
Abstract
Solving stochastic games with the reachability objective is a fundamental problem, especially in quantitative verification and synthesis. For this purpose, bounded value iteration (BVI) attracts attention as an efficient iterative method. However, BVI’s performance is often impeded by costly end component (EC) computation that is needed to ensure convergence. Our contribution is a novel BVI algorithm that conducts, in addition to local propagation by the Bellman update that is typical of BVI, global propagation of upper bounds that is not hindered by ECs. To conduct global propagation in a computationally tractable manner, we construct a weighted graph and solve the widest path problem in it. Our experiments show the algorithm’s performance advantage over the previous BVI algorithms that rely on EC computation.
K. Phalakarn—The work was done during K.P.’s internship at National Institute of Informatics, Japan, while he was a student at Chulalongkorn University, Thailand.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


1 Introduction
1.1 Stochastic Game (SG)
A stochastic game [13] is a two-player game played on a graph. In an SG, an action a of a player causes a transition from the current state s to a successor \(s'\), with the latter chosen from a prescribed probability distribution \(\delta (s,a,s')\). Under the reachability objective, the two players (called Maximizer and Minimizer) aim to maximize and minimize, respectively, the reachability probability to a designated target state.
Stochastic games are a fundamental construct in theoretical computer science, especially in the analysis of probabilistic systems. Its complexity is interesting in its own: the problem of threshold reachability—whether Maximizer has a strategy that ensures the reachability probability to be at least given p—is known to be in \(\mathsf {UP}\,\cap \,\mathsf {coUP}\) [19], but no polynomial algorithm is known. The practical significance of SGs comes from the number of problems that can be encoded to SGs and then solved. Examples include the following: solving deterministic parity games [8], solving stochastic games with the parity or mean-payoff objective [1], and a variety of probabilistic verification and reactive synthesis problems in different application domains such as cyber-physical systems. See e.g. [25].
SGs are often called 2.5-player games, where probabilistic branching is counted as 0.5 players. They generalize deterministic automata (0-player), Markov chains (MCs, 0.5-player), nondeterministic automata (1-player), Markov decision processes (MDPs, 1.5-player) and (deterministic) games (2-player). Many theoretical considerations on these special cases carry over smoothly to SGs. However, SGs have their peculiarities, too. One example is the treatment of end components in bounded value iteration, as we describe later.
1.2 Value Iteration (VI)
In an SG, we are interested in the optimal reachability probability, that is, the reachability probability when both Maximizer and Minimizer take their optimal strategies. The function that returns these optimal reachability probabilities is called the value function \(V(\mathcal {G})\) of the SG \(\mathcal {G}\); our interest is in computing this value function, desirably constructing optimal strategies for the two players at the same time. For this purpose, two principal families of solution methods are strategy iteration (SI) [19] and value iteration (VI) [10, 13]—the latter is commonly preferred for performance reasons.

The mathematical principle that underpins VI is the characterization of the value function \(V(\mathcal {G})\) as the least fixed point (lfp) of an function update operator \(\mathbb {X}\) called the Bellman operator. The Bellman operator \(\mathbb {X}\) back-propagates function values by one step, using the average. For the simple case of Markov chains shown on the right, it is defined by \((\mathbb {X}f)(s)=\sum _{i} p_{i}\cdot f(s_{i})\), turning a function \(f:S\rightarrow [0,1]\) (i.e., assignment of “scores” to states) to \(\mathbb {X}f:S\rightarrow [0,1]\).
Since \(V(\mathcal {G})\) is the lfp \(\mu \mathbb {X}\), Kleene’s fixed point theorem tells us the sequence
where \(\bot \) is the least element of the function space \(S\rightarrow [0,1]\), converges to \(V(\mathcal {G})=\mu \mathbb {X}\). VI consists of the iterative approximation of \(V(\mathcal {G})\) via the sequence (1).
An issue from the practical point of view, however, is that \(\mathbb {X}^{i}\bot \) never becomes equal to \(V(\mathcal {G})\) in general. Even worse, one cannot know how close the current approximant \(\mathbb {X}^{i}\bot \) is to the desired function \(V(\mathcal {G})\) [18]. In summary, VI as an iterative approximation method does not give any precision guarantee.
1.3 Bounded Value Iteration (BVI) and End Components
Bounded value iteration (BVI) has been actively studied as an extension of VI that comes with a precision guarantee [2, 3, 5, 16, 18, 20, 23]. Its core ideas are the following two.

Firstly, BVI computes not only iterative lower bounds \(L_{i}=\mathbb {X}^{i}\bot \) for \(V(\mathcal {G})\), but also iterative upper bounds \(U_{i}\), as shown on the right in (2). This gives us a precision guarantee—\(V(\mathcal {G})\) must lie between the approximants \(L_{i}\) and \(U_{i}\).
Secondly, for computing upper bounds \(U_{i}\), BVI uses the Bellman operator again: \(U_{i}=\mathbb {X}^{i}\top \) where \(\top \) is the greatest element of the function space \(S\rightarrow [0,1]\). This leads to the following approximation sequence that is dual to (1):
The sequence (3) converges to the greatest fixed point (gfp) \(\nu \mathbb {X}\) of \(\mathbb {X}\), which must be above the lfp \(V(\mathcal {G})=\mu \mathbb {X}\). Therefore the elements in (3) are all above \(V(\mathcal {G})\).
The problem, however, is that the gfp \(\nu \mathbb {X}\) is not necessarily the same as \(\mu \mathbb {X}\). Therefore the upper bounds \(U_{0}\ge U_{1}\ge \cdots \) given by (3) may not converge to \(V(\mathcal {G})\). In other words, for a given threshold \(\varepsilon >0\), the bounds in (2) may fail to achieve \(U_{i}-L_{i}\le \varepsilon \), no matter how large i is.

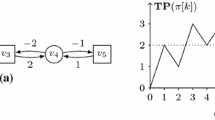
A Markov chain (MC) for which the naive BVI fails to converge
In the literature, the source of this convergence issue has been identified to be end components (ECs) in MCs/MDPs/SGs. ECs are much like loops without exits—an example is in Fig. 1, where we use a Markov chain (MC) for simplicity. Any function f that assigns the same value to the states \(s_{I}\) and s can be a fixed point of the Bellman operator \(\mathbb {X}\) (that back-propagates f by averages); therefore, the gfp \(\nu \mathbb {X}\) assigns 1 to both \(s_{I}\) and s. In contrast, \((\mu \mathbb {X})(s_{I})=(\mu \mathbb {X})(s)=0\), which says one never reaches the target \(\mathbf {1}\) from \(s_{I}\) or s (which is obvious).
Most previous works on BVI have focused on the problem of how to deal with ECs. Their solutions are to get somehow rid of ECs. For example, ECs in MDPs are discovered and collapsed in [5, 18]; ECs in SGs cannot simply be collapsed, and an elaborate method is proposed in the recent work [20] that deflates them. This is the context of the current work, and we aim to enhance BVI for SGs.
1.4 Contribution: Global Propagation in BVI with Widest Paths
The algorithms in [20] seem to be the only BVI algorithms known for SGs. In their performance, however, EC computation often becomes a bottleneck. Our contribution in this paper is a new BVI algorithm for SGs that is free from the need for EC computation.
The key idea of our algorithm is global propagation for upper bounds, as sketched below. In each iteration for upper bounds \(U_{0}\ge U_{1}\ge \cdots \), we conduct global propagation, in addition to the local propagation in the usual BVI. The latter means the application of \(\mathbb {X}\) to \(\mathbb {X}^{i}\top \), leading to \(\mathbb {X}^{i+1}\top \); this local propagation, as we previously discussed, gets trapped in end components. In contrast, our global propagation looks at paths from each state s to the target \(\mathbf {1}\), ignoring end components. For example, in Fig. 1, our global propagation sees that there is no path from \(s_{I}\) to the target \(\mathbf {1}\), and consequently assigns 0 as an upper bound for the value function \(V(\mathcal {G})(s_{I})\).
Such global propagation is easier said than done—in fact, the very advantage of VI is that the global quantities (namely reachability probabilities) get computed by iterations of local propagation. Conducting global propagation in a computationally tractable manner requires a careful choice of its venue. The solution in this paper is to compute widest paths in a suitable (directed) weighted graph.
More specifically, in each iteration where we compute an upper bound \(U_{i}\), we conduct the following operations.
-
(Player reduction) We turn the given SG \(\mathcal {G}\) into an MDP \(\mathcal {M}_{i}\), by restricting Minimizer’s actions to the empirically optimal ones. The latter means they are optimal with respect to the current under-approximation \(L_{i}\) of \(V(\mathcal {G})\).
