
Abstract
This work investigates spoken language understanding (SLU) systems in the scenario when the semantic information is extracted directly from the speech signal by means of a single end-to-end neural network model. Two SLU tasks are considered: named entity recognition (NER) and semantic slot filling (SF). For these tasks, in order to improve the model performance, we explore various techniques including speaker adaptation, a modification of the connectionist temporal classification (CTC) training criterion, and sequential pretraining.
Similar content being viewed by others


Keywords
- Spoken language understanding (SLU)
- Acoustic adaptation
- End-to-end SLU
- Slot filling
- Named entity recognition
1 Introduction
Spoken language understanding (SLU) is a key component of conversational artificial intelligence (AI) applications. Traditional SLU systems consist of at least two parts. The first one is an automatic speech recognition (ASR) system that transcribes acoustic speech signal into word sequences. The second part is a natural language understanding (NLU) system which predicts, given the output of the ASR system, named entities, semantic or domain tags, and other language characteristics depending on the considered task. In classical approaches, these two systems are often built and optimized independently.
Recent progress in deep learning has impacted many research and industrial domains and boosted the development of conversational AI technology. Most of the state-of-the art SLU and conversational AI systems employ neural network models. Nowadays there is a high interest of the research community in end-to-end systems for various speech and language technologies. A few recent papers [5, 11, 16, 18, 21, 24] present ASR-free end-to-end approaches for SLU tasks and show promising results. These methods aim to learn SLU models from acoustic signal without intermediate text representation. Paper [5] proposed an audio-to-intent architecture for semantic classification in dialog systems. An encoder-decoder framework [26] is used in [24] for domain and intent classification, and in [16] for domain, intent, and argument recognition. A different approach based on the model trained with the connectionist temporal classification (CTC) criterion [13] was proposed in [11] for named entity recognition (NER) and slot filling. End-to-end methods are motivated by the following factors: possibility of better information transfer from the speech signal due to the joint optimization on the final objective criterion, and simplification of the overall system and elimination of some of its components. However, deep neural networks and especially end-to-end models often require more training data to be efficient. For SLU, this implies the demand of big semantically annotated corpora. In this work, we explore different ways to improve the performance of end-to-end SLU systems.
2 SLU Tasks
In SLU for human-machine conversational systems, an important task is to automatically extract semantic concepts or to fill in a set of slots in order to achieve a goal in a human-machine dialogue. In this paper, we consider two SLU tasks: named entity recognition (NER) and semantic slot filling (SF). In the NER task, the purpose is to recognize information units such as names, including person, organization and location names, dates, events and others. In the SF task, the extraction of wider semantic information is targeted. These last years, NER and SF where addressed as word labelling problems, through the use of the classical BIO (begin/inside/outside) notation. For instance, “I would like to book three double rooms in Paris for tomorrow” will be represented for the NER and SF task as the following BIO labelled sentences:

In this paper, similarly to [11], the BIO representation is abandoned in profit to a chunking approach. For instance for NER, the same sentence will be presented as:

In this study, we train an end-to-end neural model to reproduce such textual representation from speech. Since our neural model emits characters, we use specific characters corresponding to each opening tag (one by named entity category or one by semantic concept), while the same symbol is used to represent the closing tag.
3 Model Training
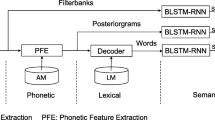
End-to-end training of SLU models is realized through the recurrent neural network (RNN) architecture and CTC loss function [13] as shown in Fig. 1. A spectrogram of power normalized audio clips calculated on 20 ms windows is used as the input features for the system. As shown in Fig. 1, it is followed by two 2D-invariant (in the time and-frequency domain) convolutional layers, and then by five BLSTM layers with sequence-wise batch normalization. A fully connected layer is applied after BLSTM layers, and the output layer of the neural network is a softmax layer. The model is trained using the CTC loss function. The neural architecture is similar to the Deep Speech 2 [1] for ASR.
The outputs of the network depend on the task. For ASR, the outputs consist of graphemes of a corresponding language, a space symbol to denote word boundaries and a blank symbol. For NER, in addition to ASR outputs, we add outputs corresponding to named entity types and a closing symbol for named entities. In the same way, for SF, we use all ASR outputs and additional tags corresponding to semantic concepts and a closing symbol for semantic tags.
