
Abstract
The \(\pi \)-calculus is a widely used process calculus, which models communications between processes and allows the passing of communication links. Various operational semantics of the \(\pi \)-calculus have been proposed, which can be classified according to whether transitions are unlabelled (so-called reductions) or labelled. With labelled transitions, we can distinguish early and late semantics. The early version allows a process to receive names it already knows from the environment, while the late semantics and reduction semantics do not. All existing reversible versions of the \(\pi \)-calculus use reduction or late semantics, despite the early semantics of the (forward-only) \(\pi \)-calculus being more widely used than the late. We define \(\pi \)IH, the first reversible early \(\pi \)-calculus, and give it a denotational semantics in terms of reversible bundle event structures. The new calculus is a reversible form of the internal \(\pi \)-calculus, which is a subset of the \(\pi \)-calculus where every link sent by an output is private, yielding greater symmetry between inputs and outputs.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



1 Introduction
The \(\pi \)-calculus [18] is a widely used process calculus, which models communications between processes using input and output actions, and allows the passing of communication links. Various operational semantics of the \(\pi \)-calculus have been proposed, which can be classified according to whether transitions are unlabelled or labelled. Unlabelled transitions (so-called reductions) represent completed interactions. As observed in [25] they give us the internal behaviour of complete systems, whereas to reason compositionally about the behaviour of a system in terms of its components we need labelled transitions. With labelled transitions, we can distinguish early and late semantics [19], with the difference being that early semantics allows a process to receive (free) names it already knows from the environment, while the late does not. This creates additional causation in the early case between those inputs and previous output actions making bound names free. All existing reversible versions of the \(\pi \)-calculus use reduction semantics [14, 26] or late semantics [7, 17]. However the early semantics of the (forward-only) \(\pi \)-calculus is more widely used than the late, partly because it has a sound correspondence with contextual congruences [13, 20].
We define \(\pi \)IH, the first reversible early \(\pi \)-calculus, and give it a denotational semantics in terms of reversible event structures. The new calculus is a reversible form of the internal \(\pi \)-calculus, or \(\pi \)I-calculus [24], which is a subset of the \(\pi \)-calculus where every link sent by an output is bound (private), yielding greater symmetry between inputs and outputs. It has been shown that the asynchronous \(\pi \)-calculus can be encoded in the asynchronous form of the \(\pi \)I-calculus [2].
The \(\pi \)-calculus has two forms of causation. Structural causation, as one would find in CCS, comes directly from the structure of the process, e.g. in \(a(b).c(d)\) the action \(a(b)\) must happen before \(c(d)\). Link causation, on the other hand, comes from one action making a name available for others to use, e.g. in the process \(a(x)\vert \overline{b}(c)\), the event \(a(c)\) will be caused by \(\overline{b}(c)\) making c a free name. Note that link causation as in this example is present in the early form of the \(\pi \)I-calculus though not the late, since it is created by the process receiving one of its free names. Restricting ourselves to the \(\pi \)I-calculus, rather than the full \(\pi \)-calculus lets us focus on the link causation created by early semantics, since it removes the other forms of link causation present in the \(\pi \)-calculus.
We base \(\pi \)IH on the work of Hildebrandt et al. [12], which used extrusion histories and locations to define a stable non-interleaving early operational semantics for the \(\pi \)-calculus. We extend the extrusion histories so that they contain enough information to reverse the \(\pi \)I-calculus, storing not only extrusions but also communications. Allowing processes to evolve, while moving past actions to a history separate from the process, is called dynamic reversibility [9]. By contrast, static reversibility, as in CCSK [21], lets processes keep their structure during the computation, and annotations are used to keep track of the current state and how actions may be reversed.
Event structures are a model of concurrency which describe causation, conflict and concurrency between events. They are ‘truly concurrent’ in that they do not reduce concurrency of events to the different possible interleavings. They have been used to model forward-only process calculi [3, 6, 27], including the \(\pi \)I-calculus [5]. Describing reversible processes as event structures is useful because it gives us a simple representation of the causal relationships between actions and gives us equivalences between processes which generate isomorphic event structures. True concurrency in semantics is particularly important in reversible process calculi, as the order actions can reverse in depends on their causal relations [22].
Event structure semantics of dynamically reversible process calculi have the added complexity of the histories and the actions in the process being separated, obscuring the structural causation. This was an issue for Cristescu et al. [8], who used rigid families [4], related to event structures, to describe the semantics of R\(\pi \) [7]. Their semantics require a process to first reverse all actions to find the original process, map this process to a rigid family, and then apply each of the reversed memories in order to reach the current state of the process. Aubert and Cristescu [1] used a similar approach to describe the semantics of a subset of RCCS processes as configuration structures. We use a different tactic of first mapping to a statically reversible calculus, \(\pi \)IK, and then obtaining the event structure. This means that while we do have to reconstruct the original structure of the process, we avoid redoing the actions in the event structure.
Our \(\pi \)IK is inspired by CCSK and the statically reversible \(\pi \)-calculus of [17], which use communication keys to denote past actions. To keep track of link causation, keys are used in a number of different ways in [17]. In our case we can handle link causation by using keys purely to annotate the action which was performed using the key, and any names which were substituted during that action.
Although our two reversible variants of the \(\pi \)I-calculus have very different syntax and originate from different ideas, we show an operational correspondence between them in Theorem 4.6. We do this despite the extrusion histories containing more information than the keys, since they remember what bound names were before being substituted. The mapping from \(\pi \)IH to \(\pi \)IK bears some resemblance to the one presented from RCCS to CCSK in [16], though with some important differences. \(\pi \)IH uses centralised extrusion histories more similar to rho\(\pi \) [15] while RCCS uses distributed memories. Additionally, unlike CCS, \(\pi \)I has substitution as part of its transitions and memories are handled differently by \(\pi \)IK and \(\pi \)IH, and our mapping has to take this into account.
We describe denotational structural event structure semantics of \(\pi \)IK, partly inspired by [5, 6], using reversible bundle event structures [10]. Reversible event structures [23] allow their events to reverse and include relations describing when events can reverse. Bundle event structures are more expressive than prime event structures, since they allow an event to have multiple possible conflicting causes. This allows us to model parallel composition without having a single action correspond to multiple events. While it would be possible to model \(\pi \)IK using reversible prime event structures, using bundle event structures not only gives us fewer events, it also lays the foundation for adding rollback to \(\pi \)IK and \(\pi \)IH, similarly to [10], which cannot be done using reversible prime event structures.
The structure of the paper is as follows: Sect. 2 describes \(\pi \)IH; Sect. 3 describes \(\pi \)IK; Sect. 4 describes the mapping from \(\pi \)IH to \(\pi \)IK; Sect. 5 recalls labelled reversible bundle event structures; and Sect. 6 gives event structure semantics of \(\pi \)IK. Proofs of the results presented in this paper can be found in the technical report [11].
