
Abstract
Heart failure is one of the leading causes of hospitalization and rehospitalization in American hospitals, leading to high expenditures and increased medical risk for patients. The discharge location has a strong association with the risk of rehospitalization and mortality, which makes determining the most suitable discharge location for a patient a crucial task. So far, work regarding patient discharge classification is limited to the state of the patients at the end of the treatment, including statistical analysis and machine learning. However, the treatment process has not been considered yet. In this contribution, the methods of process outcome prediction are utilized to predict the discharge location for patients with heart failure by incorporating the patient’s department visits and measurements during the treatment process. This paper shows that, with the help of convolutional neural networks, an accuracy of 77% can be achieved for the hospital discharge classification of heart failure patients. The model has been trained and evaluated on the MIMIC-IV real-world dataset on hospitalizations in the US.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
With a rehospitalization rate of up to 45% within six months of discharge, heart failure is the leading cause of rehospitalization and a significant cause of hospitalization for patients over the age of 65 in American hospitals [2, 4]. This constitutes a high medical risk for the patients and leads to high expenditures and workload for hospitals and other treatment facilities patients are discharged to after treatment in the hospital. However, as the rehospitalization rate varies depending on the discharge location, the decision on the most suitable discharge location is of high importance [7].
Up to now, determining characteristics and actual prediction models for the discharge location are primarily based on statistical methods, which mainly look at the patient’s state at the end of hospitalization [2, 12]. The idea of this contribution is to incorporate the treatment process of heart failure patients to make the final decision about the discharge location based on the whole treatment process. Therefore, this paper applies process outcome prediction, a business process management technique, using machine learning to predict hospital discharge locations. In practice, this approach can serve as a decision support system to choose the appropriate discharge location more accurately, as we consider the treatment process instead of merely looking at the patient’s state at the end of treatment.
The remainder of the paper is structured as follows: Sect. 2 lays the theoretical foundation on heart failure, process outcome prediction, and convolutional neural networks, followed by an overview of related work. The specifics of the MIMIC-IV dataset, which we used as a foundation for the subsequent work, are covered in Sect. 3. In Sect. 4, we describe our approach and elaborate on the discharge location prediction using convolutional neural networks trained on the MIMIC-IV dataset. Results and a discussion are part of the evaluation in Sect. 5. Section 6 summarizes our contribution and outlines future work.
2 Preliminaries and Related Work
This section provides an overview of the domain of heart failure and introduces the concepts used in the remainder of this paper. Additionally, we present related work regarding patient discharge classification and process outcome prediction.
2.1 Heart Failure
Following the American Heart Association (AHA)/American College of Cardiology guidelines [10], Roger defines heart failure as “a complex clinical syndrome that can result from any structural or functional cardiac disorder that impairs the ability of the ventricle to fill or eject blood” [17]. Heart failure was chosen as the application area as this is the leading cause of rehospitalization for people older than 65 years with a rehospitalization rate within six months of up to 45% [2, 4, 18]. According to Howie et al., the rehospitalization risk strongly varies depending on the discharge location [2, 7]. In their study, heart failure patients discharged to home or home health care had a 2.6 times higher risk of rehospitalization than those discharged to skilled nursing facilities (SNF), emphasizing the importance of the decision on the discharge location.
2.2 Process Outcome Prediction
“Business Process Management (BPM) includes concepts, methods, and techniques to support the design, administration, configuration, enactment, and analysis of business processes” [21]. The area of business process monitoring as a branch of business process management provides means to analyze events occurring during process executions, allowing for insights on the overall process and how to improve it. A subfield of business process monitoring, predictive business process monitoring, aims at making predictions about future states of current process executions based on the activities performed so far and other previously executed process instances.
One technique emerging from that field in recent years is process outcome prediction. According to Teinemaa et al., it can be defined as “classifying each ongoing case of a process according to a given set of possible categorical outcomes” with case in this context referring to a single process execution [19]. The advantages of this technique are better predictability and the potential to improve the decision-making during process executions [22]. Approaches to process outcome prediction are settled in the fields of statistics and supervised machine learning as a classification problem [8, 19].