In order to improve model training, we investigate speaker adaptive training (SAT), pretraining and transfer learning approaches. First, we formalize the \(\star \)-mode, that proved its effectiveness in all our previous and current experiments.
3.1 CTC Loss Function Interpretation Related to \(\star \)-mode
The CTC loss function [13] is relevant to train models for ASR without Hidden Markov Models. The \(\star \)-mode can be seen as a minor modification of the CTC loss function.
CTC Loss Function Definition. By means of a many-to-one \(\mathcal {B}\) mapping function, CTC transforms a sequence of the network outputs, emitted for each acoustic frame, to a sequence of final target labels by deleting repeated output labels and inserting a blank (no label) symbol. The CTC loss function is defined as:
where \(\mathbf {x}\) is a sequence of acoustic observations, \(\mathbf {l}\) is the target output label sequence, and Z the training dataset. \(P(\mathbf {l}|\mathbf {x})\) is defined as:
where \(\pi \) is a sequence of initial output labels emitted by the model for each input frame. To compute \(P(\pi |\mathbf {x})\) we use the probability of the output label \(\pi _t\) emitted by the neural model for frame t to build this sequence. This probability is modeled by the value \(y_{\pi _t}^t\) given by the output node of the neural model related to the label \(\pi _t\). \(P(\pi |\mathbf {x})\) is defined as \( P(\pi |\mathbf {x})=\prod _t^T y_{\pi _t}^t, \) where T denotes the number of frames.
CTC Loss Function and \(\varvec{\star }\) -mode. In the framework of the \(\star \)-mode, we introduce a new symbol, “\(\star \)”, that represents the presence of a label (the opposite of the blank symbol) that does not need to be disambiguated. We expect to build a model that is more discriminant on the important task-specific labels. For example, for the SF SLU task important labels are the ones corresponding to semantic concept opening and closing tags, and characters involved in the word sequences that support the value of these semantic concepts (i.e characters occurring between an opening and a closing concept tag). In the CTC loss function framework, the \(\star \)-mode consists in applying another kind of mapping function before \(\mathcal {B}\). While \(\mathcal {B}\) converts a sequence \(\pi \) of initial output labels into the final sequence \(\mathbf {l}\) to be retrieved, we introduce the mapping function \(\mathcal {S}\) that is applied to each final target output label. Let C be the set of elements \(\mathbf {l}_i\) included in subsequences \(\mathbf {l}_a^b \subset \mathbf {l}\) such as \(\mathbf {l}_a\) is an opening concept tag and \(\mathbf {l}_b\) the associated closing tag; i, a and b are indexes that handle positions in sequence \(\mathbf {l}\), and \(a\le i \le b\). Let V be the vocabulary of all the symbols present in sequences \(\mathbf {l}\) in Z, and let consider the new symbol \(\star \notin V\). Let define \(V^\star =V \cup \left\{ \star \right\} \), and L (resp. \(L^\star \)) the set of all the label sequences that can be generated from V (resp. \(V^\star \)).
Considering n as the number of elements in \(\mathbf {l}\), m an integer such as \(m \le n\), we define the mapping function \(\mathcal {S}:L \rightarrow L^\star , \mathbf {l} \mapsto \mathbf {l^\prime }\) in two steps:
By applying \(\mathcal {S}\) on the last example sentence used in Sect. 2 for NER, this sentence is transformed to:

To introduce \(\star \)-mode in the CTC loss function definition, we modify the formulation of \(P(\mathbf {l}|\mathbf {x})\) in formula (2) by introducing the \(\mathcal {S}\) mapping function applied to \(\mathbf {l}\):
3.2 Speaker Adaptive Training
Adaptation is an efficient way to reduce the mismatches between the models and the data from a particular speaker or channel. For many years, acoustic model adaptation has been a key component of any state-of-the-art ASR system. For end-to-end approaches, speaker adaptation is less studied, and most of the first end-to-end ASR systems do not use any speaker adaptation and are built on spectrograms [1] or filterbank features [2]. However, some recent works [7, 28] have demonstrated the effectiveness of speaker adaptation for end-to-end models.
