
Abstract
In this chapter we'll see how the concepts covered individually in the previous chapters relate to each other. We have been looking at the many concepts and components of the technology solutions needed to enable the trusted infrastructure that moves us toward the goal of delivering trusted clouds. We have covered the foundational elements of platform trust attestation, network virtualization security, and identity management in the cloud. In this chapter, we put all these elements together. Virtustream, a key Intel partner, took a proof of concept implementation, originally developed with Intel, for a key customer and evolved it into a new capability to enable secure cloud bursting that is available to all Virtustream customers. We'll explain the nature of this new capability and examine the architecture and reference design for this capability in the next few pages.
You have full access to this open access chapter, Download chapter PDF
Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
In this chapter we’ll see how the concepts covered individually in the previous chapters relate to each other. We have been looking at the many concepts and components of the technology solutions needed to enable the trusted infrastructure that moves us toward the goal of delivering trusted clouds. We have covered the foundational elements of platform trust attestation, network virtualization security, and identity management in the cloud. In this chapter, we put all these elements together. Virtustream, a key Intel partner, took a proof of concept implementation, originally developed with Intel, for a key customer and evolved it into a new capability to enable secure cloud bursting that is available to all Virtustream customers. We’ll explain the nature of this new capability and examine the architecture and reference design for this capability in the next few pages.
Virtustream, then, is a cloud service provider and a cloud management software vendor at the forefront of private and public cloud deployments. Virtustream’s flagship cloud management software is xStream. (See sidebar for an overview of Virtustream xStream.) The proof of concept project was designed to demonstrate application workload mobility and “bursting” capabilities between a customer’s primary IT facilities and its geographically disperse data centers and application profiles, while simultaneously ensuring policy, security, and performance controls. In addition to addressing the networking, identity management, and cross–data center orchestration, this project validated Intel’s TXT as a foundational technology to enable the critical secure cloud bursting features supported by the Virtustream platform.
This infrastructure reference design is a way to highlight the essential elements for secure hybrid cloud services. Virtustream is the first such example in the industry to provide a robust, secure, and elastic cloud management service, intended for managing and controlling bursting and the orchestration of workloads on the virtualization platforms at multiple sites under control by multiple providers. This new reference design addresses the demanding requirements from cloud customers related to personally identifiable information (PII), location enforcement, auditability, infrastructure security, network security, application bandwidth, and service levels and performance.
Cloud Bursting Usage Models
New cloud computing clients envision an application computing environment in which computing capacity can be expanded by what has been termed cloud bursting, or switching critical application loads from facilities within a company’s headquarters to geographically disperse data centers as demand requires.
An Explanation of Cloud Bursting
Figure 9-1 depicts the basic principles of cloud bursting and how it operates. This technology enables virtualized data centers to expose their excess capacity to other virtual data centers. It enables collaboration in a federated cloud that allows partners to offer capacity and move workloads or parts of workloads on demand between each other, all without compromising security and operational related SLAs.

The structure and operation of cloud bursting capability
With cloud bursting capability, it becomes possible to deploy all or some application components, packaged as virtual machines, that normally run on traditional corporate resources, transferring them to one or more data centers that host pooled resources. This allows enterprises to respond to spikes in demand, to enhance business continuity, manage capacity, and optimize cost. Hence, the general premise of cloud bursting is to use the cloud as an overflow resource—for example, in the event an organization’s base infrastructure becomes overloaded. A reduction in total cost of ownership may be possible with this overflow model if extra capacity is needed on a seasonal basis or for only a few minutes per day, or to employ disaster recovery practices. Typical utilization rates for these usages are abysmally low—namely, a few minutes per day for workload peaking or in the unlikely event of a disaster-triggered outage. In contrast, expanding a data center to address those eventualities results in poor capital utilization for the enterprise.
In short, resource utilization should be a tactical, responsive, and transparent operation. Business outcomes for a data center are no longer measured in terms of glacial five-year planning cycles; they now measured as current operational conditions in responding to short-term business demand and they use real-world metrics, such as the quality of experience and service (QoS). Cloud bursting aligns the traditional safe enterprise computing model with that of cloud computing; in essence, it means “bursting” into the cloud when necessary or using the cloud when required temporarily. These practices have the potential of improving, by several orders of magnitude, the data center’s agility and operational transparency, such as having server resources allocated in minutes instead of going through a six-month or year-long budgeting and procurement process.
Cloud bursting addresses three basic needs of an enterprise data center:
-
1.
Companies need additional capacity to handle occasional demand spikes, lest they encounter unacceptable server utilization and application response times. Investing internally to handle peak loads leads to unused capacity and stranded investment. Most enterprises want to reduce capital expenditures to the extent that does not impact QoS.
-
2.
Companies are hesitant to delegate all infrastructure to cloud computing providers, owing to serious security and stability concerns. Presently, cloud service providers are used for important but noncritical applications such as human resources and expense reporting. The organization’s crown jewels currently need to run on corporate-hosted, dedicated infrastructure and are treated as premium applications, justifying the extra cost involved. Cloud bursting addresses those concerns about migrating workloads to cloud by providing a hybrid model, and the net effect is a reduction in the total cost of ownership.
