
Abstract
This chapter describes how smart applications from multiple domains can participate in the creation of data spaces based on FIWARE software building blocks. Smart applications participating in such data spaces share digital twin data in real time using a common standard API like NGSI-LD and relying on standard data models. Each smart solution contributes to build a complete digital twin data representation of the real world sharing their data. At the same time, they can exploit data shared by other applications. Relying on FIWARE Data Marketplace components, smart applications can publish data under concrete terms and conditions which include pricing or data usage/access policies.
A federated cloud infrastructure and mechanisms supporting data sovereignty are necessary to create data spaces. However, additional elements have to be added to ease the creation of data value chains and the materialization of a data economy. Standard APIs, combined with standard data models, are crucial to support effective data exchange enabling loose coupling between parties as well as reusability and replaceability of data resources and applications. Similarly, data spaces need to incorporate mechanisms for publication, discovery, and trading of data resources. These are elements that FIWARE implements, and they can be combined with IDSA architecture elements like the IDS Connector to create data spaces supporting trusted and effective data sharing.
The GAIA-X project, started in 2020, is aimed at creating a federated form of data infrastructure in Europe which strengthens the ability to both access and share data securely and confidently. FIWARE is bringing mature technologies, compatible with IDS and CEF Building Blocks, which will accelerate the delivery of GAIA-X to the market.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others

1 Introduction to FIWARE
FIWAREFootnote 1 was created with the ultimate goal of creating an open sustainable ecosystem around public, royalty-free, and implementation-driven software platform standards easing the development of smart solutions and supporting organizations in their transition into smart organizations. From a technical perspective, FIWARE brings a curated framework of open-source software components which can be assembled together and combined with other third-party platform components to build platforms easing the development of smart solutions and smart organizations in multiple application domains: cities, manufacturing, utilities, agrifood, etc. Since the creation of the FIWARE Foundation in late 2016, a vibrant FIWARE Community has been formed with a true worldwide dimension, comprising more than 90 member organizations,Footnote 2 including large corporations, SMEs, technology centers and universities, and hundreds of individual members (Fig. 24.1). Parallel to this growth, the number of organizations adopting FIWARE has not stopped growing.

Current member organizations in the FIWARE community (©2021, FIWARE)
Any software architecture “powered by FIWARE’‘ gravitates around management of a digital twin data representation of the real world. This digital twin data representation is built based on information gathered from many different sources, including sensors, cameras, information systems, social networks, end users through mobile devices, etc. It is constantly maintained and accessible in near real time (“right time” is the term also often used, reflecting that the interval between the instants of time at which some data is gathered and made accessible is enough short to allow a proper reaction). Applications constantly process and analyze this data (not only current values but also history generated over time) in order to automate certain tasks or bring support to smart decisions by end users. The collection of all digital twins modelling the real world that is managed is also referred to as Context, and the data associated with attributes of digital twins is also referred to as context information.
In FIWARE, a digital twin is an entity which digitally represents a real-world physical asset (e.g., a bus in a city, a milling machine in a factory) or a concept (e.g., a weather forecast, a product order). Each digital twin:
-
Is universally identified with a URI (Universal Resource Identifier).
-
Belongs to a well-known type (e.g., the Bus type, of the Room type) also universally identified by an URI.
-
Is characterized by several attributes which in turn are classified as:
-
Properties holding data (e.g., the “current speed” of a Bus, or “max temperature” in a Room).
-
Relationships, each holding a URI identifying a third digital twin entity the given entity is linked to (e.g., the concrete Building where a concrete Room is located).
-
Attributes of a digital twin may vary ranging from attributes that are quite static (e.g., the “license plate” of a Bus) to attributes that change very dynamically (e.g., the “speed” or “number of passengers” in a Bus) to attributes which still change but not that often (e.g., the “driver” in a Bus which may change twice a day). Very important, the attributes of a digital twin are not only limited to observable data but also inferred data. Thus, for example, the digital twin of a Street may not only have an attribute “current traffic”, which may be automatically measured through sensors or cameras, but an attribute “forecasted traffic in 30 minutes” which might be calculated based on AI algorithms that keep the value of this attribute updated based on current traffic data, other relevant data impacting traffic (e.g., current weather observed and forecasted, schedule of events nearby, etc.), and historical information about traffic in the given street. Therefore, the digital twin data representation of the world that is managed in a “powered by FIWARE” architecture is expected to contain all the information needed by smart applications, not only measurable data but also other augmented insights and knowledge acquired over time.