For SLU tasks, there is also an emerging interest in the end-to-end models which have a speech signal as input. Thus, acoustic, and particularly speaker, adaptation for such models can play an important role in improving the overall performance of these systems. However, to our knowledge, there is no research on speaker adaptation for end-to-end SLU models, and the existing works do not use any speaker adaptation.
One way to improve SLU models which we investigate in this paper is speaker adaptation. We apply i-vector based speaker adaptation [23]. The proposed way of integration of i-vectors into the end-to-end model architecture is shown in Fig. 1. Speaker i-vectors are appended to the outputs of the last (second) convolutional layer, just before the first recurrent (BLSTM) layer. In this paper, for better initialization, we first train a model with zero pseudo i-vectors (all values are equal to 0). Then, we use this pretrained model and fine-tune it on the same data but with the real i-vectors. This approach was inspired by [6], where an idea of using zero auxiliary features during pretraining was implemented for language models and in our preliminary experiments it demonstrated better results than direct model training with i-vectors [27].

Universal end-to-end deep neural network model architecture for ASR, NER and SF tasks. Depending on the task, the set of the output characters consists of: (1) ASR: graphemes for a given language; (2) NER: graphemes and named entity tags; (3) SF: graphemes and semantic SF tags.
3.3 Transfer Learning
Transfer learning is a popular and efficient method to improve the learning performance of the target predictive function using knowledge from a different source domain [19]. It allows to train a model for a given target task using available out-of-domain source data, and hence to avoid an expensive data labeling process, which is especially useful in case of low-resource scenarios.
In this paper, for SF, we investigate the effectiveness of transfer learning for various source domains and tasks: (1) ASR in the target and out-of-domain languages; (2) NER in the target language; (3) SF. For all the tasks, we used similar model architectures (Sect. 4.2 and Fig. 1). The difference is in the text data preparation and output targets. For training ASR systems, the output targets correspond to alphabetic characters and a blank symbol. For NER tasks, the output targets include all the ASR targets and targets corresponding to named entity tags. We have several symbols corresponding to named entities (in the text these characters are situated before the beginning of a named entity, which can be a single word or a sequence of several words) and a one tag corresponding to the end of the named entity, which is the same for all named entities. Similarly, for SF tags, we use targets corresponding to the semantic concept tags and one tag corresponding to the end of a concept. Transfer learning is realized through the chain of consequence model training on different tasks. For example, we can start from training an ASR model on audio data and corresponding text transcriptions. Then, we change the softmax layer in this model by replacing the targets with the SF targets and continue training on the corpus annotated with semantic tags. Further in the paper, we denote this type of chain as
 . Models in this chain can be trained on different corpora, that can make this method useful in low-resource scenario when we do not have enough semantically annotated data to train an end-to-end model, but have sufficient amount of data annotated with more general concepts or only transcribed data. For NER, we also investigates the knowledge transfer from ASR.
. Models in this chain can be trained on different corpora, that can make this method useful in low-resource scenario when we do not have enough semantically annotated data to train an end-to-end model, but have sufficient amount of data annotated with more general concepts or only transcribed data. For NER, we also investigates the knowledge transfer from ASR.
4 Experiments
4.1 Data
Several publicly available corpora have been used for experiments (see Table 1).
ASR Data. The corpus for ASR training was composed of corpora from various evaluation campaigns in the field of automatic speech processing for French. The EPAC [9], ESTER 1,2 [10], ETAPE [14], REPERE [12] contain transcribed speech in French from TV and radio broadcasts. These data were originally in the microphone channel and for experiments in this paper were downsampled from 16 kHz to 8 kHz, since the test set for our main target task (SF) consists of telephone conversations. The DECODA [3] corpus is composed of dialogues from the call-center of the Paris transport authority. The MEDIA [4, 8] and PORTMEDIA [17] are corpora of dialogues simulating a vocal tourist information server. The target language in all experiments is French. For experiments with transfer learning from ASR built in a different source language to SF in the target language, we used the TED-LIUM corpus [22]. This publicly available dataset contains 1495 TED talks in English that amount to 207 h of speech data from 1242 speakers.