-
3.
Cloud bursting meets a need to migrate workloads from one cloud to another, based on resource consumption and performance. This involves network bandwidth, storage, management, security, among other considerations. In this scenario, bursting is not triggered by load overflow; rather, it is initiating by a need for workload migration to optimize the resource utilization.
Implementing a cloud bursting strategy brings with it a need for automation in the data center and capabilities to orchestrate the local and remote resources, as well as to globally enforce policies from a specified command point or entity. It requires enterprise service consumers to manage not only the deployment of applications and resources in the enterprise data centers but also those within the cloud platform of the cloud service provider, accomplished through a cloud API using the cloud service provider’s self-service portal or by directly manipulating the hypervisor. For ultimate flexibility, operators will want to implement the cloud bursting across heterogeneous hypervisor environments. Doing so brings up issues of virtual machine interoperability.
The Open Data Center Alliance has carried out initial studies on this usage. All demand spikes on a virtualized enterprise data center infrastructure are not the same; the spikes come in different shapes and forms. Today, enterprises handle spikes through the one-size-fits-all approach of overprovisioning the infrastructure. But with cloud bursting, enterprises have another means for handling overflow capacity and delivering the same or better QoS. They get to take the money to the bank that otherwise would have been spent on addressing this occasional demand.
Architectural Considerations for Cloud Bursting
There are key architectural considerations for successfully deploying cloud bursting.
-
Security and isolation. In the end-to-end view of this deployment model, security and isolattion are extremely critical. Enterprises would be hesitant to trust a third-party service provider to host applications or components thereof, and so they access the enterprise data either by reaching back into the enterprise through long pipelines or by caching the data at the service provider. Service providers need to prove they meet compliance and audit requirements as specified by the enterprise customer. In addition to the primary capability of facilitating migration and use of overflow capacity, they need to address to their customers’ satisfaction the security for data in transit, in use, and at rest, as well as the implementation of access control mechanisms. For cloud bursting to be embraced, there needs to be bilateral trust between cloud data centers. The relevant technologies and security standards are still in their infancy at the time of this writing.
-
Network performance and data architecture. Network latency and bandwidth are logical concerns for bursting applications to handle overflow capacity. The connectivity between the clouds looks like a horizontal hourglass; the Open Data Center Alliance speaks of this as the “tromboning” phenomenon. Even with the best WAN networks and WAN performance optimization, the throughput and latency can have significant impact on application performance. Also, the connectivity of choice for cloud bursting data centers is almost invariably a VPN connection with encryption, which adds to the latency. The challenge is to determine the best way to deal with the data that distributed applications require or generate. There are several strategies for dealing with cloud bursting, each with its different implications for cost, performance, and architecture. Some architectural remedies involve data cache in the overflow capacity and replication, and shadow databases in overflow capacity. It is not currently practical to send terabyte data sets over the wire, and the “sneakernet” approach of shipping data on physical media still makes the most sense. Reaching back to base, or replicating data in the overflow capacity, works best for applications with smaller data sets or for those not overly latency sensitive.
-
Data locality and compliance. The current lack of transparency from cloud providers on the exact physical location of their data is such a significant concern that we dedicated Chapter 5 to the subject. As we saw earlier, there are country and regional constraints on how far and where the data can and cannot migrate. Depending on the type and kind of data processed by the cloud application, there might be legal restrictions on the location of a physical server where the data is stored. Missing is a simple API-based mechanism with cloud platforms to query the location of tenant data. The migration of workloads to a public cloud, even if the associated data doesn’t move, increases the complexity associated with meeting legal and regulatory requirements for handling sensitive information. How can a service consumer be certain that the virtual machines instantiated in the overflow capacity at the service provider were shut down and the temporary storage securely wiped afterwards?
-
Management and federation. This concept comprises the management, resource allocation, resource optimization, and lifecycle management between a virtualized data center and the overflow capacity in a remote data center. In short, cloud bursting can’t be implemented without these logistical capabilities. The extent of interoperability across cloud platforms and the programmability of these platforms determine the extent to which an enterprise can utilize the uniform processes to manage resources. Cloud IaaS offerings are defined, developed, published, provisioned, and managed through the API from the service provider. These APIs must be standardized to enable hybrid cloud users to move workloads quickly and easily across different cloud service providers, without vendor lock-in. The current situation is far from ideal. A number of software tools are available from service providers to import workloads into their infrastructure. Understandably, the tools to migrate workloads out of their infrastures are much less available. Conflicts of interest might be avoided if there were third-party tools from independent software vendors. This won’t happen until a modicum of API standardization takes place.
Data Center Deployment Models
All the existing cloud deployment models support the cloud bursting usage model. A key objective defined as part of the reference design architecture, then, includes the ability to deploy into and connect to remote data center cloud locations across wide area networks. Additionally, enterprise users expect to gain from the operational flexibility and cost reduction through competitive sourcing. There is the benefit of resource elasticity and response to changeable workload demand. For these workloads, a pay-as-you-go IT using cloud service providers is usually more economical. In this section, we do not deep dive into deployment model configurations. Instead, we focus on the model selected for the reference design architecture.
