
Abstract
Mathematical models can take very different forms and very different levels of complexity. A systematic way to postulate, calibrate and validate, as provided by systems theory, can therefore be very helpful. In this chapter, dynamic systems modelling of aquaponic (AP) systems, from a systems theoretical perspective, is considered and demonstrated to each of the subsystems of the AP system, such as fish tanks, anaerobic digester and hydroponic (HP) greenhouse. It further shows the links between the subsystems, so that in principle a complete AP systems model can be built and integrated into daily practice with respect to management and control of AP systems. The main challenge is to choose an appropriate model complexity that meets the experimental data for estimation of parameters and states and allows us to answer questions related to the modelling objective, such as simulation, experiment design, prediction and control.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
- Modelling
- Recirculating aquaculture system
- Anaerobic digestion
- Hydroponic greenhouse
- Multi-loop aquaponic system
- Tools
1 Introduction
In general, mathematical models can take very different forms depending on the system under study, which may range from social, economic and environmental to mechanical and electrical systems. Typically, the internal mechanisms of social, economic or environmental systems are not very well known or understood and often only small data sets are available, while the prior knowledge of mechanical and electrical systems is at a high level, and experiments can easily be done. Apart from this, the model form also strongly depends on the final objective of the modelling procedure. For instance, a model for process design or simulation should contain much more detail than a model used for studying different long-term scenarios.
In particular, for a wide range of applications (e.g. Keesman 2011), models are developed to:
-
Obtain or enlarge insight in different phenomena, for example, recovering physical or economic relationships.
-
Analyse process behaviour using simulation tools, for example, process training of operators or weather forecasts.
-
Estimate state variables that cannot be easily measured in real time on the basis of available measurements, for instance, online process information.
-
Control, for instance, in the internal model control or model-based predictive control concept or to manage processes.
A critical step in the modelling of any system is to find a mathematical model which adequately describes the actual situation or state. Firstly, the system boundaries and the system variables have to be specified. Then relationships between these variables have to be specified on the basis of prior knowledge, and assumptions about the uncertainties in the model have to be made. Combining this information defines the model structure. Still the model may contain some unknown or incompletely known coefficients, the model parameters, which in case of time-varying behaviour define an additional set of system variables. For a general introduction to mathematical modelling we refer to, for instance, Sinha and Kuszta (1983), Willems and Polderman (1998) and Zeigler et al. (2000).
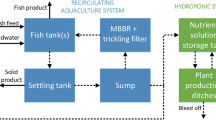
In this chapter, the modelling of an aquaponic (food) production (AP) system will be described. Figure 11.1 shows a typical example of an AP system, i.e. the so-called decoupled three-loop aquaponic system. As a result of basic principles modelling, using conservation laws and constitutive relationships, mathematical models of all kinds of AP systems are usually represented as a set of ordinary or partial differential equations. These mathematical models are commonly used for design, estimation and control. In each of these specific modelling objectives, we distinguish between analysis and synthesis.

Decoupled, three-loop aquaponic system with RAS, hydroponic and remineralization subsystems. (Goddek, 2017)
The outline of the chapter is as follows. In Sect. 11.1 some background on mathematical systems modelling is presented. Sections 11.2, 11.3, 11.4 and 11.5 describe the modelling of a recirculating aquaculture system (RAS), anaerobic digestion, hydroponic (HP) greenhouse and a multi-loop AP system, respectively. In Sect. 11.6 modelling tools are introduced and illustrated with some examples. The chapter concludes with a Discussion and Conclusions section.
2 Background
Many definitions of a system are available, ranging from loose descriptions to strict mathematical formulations. In what follows, a system is considered to be an object in which different variables interact at all kinds of time and space scales and that produces observable signals. These types of systems are also called open systems. A graphical representation of a general open system (S) with vector-valued input and output signals is represented in Fig. 11.2. Thus, multiple inputs or outputs are combined in one single arrow. So, the system variables may be scalars or vectors. In addition, they can be continuous or discrete functions of time. It is important to stress that the arrows in Fig. 11.2 represent signal flows and thus not necessarily physical flows.

General open system representation
It is also possible to connect systems into a network, as in an AP system, with parallel, feedback and feedforward paths. Figure 11.3 presents an example of such a network.

Open system network representation
For controller/management analysis and synthesis, it is often convenient to connect the system (S) to the controller or management strategy (C), as in Fig. 11.4. Most often the input to the controller or management strategy is the external steering signal of the controlled system, and the output of the system is the observed system’s behaviour.

Controlled system
Finally, to emphasize the incorporation of a mathematical model (M) into the controller structure or management strategy, the following model-based controlled system representation is introduced (Fig. 11.5).

Model-based controlled system
For now, it suffices to present the block diagram representation. In subsequent sections, the modelling of AP systems will be worked out in more detail.
In systems theory the basic structure of a mathematical model (M) is schematically represented as in Fig. 11.6. In Fig. 11.6, x is the so-called state of the system, u the control input, y the output, w the disturbance input and v the output noise. In general, each of these variables is vector-valued.

Basic structure of mathematical model (M)
In continuous time, the following set of equations describes a general dynamic model (M), with parameter vector p, in what is called state-space form:
where the first equation describes the nonlinear and time-varying dynamics of the system in terms of state variables (x) and the second one expresses the algebraic relationship between u, x and y. This state-space model representation has been a starting point for many software implementations for design, control and estimation. In what follows, however, only deterministic models, thus without the stochastic vectors v and w, are considered. Let us illustrate this theory on a fish tank system.
Example: Fish Tank System
Consider the following fish tank, which is a typical example of the general system presented in Fig. 11.7.