-
(Local propagation) The MDP \(\mathcal {M}_{i}\) is then turned into a weighted graph (WG) \(\mathcal {W}_{i}\). The construction of \(\mathcal {W}_{i}\) consists of the application of \(\mathbb {X}\) to the previous bound \(U_{i-1}\) (i.e. local propagation), and forgetting the information that cannot be expressed in a weighted graph (such as the precise transition probabilities \(\delta (s,a,s')\) that depend on the action a). Due to this information loss, our analysis in \(\mathcal {W}_{i}\) is necessarily approximate. Nevertheless, the benefit of \(\mathcal {W}_{i}\)’s simplicity is significant, as in the following step.
-
(Global propagation) In the WG \(\mathcal {W}_{i}\), we solve the widest path problem. This classic graph-theoretic problem can be solved efficiently, e.g., by the Dijkstra algorithm. The widest path width gives a new upper bound \(U_{i}\).
We prove the correctness of our algorithm: soundness (\(V(\mathcal {G})\le U_{i}\)), and convergence (\(U_{i}\rightarrow V(\mathcal {G})\) as \(i\rightarrow \infty \)). That the upper bounds decrease (\(U_{0}\ge U_{1}\ge \cdots \)) will be obvious by construction. These correctness proofs are technically nontrivial, combining combinatorial, graph-theoretic, and analytic arguments.
We have also implemented our algorithm. Our experiments compare its performance to the algorithms from [20] (the original one and its learning-based variation). The results show our consistent performance advantage: depending on SGs, our performance is from comparable to dozens of times faster. The advantage is especially eminent in SGs with many ECs.
1.5 Related Works
VI and BVI have been pursued principally for MDPs. The only work we know that deals with SGs is [20]—with the exception of [26] that works in a restricted setting where every end component belongs exclusively to either player. The work closest to ours is therefore [20], in that we solve the same problem.
For MDPs, the idea of BVI is first introduced in [23]; they worked in a limited setting where ECs do not cause the convergence issue. Its extension to general MDPs with the reachability objective is presented in [5, 18], where ECs are computed and then collapsed. BVI is studied under different names in these works: bounded real time dynamic programming [5, 23] and interval iteration [18]. The work [20] is an extension of this line of work from MDPs to SGs.
The work [20] has seen a few extensions to more advanced settings: black-box settings [3], concurrent reachability [16], and generalized reachability games [2].
Most BVI algorithms involve EC computation (although ours does not). The EC algorithm in [14, 15] is used in [18, 20]; more recent algorithms include [7, 9].
1.6 Organization
In Sect. 2 we present some preliminaries. In Sect. 3 we review VI and BVI with an emphasis on the role of Kleene’s fixed point theorem. This paves the way to Sect. 4 where we present our algorithm. We do so in three steps, and prove the correctness—soundness and convergence—in the end. Experiment results are shown in Sect. 5.
2 Preliminaries
We fix some basic notations. Let X be a set. We let \(X^{*}\) denote the set of finite sequences over X, that is, \(X^{*}=\bigcup _{i\in \mathbb {N}}X^{i}\). We let \(X^{+}=X^{*}\setminus \{\varepsilon \}\), where \(\varepsilon \) denotes the empty sequence (of length 0). The set of infinite sequences over X is denoted by \(X^{\omega }\). The set of functions from X to Y is denoted by \(X\rightarrow Y\).
2.1 Stochastic Games
In a stochastic game, two players (Maximizer \(\square \) and Minimizer \(\bigcirc \)) play against each other. The goals of the two players are to maximize and minimize the value function, respectively. Many different definitions are possible for value functions. In this paper (as well as all the works on (bounded) value iteration), we focus on the reachability objective, in which case a value function is defined by the reachability probability to a designated target state \(\mathbf {1}\).
Definition 2.1
(stochastic game (SG)). A stochastic game (SG) is a tuple \(\mathcal {G}= (S, S_{\square }, S_{\bigcirc }, s_I,\) \( \mathbf {1}, \mathbf {0}, A, \mathrm {Av}, \delta )\) where
-
S is a finite set of states, partitioned into \(S_{\square }\) and \(S_{\bigcirc }\) (i.e., \(S = S_{\square } \cup S_{\bigcirc }\), \(S_{\square } \cap S_{\bigcirc } = \emptyset \)). \(s\in S_{\square }\) is Maximizer’s state; \(s\in S_{\bigcirc }\) is Minimizer’s state.
-
\(s_I \in S\) is an initial state, \(\mathbf {1} \in S_{\square }\) is a target, and \(\mathbf {0} \in S_{\bigcirc }\) is a sink.
-
A is a finite set of actions.
-
\(\mathrm {Av}: S \rightarrow 2^{A}\) defines the set of actions that are available at each state \(s\in S\).
-
\(\delta : S \times A \times S \rightarrow [0,1]\) is a transition function, where \(\delta (s,a,s')\) gives a probability with which to reach the state \(s'\) when the action a is taken at the state s. The value \(\delta (s,a,s')\) is non-zero only if \(a \in \mathrm {Av}(s)\); it must satisfy \(\sum _{s' \in S} \delta (s,a,s') = 1\) for all \(s \in S\) and \(a \in \mathrm {Av}(s)\).
We assume that each of \(\mathbf {1}\) and \(\mathbf {0}\) allows only one action that leads to a self-loop with probability 1. Moreover, for theoretical convenience, we assume that all SGs are non-blocking. That is, \(\mathrm {Av}(s)\ne \emptyset \) for each \(s\in S\).
We introduce some notations: \(\mathrm {post}(s,a) = \{s' \mid \delta (s ,a,s') > 0\}\), and for \(S' \subseteq S\), we let \(S'_{\square } = S' \cap S_{\square }\) and \(S'_{\bigcirc } = S' \cap S_{\bigcirc }\).
Definition 2.2
(Markov decision process (MDP), Markov chain (MC)). An SG such that \(S_\square = S \setminus \{\mathbf {0}\}\) (i.e. Minimizer is absent) is called a Markov decision process (MDP). We often omit the second and third components for MDPs, writing \(\mathcal {M}=(S, s_I, \mathbf {1}, \mathbf {0}, A, \mathrm {Av}, \delta )\).
An SG such that \(|\mathrm {Av}(s)| = 1\) for each \(s \in S\)—both Maximizer and Minimizer are absent—is called a Markov chain (MC). It is also denoted simply by a tuple \(\mathcal {G}= (S, s_I, \mathbf {1}, \mathbf {0}, \delta )\) where its transition function is of the type \(\delta :S\times S \rightarrow [0,1]\).
Every notion for SGs that appears below applies to MDPs and MCs, too.
Example 2.3
Figure 2 presents an example of an SG. At the state \(s_1\) of Minimizer, two actions \(\alpha \) and \(\beta \) are in \(\mathrm {Av}(s_1)\). If Minimizer chooses \(\alpha \), the next state is \(s_2\) with probability \(\delta (s_1,\alpha ,s_2) = 1\). If Minimizer instead chooses \(\beta \), the next state is \(\mathbf {1}\) with probability \(\delta (s_1,\beta ,\mathbf {1}) = 0.8\) or \(\mathbf {0}\) with probability \(\delta (s_1,\beta ,\mathbf {0}) = 0.2\).
Maximizer’s goal is to reach \(\mathbf {1}\) as often as possible by choosing suitable actions. Minimizer’s goal is to avoid reaching \(\mathbf {1}\)—this can be achieved, for example but not exclusively, by reaching \(\mathbf {0}\).

A stochastic game (SG), an example
Both players choose their actions according to their strategies. It is well-known [13] that positional (also called memoryless) and deterministic (also called pure) strategies are complete for finite SGs with the reachability objective.
Definition 2.4
(strategy, path). Let \(\mathcal {G}\) be the SG in Definition 2.1. A strategy for Maximizer in \(\mathcal {G}\) is a function \(\sigma :S_{\square } \rightarrow A\) such that \(\sigma (s)\in \mathrm {Av}(s)\) for each \(s\in S_{\square }\). A strategy for Minimizer is defined similarly. The set of Maximizer’s strategies in \(\mathcal {G}\) is denoted by \(\mathrm {str}^{\mathcal {G}}_{\square }\); that of Minimizer’s is denoted by \(\mathrm {str}^{\mathcal {G}}_{\bigcirc }\).
Strategies \(\tau \in \mathrm {str}^{\mathcal {G}}_{\square }\) and \(\sigma \in \mathrm {str}^{\mathcal {G}}_{\bigcirc }\) in \(\mathcal {G}\) turn the game \(\mathcal {G}\) into a Markov chain, which is denoted by \(\mathcal {G}^{\tau ,\sigma }\). Similarly, a strategy \(\tau \) for Maximizer (who is the only player) in an MDP \(\mathcal {M}\) induces an MC, denoted by \(\mathcal {M}^{\tau }\).
An infinite path in \(\mathcal {G}\) is a sequence \(s_0 a_0 s_1 a_1 s_2 a_2 \ldots \in (S \times A)^\omega \) such that for all \(i \in \mathbb {N}\), \(a_i \in \mathrm {Av}(s_i)\) and \(s_{i+1} \in \mathrm {post}(s_i,a_i)\). A prefix \(s_0 a_0 s_1 \ldots s_k\) of an infinite path ending with a state is called a finite path. If \(\mathcal {G}\) is an MC, then we omit actions in a path and write \(s_0s_1s_2\ldots \) or \(s_0s_1 \ldots s_k\).
