
Abstract
In deep neural networks, how to model the remote dependency on time or space has always been a problem for scholars. By aggregatingpioneering method of capturing remote dependencies. However, the NL network faces many problems; 1) For different query positions in the image, the long-range dependency modeled by the NL network is quite similar so that it’s a wates of computation cost to build pixel-level pairwise relations. 2) The NL network only focuses on capturing spatial-wise lo a ng-range dependencies and neglects channel-wise attention. Therefore, in response to thesquery-specific global context of each query location, Non-Local (NL) networks propose e problems, we propose the Channel and Position Squeeze Attention Module (CPSAM). Specifically, for a feature map of the middle layer, our module infers attention maps along channel and spatial dimensions in parallel. The Channel Squeeze Attention Module selectively joins the feature of different position by a query-independent feature map. Meanwhile, the Position Squeeze Attention Module uses both avg and max pooling to compress the spatial dimension and Integrate the correlation characteristics between all channel maps. Finally, the outputs of two attention modules are combine together through the conv layer to further enhance feature representation. We have achieved higher accuracy and fewer parameters on the cifar100 and ImageNet1k compared to the NL network. The code will be publicly available soon.
Supported by National Key Research and Development Program of China (Grant 2019YFC1521104), National Natural Science Foundation of China (Grant 61972157), Shanghai Municipal Science and Technology Major Project (Grant 2021SHZDZX0102), Shanghai Science and Technology Commission (Grant 21511101200), Art major project of National Social Science Fund (Grant I8ZD22)
Y. Gong, Z. Gu—Equal Contribution.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
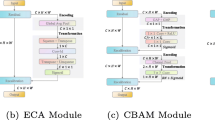

References
Bello, I., Zoph, B., Vaswani, A., Shlens, J., Le, Q.V.: Attention augmented convolutional networks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3286–3295 (2019)
Cao, Y., Xu, J., Lin, S., Wei, F., Hu, H.: GCNet: non-local networks meet squeeze-excitation networks and beyond. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (2019)
Chen, Y., et al.: Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3435–3444 (2019)
Chen, Y., Kalantidis, Y., Li, J., Yan, S., Feng, J.: \(a^{\wedge }2\)-nets: double attention networks. arXiv preprint arXiv:1810.11579 (2018)
Chi, L., Yuan, Z., Mu, Y., Wang, C.: Non-local neural networks with grouped bilinear attentional transforms. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11804–11813 (2020)
Chollet, F.: Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1251–1258 (2017)
Dai, J., et al.: Deformable convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 764–773 (2017)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255. IEEE (2009)
DeVries, T., Taylor, G.W.: Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552 (2017)
Ding, X., Zhang, X., Ma, N., Han, J., Ding, G., Sun, J.: RepVGG: making VGG-style convnets great again. arXiv preprint arXiv:2101.03697 (2021)
Fu, J., et al.: Dual attention network for scene segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3146–3154 (2019)
Gao, Z., Xie, J., Wang, Q., Li, P.: Global second-order pooling convolutional networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3024–3033 (2019)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Hou, Q., Zhang, L., Cheng, M.M., Feng, J.: Strip pooling: rethinking spatial pooling for scene parsing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4003–4012 (2020)
Hou, Q., Zhou, D., Feng, J.: Coordinate attention for efficient mobile network design. arXiv preprint arXiv:2103.02907 (2021)
Hu, J., Shen, L., Albanie, S., Sun, G., Vedaldi, A.: Gather-Excite: exploiting feature context in convolutional neural networks. arXiv preprint arXiv:1810.12348 (2018)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7132–7141 (2018)
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4700–4708 (2017)
Huang, Z., Wang, X., Huang, L., Huang, C., Wei, Y., Liu, W.: CCNet: criss-cross attention for semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 603–612 (2019)
Lee, H., Kim, H.E., Nam, H.: SRM: a style-based recalibration module for convolutional neural networks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1854–1862 (2019)
Liu, J.J., Hou, Q., Cheng, M.M., Wang, C., Feng, J.: Improving convolutional networks with self-calibrated convolutions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10096–10105 (2020)
Torralba, A., Fergus, R., Freeman, W.T.: 80 million tiny images: a large data set for nonparametric object and scene recognition. IEEE Trans. Patt. Anal. Mach. Intell. 30(11), 1958–1970 (2008)
Tsotsos, J.K.: A Computational Perspective on Visual Attention. MIT Press, Cambridge (2011)
Tsotsos, J.K., et al.: Analyzing vision at the complexity level. Behav. Brain Sci. 13(3), 423–469 (1990)
Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7794–7803 (2018)
Woo, S., Park, J., Lee, J.Y., Kweon, I.S.: CBAM: convolutional block attention module. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 3–19 (2018)
Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K.: Aggregated residual transformations for deep neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1492–1500 (2017)
Yue, K., Sun, M., Yuan, Y., Zhou, F., Ding, E., Xu, F.: Compact generalized non-local network. arXiv preprint arXiv:1810.13125 (2018)
Zeiler, M.D., Fergus, R.: Visualizing and understanding convolutional networks. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8689, pp. 818–833. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10590-1_53
Zhu, X., Hu, H., Lin, S., Dai, J.: Deformable ConvNets v2: more deformable, better results. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9308–9316 (2019)
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Gong, Y., Gu, Z., Zhang, Z., Ma, L. (2021). CPSAM: Channel and Position Squeeze Attention Module. In: Mantoro, T., Lee, M., Ayu, M.A., Wong, K.W., Hidayanto, A.N. (eds) Neural Information Processing. ICONIP 2021. Lecture Notes in Computer Science(), vol 13108. Springer, Cham. https://doi.org/10.1007/978-3-030-92185-9_16
Download citation
DOI: https://doi.org/10.1007/978-3-030-92185-9_16
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-92184-2
Online ISBN: 978-3-030-92185-9
eBook Packages: Computer ScienceComputer Science (R0)