A digital twin approach provides the basis for data integration at different levels, as illustrated in Fig. 24.2:
-
Within a vertical smart solution, solving how main building blocks within the architecture can be integrated.
-
Within a smart organization, bringing support to the integration of the different systems within a smart organization following a system of systems approach.
-
Within a smart data space, establishing the basic “common lingua” that systems linked to the different organizations speak and understand.

Levels of integration supported following a digital twin approach (©2021, FIWARE)
Two critical elements need to be standardized in order to support an effective data integration at these three levels: the API to get access to digital twin data and the data models describing the attributes and semantics associated with the different types of digital twins being considered. The FIWARE Community has driven and continues to drive standardization at both fronts:
-
The NGSI API provides a simple yet powerful RESTful API for getting access to context/digital twin data. NGSI API specifications have evolved over time driven by feedback from developers and implementation experiences. A first mature version of the API is the NGSIv2 API, which was defined by members of the FIWARE Community and is currently used in many systems in production within multiple sectors. Evolution of the API has taken place within the ETSI CIM ISGFootnote 3 (Context Information Management Industry Specification Group), where members of the FIWARE Community and the FIWARE Foundation have led the definition of an evolved version of the API, known as the NGSI-LD API, whose specifications were first published by ETSI in 2019 and continue to evolve.Footnote 4 The NGSI-LD API is used as the data integration API and is implemented by the core component of any “powered by FIWARE” architectures: the so-called Context Broker component. Different alternative open-source implementations of a Context Broker are available within the FIWARE Community, namely, the Orion-LD, Scorpio, and Stellio products.
-
The Smart Data Models initiative,Footnote 5 launched by the FIWARE Foundation, provides a library of Data Models described in JSON/JSON-LD format which are compatible, respectively, with the NGSIv2/NGSI-LD APIs as well as any other RESTful interfaces compliant with the Open API specification. Data Models published under the initiative are compatible with schema.org and comply with other existing de facto sectoral standards when they exist. They solve one major issue developers are facing like it is the fact that a given data model specification may be mapped into JSON/JSON-LD in many different ways, all of them valid. Thanks to the Smart Data Models initiative, developers can rely on concrete mappings into JSON/JSON-LD, compatible with the NGSIv2/NGSI-LD APIs, which are made available within this library, avoiding interoperability problems derived from alternative mappings. Since its creation, more than 500 data models have been published, and the number of organizations contributing data model descriptions is constantly growing. Relevant organizations like TM ForumFootnote 6 or IUDXFootnote 7 are joining forces with the FIWARE Foundation bringing support to an open governance model for the initiative, following best open-source practices.
Building around the FIWARE Context Broker, which is the core mandatory component in any “powered by FIWARE” architecture, a rich set of complementary open-source components are available listed as part of the FIWARE Catalogue.Footnote 8 These components can be classified in the following categories or chapters:
-
Components easing development of interfaces with the Internet of Things, Robotic, and third-party systems.
-
Components supporting context/digital twin data processing and monitoring or the connection with data processing engines (e.g., Apache Spark, Apache Flink), monitoring tools (e.g., Grafana), and analysis platforms (e.g., Apache Superset).
-
Components covering aspects related to Identity and Access Management (IAM) as well as Publication and Monetization of Data (including data accessible via APIs like NGSI-LD).
Figure 24.3 depicts the reference architecture of a vertical smart solution powered by FIWARE. The concrete example corresponds to a smart solution for picking and palletizing products from a warehouse using robots. This reference architecture is structured in essentially three layers:
-
A Context Broker component is at the core of the architecture, keeping a digital twin representation of the real-world objects and concepts relevant to the specific problem tackled: AGV robots, palletizer robots, shelf sections where products are stored in the warehouse, automatic doors AGV robots have to pass, operators in the shopfloor, items of stored products, orders generated from the CRM system, etc.
-
Southbound to the Context Broker, the NGSI IoT Agents, available as part of the FIWARE IDAS framework, are used for connections to robotic systems exporting the OPC-UA IoT protocol or to specific sensors or actuators, used, for example, to detect items in shelf sections or to be able to open the shop floor doors. They perform the necessary conversions between IoT protocols and NGSI. In addition, System Adapters developed based on the IDAS Agent library cope with the connection to the CRM and the Warehouse Inventory Management system that the solution has to interface with. FIWARE components like FIROS/SOSS allow, on the other hand, to perform the adaptation to robotic systems based on ROS/ROS2. Last but not least, the FIWARE component Kurento is able to process the video streams of cameras deployed in the shop floor, which are helpful to detect potential obstacles or risky situations.