Fish tank with volume-controlled flow using level controller (LC)
Let us start with specifying our prior knowledge of the internal system mechanisms. The following mass balance can be defined in terms of the volume of the storage tank (V), also called the state of the system, inflows u(t) and outflows y(t):
Suppose there is a level controller (LC) that keeps the outflow proportional to the volume in the tank. This can be enforced by implementing the following proportional control law,
with K a real, positive constant. Hence, after substituting Eq. (11.3) into (11.2), we obtain the following differential equation
For this specific linear differential equation with constant coefficients, an analytical solution exists and is given by
under the assumption that u(t) = 0 for t < 0. From this example it is clear that applying first principles – mass conservation in this case – directly leads to an ordinary differential equation. In state-space format, the model can be represented as
With x volume, u flow input and K controller gain. Thus, in terms of the general state-space Eq. (11.1), f(t, x(t), u(t); p) ≡ − Kx(t) + u(t) and g(t, x(t), u(t); p) ≡ Kx(t).
For two volume-controlled fish tanks in series with volume V 1 and V 2, and controller gain K 1 and K 2, respectively, two mass balances can be formulated, i.e.
In vector-matrix form, and for physical outflow y(t), we can write:
And thus, with x 1 = V 1,x 2 = V 2: \( f\left(t,x(t),u(t);p\right)\equiv \left[\begin{array}{l}-{K}_1{x}_1(t)+u(t)\\ {}{K}_1{x}_1(t)-{K}_2{x}_2(t)\end{array}\right] \) and g(t, x(t), u(t); p) ≡ K 2x 2(t).
In the next sections, each of the subsystems of the AP system (Fig. 11.1) will be described in more detail.
3 RAS Modelling
Global fish aquaculture reached 50 million tons in 2014 (FAO 2016). Given the growing human population, there is a growing demand for fish proteins. Sustainable growth of aquaculture requires novel (bio)technologies such as recirculating aquaculture systems (RAS). RAS have a low water consumption (Orellana 2014) and allow for a recycling of excretory products (Waller et al. 2015). RAS provide suitable living conditions for fish, as a result of a multistep water treatment, such as particle separation, nitrification (biofiltration), gas exchange and temperature control. Dissolved and particulate excretory products can be transferred to secondary treatment such as plant (Waller et al. 2015) or algae production in integrated aqua-agriculture (IAAC) systems. IAAC systems are sustainable alternatives to conventional aquaculture systems and in particular are a promising expansion to RAS. In RAS it would be necessary to circulate the process water which has special implications for the process technology in both, the RAS and the algae/plant system. To combine RAS and algae/plant system, a deep understanding of the interaction between fish and water treatment is prerequisite and can be derived from dynamic modelling. The metabolism in fish follows a daily pattern which is well represented by the gastric evacuation rate (Richie et al. 2004). Particle separation, biofiltration and gas exchange are subjected to the same pattern. For design purposes the characterization of the basic components of a RAS treatment system should be investigated through simulation models. These simulation models are highly complex. Available numerical models for RAS capture only a small part of the complexity and consider only a part of the components with corresponding mechanisms. Hence, in this chapter, only a small part of a dynamic RAS model will be presented, i.e. nitrification-based biofiltration. The conversion of toxic ammonia into nitrate is a central process in the water treatment process in RAS. In the following, the dynamic modelling of the mass balance of ammonia excretion of fish and the conversion of ammonia into nitrate will be demonstrated as well as the transfer of the nutrient into an aquaponic system. With this it is possible not only to engineer a RAS but also to integrate fish production into an IAAC system based on valid parameters.
3.1 Dynamic Model of Nitrification-Based Biofiltration in RAS
The model is subdivided into a fish model for European seabass, Dicentrarchus labrax, a model describing the time- dependenting excretion of ammonia, and a nitrification model (Fig. 11.8). The fish excretion pattern is introduced into the model through the input vector u (Eq. 11.15), similar to the approach used by Wik et al. (2009). The complexity of the fish model is kept low to be able to explain its method of implementation. Nonetheless, a short introduction into modelling fish is presented in Sect. 11.3.2. Four basic aspects important to describe the nutrient flow in RAS (Badiola et al. 2012) are:
-
1.
The flow Q, which is the total process water flow per unit time through the RAS, determines the mass transfer of all dissolved and particulate matter, including ammonia and nitrate.
-
2.
The excretion of the fish input ammonia to the RAS process water and is depicted by the product of matrix B and vector u (Eq. 11.15).
-
3.
The ammonia conversion into nitrate, taking place in the nitrification, is depicted in the nitrification vector n (Eq. 11.15).
-
4.
The nutrient transfer from the RAS to a connected HP system is depicted in vector u (Eq. 11.15). Other important aspects of the RAS process chain such as solid removal, dissolved oxygen concentration and carbon dioxide concentration are not considered here. Hints for modelling these can be found in Sects. 3.1.1 and 3.2.2 of this book.

RAS setup with fish tank, pump, nitrification reactor and water transfer to hydroponic system
3.2 Fish
A variety of models in the scientific literature predict growth and feed intake of different aquatic species. The models describe growth as weight gain per day, as percentage growth increment or as specific growth rate based on an exponential growth model. Models are often valid for specific life stages. Feed consumption, biomass and gender are influencing the model output as well as the environmental conditions such as temperature, oxygen level and nutrient concentration (Lugert et al. 2014). Careful research is needed to identify the correct model used for the specific application. Commercial RAS that consists of several cohorts of fish in different life stages require the modelling to incorporate cohorts into the model (Fig. 8.6) (Halamachi and Simon 2005). The excretory mass flow for the European seabass (Dicentrarchus labrax) can be estimated with algorithms published by Lupatsch and Kissil (1998).
Here the net nitrogen mass flow into the process water is estimated from the feed composition (protein content), the amount of given feed and the nitrogen retained in body tissues through the growth (weight increment) of fish. The faecal nitrogen losses are not included in the model, but excretion rate is corrected assuming a share of 0.25 and 0.75 of nitrogen excretion for faecal loss and ammonia excretion, respectively. The nitrogen input through the feeding of fish is estimated from the protein content and the average relative nitrogen content of proteins which is assumed to be 0.16. The protein content of seabass tissue is reported at around 0.17 g proteins g−1 seabass (Lupatsch et al. 2003). For a fish gaining body weight by consuming a given amount of feed, the nitrogen excretion (XN,excreted, g) can be calculated from Eq. (11.9). It is assumed that the feed (Xfeed) contains 0.5 g protein g−1 fish. It is further assumed that the feed conversion rate equals 1, i.e. 1 g of feed consumption is resulting in 1 g of body weight increase (Fig. 11.9):

Representation of the mass flows (Sankey chart) of feed ingredients and excretory products for a fish consuming 1000 g of feed assuming an FCR of 1
Dissolved ammonia excreted via the gills of fish follows similar daily pattern as the gastric evacuation rate (GER). GER is described for cold water and warm water fish by He and Wurtsbaugh (1993) and Richie et al. (2004), respectively. The excretory pattern can be well simulated with a sine function. The ammonia excretion can be calculated from Eq. (11.10):
3.3 RAS
A variety of models describing RAS having different levels of complexity can be found in the literature. Very complex models are available for specific aspects, such as the interaction of soluble gases and alkalinity (Colt 2013) or the description of the microbial community (Henze et al. 2002). More practical models for the mass balance of RAS are published by Sánchez-Romero et al. (2016), Pagand et al. (2000), Wik et al. (2009) and Weatherley et al. (1993). All models provide information on excretory mass flows and/or nutrient flows in dependence of time and location in the process chain. Such models provide a base for the simulation of the coupling of RAS and HP. The most important dissolved matter in RAS modelling is total ammonia nitrogen (TAN). Besides TAN the chemical (COD) and biological (BOD) oxygen demand, the total suspended solids (TSS) and dissolved oxygen concentration need to be considered. However, different notations in the scientific literature make it sometimes hard to read, to convert and to implement the information into models. In the following, notations as recommended by Corominas et al. (2010) will be used. TAN will be rewritten as XNHx-N and nitrate nitrogen will be expressed as XNO3-N.
3.4 Model Example
The model as it is described in the following is only valid for the RAS presented in Fig. 11.8. Other possible process chains for RAS are discussed in Sect. 11.3 of this chapter. For the mathematical depiction of physical systems, the following assumptions were made:
-
(a)
Density of water is assumed to be constant.
-
(b)
Tank and reactor are assumed to be well mixed.
-
(c)
Tank and reactor volume are assumed to be constant.
-
(d)
Process water flow is always greater than zero.
The assumption of a well-mixed tank and reactor leads to a mass balance equation for continuous stirred-tank reactor (CSTR) as described by Drayer and Howard (2014) in Eq. (11.11). It must be mentioned that diffusive processes can usually be neglected in RAS calculations because of a typically high process water flow rate. For a multi-tank RAS, the following holds:
In the above given equation n represents the number of tanks in the System, \( {\dot{x}}_i \) is the change of concentration of a given substrate x in a volume given by V i.. The process water flow into the tank or reactor is represented by Q in. V i is the volume of the component where the process water flow Q in is entering in. The process water flow Q in came from a component having the volume V j.
The conversion of XNHx-N into XNO3-N in nitrifying biofilters takes place on the surface area A [m2] available on the bio-carriers in the nitrification reactor (Rusten 2006). The available bioactive surface in the nitrification is calculated by multiplying the volume of the reactor with the volume-specific active surface of the bio-carriers AS [m2· m−3]. The total bioactive surface is calculated (Eq. 11.12) from the relative filling fbc of the nitrification reactor which usually is 0.6 (for details, see Rusten 2006).
The total daily TAN microbial conversion μmax [g d−1] (nitrification) was calculated by multiplying the specific TAN conversion (nitrification) rate, NHxconversion-rate [g m−2 d−1], with the total active surface area, A [m2], of the bio-carriers. Values for TAN conversion in different types of nitrifying biofilters can be found in literature. For moving bed biofilm reactors (MBBR), values are reported by Rusten (2006). This rate is valid for certain process conditions, and it is assumed that the bacteria biofilm is fully developed over the whole.
The total mass of NHx converted into NO3-N can subsequently be calculated with a Monod kinetic (Eq. 11.14). For this the NHx-N concentration, XNHx-N,2 [g · l−1], in the volume of the nitrification reactor (MBBR) V 2, is needed.
Given Eqs. (11.9, 11.10, 11.11, 11.12, 11.13 and 11.14), the following state-space model (combining fish-nitrification) results
Example
In this example, a theoretical RAS with V_reactor = 1300 l and V_tank = 6000 l is simulated.
All simulations had a daily feed input of 2000 g/day with 500 g protein/kg feed (Eq. 11.8). The daily TAN excretion was assumed to be a sine curve (Eq. 11.9). Active surface of the bio-carriers AS is 300 [m2 m−3], and the relative filling of the reactor fbc is 0.6. Specific TAN conversion rate, NHxconversion-rate, is 1.2 [g m−2 −d], and the biofilm is supposed to be fully developed (Eqs. 11.11 and 11.12). The state-space representation (Eq. 11.14) was implemented in MATLAB Simulink. The Example showcases the importance of mass flow for nutrient concentrations in coupled systems (Fig. 11.10 and 11.11).