Given a game \(\mathcal {G}\) and strategies \(\tau ,\sigma \) for the two players, the induced MC \(\mathcal {G}^{\tau ,\sigma }\) assigns to each state \(s\in S\) a probability distribution \(\mathbb {P}_s^{\tau ,\sigma }\). The distribution is with respect to the standard measurable structure of \(S^{\omega }\); see, e.g., [4, Chap. 10]. For each measurable subset \(X \subseteq S^\omega \), \(\mathbb {P}_s^{\tau ,\sigma }(X)\) is the probability with which \(\mathcal {G}^{\tau ,\sigma }\), starting from the state s, produces an infinite path \(\pi \) that belongs to X.
It is well-known that all the LTL properties are measurable in \(S^{\omega }\). In the current setting with the reachability objective, we are interested in the probability of eventually reaching \(\mathbf {1}\), denoted by \(\mathbb {P}_s^{\tau ,\sigma }(\Diamond \mathbf {1})\).
Definition 2.5
(value function \(V(\mathcal {G})\)). Let \(\mathcal {G}\) be the SG in Definition 2.1. The value function \(V(\mathcal {G})\) of \(\mathcal {G}\) is defined by
where the last equality is shown in [13].
We say a strategy \(\tau \) of Maximizer’s is optimal if \(V(\mathcal {G})(s) = \min _\sigma \mathbb {P}_s^{\tau ,\sigma }(\lozenge \mathbf {1})\) for each \(s\in S\); similarly, we say a strategy \(\sigma \) of Minimizer’s is optimal if \(V(\mathcal {G})(s) = \max _\sigma \mathbb {P}_s^{\sigma ,\tau }(\lozenge \mathbf {1})\) for each \(s \in S\).
We write V for \(V({\mathcal {G}})\) when the dependence on \(\mathcal {G}\) is clear from the context.
The set of states with a non-zero value is denoted by \(S_{\Diamond \mathbf {1}}\). That is, \(S_{\Diamond \mathbf {1}}=\{s\in S\mid V(\mathcal {G})(s)> 0\}\).
Example 2.6
Consider the SG \(\mathcal {G}\) from Fig. 2. At \(s_2\), Maximizer’s action should be \(\alpha \). Hence, \(V(\mathcal {G})(s_2) = 0.9\). At \(s_1\), if Minimizer chooses \(\alpha \), then the probability of reaching \(\mathbf {1}\) will be 0.9 by \(V(\mathcal {G})(s_2)\). Thus, Minimizer should choose \(\beta \) at \(s_1\), which yields \(V(\mathcal {G})(s_1) = 0.8\). Finally, at \(s_I\), \(\gamma \) is the best choice, since Maximizer can choose this action infinitely often until it gets to \(s_2\). We have \(V(\mathcal {G})(s_I) = 0.9\).
2.2 The Widest Path Problem
Definition 2.7
(weighted graph (WG)). A (directed) weighted graph is a triple \(\mathcal {W}=(V,E,w)\) of a finite set V of vertices, a set \(E\subseteq V\times V\) of edges, and a weight function \(w:E\rightarrow [0,1]\) where [0, 1] is the unit interval.
A (finite) path in a WG is defined in the usual graph-theoretic way.
In the widest path problem, an edge weight \(w(v,v')\) is thought of as its capacity, and the capacity of a path is determined by its bottleneck. The problem asks for a path with the greatest capacity. In this paper, we use the following all-source single-destination version of the problem.
Definition 2.8
(the widest path problem (WPP)). A (finite) path in \(\mathcal {W}=(V,E,w)\) is a sequence \(v_{0}v_{1}\dotsc v_{n}\) of vertices such that \((v_{i},v_{i+1})\in E\) for each \(i\in [0,n-1]\). The width of a path \(v_{0}v_{1}\dotsc v_{n}\) is given by \(\min _{i\in [0,n-1]}w(v_{i},v_{i+1})\).
The widest path problem is the following problem.
-
Given: a WG \(\mathcal {W}=(V,E,w)\) and a target vertex \(v_{\mathrm {t}}\in V.\)
-
Answer: for each \(v\in V\), the widest width of the paths from v to \(v_{\mathrm {t}}\), that is,
$$\begin{aligned} \max _{n\in \mathbb {N}, v=v_{0},v_{1},\dotsc , v_{n}=v_{\mathrm {t}}} \min _{i\in [0,n-1]} w(v_{i},v_{i+1}), \end{aligned}$$
We let \(\mathrm {WPW}(\mathcal {W},v_{\mathrm {t}})\) denote a function that solves this problem, and let \(\mathrm{WPath}(\mathcal {W},v_{\mathrm {t}})\) denote a function that assigns to each \(v\in V\) a widest path to \(v_{\mathrm {t}}\). Furthermore, we assume the following property of \(\mathrm{WPath}\): if \(\mathrm{WPath}(\mathcal {W},v_{\mathrm {t}})(v_{0})=v_{0}v_{1}\dotsc v_{k}v_{\mathrm {t}}\), then \(\mathrm{WPath}(\mathcal {W},v_{\mathrm {t}})(v_{i})=v_{i}v_{i+1}\dotsc v_{k}v_{\mathrm {t}}\) for each \(i\in [0,k]\).
Efficient algorithms are known for \(\mathrm {WPW}(\mathcal {W},v_{\mathrm {t}})\). An example is the Dijkstra search algorithm with Fibonacci heaps [17]; it is originally for the single-source all-destination version but its adaptation is easy. The algorithm runs in time \(O(|E| + |V|\log |V|)\). It returns a widest path in addition to its width, too, computing the function \(\mathrm{WPath}(\mathcal {W},v_{\mathrm {t}})\) with the property required in the above.
3 (Bounded) Value Iteration
3.1 Bellman Operator and Value Iteration
The following construct—used for “local propagation” in computing the value function—is central to formal analysis of probabilistic systems and games.
Definition 3.1
(Bellman Operator). Let \(\mathcal {G}=(S, S_{\square }, S_{\bigcirc }, s_I, \mathbf {1}, \mathbf {0}, A, \mathrm {Av}, \delta ) \) be a stochastic game. For each state \(s \in S\), an available action \(a \in \mathrm {Av}(s)\), and \(f:S \rightarrow [0,1]\), we define a function \(\mathbb {X}_a f:S \rightarrow [0,1]\) by the following.
These functions are used in the following definition of the Bellman operator \(\mathbb {X}:(S\rightarrow [0,1])\rightarrow (S\rightarrow [0,1])\) over \(\mathcal {G}\):
The function space \(S\rightarrow [0,1]\) inherits the usual order \(\le \) between real numbers in the unit interval [0, 1], that is, \(f\le g\) if \(f(s)\le g(s)\) for each \(s\in S\). The Bellman operator \(\mathbb {X}\) over \(S\rightarrow [0,1]\) is clearly monotone; it is easily seen to preserve \(\max \) and \(\min \), using the fact that the state space S of an SG is finite. Therefore we obtain the following, as consequences of Kleene’s fixed point theorem.
Lemma 3.2
Assume the setting of Definition 3.1.
-
1.
The Bellman operator \(\mathbb {X}\) has the greatest fixed point (gfp) \(\nu \mathbb {X}:S\rightarrow [0,1]\). It is obtained as the limit of the descending \(\omega \)-chain
$$\begin{aligned} \top \;\ge \; \mathbb {X}\top \;\ge \; \mathbb {X}^{2}\top \;\ge \; \cdots , \end{aligned}$$where \(\top \) is the greatest element of \(S\rightarrow [0,1]\) (i.e., \(\top (s)=1\) for each \(s\in S\)). In other words, we have \( (\nu \mathbb {X})(s)=\inf _{i\in \mathbb {N}}\bigl ((\mathbb {X}^{i}\top )(s) \bigr ) \) for each \(s\in S\).
-
2.
Symmetrically, \(\mathbb {X}\) has the least fixed point (lfp) \(\mu \mathbb {X}:S\rightarrow [0,1]\), obtained as the limit of the ascending chain
$$\begin{aligned} \bot \;\le \; \mathbb {X}\bot \;\le \; \mathbb {X}^{2}\bot \;\le \; \cdots , \end{aligned}$$(4)where \(\bot (s)=0\) for each \(s\in S\). That is, we have \( (\mu \mathbb {X})(s)=\sup _{i\in \mathbb {N}}\bigl ((\mathbb {X}^{i}\bot )(s) \bigr ) \) for each \(s\in S\). \(\square \)

The following characterization is fundamental. See, e.g., [10].
