
Abstract
In the previous chapter, it has been shown that the regularization approach is particularly useful when information contained in the data is not sufficient to obtain a precise estimate of the unknown parameter vector and standard methods, such as least squares, yield poor solutions. The fact itself that an estimate is regarded as poor suggests the existence of some form of prior knowledge on the degree of acceptability of candidate solutions. It is this knowledge that guides the choice of the regularization penalty that is added as a corrective term to the usual sum of squared residuals. In the previous chapters, this design process has been described in a deterministic setting where only the measurement noises are random. In this chapter, we will see that an alternative formalization of prior information is obtained if a subjective/Bayesian estimation paradigm is adopted. The major difference is that the parameters, rather than being regarded as deterministic, are now treated as a random vector. This stochastic setting permits the definition of new powerful tools for both priors selection, e.g., through the maximum entropy principle, and for regularization parameters tuning, e.g., through the empirical Bayes approach and its connection with the concept of equivalent degrees of freedom.
You have full access to this open access chapter, Download chapter PDF
4.1 Preliminaries
We have seen that the regularization approach can be used to effectively solve estimation problems that are otherwise ill-conditioned. In particular, a penalty is added as a corrective term to the usual sum of squared residuals. In this way, between two candidate solutions achieving the same squared loss, the regularizer is chosen such as to penalize candidate solutions that depart from our prior knowledge on some features of the unknown parameter vector.
It is worth noting that the regularization approach lies within a frequentist paradigm in which the observed data, affected by noise, are random variables, but the unknown parameter vector is deterministic in nature. For linear-in-parameter models, regularization yields an estimate that, though biased, may be preferable to the unbiased least squares estimate in view of the smaller variance. In particular, the tuning of the regularization parameter aims at an advantageous solution of the bias-variance dilemma. By trading an excessive variance for some bias, a smaller mean squared error may be achieved, as exemplified by the James–Stein estimator. An alternative formalization of prior information is obtained if a subjective/Bayesian estimation paradigm is adopted. The major difference is that the parameters, rather than being regarded as deterministic, are now treated as a random vector.
In order to introduce the Bayesian paradigm, it can be useful to start with a simple example in which the parameters do depend on the result of a random experiment. Consider a metabolism model for which the parameter vector \(\theta \) can take only two possible values, \(\theta _h\) and \(\theta _d\), associated with healthy and diabetic patients, respectively. The model specifies \(\mathrm p(Y|\theta )\), where Y are observations collected from a randomly chosen patient with 90% probability of being healthy and 10% probability of being diabetic. In this simple case, model identification amounts to deciding between \(\theta _h\) and \(\theta _d\). It is also clear that \(\theta \) is a discrete random variable with \(\mathrm p(\theta =\theta _h)=0.9\) and \(\mathrm p(\theta =\theta _d)=0.1\). These probabilities summarize the prior information about the unknown parameter, before any observation is collected. Once the data Y become available, the Bayes formula can be used to compute the posterior probability
Of course, \(\mathrm p(\theta _d|Y) = 1 - \mathrm p(\theta _h|Y)\). In particular, if the data Y are consistent with diabetes symptoms, it may well happen that \(\mathrm p(\theta _d|Y)>0.5\), in which case \(\theta =\theta _d\) would be taken as the final estimate.
In the previous example, the prior probability distribution assigned to \(\theta \) reflects a real experiment that is the random choice of a patient from a population where 90% of subjects are healthy, which implies a prejudice in favour of \(\theta =\theta _h\). In other words, the prior distribution ranks the candidate parameters according to the available a priori knowledge. If we look at the numerator of (4.1), we see that it combines a priori information with the data through the product of the prior probability \(\mathrm p(\theta _h)\) and the likelihood \(\mathrm p(Y|\theta _h)\). In the example, the population was a binary one (either healthy or diabetic), but we can imagine more complex populations allowing for several countable or even uncountable possible values of \(\theta \).
In the actual Bayesian paradigm a further step is made: the parameters \(\theta \) are assigned a prior probability \(\mathrm p(\theta _h)\), even if there does not exist an underlying experiment that draws the model from a population of possible models. According to the subjective definition of probability, \(\mathrm p(\theta =\bar{\theta })\) represents the (subjective) degree of belief that \(\theta \) is going to take the value \(\bar{\theta }\). In particular, in analogy with the regularization penalty, it is possible to rank the possible values of \(\theta \), assigning a low probability to values whose occurrence is deemed unlikely. In our context, the intrinsically subjective nature of the prior probability, a controversial issue in the confrontation between the frequentist and Bayesian paradigms, is specular to the subjective choice of the regularization penalty: rather than expressing the preference for some solutions through the choice of a proper penalty, the preference is formulated by means a prior distribution.
As shown in the following, many formulas and results can be indifferently derived adopting either the regularization or the Bayesian paradigm. However, the Bayesian approach has its pros. In particular, the tuning of the regularization parameter, rather than being addressed on an ad hoc basis, can be formulated as a statistical estimation problem. Moreover, the Bayesian paradigm offers a very natural way to asses uncertainty intervals, whereas the regularization paradigm has a harder time assessing the amount of bias in the estimate. Among the cons, one may mention the need for a deeper probabilistic background in order to gain a full comprehension of all aspects.
Throughout the chapter we will mainly focus on the linear Gaussian case, but the approach is more general and some hints at generalizations will be provided. In addition, we will use \(\theta \) to denote the stochastic vector that has generated the data, in contrast with the deterministic \(\theta _0\) used in the classical setting discussed in the previous chapter.
4.2 Incorporating Prior Knowledge via Bayesian Estimation
We consider the problem of estimating a parameter vector \(\theta \in \mathbb {R}^n\), based on the observation vector \(Y \in \mathbb {R}^N\). The two ingredients of Bayesian estimation are the prior distribution of \(\theta \), also known by short as prior, and the conditional distribution of Y given \(\theta \). As already observed, the basic assumption is that the parameter vector \(\theta \) is not completely unknown, but rather some prior knowledge is available that is formulated in terms of subjective probability, specified as a probability density function:
The density function \(\mathrm {p}(\theta )\) is chosen by the user so as to assign a low probability to values whose occurrence is deemed unlikely. For instance, if \(\theta \) is a scalar parameter whose value is believed to lie more or less around 30, hardly smaller than 20 and hardly larger than 40, this prior knowledge can be embedded in a Gaussian density with \(\mathscr {E} \theta =\mu _{\theta }=30\) and standard deviation \(\sigma _{\theta } =5\):
In fact, under this distribution, \(\mathrm {p} \left( |\theta -\mu _{\theta }|> 2 \sigma _{\theta } \right) = \mathrm {p} \left( |\theta -30| > 10 \right) < 0.05\). Although not impossible, it is considered unlikely that values of \(\theta \) too distant from 30 are going to occur. A natural question is how and when our prior knowledge is sufficient to specify a distribution. This crucial issue calls for the notion and role of hyperparameters, see Sect. 4.2.4, and for the possible use of the maximum entropy principle as a way to obtain an entire probability distribution from partial knowledge relative to its moments, see Sect. 4.6.
The second ingredient is the conditional distribution of Y given \(\theta \) that, when considered as a function of \(\theta \), is also known as likelihood:
where \(\mathrm {p}(Y,\theta )\) is the joint probability distribution of the random vectors Y and \(\theta \). The likelihood is usually obtained from some mathematical model of the data. Consider, for instance, the simple model
where \(e_i \sim \mathscr {N} (0, \sigma ^2)\) are independent and identically distributed measurement errors, with known variance \(\sigma ^2\). Conditional on \(\theta \), i.e., assuming that \(\theta \) is known, \(Y_i\) is Gaussian with
so that, in view of independence, the likelihood is
When both the prior distribution \(\mathrm {p}(\theta )\) and the likelihood \(\mathrm {p}(Y |\theta )\) have been specified, the Bayes formula yields the posterior distribution
We have seen that all our prior knowledge was embedded in the prior. In a similar way, all the knowledge obtained by the combination of prior information with the new information brought by the observations is now embedded in the posterior distribution \(\mathrm {p}(\theta | Y)\), denoted by short as posterior.
Although all the relevant information is encapsulated within the posterior, a point estimate is often required for practical or communication purposes. The Maximum A Posteriori (MAP) estimate is the value that maximizes the posterior:
Its interpretation is simple, as it represents the most likely value, once the prior knowledge has been updated taking into account the observations. Alternatively, the mean squared error
can be used as a criterion to select the point estimate \(\hat{\theta }\). Above, \(\mathscr {E} (\cdot |Y)\) denotes the expected value taken with respect to the posterior distribution \(\mathrm {p}(\theta | Y)\). The following classical result from estimation theory (whose proof is in Sect. 4.13.1) then holds.