Simulation of TAN (XNHx-N,1) in [mg/l] over 2 days = 2880 min with Q = 300 l/min (blue) and Q = 200 l/min (orange)
4 Modelling Anaerobic Digestion
Anaerobic digestion (AD) of organic material is a process that involves the sequential steps of hydrolysis, acidogenesis, acetogenesis and methanogenesis (Batstone et al. 2002). The anaerobic digestion of a mixture of proteins, carbohydrates and lipids is visualized in Figure 11.11. Most often, hydrolysis is considered as the rate-limiting step in the anaerobic digestion of complex organic matter (Pavlostathis and Giraldo-Gomez 1991). Thus, increasing the hydrolysis reaction rate will most likely lead to a higher anaerobic digestion reaction rate. However, increasing the reaction rates needs further understanding of the related process. Further understanding can be obtained via experimentation and/or mathematical modelling. As there are many factors influencing, for instance, the hydrolysis process, such as ammonia concentration; temperature; substrate composition; particle size; pH; intermediates; degree of hydrolysis; i.e. the potential of hydrolysable content; and residence time, it is almost impossible to evaluate the total effect of the factors on the hydrolysis reaction rate through experimentation. Mathematical modelling could therefore be an alternative, but as a result of all the uncertainties in model formulation, rate coefficients and initial conditions, no unique answers can be expected. But, a mathematical modelling framework would allow sensitivity and uncertainty analyses to facilitate the modelling process. As mentioned before, hydrolysis is just one of the steps in anaerobic digestion. Consequently, understanding and optimization of the full anaerobic digestion process needs connections from hydrolysis to the other processes taking place during anaerobic digestion and interactions between all these steps.

Simulation of nitrate-N (XNO3-N,1) in [mg/l] over 50 days = 72,000 min with QExc = 300 l/day (yellow), QExc = 480 l/day (orange) and QExc = 600 l/day (blue)
The well-known and widely used ADM1 (anaerobic digestion model #1) is a structured model including disintegration and hydrolysis, acidogenesis, acetogenesis and methanogenesis steps. Disintegration and hydrolysis are two extracellular steps. In the disintegration step, composite particulate substrates are converted into inert material, particulate carbohydrates, protein and lipids. Subsequently, the enzymatic hydrolysis step decomposes particulate carbohydrates, protein and lipids to monosaccharides, amino acids and long-chain fatty acids (LCFA), respectively (Batstone et al. 2002) (see Fig. 11.12).

A simplified scheme for the anaerobic digestion of complex particulate organic matter. (based on El-Mashad 2003)
ADM1 is a mathematical model that describes the biological processes and physicochemical processes of anaerobic digestion as a set of differential and algebraic equations (DAE). The model contains 26 dynamic state variables in terms of concentrations, 19 biochemical kinetic processes, 3 gas-liquid transfer kinetic processes and 8 implicit algebraic variables for each process unit. As an alternative, Galí et al. (2009) described the anaerobic process as a set of differential equations with 32 dynamic state variables in terms of concentrations and an additional 6 acid-base kinetic processes per process unit. For an overview of the modelling of anaerobic digestion processes, we refer to Ficara et al. (2012). However, in what follows and for some first insights into the AD process, we will present a simple nutrient-balance model of AD in a sequencing batch reactor (SBR).
4.1 Nutrient Mineralization
The nutrient mineralization can be calculated using the following equation (Delaide et al. 2018):
where NR is the nutrient recovery at the end of the experiment in percent, DNout is the total mass of dissolved nutrient in the outflow, DNin is the total mass of dissolved nutrient in the inflow and TNin is the total mass of dissolved plus undissolved nutrients in the inflow (see also Fig. 11.13).

Overall reactor scheme for determining the mineralization potential, where DN are the dissolved nutrients in the water, UN the undissolved nutrients in the sludge (i.e. TN-DN) and TN the total nutrients
4.2 Organic Reduction
The organic reduction performance of the reactor can be calculated using the following equation:
where ΔOM is the organic matter (i.e. COD, TS, TSS, etc.) inside the reactor at the end of the experiment minus the one at the beginning of the experiment, TOM out is the total OM outflow and TOM in is the total OM inflow (see also Fig. 11.14).

Overall reactor scheme for determining the organic material reduction potential, where TOM is the total organic matter and ΔOM the change of organic matter inside the reactor
5 HP Greenhouse Modelling
The crop water use and nutrient uptake is a central subsystem of aquaponics. The HP part is complex, as pure uptake of water and dissolved nutrients do not simply follow a rather simple linear relationship as, e.g. fish growth. To create a full-functional model, a complete greenhouse simulator is needed. This involves sub-model systems of greenhouse physics including climate controllers and crop biology covering interactive processes with biological and physical stressors.
However, from the HP point of view, greenhouse climate is the main driver for the complete aquaponic system, including, next to the nutrient balances, feedback loops of heat produced by the fish and additional CO2 supplied to the plants as reported by Körner et al. (2017) (Fig. 11.15).

Additional symbiotic behaviour of an aquaponic system
In this model, the fish culture produces heat through metabolic processes. The amount of heat produced by the fish is directly calculated from oxygen consumption that is a function of temperature and a constant for heat production for one unit oxygen consumed (i.e. 13608 J g−1 fish). Heat from breakdown of organic matter (Qbio), e.g. faeces and feed remain, is also contributing to the heat balance. Energy supply to the water system can then be calculated by heat production through the fish calculated from an average oxygen consumption rate (fO2,Twb). Additional heat production can then be calculated by biological breakdown of faeces (Fig. 11.16).