Theorem 3.3
Let \(\mathcal {G}\) be a stochastic game. The value function \(V=V(\mathcal {G})\) (Definition 2.5) coincides with the least fixed point \(\mu \mathbb {X}\). \(\square \)
The fact that \(V(\mathcal {G})\) is the least fixed point of \(\mathbb {X}\) implies the following: a strategy \(\tau \) of Maximizer is optimal if and only if \(\bigl (\mathbb {X}_{\tau (s)} \bigl (V(\mathcal {G})\bigr )\bigr )(s) =V(\mathcal {G})(s)\) holds for each \(s \in S_\square \); similarly for Minimizer. We say \(a \in \mathrm {Av}(s)\) is optimal at s if \(\mathbb {X}_a V(\mathcal {G})(s) =V(\mathcal {G})(s)\) holds; otherwise a is suboptimal.
Lemma 3.2.2 & Theorem 3.3 suggest iterative under-approximation of \(V(\mathcal {G})\) by \(\bot \le \mathbb {X}\bot \le \mathbb {X}^{2}\bot \le \cdots \). This is the principle of value iteration (VI); see Algorithm 1.
Example 3.4
The values \(L_i\) computed by Algorithm 1, for the SG in Fig. 2, are shown in the following table. The values at \(\mathbf {0}\) and \(\mathbf {1}\) are omitted.
s | \(L_{0}\) | \(L_1\) | \(L_2\) | \(L_3\) | \(L_4\) | \(L_5\) | ... | \(V(\mathcal {G})\) |
|---|---|---|---|---|---|---|---|---|
\(s_I\) | 0 | 0 | 0.54 | 0.83 | 0.872 | 0.8888 | 0.9 | |
\(s_1\) | 0 | 0 | 0.8 | 0.8 | 0.8 | 0.8 | ... | 0.8 |
\(s_2\) | 0 | 0.9 | 0.9 | 0.9 | 0.9 | 0.9 | 0.9 |
\(L_i(s_I)\) converges to, but is never equal to, \(V(\mathcal {G})(s_I)\). The converges rate can be arbitrarily slow: for any \(\varepsilon \in (0,1)\) and \(k \in \mathbb {N}\) there is an SG \(\mathcal {G}\) and a state s such that \(V(\mathcal {G})(s) - L_k(s) >\varepsilon \). One sees this by modifying Fig. 2 with \(\delta (s_I, \gamma , s_2) = \varepsilon '\) and \(\delta (s_I, \gamma , s_I) = 1- \varepsilon '\), where \(\varepsilon ' > 0\) is an arbitrary small positive constant.
There is no known stopping criterion for VI (Algorithm 1) with a precision guarantee, besides the one in [10] that is too pessimistic to be practical. The one shown in Line 3 (“little progress”) is a commonly used heuristic, but it is known to lead to arbitrarily wrong results [18].
3.2 Bounded Value Iteration
When we turn back to Lemma 3.2, Lemma 3.2.1 suggests another iterative approximation, namely over-approximation of the value function V by \(\top \ge \mathbb {X}\top \ge \mathbb {X}^{2}\top \ge \cdots \). The chain converges to the gfp \(\nu \mathbb {X}\) that is necessarily above the lfp \(\mu \mathbb {X}\). This is the principle that underlies bounded value iteration (BVI); see Algorithm 2 for its naive prototype. BVI has been actively studied in the literature [2, 3, 5, 16, 18, 20, 23], sometimes under different names (such as bounded real time dynamic programming [5, 23] or interval iteration [18]).

BVI comes with a precision guarantee: since \(V(\mathcal {G})\) lies between \(L_{i}\) and \(U_{i}\) (whose gap is at most \(\varepsilon \)), the approximation \(L_{i}\) is at most \(\varepsilon \) apart from \(V(\mathcal {G})\).
The catch, however, is that \(\mu \mathbb {X}\) and \(\nu \mathbb {X}\) may not coincide, and therefore the overapproximation might not converge to the desired \(\mu \mathbb {X}\). This means Algorithm 2 might not terminate. This is the main technical challenge addressed in the previous works on BVI, including [5, 20].
In those works, the source of the failure of convergence is identified to be end components. See the (very simple) Markov chain in Fig. 1, where the reachability probability from \(s_{I}\) to \(\mathbf {1}\) is clearly 0. However, due to the loop between \(s_{I}\) and s, the values \(U_{i}(s_{I})\) and \(U_{i}(s)\)—these get updated to the average of \(U_{i-1}\) at successors—are easily seen to remain 1. Roughly speaking, end components generalize such loops defined in MDPs and SGs (the definitions are graph-theoretic, in terms of strongly connected components). End components cause non-convergence of naive BVI, essentially for the reason we just described.
The solutions previously proposed to this challenge have been to “get rid of end components.” For MDPs (1.5 players), the collapsing technique detects end components and collapses each of them into a single state [5, 18]. After doing so, the Bellman operator \(\mathbb {X}\) has a unique fixed point (therefore \(\mu \mathbb {X}=\nu \mathbb {X}\)), assuring convergence of BVI (Algorithm 2). In the case of SGs (2.5 players), end components cannot simply be collapsed into single states—they must be handled carefully, taking the “best exits” into account. This is the key idea of the deflating technique proposed for SGs in [20].
4 Our Algorithm: Bounded Value Iteration with Upper Bounds Given by Widest Paths
In our algorithm, like in other BVI algorithm, we iteratively construct upper and lower bounds \(U_{i}, L_{i}\) of the value function \(V(\mathcal {G})\) at the same time. See (2). In updating \(U_{i}\), however, we go beyond the local propagation by the Bellman update and conduct global propagation, too. This frees us from the curse of end components. The outline of our algorithm is as follows.
-
The lower bound \(L_{i}\) is given by \(L_{i}=\mathbb {X}^{i}\bot \), following Lemma 3.2.2 and Theorem 3.3. This is the same as the other VI algorithms.
-
The upper bounds \(U_{i}\) is constructed in the following three steps, using a global propagation that takes advantage of fast widest path algorithms.
-
(Player reduction) Firstly, we turn the SG \(\mathcal {G}\) into an MDP \(\mathcal {M}_{i}\) by fixing Minimizer’s strategy to a specific one \(\sigma _{i}\).
Any choice of \(\sigma _{i}\) would do for the sake of soundness (that is, \(V(\mathcal {G})\le U_{i}\)). However, for convergence (that is, \(U_{i}\rightarrow V(\mathcal {G})\) as \(i\rightarrow \infty \)), it is important to have \(\sigma _{0}, \sigma _{1},\dotsc \) eventually converge to Minimizer’s optimal strategy \(\sigma _{\bigcirc }\). Therefore we let \(L_{i}\)—the current lower estimate of \(V(\mathcal {G})\)—induce \(\sigma _{i}\). Recall that \(L_{i}\) converges to \(V(\mathcal {G})\) (Lemma 3.2.2, Theorem 3.3).
-
(Preprocessing by local propagation) Secondly, we turn the MDP \(\mathcal {M}_{i}\) into a weighted graph (WG) \(W_{i}\).
The construction here is local propagation of the previous upper bound \(U_{i-1}\), from each state s to its predecessors in \(\mathcal {M}_{i}\). This is much like an application of the Bellman operator \(\mathbb {X}\).
-
(Global propagation by widest paths) Finally, we solve the widest path problem in the WG \(W_{i}\), from each state s to the target state \(\mathbf {1}\). The maximum path width from s to \(\mathbf {1}\) is used as the value of the upper bound \(U_{i}(s)\).
This way, we conduct global propagation of upper bounds, for which end components pose no threats. Our global propagation is still computationally feasible, thanks to the preprocessing in the previous step that turns a problem on an MDP into one on a WG (modulo some sound approximation).
-
The use of global propagation for upper bounds is a distinguishing feature of our algorithm. This is unlike other BVI algorithms (such as [5, 20]) where upper-bound propagation is only local and stepwise. The latter gets trapped when it encounters an EC—therefore some trick such as collapsing [5] and deflating [20] is needed—while our global propagation looks directly at the target state \(\mathbf {1}\).
The above outline is presented as pseudocode in Algorithm 3. We describe the three steps in the rest of the section. In particular, we exhibit the definitions of \(\mathcal {M}_\mathrm {PlRd}\) and \(\mathcal {W}_\mathrm {LcPg}\) (\(\mathrm {WPW}\) has been defined and discussed in Definition 2.8), providing some of their properties towards the correctness proof of the algorithm (Sect. 4.3).
4.1 Player Reduction: From SGs to MDPs
The following general definition is not directly used in Algorithm 3. It is used in our theoretical development below, towards the algorithm’s correctness.

Definition 4.1
(the MDP \(\mathcal {M}(\mathcal {G}, \mathrm {Av}')\)). Let \(\mathcal {G}\) be the game in Algorithm 3, and \(\mathrm {Av}':S\rightarrow 2^{A}\) be such that \(\emptyset \ne \mathrm {Av}'(s)\subseteq \mathrm {Av}(s)\) for each \(s\in S\).
