
Abstract
Monte Carlo (MC) simulation using Crystal Ball® (CB) software is applied to life cycle inventory (LCI) modelling under uncertainty. Input data for all cases comes from the ENVIREE (ENVIronmentally friendly and efficient methods for extraction of Rare Earth Elements), i.e. from secondary sources eco-innovative project within the second ERA-NET ERA-MIN Joint Call Sustainable Supply of Raw Materials in Europe 2014. Case studies described the flotation tailings from the New Kankberg (Sweden) old gold mine and Covas (Portugal) old tungsten mine sent to re-processing/beneficiation for rare earth element (REE) recovery. In this study, we conduct the MC analysis using the CB software, which is associated with Microsoft® Excel spreadsheet model, used in order to assess uncertainty concerning cerium (Ce), lanthanum (La), neodymium (Nd) and tungsten (W) taken from Covas flotation tailings, as well as Ce, La and Nd taken from New Kankberg flotation tailings, respectively. For the current study, lognormal distribution has been assigned to La, Ce, Nd and W. In the case of Covas, the weights of each selected Ce, La, Nd and W are 32 ppm, 16 ppm, 15 ppm and 1900 ppm, respectively, whereas in the case of New Kankberg, the weights of each selected Ce, La and Nd are 170 ppm, 90 ppm and 70 ppm, respectively. For the presented case, lognormal distribution has been assigned to Ce, La, Nd and W. The results obtained from the CB, after 10,000 runs, are presented in the form of frequency charts and summary statistics. Thanks to uncertainty analysis, a final result is obtained in the form of value range. The results of this study based on the real data, and obtained using MC simulation, are more reliable than those obtained from the deterministic approach, and they have the advantage that no normality is presumed.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others