As indicated in Figure 9-2, there are multiple deployment models possible to support these objectives.
-
Seamless and secure integration between geographically disperse customer data centers
-
Private clouds on service provider data centers
-
Trusted hybrid clouds—hybrid clouds on trusted service provider data centers
-
Public clouds
Each model carries its advantages and drawbacks. A strong security foundation was a primary consideration for our reference design. This starts with trusted hardware as determined by hardware roots of trust and is validated using Intel TXT-capable and -enabled hardware. This allows the platform’s integrity to be measured and audited on a near-real-time basis. Hence, the choice for our reference design is a trusted hybrid cloud.

Data center deployment models
Trusted Hybrid Clouds
Given the nature of malicious threats in today’s environment and the stringent security requirements in many organizations, IT operations cannot unconditionally trust either their on-premise resources or their cloud service providers’ execution environment.
Security is a fundamental consideration in server, storage, and network deployments, be it virtualized or bare metal. In a cloud deployment scenario, security needs to be supported and managed by both the service provider and the consumer tenant. This interaction leads to the concept of trusted hybrid clouds. Trusted hybrid clouds are built on the concept of hardware-enforced roots of trust. Our reference implementation uses Intel’s Trusted Execution Technology (TXT) for this purpose, as well as to implement a real-time attestation capability for the trusted platform.
The proof of concept reference implementation deploys trusted execution environments to establish a root of trust. This root of trust is optimally compact, extremely difficult to defeat or subvert, and allows for flexibility and extensibility to measure platform components during the boot and launch of the environment, including BIOS, operating system loader, and virtual machine managers or VMMs. Chapters 3 and 4 covered the Intel TXT and the attestation process in detail.
As shown in Figure 9-3, the reference design comprehends the deployment model for trusted service provider data centers offering hybrid clouds. Under this model, the customer data center and the cloud service provider both deploy trusted execution environments. Policies and compliance activities using trusted platform attestation are required for enforcement of trust and security in the cloud.

Trusted hybrid clouds (SRC: Virtustream)
Attestation and policy enforcement are managed by the cloud management layer and include the following.
-
Trusted resource pool, relying on hardware-based secure technical measurement capability and trusted resource aggregation
-
Platform attestation and safe hypervisor launch, providing integrity measurement and enforcement for the compute nodes
-
Trust-based secure migration, offering geolocation measurement and enforcement (geo-fencing) for cloud trusted resource pools and associated compute nodes
-
Instantiation and provisioning of workloads, operating in a trusted resource pool
-
Dynamic workload migration and API-based enforcement, moving between trusted resource pools within and across geolocations
-
Visibility and transparency in real-time measurement, regarding the reporting and auditing of the workloads to support governance, risk, and compliance requirements
-
Best practices for deploying a secure virtualized infrastructure, following industry recommendations
The reference design demonstrates how an enterprise user workload application can burst into Intel TXT’s attested secured resources, as well as prevent application loads from utilizing noncompliant resources under NIST 7904 draft recommended scenarios.
We cover details of the architecture next, with network topology considerations, followed by security considerations for the successful deployment of this reference design.
Cloud Bursting Reference Architecture
Figure 9-4 shows the solution architecture for this trusted hybrid cloud deployment. Site 1 (“Customer Site”) represents an IT organization’s primary private cloud, running Virtustream xStream cloud management software and managing resource pools of servers running VMWare ESXi. (See the sidebar for details on Virtustream xStream cloud management software.) As can be seen from the figure, there are two resource pools: Intel TXT-based resource pools for security sensitive workloads and non-TXT resource pools for regular workloads. A similar setup (as indicated by site 2, “Cloud Service Provider”) is instantiated and maintained at a public cloud environment as well. The workloads from the private cloud (site 1) burst into the resource clusters at site 2. The xStream cloud management software seamlessly federates the identity, controls and configures resources and deployment of workloads, and is fully controlled, monitored, and managed from within the organizations xStream Management portal. To ensure that the management software is running on high-integrity infrastructure, as shown in Figure 9-4, the xStream software components are provisioned on Intel TXT-based trusted pools.

Cloud bursting solution architecture (SRC: Virtustream)
Here are the key components of the reference architecture, followed by a brief exposition of each:
-
Secure environment built around best practices
-
Cloud management, or cloud identity and access management
-
Separation of cloud resources, traffic, and data
-
Vulnerability and patch management
-
Compliance, or security policy, enforcement, and reporting
-
Security monitoring
Secure Environment Built Around Best Practices
Each computing platform component is built based on standard technical implementation guides (STIGs) from a reputable standards body; in this case, NIST via the NIST SP 800-70 National Checklist Program for IT Products. The cloud data center is built with the STIGs just cited, with multiple security ecosystem components utilizing a defense in depth methodology. The framework creates a multi-layered secure computing environment with a high degree of assurance in its security posture.