Theorem 4.1
The minimizer of the MSE
is known as Bayes estimate and can be shown to be equal to the conditional mean:
A third point estimate is the conditional median used especially in view of its statistical robustness when the posterior is obtained numerically via stochastic simulation algorithms, see Sect. 4.10.
When, in addition to a point estimate, an assessment of the uncertainty is needed, it can be derived from the posterior through the computation of a properly defined credible region \(C_{\gamma } \in \mathbb {R}^n\) such that
For example, \(C_{\gamma }\) could be taken as the smallest region such that (4.3) holds, a choice that goes under the name of highest posterior density region.
4.2.1 Multivariate Gaussian Variables
In this subsection, some basic properties and definitions of multivariate Gaussian variables are recalled. This review is instrumental to the derivation of the Bayesian estimator when observations and parameters are jointly Gaussian, see Sect. 4.2.2. In turn, this will pave the way to the analysis of the linear model under additive Gaussian measurement errors, see Sect. 4.2.3.
A random vector \(Z = [Z_1 \ldots Z_m]^T\) is said to be distributed according to a nondegenerate m-variate Gaussian distribution if its joint probability density function is of the type
where V is a symmetric positive definite matrix and \(\mu \) is some vector in \(\mathbb {R}^m\).
It can be shown that
Then, the notation
(already used before in the scalar case) indicates that Z is a multivariate Gaussian (Normal) random vector with mean \(\mu \) and variance matrix V.
Property 4.1
If \(Z \sim \mathscr {N}(\mu ,V)\) and \(Y = AZ\), where \(A \in \mathbb R^{n \times m}, n \le m\), is a full-rank deterministic matrix, then
In particular, it follows that the marginal distributions of the entries of Z are Gaussian:
Property 4.2
Assuming \(Z \sim \mathscr {N}(\mu ,V)\), let \(X=[Z_1 \ldots Z_n]^T\), \(Y=[Z_{n+1} \ldots Z_m]^T\), where \(1 \le n <m\), and partition \(\mu \) and V accordingly:
Then, \(\mathrm p(X|Y=y)\) is a multivariate Gaussian density function with
and we can write
where \(X|Y=y\) stands for the random vector X conditional on \(Y=y\).
4.2.2 The Gaussian Case
Let us consider the case in which the observation vector \(Y \in \mathbb {R}^N\) and the unknown vector \(\theta \in \mathbb {R}^n\) are jointly Gaussian:
The key idea behind Bayesian estimation is referring to the posterior distribution of \(\theta \) given Y as representative of the state of knowledge about the unknown vector. It follows from Property 4.2 that such posterior is Gaussian as well:
In view of Gaussianity, \(\theta ^{\mathrm {MAP}}\) coincides with the conditional expectation \({\mathscr {E}}(\theta |Y)\):
The reliability of the estimate can be assessed by the posterior variance
based on which the so-called credible intervals can be derived as explained below.
The posterior variance of \(\theta _i\) is the i-th diagonal entry of the posterior covariance matrix:
Observing that \(\theta _i |Y \sim \mathscr {N}(\theta ^{\mathrm B}_i, \sigma ^2_{\theta _i |Y})\), it follows that
so that \([\theta ^{\mathrm B}_i - 1.96 \sigma _{\theta _i |Y}, \theta ^{\mathrm B}_i + 1.96 \sigma _{\theta _i |Y}]\) is the \(95\%\)-credible interval for the parameter \(\theta _i\), given the observation vector Y. If two or more parameters are jointly considered, the notion of credible region can be obtained in a similar way. In the Gaussian case, such regions are suitable (hyper)-ellipsoids centred in \(\theta ^{\mathrm B}\).
4.2.3 The Linear Gaussian Model
The Bayesian approach can be applied to the estimation of the standard linear model in matrix form
in which \(Y \in {\mathbb R}^N\) and the parameter vector \(\theta \) is no more regarded as a deterministic quantity, but as a random vector independent of E. In particular, we assume that some prior information is available which is embedded in a Gaussian prior distribution
Since Y is the linear combination of the jointly Gaussian vectors \(\theta \) and E, the vectors Y and \(\theta \) are jointly Gaussian as well. Hereafter, positive definiteness of \(\varSigma _{\theta }\) is assumed if not stated otherwise. The singular case, see Remark 4.1, amounts to assuming perfect knowledge of some linear combination of the unknown parameters or, equivalently, to constrain the estimated vector \(\theta \) to belong to a prescribed subspace. The ability to incorporate this type of constraint is not unique to the Bayesian approach. In the context of the deterministic regularization, an example is given by the optimal regularization matrix \(P=\theta _0\theta _0^T\), derived in Sect. 3.4.2.1.
In order to obtain the Bayes estimate according to (4.7), we need to compute \(\mu _Y={\mathscr {E}}(Y)\), \(\varSigma _{\theta Y} = \mathrm {Cov}(\theta ,Y)\), and \(\varSigma _{Y} = \mathrm {Var}(Y)\):
Then, we can apply (4.7) to obtain
The proofs of the following two classical results are reported in Sects. 4.13.2 and 4.13.3.
Theorem 4.2
(Orthogonality property)
The following lemma, whose proof is in Sect. 4.13.3, is useful in order to obtain an alternative expression that proves more convenient, especially when \(n \ll N\).
Lemma 4.1
It holds that
By applying the previous lemma, the alternative expression of the Bayes estimate is obtained
As already noted, the Bayes estimate coincides with \(\theta ^{\mathrm {MAP}}\), the maximum of the posterior density:
Recall that, in view of the assumed linear model (4.9),
and note that
where \(c_1\) and \(c_2\) are constants we are not concerned with. Therefore, the maximization of the posterior density can be written as
whose solution is easily shown to be given by (4.13). This shows that, under Gaussianity assumptions, the Bayes estimate of the linear model can be seen as a regularized least squares estimator with quadratic regularization term (ReLS-Q), see Sect. 3.4. In particular, if
the Bayes and MAP estimators,
coincide with the ReLS estimator with regularization matrix \(P=\varSigma _{\theta }/\sigma ^2\). Under the further assumption \(\varSigma _{\theta } = \lambda I_n\), the MAP estimator coincides with a ridge regression estimator with \(\gamma = \sigma ^2/\lambda \).
Remark 4.1
When \(\varSigma _{\theta }=P\), where \(P=P^T \ge 0\) is singular, one can still use (4.10) to obtain the Bayes estimate, while (4.13) and the quadratic problem (4.18) are no more valid due to the nonexistence of \(\varSigma _{\theta }^{-1}\). Nevertheless, by replicating the derivation in Remark 3.1, it is still possible to interpret the Bayes estimate as the solution of a constrained quadratic problem. In particular, under (4.17), we have that
where \(U_2\) was defined in Remark 3.1, as part of the singular value decomposition of P. The result can be interpreted as follows. A singular variance matrix means that we have perfect knowledge on some linear combination of the parameter vector. In particular,
where, with reference to the SVD of P, we have exploited the fact that \(U_2^TU_1=0\). As a consequence,
thus justifying the presence of the equality constraints in the quadratic problem (4.19)–(4.20), where \(\mu _{\theta }=0\) is assumed. Recalling the orthogonality of \(U_1\) and \(U_2\), we have that \(U_2^T\theta =0\) implies that \(\theta \in \mathrm {Range}(U_1) = \mathrm {Range}(P)\). Therefore, the constrained quadratic problem (4.19)–(4.20) can also be equivalently reformulated as
One can also assess that the solution of this problem can be written as
an expression which does not require invertibility of any matrix.
In conclusion, the Bayes estimate always exists and is unique. In any case, it can be written as (4.7) with \(\varSigma _{Y} ^{-1}\) replaced by its pseudoinverse.
The Bayesian interpretation of deterministic regularization can be exploited to obtain a guideline for the selection of the regularization matrix. The simplest case is when some statistics, e.g., based on samples coming from past problems, is available for the parameter vector \(\theta \). Then, the Bayesian interpretation suggests to select the covariance matrix of \(\theta \), divided by the error variance \(\sigma ^2\), as regularization matrix. If examples from the past are not available, one may rely on prior knowledge, telling that some entries of \(\theta \) have smaller variance than others or that some correlation exists between the entries.
