
Abstract
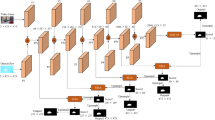
Semi-supervised Video object segmentation is one of the most basic tasks in the field of computer vision, especially in the multi-object case. It aims to segment masks of multiple foreground objects in given video sequence with annotation mask of the first frame as prior knowledge. In this paper, we propose a novel multi-object video segmentation model. We use the U-Net architecture to obtain multi-scale spatial features. In the encoder part, the spatial attention mechanism and channel attention is used to enhance the spatial features simultaneously. We use the recurrent ConvLSTM module in the decoder to segment different object instances in one stage and keep the segmentation object consistent over time. In addition, we use three loss functions for joint training to improve the model training effect. We test our network on the popular video object segmentation dataset DAVIS2017. The experiment results demonstrate that our model achieves state-of-art performance. Moreover, our model achieves faster inference runtimes than other methods.
This work was supported by the National Natural Science Foundation of China (61902027).
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Caelles, S., Maninis, K., Pont-Tuset, J., Leal-Taixé, L., Cremers, D., Gool, L.V.: One-shot video object segmentation. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), pp. 5320–5329. IEEE Computer Society (2017)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), pp. 770–778. IEEE Computer Society (2016)
Hu, Y.-T., Huang, J.-B., Schwing, A.G.: VideoMatch: matching based video object segmentation. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11212, pp. 56–73. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01237-3_4
Huang, Z., Wang, X., Huang, L., Huang, C., Wei, Y., Liu, W.: Ccnet: criss-cross attention for semantic segmentation. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV 2019), pp. 603–612. IEEE (2019)
Luiten, J., Voigtlaender, P., Leibe, B.: Premvos: proposal-generation, refinement and merging for the Davis challenge on video object segmentation 2018. In: The 2018 DAVIS Challenge on Video Object Segmentation-CVPR Workshops, vol. 1, p. 6 (2018)
Maninis, K., et al.: Video object segmentation without temporal information. IEEE Trans. Pattern Anal. Mach. Intell. 41(6), 1515–1530 (2019)
Oh, S.W., Lee, J., Sunkavalli, K., Kim, S.J.: Fast video object segmentation by reference-guided mask propagation. In: 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), pp. 7376–7385. IEEE Computer Society (2018)
Oh, S.W., Lee, J., Xu, N., Kim, S.J.: Video object segmentation using space-time memory networks. In: 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019. pp. 9225–9234. IEEE (2019)
Perazzi, F., Khoreva, A., Benenson, R., Schiele, B., Sorkine-Hornung, A.: Learning video object segmentation from static images. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), pp. 3491–3500. IEEE Computer Society (2017)
Pont-Tuset, J., Perazzi, F., Caelles, S., Arbelaez, P., Sorkine-Hornung, A., Gool, L.V.: The 2017 DAVIS challenge on video object segmentation. CoRR abs/1704.00675 (2017)
Shi, X., Chen, Z., Wang, H., Yeung, D., Wong, W., Woo, W.: Convolutional LSTM network: a machine learning approach for precipitation nowcasting, pp. 802–810 (2015)
Ventura, C., Bellver, M., Girbau, A., Salvador, A., Marqués, F., Giró-i-Nieto, X.: RVOS: end-to-end recurrent network for video object segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), pp. 5277–5286. Computer Vision Foundation/IEEE (2019)
Voigtlaender, P., Leibe, B.: Online adaptation of convolutional neural networks for video object segmentation. In: British Machine Vision Conference 2017 (BMVC 2017). BMVA Press, London (2017)
Xu, S., Liu, D., Bao, L., Liu, W., Zhou, P.: MHP-VOS: multiple hypotheses propagation for video object segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), pp. 314–323. Computer Vision Foundation/IEEE (2019)
Yang, Z., Wei, Y., Yang, Y.: Collaborative video object segmentation by foreground-background integration. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12350, pp. 332–348. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58558-7_20
Yoon, J.S., Rameau, F., Kim, J., Lee, S., Shin, S., Kweon, I.S.: Pixel-level matching for video object segmentation using convolutional neural networks. In: IEEE International Conference on Computer Vision (ICCV 2017), pp. 2186–2195. IEEE Computer Society (2017)
Zhu, W., Li, J., Lu, J., Zhou, J.: Separable structure modeling for semi-supervised video object segmentation. IEEE Trans. Circuits Syst. Video Technol. 99, 1–1 (2021)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhao, Z., Zhao, S. (2021). Dual Attention Based Network with Hierarchical ConvLSTM for Video Object Segmentation. In: Ma, H., et al. Pattern Recognition and Computer Vision. PRCV 2021. Lecture Notes in Computer Science(), vol 13022. Springer, Cham. https://doi.org/10.1007/978-3-030-88013-2_27
Download citation
DOI: https://doi.org/10.1007/978-3-030-88013-2_27
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-88012-5
Online ISBN: 978-3-030-88013-2
eBook Packages: Computer ScienceComputer Science (R0)