
Abstract
This chapter explores multi-scale estimation methods as an important future direction for segregation research in China. We explain how these recently developed methods help address many longstanding problems in traditional index-based segregation research and open up new avenues of research on Chinese cities. We explain the conceptual framework underpinning multilevel analysis in the form of a series of propositions that capture the theoretical basis and outline why a multilevel approach to segregation is advantageous. We then illustrate how this approach can be applied to China using census data on Shijiazhuang, the capital city of Hebei Province. We use the model to consider segregation of different ethnic groups and of migrants versus non-migrants. We conclude with a discussion of our findings and our thoughts on future directions for research and the implications for policy.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others

Keywords
- Segregation measurement
- Index of dissimilarity
- Segregation theory
- Intersectionality
- Multilevel segregation
- Shijiazhuang, China
1 Introduction
Much of the academic research on segregation has focused on the degree to which residents from different socioeconomic, ethnic or cultural backgrounds live separately from each other. Because this separation has the potential to exacerbate the mistrust and antipathy between groups (Allport et al. 1954), it is something that societies need to measure, monitor and often seek to mitigate. While segregation is often measured in residential locations, it can take many forms beyond including segregation in the workplace, education, travel patterns, leisure activities, and friendship groups (see Chap. 2). However, many of these alternative places are nevertheless affected by, or at least correlated with, where and how people live.
However, segregation is of interest for reasons beyond its effect on inter-group contact. From an economic perspective, segregation also charts the spatial expression of inequality within modern society. Recent work has demonstrated that there is a linkage between the extent to which a country’s urban areas are segregated and the intensity of more general inequality within that society (van Ham et al. 2015; Jones et al. 2018a, b). Against this backdrop, a large literature reports the often negative associations against which segregation is judged. Nevertheless, there may also be important positive aspects to segregation with the provision of culturally specific services, access to specific facilities, and strengthening in-group identities, as noted in the work by Merry (2016) and Merry and colleagues (2016).
In seeking to better understand how we should conceptualise segregation, Massey and Denton (1988) proposed five dimensions along which segregation had been be measured—evenness, exposure, concentration, centralisation, and clustering. These dimensions have been extensively explored in the literature and form the basis for much of the current discussion, debate and analysis. However, despite the fact that we have long had these five dimensions to measure segregation, there has been much debate—but little clarity—about how to operationalise them. Indeed, there has been substantial disagreement about which indices to use and how they should be reported. This is well-trodden ground, and we have no wish to rehearse these extensive debates. Rather, we note that the index of dissimilarity (Duncan and Duncan 1955) has been the most commonly used. Therefore, it represents a common standard against which the other indices and any new interpretations are judged. As we discuss below, there remain issues with reporting the index of dissimilarity, although some authors have explored adaptions to consider how to derive more information from the measure (Allen et al. 2015; Harris 2018). These become problematic when we set out our conceptual approach to segregation.
In this chapter, we explore some of the conceptual issues that have driven the recent wave of segregation research, drawing on multilevel modelling methods, to capture the multi-scale nature of segregation and to separate out the degree to which different population attributes (e.g. ethnicity and occupation) are the drivers of residential separation. So far, all of the studies that have used our multilevel modelling method for measuring multi-scale segregation have focused on cities in the USA, Europe, Australia, and New Zealand. There has been very little work of any kind measuring segregation at multiple scales in China. We argue that by adopting this approach and exploring China, we can gain important insights to help enrich segregation research within the Chinese context, and also inform policy responses. The development of Chinese cities has been faster and more extensive than in Western cities, necessitating context-specific work to understand the scale at which segregation occurs, where it occurs and for whom it is greatest. In doing so, we can enable researchers to understand urban development in China better and equip policy makers with insights to target their policies better.
We start by setting out our conceptual framework in the form of a series of propositions that capture the various theoretical reasons why a multilevel approach to segregation is advantageous. We then illustrate how this approach can be applied to China using census data on Shijiazhuang, the capital city of Hebei Province. We use the model to consider segregation at multiple spatial scales for different population groups. We conclude with a discussion of our findings and our thoughts on future directions for research.
2 Conceptual Framework
Until recently, segregation studies have, in general, proceeded with a clear set of well formulated, but often implicitly placed, assumptions which it is necessary to explore in detail. Against this background lies a set of assumptions we wish to scutinise. We start by exploring ideas of scale (Propositions 10.1 and 10.2) and then consider how to explore segregation in highly diverse and complex modern urban environments (Propositions 10.3–10.5).
Proposition 11.1
Segregation is not always greater at finer spatial scales: how traditional measures of segregation conflate segregation at different spatial scales.
It has long been concluded within the segregation literature that a city divided into finer spatial scales (that is, smaller neighbourhoods) will have a greater level of segregation than those with larger neighbourhoods. For instance, Logan et al. (2015) noted in a study on the emergence of ghettos in New York from 1880 to 1940 that the purpose of their work was ‘not to demonstrate that segregation is higher at a finer spatial scale, which is already well known’ (p. 1077). However, this apparent conclusion may not be a result of the spatial organisation of individuals within modern urban society but the consequence of a methodological choice. A long time ago, Duncan et al. (1961, p. 84) observed ‘[i]f one system of arealFootnote 1 units is derived by subdivision of the units of another system, the index computed for the former can be no smaller than the index for the latter.’ They go on to state that ‘[…] the index of concentration on a county basis will exceed the index on a state basis, because the county index takes into account intrastate concentration’. Therefore, the inherent rule that the finer the scale, the greater the segregation is, in fact, a rule of index calculation and not related to the distribution (i.e. the segregation) of people across space.
This methodological issue has been written about extensively elsewhere within the quantitative social sciences (see, for instance, Kish 1954; Johnston et al. 2016a, b). Tranmer and Steel (2001) identified that when processes are occurring at multiple scales it is crucial to incorporate all these levels into the analysis. If a level is omitted, then the variationFootnote 2 related to that level ends up in the lowest level included in the study. Therefore, if this finding is applied directly to the segregation literature and, for instance, there is higher-level segregation in the urban environment which is not included in the analysis, then all the segregation from higher processes is shown in the index for the lowest level included. The implication of this is that low level (micro-scale) segregation will often be over inflated, in turn leading to the belief that the finer the scale, the greater the segregation. In other words, if segregation is measured at the micro, meso and macro scales then the resulting segregation should report only micro segregation at the micro level, only measure meso segregation at the meso level, and so on (see, for instance, Jones et al. 2015; Manley et al. 2019). When using the standard descriptive indices, this is not what happens because, as Duncan et al. made clear and Tranmer and Steel further exemplified, the values at one scale are conflated with the values at other scales.
