
Abstract
The spread of demand-response (DR) programs in Europe is a slow but steady process to optimize the use of renewable energy in different sectors including manufacturing. A demand-response program promotes changes of electricity consumption patterns at the end consumer side to match the availability of renewable energy sources through price changes or incentives. This research develops a system that aims to engage manufacturing power consumers through price- and incentive-based DR programs. The system works on data from heterogeneous systems at both supply and demand sides, which are linked through a semantic middleware, instead of centralized data integration. An ontology is used as the integration information model of the semantic middleware. This chapter explains the concept of constructing the ontology by utilizing relational database to ontology mapping techniques, reusing existing ontologies such as OpenADR, SSN, SAREF, etc., and applying ontology alignment methods. Machine learning approaches are developed to forecast both the power generated from renewable energy sources and the power demanded by manufacturing consumers based on their processes. The forecasts are the groundworks to calculate the dynamic electricity price introduced for the DR program. This chapter presents different neural network architectures and compares the experiment results. We compare the results of Deep Neural Network (DNN), Long Short-Term Memory Network (LSTM), Convolutional Neural Network (CNN), and Hybrid architectures. This chapter focuses on the initial phase of the research where we focus on the ontology development method and machine learning experiments using power generation datasets.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others

1 Introduction
With the energy transition in Europe toward renewable but irregular resources underway, the need for energy flexibility to balance the weather-dependent energy generation is also increasing. Above all, local energy flexibility, which considers local or own energy generation, plays a decisive role. The Energy Union Framework of the European Union outlines the vision that end users actively participate in the market and benefit from technological progress in the form of cost reductions (Energy Union Package 2015). In order to improve the quality of service, the active participation of end customers is increasingly coming to the foreground. As positive effects, competition will be strengthened, more renewable energy sources will be integrated, and energy networks will be more balanced. This will ensure an efficient operation of the energy systems.
As a prerequisite for this, the majority of energy consumers must be willing to participate actively in demand-response programs (Siano 2014). According to the U.S. Department of Energy (DoE), demand response (DR) refers to Qdr (2006)
changes in electric usage by end-use customers from their normal consumption patterns in response to changes in the price of electricity over time, or to incentive payments designed to induce lower electricity use at times of high wholesale market prices or when system reliability is jeopardized.
Demand-response programs can be implemented as price-based or incentive-based programs (Chen and Liu 2017). Price-based programs imply the introduction of dynamic energy tariffs and dynamic demand profiles adapted to changing conditions. Incentive-based programs, on the other hand, require consumers to hand over direct control of their energy systems to third parties for the purpose of modifying the demand profile, if exceptional circumstances in the network should require this.
The modification of consumer demand for energy using methods, such as financial incentives, is known as demand-side management (DSM). DR is a subset of DSM. One objective of DSM is to encourage the consumer to reduce the usage of energy during peak periods or to store energy during off-peak hours using energy storage units. As an application, DSM helps grid operators to provide a balance between renewable generation units such as wind and solar. Due to increasing electricity demand and installation of renewable energy sources, DSM is applied for managing system behavior (Chiu et al. 2012). Therefore, DR systems can be used to attain a balance between the demand and supply in the power grid (Yassine 2016).
The dissemination of demand-response programs in Europe is a slow but steady process. As recently as 2013, European end customers were not very open to DR systems, mainly due to regulatory and legislative barriers. Today, consumers have far more opportunities to participate in demand-response programs in different member states (Bertoldi et al. 2016). Unfortunately, Germany is lagging behind other countries in this area, although demand-response services are being developed in some research. This is due to the doubt of the effectiveness of DR to guarantee energy security and to attract investments (Lehmann et al. 2015; Valdes et al. 2019). Furthermore, critical policy debates on the implementation of DR still exist. The governance needed to relate demand-side response and local energy markets is also still lacking (Kuzemko et al. 2017).
Although some legislative barriers have been dismantled and some aggregators in Europe are installing DR systems in tertiary buildings, the desired effects on the energy grid as a whole have not yet materialized. In Germany, both large industrial consumers and households remain largely unaffected by DR.
Our research project addresses this problem and develops a solution for the participation of industrial end customers in both price- and incentive-based DR programs. The research investigates the influence of such programs on the electrical grid and on the development of energy costs in the manufacturing industry, from different perspectives. This book chapter describes the development of the project’s technological solution that allows the implementation of a DR system. The solution uses a semantic middleware that utilizes a linked data approach to connect data sources coming from heterogeneous systems involved at demand and supply sides. This book chapter also explains the development of the forecasting methods to estimate the amount of electricity supply from renewable sources in the network and also the amount of electricity demand from manufacturing companies. The forecasts are used as the foundation to calculate the dynamic electricity tariffs.
Section 2 of this book chapter focuses on the related works in using ontologies or linked data for the integration of data from heterogeneous sources on semantic level and in forecasting methods in energy domain. Section 3 describes the overview of the technical concept that we develop in the project. Then, Sect. 4 shows the method to develop the ontology as the core of the semantic middleware. The methods, the dataset, and some intermediate experiment results of the forecasting are discussed in Sect. 5. Finally, the book chapter ends with conclusions and outlook.
2 Related Works
2.1 Ontologies and Linked Data
Semantic technologies, such as the graph-based data model called Resource Description Framework (RDF) (Lassila et al. 1998) and linked data principles (Bizer et al. 2011) from the Web, facilitate automated information integration. Ontologies provide vocabularies and relation models to make data semantically compatible; thus they can be linked without causing inconsistencies and ambiguities.
Ontology-based information models have been used to facilitate data integration on semantic level, for example to model objects involved in manufacturing and supply chain sustainability (Borsato 2017). In the manufacturing domain, ontologies can model the relationships between products, processes, resources, and environmental factors contributing to energy efficiency (Wicaksono et al. 2014). Ontologies also facilitate virtual collaborations in assembly automation (Ferrer et al. 2015). The AutomationML ontology is used to enable the communication of heterogeneous tools in engineering environments, such as in manufacturing (Kovalenko and Grangel-Gonzalez 2021).
In the energy management domain, ontologies have been developed to allow a common semantic data model to address interoperability problems among involved building automation systems (Wicaksono et al. 2013, 2010). They are also used to enable the interoperability among Internet-of-Things solutions in general (Alaya et al. 2015; Daniele et al. 2015; Haller et al. 2019) and for energy management applications (Cuenca et al. 2017; Daniele 2021; Kofler et al. 2012). Industry Foundation Classes (IFC) refer to a standard information model allowing exchanges of building data. ifcOWL is the ontology representation of IFC (Pauwels and Terkaj 2016). Researchers also develop ontologies to support the energy transition, for example, to model renewable energy sources (Küçük and Küçük 2018) and smart grid objects (Stap and Daniele 2021).