4.2.4 Hierarchical Bayes: Hyperparameters
In the cases in which prior information on the parameters is not sufficient to specify a prior, it is common to resort to hierarchical Bayesian models. Instead of fixing the prior, a family of priors is considered, parametrized by one or more hyperparameters. As an example, consider the case in which prior knowledge could be formalized in terms of zero-mean independent and equally distributed parameters whose absolute value is not too large. In absence of more precise information on their size, we could adopt the following prior:
where the scalar \(\lambda \), called hyperparameter, enters the game as a further unknown quantity. More in general, the prior distribution \(\mathrm {p}(\theta |\alpha )\) may depend on a hyperparameter vector \(\alpha \). One may also want to consider a hyperparameter vector \(\beta \) entering the definition of the likelihood \( \mathrm {p}(Y|\theta , \beta ). \) The most common example is when the measurement variance \(\sigma ^2\) is not known and is therefore treated as a hyperparameter. In the following, the vector of all hyperparameters will be denoted by
For a given \(\eta \), we will denote by \(\theta ^{\mathrm {MAP}}(\eta )\) and \(\theta ^{\mathrm {B}}(\eta )\) the corresponding MAP and Bayes estimates:
where
4.3 Bayesian Interpretation of the James–Stein Estimator
In this section, we show that the James–Stein estimator can be seen as a particular Bayesian estimator. As seen, in Eq. (1.2), the measurements model is
In a Bayesian setting, the parameter vector is regarded as a random vector, whose distribution reflects our state of knowledge. In particular, we assume
where \(\lambda \) plays the role of hyperparameter. It follows that \(\theta \) and Y are zero-mean jointly Gaussian variables with
According to (4.7), the Bayes estimate is given by the conditional expectation
where
It is apparent that the estimator (4.28) has the same structure as James–Stein’s one, with r replaced by \(r_{\mathrm {Bayes}}\).
Since Y and \(\theta \) are jointly Gaussian, \({\mathscr {E}}(\theta | Y) = \theta ^\mathrm {MAP}\), where
which highlights the fact that \({\mathscr {E}}(\theta | Y)\) is the solution of a regularized least squares problem, controlled by the regularization parameter \( {\sigma ^2}/{\lambda }\).
If the variances \(\lambda \) and \(\sigma ^2\) could be assigned on the basis of prior knowledge, the similarity would be only formal. Let us make a step forward, considering the case in which the variance \(\sigma ^2\) is given, while \(\lambda \) is estimated from the data. The basic idea is that the hyperparameter \(\lambda \) could be tuned based on the observed vector Y and plugged into (4.29) to obtain an estimate of \(r_{\mathrm {Bayes}}\). Alternatively, one may focus directly on finding a sensible estimate of \(r_{\mathrm {Bayes}}\). In this respect, we are going to show that Stein’s r is an unbiased estimate of \(r_{Bayes}\) under the Gaussian model (4.25) and (4.26) [6]. For this purpose, we will exploit a property of the inverse chi-square variable.
Definition 4.1
(chi-square random variable) The sum of the squares of n standard Gaussian independent random variables is a nonnegative valued random variable known as chi-square variable with n degrees of freedom:
Its mean and expectation are
The inverse of a chi-square variable is called inverse chi-square. For \(n>2\), its mean is
Now, assume \(N>2\) and observe that
Recalling that the expectation of the inverse chi-square is equal to \(1/(N-2)\), we have that
Therefore,
This means that James–Stein’s shrinking coefficient r can be seen as an unbiased estimator of the shrinking coefficient \(r_{Bayes}\) appearing in the formula of the posterior expectation.
The example is instructive under several respects. First, it shows that, under suitable probabilistic assumptions, the typical structure of regularized estimators can be justified through Bayesian arguments. The second point has to do with the tuning of the regularization parameters. In the empirical Bayes approach, see Sect. 4.4, there is a preliminary step in which a point estimate of hyperparameters is obtained by standard estimation methods. Then, this point estimate is plugged into the expression of the Bayesian estimator. Although a full Bayesian approach would call for the joint estimation of parameters and hyperparameters, the two-step empirical Bayes approach not only conjugates simplicity and effectiveness but provides a probabilistic underpinning to regularized identification methods.
4.4 Full and Empirical Bayes Approaches
When the prior, and possibly the likelihood, include hyperparameters, Bayesian estimation becomes more complex and gives rise to alternative approaches. In principle, we want to obtain the posterior distribution
However, if a hierarchical Bayesian model is adopted, we do not know \(\mathrm {p}(\theta )\), but only \(\mathrm {p}(\theta | \eta )\). At the cost of assigning a prior \(\mathrm {p}(\eta )\) also to the hyperparameters, the prior \(\mathrm {p}(\theta )\) can be obtained by marginalization of the joint probability density:
In general, this integral has to be computed numerically, e.g., by Monte Carlo methods. This leads to full Bayesian methods that compute the desired \(\mathrm {p}(\theta | Y)\) regarding both parameters and hyperparameters as random variables. Some remarks on these methods will be given in Sect. 4.10.
The justification for a simpler computational scheme stems from the following reformulation of the posterior:
Observe that
where \(L(\eta |Y)= \mathrm {p}(Y| \eta ) \) is the likelihood of the hyperparameter vector \(\eta \). It is also called marginal likelihood because it is obtained from the marginalization with respect to \(\theta \) of the joint density \(\mathrm {p}(Y,\theta | \eta )\):
If data are sufficiently informative, the marginal likelihood has good chances to be unimodal and sharply peaked in a neighbourhood of the maximum likelihood estimate
When this happens and \(\mathrm {p}(\eta )\) is rather uninformative (as it should be), from (4.32) it follows that \(\mathrm {p}(\eta |Y)\) is peaked as well. Then, as long as the properties of \(\mathrm {p}(\theta | \eta , Y)\) do not change rapidly with \(\eta \) near \(\eta ^{\mathrm {ML}}\), the integral (4.31) can be approximated as
In practice, this suggests to compute the posterior using the prior \(\mathrm {p}^*(\theta )=\mathrm {p}(\theta | \eta ^{\mathrm {ML}})\) associated with the maximum likelihood estimate of hyperparameters. More in general, Empirical Bayes (EB) methods adopt a two-stage scheme. In the first step, a point estimate \(\eta ^*\) is computed which is then kept fixed in the second step, when the posterior of the parameters is obtained, based on the prior \(\mathrm {p}^*(\theta )=\mathrm {p}(\theta | \eta ^*)\).
Among the advantages of the approach one may mention its simplicity, especially when there are few hyperparameters and the posterior \(\mathrm {p}(\theta | Y, \eta ^{\mathrm {ML}})\) is easily obtained as in the jointly Gaussian case. Moreover, the tuning of \(\eta \) admits an intuitive interpretation as the counterpart of model order selection in classic parametric estimation methods. The main drawback is that the EB method fails to propagate the uncertainty of the point estimate \(\eta ^*\).
Under the linear Gaussian model (4.9), the integral (4.33) admits a closed-form solution. In fact, since
we have
where in the right-hand side dependence on \(\eta \) has been omitted for simplicity.
Therefore, application of Empirical Bayes estimation to the linear model (4.9) would consist of the following two steps:
Step 1:
Step 2: Let \(\mu _{\theta }=\mu _{\theta }(\eta ^*)\), \(\varSigma _E=\varSigma (\eta ^*)\), \(\varSigma _{\theta } = \varSigma _{\theta }(\eta ^*)\) and compute the posterior expectation according to Sect. 4.2.3.
When the likelihood and the prior are such that integral (4.33) cannot be computed explicitly, an approximation is needed. In particular, one can resort to the Laplace approximation, which is based on a second-order Taylor expansion of \(\log \ \mathrm {p}(Y,\theta | \eta )\) around \(\theta ^{\mathrm {MAP}}(\eta )\) defined in (4.22), from which an integrable approximation of \(\mathrm {p}(Y,\theta | \eta )\) appearing in (4.33) is obtained. Note, however, that the Laplace approximation has to be recalculated for each evaluation of \(L(\eta |Y)\) occurring during the iterative computation of \(\eta ^{\mathrm {ML}}\).
4.5 Improper Priors and the Bias Space
The use of priors is most useful whenever the data alone are not sufficient to provide reliable parameter estimates but there exists some a priori knowledge that can be exploited. It may happen that for some parameters the introduction of a prior is not possible or not desirable, because their estimation can be satisfactorily performed anyway, given the information in the data. This can be accounted for by assuming that such parameters have improper priors.