2.3 CNN
Convolutional Neural Networks (CNNs) are deep neural networks that are commonly used for sequence classification tasks and process outcome prediction [14, 20, 22]. Originally, CNNs became popular for pattern recognition in, for example, computer vision tasks, i.e., the analysis of images. A CNN architecture comprises three elements: convolutional layers, pooling layers, and fully-connected layers. Convolutional layers perform convolutions using kernels of different sizes to extract relevant high-level features from the input data, reducing dimensionality. Pooling layers are used to perform down-sampling to reduce the complexity for subsequent layers. In fully-connected layers, each node has a direct connection to every node in the next layer up to the final layer, that finally produces the output [1].
2.4 Related Work
Research has been conducted on determining factors leading to patients being discharged to different discharge locations using statistical approaches. In [12], Kobewka et al. performed a systematic review to identify models and variables with predictive power for discharge location decisions after stays in intensive care units. Their results show that age, impaired physical function, and the absence of an informal caregiver are of high importance. Similarly, Allen et al. conducted an observational analysis of heart failure patients at the age of 65 or above to determine the most relevant aspects of patients and hospitals associated with discharge to SNF [2]. Their most influential predictors are the total length of stay, patient age, different comorbidities, and gender. Apart from statistical analysis, machine learning has been applied to classify the discharge location of patients by incorporating the patient’s temperature, blood pressure, comfort, and more at the end of the treatment process [6].
In the field of process outcome prediction, Teinemaa et al. present a systematic review and taxonomy of process outcome prediction methods together with a comparative experimental evaluation of a subset of these methods [19]. The approaches taken into account primarily focus on features that are not changing throughout the process. In contrast, Le et al. introduced an approach they call Markov sequence alignment, which focuses on temporal features. Their method is an extension of Markov models that uses temporal categorical features extracted from past process executions to predict the following steps during process execution, as well as the process outcomes [13]. Leontjeva et al. present a multi-class sequence classification approach to incorporate constant and temporal features where a hidden Markov model or Long Short-Term Memory (LSTM) is trained on the temporal features followed by a random forest model trained on the constant features enriched by the temporal model’s results [14]. Recent research has evaluated the application of CNNs in the field of process outcome prediction. In their comparison of CNN with LSTM architectures, Weytjens et al. conclude that “CNNs deliver the same results as the state-of-the-art LSTMs at a fraction of the time and can therefore be recommended as the first choice for practitioners” [22].
Applying process outcome prediction to the discharge location classification of heart failure patients allows for early resource allocation for the discharge facilities due to the improved predictability during a patient stay. Patients currently undergoing treatment in a hospital can be assigned the most probable discharge location, allowing treatment facilities and services, such as SNF, to predict their workload better and adjust their resource planning and staffing accordingly. Furthermore, process outcome prediction enables a process oriented decision-making by making the decision not only based on the patient’s state at the end of the treatment but also on the development of the patient’s state during the treatment process.
3 Dataset
We use the Medical Information Mart for Intensive Care (MIMIC)-IV database [11] as a data foundation for the discharge location prediction. The database is publicly available on PhysioNet [5] (authorized access due to privacy regulations - see licenseFootnote 1) and contains information on over 40,000 patients admitted to the Beth Israel Deaconess Medical Center in Boston, Massachusetts, from 2008 to 2019. The data is stored in a relational database format. All information was de-identified by obfuscating the exact time of events while retaining their chronological order, which allows for the application of process mining and process outcome prediction.
The MIMIC-IV dataset consists of 35 tables in which, amongst other information, the following patient data is stored: Demographic information on patients, such as their age and marital status, transfers between departments during their stay, as well as the medications they received in each of them. Furthermore, various information on diagnoses is provided, e.g., International Classification of Diseases (ICD) codes, Diagnosis-related Group (DRG) codes, and laboratory values resulting from laboratory tests for patients, e.g., hemoglobin, creatinine, and urea nitrogen values.
4 Contribution
The contribution is presented in three steps. First, we describe the process of selecting the cohort. Second, the steps of feature selection and preprocessing are explained. Lastly, we describe the architecture of the prediction model.