1 Introduction
This paper presents the utility of uncertainty analysis based on the MC simulation applied to LCI modelling based on research data obtained from 2015 to 2017 as part of the ENVIREE EU-funded from the ERA-MIN programme within the second Joint Call aims at complete recovery process proposal of REEs (rare earth elements) from tailings and mining waste [1, 2].
The REEs are a group of 17 elements with similar chemical properties, including 15 in the lanthanide group, yttrium (Y) and scandium (Sc) due to their similar physical and chemical properties [1, 3]. The lanthanide elements traditionally have been divided into two groups: the light rare earth elements (LREEs), lanthanum (La) through europium (Eu) (Z = 57 through 63), and the heavy rare earth elements (HREEs), gadolinium (Gd) through lutetium (Lu) (Z = 64 through 71) [4]. Although Y is the lightest REE, it is usually grouped with the HREEs to which it is chemically and physically similar [4]. On the other hand, according to [5], REEs can be divided into three groups: LREEs, HREEs and scandium (Sc). LREEs comprise lanthanum (La), cerium (Ce), praseodymium (Pr), neodymium (Nd) and samarium (Sm), and the remaining are included in the HREEs. While Koltun and Tharumarajah [6] presented three groups of the REEs classification often used in extraction given in LREEs, lanthanum (La), cerium (Ce), praseodymium (Pr), neodymium (Nd) and promethium (Pm); medium rare earth elements (MREEs), samarium (Sm), europium (Eu) and gadolinium (Gd); and HREEs, terbium (Tb), dysprosium (Dy), holmium (Ho), erbium (Er), thulium (Tm), ytterbium (Yb), lutetium (Lu), scandium (Sc) and yttrium (Y) quoted in Australian Industry Commission documents [7]. By the way, definition of REEs found in the same Australian Industry Commission documents [7] is the following: “Group of 17 chemical elements – not rare at all; yttrium, for example is thought to be more abundant than lead. These elements were mislabelled because they were first found in truly rare minerals”.
2 Uncertainty Analysis of LCI
The most popular approach for doing an uncertainty analysis in LCA is the MC approach [8], partly because it has been implemented in many of the major software programs for LCA , typically as the only way for carrying out uncertainty analysis (for instance, in SimaPro, GaBi and Brightway2 and in open LCA ).
The MC technique is widely used and recommended for the inclusion of uncertainties for LCA. Typically, 1000 or 10,000 runs are done, but a clear argument for that number is not available, and with the growing size of LCA databases, an excessively high number of runs may be time-consuming [9, 10]. It is an important parameter in simulation modelling. [11] studied stochastic flow shop scheduling metaheuristic model for vessel transits in Panama Canal. It was found that using 200 replications is optimal, because the change in the 95% confidence interval width for makespan was negligible.
According to Good [12], the uncertainty exists when the probability of an event occurring is not 0 or 1. Not only statistic but also uncertainty is a fundamental element in simulation analysis and modelling. Definition of uncertainty given by Huijbregts [13] is the following: “Uncertainty is defined as incomplete or imprecise knowledge, which can arise from uncertainty in the data regarding the system, the choice of models used to calculate emissions and the choice of scenarios with which to define system boundaries, respectively”, and uncertainty defined by Walker et al. [14] is as “any deviation from the unachievable ideal of completely deterministic knowledge of the relevant system”. Uncertainty is to be found when a decision-maker cannot mention all possible outcomes and/or cannot attribute probabilities to the various outcomes [15]. According to [16], uncertainty analysis is another important issue in LCA , as average data is usually used without considering the associated variability, and the results can be misleading when comparing systems [16]. Deterministic approaches and the description of processes in the studies of ecological life cycle assessment do not properly reflect the reality [17]. The analysis of uncertainty, a pervasive topic in LCA studies [18, 19], has been a subject for more than 10 years. Many LCA software tools (e.g. SimaPro, GaBi) facilitate uncertainty propagation by means of sampling methods, and most often used MC simulation [16, 20,21,22]. Detailed description of the combination of sources of uncertainty (parameter, model and scenario uncertainties) and combination of source of uncertainty and methods to address them (deterministic, probabilistic and simple methods) are discussed in [23].
MC simulation has received considerable attention in the literature, especially when MC simulations are used for making decisions that will have a large social and economic impact [24]. As a result, it was the most commonly recommended tool (e.g [25, 26]). Stochastic nature of the MC simulation is based on random numbers, and simulation models are generally easier to understand than many analytical approaches [18]. According to La Grega et al. [27], MC simulation can be considered the most effective quantification method for uncertainties and variability among the environmental system analysis tools available.
3 LCI Data Quality and Collection
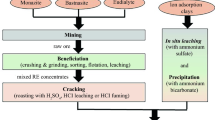
Based on the different physical and chemical separations carried out on New Kankberg and Covas tailings [28], the following process treatment scheme is shown in Figs. 1 and 2, respectively.

Proposed process scheme for the beneficiation of Covas tailings. (Adopted from [28])