Open Automated Demand Response (OpenADR) is a standardized information model for sending and receiving DR signals between network operators and consumers (Fernández-Izquierdo et al. 2020). It is implemented as a client–server architecture. Virtual End Nodes (VEN) refer to the clients and Virtual Top Nodes (VTN) are the servers. The DR signals received in the client can trigger preprogrammed actions according to their tasks and thus establish an automated demand response for each resource considered. OpenADR is open source and can therefore be implemented by any user. Since electricity prices generally correlate negatively with electricity availability, consumers can specifically control their consumption away from high price periods and significantly reduce their own energy costs.
In this research, we investigate the scopes of ontologies that are relevant for demand-response systems. We analyze those ontologies based on data requirements at both supply and demand side. Table 1 shows the domain scope of the analyzed ontologies. From the table, it can be seen that no ontology is able to fulfill the data requirements in all domains. Therefore, we develop a linked data approach to interlink those ontologies.
2.2 Machine Learning and Forecasting Methods
The fields of machine learning and artificial intelligence have undergone rapid growth in the last decade, changing the way humans interact with data, especially in the use of data for decision-making. Data-driven decision-making has thus grown in the fields of physical sciences and social sciences, influencing various aspects of daily human life. A huge part of data-driven decision-making entails the need to forecast future behavior of a system or trend of a series based on historical time-series data. Therefore, time-series forecasting has become a crucial method implemented across many domains, where different windows of time series representing past behaviors are utilized to forecast future behaviors.
Existing methods for time-series forecasting can roughly be mapped into two categories, i.e., classical methods that focus on learning linear relationships and machine learning/deep learning methods that generalize complex non-linear relationships. Classical time-series models such as Exponential Smoothing, Autoregression, and Moving Average have easy interpretability and strong theoretical assurance. Simple variations of classical models, such as Autoregressive Moving Average (ARMA) and Autoregressive Integrated Moving Average (ARIMA), have also been established as reliable methods for time-series forecasting. More complex extensions of these methods, which include variations with integration of seasonality: Seasonal Autoregressive Integrated Moving Average (SARIMA), and integration of vectorized multiple inputs: Vector Autoregression (VAR) and Vector Autoregression Moving Average (VARMA), further provide flexibility in adding complex relations in the forecasting and models. Novel extensions of these methods also support handling missing data and multiple data types (Seeger et al. 2016).
Machine learning/deep learning methods aim to learn a non-linear function mapping of stochastic historic input data to a predicted/forecasted output value. Methods such as Support Vector Regression (SVR) (Zafirakis et al. 2019; Lahouar and Slama 2017), Random Forest (RF) (Li and Shi 2010; Sun et al. 2018), and Artificial Neural Network (ANN) (Jiao et al. 2018; Olaofe and Folly 2013) are the simplest existing techniques that have shown abilities in learning these non-linear functions. Extending the ANN models to have recurrent hidden layers (RNN) that capture and preserve the relationship of a new input with previous inputs achieved ground-breaking performance in sequence learning. Improved variants of RNN, i.e., Long Short-Term Memory (LSTM) and Grated Recurrent Unit (GRU), (Liu et al. 2019; Niu et al. 2020) have also shown great potential in learning complex relationships present in stochastic historic input data for time-series forecasting. As one of the most popular deep learning methods, Convolutional Neuron Network (CNN) has not only been utilized to extract visual features in problems of computer vision and natural language processing (NLP), but is also used in feature selectors and predictors for wind speed/power forecasting. The work of Liu et al. (2019) introduced a 1D CNN-based forecasting model for direct multi-steps ahead prediction for short-term wind speed data, which outperformed other classical and baseline ANN methods. Wang et al. (2019) used 2D CNN to efficiently extract the non-linear features of the raw wind power data, which shows better accuracy in probabilistic forecasting.
Alongside the development of forecasting methods, research works have increased in forecasting both electricity generation (Wang et al. 2019) and consumption for industrial and household consumers (Hong et al. 2020). Most of the recent research works on electricity generation focus on production of green energy from wind and solar plants (Liu et al. 2019; Wang et al. 2019). On the consumption side, research is driven by optimizing energy efficiency, which also requires constant monitoring of various consumption indicators and identifying factors that affect them in real time (Hong et al. 2020). Weather conditions are identified as the main factor determining the production of green energy and the demand for electricity. Additional independent factors, such as holidays, operational characteristics of buildings, and indicators of living standards, are also identified to influence the demand (Hong et al. 2020; Kalimoldayev et al. 2020). These advancements in forecast form the basis to drive research work on dynamic pricing of electricity and implementing DR systems (Kalimoldayev et al. 2020). The influence of DR systems has also been evaluated with the use of deep learning methods. Micro-grid demand-response systems have shown high potential in not only helping consumers reduce their energy bills, but also help in improving grid stability and reliability (Shojaeighadikolaei et al. 2021).
Therefore, forecasting is seen as a fundamental aspect of planning and management, and the design of a dynamic price system requires forecasting of future supply and demand (Dutta and Mitra 2017). Further, scheduling of actual consumption would also require forecasts of future prices. Therefore, it is identifiable that an initial step toward building a price system is to have a strong forecasting method. And the potential that deep learning shows in mapping relations in data for forecasting makes exploring the deep learning method an important initial step. Thus, experimental works are done in our research to create baseline forecasting methods using deep learning. Details of the experimental works are discussed in Sect. 5. Table 2 shows different existing research works related to forecasting methods, especially in terms of renewable energy. We reviewed the works by analyzing the algorithms used or developed, whether the input data is multivariate or not, the frequency of the input data points, and the forecast horizon.
3 Overview of the Concept
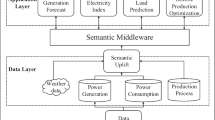
The architecture of the solution is based on the reference architecture for the smart grid developed by the EU Smart Grid Coordination Group/Reference Architecture Working Group (SG-CG/RA) (Gottschalk et al. 2017) (see Fig. 1). The core of the architecture is the semantic middleware. This is a software module with an ontology for the integration of heterogeneous information models, which are defined by standards from different subject areas (e.g., OpenADR, IFC, SAREF, PPR model). A method for mapping between the DR communication standards and the ontologies is developed for the semantic middleware to enable automatic data routing. Using the linked data approach, the heterogeneous information models shown in Table 1 are semantically linked. The adapter serves as a communication interface between various systems supplying the data. The adapter contains an HTTP/HTTPS interface and a software module for data format conversion. The applications of the energy supply and demand sides use the semantic middleware to automatically collect the data required for their functionalities. An intelligent mapping and routing algorithm is developed to capture the appropriate data from the right data sources.