2 \(\pi \)I-Calculus Reversible Semantics with Extrusion Histories
Stable non-interleaving, early operational semantics of the \(\pi \)-calculus were defined by Hildebrandt et al. in [12], using locations and extrusion histories to keep track of link causation. We will in this section use a similar approach to define a reversible variant of the \(\pi \)I-calculus, \(\pi \)IH, using the locations and histories to keep track of not just causation, but also past actions. The \(\pi \)I-calculus is a restricted variant of the \(\pi \)-calculus wherein output on a channel a, \(\overline{a}(b)\), binds the name being sent, b, corresponding to the \(\pi \)-calculus process \((\nu b)\overline{a}\!\left\langle {b} \right\rangle \!.P\). This creates greater symmetry with the input \(a(x)\), where the variable x is also bound. The syntax of \(\pi \)IH processes is:
\(P {:}{:}=\sum \limits _{i\in I} \alpha _i.P_i \;\mid \; P_0\vert P_1 \;\mid \; (\nu x) P \;\;\;\; \alpha {:}{:}=\overline{a}(b)\;\mid \; a(b)\)
The forward semantics of \(\pi \)IH can be seen in Table 1 and the reverse semantics can be seen in Table 2. We associate each transition with an action \(\mu {:}{:}=\alpha \;\vert \; \tau \) and a location u (Definition 2.1), describing where the action came from and what changes are made to the process as a result of the action. We store these location and action pairs in extrusion and communication histories associated with processes, so \((\overline{H},\underline{H},H)\vdash \! P\) means that if \((\mu ,u)\) is an action and location pair in the output history \(\overline{H}\) then \(\mu \) is an output action, which P previously performed at location u. Similarly \(\underline{H}\) contains pairs of input actions and locations and H contains triples of two communicating actions and the location associated with their communication. We use \(\mathbf {H}\) as shorthand for \((\overline{H},\underline{H},H)\).
Definition 2.1
(Location [12]). A location u of an action \(\mu \) is one of the following:
-
1.
\(l[P][P']\) if \(\mu \) is an input or output, where \(l\in \{0,1\}^*\) describes the path taken through parallel compositions to get to \(\mu \)’s origin, P is the subprocess reached by following the path before \(\mu \) has been performed, and \(P'\) is the result of performing \(\mu \) in P.
-
2.
\(l\left\langle {0l_0[P_0][P_0'],1l_1[P_1][P_1']} \right\rangle \) if \(\mu =\tau \), where \(l0l_0[P_0][P_0']\) and \(l1l_1[P_1][P_1']\) are the locations of the two actions communicating.
The path l can be empty if the action did not go through any parallel compositions.
We also use the operations on extrusion histories from Definition 2.2. These (1) add a branch to the path in every location, (2) isolate the extrusions whose locations begin with a specific branch, (3) isolate the extrusions whose locations begin with a specific branch and then remove the first branch from the locations, and (4) add a pair to the history it belongs in.
Definition 2.2
(Operations on extrusion histories [12]). Given an extrusion history \((\overline{H},\underline{H},H)\), for \(H^*\in \{\overline{H},\underline{H},H\}\) we have the following operations for \(i\in \{0,1\}\):
-
1.
\(iH^*=\{(\mu ,iu)\mid (\mu ,u)\in H^*\}\)
-
2.
\([i]H^*=\{(\mu ,iu)\mid (\mu ,iu)\in H^*\}\)
-
3.
\([\check{i}]H^*=\{(\mu ,u)\mid (\mu ,iu)\in H^*\}\)
-
4.
\(\mathbf {H}+(\mu ,u)={\left\{ \begin{array}{ll} (\overline{H}\cup \{L\},\underline{H},H) &{} if\,(\mu ,u)=(\overline{a}(n),u) \\ (\overline{H},\underline{H}\cup \{L\},H) &{} if\,(\mu ,u)=(a(x),u) \\ (\overline{H},\underline{H},H\cup \{L\}) &{} if\,(\mu ,u)=(a(x),\overline{a}(n),l\langle u_0,u_1\rangle ) \\ \end{array}\right. }\)
The forwards semantics of \(\pi \)IH have six rules. In \([\text {OUT}]\) the action is an output, the location is the process before and after doing the output, and they are added to the output history. The equivalent reverse rule, \([\text {OUT}^{-1}]\), similarly removes the pair from the history and transforms the process from the second part of the location back to the first. The input rule \([\text {IN}]\) works similarly, but performs a substitution on the received name and adds the pair to the input history instead. In \([\text {PAR}_i]\) we isolate the parts of the histories whose locations start with i and use those to perform an action in \(P_i\), getting \(\mathbf {H}_i'\vdash \! P_i'\). It then replaces the part of the histories parts of the histories whose locations start with i with \(\mathbf {H}_i'\) when propagating the action through the parallel. A communication in \([\text {COM}_i]\) adds memory of the communication to the history. The rules \([\text {SCOPE}]\) and \([\text {STR}]\) are standard and self-explanatory.
The reverse rules use the extrusion histories to find a location \(l[P][P']\) such that the current state of the subprocess at l is \(P'\), and change it to P.
In these semantics structural congruence, consisting only of \(\alpha \)-conversion together with \({!P}\equiv {!P\vert P}\) and \({(\nu ~a)(\nu b)P}\equiv {(\nu ~b)(\nu ~a) P}\), is primarily used to create and remove extra copies of a replicated process when reversing the action that happened before the replication. Since we use locations in our extrusion histories, we try to avoid using structural congruence any more than necessary. However, not using it for parallel composition would mean that we would need some other way of preventing traces such as  , which allows a process to reach a state it could not reach via a parabolic trace. Using structural congruence for replication does not cause any problems for the locations, as we can tell past actions originating in each copy of P apart by the path in their location, with actions from the ith copy having a path of i 0s followed by a 1.
, which allows a process to reach a state it could not reach via a parabolic trace. Using structural congruence for replication does not cause any problems for the locations, as we can tell past actions originating in each copy of P apart by the path in their location, with actions from the ith copy having a path of i 0s followed by a 1.
Example 2.3
Consider the process \((a(x).\overline{x}(d) \vert \overline{a}(c))\vert b(y)\). If we start with empty histories, each transition adds actions and locations:

We show that our forwards and reverse transitions correspond.
Proposition 2.4
(Loop).
-
1.
Given a \(\pi \)IH process P and an extrusion history \(\mathbf {H}\), if \({\mathbf {H}\vdash \! P}\,\xrightarrow [u]{\alpha } {\mathbf {H}' \vdash \! Q}\), then
 .
. -
2.
Given a forwards-reachable \(\pi \)IH process P and an extrusion history \(\mathbf {H}\), if
 , then \({\mathbf {H}'\vdash \! Q}\,\,\xrightarrow [u]{\alpha } {\mathbf {H}\vdash \! P}\).
, then \({\mathbf {H}'\vdash \! Q}\,\,\xrightarrow [u]{\alpha } {\mathbf {H}\vdash \! P}\).
 .
. , then
, then 3 \(\pi \)I-Calculus Reversible Semantics with Annotations
In order to define event structure semantics of \(\pi \)IH, we first map from \(\pi \)IH to a statically reversible variant of \(\pi \)I-calculus, called \(\pi \)IK. \(\pi \)IK is based on previous statically reversible calculi \(\pi \)K [17] and CCSK [21]. Both of these use communication keys to denote past actions and which other actions they have interacted with, so \({a(x)\vert \overline{a}(b)}\xrightarrow {\tau [n]}{a(b)[n]\vert \overline{a}(b)[n]}\) means a communication with the key n has taken place between the two actions. We apply this idea to define early semantics of \(\pi \)IK, which has the following syntax:
\(P {:}{:}= \alpha .P\,\mid \,\alpha [n].P\,\mid \, P_0+P_1\,\mid \, P_0\vert P_1\,\mid \, (\nu x)P \;\;\; \alpha {:}{:}=\overline{a}(b)\,\mid \, a(b)\)
The primary difference between applying communication keys to CCS and the \(\pi \)I-calculus is the need to deal with substitution. We need to keep track of not only which actions have communicated with each other, but also which names were substituted when. We do this by giving the substituted names a key, \(a_{[n]}\), but otherwise treating them the same as those without the key, except when undoing the input associated with n.