4.1 Cohort Selection
The cohort of patients was selected based on the diagnosis, and the DRG of the hospital stay to identify patients where heart failure was treated. The dataset stores diagnoses as so-called ICD codes. Thus, we selected all patients who had a heart failure related diagnosis as their primary diagnosis. Today, two ICD coding systems co-exist in hospitals, which are ICD-9 and ICD-10. For ICD-9, the codes starting with 428 are related to heart failure, whereas for ICD-10, the codes starting with I50 are heart failure related.
Second, we used DRG codes to identify only those patients whose primary reason for hospitalization was heart failure. DRG codes correspond to the main reason for a patient’s stay at the hospital. All cardiac related DRG codesFootnote 2 were considered, which can be seen in the script for data extraction from the MIMIC-IV databaseFootnote 3.
With the combination of a heart failure primary diagnosis and a cardiac-related DRG, it is known that the patients suffered from heart failure and that this was the primary reason for their hospitalization. Filtering for these characteristics, the dataset provides a total of 12,306 stays of 7,693 patients.
The discharge location is stored for each patient stay, with 13 different discharge locations available. The three most frequent discharge locations for heart failure patients found in the MIMIC-IV dataset are home (3,430 stays, 27.9%), home health care (4,982 stays, 40.5%), and SNF (2,323 stays, 18.9%). As the other discharge locations have a frequency of less than 4%, we decided to focus on the discharge locations listed above to have a sufficient sample size for each class for model training and testing.
Since the discharge to SNF is associated with high costs and workload for medical personnel, we also decided to make predicting discharge to SNF the primary goal of our classification models. Additionally, there is a need to better characterize the patient population being discharged to SNF [2]. This reduces the complexity to binary classification where we predict SNF vs. others (representing discharge to home or home health care).
Considering only heart failure patients discharged to the three most frequent discharge locations, the resulting number of patient stays serving as data points for model training, validation, and testing is 10,725.
4.2 Feature Selection and Data Preprocessing
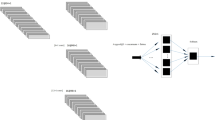
In order to represent the process behind the data, i.e., the order of departments each patient visits during a stay, the data is required to be in a three-dimensional shape. We consider the different features across multiple time steps for each patient stay individually. A visualization of the data’s shape is shown in Fig. 1. This allows us to combine features that do not change during a patient’s stay, such as age and gender, with features that may be different for every department visit, such as the length of stay there and laboratory values measured in a department.
Initially, the features taken into account were selected based on the literature presented in Sect. 2.4. This selection included the total length of stay in the hospital, patient age, and gender, which do not change during a stay. Furthermore, the selection of variables included the stay duration, the med count representing the number of medications received, and the lab count representing the number of laboratory values resulting from analyses conducted, which are different for each stay in a department. Starting with these features, we tested and compared multiple combinations with additional features and their impact on the predictive performance, resulting in the final feature selection shown in Table 1. In addition to the aforementioned features, incorporating information on the patient’s insurance situation, marital status, ethnicity, and the number of ICD codes associated with them, meaning the number of different diagnosed disease patterns, lead to improved predictive performances. Also, taking laboratory values such as creatinine, hemoglobin, red blood cells, glucose, and urea nitrogen into account resulted in higher accuracy.

Visualization of the data shape
Given the set of features, the raw data had to be preprocessed to fulfill the shape and data type requirements of the models to train. Categorical features such as the department visited, gender, and marital status were one-hot encoded to represent them as numerical values that can serve as input for machine learning analyses. This also prevents the introduction of non-existent ordering between the items [16]. To avoid potential biases from different value ranges, all numerical features were standardized by scaling them to zero mean and unit variance. In addition, many model architectures require each sequence of departments to have the same length. Therefore, each sequence shorter than a specified length was padded with null values while longer sequences were cut off. The value of the sequence length was derived from the distribution of the number of departments visited by patients during a single stay.