Proposed process scheme for the beneficiation of REE in the flotation tailings from New Kankberg mine. (Adopted from [28])
The possibilities of extraction of Ne, Ce and La using magnetic separation can be reached, thanks to the paramagnetic property of monazite. Inventory data used in the study has been obtained from the following sources: the primary data used in this study is based on the elements determined from the chemical analyses done by instrumental neutron activation analyses site-specific measured or calculated data, and on values found in literature. In the current study, we discuss and model our LCI adopting the proposed process for the beneficiation of REE in the flotation tailings from New Kankberg mine in Sweden and Covas tailings [29].
4 Simulation Model: Model Assumptions
Simulation models are generally easier, when it comes to their interpretation and understanding, than a number of analytical solutions. Moreover, simulation models provide an interesting opportunity to give more reliable and comprehensive data [30]. For input parameters analysed in this study (La, Ce, Ne and W), uncertainty was included in the MC analysis by assigning distributions.
For uncertainty analysis in the LCI study, the lognormal probability distributions have been assigned to each analysed REE. Lognormal distribution is stable and no negative values are possible [21]. In this context, it should be pointed out that the lognormal probability distribution with the GSD equal to 1.13 was applied to rare earth oxides in the ecoinvent background process “Rare earth oxide production from bastnaesite” taken from the “Life Cycle Inventories of Chemicals Data v2.0 Ecoinvent report No. 8” [31].
The decision to choose lognormal distribution is based on the works of [20, 21, 32] and the bibliographies included in the above-mentioned publication because the quality of data was not sufficient to estimate best-fitting distributions.
Several examples of performance of MC simulation by using CB software can be found in [33] as well as in [20, 21, 34]. The MC simulation results for La, Ce, Ne and W are shown in graphical forms (histograms) and descriptive statistics (percentiles summary and statistics summary).
It is important that a sufficient number of replications (runs) should be used in a simulation [35], because the quality of the simulation results depends on the number of replications. In general, the higher the number of replications, the more accurate will be the characterization of the output distribution and estimates of its parameters, such as the mean [34].
5 Results and Discussion
Random values from the probability distribution of each parameter were selected in each run and a forecast distribution for each selected REE. CB’s distribution fitting function can analyse a data set and determine not only the best fit but also the quality of the fit [34]. During a single trial, CB randomly selects a value from the defined possibilities (the range and shape of the distribution) for each uncertain variable and then recalculates the spreadsheet [36].
5.1 Covas (Portugal) Old Tungsten Mine Case Study
After activating the simulation with the randomization cycle, set previously to 10,000 trials, the results obtained by MC simulation after 10,000 trials, for the Ce, La and Ne, have been presented in the form of frequency charts (histograms). They are shown in Figs. 3, 4, 5 and 6, respectively; statistics, as well as percentiles, reports are presented in Tables 1 and 2, respectively. The mean values of Ce, La, Ne and W forecast values amounted to the GSD with a 95% confidence interval around the mean values were situated between:
-
Ce [26.17 and 38.61] ppm (see Fig. 3)
-
La [13.13 and 19.46] ppm (see Fig. 4)
-
Nd [12.24 and 18.06] ppm (see Fig. 5)
-
W [1556.96 and 2302.73] ppm (see Fig. 6)

CB forecast chart: Ce after 10,000 trials (95% confidence interval). Certainty is 95.00% from 26.17 to 38.61 ppm. (Source: own work)

CB forecast chart: La after 10,000 trials (95% confidence interval). Certainty is 95.00% from 13.13 to 19.46 ppm. (Source: own work)

CB forecast chart: Nd after 10,000 trials (95% confidence interval). Certainty is 95.00% from 12.24 to 18.06 ppm. (Source: own work)

CB forecast chart: W after 10,000 trials (95% confidence interval). Certainty is 95.00% from 1556.96 to 2302.73 ppm. (Source: own work)
The histograms of the outcome variables include all values within 2.6 standard deviations from the mean, which represents approximately 99% of the data, and the number of data points inside 2.6 standard deviations of the mean is shown in the upper right corner of the frequency charts, as presented in Figs. 3, 4, 5 and 6 (see [20, 34] for more details). It is worth noting that if the number of runs increases, the mean standard error decreases [34]. Moreover, the mean standard error can be used to construct confidence intervals as described in Evans and Olson [34].
The confidence interval range expressing 95% presented in the frequency chart (see Figs. 3, 4, 5 and 6) is highlighted with a darker colour marker. In other words, this means that 95% of the results are lying inside this range. Moreover, by setting the certainty values (e.g. 95%), the confidence intervals (minimum and maximum bounds) are set automatically by the grabbers, and the corresponding numerical values are entered in the edit fields at the bottom part of the dialog boxes of the Forecast tab (e.g [20, 34].).
5.2 New Kankberg (Sweden) Old Gold Mine Case Study
The results obtained by MC simulation , after 10,000 runs, for Ce, Ne and La, are shown in Figs. 7, 8 and 9, respectively, as well as in statistics and percentiles reports presented in Tables 3 and 4, respectively. The mean values of Ce, Nd and La with a 95% confidence interval around the mean values were situated between:
-
Ce [138.93 and 207.00] ppm (see Fig. 7)
-
Nd [57.29 and 84.67] ppm (see Fig. 9)
-
La [73.97 and 108.33] ppm (see Fig. 8)