-
Northbound to the Context Broker, a number of tools are targeted to support real-time big data processing of the streams of history data generated as context/digital twin information evolves over time. A combination of third-party open-source components (Apache Superset, Grafana) and FIWARE components (e.g., Wirecloud) is shown in the picture targeted to support the creation of operational dashboards and advanced data maps for monitoring processes. A number of FIWARE Data Connectors (Cygnus, Draco, Cosmos, STH Comet, QuantumLeap) are available as part of FIWARE to facilitate transference of historic context/digital twin information to these tools.

Smart solution for picking and palletizing products from a warehouse (©2021, FIWARE)
Transversal to all these layers, a number of FIWARE components support Identity and Access Management. They control the flow of data across the different layers. With regard to the access to the Context Broker, they enforce the policies establishing what users can update, query, or subscribe to changes on context/digital twin data. Note that the flow of data is not only south to north in the picture. Northbound applications can perform updates on context data, which in turn will trigger changes in the devices, robots, or systems that are connected southbound.
An important point to highlight is that FIWARE is not about taking it all or nothing. You are not forced to use all the complementary FIWARE components mentioned above, but you are free to use other third-party platform components as well to design the hybrid platform of your choice. Thus, for example, you may opt to use a concrete IoT platform instead of IDAS IoT Agents to interface with sensors and actuators as reflected in the picture. As long as it uses the FIWARE Context Broker technology to manage context information, your platform can be labeled as “Powered by FIWARE” and solutions build on top as well.
Figure 24.4 depicts the reference architecture of a smart city powered by FIWARE. Again, the Context Broker component is at the core of the architecture, holding a digital twin representation of the real-world objects and concepts and describing what is going on in the city: streets, waste bins and containers, waste trucks, buses, electric vehicle chargers, buildings, events, citizen claims, etc. The different vertical smart solutions deployed in the city (e.g., Air Quality Monitoring, Smart Traffic Management, Smart Parking, Smart Waste Management) are connected to the Context Broker contributing that information they manage which is relevant for creating a holistic Context/Digital Twin representation of the whole City, thereby breaking the information silos. Some of these vertical smart solutions may be powered by FIWARE (e.g., Traffic Control and Waste Management systems in the figure) in which case their interface with the global city-level Context Broker does not require any adaptation. Others may not be powered by FIWARE, but this doesn’t represent a major problem because creation of NGSI system adapters which translate from whatever API those systems export to NGSI-LD has proven not to be difficult. Last but not least, the City may deploy sensor/camera infrastructures through which valuable data is extracted.

Smart city reference architecture (©2021, FIWARE)
Exploiting the complete Context/Digital Twin representation of the City, the Smart City Governance System (or City Operation Center) can be developed. Real-time big data processing tools can be used relying on data coming from multiple sources, extracting more valuable insights for the support of decisions. Similarly, monitoring tools can leverage in this holistic Context/Digital Twin representation of the City.
So far, we have described in more detail how FIWARE components can be used to achieve the two first levels of data integration using a Digital Twin approach (see Fig. 24.2). Within the next section, we will elaborate on how FIWARE also helps achieve the third level of data integration, linked to the creation of Data Spaces as a natural extension of the first two. Actually, in Fig. 24.4, part of the Context/Digital Twin data representation of the city can be made available to data spaces, published through data marketplaces.
2 FIWARE and Data Spaces
A data space can be defined as a decentralized data ecosystem built around commonly agreed building blocks enabling an effective and trusted sharing of data among participants. From a technical perspective, a number of technology building blocks are required ensuring:
-
Data interoperability—Data spaces should provide a solid framework for an efficient exchange of data among participants, supporting full decoupling of data providers and consumers. This requires the adoption of a “common lingua” every participant uses, materialized in the adoption of common APIs for the data exchange, and the definition of common data models. Common mechanisms for traceability of data exchange transactions and data provenance are also required.
-
Data sovereignty and trust—Data spaces should bring technical means for guaranteeing that participants in a data space can trust each other and exercise sovereignty over data they share. This requires the adoption of common standards for managing the identity of participants, the verification of their truthfulness, and the enforcement of policies agreed upon data access and usage control.
-
Data value creation—Data spaces should provide support for the creation of multi-sided markets where participants can generate value out of sharing data (i.e., creating data value chains). This requires the adoption of common mechanisms enabling the definition of terms and conditions (including pricing) linked to data offerings, the publication and discovery of such offerings, and the management of all the necessary steps supporting the life cycle of contracts that are established when a given participant acquires the rights to access and use data.