More broadly, there is a strong theoretical case for including multiple spatial scales. We suggest that it is highly likely that in any given urban space segregation processes are likely to be occurring at multiple spatial scales. Individuals (or households) sort themselves into different parts of the city based on various sets of criteria and availability. It might be that some groups (ethnic, occupational, cultural, and so on) associate themselves with regions or large areas within the city, and then smaller or more compact neighbourhoods within that wider area (Harris 2018). These smaller neighbourhoods may or may not be contiguous depending on the characteristics and diversity of the urban landscape and the transitions between locations (Dean et al. 2019). Uncovering these spatial processes is critical to an understanding of the urban environment and the structure of the influences on the data, leading to a multitude of methodological challenges and outcomes (see Manley et al. 2006; Jones et al. 2018b).
Once we have included multiple spatial scales, we must also have the means to separate out the relative contribution of each scale to the overall level of segregation. Being able to do so is useful for two reasons: Firstly, it is useful from a process point of view: to understand what causes segregation it is necessary to know at which scale it is at its most intense. Secondly, even if the focus is on the impact of segregation on residents’ decisions, a knowledge of the source of segregation may be instructive for policies used to ameliorate those effects. The way in which policy would tackle genuinely high micro segregation, which pertains to a particular street, differs from the interventions needed to reduce segregation from higher-level structures such as full suburbs, towns or even labour markets.
Previously, Harris (2017) has demonstrated this with a decomposition of the index of dissimilarity on aggregated data, and what we present below offers a modelled approach. More explicitly, a multilevel model makes it possible to explicitly identify the amount of variance (that is segregation) located at each scale while ensuring that the variances at the other scales present in the model do not contaminate it. Without the modelling framework, it is not possible to identify the net contributions from each scale and establish whether segregation is ‘necessarily’ greater at micro-scales.
Proposition 11.2
Aggregation of areas reduces segregation, but that does not mean higher-level segregation is lower!
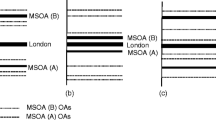
The idea of investigating geographical phenomena across many scales is not a new idea—it has appeared in the literature for many years (for recent examples see Reardon et al 2008; Östh et al. 2015). Often the data used for this work is derived from Population Censuses (in the UK and US at least).Footnote 3 For issues of privacy, these data are routinely aggregated from individuals into progressively larger areal units, from the smallest basic spatial units, through meso geographies, into larger, more regional (macro) scale units. The increasing size in terms of spatial extent and population count can be problematic for segregation measurement because the aggregation process fundamentally alters the objects being studied (see Fig. 10.1).

The hierarchical nature of segregation: members of two ethnic groups are shown by red and blue dots respectively. On the left hand side, the resolution is preserved with the addition of neighbourhood areas from small units (top) to higher-level units (bottom). By contrast, on the right hand side the population appears much more segregated when mapping by the dominant ethnic group at the same two scales
King (1996) notes that this demonstrates that scale (in terms of the modifiable areal unit problem: see Manley 2014 for details) is a theoretical and conceptual issue rather than an empirical one: scale changes, so the meaning of these changes units alters. At the individual level (or scale of the smallest areal unit), there will be sharper differences between areal units. In the case of a smaller population, it does not require a substantial change in population to alter the composition of an area dramatically, or for adjacent areas to be dramatically different in their composition. All other things being equal, at smaller scales, internal homogeneity will be higher across many variables than at higher scales.
As the areal units become larger, the population becomes more heterogeneous. It is likely that there will be the outcomes of multiple processes contained within a unit (see Manley et al. 2006). Moreover, the changes in population required to make any meaningful change to the composition of the area will need to be bigger compared with the smaller areas, and small clusters will be lost. Ultimately, as the units approach the same spatial scale as the total study area, so the composition of the unit(s) will also reflect the totality of the study area: the population of the areal units and the city will be the same (see Olteanu et al 2019).
Therefore, combining the smaller units together ‘smooths’ the differences in the data towards the overall mean of the study space. As segregation is the uneven distribution of individuals across space such ‘smoothing’ will in turn reduce the potential for segregation because the potential for uneven distributions is also reduced. This will again contribute to the apparent reduction in segregation with higher spatial scales.
How should multiple scales be incorporated into the study of segregation in urban areas? We suggest that one objective should be the preservation of the individual-level data as far as possible, or if data is not available at an individual level, then the smallest areal unit scale. To achieve that, we move away from aggregating data to different and alternative spatial scales and treat scale as a series of ‘hierarchical loops’ around individuals in the survey areas. As such, we explicitly recognise that the investigation of segregation in urban areas is about the organisation of individuals over space and within bounded areas, but not the aggregated proportions of those structures. In doing so, the initial resolution of the data is preserved. Any changes in magnitude result from segregation processes and not a product of the statistical process(es) used when constructing the dataset.
Proposition 11.3
Measures of segregation need to be able to deal with the multigroup complexities of modern urban environments , and determine if differences are meaningful.
One of the main problems with traditional measures of segregation, such as the index of dissimilarity, is that they limit the number of groups that can be compared to just two. If there are many groups we want to compare, and we can only compare two at a time, we end up with an enormously cumbersome set of statistics that are very difficult to interpret. For example, if we want to compare the segregation of all 23 ethnic groups in the UK, and we can only consider two at a time, we end up with over 500 measures of segregation. These pairwise approaches to measuring segregation made sense in the originally developed context, namely Black-White segregation in the USA (Park et al. 1925; Duncan and Duncan 1955). However, their usefulness is much more limited in the diverse cities of the twenty-first century.
Once we are able to determine more clearly the relationships for many groups (for instance, ethnic, occupational or educational) within the urban environment, we then need to be able to examine whether or not the differences between the distributions are meaningful. One of the major issues within the segregation literature is that even relatively small alterations in the distribution of individuals result in different values on many of the indices, especially with data at micro-spatial scales. If we measure segregation by modelling the data (rather than reporting descriptive values), we can also estimate the uncertainty associated with our estimate by testing statistical significance.Footnote 4 We can calculate, for example, how likely it is that changes to our measure of segregation occurred by chance, rather than as the result of a genuine socio-demographic process. There is an argument that significance testing is not relevant because we are using full population data or the inherent problems in using arbitrary significance values (Wasserstein and Lazar 2016). However, in the context of segregation modelling significance testing remains useful for exploring uncertainty and to depict similarities between distributions. Using significance (or Bayesian Credible Intervals) firstly allows the investigation of substantial differences in levels of segregation between populations, and secondly reveals if there are such differences across (multiple) groups. Even when it is clear that the data include the full population, the distribution of individuals across urban space is only one example of the potential distribution ‘universes’ that they could take. So there remains the question of whether the particular spatial pattern of segregation we observe at a particular point in time is the result of random population churn or the outcome of a systematic ‘sorting’ process (such as homophily or White Flight—see Chaps. 2, 4, 12 and 15). As a result, testing the robustness of the distribution, and the likelihood that our estimate is random, is a useful addition to the information about segregated outcomes.