Aquaculture system implemented in the greenhouse with humidity, temperature and CO2 concentrations of the air (RHair Tair, CO2,air), heat from (Q) fish environment (fish), biological breakdown (bio) and heat fluxes (ɸ), taken from Körner et al. (2017)
CO2 production from the aquatic subsystem (\( {d}_{CO_2} \), g h−1 ), i.e. delivery to the aerial environment (d, g h−1), can be calculated for the given water temperature (TH2O, K) from oxygen delivery to the system ( \( {d}_{O_2}, \) g h−1) at water base temperature (TH2O,b, K) and the Q10 value of fish respiration (Q10,R). The following relationships are used:
with feed amount for the fish (ffish, g h−1), oxygen consumption rate at base temperature (fO2, kg [O2] kg−1 [feed]), fraction of feed loss wO2 (−) and mass balance of O2/CO2 (−).
To calculate the basis of aquaponics, i.e. the process flow (indicated with arrows, →) greenhouse macroclimate → microclimate → evapotranspiration → nutrients uptake, various greenhouse simulators that were developed in the past can be used and combined with aquaculture to an aquaponic system. All greenhouse models include a crop growth model. The model quality, however, can vary a lot from simple empirical regression models, e.g. Boote and Jones (1987), via deterministic models, e.g. Heuvelink (1996), to functional structural plant models (FSPM), e.g. Buck-Sorlin et al. (2011). As current crop growth and development models are inaccurate and have limited predictive power (Poorter et al. 2013), models are occasionally employed in crop management, but then mainly for planning issues in greenhouse simulators, e.g. Vanthoor (2011) and Körner and Hansen (2011). Prediction accuracy is jeopardized by many sources of uncertainty, such as modelling errors, variability between plants, variability between greenhouses and uncertain external climate conditions. As for predictions, accuracy also varies strongly per situation. However, online feeding of sensor information into the plant model can make plant model predictions considerably more reliable and useful to the grower.
Greenhouse simulators were developed in and for several places, e.g. the Virtual Grower (Frantz et al. 2010), KASPRO (De Zwart 1996), Greenergy Energy Audit Tool (Körner et al. 2008), The Virtual Greenhouse (Körner and Hansen 2011), The Adaptive Greenhouse (Vanthoor 2011), Hortex (Rath 1992, 2011) and the integrated aquaponic greenhouse model (Goddek and Körner 2019). At a research level, some models (i.e. simulation models in combination with certain greenhouse technologies) have been developed that potentially can be used to optimize investments and structural modifications to the production unit and production process. However, most systems entail closed software environments that can only be used by the developers, and many of them only exist in a research mode and lack further development and acceptance from the industry. However, there is yet no common basis for model sharing and collaborative model development. As a result, most modellers and modelling teams work in isolation developing their own models and codes. A shortcoming of that procedure is that greenhouse simulation models are developed in parallel in disparate research environments, which fail in cooperative growth and development.
All HP greenhouse model simulators are a compilation of sub-models that depend on the aim to integrate the interaction of plants and greenhouse equipment. The general two-part differentiation in greenhouse models and also in control and planning is the shoot and the root environment. Rather complicated and differentiated model approaches have been done for the greenhouse climate (Bot 1993; de Zwart 1996), and greenhouse crop growth has been intensively modelled in the 1990s for the main greenhouse crops such as tomatoes (Heuvelink 1996), cucumber (Marcelis 1994) and lettuce (Liebig and Alscher 1993). However, in order to calculate the water and nutrient uptake of crops, the microclimate, i.e. the climate close to and on the plant organs, needs to be known (Challa and Bakker 1999). This is an ongoing issue in greenhouse modelling, as microclimate variables, such as the central leaf temperature, are highly variable and dependent on many parameters and variables. One version of a leaf temperature model used in a crop canopy for crop temperature (Tc) integrated over vertical layers (z) by Körner et al. (2007) integrating absorbed irradiative net fluxes (Rn,a, Wm−2), boundary layer and stomata resistances (rb and rs, respectively, sm−1) and vapour pressure deficit at the leaf surface (VPDs, Pa) in the canopy is shown here, i.e.
with greenhouse air temperature (Ta, K), vapour pressure air density (ρa, g m−2), Stefan-Boltzmann constant (σ, Wm−2 K−4), specific heat capacity of the air (cp, J g−1 K−1), the psychrometric constant (γ, Pa K−1) and the slope between saturated vapour pressure and greenhouse air temperature (δ, Pa K−1).
Leaf temperature is the central part of the microclimate model, it has feedback loops to several input variables and especially stomata resistance (often also used as its reciprocal, the conductance), and the calculation needs several simulation steps for equilibrium. For HP, as part of the aquaponic system, however, modelling water and nutrient fluxes is most important. All water and nutrient balances in a closed multi-loop system are controlled based on the evapotranspiration rate of the crop ETc (Chap. 8). Commonly ETc is calculated as latent heat of evaporation, i.e. in energy terms (λE, Wm−2), and can be in accordance to leaf temperature expressed in different canopy layers z
To calculate ETc (L m-2), λE needs to be multiplied with the constant Lw (heat of vaporization of water; 2454·103 J kg−1) and the specific weight of water (9.789 kN·m3 at 20 °C).
Equation (11.18), however, only calculates the water flux through the crop, while the easiest way to estimate nutrient uptake is the assumption that nutrients are taken up/absorbed as dissolved in irrigation water and assuming that no element specific chemical, biological or physical resistances exist. In reality uptake of nutrients is a highly complicated matter. Consequently, to maintain equilibrium, all nutrients taken up by the crop as contained in the nutrient solution need to be added back to the hydroponics system (see Chap. 8). However, Eq. (11.18) only calculates the potential ETc, while too high potential levels can result in a higher transpiration than plants can handle, and then potential water loss may exceed water uptake. For that, the simple assumption of nutrient uptake is not satisfying. As described in Chap. 10, the different nutrients can have different states and change states with, e.g. pH, while the plant availability strongly depends on pH and the relation of nutrients to each other. In addition, the microbiome in the root zone plays an important role, which is not implemented in models yet. Some models, however, differentiate between phloem and xylem pathways. The vast amount of nutrients, however, is not modelled in detail for aquaponics nutrient balancing and sizing of systems, while the easiest way to estimate nutrient uptake is the assumption that nutrients are taken up/absorbed as dissolved in irrigation water and apply the above explained ETc calculation approach.
For control purposes the greenhouse is typically considered as a black box, where outside climate conditions determine the disturbance inputs, CO2 supply, heating and ventilation are the control inputs, and the greenhouse macro- and microclimate define the output of the system (Fig. 11.17).

