & Boldrin, A. (2008). On warm conceptual change. Journal of Educational Psychology, 100, 291–309. https://doi.org/10.1037/0022-0663.100.2.291
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space, arXiv:1301.3781 [cs].
Muis, K. R., Pekrun, R., Sinatra, G. M., Azevedo, R., Trevors, G., Meier, E., & Heddy, B. C. (2015). The curious case of climate change: Testing a theoretical model of epistemic beliefs, epistemic emotions, and complex learning. Learning and Instruction, 39, 168–183. https://doi.org/10.1016/j.learninstruc.2015.06.003
National Research Council. (2012). A framework for K-12 science education. The National Academies Press.
Neumann, K., & Waight, N. (2020). The digitalization of science education: Déjà vu all over again? Journal of Research in Science Teaching, 57, 1519–1528. https://doi.org/10.1002/tea.21668
Nokes, T. J., & Belenky, D. M. (2011). Incorporating motivation into a theoretical framework for knowledge transfer. In Psychology of learning and motivation (pp. 109–135). Elsevier.
OECD: Global competency for an inclusive world, (2016).
Osborne, R. J., & Gilbert, J. K. (1980). A technique for exploring students’ views of the world. Physics Education, 15, 376.
Pekrun, R. (2006). The control-value theory of achievement emotions: Assumptions, corollaries, and implications for educational research and practice. Educational Psychology Review, 18, 315–341. https://doi.org/10.1007/s10648-006-9029-9
Pekrun, R., & Bühner, M. (2014). Self-report measures of academic emotions. In International handbook of emotions in education (pp. 561–579). Routledge/Taylor & Francis Group.
Pekrun, R., & Linnenbrink-Garcia, L. (Eds.). (2014). International handbook of emotions in education. Routledge/Taylor & Francis Group.
Pekrun, R., & Perry, R. P. (2014). Control-value theory of achievement emotions. In International handbook of emotions in education (pp. 120–141).
Pekrun, R., Elliot, A. J., & Maier, M. A. (2009). Achievement goals and achievement emotions: Testing a model of their joint relations with academic performance. Journal of Educational Psychology, 101, 115–135. https://doi.org/10.1037/a0013383
Pekrun, R., Lichtenfeld, S., Marsh, H. W., Murayama, K., & Goetz, T. (2017). Achievement emotions and academic performance: Longitudinal models of reciprocal effects. Child Development, 88, 1653–1670. https://doi.org/10.1111/cdev.12704
Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532–1543).
Piaget, J. (2013). Construction of reality in the child. Routledge.
Pintrich, P. R., Marx, R. W., & Boyle, R. A. (1993). Beyond cold conceptual change. Review of Educational Research., 63, 167–199.
Posner, G. J., Strike, K. A., Hewson, P. W., & Gertzog, W. A. (1982). Accommodation of a scientific conception: Toward a theory of conceptual change. Science Education, 66, 211–227. https://doi.org/10.1002/sce.3730660207
R Development Core Team. (2008). R: A language and environment for statistical computing. R Foundation for Statistical Computing.
Reisenzein, R., Junge, M., Studtmann, M., & Huber, O. (2014). Observational approaches to the measurement of emotions. In International handbook of emotions in education (pp. 580–606).
Rosenberg, J., Beymer, P., Anderson, D., van Lissa, C. J., & Schmidt, J. (2018). tidyLPA: An R package to easily carry out latent profile analysis (LPA) using open-source or commercial software. Journal of Open Source Software, 3, 978. https://doi.org/10.21105/joss.00978
Secretariat der ständigen Konferenz der Kultusminister der Länder in der Bundesrepublik Deutschland: Bildungsstandards im Fach Physik für die Allgemeine Hochschulreife. (2020).
Shuman, V., & Scherer, K. R. (2014). Concepts and structures of emotions. In International handbook of emotions in education (pp. 13–35).
Sinatra, G. M. (2005). The “Warming Trend” in conceptual change research. Educational Psychologist, 40, 107–115. https://doi.org/10.1207/s15326985ep4002_5
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15, 1929–1958.
Valdesolo, P., Shtulman, A., & Baron, A. S. (2017). Science is awe-some: The emotional antecedents of science learning. Emotion Review, 9, 215–221. https://doi.org/10.1177/1754073916673212
Vedder-Weiss, D., & Fortus, D. (2011). Adolescents’ declining motivation to learn science: Inevitable or not? Journal of Research in Science Teaching, 48, 199–216. https://doi.org/10.1002/tea.20398
Veltri, G. A. (2013). Microblogging and nanotweets: Nanotechnology on Twitter. Public Understanding of Science, 22, 832–849. https://doi.org/10.1177/0963662512463510
Veltri, G. A., & Atanasova, D. (2017). Climate change on Twitter: Content, media ecology and information sharing behaviour. Public Understanding of Science, 26, 721–737. https://doi.org/10.1177/0963662515613702
Vokaturi. https://developers.vokaturi.com/getting-started/overview
Wolf, T., Chaumond, J., Debut, L., Sanh, V., Delangue, C., Moi, A., Cistac, P., Funtowicz, M., Davison, J., Shleifer, S., et al. (2020). Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: System demonstrations (pp. 38–45).
Zhu, S., Li, S., & Zhou, G. (2019). Adversarial attention modeling for multi-dimensional emotion regression. In Proceedings of the 57th annual meeting of the association for computational linguistics (pp. 471–480).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this chapter

Cite this chapter
Kubsch, M., Caballero, D., Uribe, P. (2022). Once More with Feeling: Emotions in Multimodal Learning Analytics. In: Giannakos, M., Spikol, D., Di Mitri, D., Sharma, K., Ochoa, X., Hammad, R. (eds) The Multimodal Learning Analytics Handbook. Springer, Cham. https://doi.org/10.1007/978-3-031-08076-0_11
Download citation
DOI: https://doi.org/10.1007/978-3-031-08076-0_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-08075-3
Online ISBN: 978-3-031-08076-0
eBook Packages: Computer ScienceComputer Science (R0)