In order to deal with the case where p parameters \(\theta ^P \in {\mathbb R}^p\) have a proper prior and the remaining \(n-p\) parameters \(\theta ^I \in {\mathbb R}^{n-p}\) have an improper prior, consider the following model:
The (asymptotically) improper prior for \(\theta ^I\) is obtained by letting \(a \rightarrow \infty \) so that \(\theta ^I\) has infinite variance, i.e., its density is flat. This amounts to complete lack of prior knowledge for the last \(n-p\) entries of the parameter vector \(\theta \) that, for simplicity, is assumed to be zero mean. The use of improper priors in a Bayesian setting has the same effect as the introduction of a bias space in a deterministic regularization setting. Within such a subspace, parameters are immune from regularization, a feature that could be useful to apply regularization only where needed without causing undesired distortions. The following theorem, whose proof is in Sect. 4.13.4, is analogous to a result obtained in [22] to obtain a Bayesian interpretation of smoothing splines. It illustrates the asymptotic behaviour of posterior means and variances as a goes to infinity.
Theorem 4.3
(adapted from [22]) If \(\mathrm {rank}(\varPhi )=n\) and \(\mathrm {rank}(\varOmega )=n-p\), then
An interesting benefit of improper priors is the possibility of reducing the number of hyperparameters by treating some of them as unknowns whose prior is improper. Letting the symbol \(\mathbf {1}_{n \times 1}\) denotes a column vector of ones, assume, for example, that \(\theta \sim \mathscr {N}(\mu \mathbf {1}_{n \times 1}, \varSigma _{\theta } )\), i.e., all the scalar entries of \(\theta \) share the same prior mean \(\mu \). In most cases, very little is known about \(\mu \) that could be therefore regarded as a hyperparameter to be tuned by marginal likelihood maximization. It can be then treated as a deterministically known variable, according to the Empirical Bayes approach, see Sect. 4.4. By this choice, however, the hyperparameter is fixed to its point estimate and its uncertainty is not propagated, implying that the uncertainty of \(\theta ^{\mathrm B}\) will be underestimated if assessed by (4.14).
Alternatively, \(\mu \) can be treated as a further random parameter. For this purpose, define \(\tilde{\theta }= \theta - \mu \) and consider the model
This formulation decreases the number of hyperparameters, without introducing prejudices (provided we let \(a \rightarrow \infty \)). More importantly, it is now possible to assess the joint uncertainty of the estimates of \(\mu \) and \(\tilde{\theta }\) through the posterior variance \(\mathrm {Var}(\bar{\theta }|Y)\).
4.6 Maximum Entropy Priors
A major appeal of the Bayesian paradigm lies in its ability to provide a rational foundation to regularization: one starts from prior knowledge and then proceeds with its formalization in terms of a probabilistic prior, from which the regularization penalty is finally derived. However, there is a stumbling block in the way, because the available prior knowledge is often too vague to avoid arbitrariness in the choice of the prior distribution. As a matter of fact, the derivation of systematic approaches for the selection of prior distributions is a classic topic of Bayesian estimation theory. In this section, the approach based on entropy maximization is briefly reviewed.
The starting point is the observation that, even when prior information is absent or very limited, there are candidate distributions that are obviously preferable, due to symmetry arguments. Assume, for instance, that candidate values for a scalar parameter \(\theta \) are known to belong to a finite set \(\{\theta _i, i=1, \ldots m \}\) and no further information is available. Then, the only reasonable prior distribution will be \(\mathrm {p}(\theta = \theta _i)=1/m\). In fact, assigning unequal probabilities would create an unjustified asymmetry, given that our prior information does not make any distinction between the m possible values of the parameter.
The case of a continuous-valued parameter \(\theta \) taking values in a finite interval [a, b] can be addressed in a similar way. In this case, a reasonable prior distribution is the uniform one:
In both examples, we might say the chosen distributions are those that reflect the maximum ignorance about the unknown parameter.
The next step is to formalize this notion of maximum ignorance in contexts where some partial information about \(\theta \) is available. This can be done by means of the notion of entropy of a probability distribution. For a discrete distribution \(\mathrm p(\cdot )\) taking values \(\mathrm p(\theta _i)\) on a numerable set \(\{\theta _i\}\), the entropy H is defined as
Note that the minimum possible entropy \(H(\mathrm {p})=0\) occurs when the probability is concentrated at a unique value \(\bar{\theta }\). This is the case of a maximally informative distribution such that \(\mathrm {p}(\theta = \bar{\theta })=1\). Conversely, if the set \(\{\theta _i\}\) has cardinality m, the maximum value \(H(\mathrm {p})=\log (m)\) is achieved in correspondence of the uniform distribution \(\mathrm {p}(\theta = \theta _i)=1/m, \forall i\). In other words, the larger the entropy, the less information is conveyed by the distribution.
For continuous-valued random variables, the notion of differential entropy \(h(\mathrm {p})\) is introduced:
where \(D_{\theta }\) denotes the support of the distribution. Note that, among distributions with finite support, the maximum possible (differential) entropy is achieved by the uniform distribution.
The principle of Maximum Entropy (MaxEnt) states that the admissible distribution with largest entropy is the one that best represents the current state of knowledge. The admissible distributions are those that satisfy a set of constraints, chosen so as to incorporate all the available prior knowledge. For instance, if the prior knowledge amounts to knowing that \(\theta \in [a,b]\), the prior suggested by the MaxEnt principle is the uniform distribution. Other types of constraints are typically expressed as expectations of functions of the parameters \(\theta \). In particular, consider a random variable \(\theta \), subject to known values \(\eta _i\) of m expectations
Then, we have the following useful result.
Theorem 4.4
(General form of maximum entropy distributions, based on [12]) Among all the distributions satisfying (4.38), the maximum entropy one is of exponential type
where \(\lambda _i\) are m constants determined from (4.38) and A is such that
Example 4.5
(MaxEnt prior from information on expected absolute value) Assume that prior knowledge is summarized by the expectation \(\mathscr {E}|\theta |=\eta \). Then, the MaxEnt prior is the solution of the constrained optimization problem
Obviously, \(m=1\) and \(g_1(\theta )=|\theta |\). In view of (4.39) and (4.40), \(\mathrm p(\theta )\) is a Laplace distribution:
The value of \(\lambda \) is found by imposing the constraint on the expectation:
Since the constraint on the expectation is satisfied for \(\lambda =1/\eta \), the following Laplace distribution is eventually obtained:
Therefore, starting from a very partial information, such as a guess on the expected absolute value of the parameter, it is possible to completely specify a prior distribution that: (i) is coherent with the prior knowledge and (ii) does not introduces undue assumptions because it is the least informative one, so far as entropy is taken as a measure of informativeness. One could object that it is scarcely realistic to assume prior knowledge of the expected absolute value of \(\theta \). However, if we adopt the empirical Bayes framework, the objection is circumvented by the possibility of treating \(\eta \) as a hyperparameter that will be estimated from data.
Therefore, prior knowledge may just tell that the expectation of \(|\theta |\) is finite, without specifying a value for this expectation. The MaxEnt principle then suggests the functional form of the prior that incorporates a hyperparameter \(\eta \), whose tuning, e.g., by marginal likelihood maximization, see Sect. 4.4, will be the first step of the actual estimation algorithm. As it will be seen in the following, this particular prior is associated with the Bayesian interpretation of the regularization penalty employed by the so-called Lasso estimator that has been already introduced in a deterministic regularization setting in Sect. 3.6.1.1. \(\square \)
For our purposes, of particular interest are MaxEnt priors satisfying constraints on the second-order moments. In the scalar case, we have the following classical result, e.g., see [19].
Proposition 4.1
(based on [12]) Let \(\theta \) be a zero-mean random variable with known variance \(\mathscr {E} \theta ^2 = \lambda \). Then, the MaxEnt distribution is normal:
Also in this case, the necessity of specifying \(\lambda \) is not an issue, because the unknown variance can be regarded as a hyperparameter and tuned by marginal likelihood maximization. In other words, if the only prior knowledge is that \(\theta \) has a finite, yet unknown, variance, the MaxEnt principle suggests the use of a normal prior parametrized by its variance.
When \(\theta \) is a vector, a multivariate prior might be derived according to the following proposition.
Proposition 4.2
(based on [12]) Let \(\theta \) be a zero-mean n-dimensional random vector whose entries have known variances \(\mathscr {E} \theta ^2_i = \lambda _i, i=1, \ldots , n\). Then, the MaxEnt distribution is a multivariate normal with diagonal covariance matrix:
The importance of this result is twofold. First, also in the multivariate case, the least informative distribution under second moment constraints is of normal type. Moreover, if the covariances are unknown, it is seen that the MaxEnt principle yields independent distributions.