Input-output system of a greenhouse
To control the greenhouse, the actions are directed to minimize the fast impacts of the disturbances, i.e. being ahead of expected changes by smart control. For that, control actions such as feedback and feedforward are used (Chap. 8). The best control, however, can be achieved when using a complete greenhouse model and combine it with weather forecast (Körner and Van Straten, 2008) attaining a model-based optimal greenhouse climate control, as worked out by Van Ooteghem (2007).
6 Multi-loop Aquaponic Modelling
Traditional aquaponic designs comprise of aquaculture and hydroponic units involving recirculating water between both subsystems (Körner et al. 2017; Graber and Junge 2009). In such one-loop aquaponic systems, it is necessary to make trade-offs between the conditions of both subsystems in terms of pH, temperature and nutrient concentrations, as fish and plants share one ecosystem (Goddek et al. 2015). By contrast, decoupled double-loop aquaponic systems separate the RAS and hydroponic units from one another, creating detached ecosystems with inherent advantages for both plants and fish. Recently, there has been an increased interest in closing the loop in terms of nutrients as well as increasing the input-output efficiency. For that reason, remineralization (Goddek 2017; Emerenciano et al. 2017; Goddek et al. 2018; Yogev et al. 2016) and desalination loops (Goddek and Keesman 2018) have been incorporated into the overall system design. Such systems are called decoupled multi-loop aquaponic system (Goddek et al. 2016).
Sizing the respective subsystems is fundamental of having a functioning check-and-balance system. For sizing one-loop systems, a simple rule of thumb is generally used, determining the hydroponic cultivation area based on the daily feed input to the RAS (Knaus and Palm 2017; Licamele 2009). The higher degree of complexity of multi-loop systems does not allow this approach anymore, as it comes with inherent risks for making false assumptions for each subsystem. There is a growing body of literature that examines mass balances for aquaponic systems (Körner et al. 2017; Goddek et al. 2016; Reyes Lastiri et al. 2016; Karimanzira et al. 2016). While some research has been carried out in developing numerical models for one- and multi-loop aquaponic systems, no single study exists that integrates a multi-loop aquaponic model with a complemented full-scale deterministic greenhouse model. This is particularly relevant for sizing the system, since plant growth and nutrient uptake are location dependent with crop transpiration as major driver. In concrete terms, this means that the climate within a greenhouse – which is highly dependent on the external weather conditions – has a high impact on plant growth given environmental factors such as relative humidity (RH), light irradiation, temperature, carbon dioxide (CO2) levels, etc. that were incorporated in greenhouse microclimate modelling (Körner et al. 2007; Janka et al. 2018).
7 Modelling Tools
In aquaponics, flow charts or stock and flow diagrams (SFD) and causal loop diagrams (CLDs) are commonly used to illustrate the functionality of the aquaponic system. In the following, flow chart and CLDs will be described.
7.1 Flow Charts
To get a systemic understanding of the aquaponics, flow charts with the most important components of the aquaponics are a good tool to show how material flows in the system. This can help, for example, in finding missing components and unbalanced flows and mainly influencing determinants of the subprocesses. Figure 11.18 shows a simple flow chart in aquaponics. In the flow chart, fish food and water are added to the fish tank, where the feed is taken by the fish for growth, the water is enriched with the fish waste and the nutrient-enriched water is added to the hydroponics system to produce plant biomass. From the flow chart, a CLD shown in Fig. 11.19 can be easily constructed.

Example of a flow chart in aquaponics (only RAS and HP exchange)

Causal loop diagram (CLD) illustrating examples of a reinforcing and a balanced loop within aquaponic systems. The reinforcing loop (R) is one in which an action produces a result which influences more of the same action and consequently resulting in growth or decline, where as a balancing loop (B) attempts to bring things to a desired state and keep them there (e.g. temperature regulation in the house)
7.2 Causal Loop Diagrams
Causal loop diagrams (CLDs) are a tool to show the feedback structure of a system (Sterman 2000). These diagrams can create a foundation for understanding complex systems by visualizing the interconnection of different variables within a system. When drawing a CLD, variables are pictured as nodes. These nodes are connected by edges, which form a connection between two variables accordingly. Figure 11.19 shows that such edges can be marked as either positive or negative. This depends on the relation of the variables to one another. When both variables change into the same direction, then one can speak of a positive causal link. A negative causal link thus causes a change in opposite directions. When connecting two nodes from both sides, one creates a closed cycle that can have two characteristics: (1) a reinforcing loop that describes a causal relationship, creating exponential growth or collapse within the loop or (2) a balancing loop in which the causal influences keep the system in an equilibrium. Figure 11.19 shows an example of both types of loops.
Let us illustrate this (Fig. 11.20) for the flow chart of Fig. 11.18.

Example CLD for RAS and HP exchange
It is obvious that CLD and SFD are very useful for system understanding, when the model does not require numerical accuracy. If numerical accuracy is required, the process should be studied further with a system dynamic tool diagram (SDTD) and modelled in dynamic system simulation software. For example, the CLD in Fig. 11.20 can be augmented with differential equations to a SDTD (Fig. 11.21).