Due to the disparity in the number of samples between patient stays resulting in a discharge to SNF and those resulting in other discharge locations, we also decided to use balancing techniques. On the one hand, we applied over- and downsampling, which were found to be effective methods in dealing with class imbalance [9]. That means we randomly duplicated patient stays where the patient was discharged to SNF and randomly removed patient stays resulting in another discharge location until both cases were represented equally. On the other hand, we introduced class weighting to model training. Thereby, instances of the underrepresented class, i.e., discharge to SNF, are multiplied with a weighting factor in the loss function, increasing the penalty for misprediction. While both techniques improved the predictive performance of our model, especially with regard to the confusion matrix, class weighting yielded better results in our case, which is why we chose this technique for our final model.
4.3 Model Selection and Training
We chose CNNs as our model architecture and trained all models on the preprocessed data for patient discharge classification. In order to get the best model, we then applied hyperparameter tuning. We defined multiple hyperparameters such as the kernel sizes of the convolutional layers, the size of the fully connected layers and pooling layers, and the intermediate activation functions. Each of these hyperparameters was assigned a range of possible values. Multiple models were trained with the hyperparameter optimization approach tree-structured Parzen estimator [3]. The best model parameters were chosen based on the F1-score on the validation part of the dataset. Afterwards, the models were analyzed using accuracy, precision, recall, and confusion matrices.
The final model consists of two 1D-convolutional layers followed by a dropout and a max-pooling layer. The result is flattened and then serves as input for a sequence of four fully connected layers and the output layer using the sigmoid activation function.
5 Evaluation and Discussion
The evaluation starts with the results of model training and validation, followed by a discussion about the resulting model’s feature importance and limitations.
5.1 Results
The code to reproduce our results, including the result of the hyperparameter search, can be found on GitHubFootnote 4. Please note that due to data privacy restrictions for the MIMIC-IV database, you will have to get access to the database. The solution is implemented in Python, and the README of the linked repository provides instructions on how to run the experiments.
We split our preprocessed dataset into a train and a test set, with the latter accounting for 25% of the dataset (2684 patient stays). The metrics used to compare the models resulting from our hyperparameter tuning were calculated on a validation set consisting of 10% of the train set after training on the remaining part of the train set. They comprise the following: The accuracy represents the proportion of data points assigned to the correct discharge location. Precision reflects the fraction of correct predictions of discharge to SNF over all predictions of discharge to SNF. In contrast, recall shows the percentage of how many of the patient stays that resulted in discharge to SNF were predicted as such. The F1-score then is the harmonic mean of precision and recall. Another metric, the Area Under ROC Curve (AUROC) is the probability of a randomly chosen positive data point (discharged to SNF) being ranked higher by the model than a randomly chosen negative data point. Confusion matrices show for each true label on the y-axis the distribution of the correctly or incorrectly predicted labels on the x-axis. If the model predicted everything correctly, the diagonal from upper left to bottom right would contain only values of 1.0.

Confusion Matrix of the final CNN model
The final model reaches an accuracy of 77% with a weighted precision of 81% and a weighted recall of 77%, respectively. The F1-score is 0.78, and the AUROC is 0.73. As shown in the confusion matrix in Fig. 2, there is a discrepancy of about 14% between the accuracy of predicting SNF as discharge location on the one hand and the accuracy of predicting other discharge locations on the other hand.
Figure 3 shows the feature importance of our model as a beeswarm plot using SHAP values (SHapley Additive exPlanations) [15]. The graph was generated using the SHAP libraryFootnote 5. It shows the impact of the 18 most influential features. Each dot for each feature corresponds to a single patient stay. The x-axis shows how much impact those features had, with high negative values indicating a high impact on the decision to SNF as discharge location, high positive values indicating the opposite. The color of a dot represents the value of the feature, red representing a high value, blue a low value. Since our data had a three-dimensional shape, which could not be represented in this graph, we averaged the SHAP values and the feature values for each patient stay. For example, the distribution of dots for the patient age shows that a higher age often serves as a predictor for discharge to SNF.