Cloud Management
Virtustream’s xStream software provides management functions with a highly secure and user-friendly self-service cloud management, enabling cloud service provider tenants to move workloads around all the federated cloud service providers’ data centers in an efficient and reliable manner. This approach enables cloud bursting and migration of workloads in a secure manner. It manages the resources, identity, access control, reporting, and management within the organization’s data center, as well as the hybrid cloud resources in the service provider’s data centers. The xStream software provides a very robust set of APIs for interfacing with all the services. API endpoints allow secure HTTP access (HTTPs) to establish secure communication sessions with Virtustream services using SSL.
Cloud Identity and Access Management
The cloud management platform utilizes the least privilege to execute on all operations to ensure that no one user has more than the required privileges to accomplish its respective management tasks in the cloud data center in a controlled manner. Each user carries unique security credentials, eliminating the need for shared passwords or keys and allowing the security best practices of role separation and least privilege.
Access to the cloud environment is denied unless explicitly granted. The default access methodology for all layers of computing are denied unless explicitly given access via an authorization policy managed by the cloud administrator. Custom, secure portals requires dual-factor authentication with role-based access. Identity management is accomplished utilizing LDAP/x.500 directory services with role-based access (RBAC) control and management.
Separation of Cloud Resources, Traffic, and Data
All tenants in the cloud have their related traffic, computing, network, and storage resource separated logically from each other in a reliable and consistent manner, attained by utilizing the xStream management and orchestration platform.
Secure network is segregated into physical zones based on the level of trust associated with the intended purpose, such as management, public DMZ, core, cloud platform, and backup. (There is more detail on the physical zone segregation is in the Network Topology and Considerations section.) Additionally, xStream allows adding another layer of network security to customer virtual machines by creating private subnets and even adding an IPsec VPN tunnel between the client’s network and the third-party data center.
Vulnerability and Patch Management
Cloud vulnerability and patch management are handled in an automated method by the cloud service provider for all tenants wanting secure, trusted, and compliant computing. Logging under SIEM, intrusion detection, file integrity monitoring, content filtering, data leakage prevention, firewall audits, web application layer firewalling, and many other security processes need to be considered to ensure the security of the cloud provided.
Compliance
Security policies are defined in the orchestration portal during virtual machine provisioning. Here are some examples:
-
Trusted execution technology enforced policies: A given virtual machine requires TXT-based boot integrity and attestation and should not be allowed to execute on unverified and non-attested hypervisors and platforms. Figure 9-5 shows how a policy gets set up using the xStream operational portal.
Figure 9-5. 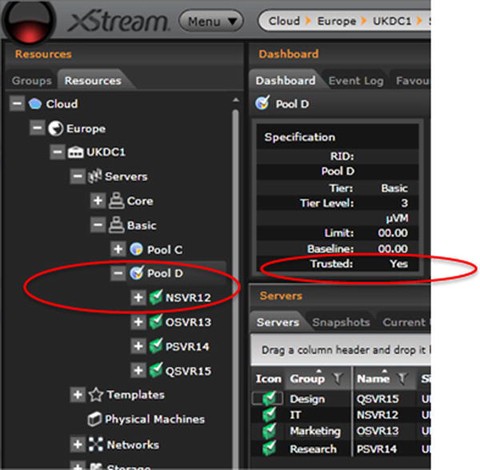
Enabling the trust policy

-
Geo-fencing policies: This type of policy defines where a virtual machine and associated data are allowed to run. A geo-fence is a set of one or more physical locations and geographies for a physical data center, including possible locations within the physical data center down to a physical rack. For example, a VM can only run on physical machines running in a data center in the United States and Canada.
-
Data security policy: Data center best practices dictate that sensitive, private, and confidential data in the cloud, including but not limited to PII data, must be protected with tokenization and/or encryption technology conformant with FIPS 140-2–level encryption technology. During provisioning, options to encrypt the provisioned disk of a virtual machine or even an entire virtual machine are available to a cloud administrator. Chapter 8 covered the notion of trusted VMs, including tenant-controlled encryption and decryption of virtual machines based on outstanding data security policies.
-
Compliance reporting: All cloud audit logs and security-related posture data from vulnerabilities scans are correlated to their respective information assurance framework security controls and are maintained as continuous monitoring artifacts in a GRC information system to attest to the controls functioning as designed and in place for auditors to validate. The reference design calls for defining a small set of controls regarding virtual machine geolocation policies. These controls are evaluated on a continuous basis to assess compliance of workloads and data location regarding trust requirements. One example of a control is an authentication event occurring for a privileged user onto a sensitive compute virtual machine.
-
Security monitoring: To ensure 24/7 continuous monitoring of the cloud environment, real-time security monitoring is built using enterprise class security information and event management (SIEM) tools. xStream SIEM (xSIEM) is used in the reference design to collect and correlate events from all components of the cloud systems. It is important to verify, on a continuing basis, the threat profile of the cloud environment and to provide visibility into the posture of the environment in a continuous real-time manner to the cloud’s security operations team and tenant customers. By monitoring the cloud infrastructure with a SIEM, security operations center personnel can react in an informed manner to any suspicious activity performed against any cloud infrastructure or compute workload. The xSIEM tool is equipped to capture any trust policies the cloud management software has executed with regard to placement and migration of workload, whether inside the enterprise data center or burst into the service provider data center. Events are analyzed, categorized, and the appropriate alerts are generated for investigation and possible remediation.
