
Abstract
One of the most commonly used techniques for validating Land Use Cover (LUC) maps are the accuracy assessment statistics derived from the cross-tabulation matrix. However, although these accuracy metrics are applied to spatial data, this does not mean that they produce spatial results. The overall, user’s and producer’s accuracy metrics provide global information for the entire area analysed, but shed no light on possible variations in accuracy at different points within this area, a shortcoming that has been widely criticized. To address this issue, a series of techniques have been developed to integrate a spatial component into these accuracy assessment statistics for the analysis and validation of LUC maps. Geographically Weighted Regression (GWR) is a local technique for estimating the relationship between a dependent variable with respect to one or more independent variables or explanatory factors. However, unlike traditional regression techniques, it considers the distance between data points when estimating the coefficients of the regression points using a moving window. Hence, it assumes that geographic data are non-stationary i.e., they vary over space. Geographically weighted methods provide a non-stationary analysis, which can reveal the spatial relationships between reference data obtained from a LUC map and classified data. Specifically, logistic GWR is used in this chapter to estimate the accuracy of each LUC data point, so allowing us to observe the spatial variation in overall, user’s and producer’s accuracies. A specific tool (Local accuracy assessment statistics) was specially developed for this practical exercise, aimed at validating a Land Use Cover map. The Marqués de Comillas region was selected as the study area for implementing this tool and demonstrating its applicability. For the calculation of the user’s and producer’s accuracy metrics, we selected the tropical rain forest category [50] as an example. Furthermore, a series of maps were obtained by interpolating the results of the tool, so enabling a visual interpretation and a description of the spatial distribution of error and accuracy.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
1 Overall, User’s and Producer’s Accuracy Through GWR
Description
Overall accuracy (OA), user’s accuracy (UA) and producer’s accuracy (PA) are assessment metrics obtained from the cross-tabulation matrix (see Sect. 5 in chapter “Metrics Based on a Cross-Tabulation Matrix to Validate Land Use Cover Maps”). Overall accuracy is expressed as the proportion of the map that has been correctly classified. User’s accuracy indicates the probability that a pixel from a specific category on the classified map correctly represents the real situation on the ground or reference map. Producer’s accuracy indicates the probability that a reference pixel belonging to a specific category has been correctly allocated to that category (Story and Congalton 1986). These last two metrics (user’s and producer’s accuracies) refer to commission and omission errors, respectively.
None of these accuracy assessment statistics produces spatially distributed information, i.e., they provide a single accuracy value for the entire study area or for each land use/land cover class. However, it is possible to explore how the error and accuracy of a classified map is spatially distributed with respect to reference data using Geographically Weighted Regression (GWR) methods.
GWR allow us to explore local spatial relationships between a dependent variable and a set of explanatory variables (Brunsdon et al. 1996; Fotheringham et al. 2002). In this chapter, we use the logistics version of the geographical weighting method (GWLR) to generate land use/land cover accuracy metrics with spatial variation, according to the proposal by Comber (2013), which was later developed in Comber et al. (2012), Comber et al. (2017) and Tsutsumida and Comber (2015).
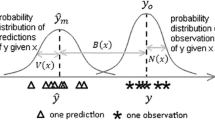
GWR is a statistical technique in which regression points are estimated on the basis of the spatial distribution of data points. A moving window analyses the data points it collects to estimate the coefficients of the selected regression point. This window, or kernel, weights each data point according to the distance within the window and the assigned weighting function (gaussian, exponential, bisquare, tricube, boxcar). Its maximum weighting value is 1 and this decreases as the distance between the observation and calibration data points increases. The size of the kernel is defined by the bandwidth, which indicates the number of data points that will be included in the local calculation for each regression point. This can consider either a fixed or a variable number of reference data points. If a fixed number of points are considered, a specific number will be obtained, while in the case of a variable number, a distance value is given. The number of reference data points therefore varies according to their distribution. It is important to select a suitable bandwidth so as to minimise the cross-validation prediction error. According to Fotheringham et al. (2002), the GWR formula is
where \({\beta }_{0}\) is the intercept, \({\beta }_{n}\) is the coefficient, \({x}_{n}\) is the value of the explanatory variable, and \({u}_{i}, {v}_{i}\) are the coordinates of the data point (Fig. 1).