Example SDTD for RAS and HP exchange
From the SDTD, we can now see how the differential equations for the nutrients balance in the tank look like. We know that the nutrient flow out of the fish tank (M xfout) must be the water flow (Q fout) times the concentration in the out stream (C xf):
Assuming a stirred tank gives the nutrient concentration of the fink tank to:
The differential equations of the RAS part can be derived to:
and for the concentration
7.3 Software
In addition to basic computer languages, such as Fortran, C++ and Python, for fast computation and fully user-specific implementation, all kinds of advanced software tools are available. These advanced software tools offer a variety of environments, concepts and options. We can model state variables, differential equations, connections and loops. In addition, we can use the model for simulations, stability analysis, optimization and control.
The main reasons for modelling of a system are to understand and control it. Therefore, the model helps to predict the system dynamics or behaviour. The software applications could allow us to do three consequent tasks: (a) the modelling itself, (b) the simulations of the model(s) and (c) optimization of the model and/or simulation.
Mathematica software is for functional analysis of mathematically described problems (Wolfram 1991). The concept is based on the LISP approach (McCarthy and Levin 1965.), a very effective functional programming language. The syntax is reasonably simple, and this software is popular in mathematics, physics and systems biology. Especially, the Ndsolve module helps to solve ordinary differential equations, plot the solution and find specific values.
Very similar tools for solving ODEs are offered by the Maple. This software is very powerful; between its features belong boundary problems solution, exact solutions and mathematical approximations. Copasi (complex pathway simulator) is a software tool for simulation and analysis of biochemical networks via ordinary differential equations.
SageMath is a free open-source mathematics software system. The software is Python-based and facilitates the simulation of ODE models. Data2Dynamics software is a collection of numerical methods for quantitative dynamic modelling and is a comprehensive model and data description language. The software allows the analysis of noise, calibration and uncertainty predictions and has libraries of biological models.
Probably the best simulation language is Simula (probably not in use anymore) and Simula 67, considered at the beginning as a package for Algol 60. These were the first fully object-oriented languages, introducing classes, inheritance, subclasses, garbage collector and others. In the beginning of the twenty-first century, the creators Ole-Johan Dahl and Kristen Nygaard were awarded the IEEE John von Neumann Medal and the A. M. Turing Award (Dahl and Nygaard 1966).
The idea behind Simula was that objects have life; they start to exist, do their being and cease. The objects are defined as general classes (template code), and each instance of such object has a ‘life’ in the simulation. The language was quite difficult to learn. However, it offered the possibility to model processes object by object and run simulation of their lives. The simulation runs on the basis of discrete events, and it is possible to simulate objects in co-routine. More tasks can start, run, detach, resume and complete in overlapping time periods in quasiparallel processes. Today’s hardware allows us modelling and simulation in fully parallel threads. However, many of the Simula concepts were already used for development of other languages, namely, Java, C/C++/C# and persistent objects libraries like DOL (Soukup and Machacek 2014). Current successor of Simula is BETA, extending and featuring the possibilities of inheritance in concepts of nested (sub)classes (with nested local time) and patterns (Madsen et al. 1993).
It is always an option to use any of the object-oriented languages and specific libraries and program all the necessary code for a specific model. On the other hand, already existing graphical programming environments allow to design and link the structure of the modelled system from libraries of objects (signal generator, sum, integrator, etc.), parametrize them and run the simulation in virtual time.
Another popular software for simulation is MathWorks Simulink, describing itself as a model-based design tool. The environment allows to combine and parametrize predefined blocks (from wide range of libraries) and diagrams into subsystems. The programming is done using graphical blocks and their connections into functional parts with feedback loops. The environment is widely used for control, automation and signal processing. Another possibility is to integrate own code from MathWorks Matlab language or use various toolboxes (Jablonsky et al. 2016). One of them, SensSB, is focused on the sensitivity analysis and allows to import other models using the Systems Biology Markup Language. For just the visualization of existing models in Simulink, it is also possible to use the very quick models viewer DiffPlug. PottersWheel supports the modelling of time-dependent dynamic systems, parameter calibration, analysis and prediction. Interesting tool is the experimental design for model verification.
For the modelling and analysis of system dynamics, similar strategy is used by the Stella Architect isee software application, where the model is composed of blocks, which are connected by relations. Stella allows modelling and simulation of very different types of applications, ranging from medical needs through building construction to the airplanes. Stella is sometimes marketed as iThink software. Powersim software was designed originally for economic purposes. However, it developed into more sophisticated tool, including electronic, solar power or drug treatment simulations. The former developer of Powersim is currently producing a similar software for more complex tasks Dynaplan Smia. Vensim is a system for modelling big data relationships of real systems. The power of Vensim is that it allows causal tracking, sensitivity analysis, calibration and intensive simulation. However, the software is also capable of dealing with wide range of simple and complex real systems (Hassan et al. 2016). True-World system dynamics software facilitates complex multibody dynamic simulations in discrete and continuous time. The modelling basically starts from balances.
Completely different approaches to modelling and simulation are cellular automata or agent-based modelling approaches, popularized by Stephen Wolfram (Wolfram 1991) as a new kind of science. The approach is sometimes also called the game of life. The modelling is implemented via interactions of autonomous individuals (Macal and North 2005). The simulations show emergent behaviour and therefore are very popular in systems biology for population dynamics. A simple tool for basic (and advanced, as well) agent-based modelling and simulation is the NetLogo software, where simple descriptions and parametrization create powerful models. The software allows visualization of the time development and noise induction (Stys et al. 2015). The application is written in Java, which sometimes limits the available memory. Probably the biggest effort in the multi-agent modelling was done by development of Wolfram software, which is the continuation of popular Mathematica, with extended tools for modelling and simulation. It has put Simulink-like modelling in a more attractive suit and also creates possibilities of agent-based modelling and much more tools for other mathematical disciplines (multivariate statistics, data mining, global optimization).
AnyLogic is very interesting software for problems of flow – information, money, traffic, logistic and mining. The simulation solves the problem of optimal flow in the designed system with minimal effort and maximal efficiency. The used concepts are system dynamics and agent-based and discrete-event modelling. It also offers hybrids between different modelling concepts. The software is useful, for example, in the epidemic spread simulations (Emrich et al. 2007).
Another agent-based modelling tool is Insight Maker, for simulation of population interacting in geographic or network space. The software supports graphical model construction, usage of multiple paradigms, embedded scripting and optimization toolset (Fortmann-Roe 2014).
For the modelling itself, description of the state variables, solution of the ODEs, parametrization and time dependency analysis, the first group of software, from Mathematica to Matlab, could be used without hesitation. They represent powerful tools for the modelling purposes. In case of more complex analysis, such as related to big data, simulation, noise induction, optimization, sensitivity and stochastics, more advanced tools are required, with object-oriented approach, involving also higher induction in the programming languages syntax.
8 Discussion and Conclusions