Overview of the solution
In our research, data are collected from heterogeneous sources. Those data include power generation, power consumption, weather, customer, balancing group, industrial automation, and manufacturing process data. We develop a continuous intelligent analysis based on this data, i.e., descriptive data analysis for monitoring, predictive analysis to generate the forecast model of electricity supply and demand, prescriptive analysis through simulation and optimization to determine the dynamic electricity prices, as well as the visualization of the data to support the analysis. This continuous data analysis makes the determination of the dynamic electricity prices more precise and transparent. This will happen on the utility side. The end-to-end intelligent data analyses are also used on the consumption side. Load profiles of the production processes are recorded based on electricity demand measurements at the systems involved in the production process, and connections between production orders and the associated electricity demand are created using machine learning methods. These findings are then used to generate electricity demand forecasts depending on the production plan. Heuristics are developed to enable electricity cost-optimized production planning and control. DR requirements are also explicitly considered.
The concepts will be examined in the context of two use cases, i.e., at a rubber component manufacturer and at a manufacturing company having a high degree of automation. Two different perspectives are considered in each use case: the technical and the economic feasibility. The use case at the rubber component manufacturer focuses on the development and integration of the hardware required to implement demand-response requirements. The use case of the second company builds on existing sensors and develops simulation models for the optimization of production by exchanging energy data with the market. Those companies have different requirements for market mechanisms and negotiation strategies, which are analyzed within the scope of our research.
The following sections focus on the development of the ontology for the semantic middleware and the methods to forecast power generation and consumption as the initial phase of end-to-end intelligent data analysis. Since the project is still in the early phase, in this book chapter, we only concentrate on the development and experiments of forecasting for wind and solar power generation. However, the developed methods can be applied to the forecast of power generation from other types of renewable sources and also to the forecast of power consumption.
4 Ontology Development
4.1 Ontology Construction Methodology
In this research, to represent a sharable and reusable knowledge as a set of concepts within the domain and to describe their relationships, ontologies as a part of the W3C standards stack for the Semantic Web are applied. They provide a link between different pieces of information from different domains. Ontologies are also used to enhance knowledge and data exchange in these domains.
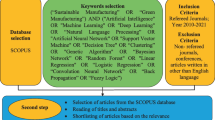
To achieve this goal, we adapt an ontology construction method toward data integration through linked data developed for building energy management domain (McGlinn et al. 2016). The adaptation of the method is shown in Fig. 2. First, we define data requirements and the mapping of those data to appropriate ontologies. Then, the method of systematic review is applied with the purpose of identifying and extracting ontologies and analyzing the potential links between them in the following specific fields: demand response, sensor networks, renewable energy, and manufacturing. The following sections explain the steps carried out in the method in detail.