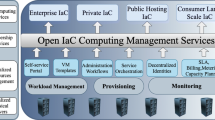
Besides the adoption of a common technology foundation, data spaces also require governance, that is, the adoption of a number of business, operational, and organizational agreements among participants. Business agreements, for example, specify what kind of terms and conditions can regulate the sharing of data between participants and the legal framework supporting contracts established through the data space. Operational agreements, on the other hand, regulate policies that have to be enforced during data space operation like, for example, compliance with GDPR (General Data Protection Regulation) or the second Payment Services Directive (PSD2) in the finance sector. They may also comprise the definition of tools that operators of cloud infrastructures or global services supporting data spaces must implement enabling auditing of certain processes or the adoption of cybersecurity practices. Last but not least, organizational agreements establish the governance bodies (very much like ICANN for the Internet). They deal with the identification of concrete specifications that products implementing technology building blocks in a data space should comply with, as well as the business and operational agreements to be adopted. The complete taxonomy of building blocks required for creating data spaces is illustrated in Fig. 24.5.

Building blocks in a data space (©2021, FIWARE)
Sharing of data within a given data space should not be limited to a single domain. This would severely limit the creation of new innovative services since individuals and organizations usually act in multiple domains at the same time and many opportunities will flourish when data generated within organizations operating in a certain domain (e.g., management of traffic in cities) is shared for its exploitation in processes relevant to other domains (continuing with the example, logistics). Therefore, technology building blocks for data spaces must be domain-agnostic. On the other hand, they should rely on open standards, allowing multiple infrastructure and global service providers to emerge and support data spaces, without getting locked in any particular provider. Given this, while making things work in living labs and pilots is relatively easy, the main challenge toward definition of successful data spaces is the decision of what concrete standards and design principles are adopted, since they have to be accepted by all participants.
The following sections elaborate on the different components FIWARE brings materializing the different technical building blocks required for creation of data spaces.
2.1 Data Interoperability
Data providers joining data spaces must be able to publish data resources at well-defined endpoints knowing that data consumers, unknown by them a priori, will know how to retrieve and consume data through those endpoints. Data consumers, on the other hand, must know how data available through endpoints they discover can be consumed. This is a key principle which was observed in the design of the World Wide Web: content providers publish web pages on web servers (endpoints) knowing that web browsers will be able to connect to them and retrieve web pages whose content they can render and display to end users. It means that all participants in data spaces should “speak the same language,” which translates into adopting domain-agnostic common APIs and security schemas for data exchange (the way of constructing sentences) together with data models represented in data formats compatible with those APIs (the vocabulary used in constructed sentences).
The NGSI API is domain-agnostic. Actually, many different systems have been developed using NGSI in domains such as smart cities, smart manufacturing, smart energy, smart water, smart agrifood, smart ports, or smart health, to mention a few. This facilitates data sharing because each system participating in a data space will be publishing data that simply enriches a digital twin data representation of the world that the rest of the systems connecting to the data space will know how to access. Systems participating into the data space don’t know a priori what other systems may consume the data they publish (although they will be able to set up concrete terms and conditions for accessing/using data as we will explain in the next section).
Figure 24.6 illustrates how different systems participating in data spaces “powered by FIWARE” will exchange data. Context Broker servers are the endpoints through which systems connected to the data space publish digital twin data, very much like web servers publish html content on the World Wide Web. Those systems can in turn connect to Context Broker servers in order to obtain information they need. Note that data spaces powered by FIWARE enable near-real-time (right-time) exchange of digital twin data which is fundamental in the design of innovative value chains demanding a very dynamic exchange of data among participants. Just think about scenarios like a city managing traffic lights in streets close to a given train station in order to facilitate that travelers arriving and taking a taxi can leave faster to their destinations. NGSI-LD brings very simple therefore easy-to-use operations for creating, updating, and consuming context/digital twin data but also more powerful operations like sophisticated queries, including geo-queries, or the subscription to get notified on changes of digital twin entities. On the other hand, data spaces “powered by FIWARE” can also support the exchange of large files using standard file transfer protocols, since this kind of file transferences may be required for certain scenarios like training of AI algorithms.