Aquaponics are complex technical and biological systems. For example, possible explanations for fish not growing properly can be small food rations, adverse water quality, technical problems causing stress, etc. Due to the inherently slow biology, scientific investigations of the validity of these explanations would be tedious and require several experimental trials to get all important factors and their interactions, demanding a lot of facilities, expertise, research time and financial assets. Therefore, the issue of modelling aquaponic systems was addressed in this chapter. In aquaponics, modelling is required for different objectives: (i) insight/understanding, (ii) analysis, (iii) estimation and (iv) management and control. For all these objectives, appropriate models are required. For example, to achieve objectives (ii) and (iii), an empirical approach can be utilized which uses statistical models to analyse data from previous experimental trials with the objective of extracting as much information as possible without conducting new experiments. Statistical models can reveal the most important factors affecting fish and crop production in the aquaponic systems. Future experiments could concentrate on these factors, thus making the utilization of costly research assets more effective.
The complexity of aquaponic systems, due to their feedback character and the interactions between RAS and hydroponic system, water treatment and fish growth, implies that in order to fulfil objectives (i) and (iv), i.e. to understand or optimize a plant (configuration, size, fish, feed, flows, etc.) with respect to cost, stability, robustness and water quality, non-trivial theoretical models of most of the system components described in this chapter are required. The advantage of these theoretical models presented over statistical models is their stronger ability to analyse the process underlying the aquaponics and the possibility to model the time aspect (dynamics). Statistical models just confirm or refute a hypothesis and to what extent variables covary but give no evidence of the underlying processes. On the other hand, theoretical models allow us to simulate the processes according to a hypothesis, compare simulated with observed data, evaluate both the hypothesis and the model and make adaptions. The validity of statistical models may not be beyond the operational range they were trained for, whereas theoretical models can be defined and used for a wide range of environments, provided that the models are validated for these ranges before application. For example, the multiple regression model used to assess relationships between fish growth with Oreochromis niloticus as fish species and environmental variables in an aquaponics facility in Germany cannot be easily applied to Spain with Cyprinus carpio, whereas a theoretical model describing the underlying processes (e.g. fish behaviour, aquaculture, freshwater ecology) as mathematical equations can be adjusted relatively easily because the fish and ecological process underlying that model are basically the same for the two sites.
Nevertheless, theoretical models also require some parameters such as reaction constants and substance settling velocity in settling tank to be determined. This is achieved commonly based on empirical study of one facility or very few facilities or in most cases from previously published studies (secondary sources). Studies based on secondary sources have limitations imposed by the given structure and amount of the available data, which is not existent when the data come from an experimental setup designed ad hoc for the study. However, estimating model parameters using experimental data from one aquaponics facility only can have problems regarding generalizability and replication of the results due to particular conditions present in the study. The data scarcity sometimes imposes strong restrictions to models that limit their practicality. The development of studies for parameter estimation with primary data that use a larger number of aquaponics facilities than earlier studies does help to overcome the present limitations and provide better and reliable results. This, however, is not an easy challenge for aquaponics researchers.
Simulation of aquaponics with the mathematical models under a wide range of management conditions will improve the understanding of aquaponics, verify different aquaponics configurations and point the way to the most promising strategies for improving aquaponics facilities. Again, this can lead to a more efficient way of conducting experiments.
Some modelling tools were also presented in this chapter. Traditionally, stock and flow diagrams (SFD) have been used for understanding processes as support tools for quantitative analysis. They are used to comprehend the flow and fluxes of quantities but lack the ability to illustrate the information associated to the flow and fluxes. Causal loop diagram (CLD) can be used to transfer complex SFD system into understandable simplified feedback structures. Together, the SFDs and the CLDs fully define the differential equation system. If only a simple qualitative understanding of the system is required, then CLD and SFD may be enough, but if the answer requires a numerical accuracy, then the problem can be investigated further with system dynamic tool diagrams (SDTD) and subsequently be modelled in a software tool for numerical simulation.
References
Badiola M, Mendiola D, Bostock J (2012) Recirculating Aquaculture Systems (RAS) analysis: main issues on management. Aquac Eng 51:26–35. https://doi.org/10.1016/j.aquaeng.2012.07.004
Batstone DJ, Keller J, Angelidaki I, Kalyuzhnyi SV, Pavlostathis SG, Rozzi A, Sanders WTM, Siegrist H, Vavilin VA (2002) The IWA Anaerobic Digestion Model no 1 (ADM1). Water Sci Technol 45:65–73
Boote KJ, Jones JW (1987) Equations to define canopy photosynthesis from given quantum efficiency, maximum leaf rate, light extinction, leaf area index, and photon flux density. In: Biggins J (ed) Progress in photosynthesis research. Martinus Nijhoff, Dordrecht, pp 415–418
Bot GPA (1993) Physical modelling of greenhouse climate. In: Hashimoto Y, Bot GPA, Day W, Tantau HJ, Nonami H (eds) The computerized greenhouse. Academic Press, San Diego, pp 51–74
Buck-Sorlin G, De Visser PHB, Henke M, Sarlikioti V, Ven der Heijden G, Marcelis LFM, Vos J (2011) Towards a functional–structural plant model of cut-rose: simulation of light environment, light absorption, photosynthesis and interference with the plant structure. Ann Bot 108:1121–1134
Challa H, Bakker M (1999) Potential production within the greenhouse environment. In: Stanhill G, Enoch HZ (eds) Ecosystems of the world 20 – Greenhouse ecosystems. Elsevier, pp 333–347
Colt JEK (2013) Impact of aeration and alkalinity on the water quality and product quality of transported tilapia—a simulation study. Aquac Eng:46–58
Corominas L, Riegler L, Takács I (2010) New framework for standardized notation in wastewater. J Int Assoc Water Pollut Res 61(4):S841–S857
Dahl O-J, Nygaard K (1966) SIMULA: an ALGOL-based simulation language. Commun ACM 9(9):671–678. https://doi.org/10.1145/365813.365819
de Zwart HF (1996) Analyzing energy-saving options in greenhouse cultivation using a simulation model. Wageningen Agricultural University, Wageningen, p 236
Delaide B, Goddek S, Keesman, KJ, Jijakli MH (2018). A methodology to quantify the aerobic and anaerobic sludge digestion performance for nutrient recycling in aquaponics. https://popups.uliege.be:443/1780-4507 22, 12
Drayer GE, Howard AM (2014) Modeling and simulation of an aquatic habitat for bioregenerative life support research. Acta Astronaut 93:S.138–S.147. https://doi.org/10.1016/j.actaastro.2013.07.013
El-Mashad H (2003) Solar Thermophilic Anaerobic Reactor (STAR) for renewable energy production PhD thesis Wageningen University. ISBN: 9058089533-238
Emerenciano M, Carneiro P, Lapa M, Lapa K, Delaide B, Goddek S (2017) Mineralizacão de sólidos. Aquac Bras 21–26
Emrich S, Suslov S, Judex F (2007) Fully agent based. Modellings of epidemic spread using anylogic. In: Proceedings of the EUROSIM
FAO (2016) The State of World Fisheries and Aquaculture 2016. Contributing to food security and nutrition for all. Food and Agriculture Organization of the United Nations, Rome
Ficara E, Hassam S, Allegrini A, Leva A, Malpei F, Ferretti G (2012) Anaerobic digestion models: a comparative study. In: Proceedings of the 7th Vienna international conference on mathematical modelling 2012, p 1052
Fortmann-Roe S (2014) Insight maker: a general-purpose tool for web-based modeling & simulation. Simul Model Pract Theory 47:28–45
Frantz JM, Hand B, Buckingham L, Ghose S (2010) Virtual grower: software to calculate heating costs of greenhouse production in the United States. HortTechnology 20:778–785
Galí A, Benabdallah T, Astals S, Mata-Alvarez J (2009) Modified version of ADM1 model for agro-waste application. Bioresour Technol 100(11):2783–2790
Goddek S (2017) Opportunities and challenges of multi-loop aquaponic systems. Wageningen University. https://doi.org/10.18174/412236
Goddek S, Delaide BPL, Joyce A, Wuertz S, Jijakli MH, Gross A, Eding EH, Bläser I, Reuter M, Keizer LCP, Morgenstern R, Körner O, Verreth J, Keesman KJ (2018) Nutrient mineralization and organic matter reduction performance of RAS-based sludge in sequential UASB-EGSB reactors. Aquac Eng 83:10–19. ISSN: 0144-8609