Ontology development
Step 1: Data Requirements
Step 1 analyzes the specific data requirements for each process in the system in more detail. The purpose of this step is to understand the exact structure of the data required to meet the use cases or functionalities of the system. All data values that are required must be captured and described. This involves structuring the data as concepts and properties.
Step 2: Ontology Domains Finding and Extracting
The purpose of this step is to provide a quick reference to ontologies related to demand-response systems and select the best of them for a particular domain (step 2a). These ontology domains are extracted and presented here. The next step is to explore and find potential links between ontologies in the abovementioned categories (step 2b and 2c).
Step 3: Develop Ontology
Step 3 is concerned with the development of models for meeting the data requirements, which are not currently supported by any existing ontologies or standards.
Step 4: Define Links
Step 4 is concerned with the definition of links between ontologies, since multiple ontologies are required to meet the data requirements. At this stage, the mappings and alignments must be identified and formalized.
4.2 Database to Ontology Mapping
In our project, we collect data from different sources. Those data can be in relational databases, CSV files, or XML formats. A relational database is commonly used in modern applications for storing and querying data and enables the organization of data points and identifies their relationships. Since an ontology provides formal semantics for the data explicitly, to describe the semantics of data stored in a database, the database schemas should be converted into semantically equivalent ontologies. Mapping rules are applied for converting relational databases into ontology. The database to ontology mapping is located in the adapter (see Fig. 1). We develop the database to ontology mapping by considering the works described in Mahria et al. (2021), Hazber et al. (2015).
4.3 Ontology Alignment
Since we consider multiple ontologies to fulfill the data requirements, we develop ontology alignment methods to interlink the ontologies. An ontology alignment is an ontology matching process to provide a set of correspondences between semantically related ontology concepts for two input ontologies (one source ontology and one target ontology). These semantic relationships are called mappings. To determine the mapping, we find similarities between the entities of semantically related ontologies. As an important task, ontology alignment allows the joint consideration of resources described by different ontologies. Ontology alignment is used to solve different problems of semantic heterogeneity in the integration and sharing of information. We apply multiple ontology alignment approaches that are based on lexical, structural, extensional, and semantic techniques (Ouali et al. 2019; Xie et al. 2016).
A lexical method is based on the comparison of terms, strings, or texts. But structural methods calculate the similarity between two entities by exploiting structural information within semantic or syntactic links, which form a hierarchy. Extensional methods infer the similarity between two entities by analyzing their extensions (i.e., their instances). Finally, semantic methods are based on the external ontologies. In Nguyen and Conrad (2015) and Essayeh and Abed (2015), the authors develop hybrid methods (combining structural and semantic).
Because of the extensive applications of ontology alignment, it has been widely studied in many research works (Mohammadi 2019; Mohammadi et al. 2018a,b; Mohammadi and Rezaei 2020; Zhou et al. 2018). In these works, the authors also consider a considerable number of alignment systems. In our research, the ontology alignment generates the integration model shown in Fig. 1.
4.4 Ontology Candidates and Potential Mapping
In this section, we provide a quick reference to ontologies related to demand response and select the best of them in the following domains: demand response, renewable energy, sensor, and manufacturing. The next step is to explore the potential links between ontologies. We interlink those ontologies to prevent information duplication, to establish a common vocabulary, and to make less development effort. We consider methods SubClassOf and EquivalentClass to link a concept in the source ontology and a concept in the target ontology. In the SubClassOf approach, concepts and properties of source ontology are a part of the target ontology. In EquivalentClass, the linked concepts refer to the same meaning. Sometimes, to be more flexible, we may define “new concepts” or “new properties” for the source and target ontologies (Haase and Motik 2005).
The lists of ontologies that we considered in this context are OpenADR, OEMA, SAREF, OntoWind, SSN/SOSA, and Mason. We elaborate the potential links between the abovementioned ontologies and show the linking method in Tables 3, 4, 5, 6, 7 and 8.
5 Forecast Methods
As the literature discussed in the previous section shows, artificial neural networks and deep learning have recently been popular in mapping stochastic historic input data to a forecast output value. The initial experiments done in our research are to develop simple deep learning networks and evaluate their prediction capabilities. In order to do so, four neural network architectures, Deep Neural Network (DNN), Long Short-Term Memory Network (LSTM), Convolutional Neural Network (CNN), and a Hybrid architecture combining the three techniques, are developed. We conduct experiments to forecast both solar and wind energy generation for both short-term (1 day) and long-term (monthly) horizons. The details of the experiments and their results are discussed in the following order. The datasets and data preprocessing techniques are discussed first, along with exploratory data analysis. This is followed by discussions on the neural network architectures. Finally, the performance of the different architectures is discussed.
5.1 Dataset Description, Data Preprocessing, and Exploratory Data Analysis
Data used for experimental purposes are historical wind and solar power generation data, from February 2019 until December 2020, collected by a local utility company. The wind power generation data are from three different wind turbines and include variables such as the wind speed, wind direction, and temperature around the turbines. Similarly, the solar power generation data are also from three different solar plants and include other variables such as global radiation and temperature around the solar plants. The dataset preprocessing is done with simple techniques to identify abnormal/anomaly values, drop them, and finally impute missing values using linear interpolation.
As a next step to understand the datasets, calculation of correlations between all variables is necessary. Initially, no correlation is seen between the generated power and the wind direction. This problem generally appears because the coordinate in which wind direction is measured is circular, opposed to the linear coordinate used to measure wind speed and power. In order to extract a new feature that encompasses the effect of wind direction and wind speed, the following trigonometric transformation is applied to the initial features:
In the equation, d is an offset direction such that: wind direction values closer to the offset direction result in higher production. Two offset directions are chosen based on the apparent relation seen between the direction feature and the generated power.
The histogram shown in Fig. 3 has power generated on the y-axis plotted with the wind direction (0∘ as North) for each month of the year. In each plot, we can see two distinct clusters form. The first cluster is centered around 45–50∘ North, and the second at 200–225∘ North. It is also slightly noticeable that the closer the wind direction to these axes, the higher wind energy production is seen (bright spots in the histogram). We therefore estimate that the ideal directions for the wind turbine output are around 50 and 200∘ North, and these are the ideal offset angles to choose. The solar dataset shows good correlations of the initial features with power generated. Figures 4 and 5 show correlation plots of the variables used to train neural network models for wind and solar power forecast.