Then the MDP given by the tuple \((S,S\setminus \{\mathbf {0}\},\{\mathbf {0}\}, s_{I},\mathbf {1},\mathbf {0},A,\mathrm {Av}',\delta )\) shall be denoted by \(\mathcal {M}(\mathcal {G}, \mathrm {Av}')\), and we say it is induced from \(\mathcal {G}\) by restricting \(\mathrm {Av}\) to \(\mathrm {Av}'\).
The above construction consists of 1) restricting actions (from \(\mathrm {Av}\) to \(\mathrm {Av}'\)), and 2) turning Minimizer’s states into Maximizer’s.
The following class of action restrictions will be heavily used.
Definition 4.2
(Minimizer restriction). Let \(\mathcal {G}\) be as in Algorithm 3. A Minimizer restriction of \(\mathrm {Av}\) is a function \(\mathrm {Av}':S\rightarrow 2^{A}\) such that 1) \(\emptyset \ne \mathrm {Av}'(s)\subseteq \mathrm {Av}(s)\) for each \(s\in S\), and 2) \(\mathrm {Av}' (s) = \mathrm {Av}(s)\) for each state \(s\in S_{\square }\) of Maximizer’s.
In Algorithm 3, we will be using the MDP induced by the following specific Minimizer restriction induced by a function f.
Definition 4.3
(the MDP \(\mathcal {M}_\mathrm {PlRd}(\mathcal {G}, f)\)). Let \(\mathcal {G}\) be the game in Algorithm 3, and \(f:S\rightarrow [0,1]\) be a function. The MDP \(\mathcal {M}_\mathrm {PlRd}(\mathcal {G}, f)\) is defined to be \(\mathcal {M}(\mathcal {G}, \mathrm {Av}_{f})\) (Definition 4.1), where the function \(\mathrm {Av}_{f}:S\rightarrow 2^{A}\) is defined as follows.
The function \(\mathrm {Av}_{f}\) is a Minimizer restriction in \(\mathcal {G}\) (Definition 4.2).
The intuition of (5) is that \(a=\mathrm {arg\,min}_{b\in \mathrm {Av}(s)}(\mathbb {X}_{b}f)(s)\). In the use of this construction in Algorithm 3, the function f will be our “best guess” \(L_{i}\) of the value function \(V(\mathcal {G})\). In this situation, \(\mathrm {arg\,min}_{b\in \mathrm {Av}(s)}(\mathbb {X}_{b}f)(s)\) is the best action for Minimizer based on the guess \(f=L_{i}\).
Definition 4.4
(the MDP \(\mathcal {M}_{i}\), and \(\mathrm {Av}_{i}\)). In Algorithm 3, the MDP \(\mathcal {M}_{i}\) is given by \(\mathcal {M}_\mathrm {PlRd}(\mathcal {G}, L_{i})=\mathcal {M}(\mathcal {G},\mathrm {Av}_{L_{i}})\). We write \(\mathrm {Av}_{i}\) for available actions in \(\mathcal {M}_{i}\), that is, \(\mathcal {M}_{i}=(S, \mathbf {1},\mathbf {0}, A,\mathrm {Av}_{i}, \delta )\).
In the case of Algorithm 3, the MDPs \(\mathcal {M}_{0},\mathcal {M}_{1},\dotsc \) do not only “converge” to \(\mathcal {G}\), but also “reach \(\mathcal {G}\) in finitely many steps,” in the following sense. The proof is deferred to [24]. The proof relies crucially on the fact that the set \(\mathrm {Av}(s)\) of available actions is finite—there is uniform \(\varepsilon >0\) such that every suboptimal action is suboptimal by a gap at least \(\varepsilon \).
Lemma 4.5
In Algorithm 3, there exists \(i_{\mathrm {M}}\in \mathbb {N}\) such that, for each \(i\ge i_{\mathrm {M}}\), we have \(V(\mathcal {G})=V(\mathcal {M}_{i})\). \(\square \)
4.2 Local Propagation: From MDPs to WGs
Here is a technical observation that motivates the function \(\mathcal {W}_\mathrm {LcPg}\).
Lemma 4.6
Let \(\mathcal {G}\) be the game in Algorithm 3, and \(\mathrm {Av}':S\rightarrow 2^{A}\) be a Minimizer restriction (Definition 4.2).
-
1.
For each state \(s\in S\), we have \( V(\mathcal {G})(s) \le \textstyle \max _{a\in \mathrm {Av}'(s)}\bigl (\,\mathbb {X}_{a}\bigl (V(\mathcal {G})\bigr )\,\bigr )(s). \)
-
2.
For each \(k\in \mathbb {N}\), we have
$$\begin{aligned} V(\mathcal {G})(s_{0}) \;\le \; \max _{s_{0}\xrightarrow {a_{0}}s_{1}\xrightarrow {a_{1}}\,\cdots \,\xrightarrow {a_{k}} \text { in }\mathrm {Av}' } \bigl (\,\mathbb {X}_{a_{k}}\bigl (V(\mathcal {G})\bigr )\,\bigr )(s_{k}), \end{aligned}$$(6)where the maximum is taken over \(a_{0}, s_{1},a_{1},\dotsc , s_{k}, a_{k}\) such that \( a_{0}\in \mathrm {Av}'(s_{0}), s_{1}\in \mathrm {post}(s_{0},a_{0}), a_{1}\in \mathrm {Av}'(s_{1}), \dotsc , s_{k}\in \mathrm {post}(s_{k-1},a_{k-1}), a_{k} \in \mathrm {Av}'(s_{k}). \)
Proof
For the item 1, recall that \(V(\mathcal {G})\) is the least fixed point of the Bellman operator (Theorem 3.3). For each Minimizer state \(s\in S_{\bigcirc }\), we have
For each Maximizer state \(s\in S_{\square }\), we have
The latter equality is because \(\mathrm {Av}'\) does not restrict Maximizer’s actions. This proves the item 1.
The item 2 is proved by induction as follows, using the item 1 in its course.
The inequality in (8) holds since an average over \(s_{1}\) on the left-hand side is replaced by the corresponding maximum on the right-hand side. Note that the value \( \max _{s_{1}{\mathop {\rightarrow }\limits ^{a_{1}}}\,\cdots \,{\mathop {\rightarrow }\limits ^{a_{k}}} \,\, \text { in }\mathrm {Av}'} \min _{i\in [1,k]} \bigl (\,\mathbb {X}_{a_{i}}\bigl (V(\mathcal {G})\bigr )\,\bigr )(s_{i}) \) that occurs on both sides is determined once \(s_{1}\) is determined. This concludes the proof. \(\square \)
Lemma 4.6.2, although not itself used in the following technical development, suggests the idea of global propagation for upper bounds. Note that a bound is given in (6) for each k; it is possible that a bound for some \(k>1\) is tighter than that for \(k=1\), motivating us to take a “look-ahead” further than one step.
However, the bound in (6) is not particularly tuned for tractability: computation of the maximum involves words whose number is exponential in k, and moreover, we want to do so for many k’s.
In the end, our main technical contribution is that a similar “look-ahead” can be done by solving the widest path problem in the following weighted graph. The soundness of this method is not so easy as for Lemma 4.6.2—see Sect. 4.3.
Definition 4.7
(the WG \(\mathcal {W}_\mathrm {LcPg}(\mathcal {M},f)\)). Let \(\mathcal {M}=(S, \mathbf {1},\mathbf {0}, A,\mathrm {Av}', \delta )\) be an MDP, and \(f:S\rightarrow [0,1] \). The WG \(\mathcal {W}_\mathrm {LcPg}(\mathcal {M},f)\) is the following triple (S, E, w).
-
Its set of vertices is S.
-
We have \((s,s')\in E\) if and only if, for some \(a\in \mathrm {Av}'(s)\), we have \(s'\in \mathrm {post}(s,a)\) (i.e., \(\delta (s,a,s')>0\)).
-
The weight function \(w:E\rightarrow [0,1]\) is given by
$$\begin{aligned} w(s,s') = \max \bigl \{\,\mathbb {X}_a f(s) \;\big |\; a \in \mathrm {Av}'(s), s'\in \mathrm {post}(s,a)\,\bigr \}. \end{aligned}$$(9)
In (9), the function f—that is, the previous upper bound \(U_{i-1}\) in Algorithm 3—is propagated one step by the application of \(\mathbb {X}_{a}\). This way of encoding these propagated values as weights in a WG seems pretty rough. For example, in case both \(s'\) and \(s''\) are in \(\mathrm {post}(s,a)\) for each \(a\in \mathrm {Av}'(s)\), we have \(w(s,s')=w(s,s'')\), no matter what the transition probabilities from s to \(s',s''\) are. The return for this paid price (namely the information lost in the rough encoding) is that the resulting data structure (WG) allows fast global analysis via the widest path problem. Our experiment results in Sect. 5 demonstrate that this rough yet global approximation can make upper bounds quickly converge.