Proposition 11.4
Intersectionality matters: individuals do not have single group identities.
Our discussion has so far assumed that when investigating segregation, we are only interested in a single dimension—perhaps between ethnic groups or occupational status. Suppose we reduce our analysis of ethnic segregation to a simple majority/minority dichotomy, and leave out highly relevant dimensions such as class, occupation or age. In that case, we restrict our understanding of the urban social environment. As a practical example, a criticism levelled at research into residential ethnic segregation is that it tends to identify exclusion based on social class and income rather than any ‘genuine’ ethnic basis. The housing market sorts people by income levels and so if particular ethnic groups have significantly lower income levels than others they will inevitably be priced out of more expensive areas. It is, of course, possible to calculate indices of segregation for multiple dimensions and report the findings alongside each other. However, as with the issue of scale discussed above, they are conflated when calculating these indices separately. So how do we know, from conventional measures, the extent to which we are gauging the degree of income segregation rather than ethnic segregation? When attempting to understand both the state of the urban environment and the drivers of segregation, the ability to unpick the entanglement of multiple influences is critical to further our understanding. We can approach segregation from an intersectional viewpoint where multiple sites of discrimination are identified (Crenshaw 1990; Jones et al. 2018a, b). This observation takes us to our next proposition:
Proposition 11.5
Segregation occurs across many different domains, both daily and across the course of a lifetime.
Space matters! The location of groups and individuals within the urban fabric matters. Many standard descriptive measures of segregation do not take account of space. For example, the index of dissimilarity does not consider the proximity of areas with similar residential composition. This means that clusters of neighbourhoods with similar population characteristics will go unnoticed by the index. More generally, it means that if the areal units that comprise a city were completely reorganised (hypothetically), the same segregation result could be achieved even though the pattern had been altered (this is known in the segregation literature as the checkerboard problem: see Wong 2004). This can occur when the measure excludes the importance of space and works under the assumption that proximity of areas with similar or contrasting features is of no consequence. This is clearly an unrealistic assumption. The clustering of neighbourhoods with high levels of deprivation (Chap. 14) can severely inhibit life chances (see the work of Galster and Sharkey 2017 summarised in Chap. 15). Note also the emerging literature on the impacts of ‘social frontiers’ which arise when highly contrasting neighbourhoods are contiguous (see Chap. 13 and Dean et al. 2019).
We therefore need to ensure that the measure of segregation we use includes at least some form of spatial dependency. However, this insufficient it itself, because as well as taking account of the spatial structure of the urban environment we need to understand the detail of the group locations. For instance, in a city with many ethnic groups, we want to know if they are segregated from the majority population and if they are segregated from each other—that is, if they are co-located or antagonistically located. It is possible to discern similar levels of segregation or spatial dependency, but still not report information on co-location. The ability to explore this aspect is crucial, given that the potential for contact has long been identified as a critical issue in the development and maintenance of group acceptance (see Allport et al. 1954).
3 Exemplifying Multilevel Segregation—Shijiazhuang, China
So far, all the studies that have used our multilevel modelling method to measure multi-scale segregation have focused on cities in the Global North and Australasia. In fact, there has been very little work of any kind to measure segregation at multiple scales in China. In the absence of such work there is clearly an important lacuna in the literature and our understanding of socio-spatial segregation in Chinese cities. To illustrate how our multilevel modelling method can be useful for increasing understanding of the multi-scale patterns of segregation in a Chinese city, we use data from the Chinese census for the city of Shijiazhuang to answer two research questions. Firstly, we ask how residentially segregated the different ethnic groups are in Shijiazhuang? Secondly, we investigate the degree of segregation among Chinese migrants into Shijiazhuang and how this is changing over time. Shijiazhuang is an industrial city, which has experienced rapid population growth over the past 30 years. It is situated on the North China plain (see Fig. 10.2), around 300 km southwest of Beijing, and is the largest city and capital of Hebei Province with a total population of around 11 million across the prefecture (by the end of 2019).

Study area of Shijiazhuang (shaded black) within Shijiazhuang prefecture within Hebei Province
Measuring the multi-scale nature of segregation requires accessible multi-scale data. The lack of (scalar) data may therefore limit the uptake of this approach especially in countries with data infrastructures that are not as rich spatially nor as detailed demographically as in the Global North. In China, however, such data exists, although, as we discuss, with the important caveat that it is not always accessible to researchers.
Figure 10.3 shows China’s six-tier administrative structure, which also provides the levels at which census data is compiled. Large urban areas which generally are of the most interest to segregation researchers are typically either prefecture-level cities or centrally administered municipalities. However, it is important to be aware that these administrative divisions usually contain more expansive surrounding rural hinterlands as well as a city’s urban core and that the size of these rural areas varies across China. Consequently, researchers who wish to study residential segregation within a particular city, may need to produce an urban boundary that differs from the administrative boundary.

(adapted from Wu et al. 2014)
Administrative Structure of China
There are three scales within a large urban area—the district, the sub-district, and the residential community. In the past, these have been likened to size to the UK spatial units of local authority, Ward and Lower Super Output Areas (LSOAs), respectively (Wu et al. 2014). However, such comparisons are unhelpful because the conceptual and spatial meaning behind the units are somewhat different. Any study that takes them as equivalents to make scalar comparisons between British and Chinese cities would be misleading.
In our example, we select the five districts (Chang’an, Qiaodong, Qiaoxi, Xinhua and Yuhua) that broadly correspond to the urban area of the wider city. We used satellite imagery combined with local knowledge to decide the boundaries, reducing the prefecture population of 10 million to a core of 2.7 million inhabitants. As five units are insufficient for reliable multilevel modelling, we do not include this level in our analysis of Shijiazhuang. Even with two levels (the sub-district and the residential community) the evidence we present still provides an improvement on the single scale literature which generally implements either the community or the sub-district scale (Wu et al. 2014).Footnote 5 Within these five districts there are 49 sub-districts and within these are 450 residential communities. The size of each unit varies both between and within cities/regions, but in our data each district has an average of around 675,000 inhabitants, each sub-district 45,000 and each residential community 6,000.