Histogram of power against wind direction

Correlation plot: features used for solar power prediction

Correlation plot: features used for wind power prediction
As mentioned earlier, the initial experiments are conducted with Deep Neural Network (DNN), Long Short-Term Memory Network (LSTM), Convolutional Neural Network (CNN), and Hybrid architecture. Each training step allows the network to learn from historical values with a window of 18 time steps in order to predict power generation for the next single time step. One year’s half power generation data are used for training and the other half for evaluation of the models. Table 9 below summarizes the network architecture for each of the methods.
5.2 Experiment Results
Each model is trained to minimize the mean-squared error between the predicted value and the actual value. Therefore, the mean-squared error (MSE) is used to evaluate the different neural network architectures. Along with the mean-squared error, the mean absolute percentage error (MAPE) of the different models is compared. Tables 10 and 11 summarize the metrics for short-term and long-term forecasting of wind and solar power generation.
The results show that the Hybrid model outperforms all other models and significantly improves prediction in terms of MSE for daily and monthly predictions. Theoretically, the Hybrid model benefits from the integration of the LSTM and CNN layers. The LSTM layer can learn the temporal differences in the data (dependence on previous values), and the CNN layer is able to learn the spatial relations (correlations between input features). Both the short-term predictions and long-term predictions of the Hybrid model show high flexibility in terms of predicting but still tend to overestimate the forecasted values resulting in higher MAPE values. Figures 6, 7, 8, and 9 show the plots of short-term and long-term forecasting of wind and solar power generation using the Hybrid model.

Short-term forecasting of wind power generation using Hybrid model

Short-term forecasting of solar power generation using Hybrid model

Long-term forecasting of wind power generation using Hybrid model

Long-term forecasting of solar power generation using Hybrid model
The LSTM model stands out in terms of MAPE as it tends to under-forecast predicted values of both wind and solar predictions. The calculation of MAPE favors models that under-forecast and penalize over-forecast (where predicted values are higher than actual values). This can be clearly seen in the evaluation plots of the LSTM model in Figs. 10, 11, 12, and 13.