NER Data. To train the NER system, we used the following corpora: EPAC, ESTER 1,2, ETAPE, and REPERE. These corpora contain speech with text transcriptions and named entity annotation. The named entity annotation is performed following the methodology of the Quaero project [15]. The taxonomy is composed of 8 main types: person, function, organization, location, product, amount, time, and event. Each named entity can be a single word or a sequence of several words. The total amount of annotated data is 112 h. Based on this data, a classical NER system was trained using NeuroNLP2Footnote 1 to automatically extract named entities for the rest 212 h of the training corpus. This was done in order to increase the amount of the training data for NER. Thus, the total amount of audio data to train the NER system is about 324 (112 + 212) h. The development part of the ETAPE corpus was used for development, and as a test set we used the ETAPE test and Quaero test datasets.
SF Data. The following two French corpora, dedicated to semantic extraction from speech in a context of human/machine dialogues, were used in the current experiments: MEDIA and PORTMEDIA. The corpora have manual transcription and conceptual annotation [8, 29]. The MEDIA corpus is related to the hotel booking domain, and its annotation contains 76 semantic tags: room number, hotel name, location, date, etc. The PORTMEDIA corpus is related to the theater ticket reservation domain and its annotation contains 35 semantic tags which are very similar to the tags used in the MEDIA corpus. For joint training on these corpora, we used a combined set of 86 semantic tags.
4.2 Models
We used the deepspeech.torch implementationFootnote 2 for training speaker independent (SI) models, and our modification of this implementation to integrate speaker adaptation. The open-source Kaldi toolkit [20] was used to extract 100-dimensional speaker i-vectors. All models had similar topology (except for the number of outputs) shown in Fig. 1 for SAT models. SI models were trained in the same way, but without i-vector integration. Input features are spectrograms. They are followed by two 2D-invariant (in the time and-frequency domain) convolutional layersFootnote 3, and then by five 800-dimensional BLSTM layers with sequence-wise batch normalization. A fully connected layer is applied after BLSTM layers, and the output layer of the neural network is a softmax layer. The size of the output layer depends on the task (see Sect. 4.3). The model is trained using the CTC loss function.
4.3 Tasks
The target tasks for us are NER and SF. For each of this task, other tasks can be used for knowledge transfer. To train NER, we use ASR for transfer learning. To train SF, we use ASR on French and English, NER and another auxiliary SF task for transfer learning. Hence, we consider the following set of tasks:

4.4 Results for NER
Performance of NER was evaluated in terms of precision, recall, and F-measure. Results for different training chains for speaker-independent (SI) and speaker adaptive training models (SAT) are given in Table 2. We can see, that pretraining with \(ASR_F\) task does not lead to significant improvement in performance. When the \(NER^\star \) is added to the training chain, it improves all the evaluation measures. In particular, F-measure is increased by 1.9% absolute. For each training chain, we trained a corresponding chain with speaker adaptation. Results for SAT models are given in the right part of Table 2. For all training chains, SAT models outperform SI models. The best result with SAT (F-measure 71.8%) outperforms the best SI result by 1.1% absolute.
4.5 Results for SF
SF performance was evaluated in terms of F-measure, concept error rate (CER) and concept value error rate (CVER).
Results for different training chains for speaker-independent (SI) models on the test set are given in Table 3 (#1–8). The first line \(SF_1\) shows the baseline result on the test MEDIA dataset for the SF task, when a model was trained directly on the target task using in-domain data for this task (training part of the MEDIA corpus). The second line \(SF_{1+2}\) corresponds to the case when the model was trained on the auxiliary SF task. Other lines in the table correspond to different training chains described in Sect. 3.3. In \(\#4\), we can see a chain that starts from training an ASR model for English. We can observe that using a pretrained ASR model from a different language can significantly (\(16.2\%\) of relative CER reduction) improve the performance of the SF model (#4 vs #3). This result is noticeable since it shows that we can take benefit from linguistic resources from another language in case of lack of data for the target one. Using an ASR model trained in French (#5) provides better improvement: \(36.0\%\) of relative CER reduction (#5 vs #3). When we start the training process from a NER model (#6) we can observe slightly better results. Further, for the best two model training chains (#5 and 6) we trained corresponding models in \(\star \)-mode (#7 and 8). Results with speaker adaptation for four best models are shown in the right part of Table 3 (#9–12). We can see that SAT models show better results than SI ones. For CVER, we can observe a similar tendency. The results for the best models using beam search and a 4-gram LM are shown in brackets in blue. The LM was built on the texts including “\(\star \)”. Finally, Table 4 resumes our best results (in greedy and beam search modes) and shows the comparison results on the MEDIA dataset from other works [11, 25]. We can see, that the reported results significantly outperform the results reported in the literature for the current task.