Data exchange in a data space “powered by FIWARE” (©2021, FIWARE)
Note that systems participating in data spaces “powered by FIWARE” do not need to be themselves “powered by FIWARE.” Systems which have not been architected using FIWARE can still use the NGSI API to share data they produce and consume data they need in the form of data associated with attributes of digital twin entities which represent that part of the world they deal with. This can be done directly by the systems or through NGSI system adapters which have been programmed to perform a conversion between NGSI and the API that the system natively supports for managing data.
From a theoretical perspective, systems connected to a data space should be able to share data using the API they prefer. The specification (information model) of each API could be published as some kind of manifesto that certain components, integrated as part of the platform that systems should use to connect to the data space, can dynamically process in order to perform an automated adaptation from/to the APIs. However, such an approach faces important challenges. In the first place, such an approach has only been demonstrated in very simple scenarios and involving very simple APIs. Thus, the ability to exploit the kind of sophisticated features NGSI-LD would support for accessing digital twin data will be rather limited. On the other hand, creating a “common lingua” has proven to work for creating the kind of ecosystems we pursue: we shall ask ourselves if the World Wide Web had experienced the speed on adoption reached if HTTP and HTML hadn’t been adopted as “common lingua” for web servers and browsers and each web server had the ability to choose a different protocol (as opposed to HTTP) or a different document format (as opposed to HTML). NGSI-LD has the advantages of being an open standard (defined by ETSI), has a strong open-source community behind (FIWARE), and, quite relevant within Europe, it will pave the way for alignment with developments in the Connecting Europe Facility (CEF) program. Creation of system adapters that transform from specific APIs a given system may still require to use from/to NGSI-LD has proven to be not a complex task.
As mentioned before, the NGSI-LD API is domain-agnostic; therefore, it is designed to work for any type of digital twin. Consequently, achieving full interoperability requires also the adoption of common data models to be represented in formats compatible with the APi. Here, the Smart Data Models initiative,Footnote 9 already introduced in the previous section, reaches great relevance. It brings a powerful resource for developers who can rely on the way data model specifications are mapped into concrete JSON and JSON-LD structures under the initiative, compatible with NGSIv2 and NGSI-LD, respectively.
Figure 24.7 illustrates how resources are organized within the Smart Data Models initiative on GitHub. Data models are grouped into “subjects” (weather, parking, aquaculture, etc.) which in turn are referred from repositories associated with the multiple application domains being considered (Smart Cities, Smart Agrifood, Smart Manufacturing, Smart Water, Smart Energy, etc.). Note that there are subjects which are very specific to a given application domain (e.g., “street lighting” with regards to smart cities and communities), while others may be relevant to multiple domains (e.g., “weather” that is relevant to almost every domain or “sewage” that is relevant to the Smart Cities and Smart Water domains). Published data models are open to contributions and royalty-free.

Smart data models organization on GitHub (©2021, FIWARE)
An open governance model has been defined for the Smart Data Models initiative defining the life cycle of data models comprising incubation of brand new data models as well as curation of data models via harmonization of different contributions. Processes and procedures for management of the different activities follow best practices from open-source communities, guided by principles of transparency and meritocracy.
Completing the picture of building blocks for Data Interoperability, FIWARE brings components which provide the means for tracing and tracking in the process of data provision and data consumption/use. It provides the basis for a number of important functions, from identification of the provenance of data to audit-proof logging of NGSI-LD transactions. For those data spaces with strong requirements on transparency and certification, FIWARE brings components (i.e., Canis Major) that ease recording of transactions into different Distributed Ledgers/Blockchains.
2.2 Data Sovereignty and Trust
Data spaces must provide means for guaranteeing organizations joining data spaces that they can trust the other participants and that they will be able to exercise sovereignty on their data. That requires the definition of common building blocks, based on mature security standards that will be used by all participants in the data space.
A first fundamental building block to support within data spaces has to do with Identity Management (IM). This building block allows identification, authentication, and authorization of organizations, individuals, machines, and other actors participating in a data space. While this building block can be implemented on the basis of third-party open-source technologies like KeyCloak,Footnote 10 just to mention one popular example, FIWARE brings the Keyrock component which supports OpenIdConnect,Footnote 11 SAML 2.0,Footnote 12 and OAuth2Footnote 13 standards. Quite relevant for data spaces deployed in Europe, Keyrock also resolves integration with eIDAS,Footnote 14 a building block provided by the European Commission that enables the mutual recognition of national electronic identification schemes (eID) across borders, allowing European citizens to use their national eIDs when accessing online services from other European countries.