Short-term forecasting of wind power using LSTM

Short-term forecasting of solar power using LSTM

Long-term forecasting of wind power using LSTM

Long-term forecasting of solar power using LSTM
6 Conclusions and Outlook
This book chapter focuses on the development of an IT system that enables the implementation of a demand-response system for manufacturing power consumers. The system architecture follows the functionalities of the reference architecture developed by EU Smart Grid Coordination Group/Reference Architecture Working Group (SG-CG/RA). The system employs ontologies as the information model to enable the interoperability of heterogeneous systems involved in demand-response programs at both supply and demand sides. We develop an ontology construction method that allows reusing and interlinking of existing ontologies and information model standards, such as SAREF, OpenADR, IFC, Mason, etc. By doing this, many systems that use existing information model standards will be compatible and able to communicate with our system.
This book chapter also discusses the development of forecast models as a component of the demand-response system. The aim of the forecast models is to allow for forecasting of the amount of power generated by renewable energy sources, such as wind and solar, and the amount of power consumed in the manufacturing companies. Therefore, we are able to calculate the dynamic electricity tariffs. We develop four different neural network architectures and conduct experiments using solar and wind power generation datasets for short-term and long-term forecasting. The experimental results show that the hybrid and LSTM architectures perform best.
The research described in this book chapter is still in the early phase. The next steps are to apply the neural network models to forecast the power consumption in manufacturing companies. We will collect the power consumption and manufacturing process data from two manufacturing companies, i.e., a rubber component manufacturer and a manufacturing subcontractor having high-degree automation. Then, we will validate the models using those data. Finally, we will develop a method to calculate dynamic electricity tariffs based on the forecast models.
References
European Telecommunications Standards Institute (ETSI). https://saref.etsi.org/saref4ener/v1.1.2/. Accessed 06 April 2020
Energy Union Package: A framework strategy for a resilient energy union with a forward-looking climate change policy. Technical report. European Commission, Brussels (2015)
Zafirakis, D., Tzanes, G., Kaldellis, J.K.: Forecasting of Wind Power Generation with the Use of Artificial Neural Networks and Support Vector Regression Models. Energy Procedia 159, 509–514 (2019). https://doi.org/10.1016/j.egypro.2018.12.007. https://www.sciencedirect.com/science/article/pii/S187661021831302X
Alaya, M.B., Medjiah, S., Monteil, T., Drira, K.: Toward semantic interoperability in oneM2M architecture. IEEE Commun. Mag. 53(12), 35–41 (2015)
Bertoldi, P., Zancanella, P., Boza-Kiss, B., et al.: Demand response status in EU member states. In: EUR 27998 EN, pp. 1–140 (2016)
Bizer, C., Heath, T., Berners-Lee, T.: Linked data: the story so far. In: Semantic Services, Interoperability and Web Applications: Emerging Concepts, pp. 205–227. IGI Global, Pennsylvania (2011)
Borsato, M.: An energy efficiency focused semantic information model for manufactured assemblies. J. Clean. Prod. 140, 1626–1643 (2017). https://doi.org/10.1016/j.jclepro.2016.09.185. https://www.sciencedirect.com/science/article/pii/S0959652616315268
Chen, S., Liu, C.C.: From demand response to transactive energy: state of the art. J. Mod. Power Syst. Clean Energy 5(1), 10–19 (2017)
Chiu, W.Y., Sun, H., Poor, H.V.: Demand-side energy storage system management in smart grid. In: 2012 IEEE Third International Conference on Smart Grid Communications (SmartGridComm), pp. 73–78. IEEE, Piscataway (2012)
Cuenca, J., Larrinaga, F., Curry, E.: A unified semantic ontology for energy management applications. In: WSP/WOMoCoE@ ISWC, pp. 86–97 (2017)
Daniele, L.: SAREF4EE: the extension of SAREF for EEbus and Energy@Home. https://ontology.tno.nl/saref4ee/. Accessed 07 Feb 2021
Daniele, L., den Hartog, F., Roes, J.: Created in close interaction with the industry: the smart appliances reference (SAREF) ontology. In: International Workshop Formal Ontologies Meet Industries, pp. 100–112. Springer, Berlin (2015)
Dutta, G., Mitra, K.: A literature review on dynamic pricing of electricity. J. Oper. Res. Soc. 68(10), 1131–1145 (2017)
Essayeh, A., Abed, M.: Towards ontology matching based system through terminological, structural and semantic level. Proc. Comput. Sci. 60, 403–412 (2015)
Fernández-Izquierdo, A., Cimmino, A., Patsonakis, C., Tsolakis, A.C., García-Castro, R., Ioannidis, D., Tzovaras, D.: OpenADR ontology: semantic enrichment of demand response strategies in smart grids. In: 2020 International Conference on Smart Energy Systems and Technologies (SEST), pp. 1–6. IEEE, Piscataway (2020)