CB forecast chart: Ce after 10,000 trials (95% confidence interval). Certainty is 95.00% from 138.93 to 207.00 ppm. (Source: own work)

CB forecast chart: Ne after 10,000 trials (95% confidence interval). Certainty is 95.00% from 57.29 to 84.67 ppm. (Source: own work)

CB forecast chart: La after 10,000 trials (95% confidence interval). Certainty is 95.00% from 73.97 to 108.33 ppm . (Source: own work)
6 Conclusions
This study provides new insight into the practical implementation of MC method, based on the stochastic approach, and applied to the uncertainty of the LCI data collection process. To our knowledge, there is a lack of publications and research presentation of stochastic modelling of the data used for the LCI , for beneficiation of REEs , in the flotation tailings processes. Probabilistic techniques using MC simulations must consider the strategy based on the specification of the optimal distribution. The MC simulation in this study provides justification for the lognormal distributions assumed for the analysed parameters. Thanks to uncertainty analysis, a final result is obtained in the form of value range. As a result, the results of this study, based on the real data and obtained using MC simulation , are more reliable than those based on the deterministic approach. An additional advantage is associated with the fact that no normality is presumed.
Finally, it is concluded that uncertainty analysis offers a well-defined procedure for LCI studies, early phase of LCA , and provides the basis for defining the data needs for full LCA of the beneficiation of REE process. It must be pointed out that MC simulation needs to know the probability distribution for the purpose of an uncertainty analysis in contrast to bootstrap sampling, which creates an uncertainty analysis without knowing the probability distribution of the analysed data.
Stochastic approach used to LCI supports decision-makers in the interpretation of final LCA results and leads to better understanding of many analytical approaches. The results of this study will encourage other researchers to consider this approach in their projects. Results can improve current procedures, and they can help the LCA practitioners and decision-makers in the REEs beneficiation processes modelling and management. They can also contribute to better understanding of many analytical procedures and bring closer to industrial application – industrially relevant focus – and may also stimulate innovation in the stochastic studies.
Summarizing, consideration of uncertainty in LCA will make the LCA field more robust and credible in supporting the practitioner decisions, as discussed in the work of Igos et al. [10].
References
Grzesik, K., Bieda, B., Kozakiewicz, R., & Kossakowska, K. (2017). Goal and scope and its evolution for life cycle assessment of rare earth elements recovery from secondary sources. SGEM 2017 Geoconference: Energy and Clean Technologies Albena., Nuclear technologies recycling air pollution and climate change, 17(41), 107–114.
ENVIREE. (2015). http://www.enviree.eu/home. Accessed 22 Feb 2020.
Navarro, J., & Zhao, F. Life-cycle assessment of the production of rare-earth elements for energy applications: A review. Frontiers in Energy Research. https://doi.org/10.3389/fenrg.2014.00045. Accessed 22 Feb 2020.
Castor, S. B., & Hedric, J. B. (2006). Rare earth elements, industrial minerals and rocks (7th ed.). Society for Mining, Metallurgy and Exploration.
Gutiérrez-Gutiérrez, S. C., Coulon, F., Jiang, Y., & Wagland, S. (2015). Rare earth elements and critical metal content of extracted landfilled material and potential recovery opportunities. Waste Management, 42, 128–136.