A second fundamental building block will be the one which facilitates trusted data exchange among participants, providing certainty that participants involved in the data exchange are who they claim to be and that they comply with defined rules/agreements. Trust refers to the fact that data providers and data consumers can rely on the identity of the members of the data ecosystem and beyond that between different security domains. Here, IDS Connector technology, as described in the IDS Reference Architecture Model (RAM),Footnote 15 emerges as a solid basis, and the FIWARE Community has incubated an open-source implementation of this technology that has already been tested how it can integrate with the rest of core FIWARE components.
Figure 24.8 illustrates how an AI service provider application and an AI service consumer application, each hosted in different organizations and participating in a common data space “powered by FIWARE,” may interact with each other. It shows the role of components that are part of the incubated FIWARE IDS Connector implementation and their integration with other FIWARE components. The AI service provided can be an advanced traffic prediction service, while the AI service consumer application might be a traffic management system running in a given city. The AI service consumer wishes to incorporate near-real-time traffic predictions based on current traffic levels measured through IoT sensors deployed in the streets. The Context Broker component running on the consumer application sends notifications based on updates on attribute “current traffic” of a given street. These updates are notified to the AI service where the value is processed in real-time applying AI algorithms (e.g., using Apache Spark). The predicted traffic in about 30 minutes is calculated (generating, e.g., values “low,” “medium,” or “high”), and the value of attribute “traffic in 30 minutes” of the given street is updated if changes occur.

Integration of FIWARE IAM and IDS Connector functionalities (©2021, FIWARE)
In FIWARE, the implementation of IDS Connectors comes closely linked to the deployment of Kubernetes clusters. In this respect, the implementation of the concept of IDS connectors would not be limited to the implementation of the procedures used to exchange data among IDS connectors but also the monitoring and control of what is deployed in the associated clusters (e.g., guaranteeing that only certified components/applications are deployed) as well as the control of the flow of data within the cluster, ensuring enforcement of data access/usage control policies. For this last purpose, the usage of products supporting service mesh concepts like IstioFootnote 16 is essential. In Fig. 24.8, such components are identified as “traffic routers.”
In the IDS RAM, identity and access/usage control is currently performed at organization level. The Certification Authority (CA) and Dynamic Attribute Provisioning Service (DAPS) are in charge of verifying that organizations exchanging data are known and trustworthy. The IDS Connectors ensure that data exchanges are authorized at organization level. In Fig. 24.8, for example, the FIWARE IDS Connector running at the AI service consumer side ensures that when an IoT agent updates context/digital twin attributes on the local Context Broker (1) forwarding of updates (2) are sent out only to authorized organizations like the AI service provider in this example. The FIWARE IDS Connector running at the service provider side will in turn verify that the organization from which updates are received is a trusted party and is authorized to make such updates to be then forwarded through the FIWARE Cosmos component to Spark where AI algorithms for traffic prediction purposes run. Similarly, when updates on the Context Broker deployed at the consumer side are invoked from the AI algorithms (3), the FIWARE IDS connector at the AI service provider side verifies that only requests authorized to be transmitted will be sent out. The FIWARE IDS connector at the AI consumer side verifies that the update request received comes from a trusted and authorized organization. All these verifications take place relying on the global CA + DAPS services of the data space.
On top of this authentication and data access/usage control procedures, performed at organization level via IDS Connectors, FIWARE security components enable an additional and finer-grained authentication and access control at the end user level. Therefore, coming back to Fig. 24.8, notifications received at the AI service provider side, same as update requests handled at the AI service consumer application side, carry additional security tokens (namely, JSON Web Tokens, JWT) linked to users on behalf of which those notifications/requests have been issued. The API proxy components, both at the consumer and on the provider side, validate those tokens and obtain the info associated with the corresponding users relying on standard Identity Provider services supported by the FIWARE Keyrock component. To manage access control, a standard XACMLFootnote 17 process is implemented. The API proxy plays the role of the Policy Enforcement Point (PEP), and the FIWARE AuthZForce component, also alternatively Keyrock, implements the Policy Decision Point (PDP) functionality. That means that the proxy forwards user info of the particular user together with information about the concrete notification/request to the PDP which then checks whether users with those credentials are entitled to perform the given operation. FIWARE brings alternative implementations of the API proxy, namely, Wilma, API Umbrella, and CoatRack, all of them compatible with Keyrock or any third-party product implementing OpenID Connect, OAuth2, and XACML standards. Keyrock also implements Policy Administration Point (PAP) and Policy Management Point (PMP) standard XACML functions.