Table 3 shows the forward semantics of \(\pi \)IK. The reverse semantics can be seen in Table 4. We use \(\alpha \) to range over input and output actions and \(\mu \) over input, output, and \(\tau \). We use \(\mathsf {std}(P)\) denote that P is a standard process, meaning it does not contain any past actions (actions annotated with a key), and \(\mathsf {fsh}[n](P)\) to denote that a key n is fresh for P. Names in past actions are always free. Our semantics very much resemble those of CCSK, with the exceptions of substitution and ensuring that any name being output does not appear elsewhere in the process. The semantics use structural congruence as defined in Table 5.
We again show a correspondence between forward and reverse transitions.
Proposition 3.1
(Loop).
-
1.
Given a process P, if \(P\xrightarrow {\mu [n]} Q\) then
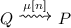 .
. -
2.
Given a forwards reachable process P, if
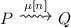 then \(Q\xrightarrow {\mu [n]} P\).
then \(Q\xrightarrow {\mu [n]} P\).
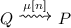 .
.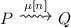 then
then 4 Mapping from \(\pi \)IH to \(\pi \)IK
We will now define a mapping from \(\pi \)IH to \(\pi \)IK and show that we have an operational correspondence in Theorem 4.6. The extrusion histories store more information than the keys, as they keep track of which names were substituted, as illustrated by Example 4.1. This means we lose some information in our mapping, but not information we need.
Example 4.1
Consider the processes \((\emptyset ,\{(a(b),[a(x)][0])\},\emptyset )\vdash \! 0\) and a(b)[n]. These are the result of a(x) receiving b in the two different semantics. We can see that the extrusion history remembers that the input name was x before b was received, but the keys do not remember, and when reversing the action could use any name as the input name. This does not make a great deal of difference, as after reversing a(b), the process with the extrusion history can also \(\alpha \)-convert x to any name.
Since we intend to define a mapping from processes with extrusion histories to processes with keys, we first describe how to add keys to substituted names in a process in Definition 4.2. We have a function, S, which takes a process, \(P_1\), in which we wish to add the key [n] to all those names which were x in a previous state of the process, \(P_2\), before being substituted for some other name in an input action with the key [n].
Definition 4.2
(Substituting in \(\pi \)IK-process to correspond with processes with extrusion histories). Given a \(\pi \)IK process \(P_1\), a \(\pi \)I-calculus process without keys, \(P_2\), a key n, and a name x, we can add the key n to any names which x has been substituted with, by applying \(S(P_1,P_2,[n],x)\), defined as:
-
1.
\(S\left( 0,0,[n],x\right) =0\)
-
2.
\(S\left( \sum \limits _{i\in I} P_{i1},\sum \limits _{i\in I} P_{i2},[n],x\right) =\sum \limits _{i\in I}S\left( P_{i1},P_{i2},[n],x\right) \)
-
3.
\(S\left( P_1\vert Q_1,P_2\vert Q_2,[n],x\right) =S\left( P_1,P_2,[n],x\right) \vert S\left( Q_1,Q_2,[n],x\right) \)
-
4.
\(S\left( (\nu a) P_1, (\nu b) P_2,[n],x\right) = P_1'\) where:
if \(x=b\) then \(P_1'=P_1\) and otherwise \(P_1'=(\nu a) S\left( P_1,P_2,[n],x\right) \).
-
5.
\(S\left( \alpha _1.P_1,\alpha _2.P_2,[n],x\right) =\alpha _1'.P_1'\) where:
if \(\alpha _2\in \{x(c),\overline{x}(c)\}\) then \(\alpha _1'=\alpha _{1_{[n]}}\) and otherwise \(\alpha _1'=\alpha _1\);
if \(\alpha _2\in \{c(x),\overline{c}(x)\}\) then \(P_1'=P_1\) and otherwise \(P_1'=S\left( P_1,P_2,[n],x\right) \).
-
6.
\(S\left( \alpha _1[m].P_1,\alpha _2.P_2,[n],x\right) =\alpha _1'[m].P_1'\) where:
if \(\alpha _2\in \{x(c),\overline{x}(c)\}\) then \(\alpha _1'=\alpha _{1_{[n]}}\) and otherwise \(\alpha _1'=\alpha _1\);
if \(\alpha _2\in \{c(x),\overline{c}(x)\}\) then \(P_1'=P_1\) and otherwise \(P_1'=S\left( P_1,P_2,[n],x\right) \).
-
7.
\(S\left( !P_1, !P_2,[n],x\right) = {!S\left( P_1,P_2,[n],x\right) }\)
-
8.
\(S\left( P_1\vert P_1', !P_2,[n],x\right) = S\left( P_1,!P_2,[n],x\right) \vert S\left( P_1',P_2,[n],x\right) \)
-
9.
\(S\left( !P_1,P_2\vert P_2', [n],x\right) =S\left( !P_1,P_2,[n],x\right) \vert S\left( P_1,P_2',[n],x\right) \)
where \(a(b)_{[n]}=a_{[n]}(b)\) and \(\overline{a}(b)_{[n]}=\overline{a_{[n]}}(b)\)
Being able to annotate our names with keys, we can define a mapping, E, from extrusion histories to keys in Definition 4.4. E iterates over the extrusions, having one process which builds \(\pi \)IK-process, and another that keeps track of which state of the original \(\pi \)IH process has been reached. When turning an extrusion into a keyed action, we use the locations as key and also give each extrusion an extra copy of its location to use for determining where the action came from. This way we can use one copy to iteratively go through the process, removing splits from the path as we go through them, while still having another intact copy of the location to use as the final key. In \(E(\mathbf {H}\vdash \! P,P')\), \(\mathbf {H}\) is a history of extrusions which need to be turned into keyed actions, P is the process these keyed actions should be added to, and \(P'\) is the state the process would have reached, had the added extrusions been reversed instead of turned into keyed actions.
If E encounters a parallel composition in P (case 2), it splits its extrusion histories in three. One part, \(\mathbf {H}_{\mathsf {shared}}\) contains the locations which have an empty path, and therefore belong to actions from before the processes split. Another part contains the locations beginning with 0, and goes to the first part of the process. And finally the third part contains the locations beginning with 1, and goes to the second part of the process.
E can add an action – and the choices not picked when that action was performed – to P (cases 3, 4) when the associated location has an empty path and has \(P'\) as its result process. When turning an input memory from the history into a past input action in the process (case 4), we use S (Definition 4.2) to add keys to the substituted names. When E encounters a restriction (case 5), it moves a memory that can be used inside the restriction inside. It does this iteratively until there are no such memories left in the extrusion histories. We apply E to a process in Example 4.5.