-
Cloud management and orchestration portal: As shown in Figure 9-6, the xStream management and orchestration portal is the heart of the cloud operations, enabling the tenant and the cloud provider to operate in an efficient manner while allowing the tenant to consume compute, network, and storage in an elastic manner, with the cloud provider managing and providing these resources in a secure and reliable manner.

xStream management environment
Network Topology and Considerations
The network for the reference data center design is built on principles of scalability, redundancy, and security. There are many design considerations in the selection of data center connectivity options. Needless to say, security and isolation are key, but there are more:
-
Bandwidth shaping
-
Traffic policing
-
Performance considerations due to latency
-
IP addressing
-
Availability and DDOS-related issues
-
Time-of-day issues

Network topology
Figure 9-7 captures the topology for the reference data center network design. The network design architecture includes separate network cores for the enterprise cloud zone and the DMZ zone. This allows a full air gap between those trust zones, and it can facilitate the achievement of certifications for the platform in data centers.
The design caters to the following elements:
-
Appropriate level of segregation between virtual machines belonging to different cloud users
-
Appropriate level of security for management network
-
Standard virtual network design considerations, such as NIC failover design
-
Capacity planning for future growth
The design is intended to be a best-practice cloud deployment for using either separate virtual switches or multiple VLANs to segregate traffic and retain inter-site mobility for the network stack. The platform utilizes virtualized converged I/O as a key technology to enable the control of both storage and network-based operations.
At all stages throughout the design, resilience is implied—that is, fault tolerance within the network switch design, multiple connections through multiple firewalls and IPS appliances, and resilient VPN concentrators.
Let’s highlight the essential network elements.
-
The demilitarized zone. All IP VPN traffic lands on a demilitarized zone (DMZ) switch before passing through a port blocking firewall, to strip all non-VPN traffic and to transform VPN traffic to VM VLAN IP traffic accessing the layer 2 switch infrastructures. From here, traffic is addressed to the client-specific vSwitches as per the VM VLAN tags. Before accessing the VM attached switches, all traffic is routed through an IPS device in order to assure quality of traffic from both external access and VM-generated packets.
The DMZ network incorporates a business continuity management (BCM) function and constitutes the virtualized infrastructure dedicated to meeting the production demands of tenants requiring web facing services. To ensure reliability and availability, one DMZ network is maintained per pair of data centers.
-
Management network. The tenant management connectivity consists of two routes for internal and external management access. Both routes need to pass through port blocking firewalls before access is granted to the layer 2 switch infrastructure. This is primarily to avoid impact if service provider management workstations are compromised. Remote access is provided through the same port blocking firewall as customer access.
Storage replication should occur over its own switching and routing infrastructure; firewalls are configured behind each secure connection appliance to avoid compromise of this route to core infrastructure. This traffic will be encrypted and assured throughout transit, and it is preferable that this transit is over a leased line to improve that security.
-
Core network. Production core network incorporates layer 3 and layer 2 equipment with a high-availability design. The zone is utilized to control, manage, and route all network traffic incoming and outgoing from the customer platform, DMZ, and management network. This zone is the centralized control point for all critical network traffic.
-
Backup network. This contains all backup devices and related service components with routes from customer platform zones to service all data backup service request and requirements.
-
Platform. Comprises the production computing infrastructure dedicated to meeting customer production requirements requiring non-web facing services. One required per pair of data centers, data security, resilience, and reliability is a key part of the design of components in this zone.
-
MPLS. MPLS is an any-to-any WAN technology robust to changes in IP topology and automatic rerouting. MPLS provides a variety of ways of logically isolating multiple virtual connections on a single physical circuit. If possible, a separate VRF (virtual routing and forwarding) MPLS instance can be temporarily created for the temporary traffic, thereby logically isolating the routing domain from the VDI traffic.
Another method is to use the prioritization techniques available to MPLS to always ensure that VDI traffic trumps any POC traffic on the circuit. These methods may include QoS markings at the IP DSCP (DiffServ Code Point) or at the Ethernet p-bits. Coexistence with any existing quality of service (QoS) markings techniques on the MPLS circuit will be a requirement.
Security Design Considerations
Security is a high priority for customers in a multi-tenant environment. While virtual infrastructures are relatively secure in their basic installation, additional changes are required to adhere to certain security audit requirements. This section provides an overview of some of the security measures considered within the reference design, as they are subject to the wider security protocols required in an offering for managed services.