4.3 Soundness and Convergence
In Algorithm 3, an SG \(\mathcal {G}\) is turned into an MDP \(\mathcal {M}_{i}\) and then to a WG \(\mathcal {W}_{i}\). Our claim is that computing a widest path in \(\mathcal {W}_{i}\) gives the next upper bound \(U_{i}\) in the iteration. Here we prove the following correctness properties: soundness (\(V(\mathcal {G})\le U_{i}\)) and convergence (\(U_{i}\rightarrow V(\mathcal {G})\) as \(i\rightarrow \infty \)).
We start with a technical lemma. The choice of the MDP \(\mathcal {M}(\mathcal {G},\mathrm {Av}')\) and the value function \(V(\mathcal {G})\) (for \(\mathcal {G}\), not for \(\mathcal {M}(\mathcal {G},\mathrm {Av}')\)) in the statement is subtle; it turns out to be just what we need.
Lemma 4.8
Let \(\mathcal {G}\) be as in Algorithm 3, and \(\mathrm {Av}':S\rightarrow 2^{A}\) be a Minimizer restriction (Definition 4.2). Let \(s_{0}\in S_{\Diamond \mathbf {1}}\) be a state with a non-zero value (Definition 2.5). Consider the MDP \(\mathcal {M}(\mathcal {G},\mathrm {Av}')\) (Definition 4.1), for which we write simply \(\mathcal {M}\). Then there is a finite path \(\pi =s_0 a_0 s_1 a_1 \dotsc a_{n-1} s_{n}\) in \(\mathcal {M}\) that satisfies the following.
-
The path \(\pi \) reaches \(\mathbf {1}\), that is, \(s_{n}=\mathbf {1}\).
-
Each action is optimal in \(\mathcal {M}\) with respect to \(V(\mathcal {G})\), that is, \( \bigl (\mathbb {X}_{a_{i}}\bigl (V(\mathcal {G})\bigr )\bigr )(s_{i}) = max_{a\in \mathrm {Av}'(s_{i})} \bigl (\mathbb {X}_{a}\bigl (V(\mathcal {G})\bigr )\bigr )(s_{i}) \) for each \(i\in [0,n-1]\).
-
The value function \(V(\mathcal {G})\) does not decrease along the path, that is, \( V(\mathcal {G})(s_{i})\le V(\mathcal {G})(s_{i+1}) \) for each \(i\in [0,n-1]\).
Proof
We construct a function \(\mathsf {PATH}: S_{\Diamond \mathbf {1}} \rightarrow S^+\) by Algorithm 4. It is clear that \(\mathsf {PATH}\) assigns a desired path to each \(s_{0}\in S_{\Diamond \mathbf {1}}\). In particular, \(V(\mathcal {G})\) does not decrease along \(\mathsf {PATH}(s_{0})\) since always a state with a smaller value of \(V(\mathcal {G})\) is prepended.

It remains to be shown that, in Line 3, a required pair \((s_{\mathrm {c}}, s_{\mathrm {p}})\) is always found. Let \(S_{\mathrm {v}} \subsetneq S_{\Diamond \mathbf {1}}\) be a subset with \(\mathbf {1}\in S_{\mathrm {v}}\); here \(S_{\mathrm {v}}\) is a proper subset of \( S_{\Diamond \mathbf {1}}\) since otherwise we should be already out of the while loop (Line 2).
Let \( S_{\max } = \{s \in S \setminus S_{\mathrm {v}} \mid V(\mathcal {G})(s) = \max _{s' \in S \setminus S_{\mathrm {v}}} V(\mathcal {G})(s')\}. \) Since \(S_{\mathrm {v}} \subsetneq S_{\Diamond \mathbf {1}}\), we have \(\emptyset \ne S_{\max }\subseteq S_{\Diamond \mathbf {1}}\) and thus \(V(\mathcal {G})(s)> 0\) for each \(s\in S_{\max }\). We also have \(\mathbf {1}\not \in S_{\max }\) since \(\mathbf {1}\in S_{\mathrm {v}}\).
We argue by contradiction: assume that for any \(s \in S\setminus S_{\mathrm {v}}\), \(s'\in S_{\mathrm {v}}\), we have \(s'\not \in \mathrm {post}(s,a_{s})\), where \(a_{s}\) is any optimal action at s in \(\mathcal {M}\) with respect to \(V(\mathcal {G})\).
Now let \(s\in S_{\max }\) be an arbitrary element. It follows that \(V(\mathcal {G})(s) > 0\).
Therefore both inequalities in the above must be equalities. In particular, for the second inequality (in (10)) to be an equality, we must have the weight for each suboptimal \(s'\) to be 0. That is, \(\delta (s,a_{s},s')=0\) for each \(s'\in (S\setminus S_{\mathrm {v}})\setminus S_{\max }\).
The above holds for arbitrary \(s\in S_{\max }\). Therefore, for any strategy that is optimal in \(\mathcal {M}\) with respect to \(V(\mathcal {G})\), once a play is in \(S_{\max }\), it never comes out of \(S_{\max }\), hence the play never reaches \(\mathbf {1}\). Moreover, an optimal strategy in \(\mathcal {M}\) with respect to \(V(\mathcal {G})\) is at least as good as an optimal strategy for Maximizer in \(\mathcal {G}\) (with respect to \(V(\mathcal {G})\)), that is, the latter reaches \(\mathbf {1}\) no more often than the former. This follows from Lemma 4.6. Altogether, we conclude that a Maximizer optimal strategy in \(\mathcal {G}\) does not lead any \(s\in S_{\max }\) to \(\mathbf {1}\), i.e., \(V(\mathcal {M})(s)=0\) for each \(s\in S_{\max }\). Now we come to a contradiction. \(\square \)
In the following lemma, we use the value function \(V(\mathcal {G})\) in the position of f in Definition 4.7. This cannot be done in actual execution of Algorithm 4: unlike \(U_{i-1}\) in Algorithm 3, the value function \(V(\mathcal {G})\) is not known to us. Nevertheless, the lemma is an important theoretical vehicle towards soundness of Algorithm 3.
Lemma 4.9
Let \(\mathcal {G}\) be the game in Algorithm 3, and \(\mathrm {Av}':S\rightarrow 2^{A}\) be a Minimizer restriction (Definition 4.2). Let \(\mathcal {M}=\mathcal {M}(\mathcal {G}, \mathrm {Av}')\), and \(\mathcal {W}=\mathcal {W}_\mathrm {LcPg}\bigl (\mathcal {M}, V(\mathcal {G})\bigr )\). Then, for each state \(s\in S\), we have \(\mathrm {WPW}(\mathcal {W})(s,\mathbf {1})\ge V(\mathcal {G})(s)\).
Proof
In what follows, we let the WG \(\mathcal {W}=\mathcal {W}_\mathrm {LcPg}\bigl (\mathcal {M}, V(\mathcal {G})\bigr ) \) be denoted by \(\mathcal {W}=(S, E, w)\). Let \(\pi =s_0 a_0 s_1 a_1 \dotsc a_{n-1} s_{n}\) be a path of the MDP \(\mathcal {M}\) such that \(s_{n}=\mathbf {1}\), each action is optimal in \(\mathcal {M}\) with respect to \(V(\mathcal {G})\), and \( V(\mathcal {G})(s_{i})\le V(\mathcal {G})(s_{i+1}) \) for each \(i\in [0,n-1]\). Existence of such a path \(\pi \) is shown by Lemma 4.8. Let \(\pi '=s_0 s_1 \dotsc s_{n-1} \mathbf {1}\) be the path in the WG \(\mathcal {W}\) induced by \(\pi \)—we simply omit actions.
The path \(\pi '\) satisfies the following, for each \(i\in [0,n-1]\).
This observation, combined with \(V(\mathcal {G})(s_{0})\le V(\mathcal {G})(s_{1})\le \cdots \le V(\mathcal {G})(s_{n})\) (by the definition of \(\pi \)), implies that the width of the path \(\pi '\) is at least \(V(\mathcal {G})(s_{0})\). The widest path width is no smaller than that. \(\square \)
Theorem 4.10
(soundness). In Algorithm 3, \(V(\mathcal {G})\le U_{i}\) holds for each \(i\in \mathbb {N}\).
Proof
We let the function

clarifying its dependence on \(\mathrm {Av}'\) and \(U:S\rightarrow [0,1]\). Clearly, for each \(i\in \mathbb {N}\), we have \(U_{i}\;=\;T(\mathrm {Av}_{L_{i}},U_{i-1})\).
The rest of the proof is by induction. It is trivial if \(i=0\) (\(U_{0}=\top \)).

\(\square \)
It is clear that \(U_{i}\) decreases with respect to i (\(U_{0}\ge U_{1}\ge \cdots \)), by the presence of \(\min \) in Line 8. It remains to show the following.
Theorem 4.11
(convergence). In Algorithm 3, let the while loop iterate forever. Then \(U_{i}\rightarrow V(\mathcal {G})\) as \(i\rightarrow \infty \).