Concept error rate (CER,%) results on the MEDIA test dataset for different concepts depending on the number of corresponding concepts in the training corpus. The CER results are given for the SAT model (#12), decoding with beam search and a 4-gram LM.

Confusion matrix for concepts on the MEDIA test dataset. The last row and last column represent insertion and deletion errors correspondingly. The CER results are given for the SAT model (#12), decoding with beam search and a 4-gram LM.
Error Analysis. In the training corpus, different semantic concepts have different number of samples, that may impact the SF performance. Figure 2 demonstrates the relation between the concept error rate (CER) of a particular semantic concept and its frequency in the training corpus. Each point in Fig. 2 corresponds to a particular semantic concept. For rare tags, the distribution of errors has larger variance and means than for more frequent tags. In addition, we are interested in the distribution of different types of SF errors (deletions, insertions and substitutions), which is shown in the form of a confusion matrix in Fig. 3. For better representation, we first ordered the concepts in descending order by the total number of errors. Then, we chose the first 36 concepts which have the biggest number of errors. The total amount of errors of the chosen 36 concepts corresponds to 90% of all the errors for all concepts in the test MEDIA dataset. The diagonal corresponds to the correctly detected concepts and other elements (except for the last row and last column) correspond to the substitution errors. The final raw represents insertion errors and the final column – deletions. Each element in the matrix shows the total number of the corresponding events (correctly recognized concept, substitution, deletion or insertion) normalized by the total number of such events in the row. The most frequent errors are deletions (50% of all errors), then substitutions (32.3%) and insertions (17.7%).
5 Conclusions
In this paper, we have investigated several ways to improve the performance of end-to-end SLU systems. We demonstrated the effectiveness of speaker adaptive training and various transfer learning approaches for two end-to-end SLU tasks: NER and SF. In order to improve the quality of the SF models, during the training, we proposed to use knowledge transfer from an ASR system in another language and from a NER in a target language. Experiments on the French MEDIA test corpus demonstrated that using knowledge transfer from the ASR in English improves the SF model performance by about 16% of relative CER reduction for SI models.
The improvement from the transfer learning is greater when the ASR model is trained on the target language (36% of relative CER reduction) or when the NER model in the target language is used for pretraining. Another contribution concerns SAT training for SLU models – we demonstrated that this can significantly improve the model performance for NER and SF.
Notes
- 1.
- 2.
- 3.
With parameters: kernel size = (41, 11), stride = (2, 2), padding = (20, 5).
References
Amodei, D., et al.: Deep speech 2: end-to-end speech recognition in English and Mandarin. In: International Conference on Machine Learning, pp. 173–182 (2016)
Bahdanau, D., Chorowski, J., Serdyuk, D., Brakel, P., Bengio, Y.: End-to-end attention-based large vocabulary speech recognition. In: ICASSP, pp. 4945–4949. IEEE (2016)
Bechet, F., Maza, B., Bigouroux, N., Bazillon, T., El-Beze, M., et al.: DECODA: a call-centre human-human spoken conversation corpus. In: LREC, pp. 1343–1347 (2012)
Bonneau-Maynard, H., Ayache, C., Bechet, F., et al.: Results of the French Evalda-Media evaluation campaign for literal understanding. In: LREC (2006)
Chen, Y.P., Price, R., Bangalore, S.: Spoken language understanding without speech recognition. In: ICASSP (2018)
Deena, S., et al.: Semi-supervised adaptation of RNNLMs by fine-tuning with domain-specific auxiliary features. In: INTERSPEECH, pp. 2715–2719. ISCA (2017)
Delcroix, M., Watanabe, S., Ogawa, A., Karita, S., Nakatani, T.: Auxiliary feature based adaptation of end-to-end ASR systems. In: INTERSPEECH, pp. 2444–2448 (2018)