Hypervisor Hardening
VMware ESXi 5 is a small-footprint version of VMware’s hypervisor. This minimal footprint also reduces the attack surface. ESXi implements support for Intel TXT. The capability is managed and controlled by xStream software for trusted compute pools, providing visibility to the integrity of the platform and enforcement of trust policies for deployment and migration of virtual machines. The ESXi installation comes with a number of additional security features:
-
LDAP integration
-
Management interface firewall
-
Lockdown mode
-
Logging
These features have to be enabled corrected to ensure hardening. With the high priority attached to security in the multi-tenant paradigm being used in the cloud platform, using ESXi 5.x is recommended. In addition to this, basic security measures such as setting a strong root password should be used and compliance requirements that are necessary for compliance with the security standards selected for the platform are checked.
Firewalls and Network separation
To provide end-to-end separation of client data, it is important to ensure that no element in the infrastructure allows data to comingle or be accessed by another client. This is especially true of the networking design and infrastructure.
In order to achieve this, the reference design prescribes the infrastructure to be entirely separate from the customer VPN landing zone, through to the individual virtual machines and at all points in between. To achieve this, the reference design uses of the following technologies:
-
VLAN
-
Virtual switches
-
Virtual appliances
-
Firewalls and routing infrastructure
Every cloud customer is assigned one or more individual VLAN, as needed. Customer network traffic remains isolated from each other within a VLAN. The switch to which a VLAN is attached is also assigned the same VLAN tag.

VLAN separation using vSwitches
As shown in Figure 9-8, the only way for machines in VLAN A to talk to machines in VLAN B (and vice versa) is for the router to be configured to allow that conversation to occur. To ensure that the switch configuration is unified across all hosts in a cluster, the reference design uses distributed virtual switches. These ensure that the switch configuration associated VLAN tagged switch port groups are the same across all attached hosts, thereby limiting the chances of a misconfiguration of VLAN tagging on the virtual switch.
In addition to the VLAN tagging, the reference design also makes use of other traditional networking separation and security tools. A key technology is firewalling (see Figure 9-9). Both virtual and physical firewalls are needed to ensure separations throughout the environment, from access to the physical network, including DMZ separation using physical firewall devices, and virtual firewalls to ensure visibility and separation across virtual machines.
Firewalls are required to scale to the highest VPN session counts, throughput, and connection speed and capacity to meet the needs of the most demanding customers. Offering protocol-agnostic client and clientless access for a broad spectrum of desktop and mobile platforms, the firewall device delivers a versatile, always-on remote access integrated with IPS and Web security for secure mobility and enhanced productivity.

Cisco ASA protection
The reference design ensures that throughout the network, be it virtual or physical, industry standard separation is enabled, and further guaranteed and improved by the inclusion of specific industry leading technologies that ensure even greater levels of granularity and visibility within the system.
Management Network Firewalling
For additional security, putting the hosts and management servers behind firewalls provides additional security and separation of the management services. Ports will be required to be opened for VMware virtual infrastructure to work.
Virtual Networking
VMware virtual infrastructure implements a virtual networking component that allows for virtual switches and port groups to be created at the software layer and operate as if they were physical infrastructure. There are certain features and ways to configure the networking to improve network segregation and prevent possible network vulnerabilities. These are:
-
Use VLAN tagging
-
Disable MAC address changes
-
Disable forged transmits
-
Disable promiscuous mode
-
Prevent and monitor for spoofing
Note that some of the features need to be enabled for certain customers— for example, for internal IDS scans—but should only be changed explicitly from defaults on an individual basis. As mentioned earlier, all customers will be assigned their own VLAN, and this will remain enabled. As a recommended practice, the reference design calls for use of different vSwitches to physically separate network traffic, disable forged transmits, and segregate management network traffic from virtual machine traffic
Anti-Virus Software
Anti-virus and anti-malware software is always a consideration by any company when security is in question. For the management layer, anti-virus software is recommended on the virtual machine manager server and any other appropriate virtual machines.
The definition of anti-virus policies and the deployment of anti-virus agents by a service provider to the tenant’s virtual machines fall outside the scope of this reference design. Tenant segregation and the use of security devices such as firewalls and IPSs—and, if selected, technologies such as virtual firewalls—will ensure that any viruses on a tenant’s virtual machines will not spread to other tenants.
It is recommended that approved anti-virus software be installed on management layer virtual machines. Unless specified by the service provider, the tenant is generally responsible for installation of anti-virus software on production virtual machines.
Cloud Management Security
The cloud management layer provides the basis for all management functions surrounding the reference design. It ties into all the other technologies previously listed and provides some additional functionality to assist in the creation of a secure and auditable cloud environment. The security elements required by a cloud management portal are as follows:
-
PCI/ISO/FedRAMP/NIST 800-53 associated security controls
-
Governance, risk, and compliance (GRC)
-
Trusted execution platform
Trusted execution platform is the one element that we have covered in depth in the earlier chapters, so we will not cover that here. Let’s cover the other two elements briefly in the next two sections.
Security Controls
The security controls implemented in the reference design are based on NIST 800-53/FedRAMP, GLB, iTAR/EAR, applicable security controls to measure and secure connectivity between data centers.
