
Abstract
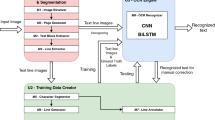
In this paper we propose a pipeline for processing of scanned historical documents into the electronic text form that could then be indexed and stored in a database. The nature of the documents presents a substantial challenge for standard automated techniques – not only there is a mix of typewritten and handwritten documents of varying quality but the scanned pages often contain multiple documents at once. Moreover, the language of the texts alternates mostly between Russian and Ukrainian but other languages also occur. The paper focuses mainly on segmentation, document type classification, and image preprocessing of the scanned documents; the output of those methods is then passed to the off-the-shelf OCR software and a baseline performance is evaluated on a simplified OCR task.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Bureš, L., Gruber, I., Neduchal, P., Hlaváč, M., Hrúz, M.: Semantic text segmentation from synthetic images of full-text documents. SPIIRAS Proc. 18(6), 1381–1406 (2019)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255. IEEE (2009)
Gruber, I., Hlaváč, M., Hrúz, M., Železný, M.: Semantic segmentation of historical documents via fully-convolutional neural network. In: Salah, A.A., Karpov, A., Potapova, R. (eds.) SPECOM 2019. LNCS (LNAI), vol. 11658, pp. 142–149. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-26061-3_15
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Lee, B.C.G., et al.: The newspaper navigator dataset: extracting and analyzing visual content from 16 million historic newspaper pages in chronicling America (2020)
Liu, L., Özsu, M.T.: Mean average precision. In: Liu, L., Özsu, M.T. (eds.) Encyclopedia of Database Systems, p. 1703. Springer, Boston (2009). https://doi.org/10.1007/978-0-387-39940-9_3032
Psutka, J., et al.: System for fast lexical and phonetic spoken term detection in a Czech cultural heritage archive. EURASIP J. Audio Speech Music Process. 2011(1), 10 (2011)
Smith, R.: An overview of the Tesseract OCR engine. In: Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), vol. 2, pp. 629–633. IEEE (2007)
Wu, Y., Kirillov, A., Massa, F., Lo, W.Y., Girshick, R.: Detectron2 (2019). https://github.com/facebookresearch/detectron2
Zajíc, Z., et al.: Towards processing of the oral history interviews and related printed documents. In: Proceedings of LREC 2018, pp. 2099–2104 (2018)
Zhong, X., Tang, J., Yepes, A.J.: PubLayNet: largest dataset ever for document layout analysis. In: 2019 International Conference on Document Analysis and Recognition (ICDAR), pp. 1015–1022. IEEE, September 2019
Acknowledgments
This research was supported by the Ministry of Culture Czech Republic, project No. DG20P02OVV018. Access to computing and storage facilities owned by parties and projects contributing to the National Grid Infrastructure MetaCentrum provided under the programme “Projects of Large Research, Development, and Innovations Infrastructures” (CESNET LM2015042), is greatly appreciated.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Gruber, I. et al. (2020). An Automated Pipeline for Robust Image Processing and Optical Character Recognition of Historical Documents. In: Karpov, A., Potapova, R. (eds) Speech and Computer. SPECOM 2020. Lecture Notes in Computer Science(), vol 12335. Springer, Cham. https://doi.org/10.1007/978-3-030-60276-5_17
Download citation
DOI: https://doi.org/10.1007/978-3-030-60276-5_17
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-60275-8
Online ISBN: 978-3-030-60276-5
eBook Packages: Computer ScienceComputer Science (R0)