Definition 4.3
The function \(\mathsf {lcopy}\) gives each member of an extrusion history an extra copy of its location:

Definition 4.4
Given a \(\pi \)IH process, \(\mathbf {H}\vdash \! P\), we can create an equivalent \(\pi \)IK process, \(E(\mathsf {lcopy}(\mathbf {H})\vdash \! P,P)=P'\) defined as
-
1.
\(E((\emptyset ,\emptyset ,\emptyset )\vdash \! P,P')=P\)
-
2.
\(E(\mathbf {H}\vdash \! P_0\vert P_1,P_0'\vert P_1')=E(\mathbf {H}_{\mathsf {shared}}\vdash \! P_0'' \vert P_1'' ,P_0'''\vert P_1''')\) where:
\(\,\,\,\mathbf {H}_{\mathsf {shared}}=(\{(\alpha ,u,u')\mid {(\alpha ,u,u')\in \overline{H}} \text { and }u\ne iu''\},\{(\alpha ,u,u')\mid {(\alpha ,u,u')\in \underline{H}} {\text {and }} {u\ne iu''}\},\emptyset )\)
\(\,\,\,P_0''=E((\overline{H_0},\underline{H_0},H_0)\vdash \! P_0,P_0')\) where:
\(\,\,\,\,\,\,\,\,\,\overline{H_0}=\{(\overline{a}(b),u_0,u_0')\mid (\overline{a}(b),0u_0,u_0')\in \overline{H} \text { or }{(\overline{a}(b),\alpha _1,\left\langle {0u_0,1u_1} \right\rangle ,u_0')}\in H\}\)
\(\,\,\,\,\,\,\,\,\,\underline{H_0}=\{ (a(b),u_0,u_0')\mid (a(b),0u_0,u_0')\in \underline{H} \text { or }{(a(b),\alpha _1,\left\langle {0u_0,1u_1} \right\rangle ,u_0')}\in H\}\)
\(\,\,\,\,\,\,\,\,\,H_0=\{(\alpha ,\alpha ',u,u')\mid (\alpha ,\alpha ',0u,u')\in H\}\)
\(\,\,\,P_1''=E((\overline{H_1},\underline{H_1},H_1)\vdash \! P_1,P_1'))\) where:
\(\,\,\,\,\,\,\,\,\,\overline{H_1}=\{(\overline{a}(b),u_1,u_1')\mid (\overline{a}(b),1u_1,u_1')\in \overline{H} \text { or }{(\alpha _0,\overline{a}(b),\left\langle {0u_0,1u_1} \right\rangle ,u_1')}\in H\}\)
\(\,\,\,\,\,\,\,\,\,\underline{H_1}=\{(a(b),u_1,u_1')\mid (a(b),1u_1,u_1')\in \underline{H} \text { or }{(\alpha _0,a(b),\left\langle {0u_0,1u_1} \right\rangle ,u_1')}\in H\}\)
\(\,\,\,\,\,\,\,\,\,H_1=\{(\alpha ,\alpha ',u,u')\mid (\alpha ,\alpha ',1u,u')\in H\}\)
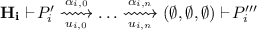 for \(i\in \{0,1\}\)
for \(i\in \{0,1\}\) -
3.
\(E((\overline{H}\cup \{(\overline{a}(b),[Q][P'],u)\},\underline{H},H)\vdash \! P,P')=E(\mathbf {H}\vdash \! \overline{a}(b)\left[ u\right] .P+\sum \limits _{i\in I\setminus \{j\}} \alpha _i.P_i,Q)\)
\(\,\,\,if Q=\sum _{i\in I} \alpha _i.P_i\), \(\overline{a}(b)=\alpha _j\), and \(P'=P_j\)
-
4.
\(E((\overline{H},\underline{H}\cup \{(a(b),[Q][P'],u)\},H)\vdash \! P,P')=\)\(E(\mathbf {H}\vdash \! a(b)\left[ u\right] .S(P,P_j,[u],x)+\sum \limits _{i\in I\setminus \{j\}} \alpha _i.P_i,Q)\)
\(\,\,\,if Q=\sum _{i\in I} \alpha _i.P_i\), \(a(x)=\alpha _j\), and \(P'=P_j[x:=b]\)
-
5.
\(E(\mathbf {H}\vdash \! (\nu x)P, (\nu x)P')=E(\mathbf {H}-(\alpha ,u,u')\vdash \! P'',(\nu x)Q')\)
\(\,\,\,where P''=(\nu x)E((\emptyset ,\emptyset ,\emptyset )+(\alpha ,u,u')\vdash \! P,P')\)
\(\,\,\,if (\alpha ,u,u')\in \overline{H}\cup \underline{H}\) and

-
6.
\(E(\mathbf {H}\vdash \! !P,!P')=E(\mathbf {H}\vdash \! !P\vert P,!P'\vert P')\) if there exists \((\alpha ,u,u')\in \overline{H}\cup \underline{H}\cup H\) such that \(u\ne [Q][Q']\).
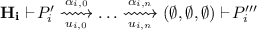 for
for 
Example 4.5
We will now apply E to the process
with locations \(u_0=[b(y).y(x)][a(x)]\), \(u_1=[\overline{b}(a)][0]\), and \(u_2=[\overline{b}(c).(b(y).y(x)\mid \overline{b}(a)][b(y).y(x)\mid \overline{b}(a)]\). We perform
Since we are at a parallel, we use Case 2 of Definition 4.4 to split the extrusion histories into three to get \(E((\{(\overline{b}(c),u_2,u_2)\},\emptyset ,\emptyset )\vdash \!P_0\mid P_1,b(y).y(x)\mid \overline{b}(a))\) where \(P_0=E((\emptyset ,\{(b(a),u_0,\langle {0u_0,1u_1}\rangle )\},\emptyset )\vdash \! a(x),a(x))\) and \(P_1= E((\{(\overline{b}(a),u_1,\langle {0u_0,1u_1}\rangle )\},\emptyset ,\emptyset )\vdash \! 0,0)\).
To find \(P_0\), we look at \(u_0\), and find that it has \(a(x)\) as its result, meaning we can apply Case 4 to obtain \(E((\emptyset ,\emptyset ,\emptyset )\vdash \! b(a)[\langle {0u_0,1u_1}\rangle ].S(a(x),y(x),[\langle {0u_0,1u_1}\rangle ],y), b(y).y(x))\). And by applying Case 5 of Definition 4.2, \(S(a(x),y(x),[\langle {0u_0,1u_1}\rangle ],y)=a_{{[\langle {0u_0,1u_1}\rangle ]}}(x)\). Since we have no more extrusions to add, we apply Case 1 to get our process \(P_0=b(a)[\langle {0u_0,1u_1}\rangle ].a_{{[\langle {0u_0,1u_1}\rangle ]}}(x)\).
To find \(P_1\), we similarly look at \(u_1\) and find that we can apply Case 3. This gives us \(P_1=\overline{b}(a)[\langle {0u_0,1u_1}\rangle ].0\).
We can then apply Case 3 to \(E((\{(\overline{b}(c),u_2,u_2)\},\emptyset ,\emptyset )\vdash \! P_0 \mid P_1,b(y).y(x)\mid \overline{b}(a))\). This gives us our final process,
where \(k=\langle {0u_0,1u_1}\rangle \) and \(k'=u_2\)
We can then show, in Theorem 4.6, that we have an operational correspondence between our two calculi and E preserves transitions. Item 1 states that every transition in \(\pi \)IH corresponds to one in \(\pi \)IK process generated by E, and Item 2 vice versa.