NIST 800-53
NIST Special Publication 800-53 is part of the Special Publication 800-series that reports on the Information Technology Laboratory’s (ITL) research, guidelines, and outreach efforts in information system security, and on ITL’s activity with industry, government, and academic organizations. Specifically, NIST Special Publication 800-53 covers the steps in the risk management framework that address security control selection for federal information systems in accordance with the security requirements in Federal Information Processing Standard (FIPS) 200. This includes selecting an initial set of baseline security controls based on a FIPS 199 worst-case impact analysis, tailoring the baseline security controls, and supplementing the security controls based on an organizational assessment of risk. The security rules cover 17 areas, including access control, incident response, business continuity, and disaster recoverability. These controls are the management, operational, and technical safeguards (or countermeasures) prescribed for an information system to protect the confidentiality, integrity, and availability of the system and its information. To implement the needed safeguards or controls, agencies must first determine the security category of their information systems in accordance with the provisions of FIPS 199, “Standards for Security Categorization of Federal Information and Information Systems.” The security categorization of the information system (low, moderate, or high) determines the baseline collection of controls that must be implemented and monitored. Agencies have the ability to adjust these controls and tailor them to fit more closely with their organizational goals or environments.
Tables 9-1 through 9-4 show the subset of key NIST 800-53 controls that are implemented in this reference design to conform to a trusted architecture. The NIST 800-53 security controls have a well-defined organization and structure. To make it easy for selection and specification, controls are organized into 18 families. Each family contains security controls related to the general security topic of the family. A two-character identifier uniquely identifies security control families—for example, SI (system and information integration). Security controls may involve aspects of policy, oversight, supervision, manual processes, actions by individuals, or automated mechanisms implemented by information systems/devices. In the context of this reference design, the key controls that are implemented belong to four specific families of controls.
-
a.
CM Configuration Management
-
b.
SA System and Services Acquisition
-
c.
SC System and Communications Protection
-
d.
SI System and Information Integration
We will briefly mention the controls implemented for each of these families in the next three sections. Column1 provides the 800-53 control ID, column 2 describes the control, and column 3 provides additional commentary or guidance (if any) for each of the controls. Selecting and specifying security controls is based on the maturity of the organization’s information systems, how they manage risk, and the system impact level in accordance with FIPS 199 and FIPS 200. The selection of the security controls includes tailoring the initial set of baseline security controls and supplementing the tailored baseline as necessary, based on an organizational assessment of risk, and assessing the security controls as part of a comprehensive continuous monitoring process.
Governance, Risk, and Compliance (GRC)
By continuously assessing the compliance of the systems and the underlying cloud system, a tenant system can be assigned a granular rating traceable over time, allowing visibility into any threats presented by the underlying, normally invisible virtualized cloud infrastructure. The tenant is alerted to any potential threat originating within the infrastructure due to poor server management.
Figure 9-10 shows the xGRC rating system used in the reference design. These ratings allow for easier audit and reporting, as well as a simple method of assessing infrastructure health. The physical and virtual data center’s machine data are correlated and fed into GRC Reporting Tools in a continuous monitoring cycle and the related controls are maintained for the specific compliance frameworks—for example, NIST 800-53 or PCI etc. xStream’s xGRC provides this functionality in the reference architecture.

xGRC rating system
Practical Considerations for Virtual Machine Migration
In the initial discussion of cloud bursting, we glossed over a number of considerations in the interests of presenting a clear explanation. In particular, with the current state of the art, there are a number of limitations when it comes to migrating virtual machines across hypervisors. This is the problem of virtual machine interoperability. Footnote 1 The assumed environment for current practical implementations is a private cloud environment connected to the home base through VPN links. The VPN links are necessary to have all virtual machines in the same subnet. Furthermore, all virtual machine movements take place across hosts running the same hypervisor environment. There are a number of operational limitations that prevent virtual machine movements across different hypervisor environments or across public clouds with different providers.
Live migration is supported by the most commonly deployed hypervisor environments: Xen, VMware, and Microsoft Hyper-V. This is a case of homogeneous migration, where the source and target hosts run the same hypervisor environment. Homogeneous migration is the first of three possible levels for virtual machine interoperability or compatibility.Footnote 2
To summarize the DMTF definitions:
-
Level 1: Workloads under compatibility level 1 only run on a particular virtualization product and/or CPU architecture and/or virtual hardware selection. Level 1 portability is logically equivalent to a suspend operation in the source environment and a resume in the target environment.
-
Level 2: Workloads under compatibility level 2 are designed to run on a specific family of virtual hardware. Migration under level 2 is equivalent to a shutdown in the source environment followed by a reboot in the target environment.
-
Level 3: Workloads supporting level 3 compatibility are able to run on multiple families of virtual hardware.
Level 1 maps to homogeneous migration, the type of migration supported today within a single hypervisor environment and the only environment where live migration is feasible. Level 2 supports movement across heterogeneous hypervisor environments; this necessitates an intervening reboot. For this reason, this scheme is known as cold migration. Level 3 allows not only migration across different hypervisors but also across different host hardware architectures, and hence we identify it as heterogeneous architecture migration.