A shortcoming of the maximum entropy approach is that the resulting distributions are not invariant with respect to reparametrizations of the unknown vector. To make an example, we have already seen that the maximum entropy distribution of \(\theta \) in a finite interval [1, 2] is uniform. On the other hand, if the reparametrization \(\psi =1/\theta \) is adopted and the MaxEnt approach is applied to \(\psi \), the resulting prior will be a uniform distribution for \(\psi \) in [0.5,1], which corresponds to
which is obviously different from a uniform distribution. A possible way to limit arbitrariness is to specify that, before applying the MaxEnt principle, one should first identify the “object of interest”. Indeed, choosing either \(\theta \) or \(1/\theta \) as object of interest is going to yield different MaxEnt priors.
4.7 Model Approximation via Optimal Projection \(\star \)
Approximate low-order models are commonly used even when there is awareness that the real data are generated by a more complex model. Motivations may range from their use for control design purposes to better interpretability of the phenomena under investigation. Unfortunately, under model misspecification, several nice properties enjoyed by standard estimators are no more valid. In particular, a naive application of the least squares may provide far less than satisfactory results. In this section, it is shown that, within the Bayesian framework, the search for an optimal approximate model can be given a rigorous formulation that admits a projection-based solution.
We assume that the data Y are distributed according to (4.9), which summarizes our state of knowledge. However, rather than resorting to Bayesian estimation of the vector \(\theta \), an approximate model, typically of low order, is searched for. For instance, if \(\theta _i\) were the samples of an impulse response, one might be interested in approximating them by a parametric model:
where \(\zeta =\left[ \begin{array}{ccc}\zeta _1&\cdots&\zeta _q\end{array}\right] ^T\) is the unknown parameter vector. For example, in order to approximate the sequence \(\theta _i\) by means of a single exponential function, it suffices to let \(q=2\) and
where \(\zeta _1\) is the amplitude and \(\zeta _2\) is the rate coefficient of the exponential.
A very natural estimator is the least squares one:
Note that \(\zeta ^{LS}\) coincides with the maximum likelihood estimate if the following model is assumed:
In the present context, however, no claim is made that reality conforms to our approximate model. It may well be that the true \(\theta \), being more complex than its parsimonious parametric model \(g(\zeta )\), is better represented by the model (4.9). Nevertheless, we are interested in finding the best approximation of \(\theta \) within a set \(\mathscr {P} = \{g(\zeta )| \zeta \in \mathbb {R}^q, \} \) of parametric approximations.
Under model (4.9), the optimal approximate model \(g^*\) can be defined as the one that minimizes the mean squared error \(\mathscr {E} \Vert \theta - g\Vert ^2\). For a generic model \(g=g(\zeta )\), parametrized by the vector \(\zeta \in \mathbb {R}^q, q \le n\), we have that
where the conditional expectation is taken with reference to the probability measure specified by (4.9). The following theorem, whose proof is in Sect. 4.13.5, was first derived in the context of linear system identification [20]. It shows that the optimal approximation is the projection of the Bayes estimate \(\theta ^{\mathrm B}\) onto the set \(\mathscr {P}\).
Theorem 4.6
(Optimal approximation, based on [20]) Assume that (4.9) holds. Then,
In view of the last theorem, the best approximation \(g(\zeta ) \in \mathscr {P}\) can be computed by a two-step procedure. First, the Bayes estimate \(\theta ^{\mathrm B}\) is obtained and in the second step the optimal \(g(\zeta ^*)\) is calculated as the solution of the least squares problem (4.42).
An interesting question is whether the obtained approximation is still optimal if the goal is minimizing the error, not with respect to \(\theta \), but with respect to the noiseless output \(\varPhi \theta \). In other words, the goal is finding \(g^o\) that minimizes \(\Vert \varPhi \theta - \varPhi g^o)\Vert ^2\). This can be done by introducing a weighted norm in the cost function:

where \(\Vert x\Vert _W^2\) stands for \(x^TWx\). In particular, if \(W= \varPhi ^T \varPhi \), then
By extending the proof of Theorem 4.6 to the case of a weighted norm, the following projection result is obtained.
Theorem 4.7
(Optimal weighted approximation, based on [20]) Assume that (4.9) holds. Then,
The consequence is that different approximations \(g^o\) are obtained depending on their prospective use. If the scope is just approximating \(\theta \), then \(W=I_n\), but, if the scope is predicting the outputs, then \(W= \varPhi ^T \varPhi \) and a different result is obtained.
4.8 Equivalent Degrees of Freedom
In this section, the Bayesian estimation problem for the linear model is analysed by means of a diagonalization approach. The purpose is twofold: (i) the equivalent degrees of freedom of the Bayesian estimator are introduced together with their relationship with suitable weighted squared sums of residuals and squared sums of estimated parameters; (ii) it is shown that \(\eta ^{\mathrm {ML}}\), the ML estimate of the hyperparameter vector, satisfies meaningful conditions involving the degrees of freedom. Finally, the obtained results are applied to the tuning of the regularization parameter, defined as the ratio between scaling factors for the noise variance \(\varSigma _E\) and the parameter variance \(\varSigma _{\theta }\). For the sake of simplicity, in this section, we assume \(\mu _{\theta }=0\).
Let us consider the case when the hyperparameters are just two scaling factors for the covariance matrices \(\varSigma _{E}\) and \(\varSigma _{\theta }\), that is,
where K and \( \varPsi \) are known definite positive matrices. In such a case, it is immediate to see that the Bayes estimate
depends only on the ratio \(\gamma =\sigma ^2/\lambda \), which behaves as a deterministic regularization parameter. This means that only the ratio between the scaling factors is relevant to the computation of a point estimate, although both of them are needed to compute the posterior variance (4.14). When \(\varPsi =I_N\) and \(K= I_n\), the above estimator provides a Bayesian interpretation to the classical ridge regression estimator. In particular, \(\gamma \) can be interpreted as a noise-to-signal ratio and its tuning reformulated as a statistical estimation problem.
Given a positive definite symmetric matrix S, let \(S^{1/2} = \left( S^{1/2} \right) ^T\) be its symmetric square root, i.e., \(S^{1/2} S^{1/2} =S\). Now, consider the singular value decomposition
where U and V are square matrices such that \(U^T U=I_N\) and \(V^T V=I_n\) and \(D \in \mathbb {R}^{N \times n}\) is a diagonal matrix with diagonal entries \(\{d_i\}, i=1, \ldots , n\), see (3.134). Moreover, define
Observe that
Analogously, \(\mathscr {E} \left( \bar{\theta }\bar{\theta }^T\right) =\lambda I_n\). Moreover,
In view of these properties, it follows that the original Bayesian estimation problem admits the following diagonal reformulation:
where \(\bar{E}\) and \(\bar{\theta }\) are independent of each other.
In view of statistical independence, we have N independent scalar models:
where \(\bar{v}_i \sim \mathscr {N}(0,\sigma ^2)\), \(i=1,\ldots ,N\), and \(\bar{\theta }_i \sim \mathscr {N}(0,\lambda )\), \(i=1, \ldots , n\).
By (4.11), it is straightforward to see that the Bayes estimates are
or, in matrix form,
Let the residuals be defined as \(\bar{\varepsilon }_i=\bar{y}_i - \bar{d}_i \bar{\theta }_i^{\mathrm B}\), \(i=1,\ldots , N\), where
Then, we have
or, in matrix form,
It is worth noting that the above relationships do not hold for a generic regularization parameter \(\gamma \), but only when \(\gamma =\sigma ^2 / \lambda \). In the remaining part, we present some results that were first derived in the context of Bayesian deconvolution in [5]. The proof of the following proposition is in Sect. 4.13.6.
Proposition 4.3
(based on [5]) For a given hyperparameter vector \(\eta \), let \(\mathrm {\mathrm {WRSS}}\) denote the following weighted squared sum of residuals:
where \(\theta ^{\mathrm B}= {\mathscr {E}}[\theta |Y,\eta ]\). Then,
where
is the so-called hat matrix.
As already noted, see (3.64), when \(\varSigma _E=\sigma ^2 I_N\), the predicted output \(\hat{Y} = \varPhi \theta ^{\mathrm B}\) and the measured output Y are related through the hat matrix:
In order to better understand the link between the hat matrix and the degrees of freedom, just consider the standard linear model \(Y=\varPhi \theta + E, \theta \in \mathbb R^n\), and the corresponding LS estimate \(\theta ^{\mathrm {LS}}=(\varPhi ^T \varPhi )^{-1}\varPhi ^T Y\). The predicted output is \(\hat{Y} = H^{\mathrm {LS}} Y\), where \(H^{\mathrm {LS}}=\varPhi (\varPhi ^T \varPhi )^{-1}\varPhi ^T\) enjoys the property \(\mathrm {trace}(H^{\mathrm {LS}}) = n\).