Spatial kernel. Regression point, data points and bandwidth are observed. The curve represents the Gaussian function that establishes the weighting of the data points for the regression point. Retrieved from Fotheringham et al. (2002)
This geographically weighted method was adapted for the calculation of local accuracy assessment statistics by Comber (2013). According to his proposal, the probability that a reference data point is correctly identified by a classified data point is given by
where P(A = 1) is the probability that the agreement between the classified data and the reference data is equal to 1. This value is 0 when there is no agreement and 1 when there is agreement.
To estimate user’s accuracy, it is necessary to analyse the reference data against the classified data. This metric indicates the probability that the reference LUC class \({y}_{i}\) and is correctly predicted by the classified data \({x}_{i}\).
To estimate producer’s accuracy, it is necessary to analyse the classified data against reference data. This indicates the probability that the classified data \({x}_{i}\) correctly represents reference LUC class \({y}_{i}\).
Finally, in order to obtain the accuracy values, the coefficients have to be adjusted. To this end, the coefficients are added together, and an alogit function (inverse logit) is applied.
Utility
Exercises | |
|---|---|
1. To validate a map against reference data/map |
Geographically Weighted methods can be used to validate single LUC maps by analysing spatial variations in the agreement between reference data and classified remotely sensed data, so enabling us to analyse the spatial non-stationarity of LUC data error and accuracy. They allow to explore the spatial relationships between the reference data and the classified data, exposing possible clusters of land cover errors, and reporting the values for each data point in contrast to global accuracy assessment statistics, which only provide a global value for the entire map.
This technique allows us not only to discover what proportion of the map has been correctly classified but also to estimate in which areas the classification fits best and to analyse possible trends that are only visible spatially. In this way, the spatial distribution of the overall, user’s and producer’s accuracy metrics can be visualized on a map so as to enable a better understanding of classification uncertainty.
QGIS Exercise
Available tools | |
|---|---|
▪ Processing Toolbox R Geographically weighted methods Local accuracy assessment statistics Interpolation IDW Interpolation GDAL Raster extraction Clip raster by mask layer |
By default, there are no tools in QGIS that carry out a Geographically Weighted Methods analysis to estimate overall, user’s and producer’s accuracy values for local areas. We have therefore developed an R tool to calculate these local accuracy assessment metrics in QGIS, in which Geographically Weighted Methods are already implemented.
The Local accuracy assessment statistics script is based on the code developed by Professor Alexis J. Comber from the University of Leicester,Footnote 1 which was created using above all the “spgwr” R package.Footnote 2 The script provides overall, user’s and producer’s accuracy values for each data point, so allowing accuracy and error distribution areas to be generated by interpolation of the results obtained by the tool.
First, to estimate local OA values, the tool calculates internally, for each data point, the agreement between the reference data and the classified data, where 0 represents disagreement and 1 represents agreement. Agreement is automatically selected as dependent variable [y] and “1” is selected as independent variable [x], where P(A = 1) is the probability that agreement is equal to 1.
To estimate local UA values, the tool generates a new data frame and obtains two columns. One column shows the presence (1)/absence (0) of the chosen category for the reference data, while the other column shows the same for the classified data. The reference data (RD) is selected as dependent variable [y], and the classified data (CD) is selected as independent variable [x], where P(RD = 1|CD = 1). The procedure for producer’s accuracy is very similar. The classified data for the chosen category is selected as dependent variable [y], and the reference data is selected as independent variable [x], where P(CD = 1|RD = 1).
In order to ensure that the tool works correctly, various parameters must be configured. Selecting an appropriate bandwidth is therefore crucial. A small bandwidth would include too few data points in the local sample, making it unreliable for calibrating the model, while a large bandwidth would include too many data points, so reducing the local analysis capacity. A spatially distributed data sample is also required.
The fact that the parameters must be configured and the need for more in-depth knowledge to interpret the results could be considered a disadvantage when choosing these validation methods. Another important consideration is that using large data samples can lead to long runtimes.
Exercise 1. To validate a map against reference data/map
Aim
To assess the spatial variation of accuracy assessment measures (overall, user’s and producer’s accuracy) when validating the Marqués de Comillas LUC map against a reference set of points.
Materials
Marqués de Comillas random sample points from Mexico (2019)
Boundary of Marques de Comillas
Requisites
The data points must be projected in their corresponding reference system. The vector point file must include two attributes, one corresponding to reference LUC data and one to classified LUC data. It is recommended that the data points have an appropriate random distribution. Sample size should not be overly large, as this could lead to long runtimes.
Execution
If necessary, install the Processing R provider plugin, and download the Local accuracy assessment statistics.rsx R script into the R scripts folder (processing/ rscripts). For more details, see chapter “About This Book” of this book.
Step 1
Open the Local accuracy assessment statistics function and fill in the required parameters (see Fig. 2). The input for this tool is the point layer containing the LUC random sample dataset. Select the type of accuracy assessment statistic to be obtained (“Overall”), and indicate the corresponding attribute table columns with the reference data and the classified data. The category can also be indicated, although this is only used to estimate the user’s and producer’s accuracy values. The remaining value to be set is the bandwidth, which in this exercise is 0.15. This means that 15% of the nearest neighbours will be used to estimate the coefficient for each regression point. The kernel is set internally in the tool by default with a Gaussian function.