2.3 Data Value Creation
Loose coupling of participants is a fundamental principle in data spaces. Data providers and consumers do not necessarily know about each other. Therefore, it becomes essential to incorporate building blocks enabling the management of data resources as true assets with a business value, assets which can be published, discovered, and, eventually, traded, this way boosting the creation of multi-side markets where innovative services can be created.
FIWARE Business Application Ecosystem (BAE) components enable creation of Marketplace services which participants in data spaces can rely on for publishing their offerings around data assets they own. Different types of data assets can be defined via plugins, but three kinds of standard data asset types are supported by default, namely, static data files, right-time data resources provided via NGSI-LD at well-defined endpoints, and data processing services, which typically have associated well-defined endpoints for providing input data and publish results, both in right time, using NGSI-LD. Marketplace services are accessible through a portal or via APIs. Users, either end users through the portal or applications via APIs, of the Marketplace service can perform the following main actions:
-
Define new data asset types via plug-ins.
-
Register offerings around defined data asset types which typically means providing description of the asset, data models behind, endpoints (URLs) through with the data asset will be accessible, and, very important, terms and conditions defined around the data asset, including SLAs, legal clauses, access control policies users of the asset have to comply with, and associated pricing schema, which may be based on:
-
Free access (open data): User pay no money.
-
One-time payments: Users pay only once.
-
Recurring payments: Users pay periodically (monthly, yearly, etc.) for getting access to some data. In addition, users will be able to cancel the subscription, but they won’t be able to access data anymore.
-
Usage payment: Users pay per use. Their payments are based on the amount of information consumed.
-
-
Ability to navigate and search/discover existing offerings based on selected criteria.
The following is a list of backend components and APIs associated with the FIWARE BAE Marketplace:
-
Backend implementing standard TM Forum APIs supporting configuration of the marketplace:
-
Catalog Management API.
-
Product Ordering Management API.
-
Product Inventory Management API.
-
Party Management API.
-
Customer Management API.
-
Billing Management API.
-
Usage Management API.
-
-
Rating, Charging, and Billing backend.
-
Revenue Settlement and Sharing System.
-
Authentication, API Orchestrator, and Web portal.
Figure 24.9 shows the FIWARE Data Marketplace portal deployed and configured for the i4Trust project.Footnote 18

FIWARE data marketplace portal (©2021, FIWARE)
FIWARE also comprises components for publication of data resources linked to data assets around which offerings are managed through the FIWARE Data Marketplace. For this purpose, we have the Idra publication platform and have developed as well extensions to the CKAN open data platform, which is an open-data publication platform widely adopted in the market. These extensions support enhanced data management capabilities and integration with FIWARE technologies including NGSI. In particular, data publication and discovery features provided by CKAN have been enhanced with the following features:
-
Right-time (near-real-time) time data publication—thanks to this extension, CKAN is not limited to list data resources linked to static files as part of its catalogue but also data resources linked to NGSI-LD requests served by Context Broker components deployed in a data space. This brings the ability to discover data resources relying on DCAT capabilities publication platforms support.
-
Identity management, authentication, and access control functions based on Keyrock components—therefore supporting OpenId Connect, OAuth2, and XACML standards adopted at overall data space level.
-
Publication of priced data resources—thanks to this extension, it is possible to mark data resources listed as part of the catalogue as linked to offerings visible in the Data Marketplace. Users can therefore click on those data resources and navigate to the Marketplace to proceed with the acquisition of access rights.
-
Enhanced Data Visualization—thanks to this extension WireCloud (Configurable Dash-boards component) to create adaptive and incremental data visualization. This way, farmers (sellers) can decide the way they want their data to be shown.
3 Toward Development of European Data Spaces
In February 2020, the European Commission announced the European Strategy for Data,Footnote 19 aiming at creating a single market for data to be shared and exchanged across sectors efficiently and securely within the EU. Behind this endeavor stands the Commission’s goal to get ahead with the European data economy in a way that fits European values of self-determination, privacy, and fair competition. For this to achieve, the rules of accessing and using data must be fair, clear, and practicable. This is especially important as the European data economy continues to grow rapidly—from 301 billion euros (2.4% of GDP) in 2018 to an estimated 829 billion euros (5.8% of GDP) by 2025.Footnote 20
The centerpiece of the European Data Strategy is the concept of “data spaces,” for which the Commission defined nine initial domains, all driven by sector-specific requirements. Actually, the Commission promotes the development of European data spaces for strategic economic sectors and public-interest domains, starting with the following nine: industrial (manufacturing), green deal, mobility, health, financial, energy, agriculture, public administration, and skills.