5.2 Discussion
This contribution suggests considering the treatment process in classifying the discharge location of heart failure patients. Looking at the feature importance in Fig. 3, features changing throughout the process have a significant effect on predicting the discharge location. For example, the development of the laboratory values creatinine, hemoglobin, glucose, red blood cells, and urea nitrogen impact the prediction. Furthermore, the number of medications received and the number of laboratory values measured per department are relevant. Interestingly, a higher number of medications indicates a discharge to SNF, whereas a higher number of laboratory values indicates a discharge to other locations.
The departments visited and the admission locations also affected the outcome, as the admission from SNF resulted in a higher probability of being discharged to SNF. Being referred by a physician to the hospital impacts the discharge decision to home/home health care. A visit to the Medicine/Cardiology department has only a slight influence on the prediction. The transfer duration, representing the length of stay in each department, helps to predict the discharge location.

Beeswarm plot for the final CNN model
Additionally, we were able to confirm relevant factors as proposed in current literature, which includes age, insurance, length of stay, gender, and laboratory values (creatinine, urea nitrogen, and hemoglobin). Information about the availability of an informal caregiver is provided in the form of the marital status in the MIMIC database, which constitutes a relevant factor [2]. However, marital status is only an indicator and does not represent the guaranteed availability.
With our process oriented approach, we emphasize to incorporate the development of the patient’s state throughout the treatment process in the decision-making. As we identified process characteristics in the different cohorts, a more precise discharge classification can be achieved by incorporating the treatment process. It should be noted that we identified patient characteristics regarding discharge classification based on decisions made by healthcare professionals in the past. Thus, we only reproduce the decision-making of healthcare professionals. Nevertheless, the identified characteristics can be further investigated to improve the decision-making, for example, why patients with increased creatinine get discharged to home/home health care and not to SNF.
Looking at the results in Fig. 2, our model is better in predicting discharge to other locations (80%) than to SNF (66%), resulting in an overall accuracy of 77%. We assume that better predictive performance could have been achieved with a larger sample size, as a sufficiently large sample size can significantly impact the predictive performance of machine learning models [22]. We performed training on other models, such as LSTM and XGBoost, while CNNs turned out to provide the best results. Comparing our results to recent research is difficult, as the discharge locations are different among the datasets. To our knowledge, there is no respective model using the MIMIC dataset yet. However, we could confirm the already identified patient characteristics as described above.
Furthermore, a more detailed view of the process could improve the results of our model, as we did not incorporate a comprehensive view of the patient’s diagnoses, medications, laboratory values, and the procedures performed on them. Additionally, the mental status and further sociodemographic information could help to improve the model’s performance.
6 Conclusion and Future Work
This paper discusses the approach of predicting the discharge location for heart failure patients by incorporating the treatment process.
We have shown that the development of the patient’s state during the process and the respective visits in the hospital departments have a considerable impact on the discharge location prediction. Therefore, taking into account the treatment process instead of merely looking at the patient’s state at the point of discharge can serve as a decision support for healthcare professionals.
An accuracy of 77% could be achieved in this contribution, which is a promising result, but still leaves room for improvement. Therefore, future work could be conducted by combining the MIMIC-IV dataset with other datasets such as the HiRIDFootnote 6 database to increase the sample size and improve the prediction results. Furthermore, a more comprehensive representation of the treatment process might help to increase the accuracy by adding detailed information on medications received or procedures performed. Besides, it would be worthwhile to consult domain experts who could point towards additional features not yet considered.