Excersice 1. Step 1. Local accuracy assessment statistics (Overall accuracy)
Step 2
The parameter configuration for calculating User’s Accuracy is very similar. Select the corresponding accuracy assessment statistic in the “Accuracy” option (“User”) and the category you want to assess in the “Category” option, (see Fig. 3). In this exercise, we will be using the tropical rain forest class [50] as an example.

Excersice 1. Step 2. Local accuracy assessment statistics (User's accuracy)
Step 3
To estimate the producer’s accuracy values, the same steps must be followed (see Fig. 4). Select the corresponding accuracy assessment statistic (“Producer”), and the tool will modify the internal inputs. The tropical rain forest class [50] will again be used as an example.

Excersice 1. Step 3. Local accuracy assessment statistics (Producer's accuracy)
Step 4
Finally, the coefficients adjusted by the Local accuracy assessment statistics tool were interpolated using the Inverse Distance Weighted method (IDW interpolation tool in QGIS) (see Fig. 5) to obtain a map showing the continuous variation in the spatial distribution of the accuracy measures, and to facilitate understanding in a more visual manner.

Excersice 1. Step 4. IDW Interpolation
The names of the column or attribute obtained as a result of applying the tool and indicating the local overall, user’s and producer’s accuracy values are “g__SDF_”, “coefs_u” and “coefs_p” respectively. This column must be specified in the “Interpolation attribute” option in line with the accuracy metric being analysed.
Step 5
As an additional, optional step, the raster images obtained by interpolation can be clipped by mask using the Marques de Comillas boundary (Clip raster by mask layer tool in QGIS) in order to provide a better visual representation. In addition, a discrete colour scale using six classes was chosen in order to make interpretation of the data more straightforward.
Results and Comments
After the execution of the previous steps, we obtain a new attribute column with the estimated local values for OA, UA and PA respectively, and the interpolated distribution maps for these accuracy measures. Another output of the tool is a new layer that includes the estimated Overall Accuracy value for each data point. In addition, a summary of the local and overall values calculated is displayed in the log window (Fig. 6). It shows the minimum, first quantile, median, mean, third quartile, maximum and global overall accuracy values (Table 1).

Results from Exercise 1 displayed in the "output" window of the "Local accuracy assessment statistics" showing variations in overall accuracy
The IDW interpolation method is used to generate an area that visually represents the distribution of the values obtained, offering a more detailed spatial representation of the distribution of accuracy and error than that provided by a single overall accuracy value. Figure 7 clearly shows a higher degree of accuracy in the north of the map, which decreases as it moves south and east.

Results from Exercise 1. Map showing the spatial distribution of overall accuracy values
The example category in this exercise is tropical rain forest (code 50). User’s accuracy describes the commission errors in the tropical rain forest category. Its values range between 0.55 and 0.87, with a variation of 0.32, despite the overall value for the entire study area of 0.74 (Fig. 8).