Live migration, when feasible, preserves the most operating states of a virtual machine image of the three schemes, including IP addresses and open file descriptors, and even transactions and streaming data in midstream. On the one hand, live migration may be required by some legacy applications that break after some of the state transitions mentioned above. On the other hand, requirements for live migration are strict: the target host usually needs to be part of a preconfigured cluster; the hosts need to be in the same subnet; and even if physically remote hosts are connected through a VPN tunnel, latency due to the trombone effect may induce failures. Live migration is not possible across heterogeneous hypervisor environments.
Heterogeneous hypervisor migration relaxes some of the environmental requirements compared to live migration. A logical shutdown and restart means that virtual machines in the target environment may end up running with a different set of IP addresses. Open file descriptors may be different, even though they may be reaching the same files; the descriptors may point to a remote file that was previously local. Transactions interrupted during the migration may have to be rolled back and retried. The virtual machine image needs to be remapped to run in the new target hypervisor environment. It is not practical to modify the memory image to run in the new environment, and hence the need for a reboot. For applications that can tolerate these environment changes, cold migration offers a broader choice of target service providers.
Heterogeneous architecture migration provides the least support of state preservation. At the same time, it provides the most options in running an application across computer architectures or service providers. It potentially involves reassembling the application in the target environment. Loose coupling becomes obligatory. This applies to advanced methodologies, such as integrated development and operations (DevOps).Footnote 3 Heterogeneous architecture migration offers the broadest choices for operating environments, running not only on a variety of hypervisor environment but also across platform architectures. The trade-off is being the least state-preserving of the three levels.
From the discussion above, it becomes clear that cloud bursting options need not include live migration as an obligatory requirement. Loosely coupled application components may be instantiated as levels 2 or 3 cloud bursting components. An example of level 2 bursting could be web server front-end instances connected to the mid-tier through DCOM or CORBA. Examples of level 3 bursting could be web server front-end components connected to the application through REST interfaces, or even instantiating auxiliary services such as content delivery networks or connecting to API managers.
Summary
This chapter on cloud bursting references an architecture design utilized by Virtustream, which marks the beginning of a new era in cloud computing. This is an era when the migration and bursting of workloads to trusted federated cloud partners, whether in a private or public infrastructure, will industrialize a new mode of cloud operations via a highly efficient model to enable the consumption of cloud resources in an elastic manner that doesn’t compromise security. The chapter covered the reference design leveraging Intel Corporation’s TXT technology to ensure the platform boot integrity and attestation, both in the private cloud infrastructure and the external/overflow capacity. The integration of Virtustream’s xStream cloud management platform with Intel TXT via the Mt. Wilson trust attestation authority provides an automated and production-ready cloud platform to accomplish the secure cloud bursting architecture and usage.
This is just the beginning. As discussed in the chapter, there are regulatory compliance issues, quality of service questions, and data locality and governance matters, as well as the immaturity of the monitoring and remediation components. The Virtustream xStream cloud management software used in this reference design and the proof of concept begin to address many of these problems. This and other cloud architectures will continue to evolve as real-world organizational requirements change, and as proofs of concept such as the illustrated proof of concept in this chapter exercise existing technology to its limits, requiring new technologies to be created or improve upon what presently exists.
VIRTUSTREAM OVERVIEW
Virtustream is a leading Enterprise Class Cloud solution provider for global 2000 workloads. xStream™ is Virtustream’s Enterprise Class Cloud solution allowing both mission-critical legacy and web-scale applications to run in the cloud—whether private, virtual private or public. xStream uses μVM technology to deliver enterprise-grade security/compliance, application performance SLAs, consumption-based pricing, significant cost efficiency beyond virtualization and the ability to deliver IT in minutes rather than months. xStream is available as software, appliance or a managed service and works with all leading hardware and virtualization software.
Figure 9-11 shows the overview of xStream management software.

Virtustream xStream Software
Notes
- 1.
Open Data Center Alliance Usage: Virtual Machine (VM) Interoperability in a Hybrid Cloud Environment Rev. 1.2; http://www.opendatacenteralliance.org/docs/Virtual_Machine_%28VM%29_Interoperability_in_a_Hybrid_Cloud_Environment_Rev1.2.pdf .
- 2.
DMTF, Open Virtualization Format White Paper, OVF version 1.0.0e, paper DSP2017, 2/6/2009, Section 5.
- 3.
Author information
Authors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License (http://creativecommons.org/licenses/by-nc-nd/4.0/), which permits any noncommercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this chapter or parts of it.
The images or other third party material in this chapter are included in the chapter’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the chapter’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2014 Raghu Yeluri
About this chapter
Cite this chapter
Yeluri, R., Castro-Leon, E. (2014). A Reference Design for Secure Cloud Bursting. In: Building the Infrastructure for Cloud Security. Apress, Berkeley, CA. https://doi.org/10.1007/978-1-4302-6146-9_9
Download citation
DOI: https://doi.org/10.1007/978-1-4302-6146-9_9
Published:
Publisher Name: Apress, Berkeley, CA
Print ISBN: 978-1-4302-6145-2
Online ISBN: 978-1-4302-6146-9
eBook Packages: Professional and Applied ComputingApress Access BooksProfessional and Applied Computing (R0)