
Abstract
Attribute profiles integrate spectral and spatial information present in an image. The construction of attribute profiles is based on attribute filtering which requires proper threshold values. In the literature, only a few approaches are available to automatically detect the threshold values. Among them, the recently presented state-of-the-art method overcomes the prior limitations but is computationally demanding. In this paper, we present a simple and computationally efficient method to detect the threshold values automatically. The proposed method obtains the candidate threshold values directly from the tree representation of the image and selects suitable threshold values in two stages. In the first stage, we separate the larger attribute values to preserve important components and then the lower attribute values are clustered in the second stage to detect the final threshold values. Using these threshold values attribute profiles are constructed for two real hyperspectral data sets considering three different attributes. The experimental results demonstrate that the proposed method is effective and faster than the state-of-the-art method.
The RPS-NER research grant from AICTE, New Delhi supports this work in part.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Hyperspectral images (HSIs) are acquired in hundreds of contiguous channels with a fine spectral resolution that allow accurate class-discrimination among the surface objects. This classification accuracy is further improved by integrating the spectral and spatial information of the HSI. An effective way of integrating spectral and spatial information is by constructing attribute profiles (APs). The characterization of spectral-spatial information with APs has gained tremendous popularity over the last decade [3, 6]. APs are concatenation of original image and the filtered images obtained by applying attribute filters (AFs). AFs process a given image based on its connected components while preserving the geometry of the objects. It can merge the objects to their background based on comparison of values for any characteristic (attribute) that can be computed for a connected component with a predefined threshold value [10]. Several attributes related to the shape, scale or gray-level of the image are suggested in the literature [6, 10]. A sequence of threshold values helps in multiscale characterization of the image providing a set of filtering results which on concatenation along with the original image create an attribute profile (AP) [3]. For hyperspectral images an extended AP (EAP) is generated by concatenating the APs constructed for each of its component images in the reduced dimension [4, 6].
One major issue in the construction of APs is the selection of proper threshold values employed during attribute filtering. To address this issue, in the literature few methods attempted to construct large profile and select the informative filtered images from it [1, 9]. In these approaches we need to create the large profile considering manual sampling of large number of threshold values. With a goal for creating low dimensional APs having sufficient spectral-spatial information, a small number of techniques are present in the literature that detect threshold values automatically [2, 5, 7, 8]. In [7] an interesting approach is presented that is sensitive to the preliminary clustering or classification for detection of candidate threshold values. Approaches in [5] and [8] are concentrated on single attributes namely area and standard deviation respectively. Another interesting approach is presented by Cavallaro et al. in [2] that overcomes the prior limitations and automatically detects threshold values by exploiting regression to approximate the curve generated after computing a measure for all the possible threshold values. This method is computationally demanding.
In this paper, we propose a simple and computationally efficient method to detect the threshold values automatically. The proposed method represents the given image using a tree structure. This tree structure represents the nested connected components of the image which can be exploited for obtaining attribute values as candidate threshold values. Then, on the unique candidate threshold values two-stage clustering operation is performed. In the first stage to preserve important connected components the larger attribute values are separated from the lower attribute values that mostly represent noise. In the second stage the lower attribute values are clustered into required number of groups whose representatives are selected as final threshold values to construct APs. Such constructed APs are compact in size and represent sufficient spectral-spatial information. Experiments are conducted on two real hyperspectral images that confirm the effectiveness and efficiency of the proposed method over the state-of-the-art method.
2 Basics of Attribute Profiles
The attribute profiles are constructed based on the connected operators called attribute filters (AFs). AFs process a gray-scale image by filtering the connected components (CCs) from the image. For this, the gray-scale image is represented with the help of a tree structure. Among the several tree representations available in literature, max tree (min tree) is considered in this paper [10]. Next, the nodes of the tree are filtered based on a criterion formulated considering an attribute and a threshold value. Finally, the filtered image is obtained from the filtered tree. As introduced in [10], AFs when uses max-tree representation for filtering bright objects is termed as attribute thinning; whereas, its dual attribute thickening uses min-tree representation to filter dark objects. An AP consists of the original gray-scale image I and the attribute thinning \(\gamma _{\lambda {_i}}\) and thickening \(\phi _{\lambda {_i}}\) results obtained considering a sequence of threshold values \(\lambda {_i}\). It is defined as:
For spectral-spatial analysis of an HSI H, an EAP is created by concatenating APs constructed on first \(\ell \) component images (\(C_j\)) that are most informative. An EAP can be formulated as:
3 Proposed Method
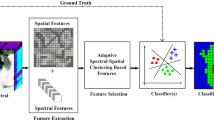
In this paper, we propose a simple and computationally efficient method for automatic selection of the suitable threshold values to construct attribute profiles by overcoming the prior limitations of the state-of-the-art. The proposed architecture is shown in Fig. 1. Initially, first \(\ell \) informative components of HSI are extracted using PCA. For each component, a max-tree as well as a min-tree is created. In a max-tree (min-tree) the nodes at different level depict the nested CCs of the gray-level image with the whole image at the root and the smallest CCs at the leaves. For the constructed trees, separate sets of threshold values are automatically selected by the proposed method which are used to construct an AP. APs constructed for each component image are concatenated to form an EAP. The constructed EAP has rich spectral-spatial content which is fed to SVM classification.