While data spaces stimulate higher availability of data pools, technical tools, and infrastructure addressing domain-specific challenges and legislations, the EU Strategy for Data acknowledges that these data spaces should be interconnected and that this challenge requires specific attention. But Europe doesn’t need to start from scratch—data sharing and exchange within specific domains and sectors is already happening in existing initiatives. However, each of these initiatives follows its own approach, and therefore they are not always interoperable.
Just like other electronic infrastructures (e.g., the Internet), data spaces basically are sector-agnostic, with many requirements and functions being similar or even identical across different sectors and data spaces. Therefore, creating the basis for data spaces primarily is not so much a technological challenge, as there are plenty of technical solutions and standards available. The main challenge toward interoperable data spaces is to agree on standards and design principles that are accepted by all participants. While making it work in pilot applications, proof of concepts, and living labs is relatively easy, the real challenge lies in the convergence of interoperability to new norms and allowing for mass adoption and scalability. Alignment with the CEF (Connecting Europe Facility) Digital programFootnote 21 would be highly desirable, since this program is precisely devoted to bring the building blocks for creating Digital Service Infrastructures in Europe.
GAIA-XFootnote 22 is aimed at creating a federated form of data infrastructure in Europe which strengthens the ability to both access and share data securely and confidently. Since its creation, the initiative has raised a lot of awareness because of the opportunity it brings to join forces and, leveraging existing assets, accelerate delivery of solutions to the market.
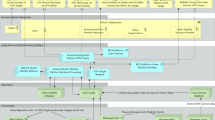
As explained earlier, IDSA is providing several architecture elements which are necessary to create data spaces with trust and data sovereignty being some of the most important ones. These are necessary but not sufficient to create real living data spaces which are accepted and adapted on the market. Standard APIs, standard data models, and marketplace functionalities are also necessary, and this is where the core strength of the FIWARE ecosystems lies. The complementarities of both initiatives are illustrated in Fig. 24.10. As the FIWARE Context Broker technology was adopted in 2019 as one of the Building Blocks of the Connecting Europe Facility (CEF) program and has proven to integrate smoothly with other relevant CEF Building Blocks for the creation of Data Spaces (e.g., eIDAS, EBSI), this would bring an opportunity of alignment with this important program. As a result, the close partnership between FIWARE and IDSA is guaranteeing the aligned contribution of both ecosystems to the success of data spaces based on GAIA-X.

IDSA and FIWARE positioning to create data spaces (©2021, FIWARE) (Labeling of a building block with the IDSA logo means that IDSA has produced or is working on specifications. Labeling with the FIWARE logo means that the FIWARE Community has produced open-source implementation of components and, eventually, is driving standardization activities. When both logos are present, an opportunity of collaboration has been identified linked to evolution of the specifications following an open-source implementation approach)
4 Conclusions
GAIA-X provides the opportunity to create a federated data infrastructure which is developed and established in a coordinated way, combining technological, functional, operational, and legal processes. This will strengthen the ability of Europe to both access and share data securely and confidently. Thus, it should be carried by the community of public and private stakeholders—and not by an individual keystone company, as we know it today from leading platform providers. FIWARE is bringing today mature technologies, compatible with IDS and CEF Building Blocks, which may accelerate the delivery of GAIA-X to the market. In addition, the FIWARE ecosystem has proven the ability to create standards in Europe which are accepted and adapted in the meantime on a global scale. Solution providers and end users in the Americas, Africa, India, or Asia are building their smart solutions based on FIWARE standards and technologies. With this, FIWARE became the global open-source-based standard, e.g., for the creation of Smart Cities. GAIA-X has the same potential to create solutions and to define standards based on a European value system which will be used also on a global scale.
Notes
- 1.
- 2.
- 3.
- 4.
- 5.
Github: https://github.com/smart-data-models; website: https://smartdatamodels.org/
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this chapter

Cite this chapter
Ahle, U., Hierro, J.J. (2022). FIWARE for Data Spaces. In: Otto, B., ten Hompel, M., Wrobel, S. (eds) Designing Data Spaces . Springer, Cham. https://doi.org/10.1007/978-3-030-93975-5_24
Download citation
DOI: https://doi.org/10.1007/978-3-030-93975-5_24
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-93974-8
Online ISBN: 978-3-030-93975-5
eBook Packages: Computer ScienceComputer Science (R0)