One of the main reasons researchers have used the sub-district as the unit of analysis in segregation studies, particularly when comparing multiple Chinese cities (e.g. Monkkonen et al. 2017), is obtaining data at the residential community level can be difficult, even within China. For the 2000 and 2010 censuses, the sub-district is the lowest level at which the National Bureau of Statistics has released official census data, while data on residential communities is often only available unofficially from local organisations. This is clearly a barrier to the uptake of the multilevel modelling method and segregation studies generally, as when used alone, sub-district data is too coarse to learn anything detailed about the magnitude of segregation for different groups in the city.
The inclusion of additional data from the smaller residential community scale has much to contribute to segregation studies in Chinese cities, for this very reason. Such representation of Chinese communities also offers an advantage over census collection units such as those in the UK and other European countries, in that they are units of local administration and, in many cases, units at which important aspects of social life are organised (Chen, Lu and Yang 2007). Adopting this scale allows us to implement the study at the level of a spatial process that is beneficial in terms of understanding segregation (see Manley et al. 2006; Jones et al. 2008). Furthermore, many communities are gated, creating a clear physical boundary (Xu and Yang 2009). In many urban areas, due to high population densities in high-rise buildings, the geographical space in which 6,000 people live is more compact than in many urban areas many Western cities. This is not to say that these communities are necessarily the perfect unit of analysis for a segregation study. Through urban renewal, housing estates are gradually replacing the work unit residential areas and traditional housing on which the residential communities are based. The newer housing estates across Chinese cities may provide a more appropriate setting for the study of concepts like community and neighbourhood and are often smaller than the administrative residential communities.
4 Ethnic Residential Segregation
While the residential segregation of ethnic groups is the focus of many segregation studies in Europe and North America, this issue has received less attention in China. This is predominantly because in most large cities, despite the existence of 56 officially recognised minority groups, the proportion from ethnic minorities is low (see Table 10.1 for the ethnic population in Shijiazhuang). In cases where there have been low numbers from ethnic minorities, it has been argued that there is insufficient difference to create distinct social areas within the city, and therefore, ethnic residential segregation is not traditionally considered a problem (Li and Wu 2008). However, even when numbers are small, understanding how different minorities locate within a city at different scales can help ascertain the level of integration across different ethnic groups and whether certain groups may be disadvantaged. An income gap exists between the minority and majority populations, and the importance of the inclusion of minorities in China’s economic reforms has been highlighted as a key challenge for the country’s future development (Cao 2010).
Of course, segregation, particularly at small scales, may offer certain benefits for ethnic minorities. This could be, for example, through enabling them to maintain their cultural heritage, providing social community support or access to specific services relevant to the group. Nevertheless, other aspects of segregation are negative, particularly if a group is clustered in deprived areas or distant from employment and education opportunities. Segregation at different scales may well bring varying advantages and disadvantages for different ethnic groups. Therefore, it is important to find methods to measure segregation at more than one scale within the city.
Previous studies of the segregation of ethnic minorities within China have tended to consider very coarse spatial scales and focused on how ethnic groups are distributed throughout a province or even throughout the whole of China, rather than within a specific city (e.g. Wong 2002; Cao 2010). Those that focused on particular cities, have looked at ethnic enclaves of foreigners such as Africans, rather than segregation of Chinese ethnic minorities (e.g. Zhang 2008).
We have already highlighted a set of propositions relating to the study of segregation. The multilevel modelling method we adopt here allows us to address each of these propositions, within the constraints of the data we are using. For this example, we build on the work of Jones et al. (2015; see also Manley et al. 2015; Johnston et al. 2018) and use multilevel modelling to explore the segregation of Chinese ethnic minorities within a Chinese city at the finest spatial scale, the residential community, while also considering a larger spatial scale, the sub-district. Our models can handle multiple groups within a single model without the need for a reference category, and produce correlations at each scale between the different groups.
To measure segregation, we calculate MRRs or Median Rate Ratios. These are transformations of the variance estimated at each spatial scale in the multilevel models and are useful as they provide standardised rates with which to make comparisons. The MRR is defined as ‘the increased rate, (on average; hence, the median) if one compares the rates of two [residential communities] chosen at random from the distribution with the estimated variance’ (Jones et al. 2015, p. 2001). If there was no segregation the MRR would be equal to one and the higher the MRR the greater the segregation. To aid interpretation, we use the MRRs as analogous to odds ratios and adopt the heuristic proposed by Cohen (1988). Values below 1.5 are considered low, between 1.5 and 2.5 are medium, between 2.5 and 4.3 represent high and above 4.3 is considered very high.
Results
Table 10.2 reports the MRRs and associated Bayesian Credible Intervals for segregation by ethnicity at both the sub-district and residential community level. While ethnic residential segregation exists at both scales, two exceptions are greater at the residential community level. This is the case for nine out of the ten ethnic groups and for five of these groups the MRR is more than 50% greater at this smallest scale. The results are visualised in Figs. 10.4 and 10.5 to highlight the range of credible intervals and demonstrate that at the Sub-District level there is little difference in the values (with the overlapping bars). At the residential community level, however, there are three clear groups. The Mongolian, Hui and Manchu—along with the majority Han—are the least segregated, while the Tujia, Korean, Zhuang and Miao are more segregated, and the Yi and Tibetan are the most segregated.

Graphical Distribution of the MRRs at the Sub-district level

Graphical distribution of the MRRs at the residential community level
At this residential community scale, the results show substantial segregation. All the ethnic minorities have an MRR greater than two meaning that if two residential communities were picked at random, the rate for the higher residential community would, on average, be at least twice that of the lower community for all ethnic groups. There is also large variation in the MRRs at the residential community level between the ethnic minority groups, ranging from the Manchu with an MRR of 2.19 to the Yi (MRR = 7.76). In particular, the larger ethnic minority groups, such as the Manchu and Hui (MRR = 2.21), of whom there are more than 15,000 individuals, are much less segregated than the smaller ethnic groups such as Yi and Tibetan (MRR = 7.28) of whom there are less than a thousand. Indeed, the correlation between size of ethnic group and level of segregation at the residential community level is 0.7.
At the township level (sub-district), segregation is lower and the range of MRRs is much smaller ranging from 1.49 (Tujia) to 2.53 (Hui). The Hui ethnic group appears to be an exception to the general rule. The segregation of this group is higher at the sub-district scale than at the residential community scale, although not significantly statistically. In fact, the Hui appear to exhibit a completely different pattern of segregation, being the second least segregated at the residential community level but the most segregated at the sub-district level. This may reflect the fact, that the Hui are different from other ethnic groups in that their unique identity is based around their Muslim religion rather than local customs and language. Additionally, compared to the other ethnic groups, which have highly localised distributions within China, the Hui are much more widely spread out across the country (Wong 2002), and therefore possibly more heterogeneous in their cultural background. Because of these factors, the key drivers of where they locate within a city may well be different, with, for example, the location of mosques within the city, likely to play an important role.