Proposed architecture of automatic attribute profiles for HSI. Figure shows for each PC of HSI suitable threshold values are automatically obtained by exploiting the tree representation of component image and clustering technique.

The results of two-stage clustering for first PC of the Indian Pines data set considering area attribute. (a) All unique attribute values are clustered into two groups; (b) The first group of attribute values is clustered again into three groups to detect three thresholds (one from each cluster).

In order to select the threshold values for each PC, the tree representation of the given PC is processed to retrieve the attribute values of each node. These attribute values are stored in a vector from which only unique attribute values are retained for further processing. Among the unique attribute values the smaller ones come from the CCs which are mostly noise whereas the larger ones depict important CCs that need to be preserved. In the first stage of the proposed method, we separate the larger attribute values from the smaller ones by applying a clustering algorithm to secure that the larger CCs do not get filtered. Figure 2(a) shows two groups of attribute values obtained for the max-tree corresponding to first PC of a real HSI with low to medium range of attribute values in one group and higher attribute values in the other group. In the next stage, only the group having lower attribute values is considered for further processing. This group is re-clustered into K groups where K is the number of required thresholds. An example with three clusters is shown in Fig. 2(b). The representatives of each cluster are chosen as final threshold values. Algorithm 1 summarizes the proposed method. For choosing representatives from each cluster the centroid of each cluster is a suitable option. However, the first cluster in the second stage may have extremely small values because of which it may not incorporate much spatial information, so the maximum attribute value from the first cluster and the centroids of the rest of the clusters are considered as threshold values for constructing APs.

Color composite and available reference ground truth for the HSIs (a) Indian Pines and (b) University of Houston.
4 Experimental Results
The effectiveness of the proposed method is assessed by the experimental results obtained on two different HSI data sets. The first HSIFootnote 1 is collected by the sensor AVIRIS. The imagery is from an agricultural land situated at Indian Pines, USA. Its size is 145 \(\times \) 145 pixels with 20 m spatial resolution. The total number of spectral bands available for use after preprocessing is 200. The spectral coverage is ranging from 400–2500 nm. The second HSI data setFootnote 2 is collected by the sensor CASI. The imagery includes the campus of University of Houston spreading over some of its neighboring urban area in Texas, USA. The imagery has 144 spectral bands between the range 380–1050 nm. Each image is of 349 \(\times \) 1905 pixels and 2.5 m spatial resolution. Figure 3 shows false color image alongside the related map showing the available reference samples. The proposed method is tested using the attributes area, diagonal of bounding box (DBB) and standard deviation (SD). The corresponding EAPs are constructed on the HSIs after reducing their dimension using principal component analysis (PCA) and considering the first 5 PCs those correspond to most of the cumulative variance in the original HSI data. The constructed profiles obtained by the proposed method are compared to those obtained by the recent state-of-the-art [2]. The different measures used in [2] (number of connected components, pixel count and sum of gray-values) generate different profiles referred as \(EAP_{CC}\), \(EAP_{P}\) and \(EAP_{G}\) respectively.
For classification we have employed a one-against-all support vector machine (SVM) classifier with radial basis function (RBF) kernel. The SVM parameters {\(\sigma \), C} are obtained by applying grid search with five-fold cross-validation. The SVM is trained with 30% randomly selected labeled data for each class whereas the rest 70% labeled data are used for testing. The experimental results are reported after running ten times to nullify random effects of the results and taking average of the quality indices namely overall accuracy (\(\overline{OA}\)), the average kappa coefficient (kappa) and the standard deviation (std). The experiments are carried out using 64-bit Matlab (R2015a) running on a workstation with CPU Intel(R) Xeon(R) 3.60 GHz and 16 GB RAM.
Table 1 demonstrates the classification results of the \(EAP_{prop}\) (created using the proposed method) and the \(EAP_{CC}\), \( EAP_{P} \) and \( EAP_{G}\) considering two different HSI data sets. The profiles for both the proposed and state-of-the-art are constructed considering the first two (leading to profile size 25) and the first three (leading to profile size 35) automatically detected thresholds. One can see from the table that the accuracies delivered by the \(EAP_{prop}\) are mostly better than the \(EAP_{CC}\), \( EAP_{P} \) and \( EAP_{G}\) in both the data sets. This signifies the potentiality of the proposed method in automatically generating compact as well as informative attribute profile for HSI classification. One can see that the first two thresholds are able to incorporate most of the spatial information because of which the next thresholds could incorporate only little additional information. This is visible from the difference of accuracies obtained considering two and three thresholds.