Koltun, P., & Tharumarajah, A. Life cycle impact of rare earth elements. ISRN Metallurgy, Article ID 907536. https://doi.org/10.1155/2014/907536. Accessed 21 Feb 2020.
Australian Industry Commission, New and Advanced Materials, Australian Government Publishing Service, Melbourne, Australia. https://www.pc.gov.au/inquiries/completed/new-advanced-materials/42newmat.pdf. Accessed 21 Feb 2020.
Lloyd, S. M., & Ries, R. (2007). Characterizing, propagating and analyzing uncertainty in life-cycle assessment. A survey of quantitative approaches. Journal of Industrial Ecology, 11, 161–179.
Heijungs, R. (2020). On the number of Monte Carlo runs in comparative probabilistic LCA. The International Journal of Life Cycle Assessment, 25, 394–402.
Igos, E., Benetto, E., Meyer, R., Baustert, P., & Othoniel, B. (2019). How to treat uncertainties in life cycle assessment studies? The International Journal of Life Cycle Assessment, 24(4), 794–807.
Jackman, J., Guerra de Castillo, Z., & Olafsson, S. (2011). Stochastic flow shop scheduling model for the Panama Canal. Journal of the Operational Research Society, 62, 69–80.
Good, I. J. (1995). Reliability always depends on probability of course. Journal of Statistical Computation and Simulation, 52, 192–193.
Huijbregts, M. A. J. (1998). Application of uncertainty and variability in LCA. Part I: A general framework for the analysis of uncertainty and variability in life cycle assessment. International Journal of Life Cycle Assessment, 3(5), 273–280.
Walker, W. E., Harremoës, P., Rotmans, J., van der Sluijs, J. P., van Asselt, M. B. A., Janssen, P., & Krayer von Krauss, M. P. (2003). Defining uncertainty: A conceptual basis for uncertainty management in model-based decision support. Integrated Assessment, 4(1), 5–17.
Thomas, C. T., & Maurice, S. C. Decisions under risk and uncertainty. Managerial Economics. http://highered.mheducation.com/sites/0070601607/student_view0/chapter15/index.html. Accessed 22 Mar 2018.
Escobar, N., Ribal, J., Clemente, G., & Sanjuán, N. (2014). Consequential LCA of two alternative systems for biodiesel consumption in Spain, concerning uncertainty. Journal of Cleaner Production, 79, 61–73.
Canarache, A., Simota, C., et al. (2002). In M. Pagliai & R. Jones (Eds.), Sustainable land management-environmental protection, a soil physical approach (Advances in geoecology 35) (pp. 495–506). Catena Verlag GmbH.
Heijungs, R., & Lenzen, M. (2014). Error propagation methods for LCA – A comparison. International Journal of Life Cycle Assessment, 19, 1445–1461.
Heijungs, R. (2020). On the number of Monte Carlo runs in comparative probabilistic LCA. The International Journal of Life Cycle Assessment, 25, 394–402.
Bieda, B. (2012). Stochastic analysis in production process and ecology under uncertainty. Springer-Verlag.
Sonnemann, G., Castells, F., & Schumacher, M. (2004). Integrated life-cycle and risk assessment for industrial processes. Lewis Publishers.
Escobar, N., Ribal, J., Clemente, G., Rodrigo, A., Pascual, A., & Sanjuán, N. (2015). Uncertainty analysis in the financial assessment of an integrated management system for restaurant and catering waste in Spain. The International Journal of Life Cycle Assessment, 20, 491–1510.
Scope, C., Ilg, P., Muench, S., & Guenther, E. J. (2016). Uncertainty in life cycle costing for long-range infrastructure. Part II: guidance and suitability of applied methods to address uncertinty. The International Journal of Life Cycle Assessment, 21, 1170–1184.
Saltelli, A., Tarantola, S., Campolongo, F., & Ratto, M. (2004). Sensitivity analysis in practice. A guide to assessing scientific models. Wiley.