Using the MRRs as the only measure of segregation, one would conclude that the segregation of ethnic minorities in Shijiazhuang was very high. It is important to remember, however that ethnic minorities are extremely rare in the population. In fact, the numbers are so low that despite this large unevenness in their distribution, there are no residential communities at all where more than 10% of the population are ethnic minorities of any kind.
The multilevel modelling method treats segregation as deviation from a theoretical evenness of the population. However, another way of measuring segregation is by exposure—defined as the degree of residential contact with majority groups (see Massey and Denton 1988, and as noted in the introduction). In contrast to the evenness measure, if we had measured segregation using the concept of exposure, we would likely have concluded that ethnic minorities are not particularly segregated. These different dimensions of segregation are important to consider when thinking about the societal implications that may result. While the numbers are very low for Shijiazhuang, this is not actually true for all cities in China. For example, in Beijing there are over half a million inhabitants from the ethnic minorities (National Bureau of Statistics 2005).
Table 10.3 shows the correlations between the ethnic groups at both spatial scales. These allow us to see which groups tend to co-locate and if there are any groups that are separated geographically. The main message from these correlations is that, generally, ethnic minorities locate in both the same districts and the same communities as other ethnic minorities. Out of 36 possible pairs of ethnic groups at each level, only three are negatively correlated at the residential community level and only four at the sub-district level.
The strongest correlations at both levels are between Mongolians and Manchus with the correlation between these groups as high as 0.8 at the residential community level. Interestingly, as both these ethnic groups are also moderately to strongly correlated with the Hui, it seems that it is the largest minority groups that tend to locate together more. To understand more about the possible implications of this, further research could investigate other characteristics of the communities where multiple minority groups are found. For example, it would be useful to know if the different minorities are choosing to live in these communities because they have desirable characteristics for minorities, or whether, instead, they live there by default, perhaps for reasons of poverty, lack of opportunity or discrimination. Furthermore, although not all ethnic minorities are migrants, the segregation of minorities may be linked with the segregation of migrants which is the focus of the second research question.
5 Segregation of Migrants
In recent decades, many Chinese cities have grown rapidly, in large part due to high numbers of migrants arriving from rural areas. Past research has suggested that these migrants are often segregated within their host cities from the local population, both geographically and socially, in terms of the activities in which they partake in their daily lives (Zhu et al. 2017; Zhao and Wang 2018). Many rural migrants arrive in cities with low levels of education and skills and can be further disadvantaged by institutional factors such as lack of local registration status or hukou. Of particular relevance to segregation is that in some cities, the lack of local hukou status has meant restricted access to local services, including housing (Wang and Zuo 1999; Chan 2010). This is important as past research has shown that settlement patterns significantly determine the future socioeconomic standing of migrants (Wu 2014).
Past studies have attempted to quantify the segregation between migrants and local populations in Chinese cities (e.g. Li and Wu 2008, 2016); however, there is little research into the scales at which this segregation exists and how the extent and patterns of segregation exist have changed over time. Migrants are likely to be a highly mobile group both within cities and between cities and rural areas (Wu 2006). Over time more arrive, some return to their place of origin while others who have stayed a long time potentially become more integrated into the city. It is therefore likely that the segregation of migrants within cities is constantly in flux due to a multitude of processes. By measuring whether the spatial separation of migrants and locals is widening or decreasing, and at what scales this is happening, we can contribute to wider research around the extent to which migrants are excluded from the social benefits of China’s rapid economic development (Li 2005; Li and Rose 2017).
In this example, we model the segregation of migrants compared to local Shijiazhuang residents at both the Residential Community and the Sub-District scale at two time points, 2000 and 2010, to explore changes over time. One important challenge in doing so is that there is no official definition of whether an individual is a migrant or not in the Chinese census. To overcome this, we therefore identify whether an individual’s hukou registration status is in the sub-district in which they live. Although this is an imperfect definition of migrants (as it includes those who have hukou status in nearby sub-districts who would probably not usually be considered as migrants) it is a definition which has been previously employed in segregation studies and is the best available given the data (Li and Wu 2008). It is also important to note that migrants are also likely to be a highly heterogeneous group. As well as the rural migrants we have discussed, there will also be highly educated migrants from other urban areas who have moved for specific economic or social reasons.
As well as the obvious advantage of enabling the study of multi-scale segregation, our modelling method offers an additional benefit. Because we model segregation rather than create a descriptive index, we can measure the uncertainty around our segregation estimates. This allows us to assess whether or not any changes from 2000 to 2010 are systematic changes in segregation levels or if they are simply a random variation. Conducting this research in a medium-sized city such as Shijiazhuang is also of interest as most studies into the segregation of migrants have assessed megacities such as Beijing and Shanghai. It is likely that some of the drivers of segregation are stronger in these megacities as competition for land is higher and the importance of the hukou system in terms of access to housing has historically been stronger (Monkkonen et al. 2017).
The results (Table 10.4) highlight that although there is segregation at both the Residential Community and the Sub-District, it is greater at the lower residential community scale. In 2000 and in 2010, the MRR at this scale is approximately two indicating no change over time (especially as the credible intervals overlap). However, at the sub-district level, there is a change with the MRR increasing from 1.40 to 1.70. Unlike the residential community results, this reflects a non-trivial amount of change—the difference between the sub-district and residential community level MRRs has halved. These results show that while the evenness of the distribution of migrants across residential communities is unchanged, the residential communities with more migrants are now more likely to be found clustered in the same larger areas (sub-districts) of the city. This pattern holds for the non-migrants as well, although the MMRs for this group is lower than for the migrants indicating less segregation. Moreover, the differences between the groups are significant, demonstrated by the lack of overlap in the credible intervals.
6 Discussion
Our empirical application has investigated the segregation of different ethnic groups and of migrants versus non-migrants. These two examples show how our multilevel modelling method can be used to increase understanding of segregation in a Chinese city. Both demonstrate how we can measure and report segregation at multiple scales. The ethnic minority example looks at how the method is easily adaptable to multiple groups and the migrant example shows how it is useful for analysing change over time. The results reveal that in Shijiazhuang segregation is highest at the smallest scale but is also present at higher scales. As we have only studied a single city, future work in other cities is necessary to explore whether these patterns are typical. In particular, comparisons with megacities such as Beijing would be fruitful to explore if Sassen’s Global City framework (Sassen 2001) applies in the Chinese context. More longitudinalFootnote 6 work would also extend our knowledge.