Proof
We give a proof using the infinitary pigeonhole principle. The proof is nonconstructive—it is not suited for analyzing the speed of convergence, for example—but the proof becomes simpler.
In what follows, we let \(\mathbb {X}_{\sigma }:(S\rightarrow [0,1])\rightarrow (S\rightarrow [0,1])\) denote the Bellman operator on an MDP \(\mathcal {M}\) induced by a strategy \(\sigma \), i.e., \( (\mathbb {X}_{\sigma }f)(s) \;:=\; (\mathbb {X}_{\sigma (s)}f)(s). \) The MC obtained from an MDP \(\mathcal {M}\) by fixing a strategy \(\sigma \) is denoted by \(\mathcal {M}^{\sigma }\).
Towards the statement of the theorem, for each \(i\in \mathbb {N}\), we choose a (positional) strategy \(\sigma _{i}\) in the MDP \(\mathcal {M}_{i}\) as follows.
-
For each \(s\in S_{\Diamond \mathbf {1}}\), take the widest path \(\mathrm{WPath}(\mathcal {W}_{i}, \mathbf {1})(s)=s s_{1}\dotsc \mathbf {1}\) in \(\mathcal {W}_{i}\) from s to \(\mathbf {1}\) (Definition 2.8). Such a path from s to \(\mathbf {1}\) exists—otherwise we have \(U_{i}(s)=0\), hence \(V(\mathcal {G})(s)=0\) by Theorem 4.10.
Let \(\sigma _{i}(s)\) be an action that justifies the first edge in the chosen widest path, that is, \(a\in \mathrm {Av}_{i}(s)\) such that \(s_{1}\in \mathrm {post}(s,a)\).
-
For each \(s\in S\setminus S_{\Diamond \mathbf {1}}\), \(\sigma _{i}(s)\) is freely chosen from \(\mathrm {Av}_{i}(s)\).
It is then easy to see that
Indeed, by the definition of \(\sigma _{i}\), the right-hand side is the weight of the first edge in the chosen widest path. This must be no smaller than the widest path width, that is, the width of the chosen path.
Now, since there are only finitely many strategies for the SG \(\mathcal {G}\), the same is true for the MDPs \(\mathcal {M}_{0}, \mathcal {M}_{1}, \dotsc \) that are obtained from \(\mathcal {G}\) by restricting Minimizer’s actions. Therefore, by the infinitary pigeonhole principle, there are infinitely many \(i_{0}<i_{1}<\cdots \) such that \( \sigma _{i_{0}}=\sigma _{i_{1}}=\cdots \quad =: \sigma ^{\dagger }. \) Moreover, we can choose them so that they are all beyond \(i_{\mathrm {M}}\) in Lemma 4.5, in which case we have
Indeed, Minimizer’s actions are already optimized in \(\mathcal {M}_{i}\) (Lemma 4.5), and thus the only freedom left for \(\sigma ^{\dagger }\) is to choose suboptimal actions of Maximizer’s.
In what follows, we cut down the domain of discourse from \(S\rightarrow [0,1]\) to \(S_{\Diamond \mathbf {1}}\rightarrow [0,1]\), i.e., 1) every function of the type \(f:S \rightarrow [0,1]\) is now seen as the restriction over \(S_{\Diamond \mathbf {1}}\), and 2) the Bellman operator only adds up the value of the input function over \(S_{\Diamond \mathbf {1}}\), namely it is now defined by \(\hat{\mathbb {X}}_a f(s) = \sum _{s' \in S_{\Diamond \mathbf {1}}} \delta (s,a,s') \cdot f(s')\). The operator \(\hat{\mathbb {X}}_\sigma \) is also defined in a similar way to \(\mathbb {X}_\sigma \).
Now proving convergence in \(S_{\Diamond \mathbf {1}}\rightarrow [0,1]\) suffices for the theorem. Indeed, for each \(i\ge i_{\mathrm {M}}\), we have \(V(\mathcal {M}_{i})(s)=V(\mathcal {G})(s)=0\) for each \(s\in S\setminus S_{\Diamond \mathbf {1}}\). This implies that there is no path from s to \(\mathbf {1}\) in \(\mathcal {M}_{i}\), thus neither in the WG \(\mathcal {W}_{i}\). Therefore \(U_{i}\le \mathrm {WPW}(\mathcal {W}_{i})=0\).
A benefit of this domain restriction is that the Bellman operator \(\hat{\mathbb {X}}_{\sigma }\) has a unique fixed point in \(S_{\Diamond \mathbf {1}}\rightarrow [0,1]\) if the set of non-sink states in \(\mathcal {M}^\sigma \) is exactly \(S_{\Diamond \mathbf {1}}\), i.e., \( V(\mathcal {M}^\sigma )(s) > 0 \) holds if and only if \(s \in S_{\Diamond \mathbf {1}}\). Furthermore, this unique fixed point is the value function \(V(\mathcal {M}^{\sigma })\) restricted to \(S_{\Diamond \mathbf {1}}\subseteq S\) [4, Theorem 10.19]. Therefore \(V(\mathcal {M}^{\sigma })\) is computed by the gfp Kleene iteration, too:
We show the following by induction on m.
It is obvious for \(m=0\). For the step case, we have the following. Notice that the inequality (11) holds in the restricted domain for \(i \ge i_M\).
We have proved (14) which proves \(\inf _{i}U_{i}\le \inf _m(\hat{\mathbb {X}}_{\sigma ^{\dagger }})^{m}\top \).
Lastly, we prove that \( V(\mathcal {M}_{i_m}^{\sigma ^\dagger })(s) > 0 \) holds if and only if \( s \in S_{\Diamond \mathbf {1}}\) for each \(m \in \mathbb {N}\), and thus \(\sigma ^\dagger \) follows the characterization in (13). This proves
Implication to the right is clear as Minimizer restriction is done optimally in \(\mathcal {M}_{i_m}\). Conversely, if \(s \in S_{\Diamond \mathbf {1}}\), then there is a path from s to \(\mathbf {1}\) in \(\mathcal {W}_{i_m}\). Let \(\mathrm{WPath}(\mathcal {W}_{i_m}, \mathbf {1})(s) = s_0s_1\ldots s_k\), where \(s_0 = s\), \(k \in \mathbb {N}\) and \(s_k = \mathbf {1}\). Then by the property of \(\mathrm{WPath}\) and \(\sigma ^\dagger \), we have \(\delta (s_j, \sigma ^\dagger (s_j), s_{j+1}) >0\) for each \(j <k\). Thus, the probability that the finite path \(\mathrm{WPath}(\mathcal {W}_{i_m}, \mathbf {1})(s)\) is obtained by running \(\mathcal {M}_{i_m}^{\sigma ^\dagger }\) starting from s, which is apparently at most \(V(\mathcal {M}_{i_{m}}^{\sigma ^{\dagger }})(s)\), is nonzero. Hence we have implication to the left.
Combining (12), (15) and Theorem 4.10, we obtain the claim. \(\square \)
5 Experiment Results
Experiment Settings. We compare the following four algorithms.
-
WP is our BVI algorithm via widest paths. It avoids end component (EC) computation by global propagation of upper bounds.
-
DFL is the implementation of the main algorithm in [20]. It relies on EC computation for deflating.
-
DFL_m is our modification of DFL, where some unnecessary repetition of EC computation is removed.
-
DFL_BRTDP is the learning-based variant of DFL. It restricts bound update to those states which are visited by simulations. See [20] for details.
The latter three—coming from [20]—are the only existing BVI algorithms for SGs with a convergence guarantee, to the best of our knowledge. The implementation of DFL and DFL_BRTDP is provided by the authors of [20].
The four algorithms are implemented on top of PRISM-games [21] version 2.0. We used the stopping threshold \(\varepsilon =10^{-6}\). The experiments were conducted on Dell Inspiron 3421 Laptop with 4.00 GB RAM and Intel(R) Core(TM) i5-3337U 1.80 GHz processor.
In the implementations of DFL and DFL_BRTDP, the deflating operation is applied only once every five iterations [20, Sect. B.3]. Following this, our WP also solves the widest path problem (Line 8) only once every five iterations, while other operations are applied in each iteration.
For input SGs, we took four models from the literature: mdsm [11], cloud [6], teamform [12] and investor [22]. In addition, we used our model manyECs—an artificial model with many ECs—to assess the effect of ECs on performance. The model manyECs is presented in the appendix in [24]. Each of these five models comes with a model parameter N.
There is another model called cdmsn in [20]. We do not discuss cdmsn since all the algorithms (ours and those from [20]) terminated within 0.001 seconds.
Results. The number i of iterations and the running time for each algorithm and each input SG is shown in Table 1. For DFL_BRTDP, the ratio of states visited by the algorithm is shown in percentage; the smaller it is, the more efficient the algorithm is in reducing the state space. Each number for DFL_BRTDP (a probabilistic algorithm) is the average over 5 runs.