Theorem 4.6
Given a reachable \(\pi \)IH process, \(\mathbf {H}\vdash \! P\), and an action, \(\mu \),
-
1.
if there exists a location u such that
 then there exists a key, m, such that
then there exists a key, m, such that 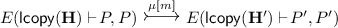 ;
; -
2.
if there exists a key, m, such that
 , then there exists a location, u, and a \(\pi \)IH process, \(\mathbf {H}'\vdash \! P'\), such that
, then there exists a location, u, and a \(\pi \)IH process, \(\mathbf {H}'\vdash \! P'\), such that  and \(P''\equiv E(\mathsf {lcopy}(\mathbf {H}')\vdash \! P',P')\).
and \(P''\equiv E(\mathsf {lcopy}(\mathbf {H}')\vdash \! P',P')\).
 then there exists a key, m, such that
then there exists a key, m, such that 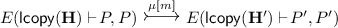 ;
; , then there exists a location, u, and a
, then there exists a location, u, and a  and
and 5 Bundle Event Structures
In this section we will recall the definition of labelled reversible bundle event structures (LRBESs), which we intend to use later to define the event structure semantics of \(\pi \)IK and through that \(\pi \)IH. We also describe some operations on LRBESs, which our semantics will make use of. This section is primarily a review of definitions from [10]. We use bundle event structures, rather than the more common prime event structures, because LRBESs yield more compact event structures with fewer events and simplifies parallel composition.
An LRBES consists of a set of events, E, a subset of which, F, are reversible, and three relations on them. The bundle relation, \(\mapsto \), says that if \(X\mapsto e\) then one of the events of X must have happened before e can and all events in X are in conflict with each other. The conflict relation, \(\mathrel {\sharp }\), says that if \(e\mathrel {\sharp }e'\) then e and \(e'\) cannot occur in the same configuration. The prevention relation, \(\rhd \), says that if \(e\rhd \underline{e'}\) then \(e'\) cannot reverse after e has happened. Since the event structure is labelled, we also have a set of labels \(\mathsf {Act}\), and a labelling function \(\lambda \) from events to labels. We use \(\underline{e}\) to denote e being reversed, and \(e^*\) to denote either e or \(\underline{e}\).
Definition 5.1
(Labelled Reversible Bundle Event Structure [10]). A labelled reversible bundle event structure is a 7-tuple \(\mathcal {E}=(E,F,\mapsto ,\mathrel {\sharp },\rhd ,\lambda ,\mathsf {Act})\) where:
-
1.
E is the set of events;
-
2.
\(F\subseteq E\) is the set of reversible events;
-
3.
the bundle set, \({\mapsto }\subseteq 2^E\times (E\cup \underline{F})\), satisfies \(X\mapsto e^*\Rightarrow \forall e_1,e_2\in X.e_1\ne e_2\Rightarrow e_1\mathrel {\sharp }e_2\) and for all \(e\in F\), \(\{e\}\mapsto \underline{e}\);
-
4.
the conflict relation, \({\mathrel {\sharp }} \subseteq E\times E\), is symmetric and irreflexive;
-
5.
\(\rhd \subseteq E\times \underline{F}\) is the prevention relation.
-
6.
\(\lambda :E\rightarrow \mathsf {Act}\) is a labelling function.
An event in an LRBES can have multiple possible causes as defined in Definition 5.2. A possible cause X of an event e is a conflict-free set of events which contains a member of each bundle associated with e and contains possible causes of all events in X.
Definition 5.2
(Possible Cause). Given an LRBES, \(\mathcal {E}=(E_{},F_{},\mapsto _{},\mathrel {\sharp }_{},\rhd _{},\lambda _{},\mathsf {Act}_{})\) and an event \(e\in E\), \(X\subseteq E\) is a possible cause of e if
-
\(e\notin X\), \(X \text {is finite}\), whenever \(X'\mapsto e\) we have \(X'\cap X\ne \emptyset \);
-
for any \( e',e''\in \{e\}\cup X\), we have
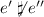 (\(X\cup \{e\}\) is conflict-free);
(\(X\cup \{e\}\) is conflict-free); -
for all \(e'\in X\), there exists \(X''\subseteq X\), such that \(X''\) is a possible cause of \(e'\);
-
there does not exist any \(X'''\subset X\), such that \(X'''\) is a possible cause of e.
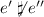 (
(Since we want to compare the event structures generated by a process to the operational semantics, we need a notion of transitions on event structures. For this purpose we use configuration systems (CSs), which event structures can be translated into.
Definition 5.3
(Configuration system [23]). A configuration system (CS) is a quadruple \(\mathcal {C} = (E_{},F_{},\mathsf {C}_{},\rightarrow _{})\) where E is a set of events, \(F\subseteq E\) is a set of reversible events, \(\mathsf {C}\subseteq 2^E\) is the set of configurations, and \(\rightarrow \subseteq \mathsf {C}\times 2^{E\cup \underline{F}} \times \mathsf {C}\) is a labelled transition relation such that if \(X\xrightarrow {A\cup \underline{B}} Y\) then:
-
\(X,Y\in \mathsf {C}\), \(A\cap X=\emptyset \); \(B\subseteq X\cap F\); and \(Y=(X\setminus B)\cup A\);
-
for all \(A'\subseteq A\) and \(B'\subseteq B\), we have \(X\xrightarrow {A'\cup \underline{B'}} Z \xrightarrow {(A\setminus A')\cup \underline{(B\setminus B')}}Y\), meaning \(Z=(X\setminus B')\cup A'\in \mathsf {C}\).
Definition 5.4
(From LRBES to CS [10]). We define a mapping \(C_{br}\) from LRBESs to CSs as: \(C_{br}((E_{},F_{},\mapsto _{},\mathrel {\sharp }_{},\rhd _{},\lambda _{},\mathsf {Act}_{}))=(E_{},F_{},\mathsf {C}_{},\rightarrow _{})\) where:
-
1.
\(X\in \textsf {C}\) if X is conflict-free;
-
2.
For \(X,Y\in \textsf {C}\), \(A\subseteq E\), and \(B\subseteq F\), there exists a transition \(X\xrightarrow {A\cup \underline{B}} Y\) if:
-
(a)
\(Y=(X\setminus B)\cup A\); \(X\cap A=\emptyset \); \(B\subseteq X\); and \(X\cup A\) conflict-free;
-
(b)
for all \(e\in B\), if \(e'\rhd \underline{e}\) then \(e'\notin X\cup A\);
-
(c)
for all \(e\in A\) and \(X'\subseteq E\), if \(X'\mapsto e\) then \(X'\cap (X\setminus B)\ne \emptyset \);
-
(d)
for all \(e\in B\) and \(X'\subseteq E\), if \(X'\mapsto \underline{e}\) then \(X'\cap (X\setminus (B\setminus \{e\}))\ne \emptyset \).
-
(a)
For our semantics we need to define a prefix, restriction, parallel composition, and choice. Causal prefixing takes a label, \(\mu \), an event, e, and an LRBES, \(\mathcal {E}\), and adds e to \(\mathcal {E}\) with the label \(\mu \) and associating every other event in \(\mathcal {E}\) with a bundle containing only e. Restriction removes a set of events from an LRBES.