Goddek S, Keesman KJ (2018) The necessity of desalination technology for designing and sizing multi-loop aquaponics systems. Desalination 428:76–85. https://doi.org/10.1016/j.desal.2017.11.024
Goddek S, Körner O (2019) A fully integrated simulation model of multi-loop aquaponics: A case study for system sizing in different environments. Agric Syst
Goddek S, Delaide B, Mankasingh U, Ragnarsdottir K, Jijakli H, Thorarinsdottir R (2015) Challenges of sustainable and commercial aquaponics. Sustainability 7:4199–4224. https://doi.org/10.3390/su7044199
Goddek S, Espinal CA, Delaide B, Jijakli MH, Schmautz Z, Wuertz S, Keesman KJ (2016) Navigating towards decoupled aquaponic systems: a system dynamics design approach. Water (Switzerland) 8:303. https://doi.org/10.3390/W8070303
Graber A, Junge R (2009) Aquaponic systems: nutrient recycling from fish wastewater by vegetable production. Desalination 246:147–156
Halamachi I, Simon Y (2005) A novel computer simulation model for design and management of re-circulating aquaculture systems. Aquac Eng 32(3–4):S443–S464. https://doi.org/10.1016/j.aquaeng.2004.09.010
Hassan J et al (2016) Transient accumulation of NO2-and N2O during denitrification explained by assuming cell diversification by stochastic transcription of denitrification genes. PLoS Comput Biol 11(1):e1004621
He E, Wurtsbaugh W (1993) An empirical model of gastric evacuation rates for fish and an analysis of digestion in piscivorous brown trout. Trans Am Fish Soc 122(5):S.717–S.730
Henze M, Willi G, Takashi M, Mark L (2002) Activated sludge models ASM1, ASM2, ASM2d AND ASM3. IWA Publishing in its Scientific and Technical Report series, UK. ISBN: 1-900222-24-8
Heuvelink E (1996) Tomato growth and yield: quantitative analysis and synthesis. Department of Horticulture. Wageningen Agricultural University, Wageningen, The Netherlands, p 326
Jablonsky J, Papacek S, Hagemann M (2016) Different strategies of metabolic regulation in cyanobacteria: from transcriptional to biochemical control. Sci Rep 6:33024
Janka E, Körner O, Rosenqvist E, Ottosen CO (2018) Simulation of PSII-operating efficiency from chlorophyll fluorescence in response to light and temperature in chrysanthemum (Dendranthema grandiflora) using a multilayer leaf model. Photosynthetica 56:633–640
Karimanzira D, Keesman KJ, Kloas W, Baganz D, Rauschenbach T (2016) Dynamic modeling of the INAPRO aquaponic system. Aquac Eng 75:29–45. https://doi.org/10.1016/j.aquaeng.2016.10.004
Keesman KJ (2011) System identification: an introduction. Springer, London
Knaus U, Palm HW (2017) Effects of fish biology on ebb and flow aquaponical cultured herbs in northern Germany (Mecklenburg Western Pomerania). Aquaculture 466:51–63. https://doi.org/10.1016/j.aquaculture.2016.09.025
Körner O, Hansen JB (2011) An on-line tool for optimising greenhouse crop production. Acta Hortic 957:147–154
Körner O, Van Straten G (2008) Decision support for dynamic greenhouse climate control strategies. Comput Electron Agric 60:18–30
Körner O, Aaslyng JM, Andreassen AU, Holst N (2007) Modelling microclimate for dynamic greenhouse climate control. HortScience 42:272–279
Körner O, Warner D, Tzilivakis J, Eveleens-Clark B, Heuvelink E (2008) Decision support for optimising energy consumption in European greenhouses. Acta Hortic 801:803–810
Körner O, Gutzmann E, Kledal PR (2017) A dynamic model simulating the symbiotic effects in aquaponic systems. Acta Hortic 1170:309–316
Licamele JD (2009) Biomass production and nutrient dynamics in an aquaponics system. The University of Arizona
Liebig HP, Alscher G (1993) Combination of growth models for optimized CO2- and temperature-control of lettuce. Acta Hortic 328:155–162
Lugert V, Thaller G, Tetens J, Schulz C, Krieter J (2014) A review on fish growth calculation: multiple functions in fish production and their specific application. Rev Aquac 8(1):30–42
Lupatsch I, Kissil GW (1998) Predicting aquaculture waste from gilthead seabream (Sparus aurata) culture using nutritional approach. Aquat Living Resour 11(4):265–268. https://doi.org/10.1016/S0990-7440(98)80010-7
Lupatsch I, Kissil GW, Sklan D (2003) Comparison of energy and protein efficiency among three fish species gilthead sea bream (Sparus aurata), European sea bass (Dicentrarchus labrax) and white grouper (Epinephelus aeneus): energy expenditure for protein and lipid deposition. Aquaculture:175–189
Macal CM, North MJ (2005) Tutorial on agent-based modeling and simulation. In: Simulation conference, 2005 proceedings of the winter. IEEE
Madsen LO, Møller-Pedersen B, Nygaard K (1993) Object-oriented programming in the BETA programming language. Addison-Wesley. ISBN 0-201-62430-3
Marcelis LFM (1994) Fruit growth and dry matter partitioning in cucumber. Department of Horticulture. Wageningen Agricultural University, Wageningen, p 173
McCarthy J, Levin MI (1965) LISP 1.5 programmer’s manual. MIT Press, Cambridge, MA
Orellana JUW (2014) Culture of yellowtail kingfish (Seriola lalandi) in a marine recirculating aquaculture system (RAS) with artificial seawater. Aquac Eng:20–28
Pagand P, Blancheton JP, Casellas C (2000) A model for predicting the quantities of dissolved inorganic nitrogen released in effluents from a sea bass (Dicentrarchus labrax) recirculating water system. Aquac Eng 22(1–2):S137–S153
Pavlostathis SG, Giraldo-gomez E (1991) Kinetics of anaerobic treatment: A critical review. Crit Rev Environ Control 21:411–490
Poorter H, Anten NP, Marcelis LFM (2013) Physiological mechanisms in plant growth models: do we need a supra-cellular systems biology approach. Plant Cell Environ 36:1673–1690
Rath T (1992) Einsatz wissensbasierter Systeme zur Modellierung und Darstellung von gartenbautechnischem Fachwissen am Beispiel des hybriden Expertensystems HORTEX. University of Hannover, Germany
Rath T (2011) Softwaresystem zur Planung von Heizanlagen von Gewächshäusern. Fachgebiet Biosystem- und Gartenbautechnik. Leibniz University Hannover, Germany
Reyes Lastiri D, Slinkert T, Cappon HJ, Baganz D, Staaks G, Keesman KJ, (2016) Model of an aquaponic system for minimised water, energy and nitrogen requirements. Water Sci Technol. wst2016127. https://doi.org/10.2166/wst.2016.127
Richie M, Haley D, Oetker M (2004) Effect of feeding frequency on gastric evacuation and the return of appetite in tilapia Oreochromis niloticus (L.). Aquaculture 234(1–4):S657–S673. https://doi.org/10.1016/j.aquaculture.2003.12.012
Rusten BE (2006) Design and operations of the Kaldnes moving bed biofilm reactors. Aquac Eng:322–331
Sánchez-Romero A, Miranda-Baeza A, Rivas-Vega M (2016) Development of a model to simulate nitrogen dynamics in an integrated shrimp–macroalgae culture system with zerowater exchange. J World Aquacult Soc 47(1):129–138
Sinha NK, Kuszta B (1983) Modelling and identification of dynamic systems. Von-Nostrand Reinhold, New York
Soukup J, Macháček P (2014) Serialization and persistent objects. Springer. https://doi.org/10.1007/978-3-642-39323-5
Sterman J (2000) Business dynamics: systems thinking and modeling for a complex world. McGraw Hill, Boston
Štys D, Stys D Jr, Pecenkova J, Stys KM, Chkalova M, Kouba P, Pautsina A, Durniev D, Nahlık T, Cısa P (2015) 5iD Viewer-observation of fish school behaviour in labyrinths and use of semantic and syntactic entropy for school structure definition. World Acad Sci Eng Technol Int J Comput Electr Autom Control Inf Eng 9(1):281–285
van Ooteghem RJC (2007) Optimal control design for a solar greenhouse. Wageningen University, Wageningen, p 304
Vanthoor B (2011) A model-based greenhouse design method. Wageningen University, Wageningen, p 307
Waller U, Buhmann AK, Ernst A et al (2015) Integrated multi-trophic aquaculture in a zero-exchange recirculation aquaculture system for marine fish and hydroponic halophyte production. Aquac Int 23:1473
Weatherley LR, Hill RG, Macmillan KJ (1993) Process modelling of an intensive aquaculture system. Aquac Eng:215–230
Wik TEI, Lindén BT, Wramner PI (2009) Integrated dynamic aquaculture and wastewater treatment modelling for recirculating aquaculture systems. Aquaculture 287(3/4):361–370
Willems JC, Polderman JW (1998) Introduction to mathematical systems theory: a behavioral approach. Springer. ISBN: 978-1-4757-2953-5
Wolfram S (1991) Mathematica: a system for doing mathematics by computer. Wolfram Research, Champagne
Yogev U, Barnes A, Gross A (2016) Nutrients and energy balance analysis for a conceptual model of a three loops off grid, aquaponics. Water 8:589. https://doi.org/10.3390/W8120589
Zeigler BP, Praehofer H, Kim TG (2000) Theory of modeling and simulation, 2nd edn. Elsevier, London
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2019 The Author(s)
About this chapter

Cite this chapter
Keesman, K.J. et al. (2019). Aquaponics Systems Modelling. In: Goddek, S., Joyce, A., Kotzen, B., Burnell, G.M. (eds) Aquaponics Food Production Systems. Springer, Cham. https://doi.org/10.1007/978-3-030-15943-6_11
Download citation
DOI: https://doi.org/10.1007/978-3-030-15943-6_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-15942-9
Online ISBN: 978-3-030-15943-6
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)