Discussion. We observe consistent performance advantage of our algorithm (WP). Even in the mdsm model where the DFL algorithms do not suffer from EC computation (#EC is just 1), WP’s performance is comparable to DFL. The cloud model is where the learning-based approach in [20] works well—see visit% that are very small. Our WP performs comparably against DFL_BRTDP, too.
The performance advantage of our WP algorithm is eminent, not only in the artificial model of manyECs (where WP is faster by magnitudes), but also in the realistic model investor that comes from a financial application scenario [22]. The results for these two models suggest that WP is indeed advantageous when EC computation poses a bottleneck for other algorithms.
Overall, we observe that our WP algorithm can be the first choice when it comes to solving SGs: for some models, it runs much faster than other algorithms; for other models, even if the performances of other algorithms differs a lot, WP’s performance is comparable with the best algorithm.
6 Conclusions and Future Work
In this paper, we presented a new BVI algorithm for solving stochastic games. It features global propagation of upper bounds by widest paths, via a novel encoding of the problem to a suitable weighted graph. This way we avoid computation of end components that often penalizes the performance of the other BVI-based algorithms. Our experimental comparison with known BVI algorithms for SGs demonstrates the efficiency of our algorithm. For correctness of the algorithm, we presented proofs for soundness and convergence.
Extending the current algorithm for more advanced settings is future work—this is much like the results in [20] are extended and used in [2, 3, 16]. In doing so, we hope to make essential use of structures that are unique to those advanced problem settings. Another important direction is to push forward the idea of global propagation in verification and synthesis, seeking further instances of the idea. Finally, pursuing the global propagation idea in the context of reinforcement learning—where problems are often formalized using MDPs and the Bellman operator is heavily utilized—may open up another fruitful collaboration between formal methods and statistical machine learning.
References
Andersson, D., Miltersen, P.B.: The complexity of solving stochastic games on graphs. In: Dong, Y., Du, D.-Z., Ibarra, O. (eds.) ISAAC 2009. LNCS, vol. 5878, pp. 112–121. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-10631-6_13
Ashok, P., Kretinsky, J., Weininger, M.: Approximating values of generalized-reachability stochastic games. CoRR abs/1908.05106 (2019). http://arxiv.org/abs/1908.05106
Ashok, P., Křetínský, J., Weininger, M.: PAC statistical model checking for Markov decision processes and stochastic games. In: Dillig, I., Tasiran, S. (eds.) CAV 2019. LNCS, vol. 11561, pp. 497–519. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-25540-4_29
Baier, C., Katoen, J.P.: Principles of Model Checking. MIT Press, Cambridge (2008)
Brázdil, T., et al.: Verification of Markov decision processes using learning algorithms. In: Cassez, F., Raskin, J.-F. (eds.) ATVA 2014. LNCS, vol. 8837, pp. 98–114. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-11936-6_8
Calinescu, R., Kikuchi, S., Johnson, K.: Compositional reverification of probabilistic safety properties for large-scale complex IT systems. In: Calinescu, R., Garlan, D. (eds.) Monterey Workshop 2012. LNCS, vol. 7539, pp. 303–329. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-34059-8_16
Chatterjee, K., Dvorák, W., Henzinger, M., Svozil, A.: Near-linear time algorithms for streett objectives in graphs and MDPS. In: Fokkink, W., van Glabbeek, R. (eds.) 30th International Conference on Concurrency Theory CONCUR 2019, 27–30 August 2019, Amsterdam, the Netherlands. LIPIcs, vol. 140, pp. 7:1–7:16. Schloss Dagstuhl - Leibniz-Zentrum für Informatik (2019). https://doi.org/10.4230/LIPIcs.CONCUR.2019.7
Chatterjee, K., Fijalkow, N.: A reduction from parity games to simple stochastic games. In: D’Agostino, G., La Torre, S. (eds.) Proceedings of Second International Symposium on Games, Automata, Logics and Formal Verification, GandALF 2011, Minori, Italy, 15–17 June 2011. EPTCS, vol. 54, pp. 74–86 (2011). https://doi.org/10.4204/EPTCS.54.6
Chatterjee, K., Henzinger, M.: Efficient and dynamic algorithms for alternating büchi games and maximal end-component decomposition. J. ACM (JACM) 61(3), 15 (2014)
Chatterjee, K., Henzinger, T.A.: Value iteration. In: Grumberg, O., Veith, H. (eds.) 25 Years of Model Checking. LNCS, vol. 5000, pp. 107–138. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-69850-0_7
Chen, T., Forejt, V., Kwiatkowska, M.Z., Parker, D., Simaitis, A.: Automatic verification of competitive stochastic systems. Formal Methods Syst. Design 43(1), 61–92 (2013). https://doi.org/10.1007/s10703-013-0183-7
Chen, T., Kwiatkowska, M., Parker, D., Simaitis, A.: Verifying team formation protocols with probabilistic model checking. In: Leite, J., Torroni, P., Ågotnes, T., Boella, G., van der Torre, L. (eds.) CLIMA 2011. LNCS (LNAI), vol. 6814, pp. 190–207. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-22359-4_14
Condon, A.: The complexity of stochastic games. Inf. Comput. 96(2), 203–224 (1992). https://doi.org/10.1016/0890-5401(92)90048-K
Courcoubetis, C., Yannakakis, M.: The complexity of probabilistic verification. J. ACM 42(4), 857–907 (1995). https://doi.org/10.1145/210332.210339
De Alfaro, L.: Formal verification of probabilistic systems. Citeseer (1997)
Eisentraut, J., Kretinsky, J., Rotar, A.: Stopping criteria for value and strategy iteration on concurrent stochastic reachability games. CoRR abs/1909.08348 (2019). http://arxiv.org/abs/1909.08348
Fredman, M.L., Tarjan, R.E.: Fibonacci heaps and their uses in improved network optimization algorithms. J. ACM 34(3), 596–615 (1987). https://doi.org/10.1145/28869.28874
Haddad, S., Monmege, B.: Interval iteration algorithm for MDPs and IMDPs. Theoret. Comput. Sci. 735, 111–131 (2018)
Hoffman, A.J., Karp, R.M.: On nonterminating stochastic games. Manage. Sci. 12(5), 359–370 (1966). https://doi.org/10.1287/mnsc.12.5.359
Kelmendi, E., Krämer, J., Křetínský, J., Weininger, M.: Value iteration for simple stochastic games: stopping criterion and learning algorithm. In: Chockler, H., Weissenbacher, G. (eds.) CAV 2018. LNCS, vol. 10981, pp. 623–642. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-96145-3_36
Kwiatkowska, M., Parker, D., Wiltsche, C.: PRISM-games: verification and strategy synthesis for stochastic multi-player games with multiple objectives. Int. J. Softw. Tools Technol. Transf. 20(2), 195–210 (2017)
McIver, A., Morgan, C.: Results on the quantitative \(\rm \mu \)-calculus qm\(\rm \mu \rm \). ACM Trans. Comput. Log. 8(1), 3 (2007). https://doi.org/10.1145/1182613.1182616
McMahan, H.B., Likhachev, M., Gordon, G.J.: Bounded real-time dynamic programming: RTDP with monotone upper bounds and performance guarantees. In: Raedt, L.D., Wrobel, S. (eds.) Machine Learning, Proceedings of the Twenty-Second International Conference (ICML 2005), Bonn, Germany, 7–11 August 2005. ACM International Conference Proceeding Series, vol. 119, pp. 569–576. ACM (2005). https://doi.org/10.1145/1102351.1102423
Phalakarn, K., Takisaka, T., Haas, T., Hasuo, I.: Widest paths and global propagation in bounded value iteration for stochastic games. arXiv preprint (2020)
Svorenová, M., Kwiatkowska, M.: Quantitative verification and strategy synthesis for stochastic games. Eur. J. Control 30, 15–30 (2016). https://doi.org/10.1016/j.ejcon.2016.04.009
Ujma, M.: On Verication and Controller Synthesis for Probabilistic Systems at Runtime. Ph.D. thesis, Wolfson College, University of Oxford (2015)
Acknowledgment
The authors are supported by ERATO HASUO Metamathematics for Systems Design Project (No. JPMJER1603), JST; I.H. is supported by Grant-in-Aid No. 15KT0012, JSPS. Thanks are due to Maximilian Weininger and Edon Kelmendi for sharing their implementation, and to Pranav Ashok and David Sprunger for useful discussions and comments.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2020 The Author(s)
About this paper

Cite this paper
Phalakarn, K., Takisaka, T., Haas, T., Hasuo, I. (2020). Widest Paths and Global Propagation in Bounded Value Iteration for Stochastic Games. In: Lahiri, S., Wang, C. (eds) Computer Aided Verification. CAV 2020. Lecture Notes in Computer Science(), vol 12225. Springer, Cham. https://doi.org/10.1007/978-3-030-53291-8_19
Download citation
DOI: https://doi.org/10.1007/978-3-030-53291-8_19
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-53290-1
Online ISBN: 978-3-030-53291-8
eBook Packages: Computer ScienceComputer Science (R0)