The results on computational time again show the advantage of the proposed technique over the state-of-the-art method. Table 2 demonstrates the computational time needed for construction of attribute profile of size 35 using both the recent state-of-the-art method and the proposed method. Time required for constructing \(EAP_{CC}\), \( EAP_{P} \), \( EAP_{G}\) and \(EAP_{prop}\) is indicated by \(t_{CC}\), \(t_{P}\), \(t_{G}\) and \(t_{prop}\) respectively. From the table, one can see that for all the attributes in both the data sets the proposed method is much faster than the state-of-the-art method. This confirms that the proposed method is more efficient than the state-of-the-art method. Note that, more time is needed by the state-of-the-art method for creating GCF after computing a measure of interest for all possible threshold values and employing regression to approximate the GCF curves. The time is also proportional to the number of candidate thresholds. This is visible from the time required in case of attribute SD in Table 2. In contrast, the proposed technique employs only a simple two-stage clustering to detect the threshold values. This makes the proposed technique faster.
Parameter Sensitivity: The proposed method employs two stage clustering for which different combinations of clustering algorithms are tested. Although, all the combinations have nominal difference, the best results as reported in Table 1 are obtained when hierarchical agglomerative clustering with single linkage is used at first stage and K-means is used at second Stage. For choosing representatives from each cluster, best results are obtained when we consider maximum attribute value in the first cluster and centroid in the rest.
5 Conclusion
This paper introduces a simple and computationally efficient method for automatically selecting threshold parameter values to construct attribute profiles. The proposed method automatically obtains the candidate threshold values exploiting the tree representation of an image and selects suitable threshold values in two stages. In the first stage, the significant connected components that possess higher attribute values are preserved by separating them from the lower values which mostly represent noise. In the second stage, the final threshold values are obtained by clustering the lower attribute values and considering their representatives. The APs constructed using these detected thresholds are compact in size and possess sufficient spectral-spatial information. Experiments are carried out on two real HSI data sets. The experimental results show that the proposed method has mostly better accuracy and is much faster than the state-of-the-art method.
Notes
- 1.
Accessible at http://engineering.purdue.edu/~biehl/MultiSpec.
- 2.
Accessible at http://hyperspectral.ee.uh.edu.
References
Bhardwaj, K., Patra, S.: An unsupervised technique for optimal feature selection in attribute profiles for spectral-spatial classification of hyperspectral images. ISPRS J. Photogramm. Remote Sens. 138, 139–150 (2018)
Cavallaro, G., Falco, N., Dalla Mura, M., Benediktsson, J.A.: Automatic attribute profiles. IEEE Trans. Image Process. 26(4), 1859–1872 (2017)
Dalla Mura, M., Benediktsson, J.A., Waske, B., Bruzzone, L.: Morphological attribute profiles for the analysis of very high resolution images. IEEE Trans. Geosci. Remote Sens. 48(10), 3747–3762 (2010)
Das, A., Bhardwaj, K., Patra, S.: Morphological complexity profile for the analysis of hyperspectral images. In: 2018 4th International Conference on Recent Advances in Information Technology (RAIT), pp. 1–6. IEEE (2018)
Ghamisi, P., Benediktsson, J.A., Sveinsson, J.R.: Automatic spectral-spatial classification framework based on attribute profiles and supervised feature extraction. IEEE Trans. Geosci. Remote Sens. 52(9), 5771–5782 (2014)
Ghamisi, P., Dalla Mura, M., Benediktsson, J.A.: A survey on spectral-spatial classification techniques based on attribute profiles. IEEE Trans. Geosci. Remote Sens. 53(5), 2335–2353 (2015)
Mahmood, Z., Thoonen, G., Scheunders, P.: Automatic threshold selection for morphological attribute profiles. In: 2012 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), pp. 4946–4949. IEEE (2012)
Marpu, P.R., Pedergnana, M., Dalla Mura, M., Benediktsson, J.A., Bruzzone, L.: Automatic generation of standard deviation attribute profiles for spectral-spatial classification of remote sensing data. IEEE Geosci. Remote Sens. Lett. 10(2), 293–297 (2013)
Pedergnana, M., Marpu, P.R., Dalla Mura, M., Benediktsson, J.A., Bruzzone, L.: A novel technique for optimal feature selection in attribute profiles based on genetic algorithms. IEEE Trans. Geosci. Remote Sens. 51(6), 3514–3528 (2013)
Salembier, P., Oliveras, A., Garrido, L.: Antiextensive connected operators for image and sequence processing. IEEE Trans. Image Process. 7(4), 555–570 (1998)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Das, A., Bhardwaj, K., Patra, S. (2019). Automatic Attribute Profiles for Spectral-Spatial Classification of Hyperspectral Images. In: Deka, B., Maji, P., Mitra, S., Bhattacharyya, D., Bora, P., Pal, S. (eds) Pattern Recognition and Machine Intelligence. PReMI 2019. Lecture Notes in Computer Science(), vol 11941. Springer, Cham. https://doi.org/10.1007/978-3-030-34869-4_2
Download citation
DOI: https://doi.org/10.1007/978-3-030-34869-4_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-34868-7
Online ISBN: 978-3-030-34869-4
eBook Packages: Computer ScienceComputer Science (R0)