Ferrer, B.R., Ahmad, B., Lobov, A., Vera, D.A., Lastra, J.L.M., Harrison, R.: An approach for knowledge-driven product, process and resource mappings for assembly automation. In: 2015 IEEE International Conference on Automation Science and Engineering (CASE), pp. 1104–1109. IEEE, Piscataway (2015)
Gottschalk, M., Uslar, M., Delfs, C.: The Use Case and Smart Grid Architecture Model Approach: The IEC 62559-2 Use Case Template and the SGAM Applied in Various Domains. Springer, Berlin (2017)
Haase, P., Motik, B.: A mapping system for the integration of OWL-DL ontologies. In: Proceedings of the First International Workshop on Interoperability of Heterogeneous Information Systems, pp. 9–16 (2005)
Haller, A., Janowicz, K., Cox, S.J., Lefrançois, M., Taylor, K., Le Phuoc, D., Lieberman, J., García-Castro, R., Atkinson, R., Stadler, C.: The modular SSN ontology: a joint W3C and OGC standard specifying the semantics of sensors, observations, sampling, and actuation. Semantic Web 10(1), 9–32 (2019)
Hazber, M.A., Li, R., Zhang, Y., Xu, G.: An approach for mapping relational database into ontology. In: 2015 12th Web Information System and Application Conference (WISA), pp. 120–125. IEEE, Piscataway (2015)
Hong, T., Pinson, P., Wang, Y., Weron, R., Yang, D., Zareipour, H.: Energy forecasting: a review and outlook. IEEE Open Access J Power Energy 7, 376–388 (2020). http://doi:10.1109/OAJPE.2020.3029979
Huang, C.M., Kuo, C.J., Huang, Y.C.: Short-term wind power forecasting and uncertainty analysis using a hybrid intelligent method. IET Renew. Power Gener. 11(5), 678–687 (2017)
Jiao, R., Huang, X., Ma, X., Han, L., Tian, W.: A model combining stacked auto encoder and back propagation algorithm for short-term wind power forecasting. IEEE Access 6, 17851–17858 (2018)
Kalimoldayev, M., Drozdenko, A., Koplyk, I., Marinich, T., Abdildayeva, A., Zhukabayeva, T.: Analysis of modern approaches for the prediction of electric energy consumption. Open Eng. 10(1), 350–361 (2020)
Kofler, M.J., Reinisch, C., Kastner, W.: A semantic representation of energy-related information in future smart homes. Energy Build. 47, 169–179 (2012)
Kovalenko, O., Grangel-Gonzalez, I.: AutomationML ontology. http://i40.semantic-interoperability.org/automationml/Documentation/index.html. Accessed 07 Mar 2021
Kovalenko, O., Grangel-González, I., Sabou, M., Lüder, A., Biffl, S., Auer, S., Vidal, M.E.: AutomationML ontology: Modeling Cyber-Physical Systems for Industry 4.0. IOS Press Journal, Amsterdam (2018)
Küçük, D., Küçük, D.: Ontowind: an improved and extended wind energy ontology. arXiv preprint arXiv:1803.02808 (2018)
Kuzemko, C., Mitchell, C., Lockwood, M., Hoggett, R.: Policies, politics and demand side innovations: the untold story of Germany’s energy transition. Energy Res. Soc. Sci. 28, 58–67 (2017). https://doi.org/10.1016/j.erss.2017.03.013. https://www.sciencedirect.com/science/article/pii/S221462961730083X
Lahouar, A., Slama, J.B.H.: Hour-ahead wind power forecast based on random forests. Renew. Energy 109, 529–541 (2017)
Lassila, O., Swick, R.R., et al.: Resource Description Framework (RDF) model and syntax specification (1998). http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.44.6030
Lehmann, P., Brandt, R., Gawel, E., Heim, S., Korte, K., Löschel, A., Massier, P., Reeg, M., Schober, D., Wassermann, S.: Capacity payments to secure electricity supply? On the future of Germany’s power market design. Energy Sustain. Soc. 5(1), 1–7 (2015)
Lemaignan, S., Siadat, A., Dantan, J.Y., Semenenko, A.: MASON: a proposal for an ontology of manufacturing domain. In: IEEE Workshop on Distributed Intelligent Systems: Collective Intelligence and Its Applications (DIS’06), pp. 195–200. IEEE, Piscataway (2006)
Li, G., Shi, J.: On comparing three artificial neural networks for wind speed forecasting. Appl. Energy 87(7), 2313–2320 (2010)
Liu, H., Mi, X., Li, Y., Duan, Z., Xu, Y.: Smart wind speed deep learning based multi-step forecasting model using singular spectrum analysis, convolutional gated recurrent unit network and support vector regression. Renew. Energy 143, 842–854 (2019)
Mahria, B.B., Chaker, I., Zahi, A.: A novel approach for learning ontology from relational database: from the construction to the evaluation. J. Big Data 8(1), 1–22 (2021)
McGlinn, K., Weise, M., Wicaksono, H.: Towards a shared use case repository—the SWIMing initiative started in the framework of the EU H2020 R&DI programme. In: Proceedings of the 33rd CIB W78 Conference 2016, Oct. 31st – Nov. 2nd 2016, Brisbane (2016)
Mohammadi, M.: Bayesian evaluation and comparison of ontology alignment systems. IEEE Access 7, 55035–55049 (2019)
Mohammadi, M., Atashin, A.A., Hofman, W., Tan, Y.: Comparison of ontology alignment systems across single matching task via the McNemar’s test. ACM Trans. Knowl. Discovery from Data (TKDD) 12(4), 1–18 (2018a)
Mohammadi, M., Hofman, W., Tan, Y.H.: A comparative study of ontology matching systems via inferential statistics. IEEE Trans. Knowl. Data Eng. 31(4), 615–628 (2018b)
Mohammadi, M., Rezaei, J.: Evaluating and comparing ontology alignment systems: an MCDM approach. J. Web Semantics 64, 100592 (2020)