Devillers, L., et al.: The French MEDIA/EVALDA project: the evaluation of the understanding capability of spoken language dialogue systems. In: LREC (2004)
Estève, Y., Bazillon, T., Antoine, J.Y., Béchet, F., Farinas, J.: The EPAC corpus: manual and automatic annotations of conversational speech in French broadcast news. In: LREC (2010)
Galliano, S., et al.: The ESTER 2 evaluation campaign for the rich transcription of French radio broadcasts. In: Interspeech (2009)
Ghannay, S., Caubrière, A., Estève, Y., et al.: End-to-end named entity and semantic concept extraction from speech. In: SLT, pp. 692–699 (2018)
Giraudel, A., Carré, M., Mapelli, V., Kahn, J., Galibert, O., Quintard, L.: The REPERE corpus: a multimodal corpus for person recognition. In: LREC, pp. 1102–1107 (2012)
Graves, A., et al.: Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In: Proceedings of the 23rd International Conference on Machine Learning, pp. 369–376. ACM (2006)
Gravier, G., Adda, G., Paulson, N., et al.: The ETAPE corpus for the evaluation of speech-based TV content processing in the French language. In: LREC (2012)
Grouin, C., Rosset, S., Zweigenbaum, P., Fort, K., Galibert, O., Quintard, L.: Proposal for an extension of traditional named entities: from guidelines to evaluation, an overview. In: Proceedings of the 5th Linguistic Annotation Workshop, pp. 92–100 (2011)
Haghani, P., et al.: From audio to semantics: approaches to end-to-end spoken language understanding. arXiv preprint arXiv:1809.09190 (2018)
Lefèvre, F., et al.: Robustness and portability of spoken language understanding systems among languages and domains: the PortMedia project (in French), pp. 779–786 (2012)
Lugosch, L., Ravanelli, M., Ignoto, P., Tomar, V.S., Bengio, Y.: Speech model pre-training for end-to-end spoken language understanding. arXiv preprint arXiv:1904.03670 (2019)
Pan, S.J., Yang, Q.: A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 22(10), 1345–1359 (2010)
Povey, D., Ghoshal, A., et al.: The Kaldi speech recognition toolkit. In: ASRU (2011)
Qian, Y., Ubale, R., et al.: Exploring ASR-free end-to-end modeling to improve spoken language understanding in a cloud-based dialog system. In: ASRU, pp. 569–576 (2017)
Rousseau, A., Deléglise, P., Esteve, Y.: Enhancing the TED-LIUM corpus with selected data for language modeling and more ted talks. In: LREC, pp. 3935–3939 (2014)
Saon, G., Soltau, H., Nahamoo, D., Picheny, M.: Speaker adaptation of neural network acoustic models using i-vectors. In: ASRU, pp. 55–59 (2013)
Serdyuk, D., Wang, Y., Fuegen, C., Kumar, A., Liu, B., Bengio, Y.: Towards end-to-end spoken language understanding. arXiv preprint arXiv:1802.08395 (2018)
Simonnet, E., et al.: Simulating ASR errors for training SLU systems. In: LREC 2018 (2018)
Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. In: Advances in Neural Information Processing Systems, pp. 3104–3112 (2014)
Tomashenko, N., Caubrière, A., Estève, Y.: Investigating adaptation and transfer learning for end-to-end spoken language understanding from speech. In: Interspeech, Graz, Austria (2019)
Tomashenko, N., Estève, Y.: Evaluation of feature-space speaker adaptation for end-to-end acoustic models. In: LREC (2018)
Vukotic, V., Raymond, C., Gravier, G.: Is it time to switch to word embedding and recurrent neural networks for spoken language understanding? In: Interspeech (2015)
Acknowledgements
This work was supported by the French ANR Agency through the ON-TRAC project, under the contract number ANR-18-CE23-0021-01, and by the RFI Atlanstic2020 RAPACE project.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Tomashenko, N., Caubrière, A., Estève, Y., Laurent, A., Morin, E. (2019). Recent Advances in End-to-End Spoken Language Understanding. In: Martín-Vide, C., Purver, M., Pollak, S. (eds) Statistical Language and Speech Processing. SLSP 2019. Lecture Notes in Computer Science(), vol 11816. Springer, Cham. https://doi.org/10.1007/978-3-030-31372-2_4
Download citation
DOI: https://doi.org/10.1007/978-3-030-31372-2_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-31371-5
Online ISBN: 978-3-030-31372-2
eBook Packages: Computer ScienceComputer Science (R0)