Definition 5.5
(Causal Prefixes [10]). Given an LRBES \(\mathcal {E}\), a label \(\mu \), and an event e, \((\mu )(e).\mathcal {E}=(E',F',\mapsto ',\mathrel {\sharp }',\rhd ',\lambda ',\mathsf {Act}')\) where:

Removing a set of labels L from an LRBES removes not just events with labels in A but also events dependent on events with labels in L.
Definition 5.6
(Removing labels and their dependants). Given an event structure \(\mathcal {E}=(E_{},F_{},\mapsto _{},\mathrel {\sharp }_{},\rhd _{},\lambda _{},\mathsf {Act}_{})\) and a set of labels \(L\subseteq \mathsf {Act}\), we define \(\rho _{\mathcal {E}}(L)=X\) as the maximum subset of E such that
-
1.
if \(e\in X\) then \(\lambda (e)\notin L\);
-
2.
if \(e\in X\) then there exists a possible cause of e, x, such that \(x\subseteq X\).
A choice between LRBESs puts all the events of one event structure in conflict with the events of the others.
Definition 5.7
(Choice [10]). Given LRBESs \(\mathcal {E}_0,\mathcal {E}_1,\dots ,\mathcal {E}_n\), the choice between them is \(\sum \limits _{0\le i\le n}\mathcal {E}_i=(E_{},F_{},\mapsto _{},\mathrel {\sharp }_{},\rhd _{},\lambda _{},\mathsf {Act}_{})\) where:

Definition 5.8
(Restriction [10]). Given an LRBES, \(\mathcal {E}=(E_{},F_{},\mapsto _{},\mathrel {\sharp }_{},\rhd _{},\lambda _{},\mathsf {Act}_{})\), restricting \(\mathcal {E}\) to \(E'\subseteq E\) creates \(\mathcal {E}\upharpoonright E'=(E',F',\mapsto ',\mathrel {\sharp }',\rhd ',\lambda ',\mathsf {Act}')\) where:

For parallel composition we construct a product of event structures, which consists of events corresponding to synchronisations between the two event structures. The possible causes of an event \((e_0,e_1)\) contain a possible cause of \(e_0\) and a possible cause of \(e_1\).
Definition 5.9
(Parallel [10]). Given two LRBESs \(\mathcal {E}_0 = (E_{0},F_{0},\mapsto _{0},\mathrel {\sharp }_{0},\rhd _{0},\lambda _{0},\mathsf {Act}_{0})\) and \(\mathcal {E}_1=(E_{1},F_{1},\mapsto _{1},\mathrel {\sharp }_{1},\rhd _{1},\lambda _{1},\mathsf {Act}_{1})\), their parallel composition \(\mathcal {E}_0\times \mathcal {E}_1=(E_{},F_{},\mapsto _{},\mathrel {\sharp }_{},\rhd _{},\lambda _{},\mathsf {Act}_{})\) with projections \(\pi _0\) and \(\pi _1\) where:
-
1.
\(E=E_0\times _* E_1=\{(e,*) \mid e\in E_0\} \cup \{(*,e) \mid e\in E_1\} \cup \{(e,e') \mid e\in E_0\text { and } e'\in E_1\}\);
-
2.
\(F=F_0\times _* F_1=\{(e,*) \mid e\in F_0\} \cup \{(*,e) \mid e\in F_1\} \cup \{(e,e') \mid e\in F_0\text { and } e'\in F_1\}\);
-
3.
for \(i \in \{0,1\}\) we have \((e_0,e_1)\in E\), \(\pi _i((e_0,e_1))=e_i\);
-
4.
for any \(e^*\in E\cup \underline{F}\), \(X\subseteq E\), \(X\mapsto e^*\) iff there exists \(i\in \{0,1\}\) and \(X_i\subseteq E_i\) such that \(X_i\mapsto \pi _i(e)^*\) and \(X=\{e'\in E\mid \pi _i(e')\in X_i\}\);
-
5.
for any \(e,e'\in E\), \(e\mathrel {\sharp }e'\) iff there exists \(i\in \{0,1\}\) such that \(\pi _i(e)\mathrel {\sharp }_i\pi _i(e')\), or \(\pi _i(e)=\pi _i(e')\ne \bot \) and \(\pi _{1-i}(e)\ne \pi _{1-i}(e')\);
-
6.
for any \(e\in E\), \(e'\in F\), \(e\rhd \underline{e'}\) iff there exists \(i\in \{0,1\}\) such that \(\pi _i(e)\rhd _i\underline{\pi _i(e')}\).
-
7.
\(\lambda (e)={\left\{ \begin{array}{ll} \lambda _0(e_0) &{} if\,e=(e_0,*)\\ \lambda _1(e_1) &{} if\,e=(*,e_1)\\ \tau &{} if\,e=(e_0,e_1)\,and\,either\,\lambda _0(e_0)=a(x) \,and\,\lambda _1(e_1)=\overline{a}(x)\\ &{} or\,\lambda _0(e_0)=\overline{a}(x)\,and\,\lambda _1(e_1)=a(x)\\ 0 &{} otherwise \end{array}\right. }\)
-
8.
\(\mathsf {Act}=\{\tau \}\cup \mathsf {Act}_0\cup \mathsf {Act}_1\)
6 Event Structure Semantics of \(\pi \)IK
In this section we define event structure semantics of \(\pi \)IK using the LRBESs and operations defined in Sect. 5. Theorems 6.3 and 6.4 give us an operational correspondence between a \(\pi \)IK process and the generated event structure. Together with Theorem 4.6, this gives us a correspondence between a \(\pi \)IH process and the event structure it generates by going via a \(\pi \)IK process.
As we want to ensure that all free and bound names in our process are distinct, we modify our syntax for replication, assigning each replication an infinite set, \(\mathbf {x}\), of names to substitute into the place of bound names in each created copy of the process, so that
Before proceeding to the semantics we also define the standard bound names of a process P, \(\mathsf {sbn}(P)\), meaning the names that would be bound in P if every action was reversed, in Definition 6.1.
Definition 6.1
The standard bound names of a process P, \(\mathsf {sbn}(P)\), are defined as:

We can now define the event structure semantics in Table 6. We do this using rules of the form \(\left\rbrace \![{P} \right]\!\}_{(\mathcal {N},l)}=\left\langle {\mathcal {E},\mathsf {Init},k} \right\rangle \) where l is the level of unfolding of replication, \(\mathcal {E}\) is an LRBES, \(\mathsf {Init}\) is the initial configuration, \(\mathcal {N}\supseteq n(P)\) is a set of names, which any input in the process could receive, and \(k:\mathsf {Init}\rightarrow \mathcal {K}\) is a function assigning communication keys to the past actions, which we use in parallel composition to determine which synchronisations of past actions to put in \(\mathsf {Init}\). We define \(\left\rbrace \![{P} \right]\!\}_{\mathcal {N}}=\sup _{l\in \mathbb {N}} \left\rbrace \![{P} \right]\!\}_{(\mathcal {N},l)}\).