The method can clearly be used to study other aspects of segregation in China. Socioeconomic segregation based on occupation and education levels is also prevalent in Chinese cities and could easily be studied with this method (Li and Wu 2008; Wu et al. 2014). It would also be possible to take our approach further by looking at the intersection between different types of segregation, as Jones et al. (2018a, b) have done in Sydney, Australia. Our method also makes it possible to answer questions around whether migrant status or socioeconomic status has a greater influence on segregation levels or whether segregation is greater for poor migrants or rich migrants. This can contribute greatly to our understanding of socio-spatial inequalities within cities.
A deeper understanding of segregation in Chinese cities is critical for policy developments. China has urbanised rapidly: in the 20 years up to 1990 the proportion of the population living in cities rose from 17.9% to 26.4% (Wei 1994) while figures from the end of 2017 suggest it has reached almost 60% (see Xiao et al. 2018). The speed and scale of urbanisation presents theoretical and empirical challenges and it is likely that current theories of urban development will not fit or explain the process or their rapidity sufficiently. Elsewhere in this volume (Chaps. 2, 3 and 15) the issue of marketisation as a driver of segregation has been identified: when households have the ability to select their neighbourhoods and homes or when housing markets become increasingly differentiated so that selective sorting into neighbourhoods occurs. As these neighbourhoods contain similar households and have amenities and characteristics reflecting residents’ desired lifestyle status (see Schelling 1969; Clark 1991), they increase segregation. Moreover, marketisation often brings with it problems of affordability and access and an understanding of how these issues occur in Chinese cities, will aid our understanding of segregation. However, within the literature of wider urban geography, relatively little is known about the organisation of Chinese cities compared to the voluminous research on US, European and other Western cities. Consequently, we know relatively little about which spatial scales are the most important for measuring and addressing residential segregation.. It is well known from the research literature worldwide that the size and scale of urban development is an important factor in the composition and structure of urban neighbourhoods (see Petrovic et al. 2018). As Chinese cities are often far greater in size than those in the West, then spatial structures are likely to extend over larger areas. However, we do not know what the impacts are on life outcomes of different scales of segregation. Recent advances in the neighbourhood effectsFootnote 7 literature will potentially make this possible in future (e.g. Manley et al. 2020).
In the context of rapid urbanisation and increasing urban expansion, it is essential to identify scalar segregation at local levels in order to gain useful policy insights. It might be that the implications of segregation—in terms of potential harm to well-being, education or social functions—occur irrespective of scale, in which case this questions the necessity for detailed local analysis. Successful policy interventions rely on the identification of the scale where they are likely to be most effective. If segregation is greatest at the micro-scale, for instance—a scale which often relates to specific dwelling choices rather than to larger neighbourhoods—then successful interventions are likely to be more targeted. As a case in point, the Hui are the only ethnic group in China that identify as Muslims and therefore, it is likely that they will locate near mosques. Other ethnic groups will show preferences for co- or close location with other specific services and facilities. Such micro segregation would be missed if the analysis is only undertaken at a macro level. Larger scale segregation, in contrast, may derive from restricted access to the housing market, either in relation to their migrant status (hukou) or because the type and cost of housing are prohibitive in those parts of the city.
Unfortunately, while these possibilities are exciting, there are also limitations, primarily in relation to data access. As discussed, data at the residential community level is often difficult to obtain and cross tabulations are likely to be even more difficult for researchers to obtain. For instance, data on both the number of migrants in a community and the number of people working in different occupations were available in our example, but not the number of migrants working within specific occupational groups. The sub-district level is the lowest at which we have cross tabulations. In this case, we can still use the multilevel modelling technique to look at whether migrants are more likely to be located in communities and sub-districts of high or low socioeconomic status. We cannot say, however, whether this is because the migrants themselves have high or low SES or whether they are simply likely to locate in the same areas. It may also be, as discussed above, that our community and residential scales are not the most appropriate for future work. In many Chinese cities, new housing estates are more appropriate subjects for studying concepts of community and neighbourhood. As these are typically smaller than the residential committee administrative areas we studies, they may represent a scale at which it will be even harder to obtain data.
Although there remain considerable challenges in the deployment of comparable data, the adoption of a modelling approach can also improve comparisons of segregation between countries. Past research has tried to do this with mixed results. One study suggested that segregation is much lower in China than in cities in Europe and North America (Li and Wu 2008), while another study (Monkkonen et al. 2017) using data from the same point in time, concluded the opposite, reporting that several of the largest Chinese cities are now more socioeconomically segregated than the most segregated American cities. Trying to make such comparisons is problematic, due to differences in how segregation is measured and differences between the countries studied. As an area spatial unit, the Chinese residential community is not necessarily comparable with any geographical unit elsewhere. Although multi-scale segregation methods do not necessarily solve these problems, they are helpful in a couple of ways. Firstly, they help us think critically about any comparisons with segregation indices in Europe and beyond by explicitly bringing attention to scale impact. Secondly, they can help us build up a more detailed multi-scale profile of segregation in a city which can at least be qualitatively compared with profiles in cities in other countries.
Studies using the multilevel method in London, UK and Sydney, Australia have shown, in general, greater segregation at micro and macro scales with little segregation present in the in-between meso scales (Jones et al. 2015; Johnston et al. 2016a, b). In Shijiazhuang we only have two scales and have shown that segregation is greater at the lower level. Drawing comparative conclusions is difficult. The smallest scale in the Chinese data we use is akin to the meso scales used in the UK and Australian studies. Suppose we map scales across national contexts using population size as our comparison measure. In that case, segregation is higher at the meso scale in Shijiazhuang than it is in London or Sydney. By contrast, it is lower at the macro scale. There is no smallest scale comparison possible because such data does not exist in China. Our results, therefore, do not allow us to make firm conclusions on whether segregation is greater or less in Shijiazhuang than in London or Sydney, but they do suggest that the nature of the segregation may be different.
Ultimately, the multilevel modelling method combined with the right data allows us to consider multi-scale segregation in Chinese cities for the first time. This approach is a range of quantitative approaches that can allow researchers to understand how different socioeconomic groups segregate within cities in China and beyond.
Notes
- 1.
In this chapter we refer to areal units and neighbourhoods interchangeably to refer to part of the town or city which has been grouped together. Although we also acknowledge that neighbourhoods have multiple meanings depending on the context in which they are being used (see for instance Talen 2018).
- 2.