Guo, M., & Murphy, R. J. (2012). LCA data quality: Sensitivity and uncertainty analysis. Science of the Total Environment, 435–436, 230–243.
Skalna, I., Rębiasz, B., Gaweł, B., Basiura, B., Duda, J., Opiła, J., & Pełech-Pilichowski, T. (2015). Advances in fuzzy decision making, studies in fuzziness and soft computing 333. Springer Verlag.
LaGrega, M. D., Buckingham, P. L., & Evans, J. C. (1994). Hazardous Waste Management. Mc Graw-Hill.
Menard, Y., & Magnaldo, A. ENVIREE DELIVERABLE D2.1: Report on the most suitable combined pre-treatment, leaching and purification processes. http://www.enviree.eu/fileadmin/user_upload/ENVIREE_D2.1.pdf. Accessed 21 Feb 2020.
Marques Dias, M. I, Borcia, C. G., & Menard, Y. ENVIREE – D1.2 and D1.3 reports on properties of secondary REE sources. http://www.enviree.eu/fileadmin/user_upload/ENVIREE_D1.2_and_D1.3.pdf. Accessed 21 Feb 2020.
Rönnlund, I., Reuter, M., Horn, S., Aho, J., Aho, M., Päällysaho, M., Ylimäki, L., & Pursula, T. (2016). Eco-efficiency indicator framework implemented in the metallurgical industry: Part 1- a comprehensive view and benchmark. The International Journal of Life Cycle Assessment, 21, 1473–1500.
Althaus, H-J., Hischier, R., Osses, M., Primas, A., Hellweg, S., Jungbluth, N., & Chudacoff, M. Life cycle inventories of chemicals data v2.0 Ecoinvent report no. 8. Dübendorf, https://db.ecoinvent.org/reports/08_Chemicals.pdf. Accessed 28 Feb 2020.
Muller, S., Lesage, P., Ciroth, A., Mutel, C., Weidema, B. P., & Samson, R. (2016). The application of the pedigree approach to the distributions foreseen in ecoinvent v3. International Journal of Life Cycle Assessment, 21, 1327–1337.
Gonzalez, A. G., Herrador, M., & Asuero, A. G. (2005). Uncertainty evaluation from Monte-Carlo simulations by using Crystal-Ball software. Accreditation and Quality Assurance, 10, 149–154.
Evans, J. R., & Olson, D. L. (1998). Introduction to simulation and risk analysis. Prentice Hall. Inc. A Simon & Schuster Company.
Warren-Hicks, W. J., & Moore, D. R. (1998). Uncertainty analysis in ecological risk assessment. In Proceeding from the Pellston workshop on uncertainty analysis in ecological risk assessment, 23–28 August 1995. Society of Environmental Toxicology and Chemistry/SETAC, Pellston, Michigan, Pensacola, FL.
Risk Analysis Overview. https://www.crystalballservices.com/Portals/0/eng/risk-analysis-overview.pdf?ver=2013-11-14-135039-623. Accessed 21 Feb 2020.
Acknowledgements
The authors are grateful for the input data provided, as part of the environmentally friendly and efficient methods, for extraction of rare earth elements from secondary sources (ENVIREE) project funded by NCBR within the second ERA-NET ERA-MIN Joint Call Sustainable Supply of Raw Materials in Europe 2014.
Funding
This work was supported by the Management Department of the AGH University of Science and Technology, Kraków, Poland.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Ethics declarations
Conflict of interest: The authors declare that they have no conflict of interest. Research is not involving human participants and/or animals.
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this chapter

Cite this chapter
Sala, D., Bieda, B. (2022). Role of Stochastic Approach Applied to Life Cycle Inventory (LCI) of Rare Earth Elements (REEs) from Secondary Sources Case Studies. In: Klos, Z.S., Kalkowska, J., Kasprzak, J. (eds) Towards a Sustainable Future - Life Cycle Management. Springer, Cham. https://doi.org/10.1007/978-3-030-77127-0_10
Download citation
DOI: https://doi.org/10.1007/978-3-030-77127-0_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-77126-3
Online ISBN: 978-3-030-77127-0
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)