The denotational semantics in Table 6 make use of the LRBES operators defined in Sect. 5. The choice and output cases are straightforward uses of the choice and causal prefix operators. The input creates a case for prefixing an input of each name in \(\mathcal {N}\) and a choice between the cases. We have two cases for restriction, one for restriction originating from a past communication and another for restriction originating from the original process. If the restriction does not originate from the original process, then we ignore it, otherwise we remove events which would use the restricted channel and their causes. The parallel composition uses the parallel operator, but additionally needs to consider link causation caused by the early semantics. Each event labelled with an input of a name in standard bound names gets a bundle consisting of the event labelled with the output on that name. And each output event is prevented from reversing by the input names receiving that name. This way, inputs on extruded names are caused by the output that made the name free. Replication substitutes the names and counts down the level of replication.
Note that the only difference between a future and a past action is that the event corresponding to a past action is put in the initial state and given a communication key.
Example 6.2
Consider the process \(a(b)[n]\mid \overline{a}(b)[n]\). Our event structure semantics generate an LRBES \(\left\rbrace \![{a(x)[n]\mid \overline{a}(b[n])} \right]\!\}_{\{a,b,x\}}=\left\langle {(E_{},F_{},\mapsto _{},\mathrel {\sharp }_{},\rhd _{},\lambda _{},\mathsf {Act}_{}),\mathsf {Init},k} \right\rangle \) where:
From this we see that (1) receiving b is causally dependent on sending b, (2) all the possible inputs on a are in conflict with one another, (3) the synchronisation between the input and the output is in conflict with either happening on their own, and (4) since the two past actions have the same key, the initial state contains their synchronisation.
We show in Theorems 6.3 and 6.4 that given a process P with a conflict-free initial state, including any reachable process, performing a transition \(P\xrightarrow {\mu [m]} P'\) does not affect the event structure, as \(\left\rbrace \![{P} \right]\!\}_{\mathcal {N}}\) and \(\left\rbrace \![{P'} \right]\!\}_{\mathcal {N}}\) are isomorphic. It also means we have an event e labelled \(\mu \) such that e is available in P’s initial state, and \(P'\)’s initial state is P’s initial state with e added. A similar event can be removed to correspond to a reverse action.
Theorem 6.3
Let P be a forwards reachable process wherein all bound and free names are different and let \(\mathcal {N}\supseteq n(P)\) be a set of names. If (1) \(\left\rbrace \![{P} \right]\!\}_{\mathcal {N}}=\left\langle {\mathcal {E},\mathsf {Init},k} \right\rangle \) where \(\mathcal {E}=(E_{},F_{},\mapsto _{},\mathrel {\sharp }_{},\rhd _{},\lambda _{},\mathsf {Act}_{})\), and \(\mathsf {Init}\) is conflict-free, and (2) there exists a transition \(P\xrightarrow {\mu [m]} P'\) such that \(\left\rbrace \![{P'} \right]\!\}_{\mathcal {N}}=\left\langle {\mathcal {E}',\mathsf {Init}',k'} \right\rangle \), then there exists an isomorphism \(f:\mathcal {E}\rightarrow \mathcal {E}'\) and a transition in \(C_{br}(\mathcal {E})\), \(\mathsf {Init}\xrightarrow {\{e\}} X\), such that \(\lambda (e)=\mu \), \(f\circ k'=k[e\mapsto m]\), and \(f(X)=\mathsf {Init}'\).
Theorem 6.4
Let P be a forwards reachable process wherein all bound and free names are different and let \(\mathcal {N}\supseteq n(P)\) be a set of names. If (1) \(\left\rbrace \![{P} \right]\!\}_{\mathcal {N}}=\left\langle {\mathcal {E},\mathsf {Init},k} \right\rangle \) where \(\mathcal {E}=(E_{},F_{},\mapsto _{},\mathrel {\sharp }_{},\rhd _{},\lambda _{},\mathsf {Act}_{})\), and (2) there exists a transition \(\mathsf {Init}\xrightarrow {\{e\}} X\) in \(C_{br}(\mathcal {E})\), then there exists a transition \(P\xrightarrow {\mu [m]} P'\) such that \(\left\rbrace \![{P'} \right]\!\}_{\mathcal {N}}=\left\langle {\mathcal {E}',\mathsf {Init}',k'} \right\rangle \) and an isomorphism \(f:\mathcal {E}\rightarrow \mathcal {E}'\) such that \(\lambda (e)=\mu \), \(f\circ k'=k[e\mapsto m]\), and \(f(X)=\mathsf {Init}'\).
By Theorems 4.6, 6.3, and 6.4 we can combine the event structure semantics of \(\pi \)IK and mapping E (Definition 4.4) and get an operational correspondence between \(\mathbf {H}\vdash \! P\) and the event structure \(\left\rbrace \![{E(\mathsf {lcopy}(\mathbf {H})\vdash \! P,P)} \right]\!\}_{n(E(\mathsf {lcopy}(\mathbf {H})\vdash \! P,P))}\).
7 Conclusion and Future Work
All existing reversible versions of the \(\pi \)-calculus use reduction semantics [14, 26] or late semantics [7, 17], despite the early semantics being used more widely than the late in the forward-only setting. We have introduced \(\pi \)IH, the first reversible early \(\pi \)-calculus. It is a reversible form of the internal \(\pi \)-calculus, where names being sent in output actions are always bound. As well as structural causation, as in CCS, the early form of the internal \(\pi \)-calculus also has a form of link causation created by the semantics being early, which is not present in other reversible \(\pi \)-calculi. In \(\pi \)IH past actions are tracked by using extrusion histories adapted from [12], which move past actions and their locations into separate histories for dynamic reversibility. We mediate the event structure semantics of \(\pi \)IH via a statically reversible version of the internal \(\pi \)-calculus, \(\pi \)IK, which keeps the structure of the process intact but annotates past actions with keys, similarly to \(\pi \)K [17] and CCSK [21]. We showed that a process \(\pi \)IH with extrusion histories can be mapped to a \(\pi \)IK process with keys, creating an operational correspondence (Theorem 4.6).
The event structure semantics of \(\pi \)IK, and by extension \(\pi \)IH, are defined inductively on the syntax of the process. We use labelled reversible bundle event structures [10], rather than prime event structures, to get a more compact representation where each action in the calculus has only one corresponding event. While causation in the internal \(\pi \)-calculus is simpler that in the full \(\pi \)-calculus, our early semantics means that we still have to handle link causation, in the form of an input receiving a free name being caused by a previous output of that free name. We show an operational correspondence between \(\pi \)IK processes and their event structure representations in Theorems 6.3 and 6.4. Cristescu et al. [8] have used rigid families [4], related to event structures, to describe the semantics of R\(\pi \) [7]. However, unlike our denotational event structure semantics, their semantics require one to reverse every action in the process before applying the mapping to a rigid family, and then redo every reversed action in the rigid family. Our approach of using a static calculus as an intermediate step means we get the current state of the event structure immediately, and do not need to redo the past steps.
Future Work: We could expand the event structure semantics of \(\pi \)IK to \(\pi \)K. This would entail significantly more link causation, but would give us event structure semantics of a full \(\pi \)-calculus. Another possibility is to expand \(\pi \)IH to get a full reversible early \(\pi \)-calculus.