It is useful to note at this stage that we regard variance as a measure of segregation. Within a city constructed out of many neighbourhoods each neighbourhood will deviate in population composition away from the overall city composition. This deviation can be measured in modelling by calculating the variance. It is, therefore, possible to assert the greater the variance the greater the segregation, because the greater the variance the more different a given neighbourhood will be compared to the city overall.
- 3.
Even when using data held in individual level population registers as is the case in The Netherlands or the Scandinavian countries, the aggregation process used to combine individuals into neighbourhoods (areas) is similar.
- 4.
- 5.
- 6.
Longitudinal research is based on repeated observations over time on a sample of individuals or geographical areas, as opposed to cross-sectional research which is based on data collected at a single time point.
- 7.
‘Neighbourhood effects’ is the name given to broad range of impacts on life outcomes caused by a person’s residential environment. Various features of the neighbourhood (housing, transport, exposure to crime and pollution, access to employment, amenities, health care, etc.) have been shown to affect childhood development, educational attainment, employment prospects and long-term health. See Chap. 15 for further discussion. See also reviews by van Ham et al. (2012), Galster and Sharkey (2017) and Graham (2018).
References
Allen R, Burgess S, Davidson R, Windmeijer F (2015) More reliable inference for the dissimilarity index of segregation. Econ J 18(1):40–66
Allport GW, Clark K, Pettigrew T (1954) The nature of prejudice
Cao H (2010) Urban-rural income disparity and urbanization: What is the role of spatial distribution of ethnic groups? A case study of Xinjiang Uyghur autonomous region in Western China. Reg Stud. https://doi.org/10.1080/00343400903401550
Chan KW (2010) The household registration system and migrant labor in China: Notes on a debate. Popul Dev Rev 36:357–364. https://doi.org/10.1111/j.1728-4457.2010.00333.x
Chen J, Lu C, Yang Y (2007) Popular support for grassroots self-government in urban China: findings from a Beijing survey. Mod China. https://doi.org/10.1177/0097700407303966
Clark WA (1991) Residential preferences and neighborhood racial segregation: a test of the Schelling segregation model. Demography 28(1):1–19
Cohen J (1988) Statistical power analysis for the behavioral sciences, 2nd edn. Lawrence Erlbaum Associates, Hillsdale, NJ
Crenshaw K (1990) Mapping the margins: intersectionality, identity politics, and violence against women of color. Stan L Rev 43:1241
Dean N, Dong G, Piekut A, Pryce G (2019) Frontiers in residential segregation: understanding neighbourhood boundaries and their impacts. Tijdschrift voor economische en sociale geografie 110(3):271–288
Duncan OD, Duncan B (1955) A methodological analysis of segregation indexes. Am Sociol Rev 20:210–217
Duncan OD, Cuzzort RP, Duncan B (1961) Statistical geography: problems in analyzing areal data. The Free Press, Glencoe, IL
Fowler CS (2015) Segregation as a multiscalar phenomenon and its implications for neighborhood‐scale research: the example of South Seattle 1990–2010. Urban Geogr 37:1–25
Fowler CS, Frey N, Folch DC, Nagle N, Spielman S (2020) Who are the people in my neighborhood?: The “contextual fallacy” of measuring individual context with census geographies. Geogr Anal 52(2):155–168
Galster G, Sharkey P (2017) Spatial foundations of inequality: a conceptual model and empirical overview. RSF: The Russell Sage Found J Soc Sci 3(2):1–33
Graham BS (2018) Identifying and estimating neighborhood effects. J Econ Lit 56(2):450–500
Harris R (2017) Measuring the scales of segregation: looking at the residential separation of White British and other schoolchildren in England using a multilevel index of dissimilarity. Trans Inst Brit Geogr 42(3):432–444
Harris R (2018) Developing a multilevel index of dissimilarity in R with a cases study looking at the changing scales of residential ethnic segregation in England and Wales between 2001 and 2011. Environ Plan B
Johnston R et al (2016a) The scale of segregation: ancestral groups in Sydney, 2011. Urban Geogr. https://doi.org/10.1080/02723638.2016.1139867
Johnston RJ, Jones K, Manley D (2016b) Macro-scale stability with micro-scale diversity: modelling changing ethnic minority residential segregation. Transa Inst Br Geogr NS 41(4):389–402
Johnston R, Manley D, Jones K (2018) Spatial scale and measuring segregation: illustrated by the formation of Chicago’s ghetto. GeoJournal 83(1):73–85
Jones K et al (2015) Ethnic residential segregation: a multilevel, multigroup, multiscale approach exemplified by London in 2011. Demography. https://doi.org/10.1007/s13524-015-0430-1
Jones K et al (2018a) Ethnic and class residential segregation: exploring their intersection – a multilevel analysis of ancestry and occupational class in Sydney. Urban Stud. https://doi.org/10.1177/0042098017730239
Jones K, Manley D, Johnston R, Owen D (2018b) Modelling residential segregation as unevenness and clustering: a multilevel modelling approach incorporating spatial dependence and tackling the MAUP. Environ Plan B: Urban Anal City Sci 45(6):1122–1141
Kavanagh L, Lee D, Pryce G (2016) Is poverty decentralizing? Quantifying uncertainty in the decentralization of urban poverty. Ann Am Assoc Geogr 106(6):1286–1298
King G (1996) Why context should not count. Polit Geogr 15(1):159–164
Kish L (1954) Differentiation in metropolitan areas. Am Sociol Rev 19(4):388–398
Lee D, Minton J, Pryce G (2015) Bayesian inference for the dissimilarity index in the presence of spatial autocorrelation. Spat Stat 11:81–95
Li B (2005) Urban social change in transitional China: a perspective of social exclusion and vulnerability. J Contingencies Crisis Manag. https://doi.org/10.1111/j.1468-5973.2005.00457.x
Li J, Rose N (2017) Urban social exclusion and mental health of China’s rural-urban migrants – a review and call for research. Health Place. https://doi.org/10.1016/j.healthplace.2017.08.009
Li Z, Wu F (2008) Tenure-based residential segregation in post-reform Chinese cities: a case study of Shanghai. Trans Inst Br Geogr. https://doi.org/10.1111/j.1475-5661.2008.00304.x