It is this analogy that justifies the introduction of equivalent degrees of freedom which we already encountered in (3.65) as a function of the regularized estimate \(\theta ^{\text {R}}\) described in the deterministic context. Its definition, here derived starting from the stochastic context, is reported below stressing its dependence on the regularization parameter \(\gamma \).
Definition 4.2
(equivalent degrees of freedom) The quantity
is called equivalent degrees of freedom.
In view of (4.52),
so that \(\mathrm {dof}(\gamma )\) is a monotonically decreasing function of \(\gamma \) with \(0 \le \mathrm {dof}(\gamma ) \le n\). The equivalent degrees of freedom provide an easily understandable measure of the flexibility of estimator: for instance, if they are approximately equal to three, the Bayesian estimator has a flexibility comparable to a model with three parameters. For linear-in-parameter models estimated by ordinary or weighted least squares, the degrees of freedom coincide with the rank of the regressor matrix and, therefore, they can take only integer values. The equivalent degrees of freedom of the Bayesian estimator, conversely, are a nonnegative real number controlled by \(\gamma \).
The next theorem establishes a connection between the degrees of freedom and the ML estimate
of the hyperparameter vector. Accordingly, we define
Moreover, we introduce the following weighted squared sum of estimated parameters:
The proof of the following result is in Sect. 4.13.7.
Theorem 4.8
(based on [5]) Assume that model (4.9) holds where \(\varSigma _{\theta }\) and \(\varSigma _E\) are as in (4.46)–(4.47). Then, the \(\mathrm {ML}\) estimates of the hyperparameters satisfy the following necessary conditions:
By taking the ratio between (4.55) and (4.56), the following proposition is obtained.
Proposition 4.4
(based on [5]) If \(\lambda ^{\mathrm {ML}}\) and \(\left( \sigma ^2 \right) ^{\mathrm {ML}}\) are nonnull and finite, then
This last corollary can be used as a simple and practical tuning procedure as it requires just a line search on the scalar \(\gamma \). Of course, (4.57) relies on the necessary conditions of Theorem 4.8, so that one has to check if the solution corresponds to a maximum of the likelihood function.
4.9 Bayesian Function Reconstruction
In this section, the Bayesian estimation approach is illustrated through its application to the reconstruction of an unknown function from noisy samples. The observations will be generated by adding pseudorandom noise to a known function g(x), so that the performances of alternative estimators can be directly assessed by comparison with the ground truth. The selected g(x) is the same function (3.26) used in the previous chapter in order to illustrate polynomial regression:
Also the noise model is the same:
We let \(N=40\), \(x_1=0,x_{40}=1\), and \(x_2,\ldots ,x_{39}\) are evenly spaced points between \(x_1\) and \(x_{40}\). Finally, \(e_i\), \(i=1,\ldots ,40\), are i.i.d. Gaussian distributed with mean zero and standard deviation 0.034.

Function reconstruction example. Top left: noisy data and true function. Top right, bottom left and bottom right: Residual sum of squares, i.e., the sum of the squared differences between the function values and their estimates, degrees of freedom and marginal loglikelihood against the hyperparameter \(\lambda \). The oracle denotes the value that minimizes RSS while ML indicates the maximizer of the marginal likelihood
The problem of estimating \(\theta _i =g(t_i)\), i.e., the samples of the unknown function, is a particular case of the linear Gaussian model (4.9) with \(\varPhi = I_N\), that is,
Since \(\varPhi \) is square, in this case, the number n of unknowns coincides with the number N of observations.
The noisy data and the true function are displayed in the top left panel of Fig. 4.1. It is assumed that the available prior knowledge regards the “regularity” of \(g(\cdot )\) and the knowledge that \(g(0)=0\). A possible probabilistic translation of this qualitative knowledge is assuming that \(\theta _i\) is a so-called random walk:
where \(w_i \sim \mathscr {N}(0, \lambda )\) are independent random variables. In fact, under the random walk model, the first difference
has a finite variance, equal to \(\lambda \). Hence, if we approximate the derivative of \(g(\cdot )\) by the first difference \(\theta _{i} - \theta _{i-1}\), this approximation is less than \(1.96 \sqrt{\lambda }\) with probability 0.95, which guarantees that the profile of the function cannot vary too quickly. Note that, due to the qualitative nature of the prior knowledge, the precise value of \(\lambda \) is unknown, so that it has to be treated as a hyperparameter. Conversely, it is assumed that the true value of \(\sigma ^2\) is known. Summarizing, we have
or, in matrix form,
Observing that \(\mathrm {Var}(w) = \lambda I_{N}\), the prior variance of the parameter vector is
For a given \(\lambda \), the Bayes estimate \(\theta ^{\mathrm B}\) is obtained according to (4.10) and can be written as
The corresponding equivalent degrees of freedom, obtained by (4.53), are now thought as a (monotonically nondecreasing) function of \(\lambda \), i.e.,
In the bottom left panel of Fig. 4.1, the degrees of freedom are plotted against \(\lambda \). For small values of \(\lambda \) they are close to zero and get closer to \(N=40\) as \(\lambda \) goes to infinity. It is a rather general feature that the function \(\mathrm {dof}(\lambda )\) is better visualized on a semilog scale. In order to tune the regularization parameter \(\lambda \), one can resort to the maximization of the marginal loglikelihood:
It turns out that \(\lambda ^{\mathrm {ML}}=4.92e-4\), the corresponding degrees of freedom being 12.17. For the sake of comparison, \(\lambda =6.61e-4\) is the best possible value, i.e., the one provided by an oracle that exploits the knowledge of the true function in order to minimize the sum of the squared reconstruction errors. This latter quantity is function of \(\lambda \) and here denoted by \(\mathrm {RSS}(\lambda )\). As seen in the top right panel of Fig. 4.1, marginal likelihood maximization achieves \(\mathrm {RSS}=9.80e-2\), not much worse than \(\mathrm {RSS}=9.71e-2\) achieved by the oracle, whose associated degrees of freedom are 13.88. Therefore, in this specific case, the marginal likelihood criterion somehow underestimates the complexity of the model.

Function reconstruction example. The panels display the Bayes estimates \(\hat{g}(x)\) corresponding to six different values of the hyperparameter \(\lambda \), including the one provided by the oracle and the maximum likelihood one
In Fig. 4.2, the estimates obtained in correspondence of six different values of \(\lambda \) are displayed. It is apparent that for \(\lambda =1e-6\) and \(\lambda =1e-5\) the estimated function is overregularized, while overfitting occurs for \(\lambda =1e-1\) and \(\lambda =1e-2\). The two bottom panels display the oracle and ML estimates, the former exhibiting a slightly more regular profile.
Finally, observing that in our case \(\varSigma _{\theta Y}=\varSigma _{\theta }\), we have
and we can compute the \(95\%\) Bayesian credible intervals, according to (4.8). As it can be seen from Fig. 4.3, the credible limits successfully capture the uncertainty, as demonstrated by the fact that the true function lies within the limits.

Function reconstruction example. True function and Empirical Bayes estimate \(\hat{g}(x)\) based on \(\lambda ^{ML}\) together with its \(95\%\) Bayesian credible intervals
This simple example has shown that Bayesian estimation can be effectively employed in order to reconstruct an unknown function without need of assuming a specific parametric structure, e.g., polynomial or other. The key idea is the use of a smoothness prior, expressed through the assumed prior distribution of the first differences of the function. The associated variance \(\lambda \) is treated as a hyperparameter that can be tuned via marginal likelihood maximization. Altogether, this is a flexible Empirical Bayes scheme that can be employed as a general-purpose black-box estimator.
Of interest is also the fact that the considered function could have been the impulse response of a dynamical system. In this respect, the example highlights also the limits of the approach. A first issue, easily fixable, has to do with the insufficient smoothness of the estimate. As seen in Fig. 4.3, the true function is significantly smoother than its estimate. As a matter of fact, it is not difficult to increase the regularity of the Bayes estimate: for instance, it suffices to assume that the samples \(\theta _i = g(x_i)\) are an integrated random walk:
where \(w_i \sim \mathscr {N}(0, \lambda )\) are again independent and identically distributed. This prior distribution is going to yield smoother profiles. Rather interestingly, the obtained estimate can be seen as the discrete-time counterpart of cubic smoothing splines, a method widely used for the nonparametric reconstruction of unknown functions.