Notes
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
References
Albawi, S., Mohammed, T.A., Al-Zawi, S.: Understanding of a convolutional neural network. In: 2017 International Conference on Engineering and Technology (ICET), pp. 1–6 (2017). https://doi.org/10.1109/ICEngTechnol.2017.8308186
Allen, L.A., et al.: Discharge to a skilled nursing facility and subsequent clinical outcomes among older patients hospitalized for heart failure. Circ. Heart Fail. 4(3), 293–300 (2011)
Bergstra, J., Bardenet, R., Bengio, Y., Kégl, B.: Algorithms for hyper-parameter optimization. In: Proceedings of the 24th International Conference on Neural Information Processing Systems, NIPS 2011, pp. 2546–2554 (2011)
Desai, A.S., Stevenson, L.W.: Rehospitalization for heart failure: predict or prevent? Circulation 126(4), 501–506 (2012)
Goldberger, A., et al.: PhysioBank, PhysioToolkit, and PhysioNet: components of a new research resource for complex physiologic signals. Circulation 101(23), e215–e220 (2000)
Gramaje, A., Thabtah, F., Abdelhamid, N., Ray, S.: Patient discharge classification using machine learning techniques, June 2019
Howie-Esquivel, J., Spicer, J.G.: Association of partner status and disposition with rehospitalization in heart failure patients. Am. J. Crit. Care 21(3), e65–e73 (2012)
Huang, Z., Dong, W., Ji, L., Duan, H.: Outcome prediction in clinical treatment processes. J. Med. Syst. 40(1), 1–13 (2016)
Japkowicz, N., et al.: Learning from imbalanced data sets: a comparison of various strategies. In: AAAI Workshop on Learning from Imbalanced Data Sets, vol. 68, pp. 10–15. AAAI Press, Menlo Park (2000)
Jessup, M., et al.: 2009 focused update: ACCF/AHA guidelines for the diagnosis and management of heart failure in adults: a report of the American College of Cardiology Foundation/American Heart Association Task Force on Practice Guidelines: developed in collaboration with the International Society for Heart and Lung Transplantation. Circulation 119(14), 1977–2016 (2009)
Johnson, A., Bulgarelli, L., Pollard, T., Horng, S., Celi, L.A., Mark, R.: MIMIC IV (version 0.4). PhysioNet (2020)
Kobewka, D.M., et al.: Predicting the need for supportive services after discharged from hospital: a systematic review. BMC Health Serv. Res. 20(1), 1–10 (2020)
Le, M., Gabrys, B., Nauck, D.: A hybrid model for business process event and outcome prediction. Expert. Syst. 34(5), e12079 (2017)
Leontjeva, A., Kuzovkin, I.: Combining static and dynamic features for multivariate sequence classification, pp. 21–30, October 2016
Lundberg, S.M., Lee, S.I.: A unified approach to interpreting model predictions. In: Guyon, I., et al. (eds.) Advances in Neural Information Processing Systems, vol. 30, pp. 4765–4774. Curran Associates, Inc. (2017)
Potdar, K., Pardawala, T., Pai, C.: A comparative study of categorical variable encoding techniques for neural network classifiers. Int. J. Comput. Appl. 175, 7–9 (2017). https://doi.org/10.5120/ijca2017915495
Roger, V.L.: Epidemiology of heart failure. Circ. Res. 113(6), 646–659 (2013)
Ross, J.S., et al.: Statistical models and patient predictors of readmission for heart failure: a systematic review. Arch. Intern. Med. 168(13), 1371–1386 (2008)
Teinemaa, I., Dumas, M., Rosa, M.L., Maggi, F.M.: Outcome-oriented predictive process monitoring: review and benchmark. ACM Tran. Knowl. Discov. Data (TKDD) 13(2), 1–57 (2019)
Weinzierl, S., et al.: An empirical comparison of deep-neural-network architectures for next activity prediction using context-enriched process event logs (2020)
Weske, M.: Business Process Management: Concepts, Languages, Architectures, 3rd edn. Springer, Heidelberg (2019). https://doi.org/10.1007/978-3-642-28616-2
Weytjens, H., De Weerdt, J.: Process outcome prediction: CNN vs. LSTM (with Attention). In: Del Río Ortega, A., Leopold, H., Santoro, F.M. (eds.) BPM 2020. LNBIP, vol. 397, pp. 321–333. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-66498-5_24
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this paper

Cite this paper
Cremerius, J., König, M., Warmuth, C., Weske, M. (2022). Patient Discharge Classification Based on the Hospital Treatment Process. In: Munoz-Gama, J., Lu, X. (eds) Process Mining Workshops. ICPM 2021. Lecture Notes in Business Information Processing, vol 433. Springer, Cham. https://doi.org/10.1007/978-3-030-98581-3_23
Download citation
DOI: https://doi.org/10.1007/978-3-030-98581-3_23
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-98580-6
Online ISBN: 978-3-030-98581-3
eBook Packages: Computer ScienceComputer Science (R0)