Li Z, Wu F (2016) Post-reform residential segregation in three Chinese Cities: Beijing. Shanghai and Guangzhou. In: Marginalization in Urban China. https://doi.org/10.1057/9780230299122_12
Logan JR, Zhang W, Chunyu MD (2015) Emergent ghettos: black neighborhoods in New York and Chicago, 1880–1940. AJS: Am J Sociol 120 (4):1055–1094
Manley D (2014) Scale, aggregation, and the modifiable areal unit problem. In: Fischer MM, Nijkamp P (eds) Handbook of Regional Science. Springer, pp 1157–1171
Manley D, Flowerdew R, Steel D (2006) Scales, levels and processes: studying spatial patterns of British census variables. Comput Environ Urban Syst 30(2):143–160
Manley D, Johnston R, Jones K, Owen D (2015) Macro-, meso-and microscale segregation: modeling changing ethnic residential patterns in Auckland, New Zealand, 2001–2013. Ann Assoc Am Geogr 105(5):951–967
Manley D, Jones K, Johnston R (2019) Multiscale segregation: multilevel modeling of dissimilarity—challenging the stylized fact that segregation is greater the finer the spatial scale. Prof Geogr 1–13
Manley D, Petrovic A, van Ham M (2020) Scale and spatial analytics: a sparc workshop. https://sgsup.asu.edu/sites/default/files/manley_scales3.pdf
Massey DS, Denton NA (1988) The dimensions of residential segregation. Soc Forces 67(2):281–315
McNeish D (2019) Poisson multilevel models with small samples. Multivar Behav Res. https://doi.org/10.1080/00273171.2018.1545630
McNeish D, Stapleton LM (2016) Modeling clustered data with very few clusters. Multivar Behav Res. https://doi.org/10.1080/00273171.2016.1167008
Merry M (2016) Equality, citizenship, and segregation: A defense of separation. Springer
Merry MS, Manley D, Harris R (2016) Community, virtue and the White British poor. Dialogues Hum Geogr 6(1):50–68
Monkkonen P, Comandon A, Zhu J (2017) Economic segregation in transition China: evidence from the 20 largest cities. Urban Geogr 38(7):1039–1061. https://doi.org/10.1080/02723638.2016.1195992
Olteanu M, Randon-Furling J, Clark WA (2019) Segregation through the multiscalar lens. Proc Natl Acad Sci 116(25):12250–12254
Östh J, Clark WAV, Malmberg S (2015) Measuring the scale of segregation using k-nearest neighbor aggregates. Geogr Anal 47(1):34–49
Park E, Burgess E, Mckenzie R (1925) The city: suggestions for investigation of human behavior in the urban environment. University of Chicago Press, Chicago, IL
Petrović A, van Ham M, Manley D (2018) Multiscale measures of population: within-and between-city variation in exposure to the sociospatial context. Ann Am Assoc Geogr 108(4):1057–1074
Reardon SF, Matthews SA, O’Sullivan D, Lee BA, Firebaugh G, Farrell CR, Bischoff K (2008) The geographic scale of metropolitan racial segregation. Demography 45(3):489–514
Sassen S (2001) The global city: New York, London. Princeton University Press, Tokyo
Schelling TC (1969) Models of segregation. Am Econ Rev 59(2):488–493
Talen E (2018) Neighborhood. Oxford University Press, Oxford
Tranmer M, Steel DG (2001) Ignoring a level in a multilevel model: evidence from UK census data. Environ Plan A 33(5):941–948
van Ham M, Manley D, Bailey N, Simpson L, Maclennan D (2012) Neighbourhood effects research: new perspectives. In: van Ham M, Manley D, Bailey N, Simpson L, Maclennan D (eds) Neighbourhood effects research: new perspectives. Springer, Dordrecht, pp 1–21
van Ham M, Marcińczak S, Tammaru T, Musterd S (2015) Socio-economic segregation in European capital cities: East Meets West. Taylor & Francis
Wang F, Zuo X (1999) Inside China’s cities: Institutional barriers and opportunities for urban migrants. Am Econ Rev. https://doi.org/10.1257/aer.89.2.276
Wasserstein RL, Lazar NA (2016) The ASA’s statement on p-values: context, process, and purpose. Am Stat 70(2):129–133
Wei Y (1994) Urban policy, economic policy, and the growth of large cities in China. Habitat Int 18(4):53–65
Wong DWS (2002) Ethnic integration and spatial segregation of the Chinese population. Asian Ethn 1:53–72. https://doi.org/10.1080/146313600115072
Wong DWS (2004) Comparing traditional and spatial segregation measures: a spatial scale perspective1. Urban Geogr 25(1):66–82
Wu W (2006) Migrant intra-urban residential mobility in urban China. Hous Stud 21:745–765. https://doi.org/10.1080/02673030600807506
Wu W (2014) Outsiders in the city. In: Rural Migrants in Urban China: Enclaves and Transient Urbanism, pp. 51–66
Wu Q et al (2014) Socio-spatial differentiation and residential segregation in the Chinese city based on the 2000 community-level census data: a case study of the inner city of Nanjing. Cities 39:109–119. https://doi.org/10.1016/j.cities.2014.02.011
Xiao Y, Song Y, Wu X (2018) How far has China’s urbanization gone? Sustainability 10(8):2953
Xu M, Yang Z (2009) Design history of China’s gated cities and neighbourhoods: prototype and evolution. Urban Des Int 14(2):99–117
Zhang L (2008) Ethnic congregation in a globalizing city: the case of Guangzhou, China. Cities. https://doi.org/10.1016/j.cities.2008.09.004
Zhao M, Wang Y (2018) Measuring segregation between rural migrants and local residents in urban China: an integrated spatio-social network analysis of Kecun in Guangzhou. Urban Anal City Sci, Environ Plan B. https://doi.org/10.1177/2399808317710658
Zhu P et al (2017) Residential segregation and commuting patterns of migrant workers in China. Transp Res Part D: Transp Environ. https://doi.org/10.1016/j.trd.2016.11.010
Acknowledgements
This research was funded by the Economic and Social Research Council (ESRC) through the ‘Global Challenges Research Fund: Dynamics of Health & Environmental Inequalities in Hebei Province, China’ project (Grant Reference: ES/P003567/1), and the ‘Understanding Inequalities’ project (Grant Reference ES/P009301/1).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2021 The Author(s)
About this chapter

Cite this chapter
Owen, G., Manley, D., Johnston, R., Birabi, T., Song, H., Wang, B. (2021). Multi-scale Inequality and Segregation: Theory and Estimation. In: Pryce, G., Wang, Y.P., Chen, Y., Shan, J., Wei, H. (eds) Urban Inequality and Segregation in Europe and China. The Urban Book Series. Springer, Cham. https://doi.org/10.1007/978-3-030-74544-8_11
Download citation
DOI: https://doi.org/10.1007/978-3-030-74544-8_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-74543-1
Online ISBN: 978-3-030-74544-8
eBook Packages: HistoryHistory (R0)