A more serious issue regards extrapolation properties of the estimate that are in turn connected with the type of asymptotic decay shown by stable impulse responses. As it can be seen from Fig. 4.3, oscillations and credible intervals do not tend to dampen as x increases. While it would be easy to compute the Bayes estimate also for values far beyond the observation window, the result would be disappointing. Indeed, coherently with the diffusive nature of random walks, the width of the credible band would diverge, which is unnecessarily conservative when a stable impulse response is reconstructed. It appears that the task of identifying impulse responses calls for prior distributions that are specifically suited to the their features, especially the asymptotic ones. The development of these prior distributions, or equivalently the design of suitable regularization penalties, will be a central topic of the subsequent chapters.
4.10 Markov Chain Monte Carlo Estimation
As already mentioned in Sect. 4.4, in the full Bayesian approach the estimate
requires a marginalization with respect to the hyperparameter vector \(\eta \). In general, this integral cannot be computed analytically. Nevertheless it can be computed numerically by means of Markov Chain Monte Carlo (MCMC) methods that generate pseudorandom samples drawn from the joint posterior density \(\mathrm {p}(\theta , \eta |Y)\). The Gibbs sampling (GS) algorithm is the most straightforward and popular MCMC method. Its goal is to simulate a realization of a Markov chain, whose samples, though not independent of each other, form an ergodic process whose stationary distribution coincides with the desired posterior. Hence, provided that the burn-in phase is discarded, the posterior distribution is approximated by the histogram of the samples. In order to generate the samples, at each step a random extraction is made from a proposal distribution. In the Gibbs sampler, the proposal distribution is the so-called full conditional, that is, the probability of a given element of the parameter vector given the data and the current values of all other elements.
For the linear Gaussian model (4.9), a Gibbs sampler may be implemented as follows:
-
1.
Select initializations \(\eta ^{0}\), \(\theta ^{0}\), and let \(k=0\).
-
2.
Draw a sample \(\eta ^{(k+1)}\) from the full conditional distribution \(\mathrm {p}(\eta |\theta ^{(k)},Y)\).
-
3.
Draw a sample \(\theta ^{(k+1)}\) from the full conditional distribution \(\mathrm {p}(\theta |\eta ^{(k+1)},Y)\).
-
4.
If \(k=k_{max}\), end, else \(k=k+1\) and go to step 2.
This stochastic simulation algorithm generates a Markov chain whose stationary distribution coincides with \(\mathrm {p}(\theta , \eta |Y)\). Therefore, though correlated, the generated samples \(\{\theta ^{(k)}, \eta ^{(k)}\}\) can be used to estimate the (joint and marginal) posterior distributions and also the posterior expectations via the proper sample averages. For example,
The choice of the prior distributions \(\mathrm {p}(\theta | \eta )\) and \(\mathrm {p}(\eta |Y)\) has a critical influence on the efficiency of the scheme. The priors are called conjugate, when for each parameter the prior and the full conditional belong to the same distribution family. This implies that the same random variable generators can be used throughout the simulation.
Consider model (4.9), where \(\varSigma _E\) is known and \(\varSigma _{\theta }=\lambda K\), with \(\lambda \) unknown. Below, we describe a Gibbs sampling scheme for obtaining the posterior distributions of \(\theta \) and \(\eta =\lambda \). For \(\theta \), the prior is \(\theta |\lambda \sim \mathscr {N}(0, \lambda K)\). A conjugate prior for \(\lambda \) is the inverse Gamma distribution:
In other words, it is assumed that \(1/\lambda \) is distributed as a Gamma random variable, so that
With this choice of the prior, the full conditional of \(1/\lambda \) will be distributed as a suitable Gamma variable, \(\forall k\). More precisely, it can be shown that, if
then

Recall that the mean and variance of the Gamma random variable are \(g_1/g_2\) and \(g_1/g_2^2\), respectively. For the prior to be as uninformative as possible, we let \(g_1\) and \(g_2\) decrease to zero. Under these assumptions, the Gibbs sampler unfolds as follows:
-
1.
Initialize \(\lambda \) and \(\theta \), e.g., using the empirical Bayes estimates
$$ \lambda ^{(0)}=\lambda ^{ML}, \quad \theta ^{0}=\theta ^{\mathrm B}=\mathscr {E} (\theta |\lambda ^{ML},Y) $$and let \(k=0\).
-
2.
Draw a sample \(1/\lambda ^{(k+1)}\) from the full conditional distribution
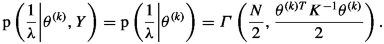 (4.62)
(4.62) -
3.
Draw a sample \(\theta ^{(k+1)}\) from the full conditional distribution
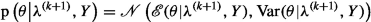
whose mean and variance are obtained according to (4.10) or (4.13).
-
4.
If \(k=k_{max}\), end, else \(k=k+1\) and go to step 2.
Above, the expression of the full conditional (4.62) is a direct consequence of the conjugacy property (4.61), as it can be seen by letting \(\bar{\theta }=K^{-1/2} \theta ^{(k)}\), where \(K^{-1/2}\) is a symmetric matrix such that \(K^{-1/2} K^{-1/2}= K^{-1}\).
When there are other hyperparameters to tune, e.g., the noise variance \(\sigma ^2\), the MCMC scheme can be properly extended. Provided that they exist, conjugate priors ensure an efficient sampling from the proposal distributions that generate the random samples, although a variety of MCMC schemes are available that deal with non-conjugate priors at the cost of an increased computational effort.
The main advantage of MCMC methods is that they implement the full Bayesian framework that is only approximated by the empirical Bayes scheme. In particular, MCMC methods do not neglect the hyperparameter uncertainty which is correctly propagated to the parameter estimate. However, as already discussed in Sect. 4.4, if data are informative enough to ensure a precise estimate of the hyperparameters, the difference between MCMC and empirical Bayes estimates (and associated credible regions) may be of minor importance.
4.11 Model Selection Using Bayes Factors
As discussed in Sect. 2.6.2, one fundamental issue is the selection of the “best” model inside a class of postulated structures. In the classical setting, this can be performed using criteria like AIC (2.34) and BIC (2.36) or adopting a cross-validation strategy. We will now see that the Bayesian approach provides a powerful alternative based on the concept of posterior model probability.
Let \(\mathscr {M}^i\) be a model structure parametrized by the vector \(x^i\). In the system identification scenario discussed in Chap. 2, the structures could be ARMAX models of different complexity. Hence, each \(x^i\) would correspond to the \(\theta ^i\) parametrizing (2.1) and containing the coefficients of rational transfer functions of different orders. If little knowledge on them were available, poorly informative prior densities could be assigned. Another example concerns the function estimation problem illustrated in Sect. 4.9. Here, \(x^i\) could contain the samples \(\theta ^i\) of the unknown function g modelled as a stochastic process. Then, the different structures could represent different covariances of g defined by a random walk or an integrated random walk. Each covariance would then depend on an unknown hyperparameter vector \(\eta ^i\) containing the variance of the random walk increments and possibly also of the measurement noise. So, in this case, one would have \(x^i=[\theta ^i \ \eta ^i]\). Here, \(\eta ^i\) is a random vector with flat priors typically assigned to the variances to include just nonnegativity information.
Now, suppose that we are given m competitive structures \(\mathscr {M}^i\). An important conceptual step is to interpret even them as (discrete) random variables, each having probability \(\Pr (\mathscr {M}^i)\) before seeing the data Y. The selection of the best model has then a natural answer: one should select the structure having the largest posterior probability \(\Pr (\mathscr {M}^i|Y)\). Using Bayes rule, one has
A typical choice is to think of the structures as equiprobable, so that \(\Pr (\mathscr {M}^i)=1/m\) for any i. Then, one can select the \(\mathscr {M}^i\) maximizing the so-called Bayesian evidence given by
Note that this corresponds to the marginal likelihood where all the parameter uncertainty connected with the i-th structure has been integrated out. Given two structures \(\mathscr {M}^1\) and \(\mathscr {M}^2\), the Bayes factor is also defined as follows:
Hence, large values of \(B_{12}\) indicate that data strongly support \(\mathscr {M}^1\) as opposed to \(\mathscr {M}^2\).
For the computation of the Bayesian evidence, the same numerical considerations reported at the end of Sect. 4.4 then hold. In particular, when the evidence cannot be computed explicitly, approximations are needed given by the Laplace approximation. Also the BIC criterion is often adopted. In particular, in the function estimation problem one can integrate out \(\theta \). Then, one can evaluate the complexity of the model using the marginal likelihood optimized w.r.t. the hyperparameters \(\eta ^i\), then adding a term which penalizes the dimension of the hyperparameter vector. This will be also discussed later on in Sect. 7.2.1.1.