Results from Exercise 1 displayed in the "output" window of the "Local accuracy assessment statistics" showing variations in user's accuracy
Figure 9 represents the probability that a classified data point belonging to the tropical rain forest class is correctly represented by the reference data (User’s accuracy). Values are high through the centre and south of the region, but fall as we move away to the northeast.

Result from Exercise 1. Map showing the spatial distribution of user's accuracy values
The last part of this exercise focuses on Producer’s Accuracy. In this case, it describes omission errors related to the tropical rain forest class. User’s accuracy varies from 0.56 to 0.89 (variation of 0.33), despite the global value for the entire area of 0.74 (Fig. 10).

Results from Exercise 1 displayed in the "output" window of the "Local accuracy assessment statistics" showing variations in producer's accuracy
Figure 11 represents the probability that any reference data point is correctly classified (producer’s accuracy). Most of the omission errors are concentrated in the north-east of our study area, while higher levels of producer’s accuracy can be seen in the south-west.

Result from Exercise 1. Map showing the spatial distribution of producer's accuracy values
The values set out in Figs. 6, 8 and 10 are summarized in Table 1, which shows the variations in the accuracy of the classified data points with respect to the reference data points. The Overall accuracy value for the entire study area is 0.80. Nonetheless, it has been demonstrated that OA varies over space. The minimum value is 0.77 and the maximum is 0.84, which means that a variation of 0.07 is observed.
Producer’s accuracy has the highest range of variation, with User’s accuracy close behind. By contrast, Overall accuracy has a relatively small range, indicating low levels of spatial variation. Despite this, the maximum Overall accuracy value (0.84) is below the value proposed by Anderson (1971).
In conclusion, Local accuracy assessment statistics should be considered as a useful complement to the cross-tabulation matrix and its global accuracy statistics in that they provide more detailed information that can help improve classification techniques by locating possible error clusters with greater precision. It is also important to stress that a visual interpretation can enable better decisions to be taken when evaluating and validating LUC maps.
Notes
- 1.
The code is available at the personal repository of Professor Alexis J. Comber. https://github.com/lexcomber/AccuracyWorkshop2016.
- 2.
Full details of this R package and the functions it includes, may be found at https://cran.r-project.org/web/packages/spgwr/spgwr.pdf.
References
Brunsdon C, Fotheringham AS, Charlton ME (1996) Geographically weighted regression: a method for exploring spatial nonstationarity. Geogr Anal 28(4):281–298
Comber AJ (2013) Geographically weighted methods for estimating local surfaces of overall, user and producer accuracies. Remote Sens Lett 4(4):373–380. https://doi.org/10.1080/2150704X.2012.736694
Comber A, Fisher P, Brunsdon C, Khmag A (2012) Spatial analysis of remote sensing image classification accuracy. Remote Sens Environ 127:237–246. https://doi.org/10.1016/j.rse.2012.09.005
Comber A, Brunsdon C, Charlton M, Harris P (2017) Geographically weighted correspondence matrices for local error reporting and change analyses: mapping the spatial distribution of errors and change. Remote Sens Lett 8(3):234–243. https://doi.org/10.1080/2150704X.2016.1258126
Story M, Congalton RG (1986) Accuracy assessment: a user’s perspective. Photogramm Eng Remote Sens 52:397–399
Tsutsumida N, Comber AJ (2015) Measures of spatio-temporal accuracy for time series land cover data. Int J Appl Earth Obs Geoinf 41:46–55. https://doi.org/10.1016/j.jag.2015.04.018
Fotheringham AS, Brunsdon C, Charlton M (2002) Geographically weighted regression. The analysis of spatially varying relationships. In: Fotheringham AS, Brunsdon C, Charlton M (eds) Wiley
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this chapter

Cite this chapter
Molinero-Parejo, R. (2022). Geographically Weighted Methods to Validate Land Use Cover Maps. In: García-Álvarez, D., Camacho Olmedo, M.T., Paegelow, M., Mas, J.F. (eds) Land Use Cover Datasets and Validation Tools. Springer, Cham. https://doi.org/10.1007/978-3-030-90998-7_13
Download citation
DOI: https://doi.org/10.1007/978-3-030-90998-7_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-90997-0
Online ISBN: 978-3-030-90998-7
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)