Nguyen, T.T.A., Conrad, S.: Ontology matching using multiple similarity measures. In: 2015 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K), vol. 1, pp. 603–611. IEEE, Piscataway (2015)
Niu, Z., Yu, Z., Tang, W., Wu, Q., Reformat, M.: Wind power forecasting using attention-based gated recurrent unit network. Energy 196, 117081 (2020)
Olaofe, Z.O., Folly, K.A.: Wind energy analysis based on turbine and developed site power curves: a case-study of darling city. Renew. Energy 53, 306–318 (2013)
Ouali, I., Ghozzi, F., Taktak, R., Sassi, M.S.H.: Ontology alignment using stable matching. Procedia Comput. Sci. 159, 746–755 (2019)
Pauwels, P., Terkaj, W.: EXPRESS to OWL for construction industry: towards a recommendable and usable ifcOWL ontology. Automat. Construct. 63, 100–133 (2016). https://doi.org/10.1016/j.autcon.2015.12.003. https://www.sciencedirect.com/science/article/pii/S0926580515002435
Qdr, Q.: Benefits of demand response in electricity markets and recommendations for achieving them. US Department, Energy, Washington, Technical Report (2006)
Seeger, M., Salinas, D., Flunkert, V.: Bayesian intermittent demand forecasting for large inventories. In: Proceedings of the 30th International Conference on Neural Information Processing Systems, pp. 4653–4661 (2016)
Shojaeighadikolaei, A., Ghasemi, A., Jones, K.R., Bardas, A.G., Hashemi, M., Ahmadi, R.: Demand responsive dynamic pricing framework for prosumer dominated microgrids using multiagent reinforcement learning. In: 2020 52nd North American Power Symposium (NAPS), pp. 1–6. IEEE, Piscataway (2021)
Siano, P.: Demand response and smart grids—a survey. Renew. Sust. Energ. Rev. 30, 461–478 (2014). https://doi.org/10.1016/j.rser.2013.10.022. https://www.sciencedirect.com/science/article/pii/S1364032113007211
Stap, R., Daniele, L.: Ontology ‘a CIM profile for smart grids’. https://ontology.tno.nl/cerise/cim-profile/. Accessed 07 Feb 2021
Sun, Z., Sun, H., Zhang, J.: Multistep wind speed and wind power prediction based on a predictive deep belief network and an optimized random forest. Math. Prob. Eng. 2018 (2018)
Valdes, J., Poque González, A.B., Ramirez Camargo, L., Valin Fenández, M., Masip Macia, Y., Dorner, W.: Industry, flexibility, and demand response: applying German energy transition lessons in Chile. Energy Res. Soc. Sci. 54, 12–25 (2019). https://doi.org/10.1016/j.erss.2019.03.003. https://www.sciencedirect.com/science/article/pii/S2214629618306054
Wang, H., Lei, Z., Zhang, X., Zhou, B., Peng, J.: A review of deep learning for renewable energy forecasting. Energy Convers. Manag. 198, 111799 (2019)
Wicaksono, H.: An integrated method for information and communication technology (ICT) supported energy efficiency evaluation and optimization in manufacturing: knowledge-based approach and energy performance indicators (EnPI) to support evaluation and optimization of energy efficiency. Ph.D. Thesis, Karlsruher Institut für Technologie (KIT) (2016). https://doi.org/10.5445/IR/1000060882
Wicaksono, H., Dobreva, P., Häfner, P., Rogalski, S.: Methodology to develop ontological building information model for energy management system in building operational phase. In: International Joint Conference on Knowledge Discovery, Knowledge Engineering, and Knowledge Management, pp. 168–181. Springer, Berlin (2013)
Wicaksono, H., Jost, F., Rogalski, S., Ovtcharova, J.: Energy efficiency evaluation in manufacturing through an ontology-represented knowledge base. Intell. Syst. Account. Financ. Manag. 21(1), 59–69 (2014)
Wicaksono, H., Rogalski, S., Kusnady, E.: Knowledge-based intelligent energy management using building automation system. In: 2010 Conference Proceedings IPEC, pp. 1140–1145. IEEE, Piscataway (2010)
Xie, C., Chekol, M.W., Spahiu, B., Cai, H.: Leveraging structural information in ontology matching. In: 2016 IEEE 30th International Conference on Advanced Information Networking and Applications (AINA), pp. 1108–1115. IEEE, Piscataway (2016)
Yassine, A.: Implementation challenges of automatic demand response for households in smart grids. In: 2016 3rd International Conference on Renewable Energies for Developing Countries (REDEC), pp. 1–6. IEEE, Piscataway (2016)
Zhou, L., Cheatham, M., Krisnadhi, A., Hitzler, P.: A complex alignment benchmark: GeoLink dataset. In: International Semantic Web Conference, pp. 273–288. Springer, Berlin (2018)
Acknowledgements
This research is funded by German Federal Ministry of Economics and Technology (BMWi). We thank all project members who have contributed in preliminary works and discussions for this research.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2021 The Author(s)
About this chapter

Cite this chapter
Wicaksono, H., Boroukhian, T., Bashyal, A. (2021). A Demand-Response System for Sustainable Manufacturing Using Linked Data and Machine Learning. In: Freitag, M., Kotzab, H., Megow, N. (eds) Dynamics in Logistics. Springer, Cham. https://doi.org/10.1007/978-3-030-88662-2_8
Download citation
DOI: https://doi.org/10.1007/978-3-030-88662-2_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-88661-5
Online ISBN: 978-3-030-88662-2
eBook Packages: Business and ManagementBusiness and Management (R0)