MCMC can be also used to compute the evidence by simulating from posterior distributions and using the harmonic mean of the likelihood values, see Sect. 4.3 in [14]. A more powerful and complex approach employs MCMC techniques able to jump between models of different dimensions, an approach known in the literature as reversible jump Markov chain Monte Carlo computation [10].
4.12 Further Topics and Advanced Reading
There is an extensive literature debating on the interpretation of probability as a quantification of personal belief and it would be impossible to give a satisfactory account of all the contributions. The reader interested in studying motivations and foundations of subjective probability may refer to [4, 16]. One of the merits of Bayesian probability is its efficacy in addressing ill-posed and ill-conditioned problems, including also a wide class of statistical learning problems. The connection between deterministic regularization and Bayesian estimation has been pointed out by several authors in different contexts. Two examples related to spline approximation and neural networks are given by [8, 15].
The choice and tuning of the priors is undoubtedly the crux of any Bayesian approach. It is not a surprise that the tuning of hyperparameters via the Empirical Bayes approach emerged early as a practical and effective way to deploy Bayesian methods in real-world contexts, see [6] for its use in the study of the James–Stein estimator. Since the 1980s, thanks to the advent of Markov chain Monte Carlo methods, full Bayesian approaches have become a viable alternative, motivating reflections on the pros and cons of the two approaches, see, for instance, [17]. In particular, the connection between Stein’s Unbiased Risk Estimator (SURE), equivalent degrees of freedom and the robustness of marginal likelihood hyperparameter tuning has been investigated by [1, 21]. The choice of the prior distributions is somehow more controversial. In the present chapter, we exposed the principles of the maximum entropy approach, mainly following [12], but other approaches have been advocated for finding non-informative priors. A requirement could be invariance with respect to change of coordinates, enjoyed, for instance, by Jeffreys’ prior [13].
It not unusual to have parameters that should be left immune from regularization. In the Bayesian approach, this corresponds to the absence of prior information, usually expressed through an infinite variance prior. Although the case could be treated by assigning large variances to some parameters, it is numerically more robust useful to use the exact formulas. Their derivation by a limit argument followed [22].
The idea of deriving approximated parametric models by a suitable projection of the Bayes estimate conforms to Hjalmarsson’s advice “always first model as well as possible” [11]. The projection result has been derived in [23] for Gaussian processes and subsequently extended to general distributions in [20].
The equivalent degrees of freedom of a regularized estimator have been studied in the context of smoothing by additive [2] and spline models [3, 9], while a discussion specialized to the case of Bayesian estimation can be found in [5, 17].
Starting by the seminal paper [7], the use of stochastic simulation for computing posterior distributions according to a full Bayesian paradigm has gained a wider and wider adoption, especially when there exist conjugate priors that allow efficient sampling schemes. In particular, this is possible for the linear model discussed in this chapter, whose MCMC estimation is discussed in [18].
4.13 Appendix
4.13.1 Proof of Theorem 4.1
For simplicity, the proof is given in the scalar parameter case. We have that

Moreover,
Therefore, \(\theta ^\mathrm {B} = E \left[ \theta | Y \right] \) minimizes \(\mathrm {MSE}(\hat{\theta })\).
4.13.2 Proof of Theorem 4.2
Let \(X=\theta ^{\mathrm B} - \theta \) denote the estimation error. Recalling that \(\mathscr {E}[Y-\varPhi \mu _{\theta }]=\) \(\mathscr {E} [E]= 0\), from (4.10) it follows that \(\mathscr {E} X=0\). Note also that X and Y are jointly Gaussian and
Now, using (4.7), we have
4.13.3 Proof of Lemma 4.1
By applying the matrix inversion lemma (3.145) and proceeding with simple matrix manipulations,
4.13.4 Proof of Theorem 4.3
In view of (4.13), the conditional variance is
In view of (4.7)
By replicating the passages of Lemma 4.1
Moreover, by applying the matrix inversion lemma, see (3.145),
Then, letting \(a \rightarrow \infty \) complete the proof. Observe that all the inverse matrices appearing in the proof exist due to the full-rank assumptions made on \(\varPhi \) and \(\varPsi \).
4.13.5 Proof of Theorem 4.6
The expectation in (4.41) can be rewritten as

The proof follows by observing that in the last equation the first term does not depend on \(\zeta \). In the last passage, we have exploited the fact that \(\theta ^{\mathrm B} | Y\) is deterministic and equal to \(\mathscr {E} (\theta | Y)\).
4.13.6 Proof of Proposition 4.3
First observe that
Hence, in view of (4.52)
On the other hand, by simple matrix manipulations, it turns out that
Finally, recalling that \(\mathrm {trace}(AB)=\mathrm {trace}(BA)\),
thus proving the thesis.
4.13.7 Proof of Theorem 4.8
Without loss of generality, the proof refers to the diagonalized Bayesian estimation problem (4.48). The marginal loglikelihood function is
where \(\kappa \) denotes a constant we are not concerned with. By equating to zero the partial derivatives with respect to \(\sigma ^2\) and \(\lambda \) we obtain
which concludes the proof.
References
Aravkin A, Burke JV, Chiuso A, Pillonetto G (2014) Convex vs non-convex estimators for regression and sparse estimation: the mean squared error properties of ARD and GLASSO. J Mach Learn Res 15(1):217–252
Buja A, Hastie T, Tibshirani R (1989) Linear smoothers and additive models. Ann Stat 453–510
Craven P, Wahba G (1979) Smoothing noisy data with spline functions. Numer Math 31:377–403
De Finetti B (2017) Theory of probability: a critical introductory treatment, vol 6. Wiley
De Nicolao G, Sparacino G, Cobelli C (1997) Nonparametric input estimation in physiological systems: problems, methods, and case studies. Automatica 33(5):851–870
Efron B, Morris C (1973) Stein’s estimation rule and its competitors-an empirical Bayes approach. J Am Stat Assoc 68(341):117–130
Geman S, Geman D (1984) Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans Pattern Anal Mach Intell 6:721–741
Girosi F, Jones M, Poggio T (1995) Regularization theory and neural networks architectures. Neural Comput 7(2):219–269
Golub GH, Heath M, Wahba G (1979) Generalized cross-validation as a method for choosing a good ridge parameter. Technometrics 21(2):215–223
Green PJ (1995) Reversible jump Markov chain Monte Carlo computation and Bayesian model determination. Biometrika 82(4):711–732
Hjalmarsson H (2005) From experiment design to closed loop control. Automatica 41(3):393–438
Jaynes ET (1982) On the rationale of maximum-entropy methods. Proc IEEE 70(9):939–952
Jeffreys H (1946) An invariant form for the prior probability in estimation problems. Proc Math Phys Eng Sci 186(1007):453–461
Kass RE, Raftery AE (1995) Bayes factors. J Amer Statist Assoc 90:773–795
Kimeldorf G, Wahba G (1970) A correspondence between Bayesian estimation on stochastic processes and smoothing by splines. Ann Math Stat 41(2):495–502
Lindley DV (2013) Understanding uncertainty. Wiley
MacKay DJC (1992) Bayesian interpolation. Neural Comput 4:415–447
Magni P, Bellazzi R, De Nicolao G (1998) Bayesian function learning using MCMC methods. IEEE Trans Pattern Anal Mach Intell 20(12):1319–1331
Papoulis A (1984) Probability, random variables and stochastic processes. Mc Graw-Hill
Pillonetto G, De Nicolao G (2010) A new kernel-based approach for linear system identification. Automatica 46(1):81–93
Pillonetto G, Chiuso A (2015) Tuning complexity in regularized kernel-based regression and linear system identification: the robustness of the marginal likelihood estimator. Automatica 58:106–117
Wahba G (1990) Spline models for observational data. SIAM, Philadelphia
Zhu H, Rohwer R (1996) Bayesian regression filters and the issue of priors. Neural Comput Appl 4:130–142
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this chapter

Cite this chapter
Pillonetto, G., Chen, T., Chiuso, A., De Nicolao, G., Ljung, L. (2022). Bayesian Interpretation of Regularization. In: Regularized System Identification. Communications and Control Engineering. Springer, Cham. https://doi.org/10.1007/978-3-030-95860-2_4
Download citation
DOI: https://doi.org/10.1007/978-3-030-95860-2_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-95859-6
Online ISBN: 978-3-030-95860-2
eBook Packages: EngineeringEngineering (R0)