References
Aubert, C., Cristescu, I.: Contextual equivalences in configuration structures and reversibility. JLAMP 86(1), 77–106 (2017). https://doi.org/10.1016/j.jlamp.2016.08.004
Boreale, M.: On the expressiveness of internal mobility in name-passing calculi. Theoret. Comput. Sci. 195(2), 205–226 (1998). https://doi.org/10.1016/S0304-3975(97)00220-X
Boudol, G., Castellani, I.: Permutation of transitions: an event structure semantics for CCS and SCCS. In: de Bakker, J.W., de Roever, W.-P., Rozenberg, G. (eds.) REX 1988. LNCS, vol. 354, pp. 411–427. Springer, Heidelberg (1989). https://doi.org/10.1007/BFb0013028
Castellan, S., Hayman, J., Lasson, M., Winskel, G.: Strategies as concurrent processes. Electron. Notes Theor. Comput. Sci. 308, 87–107 (2014). https://doi.org/10.1016/j.entcs.2014.10.006
Crafa, S., Varacca, D., Yoshida, N.: Compositional event structure semantics for the internal \({\pi }\)-calculus. In: Caires, L., Vasconcelos, V.T. (eds.) CONCUR 2007. LNCS, vol. 4703, pp. 317–332. Springer, Heidelberg (2007). https://doi.org/10.1007/978-3-540-74407-8_22
Crafa, S., Varacca, D., Yoshida, N.: Event structure semantics of parallel extrusion in the Pi-calculus. In: Birkedal, L. (ed.) FoSSaCS 2012. LNCS, vol. 7213, pp. 225–239. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-28729-9_15
Cristescu, I., Krivine, J., Varacca, D.: A compositional semantics for the reversible pi-calculus. LICS, pp. 388–397. IEEE Computer Society, Washington, DC (2013). https://doi.org/10.1109/LICS.2013.45
Cristescu, I., Krivine, J., Varacca, D.: Rigid families for the reversible \(\pi \)-calculus. In: Devitt, S., Lanese, I. (eds.) RC 2016. LNCS, vol. 9720, pp. 3–19. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-40578-0_1
Danos, V., Krivine, J.: Reversible communicating systems. In: Gardner, P., Yoshida, N. (eds.) CONCUR 2004. LNCS, vol. 3170, pp. 292–307. Springer, Heidelberg (2004). https://doi.org/10.1007/978-3-540-28644-8_19
Graversen, E., Phillips, I., Yoshida, N.: Event structure semantics of (controlled) reversible CCS. In: Kari, J., Ulidowski, I. (eds.) RC 2018. LNCS, vol. 11106, pp. 102–122. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-99498-7_7
Graversen, E., Phillips, I., Yoshida, N.: Event structures for the reversible early internal pi-calculus. arXiv:2004.01211 [cs.FL] (2020). https://arxiv.org/abs/2004.01211
Hildebrandt, T.T., Johansen, C., Normann, H.: A stable non-interleaving early operational semantics for the Pi-calculus. In: Drewes, F., Martín-Vide, C., Truthe, B. (eds.) LATA 2017. LNCS, vol. 10168, pp. 51–63. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-53733-7_3
Honda, K., Yoshida, N.: On reduction-based process semantics. TCS 151(2), 437–486 (1995). https://doi.org/10.1016/0304-3975(95)00074-7
Lanese, I., Mezzina, C.A., Stefani, J.-B.: Reversing higher-order Pi. In: Gastin, P., Laroussinie, F. (eds.) CONCUR 2010. LNCS, vol. 6269, pp. 478–493. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-15375-4_33
Lanese, I., Mezzina, C.A., Stefani, J.B.: Reversibility in the higher-order \(\pi \)-calculus. Theoret. Comput. Sci. 625, 25–84 (2016). https://doi.org/10.1016/j.tcs.2016.02.019
Medić, D., Mezzina, C.A.: Static VS dynamic reversibility in CCS. In: Devitt, S., Lanese, I. (eds.) RC 2016. LNCS, vol. 9720, pp. 36–51. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-40578-0_3
Medic, D., Mezzina, C.A., Phillips, I., Yoshida, N.: A parametric framework for reversible pi-calculi. In: EXPRESS/SOS, pp. 87–103 (2018). https://doi.org/10.4204/EPTCS.276.8
Milner, R., Parrow, J., Walker, D.: A calculus of mobile processes, I and II. Inf. Comput. 100(1), 1–77 (1992). https://doi.org/10.1016/0890-5401(92)90008-4
Milner, R., Parrow, J., Walker, D.: Modal logics for mobile processes. Theoret. Comput. Sci. 114(1), 149–171 (1993). https://doi.org/10.1016/0304-3975(93)90156-N
Milner, R., Sangiorgi, D.: Barbed bisimulation. In: Kuich, W. (ed.) ICALP 1992. LNCS, vol. 623, pp. 685–695. Springer, Heidelberg (1992). https://doi.org/10.1007/3-540-55719-9_114
Phillips, I., Ulidowski, I.: Reversing algebraic process calculi. JLAMP 73(1–2), 70–96 (2007). https://doi.org/10.1016/j.jlap.2006.11.002
Phillips, I., Ulidowski, I.: Reversibility and models for concurrency. Electron. Notes Theor. Comput. Sci. 192(1), 93–108 (2007). https://doi.org/10.1016/j.entcs.2007.08.018
Phillips, I., Ulidowski, I.: Reversibility and asymmetric conflict in event structures. JLAMP 84(6), 781–805 (2015). https://doi.org/10.1016/j.jlamp.2015.07.004
Sangiorgi, D.: \(\pi \)-calculus, internal mobility, and agent-passing calculi. Theoret. Comput. Sci. 167(1), 235–274 (1996). https://doi.org/10.1016/0304-3975(96)00075-8
Sewell, P., Wojciechowski, P.T., Unyapoth, A.: Nomadic pict: programming languages, communication infrastructure overlays, and semantics for mobile computation. ACM Trans. Program. Lang. Syst. 32(4), 121–1263 (2010). https://doi.org/10.1145/1734206.1734209
Tiezzi, F., Yoshida, N.: Reversible session-based pi-calculus. JLAMP 84(5), 684–707 (2015). https://doi.org/10.1016/j.jlamp.2015.03.004
Winskel, G.: Event structure semantics for CCS and related languages. In: Nielsen, M., Schmidt, E.M. (eds.) ICALP 1982. LNCS, vol. 140, pp. 561–576. Springer, Heidelberg (1982). https://doi.org/10.1007/BFb0012800
Acknowledgements
We thank Thomas Hildebrandt and Håkon Normann for discussions on how to translate their work on \(\pi \)-calculus with extrusion histories to a reversible setting. We thank the anonymous reviewers of RC 2020 for their helpful comments.
This work was partially supported by an EPSRC DTP award; also by the following EPSRC projects: EP/K034413/1, EP/K011715/1, EP/L00058X/1, EP/N027833/1, EP/T006544/1, EP/N028201/1 and EP/T014709/1; and by EU COST Action IC1405 on Reversible Computation.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Graversen, E., Phillips, I., Yoshida, N. (2020). Event Structures for the Reversible Early Internal \(\pi \)-Calculus. In: Lanese, I., Rawski, M. (eds) Reversible Computation. RC 2020. Lecture Notes in Computer Science(), vol 12227. Springer, Cham. https://doi.org/10.1007/978-3-030-52482-1_4
Download citation
DOI: https://doi.org/10.1007/978-3-030-52482-1_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-52481-4
Online ISBN: 978-3-030-52482-1
eBook Packages: Computer ScienceComputer Science (R0)